Python爬虫之文件存储#5
爬虫专栏:http://t.csdnimg.cn/WfCSx
文件存储形式多种多样,比如可以保存成 TXT 纯文本形式,也可以保存为 JSON 格式、CSV 格式等,本节就来了解一下文本文件的存储方式。
TXT 文本存储
将数据保存到 TXT 文本的操作非常简单,而且 TXT 文本几乎兼容任何平台,但是这有个缺点,那就是不利于检索。所以如果对检索和数据结构要求不高,追求方便第一的话,可以采用 TXT 文本存储。本节中,我们就来看下如何利用 Python 保存 TXT 文本文件。
1. 本节目标
本节中,我们要保存知乎上 “发现” 页面的 “热门话题” 部分,将其问题和答案统一保存成文本形式。
2. 基本实例
首先,可以用 requests 将网页源代码获取下来,然后使用 pyquery 解析库解析,接下来将提取的标题、回答者、回答保存到文本,代码如下:
import requests
from pyquery import PyQuery as pq
url = 'https://www.zhihu.com/explore'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
html = requests.get(url, headers=headers).text
doc = pq(html)
items = doc('.explore-tab .feed-item').items()
for item in items:question = item.find('h2').text()author = item.find('.author-link-line').text()answer = pq(item.find('.content').html()).text()file = open('explore.txt', 'a', encoding='utf-8')file.write('\n'.join([question, author, answer]))file.write('\n' + '=' * 50 + '\n')file.close()
这里主要是为了演示文件保存的方式,因此 requests 异常处理部分在此省去。首先,用 requests 提取知乎的 “发现” 页面,然后将热门话题的问题、回答者、答案全文提取出来,然后利用 Python 提供的 open 方法打开一个文本文件,获取一个文件操作对象,这里赋值为 file,接着利用 file 对象的 write 方法将提取的内容写入文件,最后调用 close 方法将其关闭,这样抓取的内容即可成功写入文本中了。
运行程序,可以发现在本地生成了一个 explore.txt 文件,其内容如图所示。

这样热门问答的内容就被保存成文本形式了。
这里 open 方法的第一个参数即要保存的目标文件名称,第二个参数为 a,代表以追加方式写入到文本。另外,我们还指定了文件的编码为 utf-8。最后,写入完成后,还需要调用 close 方法来关闭文件对象。
3. 打开方式
在刚才的实例中,open 方法的第二个参数设置成了 a,这样在每次写入文本时不会清空源文件,而是在文件末尾写入新的内容,这是一种文件打开方式。关于文件的打开方式,其实还有其他几种,这里简要介绍一下。
-
r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
-
rb:以二进制只读方式打开一个文件。文件指针将会放在文件的开头。
-
r+:以读写方式打开一个文件。文件指针将会放在文件的开头。
-
rb+:以二进制读写方式打开一个文件。文件指针将会放在文件的开头。
-
w:以写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
-
wb:以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
-
w+:以读写方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
-
wb+:以二进制读写格式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
-
a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
-
ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
-
a+:以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,则创建新文件来读写。
-
ab+:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。如果该文件不存在,则创建新文件用于读写。
4. 简化写法
另外,文件写入还有一种简写方法,那就是使用 with as 语法。在 with 控制块结束时,文件会自动关闭,所以就不需要再调用 close 方法了。这种保存方式可以简写如下:
with open('explore.txt', 'a', encoding='utf-8') as file:file.write('\n'.join([question, author, answer]))file.write('\n' + '=' * 50 + '\n')
如果想保存时将原文清空,那么可以将第二个参数改写为 w,代码如下:
with open('explore.txt', 'w', encoding='utf-8') as file:file.write('\n'.join([question, author, answer]))file.write('\n' + '=' * 50 + '\n')
上面便是利用 Python 将结果保存为 TXT 文件的方法,这种方法简单易用,操作高效,是一种最基本的保存数据的方法。
JSON 文件存储
JSON,全称为 JavaScript Object Notation, 也就是 JavaScript 对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。本节中,我们就来了解如何利用 Python 保存数据到 JSON 文件。
1. 对象和数组
在 JavaScript 语言中,一切都是对象。因此,任何支持的类型都可以通过 JSON 来表示,例如字符串、数字、对象、数组等,但是对象和数组是比较特殊且常用的两种类型,下面简要介绍一下它们。
对象:它在 JavaScript 中是使用花括号 {} 包裹起来的内容,数据结构为 {key1:value1, key2:value2, ...} 的键值对结构。在面向对象的语言中,key 为对象的属性,value 为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。
数组:数组在 JavaScript 中是方括号 [] 包裹起来的内容,数据结构为 ["java", "javascript", "vb", ...] 的索引结构。在 JavaScript 中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。
所以,一个 JSON 对象可以写为如下形式:
[{"name": "Bob","gender": "male","birthday": "1992-10-18"
}, {"name": "Selina","gender": "female","birthday": "1995-10-18"
}]
由中括号包围的就相当于列表类型,列表中的每个元素可以是任意类型,这个示例中它是字典类型,由大括号包围。
JSON 可以由以上两种形式自由组合而成,可以无限次嵌套,结构清晰,是数据交换的极佳方式。
2. 读取 JSON
Python 为我们提供了简单易用的 JSON 库来实现 JSON 文件的读写操作,我们可以调用 JSON 库的 loads 方法将 JSON 文本字符串转为 JSON 对象,可以通过 dumps() 方法将 JSON 对象转为文本字符串。
例如,这里有一段 JSON 形式的字符串,它是 str 类型,我们用 Python 将其转换为可操作的数据结构,如列表或字典:
import json
str = '''
[{"name": "Bob","gender": "male","birthday": "1992-10-18"
}, {"name": "Selina","gender": "female","birthday": "1995-10-18"
}]
'''
print(type(str))
data = json.loads(str)
print(data)
print(type(data))
运行结果如下:
<class'str'>
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
<class 'list'>
这里使用 loads 方法将字符串转为 JSON 对象。由于最外层是中括号,所以最终的类型是列表类型。
这样一来,我们就可以用索引来获取对应的内容了。例如,如果想取第一个元素里的 name 属性,就可以使用如下方式:
data[0]['name']
data[0].get('name')
得到的结果都是:
Bob
通过中括号加 0 索引,可以得到第一个字典元素,然后再调用其键名即可得到相应的键值。获取键值时有两种方式,一种是中括号加键名,另一种是通过 get 方法传入键名。这里推荐使用 get 方法,这样如果键名不存在,则不会报错,会返回 None。另外,get 方法还可以传入第二个参数(即默认值),示例如下:
data[0].get('age')
data[0].get('age', 25)
运行结果如下:
None 25
这里我们尝试获取年龄 age,其实在原字典中该键名不存在,此时默认会返回 None。如果传入第二个参数(即默认值),那么在不存在的情况下返回该默认值。
值得注意的是,JSON 的数据需要用双引号来包围,不能使用单引号。例如,若使用如下形式表示,则会出现错误:
import json
str = '''
[{'name': 'Bob','gender': 'male','birthday': '1992-10-18'
}]
'''
data = json.loads(str)
运行结果如下:
json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 3 column 5 (char 8)
这里会出现 JSON 解析错误的提示。这是因为这里数据用单引号来包围,请千万注意 JSON 字符串的表示需要用双引号,否则 loads 方法会解析失败。
如果从 JSON 文本中读取内容,例如这里有一个 data.json 文本文件,其内容是刚才定义的 JSON 字符串,我们可以先将文本文件内容读出,然后再利用 loads 方法转化:
import json
with open('data.json', 'r') as file:str = file.read()data = json.loads(str)print(data)
运行结果如下:
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
3. 输出 JSON
另外,我们还可以调用 dumps 方法将 JSON 对象转化为字符串。例如,将上例中的列表重新写入文本:
import json
data = [{'name': 'Bob','gender': 'male','birthday': '1992-10-18'
}]
with open('data.json', 'w') as file:file.write(json.dumps(data))
利用 dumps 方法,我们可以将 JSON 对象转为字符串,然后再调用文件的 write 方法写入文本,结果如图所示。

