DS:二叉树的顺序结构及堆的实现

创作不易,兄弟们给个三连!!
一、二叉树的顺序存储

顺序结构指的是利用数组来存储,一般只适用于表示完全二叉树,原因如上图,存储不完全二叉树会造成空间上的浪费,有的人又会问,为什么图中空的位置不能存储呢??原因是我们需要根据数组的下标关系才能访问到对应的节点!!有以下两个下标关系公式:
1、父亲找孩子:leftchild=parent*2+1,rightchild=parent*2+2
2、孩子找父亲:parent=(child-1)/2 要注意,这边无论用左孩子算还是右孩子算都是可以的,因为一般俩说,(child-1)/2 由于int类型向下取整的特点,所以得到的结果都是一样的!!
所以我们想要上面这种方式去访问节点,并且还不希望有大量的空间浪费,现实中只有堆才会使用数组存储,二叉树的顺序存储中在物理上是一个数组,再逻辑上是一颗二叉树!!
二、堆的概念及结构
现实中我们把堆(类似完全二叉树)使用顺序结构来存储,要注意这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分区。
如果有一个关键码的集合k,我们将他的全部元素按照完全二叉树的存储逻辑放在一个一维数组中,则成为堆,根节点最大的堆叫做大堆,根节点最小的堆叫做小堆。
堆的性质:
1、堆中某个节点的值总是不大于或不小于其父节点的值
2、堆总是一颗完全二叉树
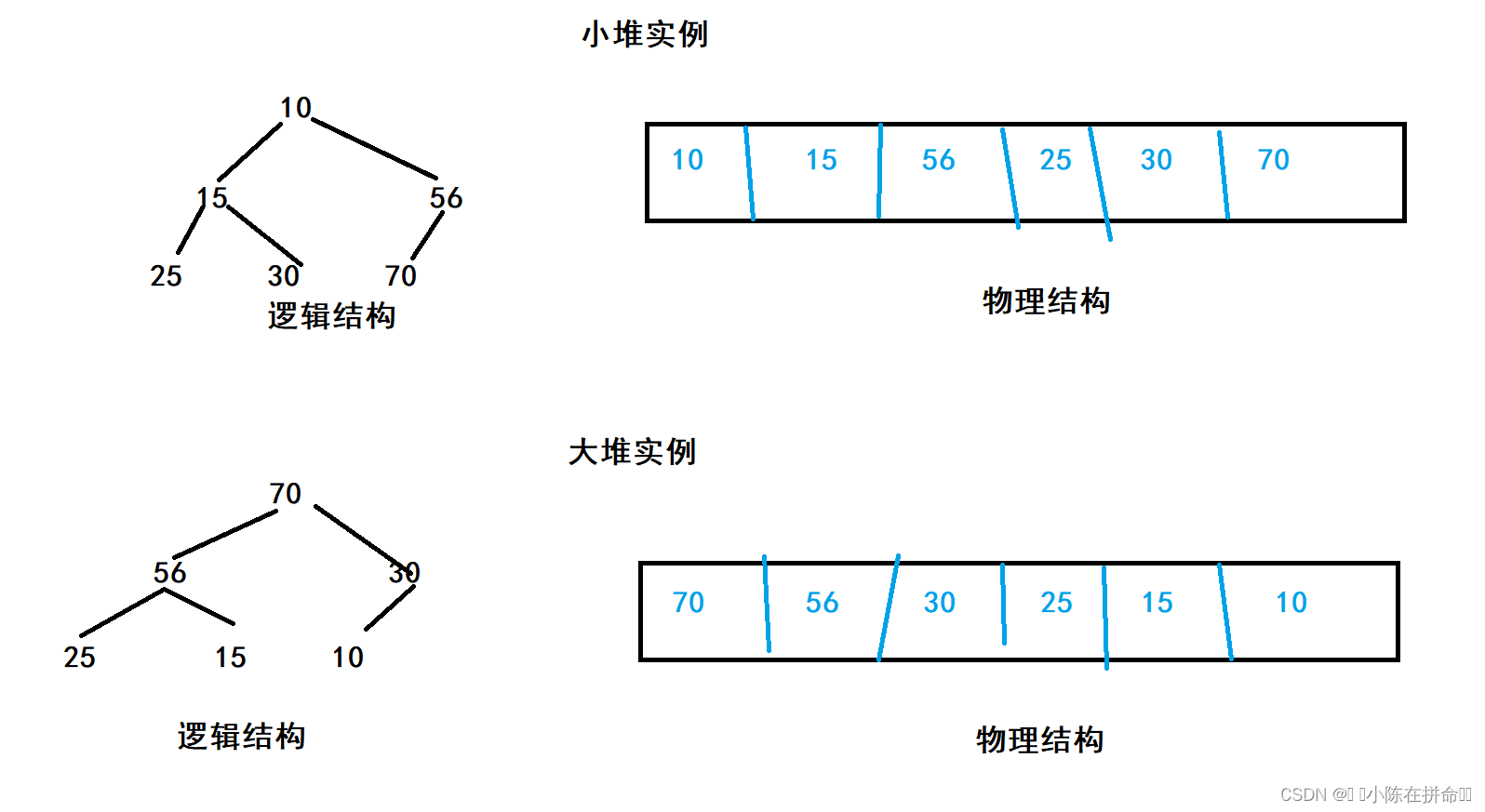
注意:并不一定有序
三、堆的实现
假设我们实现小堆
3.1 相关结构体的创建
跟顺序表的形式是一样的,但是换了个名字
typedef int HPDataType;
typedef struct Heap
{HPDataType * a;int size;int capacity;
}Heap;3.2 堆的初始化
void HeapInit(Heap* php)
{assert(php);php->a = NULL;php->capacity = php->size = 0;
}3.3 堆的插入
堆的插入很简单,但是我们要保证堆插入后还能维持堆的形状

所以我们在插入后,还要进行向上调整,也就是孩子要根据下标关系找到自己的父亲去比较,小就交换
void HeapPush(Heap* php, HPDataType x)
{assert(php);//首先要判断是否需要扩容if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* temp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * newcapacity);if (temp == NULL){perror("malloc fail");exit(1);}//扩容成功php->a = temp;php->capacity = newcapacity;}//扩容后,我们插入这个元素并size++php->a[php->size++] = x;//但是插入之后可能会破坏堆的结构,所以我们需要这个元素和他的父辈进行逐个比较, AdjustUp(php->a,php->size-1);//封装一个向上调整函数,传入数组和新加元素的下标
}3.4 向上调整算法
void AdjustUp(HPDataType* a, int child)
{assert(a);//通过孩子找父亲 parent=(child-1)/2int parent = (child - 1) / 2;//孩子和父亲开始比较,如果孩子小,就交换,如果孩子大,退出循环while (child>0)//如果孩子变成了根节点,就没有必要再找了,因为已经没有父母了//如果用parent>=0来判断,那么由于(0-1)/2是-1/2,取整后还是0,就会一直死循环,所以必须用孩子来当循环条件{if (a[child] < a[parent])//孩子小,交换{Swap(&a[child], &a[parent]);//但是交换过后,可能还需要继续往上比,所以我们要让原来的父亲变成孩子,然后再找新的父亲进行比较child = parent;parent = (child - 1) / 2;}else//孩子大,退出break;}
}注:这里的向上调整算法和后面向下调整算法我们都不用跟堆有关的接口,原因就是这个算法的运用范围很广,可以用在堆排序以及top-k问题中!!
3.5 交换函数
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType temp = *p1;*p1 = *p2;*p2 = temp;
}3.6 堆的删除
一般来说,如果直接删除堆的最后一个元素,其实是没什么意义的,一行代码就可以搞定,没必要封装什么函数,所以这里的堆的删除指的是删除根部的元素!!

