【解决(几乎)任何机器学习问题】:超参数优化篇(超详细)
best_accuracy = 0
best_parameters = {"a": 0, "b": 0, "c": 0}
for a in range(1, 11):for b in range(1, 11):for c in range(1, 11):model = MODEL(a, b, c)model.fit(training_data)preds = model.predict(validation_data)accuracy = metrics.accuracy_score(targets, preds)if accuracy > best_accuracy:best_accuracy = accuracybest_parameters["a"] = abest_parameters["b"] = bbest_parameters["c"] = cRandomForestClassifier(n_estimators=100,criterion='gini',max_depth=None,min_samples_split=2,min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features='auto',max_leaf_nodes=None,min_impurity_decrease=0.0,min_impurity_split=None,bootstrap=True,oob_score=False,n_jobs=None,random_state=None,verbose=0,warm_start=False,class_weight=None,ccp_alpha=0.0,max_samples=None,) 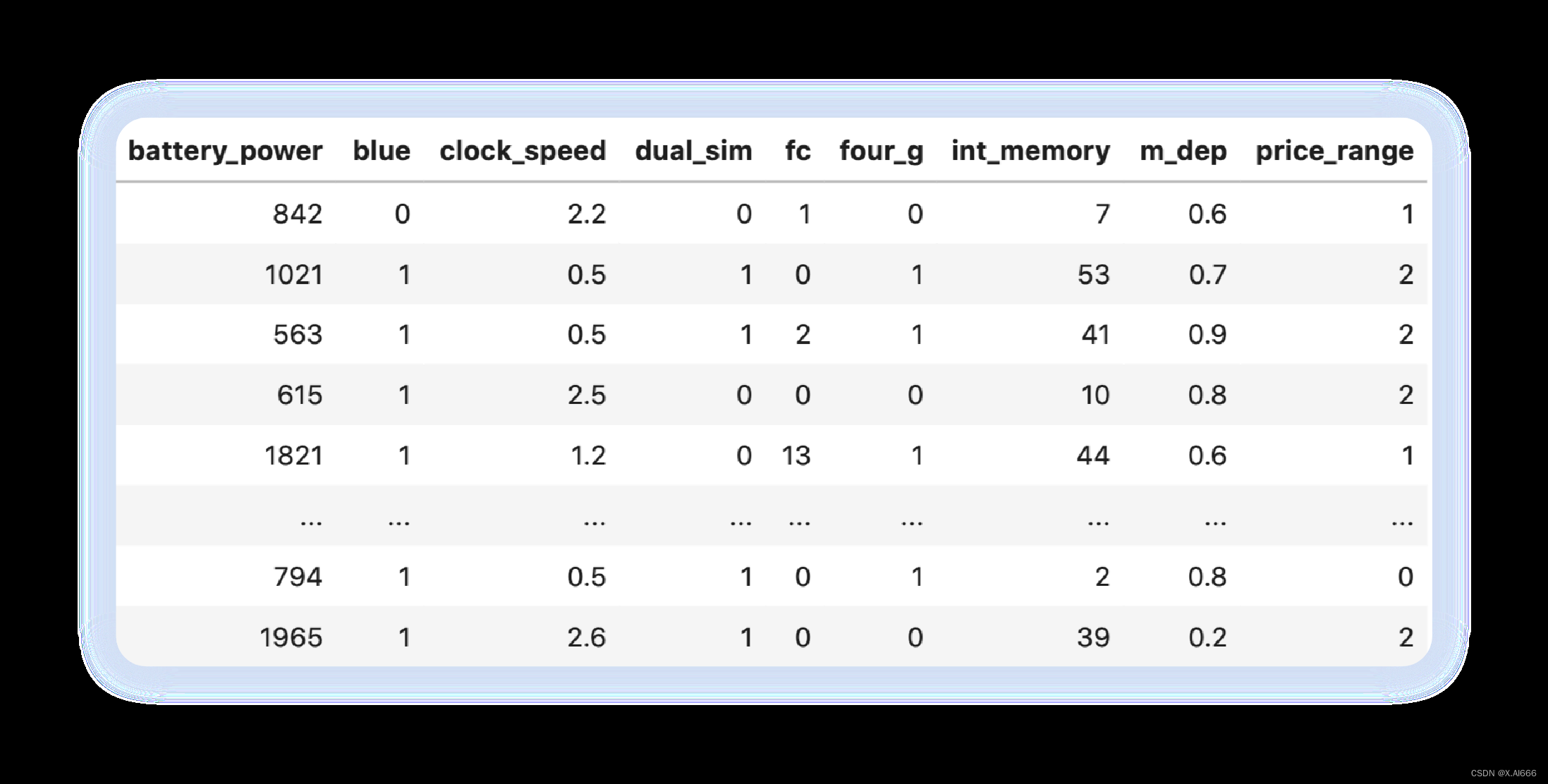
# rf_grid_search.py
import numpy as np
import pandas as pd
from sklearn import ensemble
from sklearn import metrics
from sklearn import model_selectionif __name__ == "__main__":df = pd.read_csv("./input/mobile_train.csv")X = df.drop("price_range", axis=1).valuesy = df.price_range.valuesclassifier = ensemble.RandomForestClassifier(n_jobs=-1)param_grid = {"n_estimators": [100, 200, 250, 300, 400, 500],"max_depth": [1, 2, 5, 7, 11, 15],"criterion": ["gini", "entropy"]}model = model_selection.GridSearchCV(estimator=classifier,param_grid=param_grid,scoring="accuracy",verbose=10,n_jobs=1,cv=5)model.fit(X, y)print(f"Best score: {model.best_score_}")print("Best parameters set:")best_parameters = model.best_estimator_.get_params()for param_name in sorted(param_grid.keys()):print(f"\t{param_name}: {best_parameters[param_name]}")[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 , score = 0.895 ,total = 1.0 s[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 ...............[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 , score = 0.890 ,total = 1.1 s[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 ...............[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 , score = 0.910 ,total = 1.1 s[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 ...............[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 , score = 0.880 ,total = 1.1 s[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 ...............[ CV ] criterion = entropy , max_depth = 15 , n_estimators = 500 , score = 0.870 , total = 1.1 s[ Parallel ( n_jobs = 1 )]: Done 360 out of 360 | elapsed : 3.7 min finishedBest score : 0.889Best parameters set :criterion : 'entropy'max_depth : 15n_estimators : 500
if __name__ == "__main__":classifier = ensemble.RandomForestClassifier(n_jobs=-1)param_grid = {"n_estimators": np.arange(100, 1500, 100),"max_depth": np.arange(1, 31),"criterion": ["gini", "entropy"]}model = model_selection.RandomizedSearchCV(estimator=classifier,param_distributions=param_grid,n_iter=20,scoring="accuracy",verbose=10,n_jobs=1,cv=5)model.fit(X, y)print(f"Best score: {model.best_score_}")print("Best parameters set:")best_parameters = model.best_estimator_.get_params()for param_name in sorted(param_grid.keys()):print(f"\t{param_name}: {best_parameters[param_name]}")我们更改了随机搜索的参数⽹格,结果似乎有了些许改进。
