C++ 50道面试题
1. static关键字
1.全局static变量
存储位置:静态存储区,在程序运行期间一直存在
初始化: 未手动初始化的变量自动初始化为0
作用域: 从定义之处开始,到文件结束,仅能在本文件中使用
2.局部static变量
存储位置:静态存储区,在程序运行期间一直存在
初始化: 未手动初始化的变量自动初始化为0
作用域: 为局部作用域, 当函数或语句块结束,静态变量仍然存在于内存区,再次调用函数或进入语句块时,可以再次被访问,且值保持不变
3.静态函数
静态函数只在声明他的文件内可见,无法被其他文件使用,若想在其他文件服用复用函数,最好把它写在头文件中,否则一般加static关键字
4.类的静态成员&静态函数
类的静态成员不属于任何一个类,可以在对象间共享,对于多个对象来说, 静态成员存储于一处,供所有对象访问,对静态函数/静态成员的访问不需要使用对象名。
类的静态函数不能直接引用类的非静态成员,可以引用静态成员,若要引用非静态成员,则需要使用对象名。
总的来说,static的作用
一是隐藏,当static修饰变量的时候,能够将变量或函数对本文件外的文件进行隐藏,无法在其他文件中访问。
二是初始化,静态存储区分为DATA段和BSS段,DATA段存放已经初始化了的全局变量,BSS段存放未初始化的全局变量和静态变量,在程序执行前,BSS段会被清零,从而所有静态变量都被初始化为0.
三是延长变量的生命周期,若想延长一个变量的生命周期,可以把它声明为static,比如对于一个函数中的变量,在函数下次调用的时候若想仍然使用这个变量,
2. 常量指针和指针常量
常量指针:表示const修饰的为所申明的类型。 也就是指向常量的指针。也是底层const
int const *p1 = &b; //const 在前,定义为常量指针
指针常量:表示指针是一个常量,无法改变其指向的内存空间。 即顶层const
int *const p2 = &c; // 在前,定义为指针常量
3. C和C++的区别
c++是C的超集
设计思想不同: C是面向过程的结构化编程语言,C++是面向对象的语言。
在语法上也存在差别:比如c++可以使用引用,c仅支持指针操作。比如c++有三种特性,继承封装多态,也对c进行了许多类型安全的封装,比如强制类型转换这些。而且c++支持范式编程,支持模板类等等。但是c++的高级特性大都是建立在降低效率的基础上实现的,c能够以最简便的方式编译,处理低级存储器,因此更适用于偏底层的设计,像嵌入式,单片机这些。
4. 浮点数的存储方式
5. 四种强制类型转换
- static_cast 可以用于任何有明确定义的类型转换,只要不包含底层const, 都可以使用static_cast。
- const_cast 只能改变运算对象的底层const,即去掉const性质
- reinterpret_cast 从运算对象底层的位模式提供低层次上的重新解释,不建议使用,若使用必须对涉及的类型和编译器的转换过程都十分了解。
- dynamic_cast 动态类型转换,一般用于含有虚函数的类,用于类层次间的向下(基类向子类的转换)或向上转化(子类向基类的转换),只能转化指针或者引用。
C++强制类型转换相对c语言的类型强转相比,虽然看起来c语言的强制类型转换功能更强大一些,但C++封装了更多保证内存安全性的操作,因此大多时候最好使用C++的强制类型转换。
6. 左值和右值
左值是持久化的变量,一般的具名变量都是左值,而右值是当前表达式运行结束就销毁的临时对象,区分左值右值得简单方法,能进行取址符操作的都是左值,其他的都是右值。
7. std::move语义
- std::move的本质就强制类型转换,它无条件地将实参转为右值引用类型
std::move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转移,没有内存的搬迁或者内存拷贝。
8. C++指针和引用的区别
指针
指针是指向另外一种类型的复合类型,用于实现数据的间接访问,指针本身同样是一个对象,它存储指向变量的地址值,当需要修改指针指向的变量时,需要使用解引用符,从而访问修改其指向的地址空间。
引用:
相当于给对象起了另外一个名字,定义引用时,程序把引用和初始值绑定在一起,而不是和其他变量一样把初始值拷贝给变量,一旦初始化完成,则与引用绑定的对象无法进行修改,因此定义引用时必须绑定一个初始值。
指针和引用的区别在于:
- 指针拥有属于自己的内存空间,是一个实实在在的对象,若想操作其指向的对象,需要解引用。而引用只是一个别名,当对引用使用任何操作符时,都是对和它绑定的对象进行操作。
- 指针不必在定义时赋值初始化,而引用必须进行初始化绑定。但是指针使用前必须进行赋值,否则会产生野指针从而出现问题。
- 指针在它的生命周期内,可以指向多个类型符合的对象,但引用只能与一个对象绑定。
- 指针可以存在 多级指针,但引用只能存在一级,因为引用就是该对象的别名。
- 指针和引用自增自减的效果不同,指针自增是指其内存中的地址增加一个指向对象类型单位大小的字节,而引用自增就只是与其绑定的对象的自增。
- 其实对于大多数编译器而言,引用可以被解释为const指针,低级语言的特性较少,表达的概念有限,所以编译器要将高级语言的概念映射到低级语言,可能会有很多种解释方式,但目前主流编译器都将引用与指针使用相同的方式来描述,即分配给引用一个地址空间存储绑定对象的地址,当使用引用时,就是对它存储的地址解引用后进行操作,我们无法访问引用的地址空间。
右值引用
c++11增加了一种引用叫右值引用,平时我们所指的引用就是左值引用,所谓右值引用,就是必须绑定到右值的引用,使用&&来定义。
右值引用拥有一个最重要的性质,只能绑定到一个将要销毁的对象,这样 我们可以将一个右值引用的资源直接移中存在一个std::move函数,可以显式的将一个左值变量转换为对应的右值引用类型,交给一个右值引用接收。
调用std::move则意味着除了对源对象进行重新赋值或者销毁,我们不再使用它,即我们不能对移后源对象作任何假设
9. c++的三种智能指针
c++11标准引入了三种智能指针,均定义在头文件下,其本质上是一个模板类,拥有构造函数和析构函数,在超出其作用域后,它会主动释放其管理的内存。