另外,如果想保存 JSON 的格式,可以再加一个参数 indent,代表缩进字符个数。示例如下:
with open('data.json', 'w') as file:file.write(json.dumps(data, indent=2))
此时写入结果如图所示。
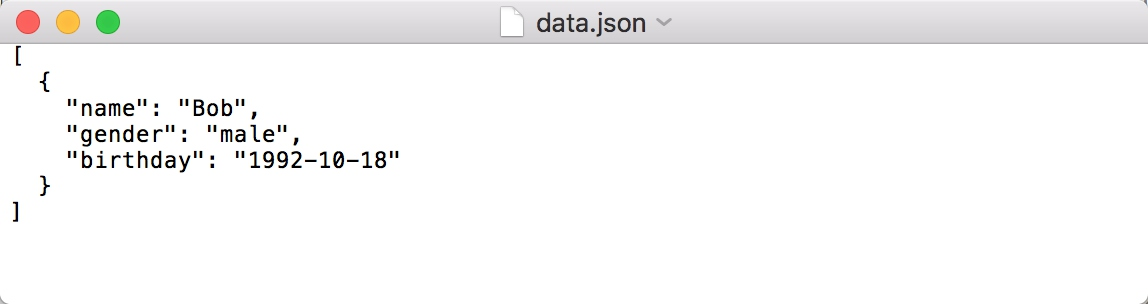
这样得到的内容会自动带缩进,格式会更加清晰。
另外,如果 JSON 中包含中文字符,会怎么样呢?例如,我们将之前的 JSON 的部分值改为中文,再用之前的方法写入到文本:
import json
data = [{'name': ' 王伟 ','gender': ' 男 ','birthday': '1992-10-18'
}]
with open('data.json', 'w') as file:file.write(json.dumps(data, indent=2))
写入结果如图所示。
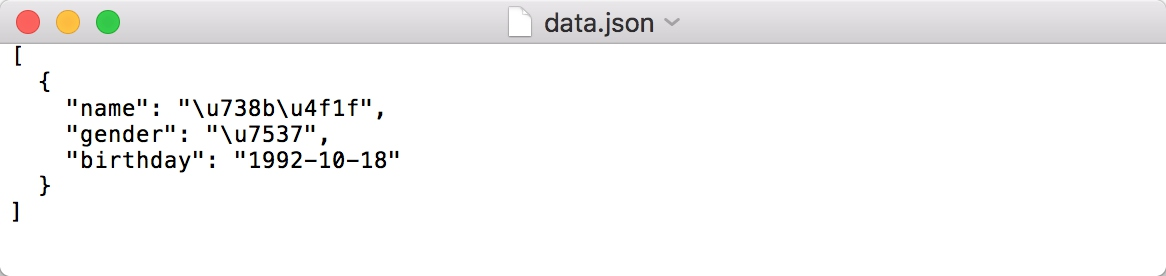
可以看到,中文字符都变成了 Unicode 字符,这并不是我们想要的结果。
为了输出中文,还需要指定参数 ensure_ascii 为 False,另外还要规定文件输出的编码:
with open('data.json', 'w', encoding='utf-8') as file:file.write(json.dumps(data, indent=2, ensure_ascii=False))
写入结果如图所示。
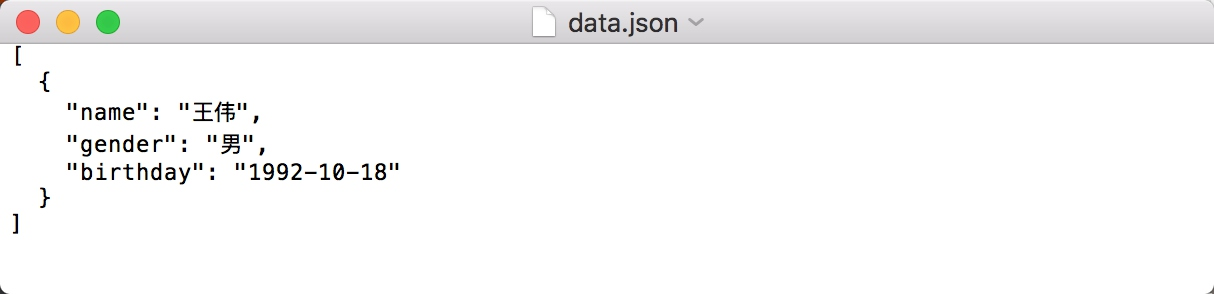
可以发现,这样就可以输出 JSON 为中文了。
本节中,我们了解了用 Python 进行 JSON 文件读写的方法,后面做数据解析时经常会用到,建议熟练掌握。
CSV 文件存储
CSV,全称为 Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。该文件是一个字符序列,可以由任意数目的记录组成,记录间以某种换行符分隔。每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。它比 Excel 文件更加简洁,XLS 文本是电子表格,它包含了文本、数值、公式和格式等内容,而 CSV 中不包含这些内容,就是特定字符分隔的纯文本,结构简单清晰。所以,有时候用 CSV 来保存数据是比较方便的。本节中,我们来讲解 Python 读取和写入 CSV 文件的过程。
1. 写入
这里先看一个最简单的例子:
import csv
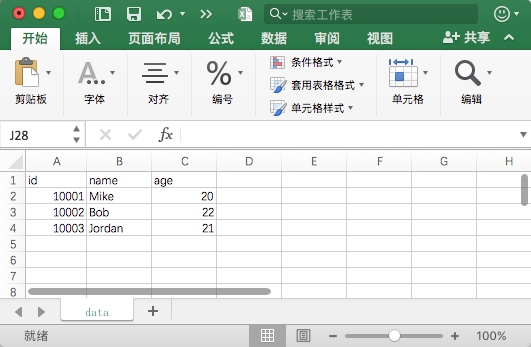
with open('data.csv', 'w') as csvfile:writer = csv.writer(csvfile)writer.writerow(['id', 'name', 'age'])writer.writerow(['10001', 'Mike', 20])writer.writerow(['10002', 'Bob', 22])writer.writerow(['10003', 'Jordan', 21])
首先,打开 data.csv 文件,然后指定打开的模式为 w(即写入),获得文件句柄,随后调用 csv 库的 writer 方法初始化写入对象,传入该句柄,然后调用 writerow 方法传入每行的数据即可完成写入。
运行结束后,会生成一个名为 data.csv 的文件,此时数据就成功写入了。直接以文本形式打开的话,其内容如下:
id,name,age 10001,Mike,20 10002,Bob,22 10003,Jordan,21
