Hive on Spark配置
前提条件
1、安装好Hive,参考:Hive安装部署-CSDN博客
2、下载好Spark安装包,链接:https://pan.baidu.com/s/1plIBKPUAv79WJxBSbdPODw?pwd=6666
3、将Spark安装包通过xftp上传到/opt/software
安装部署Spark
1、解压spark-3.3.1-bin-without-hadoop.tgz
进入安装包所在目录
cd /opt/software
解压缩
tar -zxvf spark-3.3.1-bin-without-hadoop.tgz -C /opt/moudle
进入解压后的目录,修改文件名
cd /opt/moudle
mv spark-3.3.1-bin-without-hadoop/ spark
2、修改spark-env.sh配置文件
进入配置目录
cd /opt/moudle/spark/conf/
编辑文件
vim spark-env.sh.template
末尾增加如下内容
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
将配置文件.template(不访问)去掉
mv spark-env.sh.template spark-env.sh

3、配置SPARK_HOME环境变量
vim /etc/profile.d/my_env.sh
添加如下内容
# SPARK_HOME
export SPARK_HOME=/opt/moudle/spark
export PATH=$PATH:$SPARK_HOME/bin

source 使其生效
source /etc/profile.d/my_env.sh
4、在hive中创建spark配置文件
vim /opt/moudle/hive/conf/spark-defaults.conf
添加如下内容(在执行任务时,会根据如下参数执行)。
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/spark-history
spark.executor.memory 1g
spark.driver.memory 1g

在HDFS创建如下路径,用于存储历史日志
hadoop fs -mkdir /spark-history
5、向HDFS上传Spark纯净版jar包
说明1:采用Spark纯净版jar包,不包含hadoop和hive相关依赖,能避免依赖冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
hadoop fs -mkdir /spark-jars
hadoop fs -put /opt/moudle/spark/jars/* /spark-jars

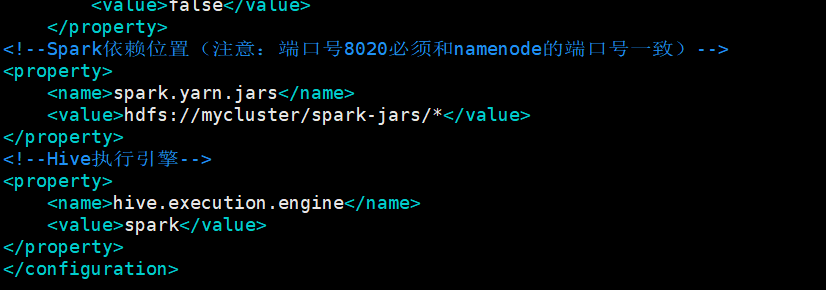
6、修改hive-site.xml文件
vim /opt/moudle/hive/conf/hive-site.xml

添加如下内容
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://mycluster/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
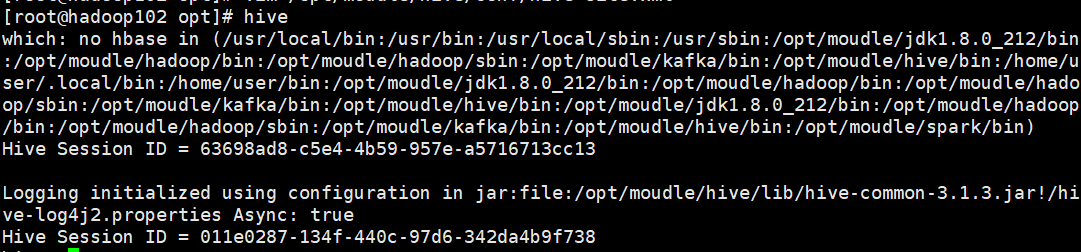
Hive on Spark测试
启动hive客户端
hive
创建一张测试表
create table student(id int, name string);
通过insert测试效果
insert into table student values(1,'abc');

若结果如下,则说明配置成功。

相关文章:
Hive on Spark配置
前提条件 1、安装好Hive,参考:Hive安装部署-CSDN博客 2、下载好Spark安装包,链接:https://pan.baidu.com/s/1plIBKPUAv79WJxBSbdPODw?pwd6666 3、将Spark安装包通过xftp上传到/opt/software 安装部署Spark 1、解压spark-3.3…...

