变分自编码器(VAE)PyTorch Lightning 实现

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- VAE 简介
- 基本原理
- 应用与优点
- 缺点与挑战
- 使用 VAE 生成 MNIST 手写数字
- 忽略警告
- 导入必要的库
- 设置随机种子
- cuDNN 设置
- 超参数设置
- 数据加载
- 定义 VAE 模型
- 定义损失函数
- 定义 Lightning 模型
- 训练模型
- 绘制训练过程
- 随机生成新样本
- 根据潜变量插值生成新样本
VAE 简介
变分自编码器(Variational Autoencoder,VAE)是一种深度学习中的生成模型,它结合了自编码器(Autoencoder, AE)和概率建模的思想,在无监督学习环境中表现出了强大的能力。VAE 在 2013 年由 Diederik P. Kingma 和 Max Welling 首次提出,并迅速成为生成模型领域的重要组成部分。
基本原理
自编码器(AE)基础:
自编码器是一种神经网络结构,通常由两部分组成:编码器(Encoder)和解码器(Decoder)。原始数据通过编码器映射到一个低维的潜在空间(或称为隐空间),这个低维向量被称为潜变量(latent variable)。然后,潜变量再通过解码器重构回原始数据的近似版本。在训练过程中,自编码器的目标是使得输入数据经过编码-解码过程后能够尽可能地恢复原貌,从而学习到数据的有效表示。
VAE的引入与扩展:
VAE 将自编码器的概念推广到了概率框架下。在 VAE 中,潜变量不再是确定性的,而是被赋予了概率分布。具体来说,对于给定的输入数据,编码器不直接输出一个点估计值,而是输出潜变量的均值和方差(假设潜变量服从高斯分布)。这样,每个输入数据可以被视为是从某个潜在的概率分布中采样得到的。
变分推断(Variational Inference):
训练 VA E时,由于真实的后验概率分布难以直接计算,因此采用变分推断来近似后验分布。编码器实际上输出的是一个参数化的概率分布 q ( z ∣ x ) q(z|x) q(z∣x),即给定输入 x x x 时潜变量 z z z 的概率分布。然后通过最小化 KL 散度(Kullback-Leibler divergence)来优化这个近似分布,使其尽可能接近真实的后验分布 p ( z ∣ x ) p(z|x) p(z∣x)。
目标函数 - Evidence Lower Bound (ELBO):
VAE 的目标函数是证据下界(ELBO),它是原始数据 log-likelihood 的下界。优化该目标函数既鼓励编码器找到数据的高效潜在表示,又促使解码器基于这些表示重建出类似原始数据的新样本。
数学表达上,ELBO 通常分解为两个部分:
- 重构损失(Reconstruction Loss):衡量从潜变量重构出来的数据与原始数据之间的差异。
- KL散度损失(KL Divergence Loss):衡量编码器产生的潜变量分布与预设的标准正态分布(或其他先验分布)之间的距离。
应用与优点
- VAE 可以用于生成新数据,例如图像、文本、音频等。
- 由于其对潜变量进行概率建模,所以它可以提供连续的数据生成,并且能够探索数据的不同模式。
- 在处理连续和离散数据时具有一定的灵活性。
- 可以用于特征学习,提取数据的有效低维表示。
缺点与挑战
- 训练 VAE 可能需要大量的计算资源和时间。
- 生成的样本有时可能不够清晰或细节模糊,尤其是在复杂数据集上。
- 对于某些复杂的分布形式,VAE 可能无法完美捕获所有细节。
使用 VAE 生成 MNIST 手写数字
下面我们将使用 PyTorch Lightning 来实现一个简单的 VAE 模型,并使用 MNIST 数据集来进行训练和生成。
在线 Notebook:https://www.kaggle.com/code/marquis03/vae-mnist
忽略警告
import warnings
warnings.filterwarnings("ignore")
导入必要的库
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snssns.set_theme(style="darkgrid", font_scale=1.5, font="SimHei", rc={"axes.unicode_minus":False})import torch
import torchmetrics
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import transforms, datasetsimport lightning.pytorch as pl
from lightning.pytorch.loggers import CSVLogger
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
设置随机种子
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
cuDNN 设置
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = True
超参数设置
batch_size = 64epochs = 10
KLD_weight = 1
lr = 0.001input_dim = 784 # 28 * 28
h_dim = 256 # 隐藏层维度
z_dim = 2 # 潜变量维度
数据加载
train_dataset = datasets.MNIST(root="data", train=True, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
定义 VAE 模型