可以看到,写入的文本默认以逗号分隔,调用一次 writerow 方法即可写入一行数据。用 Excel 打开的结果如图所示。
如果想修改列与列之间的分隔符,可以传入 delimiter 参数,其代码如下:
import csv
with open('data.csv', 'w') as csvfile:writer = csv.writer(csvfile, delimiter=' ')writer.writerow(['id', 'name', 'age'])writer.writerow(['10001', 'Mike', 20])writer.writerow(['10002', 'Bob', 22])writer.writerow(['10003', 'Jordan', 21])
这里在初始化写入对象时传入 delimiter 为空格,此时输出结果的每一列就是以空格分隔了,内容如下:
id name age 10001 Mike 20 10002 Bob 22 10003 Jordan 21
另外,我们也可以调用 writerows 方法同时写入多行,此时参数就需要为二维列表,例如:
import csv
with open('data.csv', 'w') as csvfile:writer = csv.writer(csvfile)writer.writerow(['id', 'name', 'age'])writer.writerows([['10001', 'Mike', 20], ['10002', 'Bob', 22], ['10003', 'Jordan', 21]])
输出效果是相同的,内容如下:
id,name,age 10001,Mike,20 10002,Bob,22 10003,Jordan,21
但是一般情况下,爬虫爬取的都是结构化数据,我们一般会用字典来表示。在 csv 库中也提供了字典的写入方式,示例如下:
import csv
with open('data.csv', 'w') as csvfile:fieldnames = ['id', 'name', 'age']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()writer.writerow({'id': '10001', 'name': 'Mike', 'age': 20})writer.writerow({'id': '10002', 'name': 'Bob', 'age': 22})writer.writerow({'id': '10003', 'name': 'Jordan', 'age': 21})
这里先定义 3 个字段,用 fieldnames 表示,然后将其传给 DictWriter 来初始化一个字典写入对象,接着可以调用 writeheader 方法先写入头信息,然后再调用 writerow 方法传入相应字典即可。最终写入的结果是完全相同的,内容如下:
id,name,age 10001,Mike,20 10002,Bob,22 10003,Jordan,21
这样就可以完成字典到 CSV 文件的写入了。
另外,如果想追加写入的话,可以修改文件的打开模式,即将 open 函数的第二个参数改成 a,代码如下:
import csv
with open('data.csv', 'a') as csvfile: fieldnames = ['id', 'name', 'age'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writerow({'id': '10004', 'name': 'Durant', 'age': 22})