计算机网络——11EMail
EMail 电子邮件(EMail) 3个主要组成部分 用户代理邮件服务器简单邮件传输协议:SMTP 用户代理 又名“邮件阅读器”撰写、编辑和阅读邮件输入和输出邮件保存在服务器上 邮件服务器 邮箱中管理和维护发送给用户的邮件输出报文队列保持待发…...
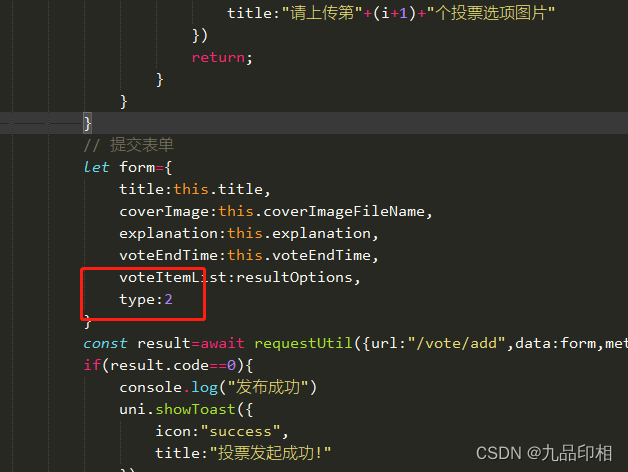
第13讲创建图文投票
创建图文投票实现 图文投票和文字投票基本一样,就是在投票选项里面,多了一个选项图片;、 <view class"option_item" v-for"(item,index) in options" :key"item.id"><view class"option_input&…...
Vulnhub靶机:DC3
一、介绍 运行环境:Virtualbox 攻击机:kali(10.0.2.15) 靶机:DC3(10.0.2.56) 目标:获取靶机root权限和flag 靶机下载地址:https://www.vulnhub.com/entry/dc-32,312…...

代码随想录算法训练营第三十一天|● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和
仅做学习笔记,详细请访问代码随想录 ● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和 ● 理论基础 有同学问了如何验证可不可以用贪心算法呢? 最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧。 …...
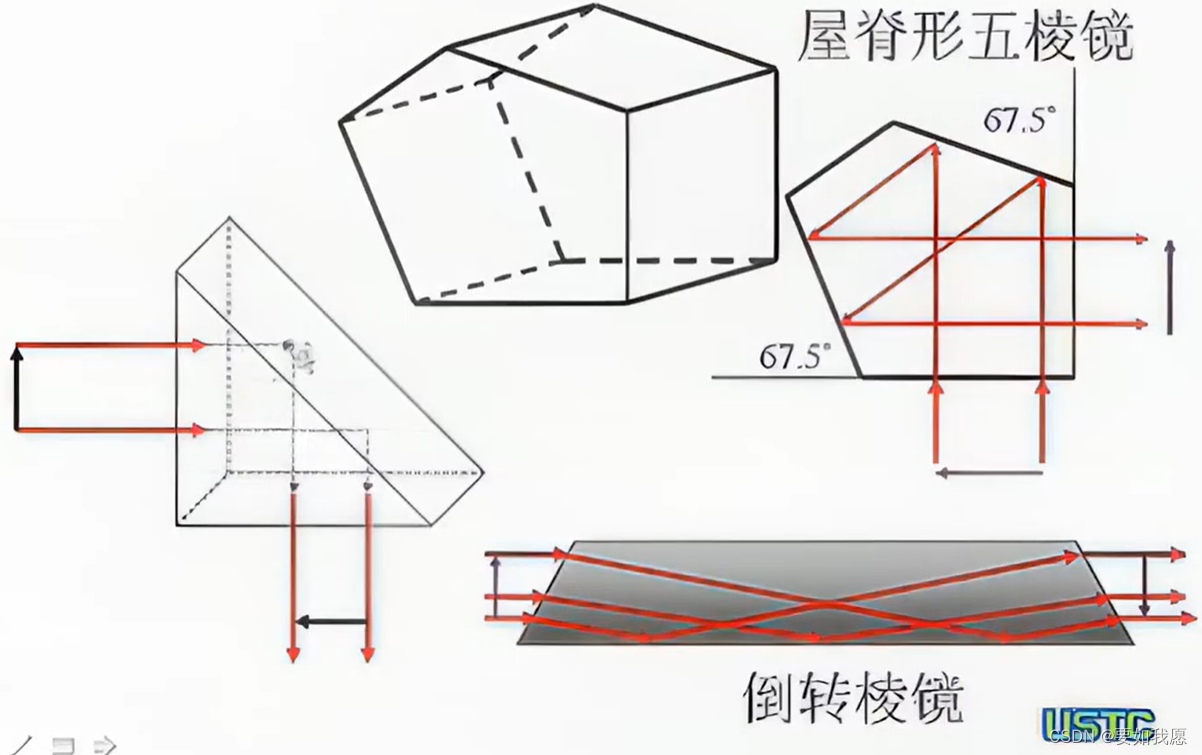
【光学】学习记录1-几何光学的近轴理论
课程来源:b站资源-光学-中科大-崔宏滨老师(感谢),本系列仅为自学笔记 【光学 中科大 崔宏滨老师 1080p高清修复(全集)】https://www.bilibili.com/video/BV1NG4y1C7T9?p2&vd_source7ba37b2cff2a1b783…...