shared_ptr
shared_ptr是一种共享式指针,它引入了一个引用计数的概念,对于一块内存,每增加一个shared_ptr指向,其引用计数+1,每有一个shared_ptr释放对内存的使用权,即销毁指针或指向其他内存,则引用计数-1,当引用计数为0时,则自动释放其之前指向的内存。shared_ptr可以使用方法use_count()查看拥有管理权的shared_ptr的个数,可以使用release()方法释放其所有权,此时引用计数-1。
unique_ptr
为了保证同一时间仅能有一个指针来管理一块内存,c++11引入了unique_ptr,它是一种独占式指针,仅支持一个指针指向该内存。可以使用std::move来移动unique_ptr指向的内存。
weak_ptr
当有两个shared_ptr相互指向发生循环引用时,会产生死锁导致内存泄漏,因此c++11为了防止死锁现象的发生,引入了弱引用的概念,它的存在不会改变内存的引用计数,仅仅用于辅助shared_ptr来管理内存,提供一个访问内存的方式,可用于核查指针类,即检查该对象是否已经被释放。
10. shared_ptr是线程安全的吗
不是线程安全的,单独的修改引用计数是原子操作。
11. C++多态的原理和实现
C++可以使用两种方法实现多态
其一是使用函数重载(overload),也就是编译时多态,要求两函数有不同的参数列表
其二是使用虚函数进行函数重写(override),维护一个虚函数表vtbl,每个类存在vptr指针指向其vtbl对应的函数。
12. C语言如何实现多态,如何实现继承
实现多态,使用函数指针手动维护一个虚函数表,每个类都使用一个函数指针标记其函数表对应的函数。
继承: 将父类作为成员变量封装进子类。
13. 菱形继承的问题
菱形继承就是指: 一个派生类有多个基类,多个基类又由同一个类派生, 这样就会造成一个派生类中同时存在多个基类的基类, 编译器无法确定要调用哪个
解决方法: 虚继承
C++中引入了虚基类,其作用是 在间接继承共同基类时只保留一份基类成员
虚继承是声明类时的一种继承方式,在继承属性前面添加virtual关键字。
class A//A 基类
{ ... };//类B是类A的公用派生类, 类A是类B的虚基类
class B : virtual public A
{ ... };//类C是类A的公用派生类, 类A是类C的虚基类
class C : virtual public A
{ ... };
14. 什么是虚函数,为什么析构函数必须是虚函数,为什么C++默认构造函数不是虚函数
虚函数是在某个基类中声明,在其派生类中被重写的成员函数。用于实现多态性,简单来说就是,对于不同的类,相同的方法可以采用不同的策略。
如果析构函数不是虚函数,那么当一个派生类经由一个基类指针删除的时候,其结果是未定义的,实际实行的时候,通常是对象的派生类部分没有被销毁,而其中基类部分被销毁掉了,就产生了一种局部销毁的现象, 从而造成资源泄漏。
为了消除这个问题,就必须在基类中定义virtual的析构函数,从而销毁对象时,才能完整销毁。
如果class是不带虚函数的,通常表示它并不意图作为一个基类,当class不意图作为一个基类时,使用它作为基类往往不是一个好主意。因为想要实现虚函数,该对象必须要携带更多的信息,用来在运行期决定哪个虚函数被调用,这份信息一般由vptr(virtual table pointer)指出,vptr指向一个函数指针构成的数组(virtual table),每一个带有虚函数的都存在一个相应的vtbl。当程序运行某个虚函数,则实际被调用的函数取决于vptr当前指向的函数。这样为每个类都添加一个虚函数表可能会增加对象大小到50%-100%。因此,一般情况下,只有当一个class存在至少一个虚函数,才认为它可以被当作base class,然后为他添加virtual的析构函数。比如stl中的所有模板类,就都是不被设计作为base class的
当定义某个对象的时候,首先要为它分配空间,然后执行构造函数,而vptr就是在构造函数中初始化的,而又需要查找vptr来决定执行哪个函数,这时就陷入了循环。所以不能将构造函数设置为虚函数。
15. 什么是函数指针
函数指针是指向函数的指针变量,作为一个可调用对象,他能指向所有返回值和参数匹配的函数,从而可以传入其他函数,分情况调用不同的函数。
int (*fp)(args)
typedef int (*fun)(int a,int b);
16. 说一下C++的三大特性
C++的三大特性是封装继承和多态。
封装,就是隐藏对象的内部细节,只留给使用者几个接口,来按设计者的规范来使用该对象。可以隔离开外部使用者对内部数据的干扰,提高了安全性,同样也便于使用者操作。
继承,就是从一个对象继承它的属性和方法,可以减少重复代码,同时继承也是多态的前提,也增加了类的耦合性。
多态,就是不同的对象,对于相同的方法有不同的操作逻辑,一般使用虚函数来实现。它大大提高了代码的可复用性,可维护性和可扩充性,三大特性是C++面向对象的基础,正是C++与C的最大区别。
17. C++如何定义常量,常量存放在哪个位置
对于const定义的常变量,其本质上就是个只读变量。
对于局部常量,在运行前不会为其分配内存,会在运行时进行栈上分配。
对于全局常量,在运行前就已经存储在了.DATA段中。
18. 如何让一个函数在main函数执行前先执行
写在类的构造函数中,定义全局对象,在构造时运行。
19. 隐式类型转换
对于内置类型,当运算符两端类型不同时,编译器会自动使低精度的类型向高精度类型转换。
在类的构造函数中,可以直接传入参数,编译器会为其生成一个临时对象用于构造。
虽然隐式类型转换很多情况下很方便,但是有的时候也会得到我们不想得到的结果,所以可以使用explicit关键字禁止编译器进行隐式类型转换。
20. new/delete与malloc/free的区别
new和delete是c++的关键字,而malloc和free是内置函数,当使用new对对象进行分配空间时,编译器会自动得到该对象的大小,但是malloc需要显式给出需要分配的空间大小。