这样在上面的基础上再执行这段代码,文件内容便会变成:
id,name,age 10001,Mike,20 10002,Bob,22 10003,Jordan,21 10004,Durant,22
可见,数据被追加写入到文件中。
如果要写入中文内容的话,可能会遇到字符编码的问题,此时需要给 open 参数指定编码格式。比如,这里再写入一行包含中文的数据,代码需要改写如下:
import csv
with open('data.csv', 'a') as csvfile:fieldnames = ['id', 'name', 'age']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writerow({'id': '10004', 'name': 'Durant', 'age': 22})
这里需要给 open 函数指定编码,否则可能发生编码错误。
另外,如果接触过 pandas 等库的话,可以调用 DataFrame 对象的 to_csv 方法来将数据写入 CSV 文件中。
2. 读取
我们同样可以使用 csv 库来读取 CSV 文件。例如,将刚才写入的文件内容读取出来,相关代码如下:
import csv
with open('data.csv', 'r', encoding='utf-8') as csvfile: reader = csv.reader(csvfile) for row in reader: print(row)
运行结果如下:
['id', 'name', 'age'] ['10001', 'Mike', '20'] ['10002', 'Bob', '22'] ['10003', 'Jordan', '21'] ['10004', 'Durant', '22'] ['10005', ' 王伟 ', '22']
这里我们构造的是 Reader 对象,通过遍历输出了每行的内容,每一行都是一个列表形式。注意,如果 CSV 文件中包含中文的话,还需要指定文件编码。
另外,如果接触过 pandas 的话,可以利用 read_csv 方法将数据从 CSV 中读取出来,例如:
import pandas as pd
df = pd.read_csv('data.csv')
print(df)
运行结果如下:
id name age 0 10001 Mike 20 1 10002 Bob 22 2 10003 Jordan 21 3 10004 Durant 22 4 10005 王伟 22
在做数据分析的时候,此种方法用得比较多,也是一种比较方便地读取 CSV 文件的方法。
相关文章:
Python爬虫之文件存储#5
爬虫专栏:http://t.csdnimg.cn/WfCSx 文件存储形式多种多样,比如可以保存成 TXT 纯文本形式,也可以保存为 JSON 格式、CSV 格式等,本节就来了解一下文本文件的存储方式。 TXT 文本存储 将数据保存到 TXT 文本的操作非常简单&am…...
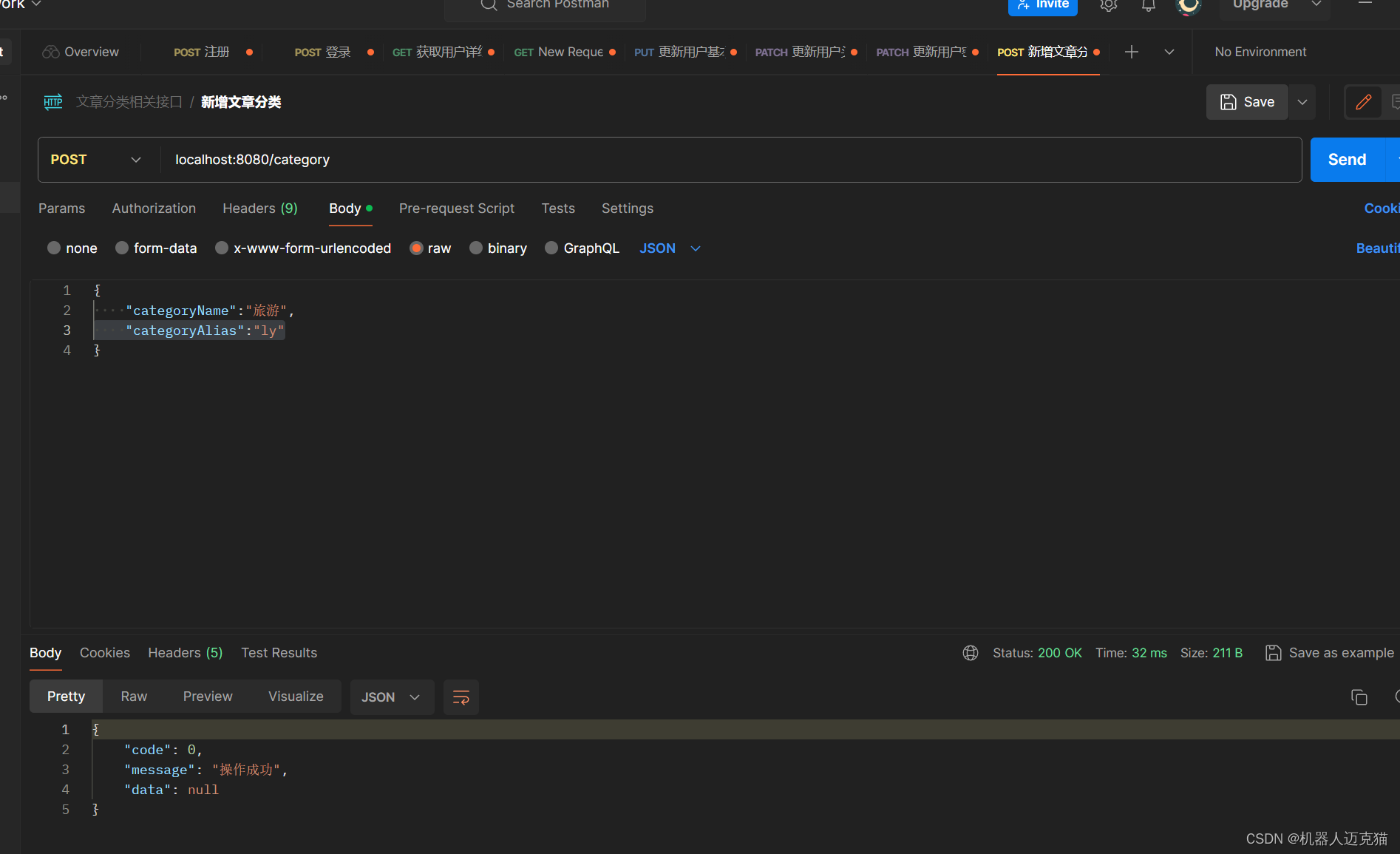
Spring Boot 笔记 012 创建接口_添加文章分类
1.1.1 实体类添加校验 package com.geji.pojo;import jakarta.validation.constraints.NotEmpty; import lombok.Data;import java.time.LocalDateTime;Data public class Category {private Integer id;//主键IDNotEmptyprivate String categoryName;//分类名称NotEmptypriva…...