【51单片机】AT24C02(江科大、爱上半导体)
一、AT24C02 1.AT24C02介绍 AT24C02是一种可以实现掉电不丢失的存储器,可用于保存单片机运行时想要永久保存的数据信息 存储介质:E2PROM 通讯接口:12C总线 容量:256字节 2.引脚即应用电路 本开发板AT24C02原理图 12C地址全接地,即全为0 WE接地,没有写使能 SCL接P21 S…...

nohup基本使用
在Linux终端命令中经常要使用到在关闭终端界面的情况下需要后台挂起执行的进程,也就是关闭终端后台任务的进程还是会常驻,下面就简单介绍下 nohup 命令 1. nohup nohup 英文全称 no hang up(不挂起),默认情况下&#x…...

postgresql 手动清理wal日志的101个坑
新年的第一天,总结下去年遇到的关于WAL日志清理的101个坑,以及如何相对安全地进行清理。前面是关于WAL日志堆积的原因分析,清理相关可以直接看第三部分。 首先说明,手动清理wal日志是一个高风险的操作,尤其对于带主从的…...

【开源训练数据集3】Top3人脸数据集及其使用方法-计算机视觉应用
目录 什么是人脸数据集? Top 3 人脸数据集 CelebFaces Attributes (CelebA)数据集 Flickr-Faces-HQ (FFHQ) 数据集 野外标记面孔 (LFW) 使用先进的人脸数据集 CelebA 访问数据集 在 Pytorch 中使用 CelebA 在 Tensorflow 中使用 CelebA Flickr-Faces-HQ 数据集 (FFH…...

精灵图,字体图标,CSS3三角
精灵图 1.1为什么需要精灵图 一个网页中往往会应用很多小的背景图像作为修饰,当网页中的图像过多时,服务器就会频繁的接受和发送请求图片,造成服务器请求压力过大,这将大大降低页面的加载速度。 因此,为了有效地减少…...

.NET Core性能优化技巧
.NET Core作为一个跨平台的开源框架,以其高效、灵活和可扩展的特性受到了广大开发者的青睐。但在实际开发中,如何确保应用程序的性能始终是一个关键的问题。本文将介绍十大.NET Core性能优化技巧,帮助开发者提升应用程序的性能。 1. 使用异步…...

