用keras对电影评论进行情感分析
文章目录
- 下载IMDb数据
- 读取IMDb数据
- 建立分词器
- 将评论数据转化为数字列表
- 让转换后的数字长度相同
- 加入嵌入层
- 建立多层感知机模型
- 加入平坦层
- 加入隐藏层
- 加入输出层
- 查看模型摘要
- 训练模型
- 评估模型准确率
- 进行预测
- 查看测试数据预测结果
- 完整函数
- 用RNN模型进行IMDb情感分析
- 用LSTM模型进行IMDb情感分析
GITHUB地址https://github.com/fz861062923/Keras
下载IMDb数据
#下载网站http://ai.stanford.edu/~amaas/data/sentiment/
读取IMDb数据
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
C:\Users\admin\AppData\Local\conda\conda\envs\tensorflow\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.from ._conv import register_converters as _register_converters
Using TensorFlow backend.
#因为数据也是从网络上爬取的,所以还需要用正则表达式去除HTML标签
import re
def remove_html(text):r=re.compile(r'<[^>]+>')return r.sub('',text)
#观察IMDB文件目录结构,用函数进行读取
import os
def read_file(filetype):path='./aclImdb/'file_list=[]positive=path+filetype+'/pos/'for f in os.listdir(positive):file_list+=[positive+f]negative=path+filetype+'/neg/'for f in os.listdir(negative):file_list+=[negative+f]print('filetype:',filetype,'file_length:',len(file_list))label=([1]*12500+[0]*12500)#train数据和test数据中positive都是12500,negative都是12500text=[]for f_ in file_list:with open(f_,encoding='utf8') as f:text+=[remove_html(''.join(f.readlines()))]return label,text
#用x表示label,y表示text里面的内容
x_train,y_train=read_file('train')
filetype: train file_length: 25000
x_test,y_test=read_file('test')
filetype: test file_length: 25000
y_train[0]
'Bromwell High is a cartoon comedy. It ran at the same time as some other programs about school life, such as "Teachers". My 35 years in the teaching profession lead me to believe that Bromwell High\'s satire is much closer to reality than is "Teachers". The scramble to survive financially, the insightful students who can see right through their pathetic teachers\' pomp, the pettiness of the whole situation, all remind me of the schools I knew and their students. When I saw the episode in which a student repeatedly tried to burn down the school, I immediately recalled ......... at .......... High. A classic line: INSPECTOR: I\'m here to sack one of your teachers. STUDENT: Welcome to Bromwell High. I expect that many adults of my age think that Bromwell High is far fetched. What a pity that it isn\'t!'
建立分词器
具体用法可以参看官网https://keras.io/preprocessing/text/
token=Tokenizer(num_words=2000)#建立一个有2000单词的字典
token.fit_on_texts(y_train)#读取所有的训练数据评论,按照单词在评论中出现的次数进行排序,前2000名会列入字典
#查看token读取多少文章
token.document_count
25000
将评论数据转化为数字列表
train_seq=token.texts_to_sequences(y_train)
test_seq=token.texts_to_sequences(y_test)
print(y_train[0])
Bromwell High is a cartoon comedy. It ran at the same time as some other programs about school life, such as "Teachers". My 35 years in the teaching profession lead me to believe that Bromwell High's satire is much closer to reality than is "Teachers". The scramble to survive financially, the insightful students who can see right through their pathetic teachers' pomp, the pettiness of the whole situation, all remind me of the schools I knew and their students. When I saw the episode in which a student repeatedly tried to burn down the school, I immediately recalled ......... at .......... High. A classic line: INSPECTOR: I'm here to sack one of your teachers. STUDENT: Welcome to Bromwell High. I expect that many adults of my age think that Bromwell High is far fetched. What a pity that it isn't!