class VAE(nn.Module):def __init__(self, input_dim=784, h_dim=400, z_dim=20):super(VAE, self).__init__()self.input_dim = input_dimself.h_dim = h_dimself.z_dim = z_dim# Encoderself.fc1 = nn.Linear(input_dim, h_dim)self.fc21 = nn.Linear(h_dim, z_dim) # muself.fc22 = nn.Linear(h_dim, z_dim) # log_var# Decoderself.fc3 = nn.Linear(z_dim, h_dim)self.fc4 = nn.Linear(h_dim, input_dim)def encode(self, x):h = torch.relu(self.fc1(x))mean = self.fc21(h)log_var = self.fc22(h)return mean, log_vardef reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):h = torch.relu(self.fc3(z))out = torch.sigmoid(self.fc4(h))return outdef forward(self, x):mean, log_var = self.encode(x)z = self.reparameterize(mean, log_var)reconstructed_x = self.decode(z)return reconstructed_x, mean, log_varvae = VAE(input_dim, h_dim, z_dim)
x = torch.randn((10, input_dim))
reconstructed_x, mean, log_var = vae(x)
print(reconstructed_x.shape, mean.shape, log_var.shape)
# torch.Size([10, 784]) torch.Size([10, 2]) torch.Size([10, 2])
定义损失函数
def loss_function(x_hat, x, mu, log_var, KLD_weight=1):BCE_loss = F.binary_cross_entropy(x_hat, x, reduction="sum") # 重构损失KLD_loss = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # KL 散度损失loss = BCE_loss + KLD_loss * KLD_weightreturn loss, BCE_loss, KLD_loss
定义 Lightning 模型
class LitModel(pl.LightningModule):def __init__(self, input_dim=784, h_dim=400, z_dim=20):super().__init__()self.model = VAE(input_dim, h_dim, z_dim)def forward(self, x):x = self.model(x)return xdef configure_optimizers(self):optimizer = optim.Adam(self.parameters(), lr=lr, betas=(0.9, 0.99), eps=1e-08, weight_decay=1e-5)return optimizerdef training_step(self, batch, batch_idx):x, y = batchx = x.view(x.size(0), -1)reconstructed_x, mean, log_var = self(x)loss, BCE_loss, KLD_loss = loss_function(reconstructed_x, x, mean, log_var, KLD_weight=KLD_weight)self.log("loss", loss, on_step=False, on_epoch=True, prog_bar=True, logger=True)self.log_dict({"BCE_loss": BCE_loss,"KLD_loss": KLD_loss,},on_step=False,on_epoch=True,logger=True,)return lossdef decode(self, z):out = self.model.decode(z)return out
训练模型
model = LitModel(input_dim, h_dim, z_dim)
logger = CSVLogger("./")
early_stop_callback = EarlyStopping(monitor="loss", min_delta=0.00, patience=5, verbose=False, mode="min")
trainer = pl.Trainer(max_epochs=epochs,enable_progress_bar=True,logger=logger,callbacks=[early_stop_callback],
)
trainer.fit(model, train_loader)
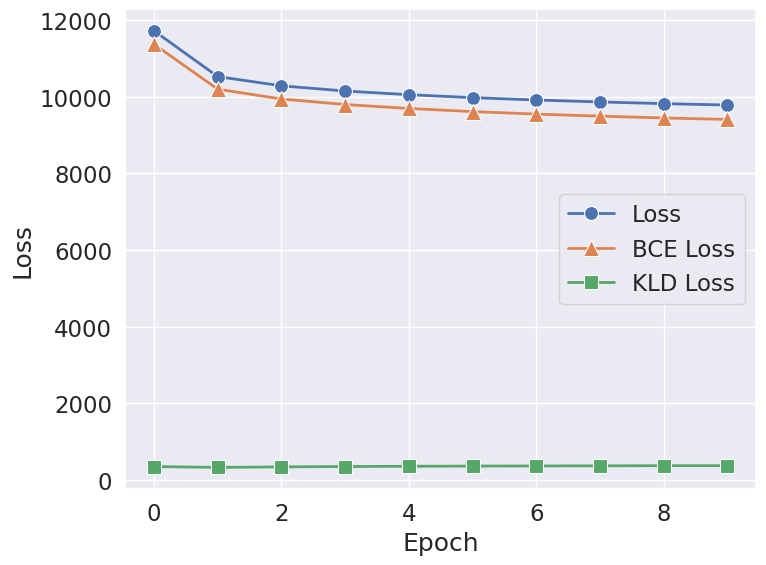
绘制训练过程
log_path = logger.log_dir + "/metrics.csv"
metrics = pd.read_csv(log_path)
x_name = "epoch"plt.figure(figsize=(8, 6), dpi=100)
sns.lineplot(x=x_name, y="loss", data=metrics, label="Loss", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="BCE_loss", data=metrics, label="BCE Loss", linewidth=2, marker="^", markersize=12)
sns.lineplot(x=x_name, y="KLD_loss", data=metrics, label="KLD Loss", linewidth=2, marker="s", markersize=10)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.tight_layout()
plt.show()
随机生成新样本
row, col = 4, 18
z = torch.randn(row * col, z_dim)
random_res = model.model.decode(z).view(-1, 1, 28, 28).detach().numpy()plt.figure(figsize=(col, row))
for i in range(row * col):plt.subplot(row, col, i + 1)plt.imshow(random_res[i].squeeze(), cmap="gray")plt.xticks([])plt.yticks([])plt.axis("off")
plt.show()