void HeapPop(Heap* php)//一般来说,堆中的删除指的是删除根位置的数据
//如果直接删除根然后往前挪动一位,那么亲缘关系就会十分混乱,为了能够尽量在调整中减少对关系的改变
//我们将根部元素与最后一个元素进行交换之后再删除,此时的根是原先的最后一个元素
//然后将该元素进行向下调整(封装一个函数,传入数组、元素个数、)
{assert(php);assert(!HeapEmpty(php));//为空的话没有删除的必要Swap(&php->a[0], &php->a[php->size - 1]);php->size--;//开始向下调整AdjustDown(php->a, php->size,0);
}3.7 向下调整算法
void AdjustDown(HPDataType* a, int n,int parent)
{assert(a);//此时根部为原来的最后一个元素,往下比较//即通过父亲去找到自己的孩子,如果孩子比自己小,就得交换位置,如果孩子比自己大,就退出//但是因为父亲有一个左孩子parent*2+1,右孩子parent*2+2,我们选择孩子中较小的和自己交换int child = parent * 2 + 1;//假设左孩子比右孩子小while (child<n)//当child超出个数的时候结束{if (child+1<n && a[child + 1]<a[child])//如果右孩子比左孩子小,假设错误,修正错误//注意,一定不能写反,要注意只有左孩子没有右孩子的情况child++;if (a[child] < a[parent])//如果孩子小于父亲,交换{Swap(&a[child], &a[parent]);//交换完后,让原来的孩子变成父亲,然后再找新的孩子parent = child;child = parent * 2 + 1;}elsebreak;//如果孩子大于等于父亲,直接退出}
}在上述算法中,我们应用了先假设再推翻的方法,一开始我们先假设左孩子比较小,然后我们再给个条件判断,如果左孩子大于右孩子,假设不成立,再推翻,这样可以保证我们的child变量一定是较小的孩子!!
虽然这里的parent很明显是从a[0]开始,好像不需要专门去传一个parent的参数,但是这也是为了之后的堆排序做准备!
3.8 取堆顶的数据
HPDataType HeapTop(Heap* php)
{assert(php);assert(!HeapEmpty(php));//为空的话没有取的必要return php->a[0];
}3.9 堆的数据个数
int HeapSize(Heap* php)
{assert(php);return php->size;
}
3.10 堆的判空
bool HeapEmpty(Heap* php)
{assert(php);return php->size == 0;
}3.11 堆的销毁
void HeapDestory(Heap* php)
{assert(php);free(php->a);php->a = NULL;php->size = php->capacity = 0;
}3.12 堆的打印(测试)
我们要实现堆的打印,利用我们之前封装的函数,每获取一次堆顶元素就删除一次,直到堆删完就可以获取全部的元素了!!
#include"Heap.h"
int main()//该方法实现堆的顺序打印
{Heap hp;HeapInit(&hp);int a[] = { 55,100,70,32,50,60 };for (int i = 0; i < sizeof(a) / sizeof(int); i++)HeapPush(&hp, a[i]);//不断进堆while (!HeapEmpty(&hp)){int top = HeapTop(&hp);printf("%d\n", top);HeapPop(&hp);}HeapDestory(&hp);return 0;
}前面只是先创建一个堆,从while循环开始才是实现对堆的打印!!
运行结果 :32 50 55 60 70 100
我们发现了一个情况:按道理来说堆只有父子节点之间有大小关系,兄弟之间没有的,但是我们最后打印出来的结果却完成了排序!!!下面我们来进行分析
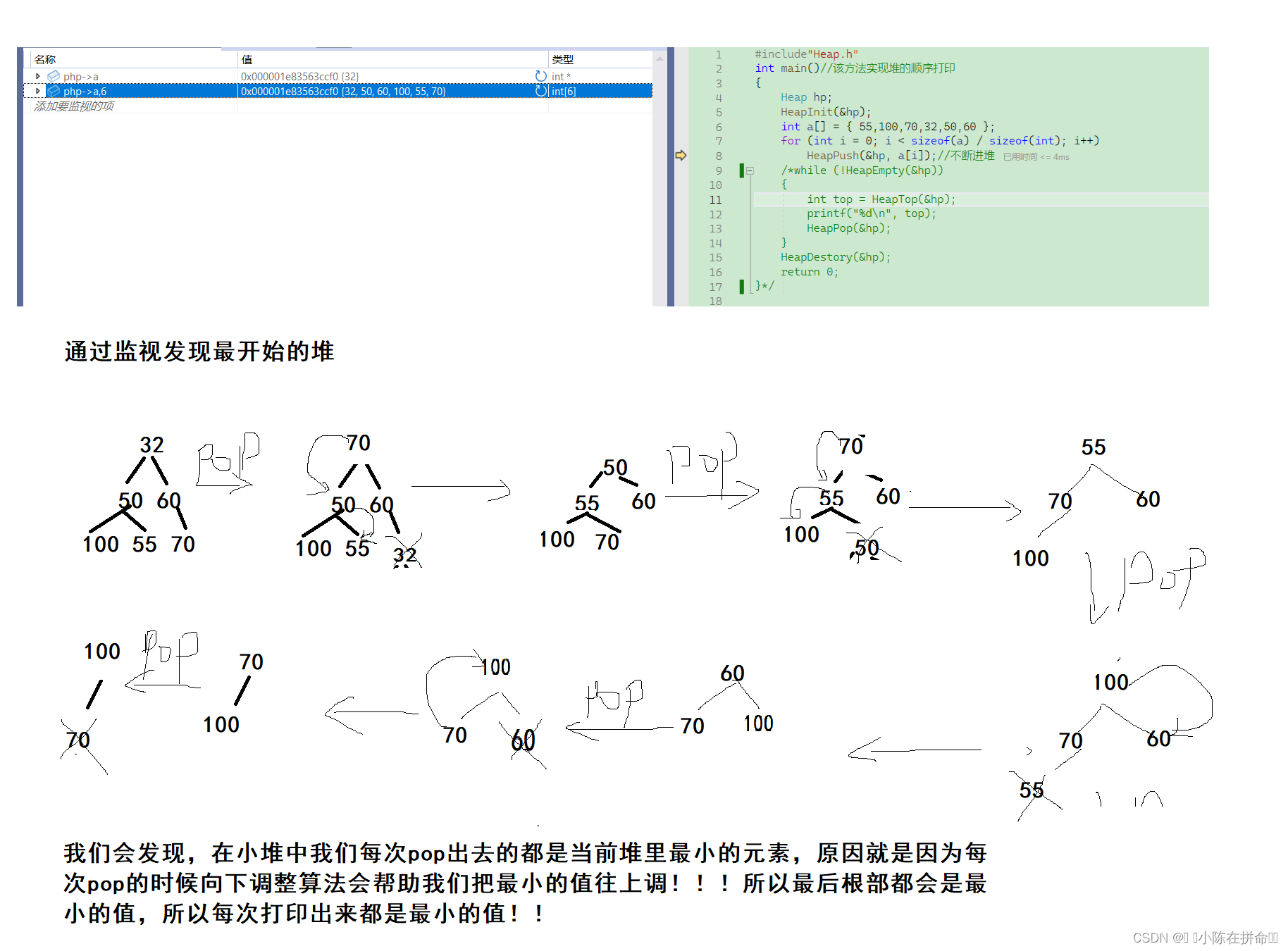
总之任何一个堆,我们都可以通过不断地pop去实现它的顺序打印!!堆排序后面会介绍!
四、堆实现的全部代码
4.1 Heap.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int HPDataType;
typedef struct Heap
{HPDataType * a;int size;int capacity;
}Heap;void Swap(HPDataType* p1, HPDataType* p2);//实现父亲和孩子的交换
void AdjustUp(HPDataType* a, int child);//向上调整算法// 堆的初始化
void HeapInit(Heap* php);
// 堆的插入
void HeapPush(Heap* php, HPDataType x);
// 堆的删除
void HeapPop(Heap* php);
// 取堆顶的数据
HPDataType HeapTop(Heap* php);
// 堆的数据个数
int HeapSize(Heap* php);
// 堆的判空
bool HeapEmpty(Heap* php);
// 堆的销毁
void HeapDestory(Heap* php);
4.2 Heap.c
#include"Heap.h"
//当前实现小堆
void HeapInit(Heap* php)
{assert(php);php->a = NULL;php->capacity = php->size = 0;
}void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType temp = *p1;*p1 = *p2;*p2 = temp;
}void AdjustUp(HPDataType* a, int child)
{assert(a);//通过孩子找父亲 parent=(child-1)/2int parent = (child - 1) / 2;//孩子和父亲开始比较,如果孩子小,就交换,如果孩子大,退出循环while (child>0)//如果孩子变成了根节点,就没有必要再找了,因为已经没有父母了//如果用parent>=0来判断,那么由于(0-1)/2是-1/2,取整后还是0,就会一直死循环,所以必须用孩子来当循环条件{if (a[child] < a[parent])//孩子小,交换{Swap(&a[child], &a[parent]);//但是交换过后,可能还需要继续往上比,所以我们要让原来的父亲变成孩子,然后再找新的父亲进行比较child = parent;parent = (child - 1) / 2;}else//孩子大,退出break;}