Best score : 0.8905Best parameters set :criterion : entropymax_depth : 25n_estimators : 300
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn import model_selection
from sklearn import pipeline
from sklearn.decomposition import TruncatedSVD
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVCdef quadratic_weighted_kappa(y_true, y_pred):return metrics.cohen_kappa_score(y_true, y_pred, weights="quadratic")if __name__ == '__main__':train = pd.read_csv('./input/train.csv')idx = test.id.values.astype(int)train = train.drop('id', axis=1)test = test.drop('id', axis=1)y = train.relevance.valuestraindata = list(train.apply(lambda x:'%s %s' % (x['text1'], x['text2']), axis=1))testdata = list(test.apply(lambda x:'%s %s' % (x['text1'], x['text2']), axis=1))tfv = TfidfVectorizer(min_df=3,max_features=None,strip_accents='unicode',analyzer='word',token_pattern=r'\w{1,}',ngram_range=(1, 3),use_idf=1,smooth_idf=1,sublinear_tf=1,stop_words='english')tfv.fit(traindata)X = tfv.transform(traindata)X_test = tfv.transform(testdata)svd = TruncatedSVD()scl = StandardScaler()svm_model = SVC()clf = pipeline.Pipeline([('svd', svd),('scl', scl),('svm', svm_model)])param_grid = {'svd__n_components': [200, 300],'svm__C': [10, 12]}kappa_scorer = metrics.make_scorer(quadratic_weighted_kappa,greater_is_better=True)model = model_selection.GridSearchCV(estimator=clf,param_grid=param_grid,scoring=kappa_scorer,verbose=10,n_jobs=-1,refit=True,cv=5)model.fit(X, y)print("Best score: %0.3f" % model.best_score_)print("Best parameters set:")best_parameters = model.best_estimator_.get_params()for param_name in sorted(param_grid.keys()):print("\t%s: %r" % (param_name, best_parameters[param_name]))best_model = model.best_estimator_best_model.fit(X, y)preds = best_model.predict(X_test)# rf_gp_minimize.py
import numpy as np
import pandas as pd
from functools import partial
from sklearn import ensemble
from sklearn import metrics
from sklearn import model_selection
from skopt import gp_minimize
from skopt import spacedef optimize(params, param_names, x, y):params = dict(zip(param_names, params))model = ensemble.RandomForestClassifier(**params)kf = model_selection.StratifiedKFold(n_splits=5)accuracies = []for idx in kf.split(X=x, y=y):train_idx, test_idx = idx[0], idx[1]xtrain = x[train_idx]ytrain = y[train_idx]xtest = x[test_idx]ytest = y[test_idx]model.fit(xtrain, ytrain)preds = model.predict(xtest)fold_accuracy = metrics.accuracy_score(ytest, preds)accuracies.append(fold_accuracy)return -1 * np.mean(accuracies)if __name__ == "__main__":df = pd.read_csv("./input/mobile_train.csv")X = df.drop("price_range", axis=1).valuesy = df.price_range.valuesparam_space = [space.Integer(3, 15, name="max_depth"),space.Integer(100, 1500, name="n_estimators"),space.Categorical(["gini", "entropy"], name="criterion"),space.Real(0.01, 1, prior="uniform", name="max_features")]param_names = ["max_depth","n_estimators","criterion","max_features"]optimization_function = partial(optimize,param_names=param_names,x=X,y=y)result = gp_minimize(optimization_function,dimensions=param_space,n_calls=15,n_random_starts=10,verbose=10)best_params = dict(zip(param_names,result.x))print(best_params)这同样会产⽣⼤量输出,最后⼀部分如下所⽰。
Iteration No : 14 started . Searching for the next optimal point .Iteration No : 14 ended . Search finished for the next optimal point .Time taken : 4.7793Function value obtained : - 0.9075Current minimum : - 0.9075Iteration No : 15 started . Searching for the next optimal point .Iteration No : 15 ended . Search finished for the next optimal point .Time taken : 49.4186Function value obtained : - 0.9075Current minimum : - 0.9075{ 'max_depth' : 12 , 'n_estimators' : 100 , 'criterion' : 'entropy' ,'max_features' : 1.0 }
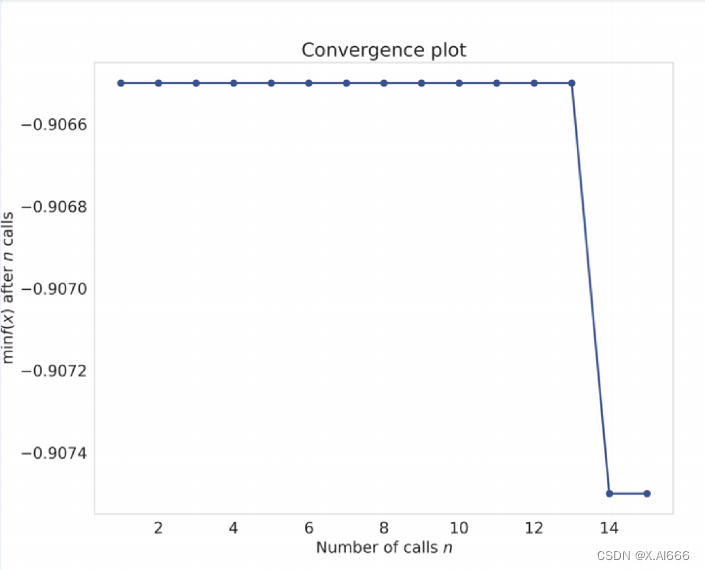
from skopt . plots import plot_convergenceplot_convergence ( result )
收敛图如图 2 所⽰。
import numpy as np
import pandas as pd
from functools import partial
from sklearn import ensemble
from sklearn import metrics
from sklearn import model_selection
from hyperopt import hp, fmin, tpe, Trials
from hyperopt.pyll.base import scopedef optimize(params, x, y):model = ensemble.RandomForestClassifier(**params)kf = model_selection.StratifiedKFold(n_splits=5)accuracies = []for idx in kf.split(X=x, y=y):train_idx, test_idx = idx[0], idx[1]xtrain = x[train_idx]ytrain = y[train_idx]xtest = x[test_idx]ytest = y[test_idx]model.fit(xtrain, ytrain)preds = model.predict(xtest)fold_accuracy = metrics.accuracy_score(ytest, preds)accuracies.append(fold_accuracy)return -1 * np.mean(accuracies)if __name__ == "__main__":df = pd.read_csv("./input/mobile_train.csv")X = df.drop("price_range", axis=1).valuesy = df.price_range.valuesparam_space = {"max_depth": scope.int(hp.quniform("max_depth", 1, 15, 1)),"n_estimators": scope.int(hp.quniform("n_estimators", 100, 1500, 1)),"criterion": hp.choice("criterion", ["gini", "entropy"]),"max_features": hp.uniform("max_features", 0, 1)}optimization_function = partial(optimize,x=X,y=y)trials = Trials()hopt = fmin(fn=optimization_function,space=param_space,algo=tpe.suggest,max_evals=15,trials=trials)print(hopt)❯ python rf_hyperopt . py100 %| ██████████████████ | 15 / 15 [ 0 4 : 38 < 0 0 : 0 0 , 18.57 s / trial , best loss : -0.9095000000000001 ]{ 'criterion' : 1 , 'max_depth' : 11.0 , 'max_features' : 0.821163568049807 ,'n_estimators' : 806.0 }
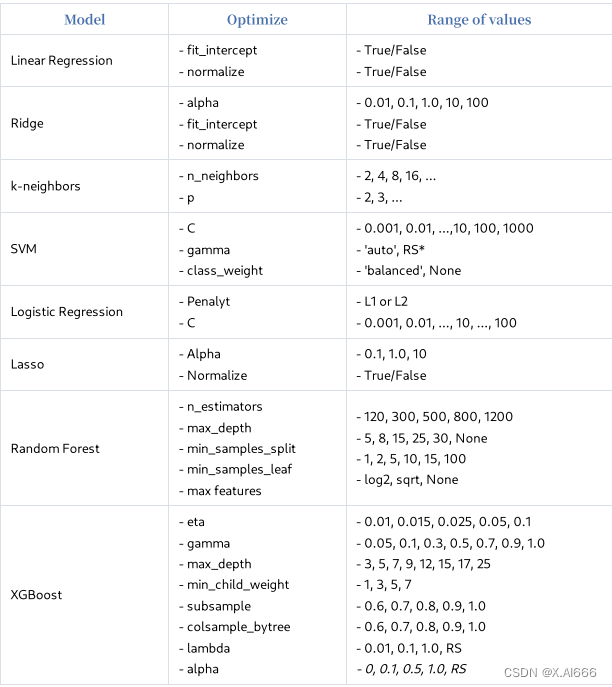
相关文章:
【解决(几乎)任何机器学习问题】:超参数优化篇(超详细)
这篇文章相当长,您可以添加至收藏夹,以便在后续有空时候悠闲地阅读。 有了优秀的模型,就有了优化超参数以获得最佳得分模型的难题。那么,什么是超参数优化呢?假设您的机器学习项⽬有⼀个简单的流程。有⼀个数据集&…...