根据潜变量插值生成新样本
from scipy.stats import normn = 15
digit_size = 28grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))figure = np.zeros((digit_size * n, digit_size * n))
for i, yi in enumerate(grid_y):for j, xi in enumerate(grid_x):t = [xi, yi]z_sampled = torch.FloatTensor(t)with torch.no_grad():decode = model.decode(z_sampled)digit = decode.view((digit_size, digit_size))figure[i * digit_size : (i + 1) * digit_size,j * digit_size : (j + 1) * digit_size,] = digitplt.figure(figsize=(10, 10))
plt.imshow(figure, cmap="gray")
plt.xticks([])
plt.yticks([])
plt.axis("off")
plt.show()

相关文章:
变分自编码器(VAE)PyTorch Lightning 实现
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

设备驱动开发_1
可加载模块如何工作的 主要内容 描述可加载模块优势使用模块命令效率使用和定义模块密钥和模块工作1 描述可加载模块优势 开发周期优势: 静态模块在/boot下的vmlinuz中,需要配置、编译、重启。 开发周期长。 LKM 不需要重启。 开发周期优于静态模块。 2 使用模块命令效率…...
知识点精要解析)
C语言位域(Bit Fields)知识点精要解析
在C语言中,位域(Bit Field)是一种独特的数据结构特性,它允许程序员在结构体(struct)中定义成员变量,并精确指定其占用的位数。通过使用位域,我们可以更高效地利用存储空间࿰…...

离散数学——图论(笔记及思维导图)
离散数学——图论(笔记及思维导图) 目录 大纲 内容 参考 大纲 内容 参考 笔记来自【电子科大】离散数学 王丽杰...
opencv图像像素的读写操作
void QuickDemo::pixel_visit_demo(Mat & image) {int w image.cols;//宽度int h image.rows;//高度int dims image.channels();//通道数 图像为灰度dims等于一 图像为彩色时dims等于三 for (int row 0; row < h; row) {for (int col 0; col < w; col) {if…...

Java学习第十四节之冒泡排序
冒泡排序 package array;import java.util.Arrays;//冒泡排序 //1.比较数组中,两个相邻的元素,如果第一个数比第二个数大,我们就交换他们的位置 //2.每一次比较,都会产生出一个最大,或者最小的数字 //3.下一轮则可以少…...

第1章 计算机网络体系结构-1.1计算机网络概述
1.1.1计算机网络概念 计算机网络是将一个分散的,具有独立功能的计算机系统通过通信设备与路线连接起来,由功能完善的软件实现资源共享和信息传递的系统。(计算机网络就是一些互连的,自治的计算机系统的集合) 1.1.2计算机网络的组成 从不同角…...

蓝桥杯:C++排序
排序 排序和排列是算法题目常见的基本算法。几乎每次蓝桥杯软件类大赛都有题目会用到排序或排列。常见的排序算法如下。 第(3)种排序算法不是基于比较的,而是对数值按位划分,按照以空间换取时间的思路来排序。看起来它们的复杂度更好,但实际…...
数据结构-堆
1.容器 容器用于容纳元素集合,并对元素集合进行管理和维护. 传统意义上的管理和维护就是:增,删,改,查. 我们分析每种类型容器时,主要分析其增,删,改ÿ…...