Spring-面试题
一、Spring 1、Spring的优势 通过IOC、AOP简化java开发 IOC减低业务对象替换的复杂性,降低耦合AOP允许将一些通用的事务、日志进行集中处理,从而提高更好的复用性Spring生态圈低嵌入式涉及,代码污染小高度开放性,用的人多2、Spring的核心 IOC控制反转: Spring容器为我们创…...
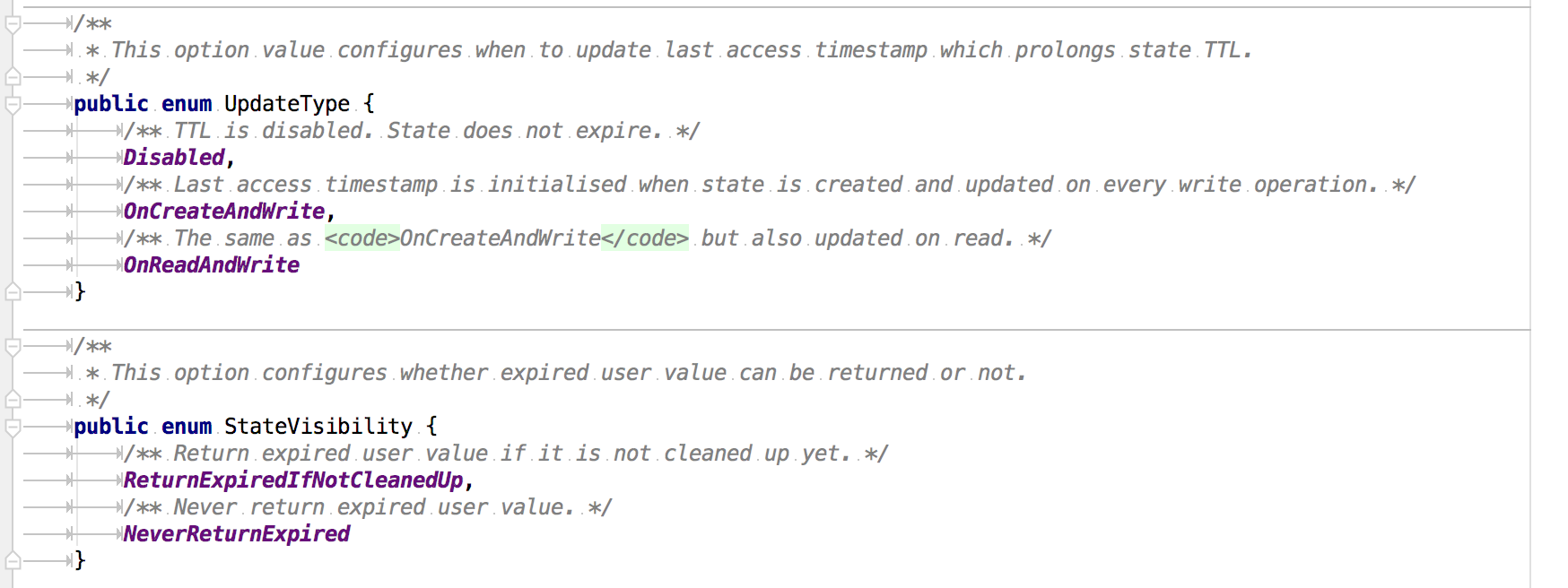
Flink理论—容错之状态
Flink理论—容错之状态 在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。 Flink 使用…...
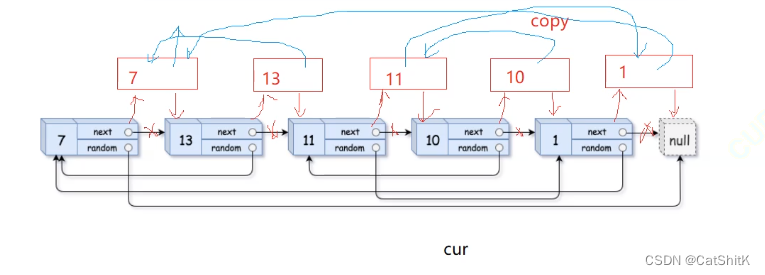
【数据结构】链表OJ面试题5《链表的深度拷贝》(题库+解析)
1.前言 前五题在这http://t.csdnimg.cn/UeggB 后三题在这http://t.csdnimg.cn/gbohQ 给定一个链表,判断链表中是否有环。http://t.csdnimg.cn/Rcdyc 给定一个链表,返回链表开始入环的第一个结点。 如果链表无环,则返回 NULLhttp://t.cs…...
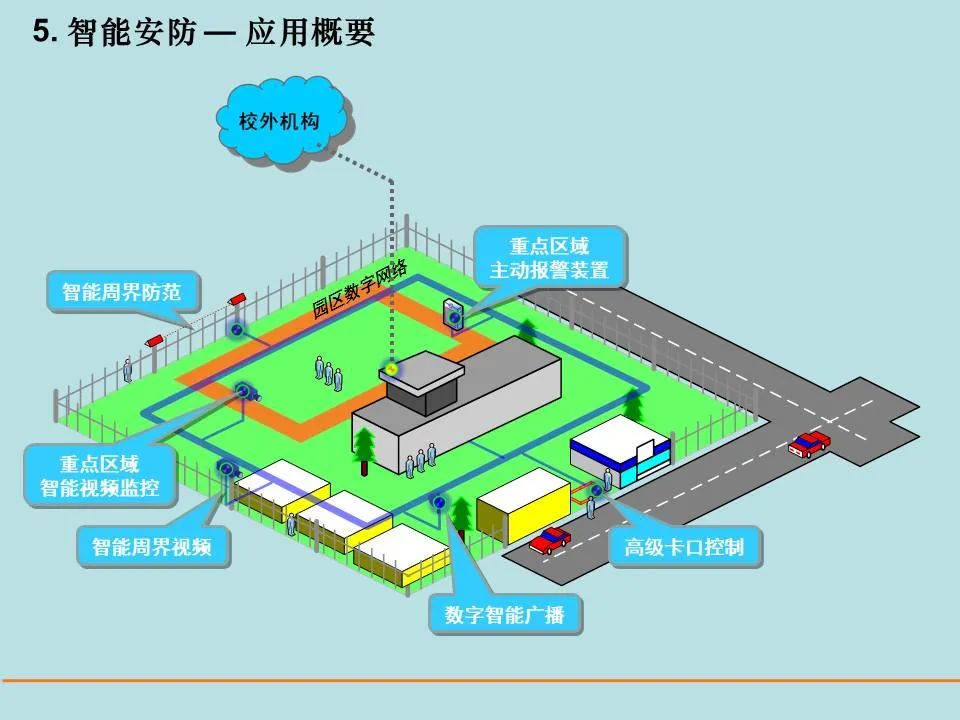
智慧校园规划建设方案
校园信息化建设呈现智能化、应用多样化发展趋势,多种技术和应用交叉渗透至校园生活的各个方面,全面的智慧校园时代已经到来。 对智慧校园的四大应用领域分析 智慧的教学 信息共享交互:建立信息发布、共享、传播与交互的公共平台 教学流程…...