面试计算机网络框架八股文十问十答第七期
面试计算机网络框架八股文十问十答第七期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)UDP协议为什么不可…...

Codeforces Round 926 (Div. 2)
A. Sasha and the Beautiful Array(模拟) 思路 最大值减去最小值 #include<iostream> #include<algorithm> using namespace std; const int N 110; int a[N];int main(){int t, n;cin>>t;while(t--){cin>>n;for(int i 0; i…...
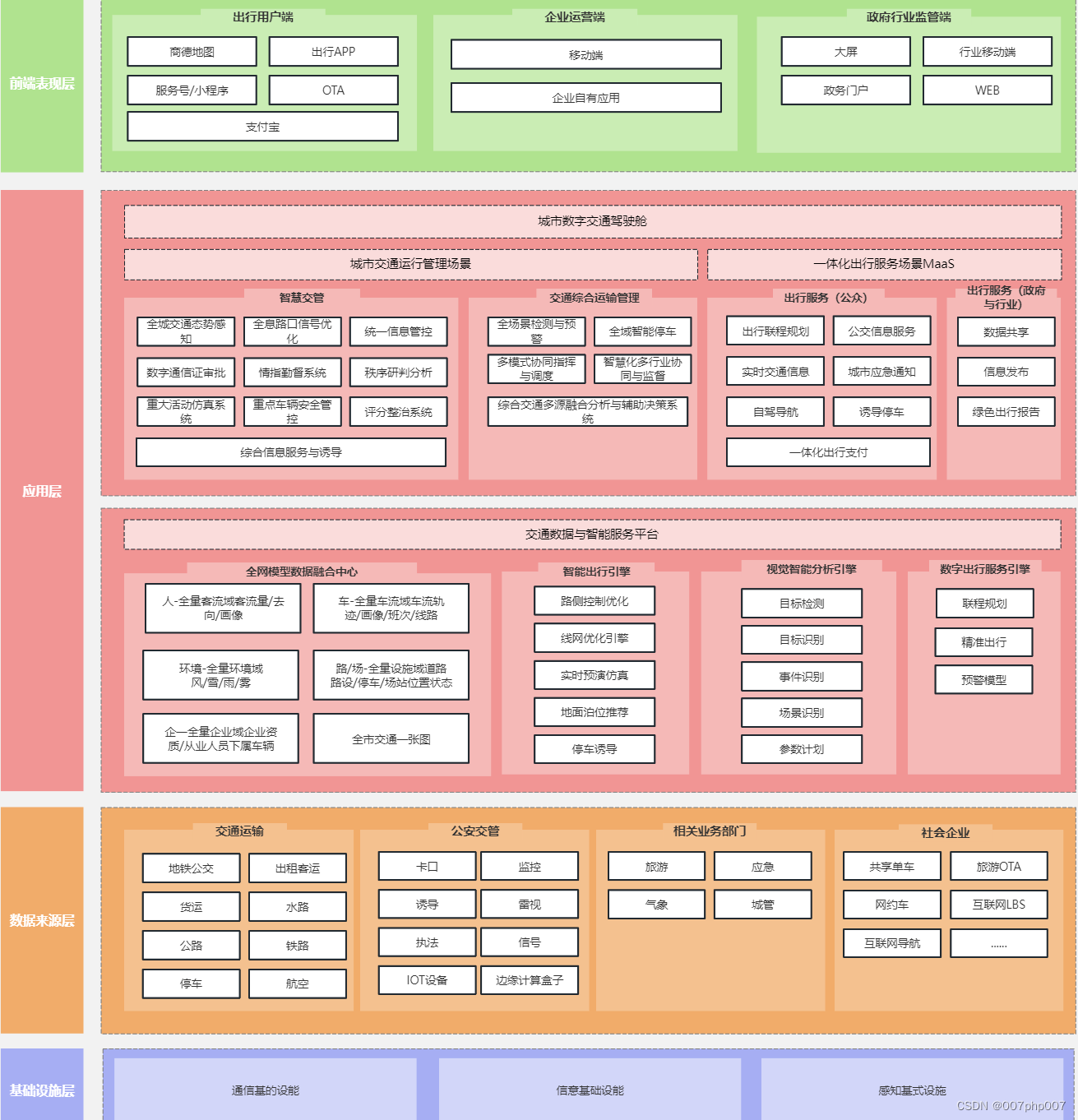
构建智慧交通平台:架构设计与实现
随着城市交通的不断发展和智能化技术的迅速进步,智慧交通平台作为提升城市交通管理效率和水平的重要手段备受关注。本文将探讨如何设计和实现智慧交通平台的系统架构,以应对日益增长的城市交通需求,并提高交通管理的智能化水平。 ### 1. 智慧…...
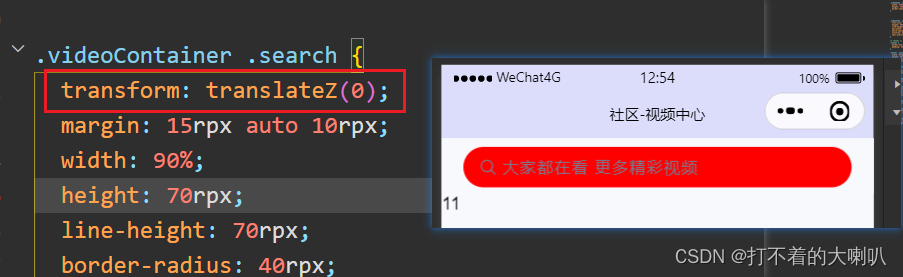
移动端设置position: fixed;固定定位,底部出现一条缝隙,不知原因,欢迎探讨!!!
1、问题 在父盒子中有一个子盒子,父盒子加了固定定位,需要子盒子上下都有要边距,用margin或者padding挤开时,会出现缝隙是子盒子背景颜色的。 测试过了,有些手机型号有,有些没有,微信小程序同移…...
有关网络安全的课程学习网页
1.思科网络学院 免费学习skillsforall的课程 课程链接:Introduction to Cybersecurity by Cisco: Free Online Course (skillsforall.com) 2.斯坦福大学计算机和网络安全基础 该证书对于初学者来说最有价值,它由最著名的大学之一斯坦福大学提供。您可…...