}void AdjustDown(HPDataType* a, int n,int parent)
{assert(a);//此时根部为原来的最后一个元素,往下比较//即通过父亲去找到自己的孩子,如果孩子比自己小,就得交换位置,如果孩子比自己大,就退出//但是因为父亲有一个左孩子parent*2+1,右孩子parent*2+2,我们选择孩子中较小的和自己交换int child = parent * 2 + 1;//假设左孩子比右孩子小while (child<n)//当child超出个数的时候结束{if (child+1<n && a[child + 1]<a[child])//如果右孩子比左孩子小,假设错误,修正错误//注意,一定不能写反,要注意只有左孩子没有右孩子的情况child++;if (a[child] < a[parent])//如果孩子小于父亲,交换{Swap(&a[child], &a[parent]);//交换完后,让原来的孩子变成父亲,然后再找新的孩子parent = child;child = parent * 2 + 1;}elsebreak;//如果孩子大于等于父亲,直接退出}
}void HeapPush(Heap* php, HPDataType x)
{assert(php);//首先要判断是否需要扩容if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* temp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * newcapacity);if (temp == NULL){perror("malloc fail");exit(1);}//扩容成功php->a = temp;php->capacity = newcapacity;}//扩容后,我们插入这个元素并size++php->a[php->size++] = x;//但是插入之后可能会破坏堆的结构,所以我们需要这个元素和他的父辈进行逐个比较, AdjustUp(php->a,php->size-1);//封装一个向上调整函数,传入数组和新加元素的下标
}void HeapPop(Heap* php)//一般来说,堆中的删除指的是删除根位置的数据
//如果直接删除根然后往前挪动一位,那么亲缘关系就会十分混乱,为了能够尽量在调整中减少对关系的改变
//我们将根部元素与最后一个元素进行交换之后再删除,此时的根是原先的最后一个元素
//然后将该元素进行向下调整(封装一个函数,传入数组、元素个数、)
{assert(php);assert(!HeapEmpty(php));//为空的话没有删除的必要Swap(&php->a[0], &php->a[php->size - 1]);php->size--;//开始向下调整AdjustDown(php->a, php->size,0);
}HPDataType HeapTop(Heap* php)
{assert(php);assert(!HeapEmpty(php));//为空的话没有取的必要return php->a[0];
}int HeapSize(Heap* php)
{assert(php);return php->size;
}bool HeapEmpty(Heap* php)
{assert(php);return php->size == 0;
}void HeapDestory(Heap* php)
{assert(php);free(php->a);php->a = NULL;php->size = php->capacity = 0;
}4.3 test.c(测试)
#include"Heap.h"
int main()//该方法实现堆的顺序打印
{Heap hp;HeapInit(&hp);int a[] = { 55,100,70,32,50,60 };for (int i = 0; i < sizeof(a) / sizeof(int); i++)HeapPush(&hp, a[i]);//不断进堆while (!HeapEmpty(&hp)){int top = HeapTop(&hp);printf("%d\n", top);HeapPop(&hp);}HeapDestory(&hp);return 0;
}
五、堆的应用
5.1 堆排序
要对数组排序前,我们要用堆排序,首先要建堆!
大家看看之前堆的打印时的测试代码逻辑的方法
就是我们得到一个数组,就先建堆,然后先把数组push进去,再pop出来,是可以实现有序的
但是现在我们的需求不是打印出来,而是将他排好序后放进数组里,所以们可以这么写:
void HeapSort(int* a, int n)
{HP hp;HeapInit(&hp);// N*logNfor (int i = 0; i < n; ++i){HeapPush(&hp, a[i]);}// N*logNint i = 0;while (!HeapEmpty(&hp)){int top = HeapTop(&hp);a[i++] = top;HeapPop(&hp);}HeapDestroy(&hp);
}这个方法固然是可以的,但是很麻烦,原因如下:
1、每次都要建立一个新的堆,然后再销毁,比较麻烦,而且空间复杂度比较高
2、我通过把数组放进变成堆,还要再把堆拷贝到数组中,数据的拷贝是很繁琐的!!
所以我们要思考一种方式避免数据的拷贝,所以就有了向上调整建堆和向下调整建堆的方法了!!
也就是我们在原数组的基础上直接建堆,然后向下调整排序即可,下面会详细介绍
5.1.1 向上调整建堆
 假设数组有n个元素
假设数组有n个元素
for (int i = 1; i < n; i++)
{AdjustUp(a, i);
}5.1.2 向下调整建堆
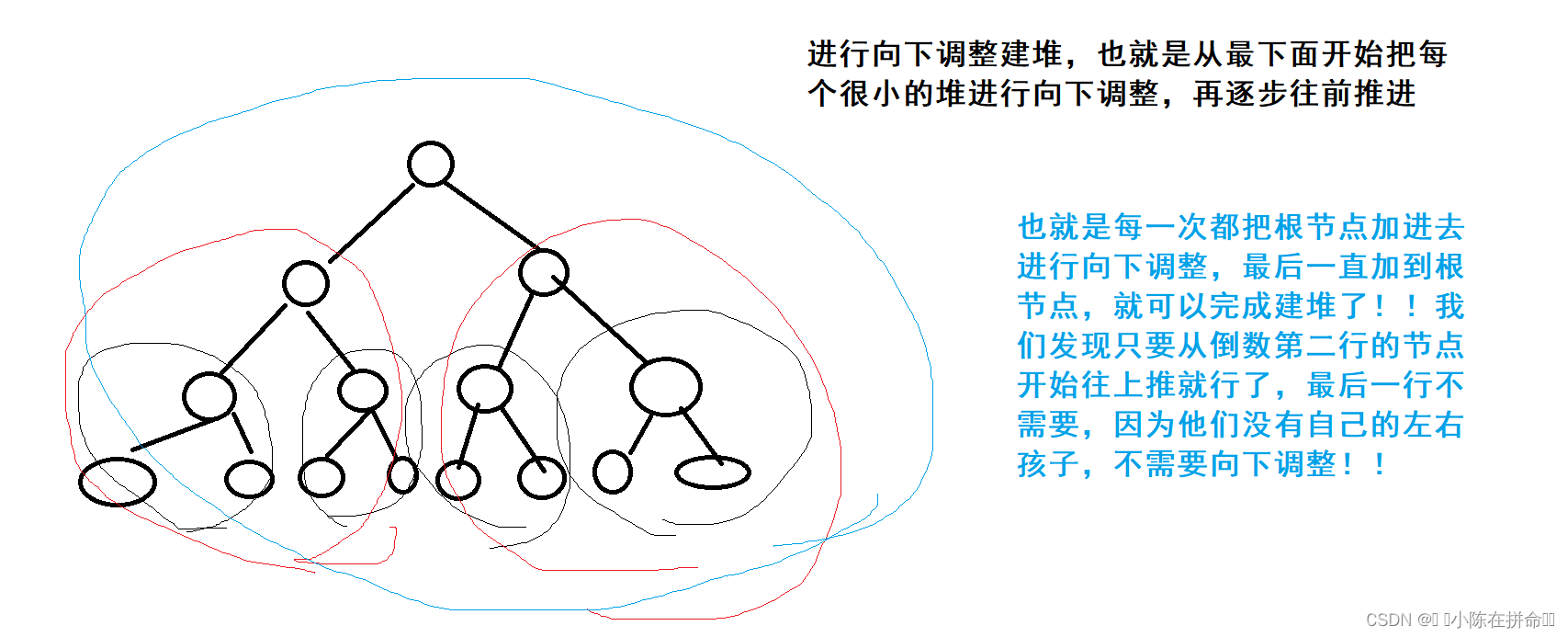
for (int i = (n-1-1)/2; i >= 0; i--)
{AdjustDown(a, n, i);
}5.1.3 堆排序的实现
那我们究竟选择向下建堆好还是向下建堆好呢??我们来分析一下
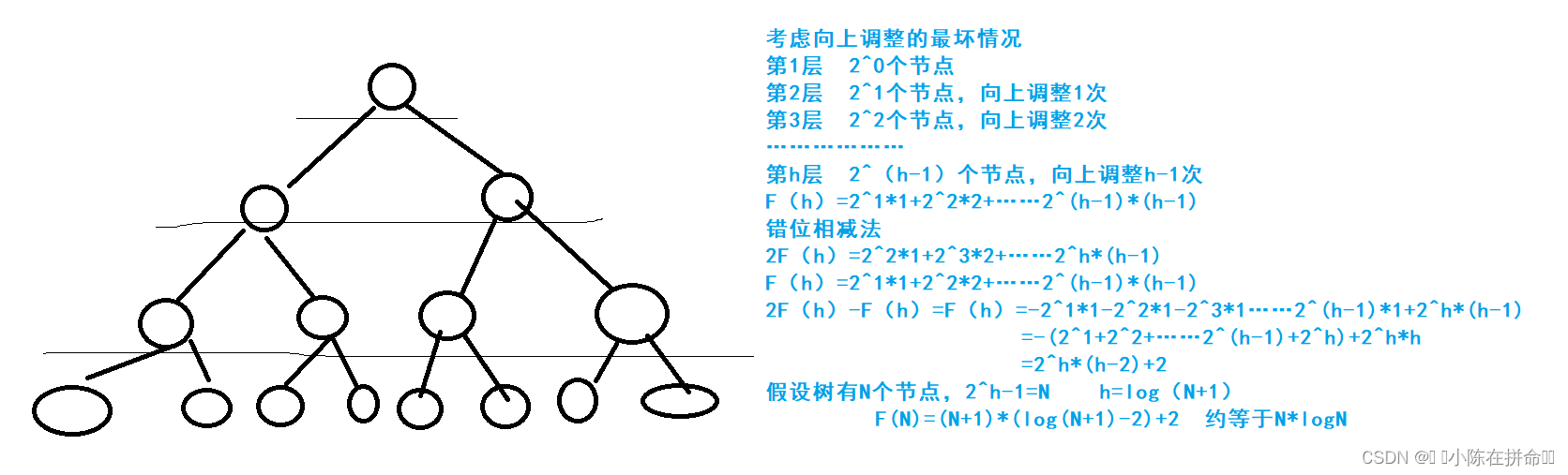
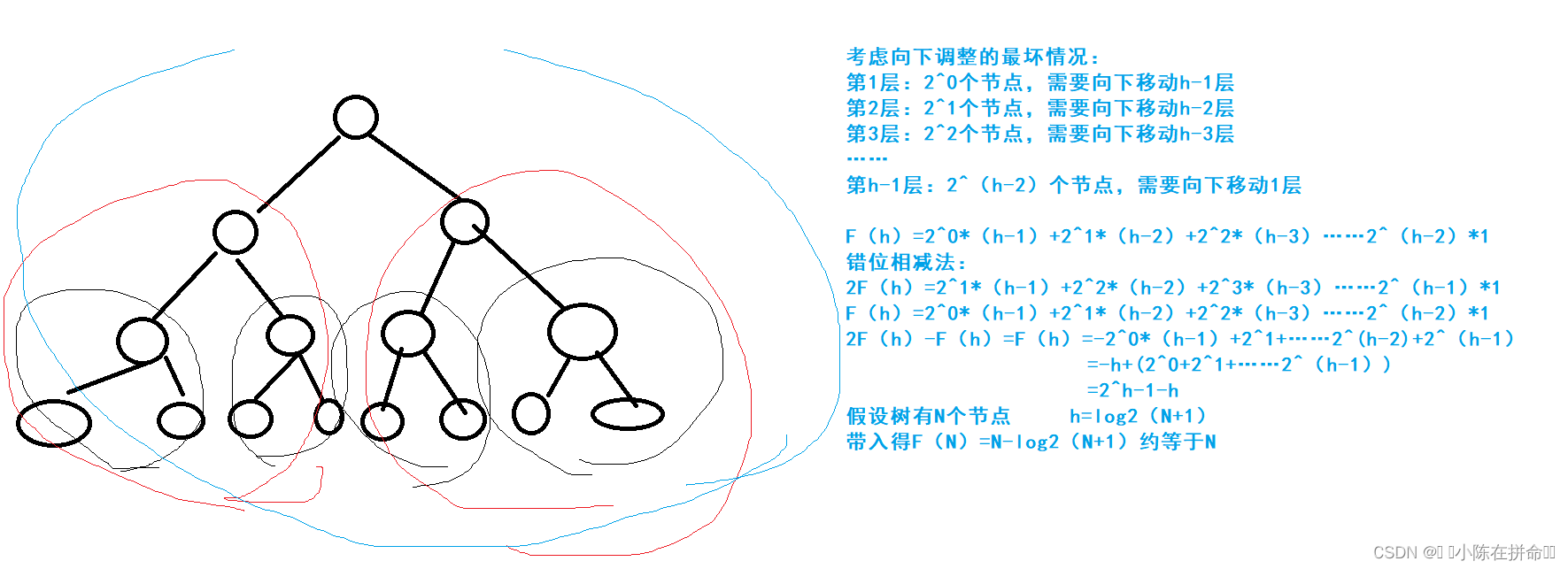
所以我们发现向上调整建堆的时间复杂度大概是N*logN,而向下调整建堆的时间复杂度是N
其实们在推导的时候也能发现,向上调整建堆是节点多的情况调整得多,节点少的情况调整的少,次数是多*多+少*少 ,而向下调整建堆是节点多的情况调整得少,节点少的情况调整的多,次数是多*少+少*多,显然是向下调整建堆是更有优势的!!
接下去我们建好堆,就要想着怎么去排序了,我们思考一下,之前我们对堆的打印时,不断pop打印出来有序结果的原因是什么??原因就是pop函数里的向下调整算法!!每一次交换根节点和尾节点,将每个节点进行向下调整,最后就可以得到有序的