003 - Hugo, 创建文章
003 - Hugo, 创建文章创建文章单个md文件md文件图片总结 文章内容Front Matter文章目录数学公式的显示KaTeXMathJax 图片 003 - Hugo, 创建文章 创建文章 单个md文件 创建文章的方式: 手动创建:在post目录下,手动创建md文件。命令创建&am…...
HCIA-HarmonyOS设备开发认证V2.0-IOT硬件子系统-GPIO
目录 一、GPIO 概述二、GPIO模块相关API三、实例四、GPIO HDF驱动开发4.1、LED驱动程序(待续...)4.2、LED驱动配置(待续...) 坚持就有收获 轻量系统设备通常需要进行外设控制,例如温湿度数据的采集、灯开关的控制,因此在完成内核开发后,需要进…...

《Java 简易速速上手小册》第7章:Java 网络编程(2024 最新版)
文章目录 7.1 网络基础和 Java 中的网络 - 揭开神秘的面纱7.1.1 基础知识7.1.2 重点案例:实现一个简单的聊天程序7.1.3 拓展案例 1:使用 UDP 进行消息广播7.1.4 拓展案例 2:建立一个简单的 Web 服务器 7.2 创建客户端和服务器 - 构建沟通的桥…...

用keras对电影评论进行情感分析
文章目录 下载IMDb数据读取IMDb数据建立分词器将评论数据转化为数字列表让转换后的数字长度相同加入嵌入层建立多层感知机模型加入平坦层加入隐藏层加入输出层查看模型摘要 训练模型评估模型准确率进行预测查看测试数据预测结果完整函数用RNN模型进行IMDb情感分析用LSTM模型进行…...
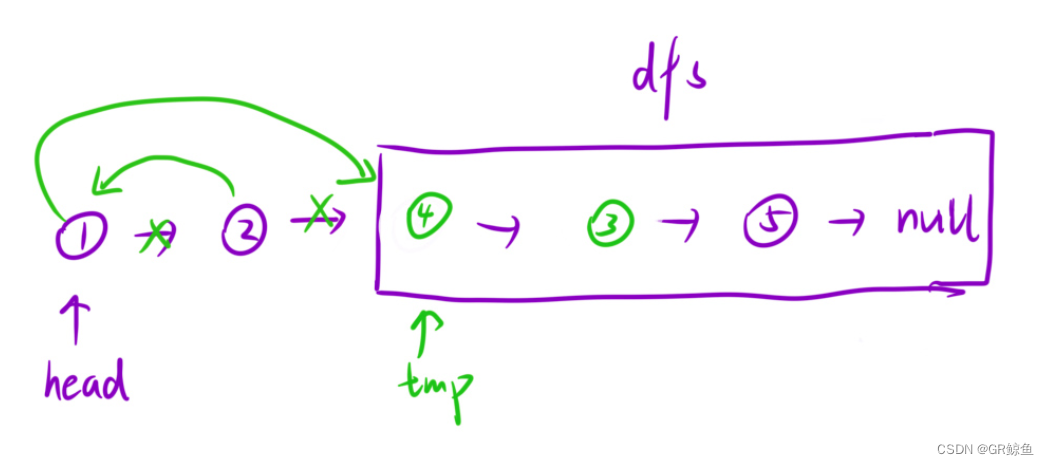
每日OJ题_算法_递归④力扣24. 两两交换链表中的节点
目录 ④力扣24. 两两交换链表中的节点 解析代码 ④力扣24. 两两交换链表中的节点 24. 两两交换链表中的节点 难度 中等 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即…...