对于自定义的类来说,new会先调用operator new申请足够的空间,然后调用类类型的构造函数,最后返回该类型的指针,delete会先调用类的析构函数,然后调用operator delete释放内存空间。而malloc和free是内置函数,无法要求他们调用构造函数和析构函数。
21. 什么是RTTI
RTTI(Run Time Type Identification)即运行时对类型进行识别,即程序在运行中可以根据基类的指针或者引用来识别所指对象的实际派生类,它的实际用处主要是在当我们想要使用基类对象的指针或引用来操作它的派生类对象的方法,但此方法由于一些原因无法被设置为虚函数。
RTTI机制的功能由两个运算符实现。
一个是typeid运算符,返回指针或引用指向的对象的实际类型。但是其操作时作用于对象的,所以需要使用取址符,当typeid作用于指针的时候,将返回该指针的编译时静态类型。
另一个时dynamic_cast 运算符,他有三种形式,可以传入指针,引用与右值引用,可以用于类类型的向上或向下转换。
RTTI在有些情况下作用十分明显,比如我们需要实现一个有继承关系的类之间的相等运算符,我们可以先使用typeid比较两个对象类型是否一致,一致则进行每个函数的内置equal函数判断。
22. inline跨文件使用
内联函数必须在调用它的每个文件中定义, 若想在所有文件中使用,最好在头文件中定义,且一旦内联函数在多个头文件中定义,则会产生内联函数的重定义
23. 虚函数表具体怎样实现运行时多态
所谓虚函数表是一个类的虚函数地址表,在每个对象创建的时候,都会有一个vptr指向虚函数表,当继承它的子类对虚函数进行重写时,虚函数表中的对应函数地址将被新地址覆盖,所以当父类指针调用子类的成员函数时,虚函数指针就可以指向对应的函数。
当调用虚函数时过程如下(引自More Effective C++):
- 通过对象的 vptr 找到类的 vtbl。
这是一个简单的操作,因为编译器知道在对象内 哪里能找到 vptr(毕竟是由编译器放置的它们)。因此这个代价只是一个偏移调整(以得到 vptr)和一个指针的间接寻址(以得到 vtbl)。 - 找到对应 vtbl 内的指向被调用函数的指针。
这也是很简单的, 因为编译器为每个虚函数在 vtbl 内分配了一个唯一的索引。这步的代价只是在 vtbl 数组内的一个偏移。 - 调用第二步找到的的指针所指向的函数。
- 在单继承的情况下
调用虚函数所需的代价基本上和非虚函数效率一样,在大多数计算机上它多执行了很少的一些指令,所以有很多人一概而论说虚函数性能不行是不太科学的。 - 在多继承的情况
由于会根据多个父类生成多个vptr,在对象里为寻找 vptr 而进行的偏移量计算会变得复杂一些,但这些并不是虚函数的性能瓶颈。**虚函数运行时所需的代价主要是虚函数不能是内联函数。**这也是非常好理解的,是因为内联函数是指在编译期间用被调用的函数体本身来代替函数调用的指令,但是虚函数的“虚”是指“直到运行时才能知道要调用的是哪一个函数。”但虚函数的运行时多态特性就是要在运行时才知道具体调用哪个虚函数,所以没法在编译时进行内联函数展开。当然如果通过对象直接调用虚函数它是可以被内联,但是大多数虚函数是通过对象的指针或引用被调用的,这种调用不能被内联。 因为这种调用是标准的调用方式,所以虚函数实际上不能被内联。
- 在单继承的情况下
24. C语言如何进行函数调用
对于每个函数,c++都会为它分配一个栈,在进行函数调用之前,先将当前指令的esp指针压入栈中,并将参数入栈,跳转到函数存储的地址,函数执行结束后,恢复esp指针,回到原地址继续运行。
25. 拷贝构造函数的调用时机
1.直接初始化和拷贝初始化时
2.将一个对象作为实参传递给一个非引用或非指针类型的形参时
3.从一个返回类型为非引用或非指针的函数返回一个对象时
4.用花括号列表初始化一个数组的元素或者一个聚合类(很少使用)中的成员时。
26. 当C++定义类时,编译器会为类自动生成哪些函数?这些函数各自都有什么特点?
- 默认构造函数
- 默认析构函数
- 拷贝构造函数
- 默认赋值函数
27. 静态函数和虚函数的区别
静态函数是在编译时就已经确定好了运行的时机,而虚函数是使用动态绑定,虚函数使用了虚函数表机制,调用会增加一次的内存开销。
28. STL由什么组成
容器:容纳,包含一种元素或元素集合。
迭代器: 用于遍历,访问容器中的元素,一般作为泛型算法的参数。
仿函数:
泛型算法:用来操作容器中元素的方法。
分配器:为容器等分配空间。
配接器:将一个class的接口转换为另一个class的接口,使原本因接口不兼容不能合作的两个class共同运作。
29. map 和set的区别,它们是如何实现的
map和set都是c++的关联容器,其底层实现都是红黑树,他们所有的接口都由红黑树给出,所以几乎所有的操作行为都是转调红黑树的操作。
区别:
map是映射,其中的元素是key-value的,可以按key值来索引value值。
set是集合,其中元素只是一个值,仅包含一个关键字。
set的迭代器是const的,它不支持使用迭代器修改元素,而map允许修改value的值,他们的元素都是根据关键字来保证有序的,所以不能轻易修改,只能将原关键字删除,重新插入,但是对于这些操作都是O(logn)的,所以时间开销较大。
另外,map支持下标操作,set不支持。
30. vector 和list的区别,它们是如何实现的
vector和list都是c++中的容器,vector是向量,底层存储空间是连续的,也就是数组,所以对于随机读取修改所需时间较低,为O(1),但插入的复杂度较低,每次插入要将其后面的元素向后移动,所以最坏时间复杂度是O(n)的。且在可分配空间不足时,可能需要将所有的数据移动到另一块内存。
list底层实现是双向链表,底层存储时非连续的,随机读取只能从头节点向后查找,所以最坏时间复杂度是O(n)的,但插入仅需 O(1)。
31. 有哪些内存泄漏?如何判断内存泄漏?如何定位内存泄漏?
内存泄漏是指对内存的泄露,堆内存在程序中由程序动态分配的内存,使用过后需要显示释放,有些时候忘记释放已使用完的内存,就会发生内存泄漏。若运行过久,可能会导致栈溢出致使程序崩溃。