因为我们之前实现的向下调整算法是小堆的,所以我们这边来实现一个降序的堆排序算法
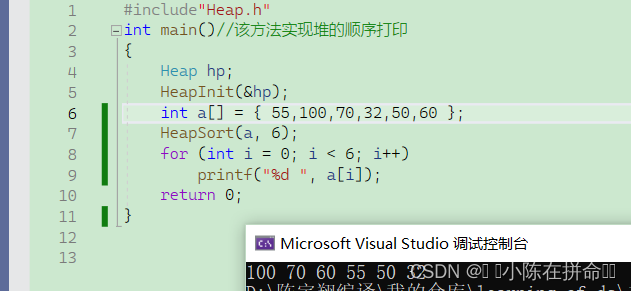
void HeapSort(int* a, int n)
{//降序 建小堆//升序 建大堆for (int i = (n-1-1)/2; i >=0;i--)AdjustDown(a, n, i);//开始排序 先交换向下调整int end = n - 1;while (end >= 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
} 
如果我们想实现升序,将向下调整算法按照大堆的规则改一下就行
向下调整算法和向上调整算法的空间复杂度都是(logN)
堆排序中,建堆的时间复杂度是o(N),排序的时间复杂度是(N*logN)所以堆排序的总时间复杂度是N*logN
5.2 TOP-K问题
Top-k问题:即求数据中前k个最大的元素或者是最小的元素,一般情况下的数据量都比较大!
比如:专业前10名、世界五百强、富豪榜前十
堆排序能够帮助我们在大量数据中筛选出最好的几个。
5.2.1 思路
比如说我们要从1000个学生的成绩中找到前10个分数最高的,方法就是将所有的数据放在一个数组里,直接建大堆,然后pop9次就可以找到了(pop中的向下调整算法可以使得每次pop出去的都是最大值,然后pop9次的原因是因为第10次就可以直接去获取堆顶元素即可)
但是有些情况,上述思路解决不了,分析:

5.2.2 通过数组验证TOP-K
void PrintTopK(int* a, int n, int k)
{//建前k个建小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--)AdjustDown(a, k, i);//将剩余n个数据不断与堆顶元素比较,大就交换,然后向下调整for (int i = k; i < n; i++){if (a[i] > a[0]){a[0] = a[i];//直接覆盖就行,不用交换AdjustDown(a, k, 0);}}//打印for(int i=0;i<k;i++)printf("%d ", a[i]);
}void TestTopk()
{int n = 10000;int* a = (int*)malloc(sizeof(int) * n);srand((unsigned int)time(NULL));for (size_t i = 0; i < n; ++i){a[i] = rand() % 1000000;//随机数范围0-999999}
// 为了能够方便找到这些数a[5] = 1000000 + 1;a[1231] = 1000000 + 2;a[531] = 1000000 + 3;a[5121] = 1000000 + 4;a[115] = 1000000 + 5;a[2335] = 1000000 + 6;a[9999] = 1000000 + 7;a[76] = 1000000 + 8;a[423] = 1000000 + 9;a[3144] = 1000000 + 10;PrintTopK(a, n, 10);
}int main()
{TestTopk();return 0;
}

5.2.3 通过文件验证TOP-K
其实用数组的方法,并不能有效地模拟,我们可以尝试用文件的方式来验证
void CreateNDate()
{// 造数据int n = 10000;srand((unsigned int)time(NULL));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (size_t i = 0; i < n; ++i){int x = rand() % 1000000;fprintf(fin, "%d\n", x);//将随机数写进文件}fclose(fin);
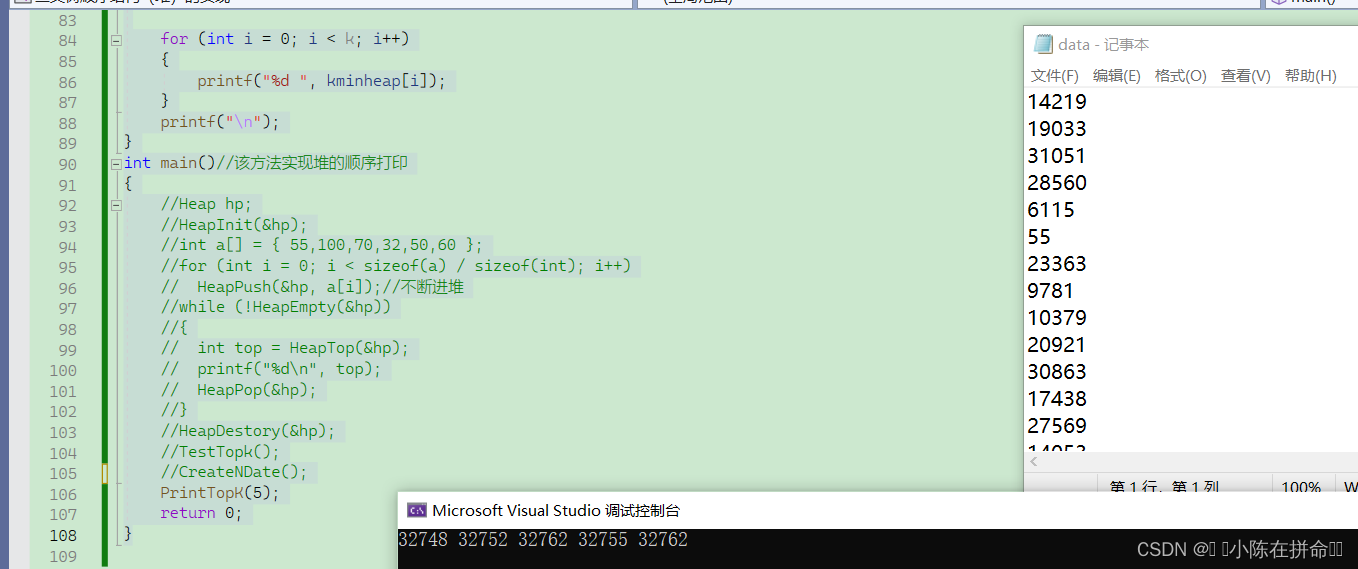
}void PrintTopK(int k)
{const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen fail");return;}int* kminheap = (int*)malloc(sizeof(int) * k);if (kminheap == NULL){perror("malloc fail");return;}for (int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]);//从文件读取数据}// 建小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(kminheap, k, i);}int val = 0;while (!feof(fout))//feof是文件结束的标识,如果返回1,则说明文件结束{fscanf(fout, "%d", &val);//fscaf的光标闪动到原先的位置,所以会从k的位置开始读if (val > kminheap[0]){kminheap[0] = val;AdjustDown(kminheap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");
}
int main()//该方法实现堆的顺序打印
{CreateNDate();PrintTopK(5);return 0;
}友友们上述代码有不理解的,看看博主关于文件操作里的函数介绍:
C语言:文件操作详解-CSDN博客
 不太好找,所以我们可以先注释创造数据的文件,然后再文件中修该出5个最大数,然后再执行一次函数
不太好找,所以我们可以先注释创造数据的文件,然后再文件中修该出5个最大数,然后再执行一次函数