110 C++ decltype含义,decltype 主要用途
一,decltype 含义和举例 decltype有啥返回啥,auto则不一样,auto可能会舍弃一些东西。 decltype 是 C11提出的说明符。主要作用是:返回操作数的数据类型。 decltype 是用来推导类型,decltype对于一个给定的 变量名或…...
)
PYTHON 120道题目详解(85-87)
85.Python中如何使用enumerate()函数获取序列的索引和值? enumerate()函数是Python的内置函数,它可以将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。 以下是一个…...
【Linux】Linux编译器-gcc/g++ Linux项目自动化构建工具-make/Makefile
目录 Linux编译器-gcc/g使用 1.背景知识 Linux中头文件的目录在 Linux 库 条件编译的典型应用 2.gcc如何完成 动态库 vs 静态库 debug && release Linux项目自动化构建工具-make/Makefile 背景 用法 特殊符号 Linux编译器-gcc/g使用 1.背景知识 预处理&am…...

sqlserver 子查询 =,in ,any,some,all的用法
在 SQL Server 中,子查询常用于嵌套在主查询中的子句中,以便根据子查询的结果集来过滤主查询的结果,或者作为主查询的一部分来计算结果。 以下是 、IN、ANY、SOME 和 ALL 运算符在子查询中的用法示例: 使用 运算符进行子查询&a…...

基于MapVGL的地理信息三维度数据增长可视化
写在前面 工作中接触,简单整理博文内容为 基于MapVGL的地理信息维度数据增长可视化 Demo理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都…...

天锐绿盾|防泄密系统|计算机文件数据\资料安全管理软件
“天锐绿盾”似乎是一款专注于防泄密和计算机文件数据/资料安全管理的软件。在信息安全日益受到重视的今天,这样的软件对于保护企业的核心数据资产和防止敏感信息泄露至关重要。 通用地址:www.drhchina.com 防泄密系统的主要功能通常包括: 文…...

leetcode刷题(罗马数字转数字)
1.题目描述 2.解题思路 这时候已经给出了字母对应的数字,我们只需要声明一个字典,将罗马数字和数字之间的对应关系声明即可。其中可能涉及到会出现两个连续的罗马字母代表一个数字,这时候我们需要判断遍历的字符和将要遍历的下一个字符是否存…...