奔跑吧小恐龙(Java)
前言 Google浏览器内含了一个小彩蛋当没有网络连接时,浏览器会弹出一个小恐龙,当我们点击它时游戏就会开始进行,大家也可以玩一下试试,网址:恐龙快跑 - 霸王龙游戏. (ur1.fun) 今天我们也可以用Java来简单的实现一下这…...

Ubuntu 1804 And Above Coredump Settings
查看 coredump 是否开启 # 查询, 0 未开启, unlimited 开启 xiaoUbuntu:/var/core$ ulimit -c 0# 开启 xiaoUbuntu:/var/core$ ulimit -c unlimited查看 coredump 保存路径 默认情况下,Ubuntu 使用 apport 服务处理 coredump 文件ÿ…...

docker 2:安装
docker 2:安装 ubuntu 安装 docker sudo apt install docker.io 把当前用户放进 docker 用户组,避免每次运行 docker 命都要使用 sudo 或者 root 权限。 sudo usermod -aG docker $USERid $USER 看到用户已加入 docker 组 …...
LeetCode Python - 19.删除链表的倒数第N个结点
目录 题目答案运行结果 题目 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n 1 输出&a…...
Spring Boot 笔记 005 环境搭建
1.1 创建数据库和表(略) 2.1 创建Maven工程 2.2 补齐resource文件夹和application.yml文件 2.3 porn.xml中引入web,mybatis,mysql等依赖 2.3.1 引入springboot parent 2.3.2 删除junit 依赖--不能删,删了会报错 2.3.3 引入spring web依赖…...
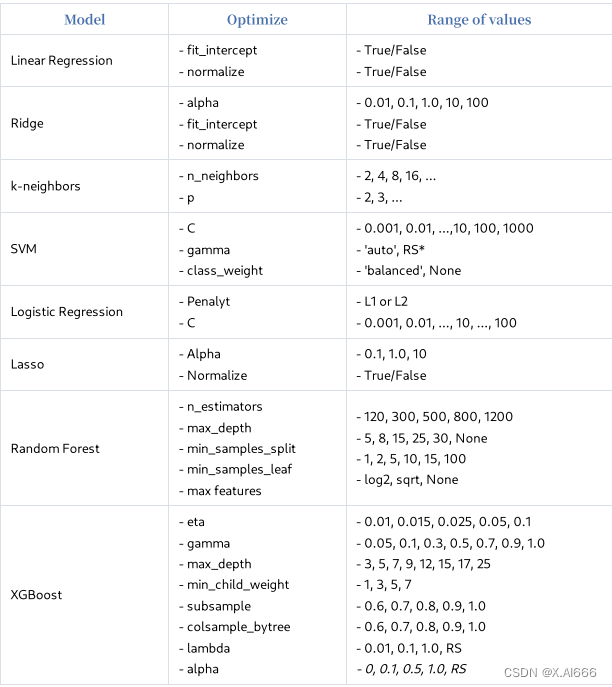
【解决(几乎)任何机器学习问题】:超参数优化篇(超详细)
这篇文章相当长,您可以添加至收藏夹,以便在后续有空时候悠闲地阅读。 有了优秀的模型,就有了优化超参数以获得最佳得分模型的难题。那么,什么是超参数优化呢?假设您的机器学习项⽬有⼀个简单的流程。有⼀个数据集&…...

面试计算机网络框架八股文十问十答第七期
面试计算机网络框架八股文十问十答第七期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)UDP协议为什么不可…...