以上就是通过数组验证top和利用文件验证tok的方法!!
相关文章:
DS:二叉树的顺序结构及堆的实现
创作不易,兄弟们给个三连!! 一、二叉树的顺序存储 顺序结构指的是利用数组来存储,一般只适用于表示完全二叉树,原因如上图,存储不完全二叉树会造成空间上的浪费,有的人又会问,为什么…...
:python的多线程详细使用)
python从入门到精通(十九):python的多线程详细使用
python的多线程详细使用 1.什么是线程2.线程的作用3.导入线程4.创建线程启动线程线程阻塞线程的方法守护线程线程阻塞2个都是守护线程1个是守护线程线程间通信1.什么是线程 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指…...

【More Effective C++】条款19:了解临时对象的来源
临时对象:没有命名,不会出现在源代码中 帮助隐式类型转换成功而创建的对象 编译器创建一个类型为string的临时对象,以buffer作为参数,调用string的构造函数;str绑定到了这个临时对象上函数返回时,这个临时…...
站在C/C++的肩膀速通Java面向对象
默认学过C或C,对变量、表达式、选择、循环都会。 运行特征 解释型语言(JavaScript、Python等) 源文件-(平台专属解释器)->解释器中执行编译型语言(C、Go等) 源文件-(平台编译器)->平台可执行文件Java 源文件-(…...

【AI视野·今日Robot 机器人论文速览 第七十八期】Wed, 17 Jan 2024
AI视野今日CS.Robotics 机器人学论文速览 Wed, 17 Jan 2024 Totally 49 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers Safe Mission-Level Path Planning for Exploration of Lunar Shadowed Regions by a Solar-Powered Rover Authors Olivier L…...

flask cors 跨域问题解决
座右铭:怎么简单怎么来,以实现功能为主。 欢迎大家关注公众号与我交流 环境安装 pip install -U flask-cors 示例代码 from flask import Flask from flask_cors import CORS, cross_originapp Flask(__name__) CORS(app, supports_credentialsTrue)…...
18 19 SPI接口的74HC595驱动数码管实验
1. 串行移位寄存器原理(以四个移位寄存器为例) 1. 通过移位寄存器实现串转并:一个数据输入端口可得到四位并行数据。 通过给data输送0101数据,那么在经过四个时钟周期后,与data相连的四个寄存器的输出端口得到了0101…...
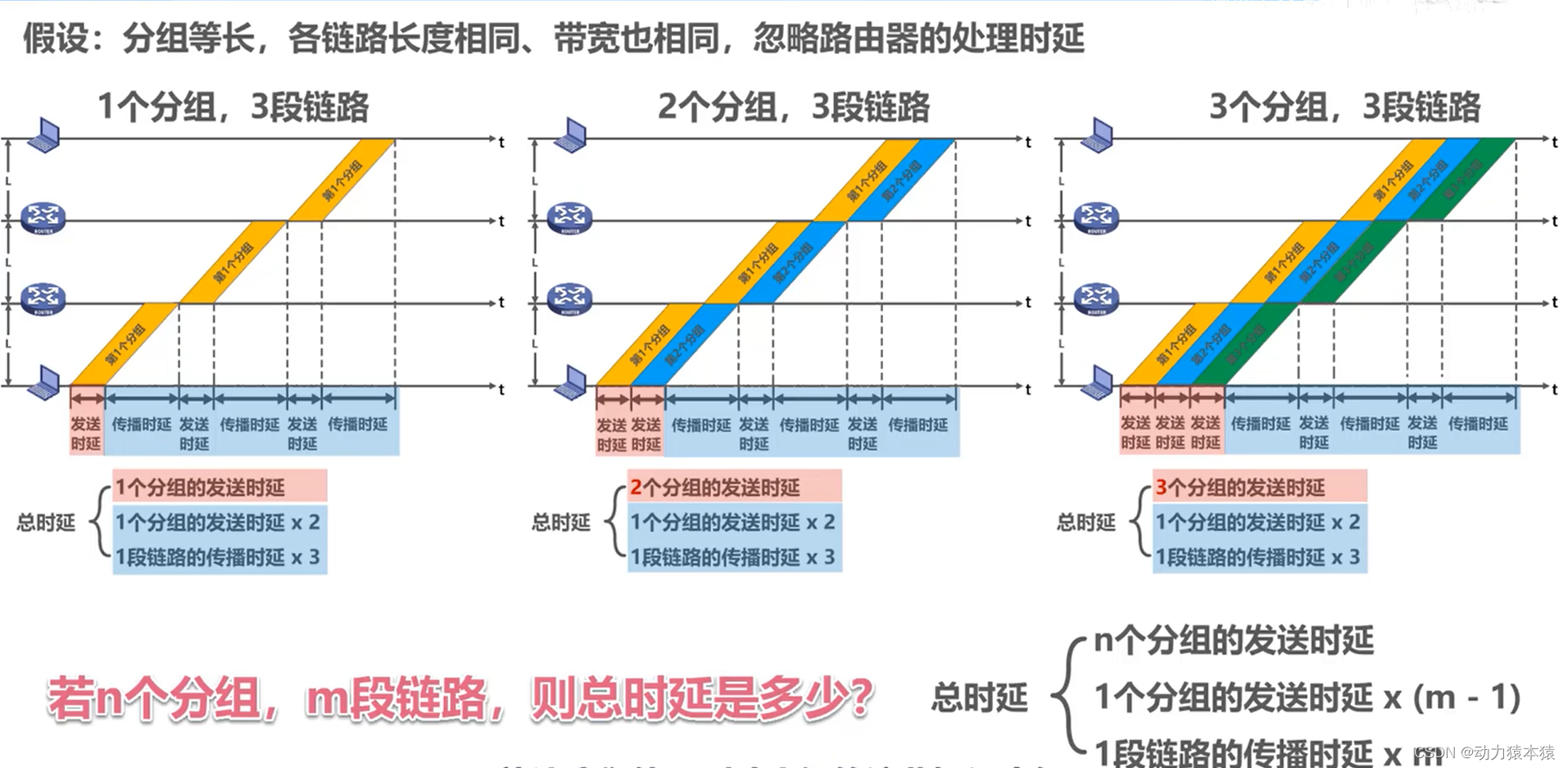
计算机网络概述习题拾遗
学习目标: 自下而上第一个提供端到端服务的层次 路由器、交换机、集线器实现的功能层 TCP/IP体系结构的网络接口层对应OSI体系结构的哪两个层次 分组数量对总时延的影响 如果这篇文章对您有帮助,麻烦点赞关注支持一下动力猿吧! 学习内容…...