c++无法检测内存泄漏,但是可以依靠top命令查看进程的动态内存总额,也可以使用mtrace来检测定位内存泄漏。
32. 动态链接和静态链接的区别
-
静态链接
所谓静态链接就是在编译链接时直接将代码拷贝至链接处,他的优点是可以独立于库进行发布,但是若静态库文件过大,容易造成资源的浪费。
-
动态链接
动态链接就是编译的时候不将代码拷贝到文件,而是只复制了一些重定位信息和符号表信息,在程序运行或加载时,将这些信息传递给操作系统,操作系统负责将动态库加载到内存中,程序运行到指定代码时,再去执行已经加载到内存中的函数。
-
静态链接存在着明显的缺点,一是资源的浪费,对于多个可执行文件均调用同一个模块时,需要将每个模块都要拷贝到内存中。二是当静态库文件过大时,若想更新静态库存在着诸多不便。而动态库就是为了解决这两个问题而生。
-
动态链接将程序按模块拆分,在构建可执行程序时,发现该函数十几个外部符号,则将其放到运行时进行处理,运行时对其进行重定位。动态链接相比静态链接更加灵活,解决了模块拷贝到内存时的资源浪费,虽然性能相对存在一定的下降,但是相比灵活性的提升,显然是更值得的。
如何让一个类不能实例化?
将类定义为抽象基类或者将构造函数声明为private。
33. C++如何创建一个类,使得他只能在堆或者栈上创建?
- 只能在堆上生成对象:将析构函数设置为私有。
原因:C++是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。 - 只能在栈上生成对象:将new 和 delete 重载为私有。
原因:在堆上生成对象,使用new关键词操作,其过程分为两阶段:第一阶段,使用new在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将new操作设置为私有,那么第一阶段就无法完成,就不能够再堆上生成对象。
34. C++内存管理
c++中内存分为五个区域
- 堆区, 程序需要主动申请分配,主动释放的区域。可以使用malloc申请
- 栈区, 当创建对象时由程序主动分配
- 全局变量区, 创建的静态变量或全局变量
- 文字常量区, 字面值常量以及字符常量,比如printf中的格式化输出字符
- 代码区,代码区段
35. 介绍一下allocator
new是有局限性的,每次new一个对象的时候,会将分配空间和构造对象组合在一起,,有的时候可能会产生一些灵活性上的局限。allocator正是为了解决这个问题而产生的。
一个allocator类调用allocate来分配空间,调用construct来构造对象,destroy来销毁对象。
36. STL迭代器删除元素
对于顺序容器,当使用erase删除元素后,会导致排在后面的迭代器失效,每个元素向前移动一位,但是erase会指向下一个迭代器。
对于关联容器,由于底层总是树形结构或者哈希结构,对后面的迭代器是没有影响的。
37. 介绍一下模板
模板的目的就是编写与类型无关的代码。
可以使用它来编写函数模板以及类模板。
模板的使用,可以增加代码的灵活性和可重用性,减少开发时间,且模板来模拟多态比类继承实现多态效率会更高一些
但是模板也存在一定问题,比如可读性较差,调试较困难,因为模板的类型只有编译时才能确定,所以编译时间会稍长一点。
38. resize和reserve的区别
resize是对改变当前容器元素的数量,若resize大小小于当前容器元素的数量,则删除后面的元素。
reserve是改变其预留空间,保证内存空间可容纳的元素数量,并不生成新的对象,若参数小于当前容器元素数量,则不改变当前的元素数量。
39. C++内存对齐
内存对齐就是计算机系统对数据存放位置的限制。
大部分处理器的内存存取粒度是4字节8字节这样的,如果不进行内存对齐,可能会产生一个整数的存储位置被分到两块内存,需要cpu进行两次读取再拼接,需要做的工作十分复杂,而对齐后可以将一个数据一次直接读取出来,提高cpu的读取效率,一般编译器默认的内存对齐系数是4,在结构体或类中,内存对齐系数一般为其成员变量的最大内存对齐系数。
可以使用#pragma pack(n)来改变默认对齐系数
40. 结构体的对齐,为什么要对齐
内存对齐主要遵从以下三个原则
- 结构体变量的起始地址能够被其最宽的成员大小整除
- 结构体每个成员相对于起始地址的偏移能够被其自身大小整除,如果不能则在前一个成员后面补充字节
- 结构体总体大小能够被最宽的成员的大小整除,如不能则在后面补充字节
为什么需要对齐?
1.平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2.性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
41. 说一下c++的编译过程
-
编译预处理
预处理阶段主要是做一些代码替换的工作,处理预处理指令,解包头文件,替换宏定义,删掉注释等等。 -
编译、优化阶段
通过词法语法分析,将代码文件转换为汇编代码
-
汇编过程
将汇编代码转换为指定目标的机器指令,以便在目标机器上运行。
-
链接程序
链接程序就是将代码所用到的模块,代码片段等连接起来,使其可以运行。
42. 深拷贝与浅拷贝
深拷贝是直接将内存拷贝出一份
浅拷贝只是将指针拷贝指向同一块内存
当类成员存在指针时,若使用默认构造函数使用简单的浅拷贝,那么当使用析构函数释放资源时,会提前释放成员指针指向的数据,可能造成空悬指针多次释放导致内存泄漏。
43. C++ 11/14/17新特性
11:
- 智能指针
- override关键字
- =delete/=default
- auto
- for each语法
- 无序容器
- nullptr
- lambda匿名函数
- 右值引用 和 移动语义
- explicit/override/final/noexcept
- std::function
14:
- 泛型lambda
- 二进制字面值
- 数字分隔符
17:
- 扩展了auto的推断范围
- 嵌套命名空间
- 条件分支语句初始化
44. 零拷贝