Codeforces Round 926 (Div. 2)
A. Sasha and the Beautiful Array(模拟) 思路 最大值减去最小值 #include<iostream> #include<algorithm> using namespace std; const int N 110; int a[N];int main(){int t, n;cin>>t;while(t--){cin>>n;for(int i 0; i…...
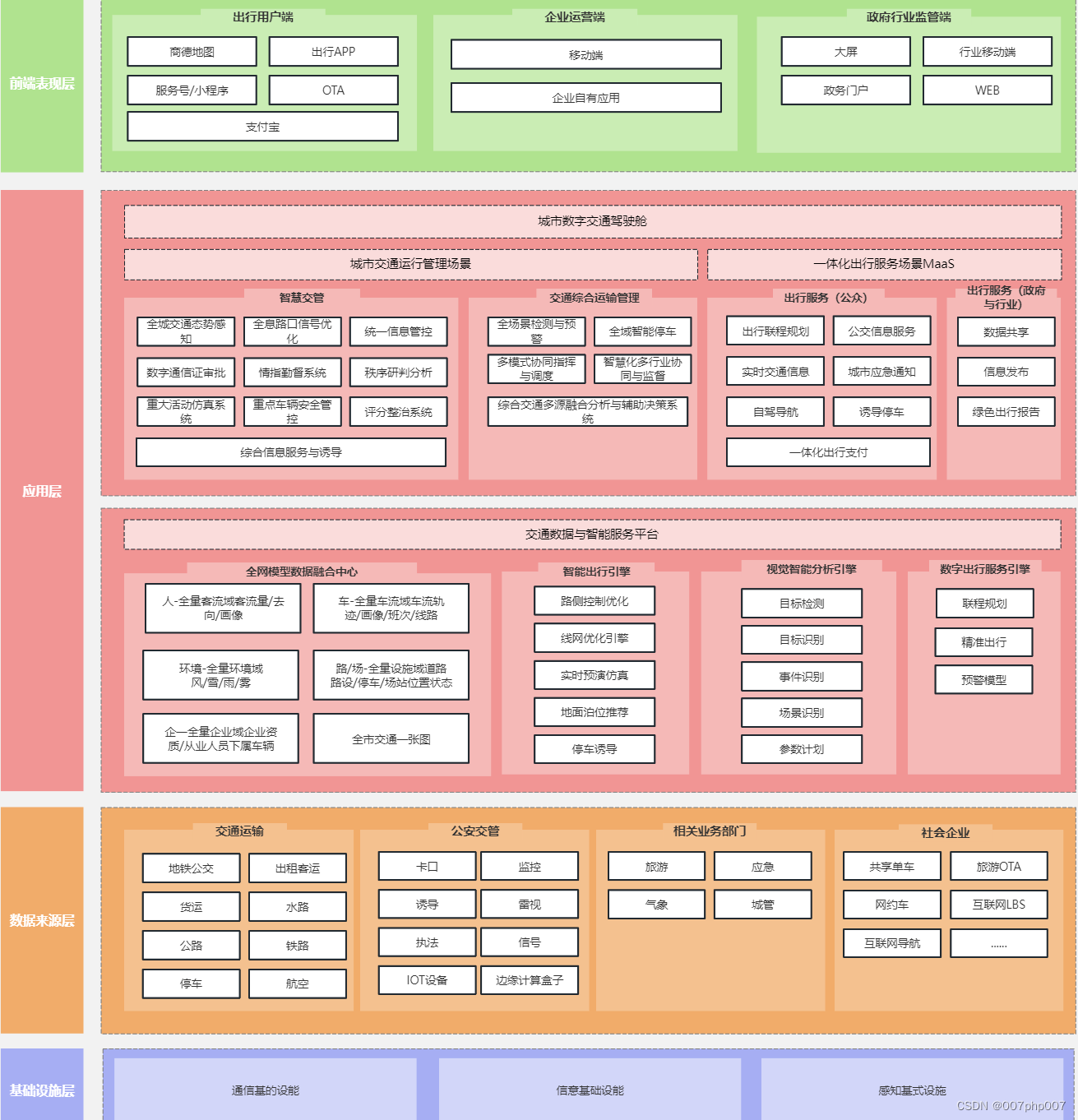
构建智慧交通平台:架构设计与实现
随着城市交通的不断发展和智能化技术的迅速进步,智慧交通平台作为提升城市交通管理效率和水平的重要手段备受关注。本文将探讨如何设计和实现智慧交通平台的系统架构,以应对日益增长的城市交通需求,并提高交通管理的智能化水平。 ### 1. 智慧…...
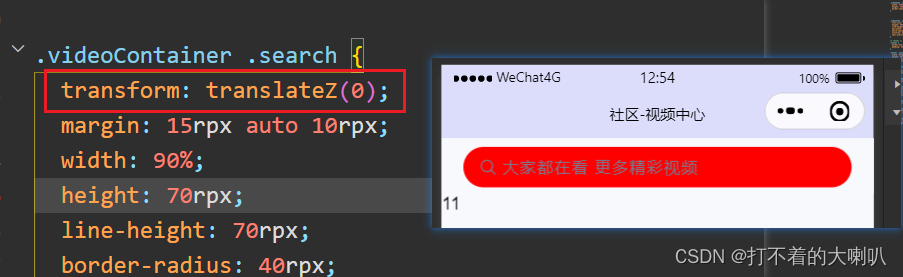
移动端设置position: fixed;固定定位,底部出现一条缝隙,不知原因,欢迎探讨!!!
1、问题 在父盒子中有一个子盒子,父盒子加了固定定位,需要子盒子上下都有要边距,用margin或者padding挤开时,会出现缝隙是子盒子背景颜色的。 测试过了,有些手机型号有,有些没有,微信小程序同移…...
有关网络安全的课程学习网页
1.思科网络学院 免费学习skillsforall的课程 课程链接:Introduction to Cybersecurity by Cisco: Free Online Course (skillsforall.com) 2.斯坦福大学计算机和网络安全基础 该证书对于初学者来说最有价值,它由最著名的大学之一斯坦福大学提供。您可…...