你的电脑关机吗
目录 程序员为什么不喜欢关电脑? 电脑长时间不关机会怎样? 电脑卡顿 中度风险 硬件损耗 能源浪费 散热问题 软件问题 网络安全问题 程序员为什么不喜欢关电脑? 大部分人都会选择将电脑进行关机操作。其实这不难理解,毕竟人类都需要…...
flask+python儿童福利院管理系统pycharm毕业设计项目
本系统解决了儿童福利院管理事务中的主要问题,包括首页、个人中心、爱心人士管理、员工管理、后勤人员管理、儿童信息管理、院所风采管理、活动管理、食谱管理、领养流程管理、政策法规管理、楼栋管理、宿舍管理、领养申请管理、义工申请管理、捐赠信息管理、宿舍物…...

React:高阶组件|ref转发
高阶组件 参考文档:高阶组件 – React (reactjs.org) 高阶组件(Higher-Order Components,简称 HOC)是React中用于复用组件逻辑的一种高级技巧。具体而言:高阶组件是参数为组件,返回值为新组件的函数。 组件…...

AI:127-基于卷积神经网络的交通拥堵预测
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~ 🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带有在本地跑过的关键代码,详细讲解供…...

MongoDB聚合操作符:$abs
$abs聚合操作符用于返回数值的绝对值。 语法 { $abs: <数值> }<数值>表达式可以是任何能被解析为数值的合法表达式。 用法 如果$abs的<number>参数被解析为null值或引用不存在的字段,将返回null,如果参数被解析为NaN,也…...

【element-ui】输入框组件el-input输入数字/输出Number类型:type=“number“、v-model.number用法
输入框组件el-input输入数字/输出Number类型 1、基础用法 输入:任何文本 → 输出:String类型 <el-input v-model"inputText"></el-input> <!-- 输入 abc —— inputText输出 "abc" 输入 123 —— inputText输出 …...
算法与数据结构
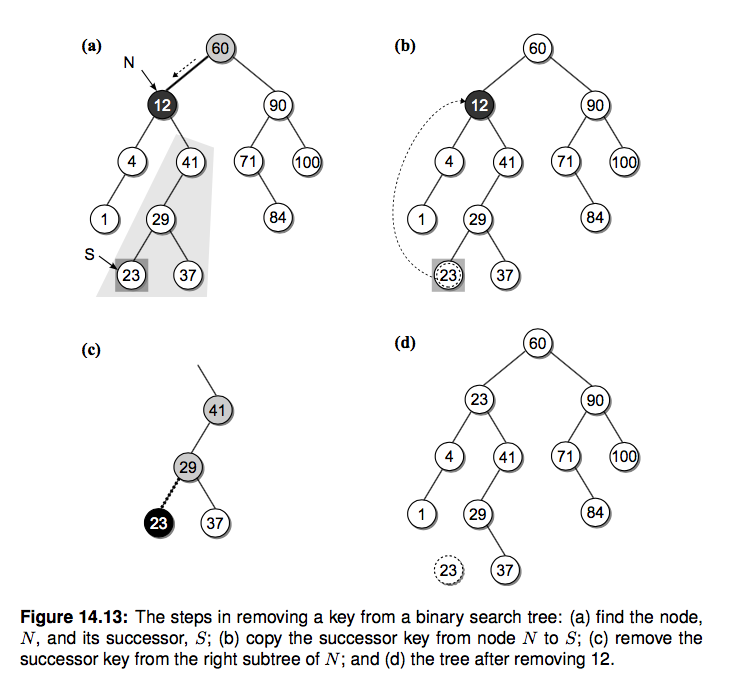
算法与数据结构 前言 什么是算法和数据结构? 你可能会在一些教材上看到这句话: 程序 算法 数据结构 算法(Algorithm):是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代…...
C++动态规划-线性dp算法
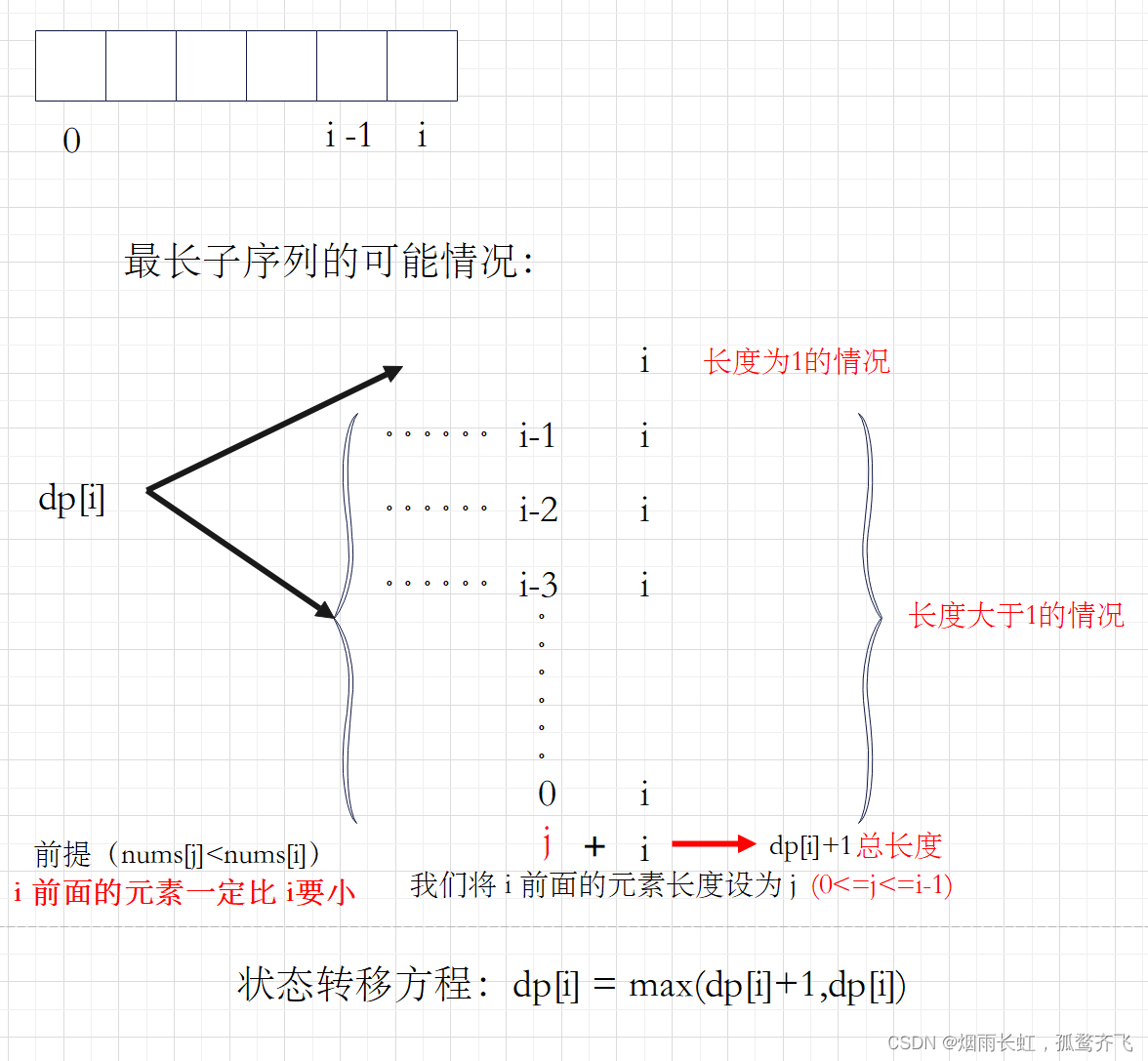
莫愁千里路 自有到来风 CSDN 请求进入专栏 X 是否进入《C专栏》? 确定 目录 线性dp简介 斐波那契数列模型 第N个泰波那契数 思路: 代码测试: 三步问题 思路: 代码测试: 最小花费爬楼梯 思路…...
基于 Python 深度学习的电影评论情感分析系统,附源码
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
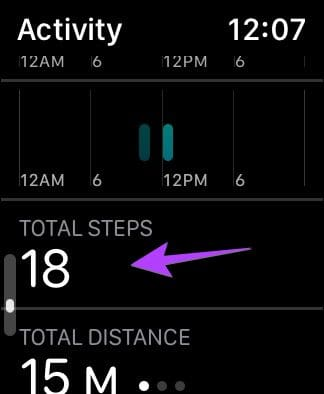
如何查看Apple Watch的步数?这里提供几个方法
所有Apple Watch都配有内置计步器,即具有步进跟踪功能。当你第一次设置手表时,你的Apple Watch将自动开始计算步数。让我们看看如何在Apple Watch上查看步数。 使用活动应用程序 1、按下Apple Watch上的数字皇冠,打开应用程序屏幕。 2、点击活动应用程序。 3、你会看到…...
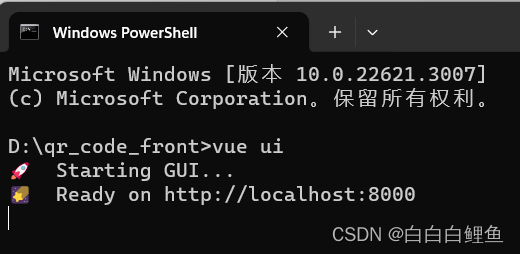
解决‘vue‘ 不是内部或外部命令,也不是可运行的程序(设置全局变量)
发现是没有执行: npm install -g vue/cli 但是发现还是不行 此时,我们安装了 Vue CLI,但是在运行 vue ui 命令时出现了问题。这通常是因为全局安装的 Vue CLI 的路径没有被正确地添加到系统的环境变量中。 可以尝试以下几种方法来解决这个问…...
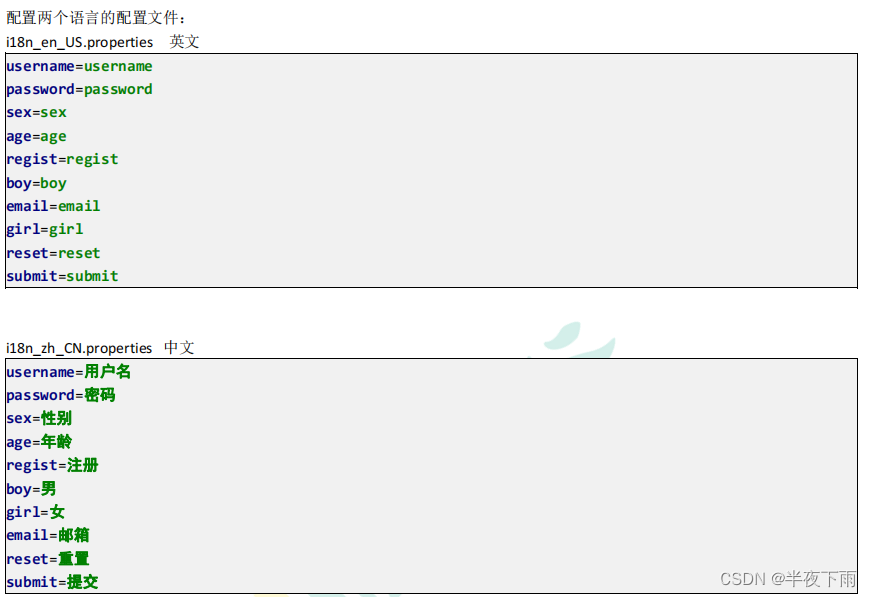
JavaWeb学习|i18n
学习材料声明 所有知识点都来自互联网,进行总结和梳理,侵权必删。 引用来源:尚硅谷最新版JavaWeb全套教程,java web零基础入门完整版 i18n 国际化(Internationalization)指的是同一个网站可以支持多种不同的语言&…...