print(train_seq[0])
[308, 6, 3, 1068, 208, 8, 29, 1, 168, 54, 13, 45, 81, 40, 391, 109, 137, 13, 57, 149, 7, 1, 481, 68, 5, 260, 11, 6, 72, 5, 631, 70, 6, 1, 5, 1, 1530, 33, 66, 63, 204, 139, 64, 1229, 1, 4, 1, 222, 899, 28, 68, 4, 1, 9, 693, 2, 64, 1530, 50, 9, 215, 1, 386, 7, 59, 3, 1470, 798, 5, 176, 1, 391, 9, 1235, 29, 308, 3, 352, 343, 142, 129, 5, 27, 4, 125, 1470, 5, 308, 9, 532, 11, 107, 1466, 4, 57, 554, 100, 11, 308, 6, 226, 47, 3, 11, 8, 214]
让转换后的数字长度相同
#截长补短,让每一个数字列表长度都为100
_train=sequence.pad_sequences(train_seq,maxlen=100)
_test=sequence.pad_sequences(test_seq,maxlen=100)
print(train_seq[0])
[308, 6, 3, 1068, 208, 8, 29, 1, 168, 54, 13, 45, 81, 40, 391, 109, 137, 13, 57, 149, 7, 1, 481, 68, 5, 260, 11, 6, 72, 5, 631, 70, 6, 1, 5, 1, 1530, 33, 66, 63, 204, 139, 64, 1229, 1, 4, 1, 222, 899, 28, 68, 4, 1, 9, 693, 2, 64, 1530, 50, 9, 215, 1, 386, 7, 59, 3, 1470, 798, 5, 176, 1, 391, 9, 1235, 29, 308, 3, 352, 343, 142, 129, 5, 27, 4, 125, 1470, 5, 308, 9, 532, 11, 107, 1466, 4, 57, 554, 100, 11, 308, 6, 226, 47, 3, 11, 8, 214]
print(_train[0])
[ 29 1 168 54 13 45 81 40 391 109 137 13 57 1497 1 481 68 5 260 11 6 72 5 631 70 6 15 1 1530 33 66 63 204 139 64 1229 1 4 1 222899 28 68 4 1 9 693 2 64 1530 50 9 215 1386 7 59 3 1470 798 5 176 1 391 9 1235 29 3083 352 343 142 129 5 27 4 125 1470 5 308 9 53211 107 1466 4 57 554 100 11 308 6 226 47 3 118 214]
_train.shape
(25000, 100)
加入嵌入层
将数字列表转化为向量列表(为什么转化,建议大家都思考一哈)
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation,Flatten
from keras.layers.embeddings import Embedding
model=Sequential()
model.add(Embedding(output_dim=32,#将数字列表转换为32维的向量input_dim=2000,#输入数据的维度是2000,因为之前建立的字典有2000个单词input_length=100))#数字列表的长度为100
model.add(Dropout(0.25))
建立多层感知机模型
加入平坦层
model.add(Flatten())
加入隐藏层
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.35))
加入输出层
model.add(Dense(units=1,#输出层只有一个神经元,输出1表示正面评价,输出0表示负面评价activation='sigmoid'))
查看模型摘要
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 32) 64000
_________________________________________________________________
dropout_1 (Dropout) (None, 100, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 3200) 0
_________________________________________________________________
dense_1 (Dense) (None, 256) 819456
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 257
=================================================================
Total params: 883,713
Trainable params: 883,713
Non-trainable params: 0
_________________________________________________________________
训练模型
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
train_history=model.fit(_train,x_train,batch_size=100,epochs=10,verbose=2,validation_split=0.2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/10- 21s - loss: 0.4851 - acc: 0.7521 - val_loss: 0.4491 - val_acc: 0.7894
Epoch 2/10- 20s - loss: 0.2817 - acc: 0.8829 - val_loss: 0.6735 - val_acc: 0.6892
Epoch 3/10- 13s - loss: 0.1901 - acc: 0.9285 - val_loss: 0.5907 - val_acc: 0.7632
Epoch 4/10- 12s - loss: 0.1066 - acc: 0.9622 - val_loss: 0.7522 - val_acc: 0.7528
Epoch 5/10- 13s - loss: 0.0681 - acc: 0.9765 - val_loss: 0.9863 - val_acc: 0.7404
Epoch 6/10- 13s - loss: 0.0486 - acc: 0.9827 - val_loss: 1.0818 - val_acc: 0.7506
Epoch 7/10- 14s - loss: 0.0380 - acc: 0.9859 - val_loss: 0.9823 - val_acc: 0.7780
Epoch 8/10- 17s - loss: 0.0360 - acc: 0.9860 - val_loss: 1.1297 - val_acc: 0.7634
Epoch 9/10- 13s - loss: 0.0321 - acc: 0.9891 - val_loss: 1.2459 - val_acc: 0.7480
Epoch 10/10- 14s - loss: 0.0281 - acc: 0.9899 - val_loss: 1.4111 - val_acc: 0.7304
评估模型准确率
scores=model.evaluate(_test,x_test)#第一个参数为feature,第二个参数为label
25000/25000 [==============================] - 4s 148us/step
scores[1]
0.80972
进行预测
predict=model.predict_classes(_test)
predict[:10]
array([[1],[0],[1],[1],[1],[1],[1],[1],[1],[1]])
#转换成一维数组
predict=predict.reshape(-1)
predict[:10]
array([1, 0, 1, 1, 1, 1, 1, 1, 1, 1])
查看测试数据预测结果
_dict={1:'正面的评论',0:'负面的评论'}
def display(i):print(y_test[i])print('label真实值为:',_dict[x_test[i]],'预测结果为:',_dict[predict[i]])
display(0)
I went and saw this movie last night after being coaxed to by a few friends of mine. I'll admit that I was reluctant to see it because from what I knew of Ashton Kutcher he was only able to do comedy. I was wrong. Kutcher played the character of Jake Fischer very well, and Kevin Costner played Ben Randall with such professionalism. The sign of a good movie is that it can toy with our emotions. This one did exactly that. The entire theater (which was sold out) was overcome by laughter during the first half of the movie, and were moved to tears during the second half. While exiting the theater I not only saw many women in tears, but many full grown men as well, trying desperately not to let anyone see them crying. This movie was great, and I suggest that you go see it before you judge.