人类智能远远超越了物理与数理范畴
德国哲学家黑格尔曾这样写道,我们越是熟悉的东西,就越不清楚它。这或许意味着当我们对某个事物非常熟悉时,可能会陷入一种思维定势,导致我们无法客观地认识和理解它。这种思维定势可能来自于习惯、传统观念或者个人经验࿰…...
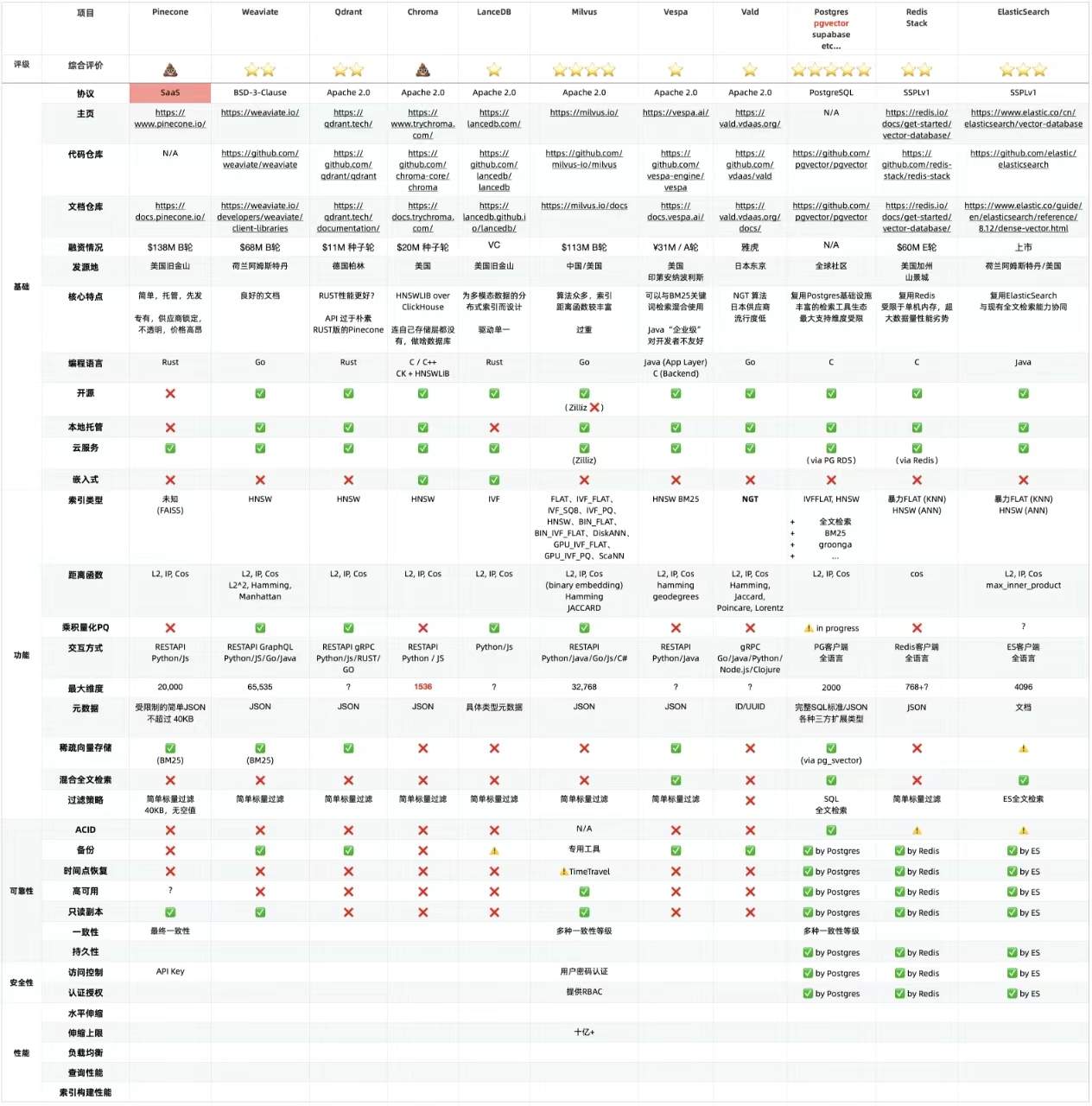
数据库管理-第149期 Oracle Vector DB AI-01(20240210)
数据库管理149期 2024-02-10 数据库管理-第149期 Oracle Vector DB & AI-01(20240210)1 机器学习2 向量3 向量嵌入4 向量检索5 向量数据库5 专用向量数据库的问题总结 数据库管理-第149期 Oracle Vector DB & AI-01(20240210…...
FlinkSql通用调优策略
历史文章迁移,稍后整理 使用DataGenerator 提前进行压测,了解数据的处理瓶颈、性能测试和消费能力 开启minibatch:"table.exec.mini-batch.enabled", "true" 开启LocalGlobal 两阶段聚合:"table.exec.m…...

Linux在云计算领域的重要作用
在云计算领域,Linux扮演着至关重要的角色。以下是Linux在云计算领域中的重要作用: 稳定性和安全性:Linux操作系统具有稳定性和安全性,可以有效地保护用户的数据安全。它具有各种安全功能,可以防止未经授权的访问&…...

sqlserver2012 解决日志大的问题 bat脚本
要解决SQL Server 2012中事务日志过大的问题,你可以创建一个批处理脚本(.bat)来定期备份事务日志。下面是一个示例批处理脚本,该脚本使用SQLCMD工具来执行事务日志备份: echo off set "DBNAMEYourDatabaseName&qu…...

SpringCloud之Eureka注册中心和负载均衡
SpringCloud之Eureka注册中心和负载均衡 微服务技术栈认识微服务单体架构分布式架构微服务 微服务拆分及远程调用微服务拆分注意事项 Eureka注册中心提供者与消费者原理分析服务调用出现的问题Eureka的作用 使用流程1、搭建EurekaServer2、注册user-service3、在order-service完…...