ABAP 采购带组件收货BAPI
一、背景 有一项业务比较特殊,金靶的回收加工,既会有物料的消耗,也会收进上一批加工洗出来的物料,并且组件物料会带有批次,MIGO过账时需要填写批次,那么对应BAPI,也需要加入这一部分批次。如果…...
)
别再点那个小箭头了!手把手教你用自定义按钮控制ElementUI表格展开行(Vue3 + Element Plus版)
用文字按钮重构Element Plus表格交互:让展开行操作更符合用户直觉 后台管理系统中最常见的交互痛点之一,就是默认的表格展开箭头设计。当用户面对密密麻麻的数据表格时,那个小小的三角形图标往往成为操作盲区。我曾参与过一个电商后台系统的用…...

从RTL Viewer到仿真波形:用Quartus II给你的Verilog代码做一次‘可视化体检’
从RTL Viewer到仿真波形:用Quartus II给你的Verilog代码做一次‘可视化体检’ 在数字电路设计的浩瀚宇宙中,Verilog代码就像工程师手中的魔法咒语,但如何确认这些咒语真正转化成了预期的电路结构?Quartus II提供的RTL Viewer与仿真…...

Qt新手也能搞定的GPU加速图片渲染:用QOpenGLWidget和QImage实现高性能显示
Qt新手也能搞定的GPU加速图片渲染:用QOpenGLWidget和QImage实现高性能显示 在Qt应用开发中,处理高分辨率图片或序列帧(如医学影像、地图切片)时,传统的QLabel显示方式常会遇到性能瓶颈。当图片尺寸超过1080P或需要快速…...
:金融工程师内部使用的12项校验规则)
Perplexity股票数据清洗SOP(含NASDAQ非标字段映射表):金融工程师内部使用的12项校验规则
更多请点击: https://codechina.net 第一章:Perplexity股票信息检索 Perplexity AI 公司尚未上市,因此不存在公开交易的股票代码、实时行情或交易所挂牌信息。这一事实常被开发者和投资者误读,尤其在使用金融数据 API 时容易触发…...

2026届必备的五大降AI率神器推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术不断深入发展着,学术领域对于原创性以及学术诚信的要求愈发严格起来…...

不只是F5隐写:一次CTF解题,带你深入理解ZIP伪加密的底层原理与手动修复
深入解析ZIP伪加密:从CTF实战到二进制手动修复 在CTF竞赛中,ZIP伪加密一直是Misc类题目的经典考点。不同于常规的加密破解,伪加密巧妙地利用了ZIP文件格式的设计特性,在不实际加密数据的情况下制造出需要密码的假象。本文将带您深…...

解放你的B站缓存视频:3步让m4s文件变身为通用MP4格式
解放你的B站缓存视频:3步让m4s文件变身为通用MP4格式 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了精彩的教…...

避坑指南:STM32F4 HAL库驱动MPU6050,从GitHub标准库移植到DMA模式的完整记录
STM32F4 HAL库下MPU6050 DMA模式移植实战:从标准库到高效姿态采集 移植第三方传感器驱动是嵌入式开发中的高频操作。最近在平衡车项目中,需要将GitHub上一个基于标准库的MPU6050驱动移植到STM32CubeMX生成的HAL库环境,并升级为DMA传输模式。这…...

终极指南:HS2-HF_Patch汉化补丁完全免费使用手册
终极指南:HS2-HF_Patch汉化补丁完全免费使用手册 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而烦恼吗ÿ…...