DNS 泄露是什么?为什么网络环境检测时要看 DNS
很多人在检查网络环境时,第一反应通常是看 IP。比如 IP 显示在哪个地区、运营商是谁、是不是数据中心网络。 但实际上,除了 IP 之外,DNS 也是一个很容易被忽略的关键指标。如果 DNS 查询结果和当前网络出口不一致,就可能出现所谓的…...

Cadence变种BOM实战:以IMU模块为例,打造多配置硬件设计流程
1. 从零理解变种BOM的核心价值 第一次接触变种BOM这个概念时,我正被一个IMU模块的项目折磨得焦头烂额。客户要求这个模块能支持五种不同的通信接口,还要可选配导航和RTC功能。这意味着我需要维护十几个不同版本的原理图和BOM表,每次修改都要同…...

NotebookLM相似文档推荐不准,深度解析向量维度坍缩、跨域语义漂移与上下文窗口截断三大根源问题
更多请点击: https://intelliparadigm.com 第一章:NotebookLM相似文档推荐不准的系统性现象观察 在实际使用 NotebookLM 过程中,用户频繁反馈其“相似文档推荐”功能存在显著偏差:高语义相关但低表面重合度的文档常被遗漏&#x…...
)
瑞萨RA系列MCU入门实战:用e2 studio和FSP库5分钟点灯(从安装到烧录)
瑞萨RA系列MCU五分钟极速入门:从零点亮LED的全流程解析 当一块全新的瑞萨RA系列开发板第一次在你手中亮起LED时,那种"Hello World"式的成就感往往能瞬间点燃学习热情。不同于传统教程按部就班的软件安装介绍,本文将带您体验实战驱…...

Thanos剪枝算法:高效压缩大型语言模型的技术解析
1. 项目概述:Thanos剪枝算法解析在深度学习领域,大型语言模型(LLM)的参数量已突破千亿级别,这对计算资源和内存提出了极高要求。模型剪枝技术通过移除神经网络中的冗余连接,能在保持模型性能的同时显著降低…...

别再死记硬背了!用PyTorch手把手拆解ECAPA-TDNN中的Res2Net与SENet模块
用PyTorch实战解析ECAPA-TDNN中的Res2Net与SENet模块 当我们在说话人识别任务中追求更高的准确率时,ECAPA-TDNN无疑是一个绕不开的标杆模型。这个模型之所以能在VoxSRC等权威比赛中屡创佳绩,关键在于其精心设计的Res2Net和SENet模块的协同工作。本文将带…...
任务通知)
FreeRTOS源码解析(9)任务通知
1.任务通知本质:直接操作目标任务的 TCB 字段。 它不自带控制块、不分配独立存储、不维护自己的等待列表——全程只做一件事:读写目标任务 TCB 里已有的 ulNotifiedValue 和 ucNotifyState,必要时将对方从延迟列表移到就绪列表。正因如此&…...

别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器
别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器 信号处理工程师的日常工作中,滤波器设计是个绕不开的话题。无论是音频处理、通信系统还是生物医学信号分析,我们总需要根据不同的应用场景调整滤波器参数。传统方法中…...

从隔壁实验室到网易食堂:一个非985研究生的Python爬虫实习转正全记录
从实验室到网易食堂:一位普通研究生的Python爬虫逆袭之路 记得第一次听说隔壁实验室的Lucky拿到网易实习offer时,我们整个实验室都沸腾了。不是因为网易有多难进——事实上每年都有名校生进入各大厂——而是因为Lucky和我们一样,来自一所普通…...

数据流计算模型在边缘到云场景的优化实践
1. 数据流计算模型的演进与挑战数据流计算模型自诞生以来,已经成为分布式系统领域处理大规模数据的核心范式。这种模型通过将计算过程抽象为有向无环图(DAG),其中顶点代表数据处理算子,边代表数据流动路径,…...