所谓的零拷贝(Zero-Copy)是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手 。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换 。 对 Linux操作系统而言,零拷贝技术依赖于底层的 sendfile() 方法实现 。
ssize_t sendfile(int out_fd,int in_fd,off_t* offset,size_t count);
in_fd参数是待读出内容的文件描述符,out_fd参数是待写入内容的文件描述符。offset参数指定从读入文件流的哪个位置开始读,如果为空,则使用读入文件流默认的起始位置。count参数指定文件描述符in_fd和out_fd之间传输的字节数。
工作原理
系统调用直接通过DMA将数据拷贝到内核缓冲区,然后被内核直接转发到与另一个文件相关的内核缓冲区,其中一直都是内核态,不需要进入用户态。
45. 零拷贝在c++中的使用
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
45. 什么是线程安全
线程安全是指内存安全,也就是保证本线程所使用的数据,不被其他线程暗改,导致得到的数据不是自己想要的数据。
46. 解决线程安全的办法
- 使用线程自己的栈内存,每个线程都存在自己所独有的栈,其他线程无法影响,可以把需要保证安全的数据存放在自己的栈区中,这样其他线程无法访问,也就保证了线程安全
- 对于所需数据copy一份自己的,每个线程都copy一份原数据,每个线程只访问属于自己的那部分数据,也就保证了线程安全
- 定义常变量,也就是只读变量,保证变量无法被修改。
- 使用互斥锁,保证内存中的数据互斥访问。
47. 异常处理 栈展开
在C++里,当有异常被抛出,调用栈(call stack),即栈中用来储存函数调用信息的部分,会被按次序搜索,直到找到对应类型的处理程序(exception handler)。而这里的搜索顺序就是f1->f2->f3。f1没有对应类型的catch块,因此跳到了f2,但f2也没有对应类型的catch块,因此跳到f3才能处理掉这个异常。 这个寻找异常相应类型处理器的过程就叫做栈展开。
48. 析构函数能否抛出异常
不能。
- 如果析构函数抛出异常,则异常点之后的程序不会执行,如果析构函数在异常点之后执行了某些必要的动作比如释放某些资源,则这些动作不会执行,会造成诸如资源泄漏的问题。
- 通常异常发生时,c++的异常处理机制在异常的传播过程中会进行栈展开(stack-unwinding)在栈展开的过程中 会释放局部对象所占用的内存并运行类类型局部对象的析构函数 ,此时若其他析构函数本身也抛出异常,则前一个异常尚未处理,又有新的异常,会造成程序崩溃。
解决方法
- 直接结束程序
- 把可能产生异常的代码移出析构函数
- 直接消化处理异常
49. 单例模式
class sigleton
{
private: sigleton(){};static sigleton* _instance;
public:sigleton* instance(){if(!_instance){_instance = new sigleton;}return _instance;}};
sigleton* sigleton::_instance = 0;
多线程安全单例模式
std::mutex mt;
class sigleton
{
private: sigleton(){};static sigleton* _instance;
public:sigleton* instance(){if(!_instance){mt.lock();if(!_instance) _instance = new sigleton;mt.unlock();}return _instance;}};
sigleton* sigleton::_instance = 0;
50. std::sort源码剖析
背景:
- 快速排序虽然平均复杂度为O(N logN),却可能由于不当的pivot选择,导致其在最坏情况下复杂度恶化为O(N2)。另外,由于快速排序一般是用递归实现,我们知道递归是一种函数调用,它会有一些额外的开销,比如返回指针、参数压栈、出栈等,在分段很小的情况下,过度的递归会带来过大的额外负荷,从而拉缓排序的速度。
- 堆排序经常是作为快速排序最有力的竞争者出现,平均时间上,堆排序的时间常数比快排要大一些,因此通常会慢一些,但是堆排序最差时间也是O(nlogn)的,这点比快排好。
- 快排在递归进行部分的排序的时候,只会访问局部的数据,因此缓存能够更大概率的命中;而堆排序的建堆过程是整个数组各个位置都访问到的,后面则是所有未排序数据各个位置都可能访问到的,所以不利于缓存发挥作用。简单的说就是快排的存取模型的**局部性(locality)**更强,堆排序差一些。
- 还有一个问题就是:难以并行。
递归调用和循环调用相结合
std::sort 在内部使用使用快速排序, 但是为了优化时间复杂度,sort将整个序列分为两部分后,对于右子区间执行递归调用,而对左子区间,直接将其分为两部分进行循环调用。这样可以节省一半时间的函数调用,节省掉函数调用的时间。
-
三点中值法
对于快排的基准值,sort采用三点中值法,取首尾和中间三个值中的中间值作为基准值执行快排。
-
递归深度阈值
sort设定了一个递归深度阈值,初始值是nlogn,当达到递归深度阈值时,说明该序列存在着恶化倾向,函数调用堆排序,将该区间进行严格的nlogn复杂度的排序。
-
最小分段阈值
sort还设定了一个最小分段阈值, 一般定义为16, 当序列长度达到这个阈值,且经过了多次的快速排序的分段,序列是存在一定程度的有序的,这时调用插入排序,可以最优化的处理该子段。
51. lambda表达式底层实现
编译器会把一个lambda表达式生成一个匿名类的匿名对象,并在类中重载函数调用运算符。
本质就是因为 lambda 表达式在底层被转换成了仿函数。当我们定义一个lambda表达式后,编译器会自动生成一个类,在该类中对 () 运算符进行重载,实际 lambda 函数体的实现就是这个仿函数 operator() 的实现,在调用 lambda 表达式时,参数列表和捕获列表的参数,最终都传递给了仿函数的 operator()。
相关文章:

C++ 50道面试题
1. static关键字 1.全局static变量 存储位置:静态存储区,在程序运行期间一直存在 初始化: 未手动初始化的变量自动初始化为0 作用域: 从定义之处开始,到文件结束,仅能在本文件中使用 2.局部static变量…...

寒假学习记录14:JS字符串
目录 查找字符串中的特定元素 String.indexOf() (返回索引值) 截取字符串的一部分 .substring() (不影响原数组)(不允许负值) 截取字符串的一部分 .slice() (不影响原数…...

【数学建模】【2024年】【第40届】【MCM/ICM】【C题 网球运动中的“动量”】【解题思路】
一、题目 (一) 赛题原文 2024 MCM Problem C: Momentum in Tennis In the 2023 Wimbledon Gentlemen’s final, 20-year-old Spanish rising star Carlos Alcaraz defeated 36-year-old Novak Djokovic. The loss was Djokovic’s first at Wimbledon…...
无人驾驶LQR控制算法 c++ 实现
参考博客: (1)LQR的理解与运用 第一期——理解篇 (2)线性二次型调节器(LQR)原理详解 (3)LQR控制基本原理(包括Riccati方程具体推导过程) (4)【基础…...
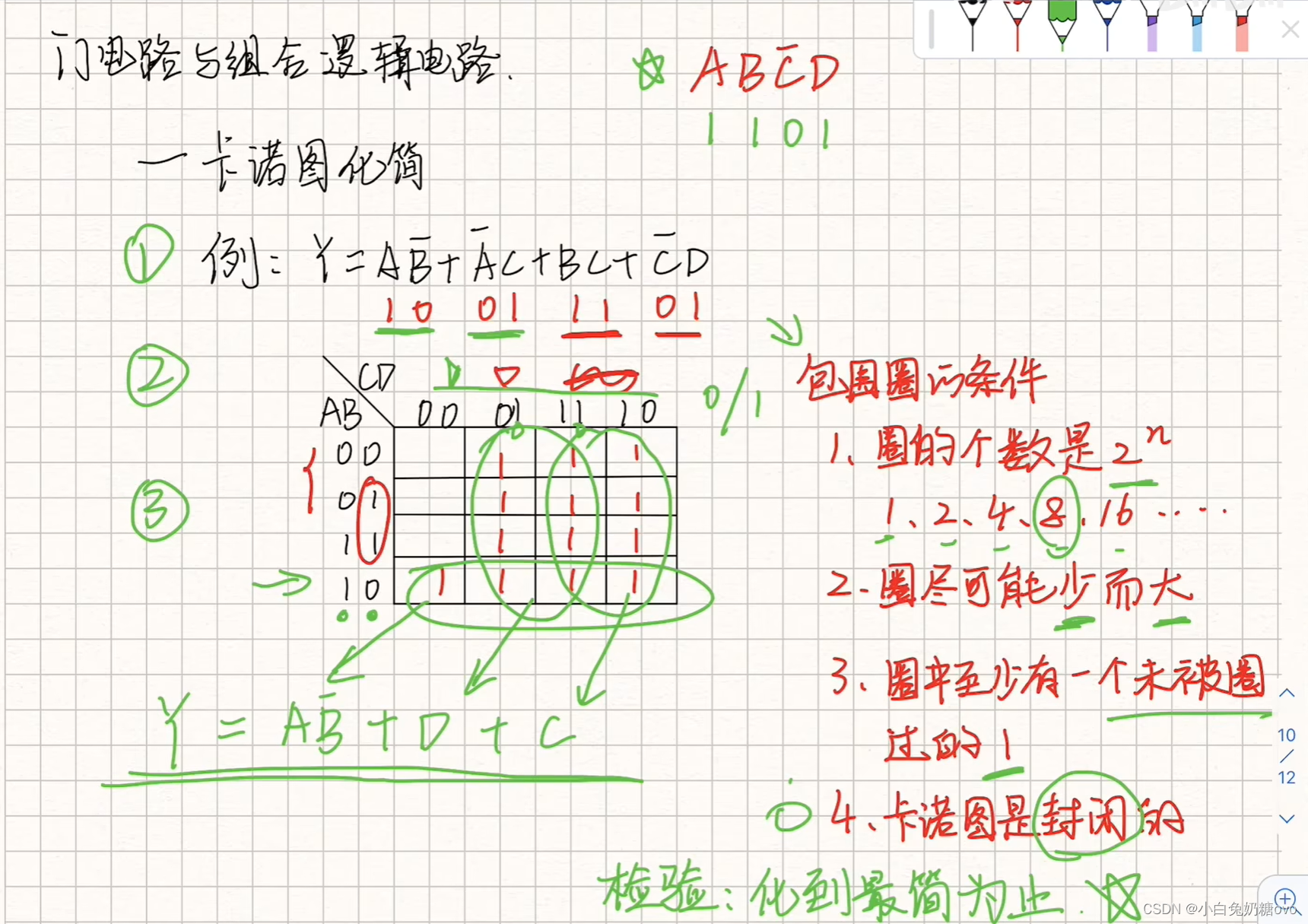
Karnaugh map (卡诺图)
【Leetcode】 289. Game of Life According to Wikipedia’s article: “The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.” The board is made up of an m x n grid of cells, wh…...