什么是NAT网关?联通云NAT网关有什么优势
在当今云计算时代,网络安全和连接性是企业发展的关键因素之一。NAT网关(Network Address Translation Gateway)是一种网络设备,它可以在私有网络和公共网络之间进行地址转换,从而使得内部网络中的设备能够与外部网络进…...
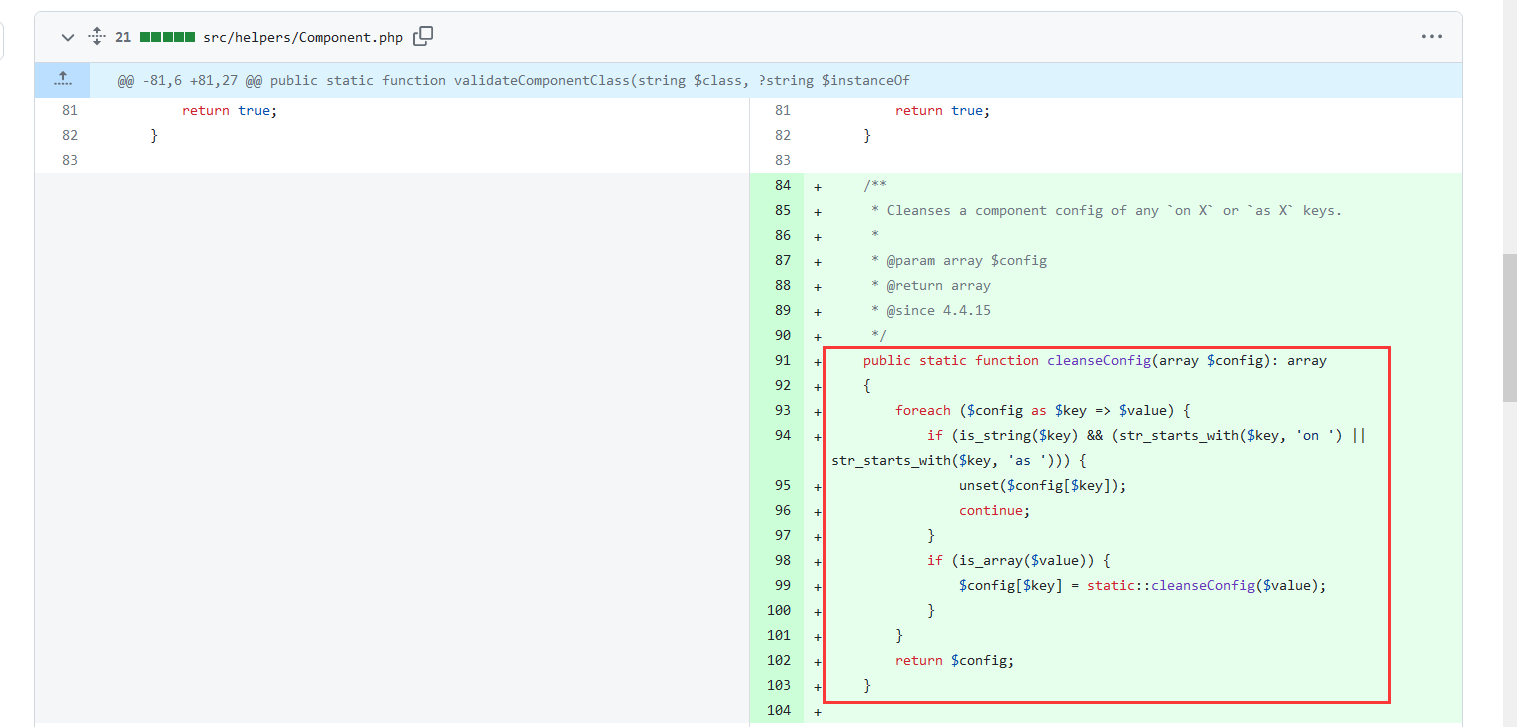
CVE-2023-41892 漏洞复现
CVE-2023-41892 开题,是一个RCE Thanks for installing Craft CMS! You’re looking at the index.twig template file located in your templates/ folder. Once you’re ready to start building out your site’s front end, you can replace this with someth…...

手把手教你用AsyncOpenAI库,为自部署的Llama 3模型打造一个高速问答接口
基于AsyncOpenAI与Llama 3构建高并发问答接口的工程实践 在当今AI应用开发领域,如何将开源大模型高效地集成到生产环境中,是许多开发者面临的挑战。特别是当我们需要处理大量并发请求时,传统的同步调用方式往往成为性能瓶颈。本文将深入探讨…...

自动化测试的未来:AI测试会取代人工测试吗
一、AI浪潮下的测试行业变局在软件测试行业的发展历程中,自动化测试的出现曾被视为提升效率的关键转折点,而如今,AI技术的深度介入,正在将这场变革推向新的高度。从AI自动生成测试用例,到智能预测高风险代码模块&#…...

10分钟掌握Dism++:Windows系统优化终极完整指南
10分钟掌握Dism:Windows系统优化终极完整指南 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language 还在为Windows系统越来越慢而烦恼吗?磁盘空…...

嵌入式学习的第八天
字符指针常见错误 核心:字符串常量存只读内存,不可修改! #include <stdio.h> int main() {// 错误写法:指针指向字符串常量(只读),不能修改内容char *p "hello"; // *(p0) e…...

Perplexity考试信息失效预警:为什么你查的“最新大纲”已滞后11.7天?——基于237份版本哈希比对的紧急修正指南
更多请点击: https://intelliparadigm.com 第一章:Perplexity考试信息失效的严峻现实 Perplexity 作为一款依赖实时语义检索与动态知识图谱的 AI 工具,其内置的“考试信息”模块(如模拟题库、认证大纲、考点索引等)并…...

Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作
Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作 上个月老板丢给我一个任务:把现有的Electron应用搬到鸿蒙PC上。我花了两天把代码跑通了,build了一版安装包,一看体积——180MB。老板看了一眼࿰…...
)
别再手动复制粘贴了!用poi-tl + Spring Boot自动生成带表格、二维码的Word领料单(附完整源码)
基于poi-tl的Spring Boot领料单自动化生成实战指南 在企业日常运营中,领料单这类标准化文档的生成往往占据大量重复性工作时间。传统的手工复制粘贴不仅效率低下,还容易出错。本文将介绍如何利用poi-tl这一强大的Word模板引擎,结合Spring Bo…...

从B类到连续类:一篇讲透功放效率与带宽的“鱼与熊掌”兼得史
射频功率放大器的进化论:从B类到连续类的带宽革命 在无线通信技术狂飙突进的三十年里,有个看似矛盾的命题始终困扰着工程师:如何让功率放大器同时"吃得少"(高效率)和"干得多"(宽带宽&…...

Autoswagger与Intruder生态集成:企业级API安全解决方案的完整指南
Autoswagger与Intruder生态集成:企业级API安全解决方案的完整指南 【免费下载链接】autoswagger Autoswagger by Intruder - detect API auth weaknesses 项目地址: https://gitcode.com/gh_mirrors/au/autoswagger 在当今API驱动的数字世界中,AP…...

从鼠类到人体:汉坦病毒的全球威胁与科研突破
2026年5月17日,加拿大正式确诊一名“洪迪厄斯”号邮轮乘员感染汉坦病毒。结合世界卫生组织(WHO)的通报,疫情已陆续造成9人感染并出现3例死亡。这引起广泛的关注和担忧。汉坦病毒究竟是哪类病毒呢?感染力强吗࿱…...