Python 数据可视化之山脊线图 Ridgeline Plots
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 JoyPy 是一个基于 matplotlib pandas 的单功能 Python 包,它的唯一目的是绘制山脊线图 Joyplots(也称为 Ridgeline Plots&…...
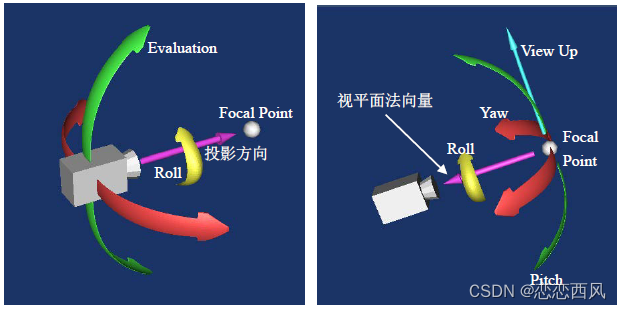
VTK 三维场景的基本要素(相机) vtkCamera 相机的运动
相机的运动 当物体在处于静止位置时,相机可以在物体周围移动,摄取不同角度的图像 移动 移动分为相机的移动,和相机焦点的移动;移动改变了相机相对焦点的位置,离焦点更近或者更远;这样就会改变被渲染的物体…...

CANN hcomm通道获取API
HcclChannelAcquire 【免费下载链接】hcomm HCOMM(Huawei Communication)是HCCL的通信基础库,提供通信域以及通信资源的管理能力。 项目地址: https://gitcode.com/cann/hcomm 产品支持情况 Ascend 950PR/Ascend 950DT:支…...

三步搞定Windows和Office永久激活:KMS_VL_ALL_AIO智能激活全攻略
三步搞定Windows和Office永久激活:KMS_VL_ALL_AIO智能激活全攻略 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office突然…...

Diablo Edit2完全指南:暗黑破坏神2存档修改器终极使用教程
Diablo Edit2完全指南:暗黑破坏神2存档修改器终极使用教程 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经在暗黑破坏神2中花费数小时刷装备却一无所获?或者想要…...
)
手把手教你搞定Windows下的NAMD和VMD安装(附最新版下载与注册避坑指南)
Windows平台NAMD与VMD安装全攻略:从零开始玩转分子动力学模拟 当第一次接触分子动力学模拟时,软件安装往往是新手面临的第一个挑战。NAMD和VMD作为该领域最常用的工具组合,它们的安装过程看似简单,实则暗藏诸多细节。本文将带你从…...

英雄联盟皮肤修改器R3nzSkin:从内存钩子到游戏逆向的完整技术指南
英雄联盟皮肤修改器R3nzSkin:从内存钩子到游戏逆向的完整技术指南 【免费下载链接】R3nzSkin Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3n/R3nzSkin R3nzSkin是一款专为《英雄联盟》设计的开源游戏皮肤修改器&a…...

Logisim保姆级避坑指南:从布尔表达式到卡诺图,一次搞定数字逻辑实验常见错误
Logisim数字逻辑实验避坑实战:从表达式到卡诺图的深度解法 为什么你的Logisim电路总是不工作? 刚接触数字逻辑实验时,我总在Logisim里反复调试同一个电路——明明按照教材步骤操作,仿真结果却和预期不符。直到某次深夜debug才发现…...
)
保姆级教程:在Windows上用CMake搞定Qt 6.5与WebRTC M114的集成(附完整代码)
Windows平台Qt 6.5与WebRTC M114深度集成实战指南 环境准备与工具链配置 在Windows平台上进行Qt与WebRTC的集成开发,首先需要搭建完整的工具链环境。不同于简单的库引用,这种深度集成对工具版本和系统配置有着严格要求。 必备组件清单: Visua…...

告别CV大法:用MyBatisX插件5分钟搞定MyBatis Plus全套基础代码
告别重复劳动:MyBatisX插件在MyBatis Plus项目中的高效实践 每次启动新项目时,面对数十张数据库表和数百个字段,你是否也厌倦了手动编写那些格式固定的实体类、Mapper接口和Service层代码?在团队协作中,这种重复劳动不…...

RH850 F1的FLASH自编程实战:如何在程序运行时安全更新数据闪存?
RH850 F1 FLASH自编程实战:如何在运行时安全更新数据闪存? 当车载ECU以120km/h行驶时,突然需要更新发动机标定参数——这个看似矛盾的场景,正是汽车电子工程师每天面对的挑战。RH850 F1系列微控制器独有的**后台操作(BGO)**功能&a…...

从零构建YOLOv8火焰烟雾检测系统:GUI开发、模型训练与实战部署全解析
1. 项目背景与核心价值 火焰烟雾检测在工业安全、森林防火和智能家居等领域有着广泛的应用需求。传统检测方法主要依赖传感器,但存在响应慢、覆盖范围有限等问题。基于计算机视觉的解决方案能够突破物理限制,实现大范围实时监控。YOLOv8作为当前最先进的…...