C# CAD 框选pdf输出
在C#中进行AutoCAD二次开发时,实现框选(窗口选择)实体并输出这些实体到PDF文件通常涉及以下步骤: public ObjectIdCollection GetSelectedEntities() {using (var acTrans HostApplicationServices.WorkingDatabase.Transaction…...

【Linux】 Linux 小项目—— 进度条
进度条 基础知识1 \r && \n2 行缓冲区3 函数介绍 进度条实现版本 1代码实现运行效果 版本2 Thanks♪(・ω・)ノ谢谢阅读!!!下一篇文章见!!! 基础知识 1 \r &&a…...
Sora和Pika,RunwayMl,Stable Video对比!网友:Sora真王者,其他都是弟
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识…...

Go内存优化与垃圾收集
Go提供了自动化的内存管理机制,但在某些情况下需要更精细的微调从而避免发生OOM错误。本文介绍了如何通过微调GOGC和GOMEMLIMIT在性能和内存效率之间取得平衡,并尽量避免OOM的产生。原文: Memory Optimization and Garbage Collector Management in Go 本…...

【Spring】Bean 的生命周期
一、Bean 的生命周期 Spring 其实就是一个管理 Bean 对象的工厂,它负责对象的创建,对象的销毁等 所谓的生命周期就是:对象从创建开始到最终销毁的整个过程 什么时候创建 Bean 对象?创建 Bean 对象的前后会调用什么方法…...
云计算基础-存储基础
存储概念 什么是存储: 存储就是根据不同的应用程序环境,通过采取合理、安全、有效的方式将数据保存到某些介质上,并能保证有效的访问,存储的本质是记录信息的载体。 存储的特性: 数据临时或长期驻留的物理介质需要保…...
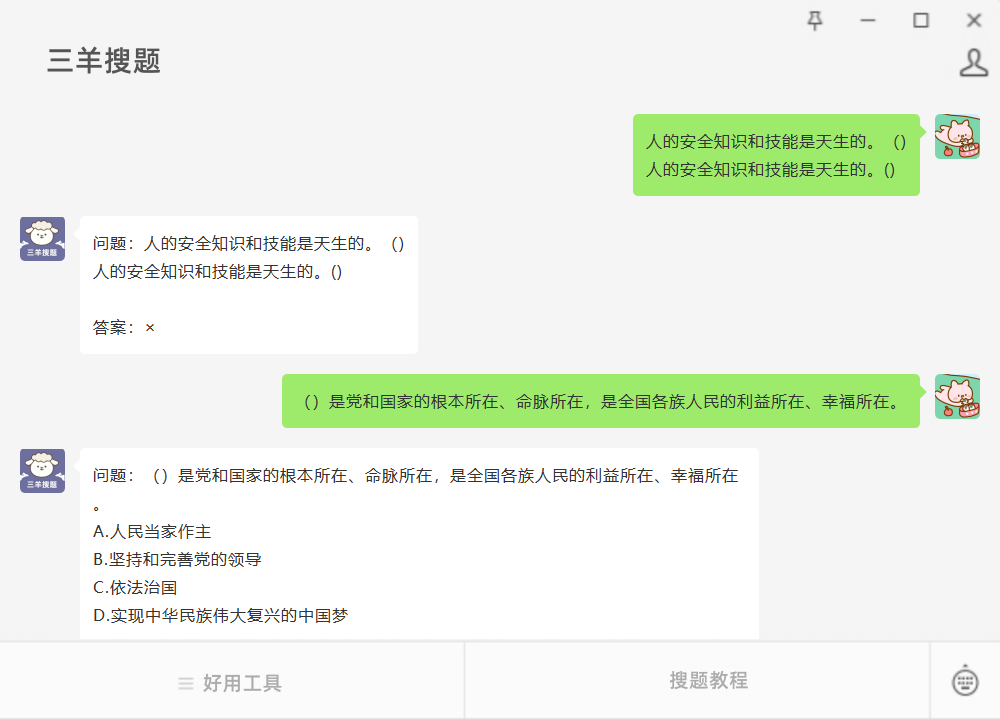
问题:人的安全知识和技能是天生的。() #媒体#知识分享#学习方法
问题:人的安全知识和技能是天生的。() 人的安全知识和技能是天生的。() 参考答案如图所示 问题:()是党和国家的根本所在、命脉所在,是全国各族人民的利益所在、幸福所在。 A.人民当家作主 B.坚持和完善…...
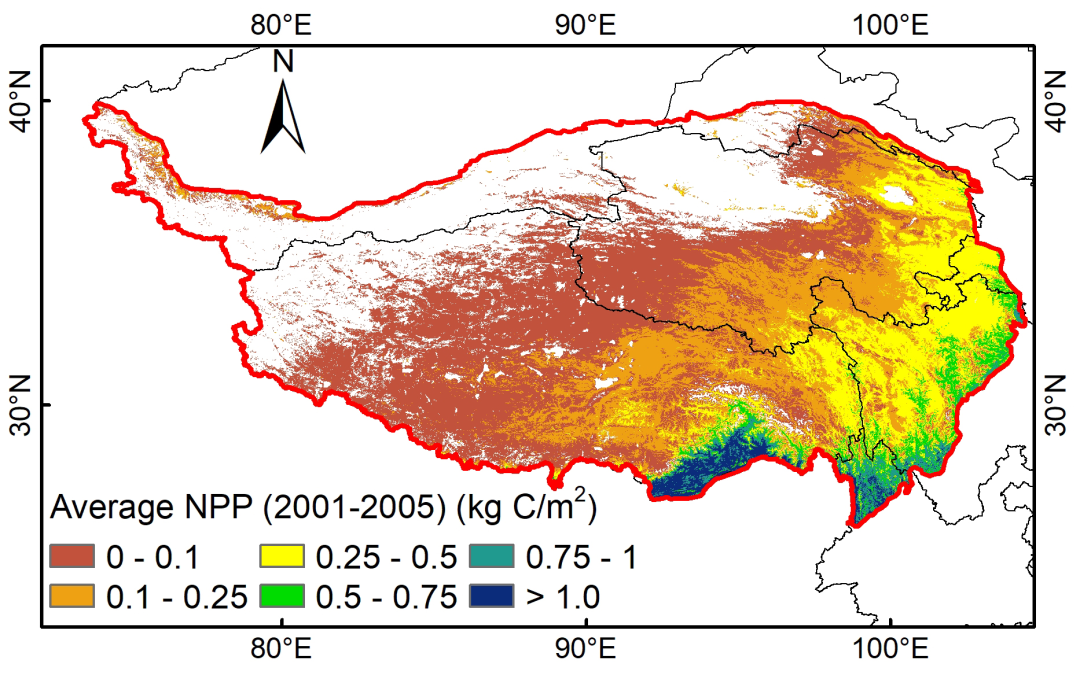
【数据分享】2001~2020年青藏高原植被净初级生产力数据集
各位同学们好,今天和大伙儿分享的是2001~2020年青藏高原植被净初级生产力数据集。如果大家有下载处理数据等方面的问题,您可以私信或评论。 朱军涛. (2022). 青藏高原植被净初级生产力数据集(2001-2020). 国家青藏高原数据中心. …...