计算机网络-面试题
一、基础 1、网络编程 网络编程的本质是多台计算机之间的数据交换存在问题 如何准确的定位网络上一台或多台主机如何进行可靠传输2、网络协议 在计算机网络有序的交换数据,就必须遵守一些事先约定好的规则,比如交换数据的格式、是否需要发送一个应答信息。这些规则被称为网络…...

C++虚函数
C虚函数 在C中,虚函数(Virtual Function)是一个使用关键字virtual声明的成员函数,它在基类中被声明,以便在任何派生类中被重写(Override)。使用虚函数的目的是实现多态性——一种允许使用基类指…...
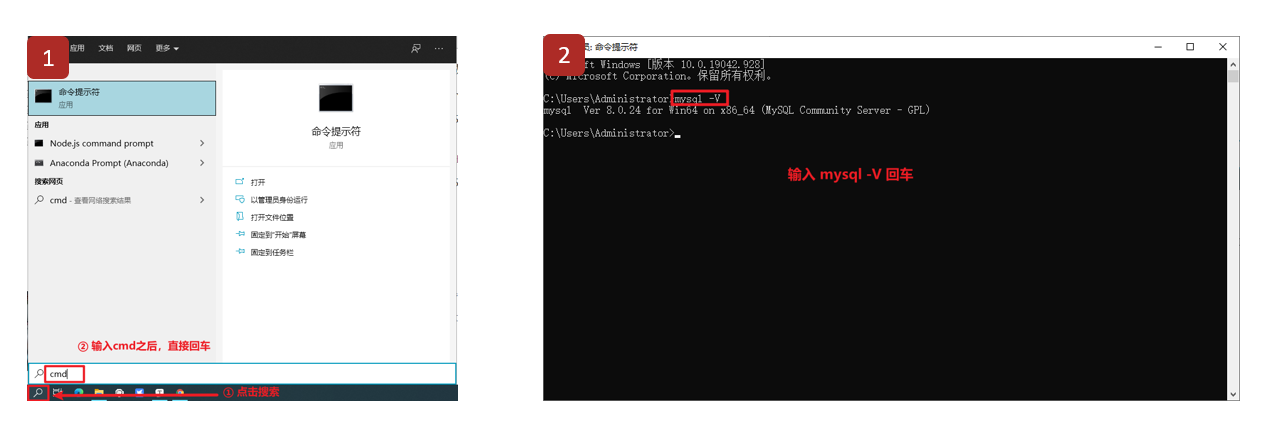
MySQL数据库基础(二):MySQL数据库介绍
文章目录 MySQL数据库介绍 一、MySQL介绍 二、MySQL的特点 三、MySQL版本 四、MySQL数据库下载与安装 1、下载 2、安装 五、添加环境变量(Windows) 六、检测环境变量是否配置成功 MySQL数据库介绍 一、MySQL介绍 MySQL是一个关系型数据库管理…...