【Spring MVC篇】返回响应
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【Spring MVC】 本专栏旨在分享学习Spring MVC的一点学习心得,欢迎大家在评论区交流讨论💌 目录 一、返回静态页面…...
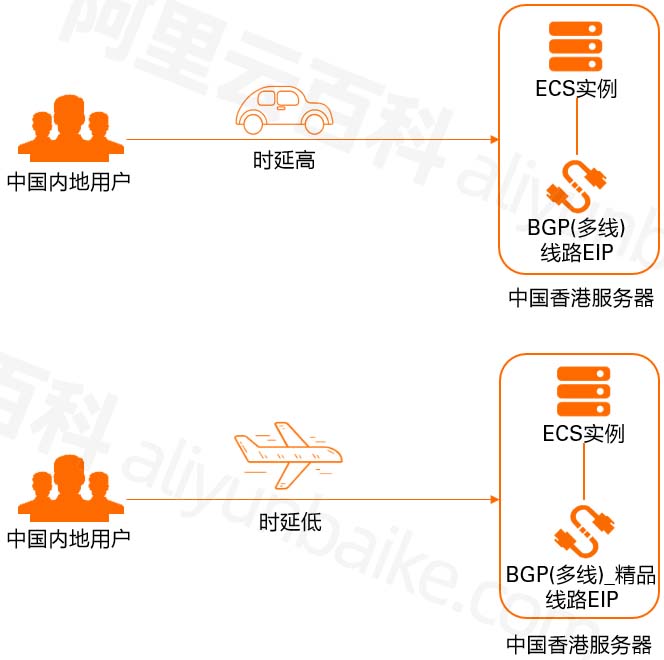
阿里云BGP多线精品EIP香港CN2线路低时延,价格贵
阿里云香港等地域服务器的网络线路类型可以选择BGP(多线)和 BGP(多线)精品,普通的BGP多线和精品有什么区别?BGP(多线)适用于香港本地、香港和海外之间的互联网访问。使用BGP…...
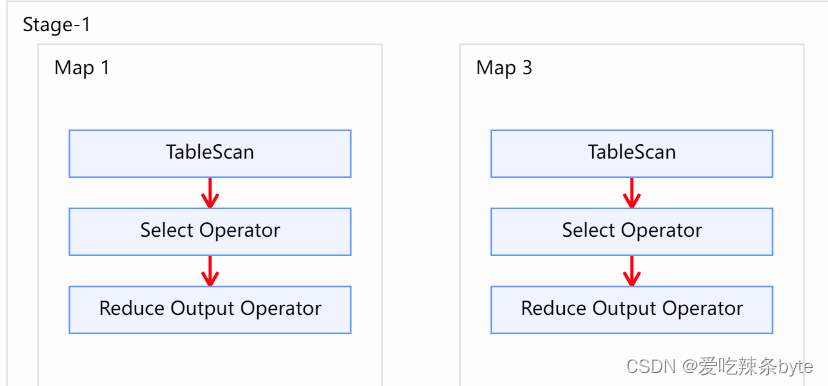
(08)Hive——Join连接、谓词下推
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左…...

创新技巧|迁移到 Google Analytics 4 时如何保存历史 Universal Analytics 数据
Google Universal Analytics 从 2023 年 7 月起停止收集数据(除了付费 GA360 之外)。它被Google Analytics 4取代。为此,不少用户疑惑:是否可以将累积(历史)数据从 Google Analytics Universal 传输到 Goog…...

一个小而实用的 Python 包 pangu,实现在中文和半宽字符(字母、数字和符号)之间自动插入空格
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一个小巧的库,可以避免自己重新开发功能。利用 Python 包 pangu,可以轻松实现在 CJK(中文、日文、韩文)和半宽字符(字母、数字和符号…...

openJudge | 中位数 C语言
总时间限制: 2000ms 内存限制: 65536kB 描述 中位数定义:一组数据按从小到大的顺序依次排列,处在中间位置的一个数或最中间两个数据的平均值(如果这组数的个数为奇数,则中位数为位于中间位置的那个数;如果这组数的个…...
ctfshow-文件上传(web151-web161)
目录 web151 web152 web153 web154 web155 web156 web157 web158 web159 web160 web161 web151 提示前台验证不可靠 那限制条件估计就是在前端设置的 上传php小马后 弹出了窗口说不支持的格式 查看源码 这一条很关键 这种不懂直接ai搜 意思就是限制了上传类型 允许…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南
NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾为游戏卡顿而烦恼?是否觉得显卡性能总差那么一点&#x…...

AICoverGen终极指南:5分钟用AI制作专业级翻唱歌曲
AICoverGen终极指南:5分钟用AI制作专业级翻唱歌曲 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想不想让AI…...
深入Transformer内部:LoRA到底改动了哪部分权重才让模型“学会”新任务?
深入Transformer内部:LoRA如何通过低秩更新重塑大模型能力 在自然语言处理领域,大型预训练模型的微调一直是个计算密集型任务。传统全参数微调需要更新数十亿甚至数千亿参数,这对大多数研究者和企业来说都是难以承受的负担。低秩适应(LoRA)技…...

OCT-X算法:早期胃癌AI检测的技术突破与应用
1. OCT-X算法:早期胃癌AI检测的技术突破在医疗影像分析领域,胃癌早期检测一直面临着巨大挑战。传统内窥镜检查依赖医生经验判断,存在主观性强、漏诊率高等问题。我们团队开发的OCT-X(One Class Twin Cross Learning)算…...

Arduino nRF52 BLE开发:GATT服务与特征值配置实战详解
1. 项目概述如果你正在用Arduino和nRF52系列芯片(比如nRF52832或nRF52840)做蓝牙低功耗(BLE)开发,那你肯定绕不开GATT(通用属性配置文件)这一关。GATT是BLE通信的“语言规则”,它定义…...

Arm CoreLink PCK-600电源管理套件解析与应用实践
1. Arm CoreLink PCK-600电源控制套件概述在现代SoC设计中,电源管理已经成为一个关键的技术挑战。随着移动设备和物联网应用的普及,如何在保证性能的同时最大限度地降低功耗,成为芯片设计者面临的核心问题。Arm CoreLink PCK-600电源控制套件…...

Bun用Rust重写核心代码,百万行新增代码直接把GitHub干爆了!
Bun 项目刚刚完成了一次惊人的技术跨越。5月14日,Bun 正式宣布其核心运行时已从 Zig 重写为 Rust——这个版本包含 6755 个 commit,二进制文件体积缩小 3-8 MB,性能测试在各个平台上均达到或超越原有水平。Jarred Sumner(Bun 的创…...
:为什么它突然支持Nastaliq音素映射?)
ElevenLabs乌尔都语语音合成精度实测报告(WER 8.2% vs 行业均值19.6%):为什么它突然支持Nastaliq音素映射?
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都语语音合成精度实测报告(WER 8.2% vs 行业均值19.6%):为什么它突然支持Nastaliq音素映射? ElevenLabs于2024年Q2悄然上线乌尔都语&#…...

5分钟快速上手:PlantUML Editor - 告别拖拽,用代码绘制专业UML图表
5分钟快速上手:PlantUML Editor - 告别拖拽,用代码绘制专业UML图表 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 还在为绘制复杂的UML图表而烦恼吗?你…...