常用文件命令
文章目录 文件命令文件内容查看catnlmoreless(more的plus版)headtailod 文件属性操作用户权限常见的权限chownchmodchgrpumask 隐藏属性常见的隐藏属性lsattrchattr 查找文件查看文件类型查找文件位置whichwhereislocatefind 文件操作(复制、…...

在屏蔽任何FRP环境下从零开始搭建安全的FRP内网穿透服务
背景 本人目前在境外某大学读博,校园网屏蔽了所有内网穿透的工具的数据包和IP访问,为了实现在家也能远程访问服务器,就不得不先开个学校VPN,再登陆。我们实验室还需要访问另一个大学的服务器,每次我都要去找另一个大学…...

OpenGL-ES 学习(1)---- AlphaBlend
AlphaBlend OpenGL-ES 混合本质上是将 2 个片元的颜色进行调和(一般是求和操作),产生一个新的颜色 OpenGL ES 混合发生在片元通过各项测试之后,准备进入帧缓冲区的片元和原有的片元按照特定比例加权计算出最终片元的颜色值,不再是新…...

Python 函数的学习笔记
Python 函数的学习笔记 0. Python 函数的概要说明1. 自定义函数示例2. 匿名函数示例3. 内置函数示例3-1. filter() 示例3-2. map() 示例3-3. reduce() 示例 4. 可变长参数*args和**kwargs示例4-1. *args(Positional Variadic Arguments)4-2. **kwargs&am…...

详解 Redis 实现数据去重
✨✨ 欢迎大家来到喔的嘛呀的博客✨✨ 🎈🎈希望这篇博客对大家能有帮助🎈🎈 目录 言 一. Redis去重原理 1. Redis Set 数据结构 2. 基于 Set 实现数据去重 3. 代码示例 4. 总结 …...
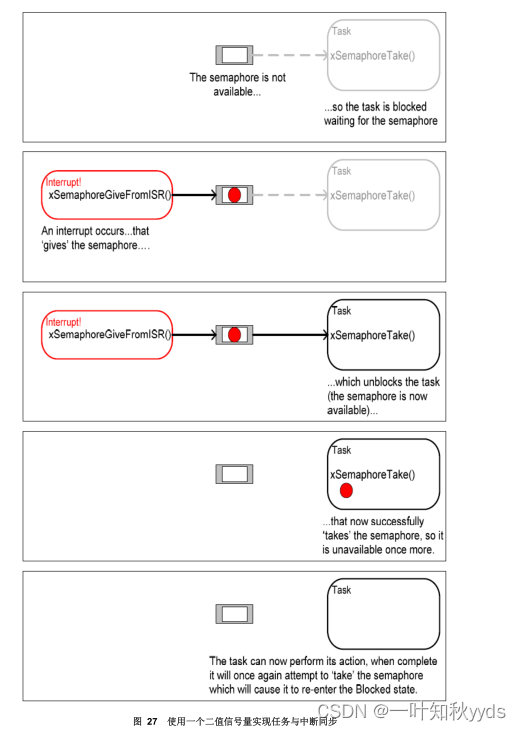
FreeRTOS 延迟中断处理
采用二值信号量同步 二值信号量可以在某个特殊的中断发生时,让任务解除阻塞,相当于让任务与中断 同步。这样就可以让中断事件处理量大的工作在同步任务中完成,中断服务例程(ISR) 中只是快速处理少部份工作。如此,中断处理可以说是…...

计网体系结构
计算机网络的概述 概念 网络:网状类的东西或系统。 计算机网络:是一个将分散的、具有独立性功能的计算机系统,通过通信设备与线路连接起来,由功能完善的软件实现资源共享和信息传递的系统。即计算机网络是互连(通过通信链路互连…...
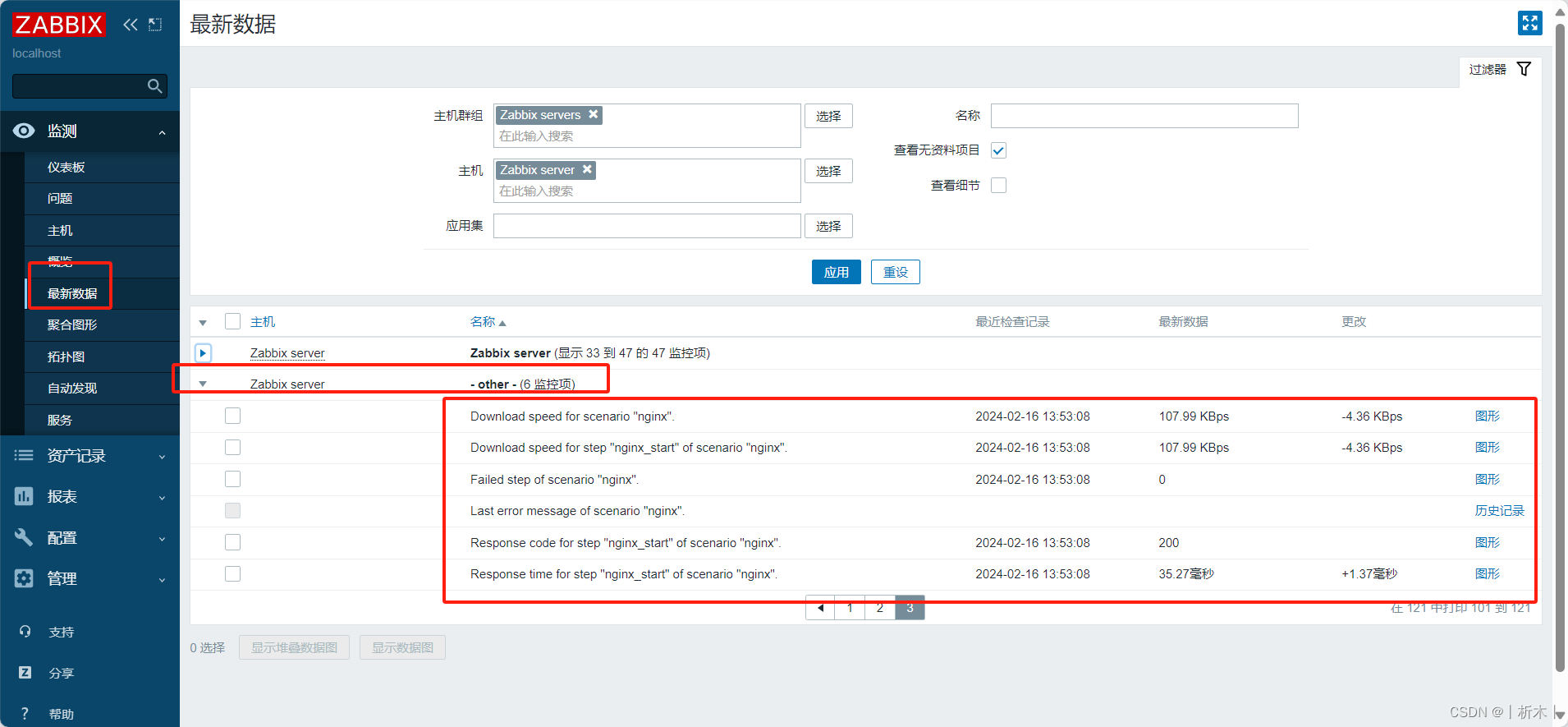
linux系统zabbix工具监控web页面
web页面监控 内建key介绍浏览器配置浏览器页面查看方式 监控指定的站点的资源下载速度,及页面响应时间,还有响应代码; web Scenario: web场景(站点)web page :web页面,一个场景有多…...
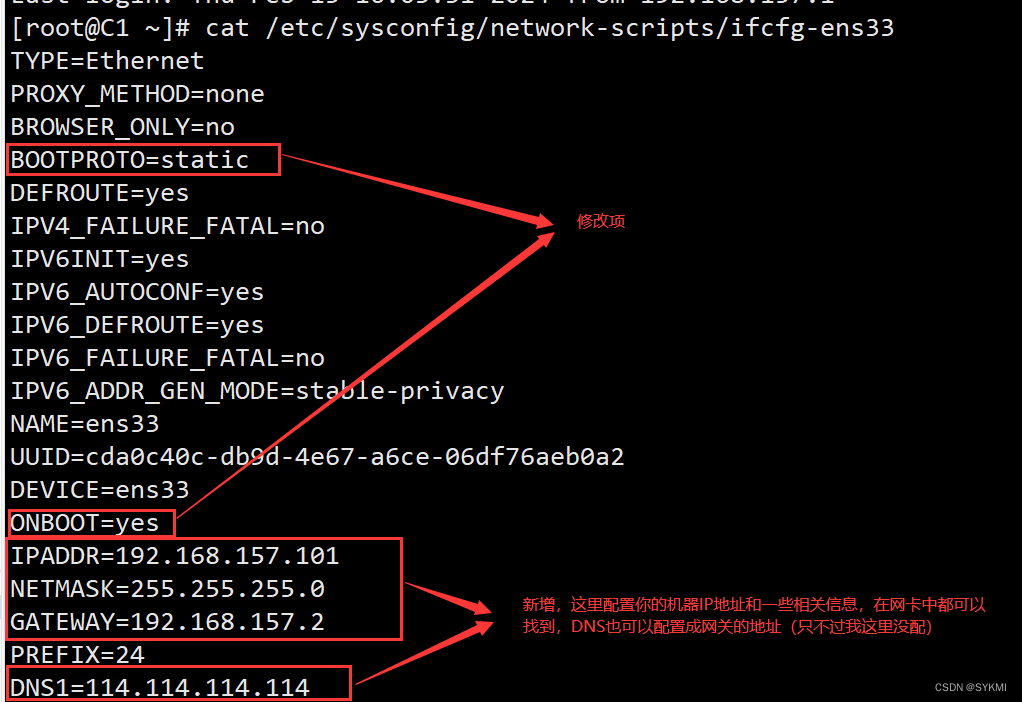
VMware虚拟机网络配置
VMware虚拟机网络配置 桥接模式NAT网络 桥接模式 桥接模式其实就是借助你宿主机上的网卡进行联网和通信,所以相当于虚拟机和宿主机平级,处于同一个网段中。 配置要点: 注意选择正确的宿主机网卡 查看宿主机的网络信息,这些信息指…...
代码随想录算法训练营DAY18 | 二叉树 (5)
一、LeetCode 513 找树左下角的值 题目链接:513.找树左下角的值https://leetcode.cn/problems/find-bottom-left-tree-value/ 思路一:递归回溯全局变量比深度。 class Solution {int Max_depth 0;int result 0;public int findBottomLeftValue(TreeNo…...

企业微信自动推送机器人的应用与价值
随着科技的快速发展,企业微信自动推送机器人已经成为了企业数字化转型的重要工具。这种机器人可以自动推送消息、执行任务、提供服务,为企业带来了许多便利。本文将探讨企业微信自动推送机器人的应用和价值。 一、企业微信自动推送机器人的应用 企业微信…...

吕欣团队《大数据平台架构》第四章读书笔记:HDFS——把一块硬盘“拆”成一整个数据中心
最近在系统地补 Hadoop 的基础设施部分,第四章讲的是 HDFS(Hadoop Distributed File System)。这一章看下来最大的感受是:HDFS 本质上不是一个“文件系统增强版”,而是一种完全围绕“大规模数据处理”重新设计的存储哲…...

NotebookLM概念关联分析全链路解析,从原始文本到可验证知识网络的6大断点与修复方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM概念关联分析全链路解析概览 NotebookLM 是 Google 推出的基于 LLM 的实验性研究辅助工具,其核心能力在于对用户上传的文档(PDF、TXT、网页等)进行语义理…...

Docker化部署KingbaseES V9:从镜像导入到开发版License激活实战
1. 为什么选择Docker部署KingbaseES V9? 在开发测试环境中,传统数据库安装方式往往需要耗费大量时间在环境配置和依赖解决上。我去年参与的一个政务云项目就遇到过这种情况:团队花了三天时间在不同操作系统的测试机上反复折腾依赖库ÿ…...

Molflow仿真结果怎么看?Texture、Profile、Counter Facet全解析,选对方法效率翻倍
Molflow仿真结果解读实战指南:Texture、Profile、Counter Facet深度解析 面对真空系统仿真结果,许多工程师常陷入"数据海洋"的困惑——明明跑完了模拟,却不知如何高效提取关键信息。Molflow作为专业级真空仿真工具,提供…...

Xarray数据处理的隐藏神器:rioxarray实战,用SHP文件精准裁剪NetCDF气象数据
Xarray数据处理的隐藏神器:rioxarray实战,用SHP文件精准裁剪NetCDF气象数据 在气象、海洋和遥感领域,NetCDF格式的网格数据几乎是科研和业务工作中的标配。当我们面对全球或大区域的高分辨率数据集时,往往只需要提取其中某个特定区…...

深入QGIS矢量数据底层:手写WKT字符串添加几何图形,一次搞懂空间数据存储原理
深入QGIS矢量数据底层:手写WKT字符串添加几何图形,一次搞懂空间数据存储原理 当你第一次在QGIS中看到一个点、一条线或一个多边形时,是否好奇过这些图形在计算机中究竟是如何被存储和表达的?本文将带你从最基础的WKT字符串开始&am…...

35岁程序员亲历:AI时代如何避免踩坑?收藏这份避坑指南,小白也能看懂大模型!
作者作为一名有十多年经验的程序员,分享了自己在AI快速发展背景下,利用GPT Pro和Deep Research进行产品调研的经历。文章指出,仅依靠AI工具并不足以成功,更重要的是要找到真实的市场痛点和需求。作者通过实际案例分析了纯工具类、…...

不只是CT重建:手把手教你用RTK+ITK+VS2022搭建可扩展的医学影像处理开发环境
构建医学影像算法开发平台:RTKITKVS2022全流程实战指南 医学影像处理领域正迎来前所未有的技术革新,从传统的CT重建到三维可视化、病灶自动检测等高级应用,开发者需要一套稳定且可扩展的开发环境。本文将带您从零开始,在Windows平…...

暗物质暗能量本质,分享给各位玩家
通过百度网盘分享的文件:A First-…等3个文件链接:https://pan.baidu.com/s/1FVDfTxTDAslqLtN17ulQ1w?pwd516r 复制这段内容打开「百度网盘APP 即可获取」...

光模块PCB设计学习记录01
/*光模块布局,有错误可以指出,有不足可以补充*/ 光模块PCB布局规划 01导入板框与结构约束导入 这里的outline板框一般由机械提供.dxf文件,板框决定PCB尺寸、器件可用区域和接口位置;成功导入dxf文件后,打开Board Geo…...