label真实值为: 正面的评论 预测结果为: 正面的评论
完整函数
def review(input_text):input_seq=token.texts_to_sequences([input_text])pad_input_seq=sequence.pad_sequences(input_seq,maxlen=100)predict_result=model.predict_classes(pad_input_seq)print(_dict[predict_result[0][0]])
#IMDB上面找的一段评论,进行预测
review('''
Going into this movie, I had low expectations. I'd seen poor reviews, and I also kind of hate the idea of remaking animated films for no reason other than to make them live action, as if that's supposed to make them better some how. This movie pleasantly surprised me!Beauty and the Beast is a fun, charming movie, that is a blast in many ways. The film very easy on the eyes! Every shot is colourful and beautifully crafted. The acting is also excellent. Dan Stevens is excellent. You can see him if you look closely at The Beast, but not so clearly that it pulls you out of the film. His performance is suitably over the top in anger, but also very charming. Emma Watson was fine, but to be honest, she was basically just playing Hermione, and I didn't get much of a character from her. She likes books, and she's feisty. That's basically all I got. For me, the one saving grace for her character, is you can see how much fun Emma Watson is having. I've heard interviews in which she's expressed how much she's always loved Belle as a character, and it shows.The stand out for me was Lumieré, voiced by Ewan McGregor. He was hilarious, and over the top, and always fun! He lit up the screen (no pun intended) every time he showed up!The only real gripes I have with the film are some questionable CGI with the Wolves and with a couple of The Beast's scenes, and some pacing issues. The film flows really well, to such an extent that in some scenes, the camera will dolly away from the character it's focusing on, and will pan across the countryside, and track to another, far away, with out cutting. This works really well, but a couple times, the film will just fade to black, and it's quite jarring. It happens like 3 or 4 times, but it's really noticeable, and took me out of the experience. Also, they added some stuff to the story that I don't want to spoil, but I don't think it worked on any level, story wise, or logically.Overall, it's a fun movie! I would recommend it to any fan of the original, but those who didn't like the animated classic, or who hate musicals might be better off staying aw''')
正面的评论
review('''
This is a horrible Disney piece of crap full of completely lame singsongs, a script so wrong it is an insult to other scripts to even call it a script. The only way I could enjoy this is after eating two complete space cakes, and even then I would prefer analysing our wallpaper!''')
负面的评论
- 到这里用在keras中用多层感知机进行情感预测就结束了,反思实验可以改进的地方,除了神经元的个数,还可以将字典的单词个数设置大一些(原来是2000),数字列表的长度maxlen也可以设置长一些
用RNN模型进行IMDb情感分析
- 使用RNN的好处也可以思考一哈
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import SimpleRNN
model_rnn=Sequential()
model_rnn.add(Embedding(output_dim=32,input_dim=2000,input_length=100))
model_rnn.add(Dropout(0.25))
model_rnn.add(SimpleRNN(units=16))#RNN层有16个神经元
model_rnn.add(Dense(units=256,activation='relu'))
model_rnn.add(Dropout(0.25))
model_rnn.add(Dense(units=1,activation='sigmoid'))
model_rnn.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 32) 64000
_________________________________________________________________
dropout_1 (Dropout) (None, 100, 32) 0
_________________________________________________________________
simple_rnn_1 (SimpleRNN) (None, 16) 784
_________________________________________________________________
dense_1 (Dense) (None, 256) 4352
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 257
=================================================================
Total params: 69,393
Trainable params: 69,393
Non-trainable params: 0
_________________________________________________________________
model_rnn.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
train_history=model_rnn.fit(_train,x_train,batch_size=100,epochs=10,verbose=2,validation_split=0.2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/10- 13s - loss: 0.5200 - acc: 0.7319 - val_loss: 0.6095 - val_acc: 0.6960
Epoch 2/10- 12s - loss: 0.3485 - acc: 0.8506 - val_loss: 0.4994 - val_acc: 0.7766
Epoch 3/10- 12s - loss: 0.3109 - acc: 0.8710 - val_loss: 0.5842 - val_acc: 0.7598
Epoch 4/10- 13s - loss: 0.2874 - acc: 0.8833 - val_loss: 0.4420 - val_acc: 0.8136
Epoch 5/10- 12s - loss: 0.2649 - acc: 0.8929 - val_loss: 0.6818 - val_acc: 0.7270
Epoch 6/10- 14s - loss: 0.2402 - acc: 0.9035 - val_loss: 0.5634 - val_acc: 0.7984
Epoch 7/10- 16s - loss: 0.2084 - acc: 0.9190 - val_loss: 0.6392 - val_acc: 0.7694
Epoch 8/10- 16s - loss: 0.1855 - acc: 0.9289 - val_loss: 0.6388 - val_acc: 0.7650
Epoch 9/10- 14s - loss: 0.1641 - acc: 0.9367 - val_loss: 0.8356 - val_acc: 0.7592
Epoch 10/10- 19s - loss: 0.1430 - acc: 0.9451 - val_loss: 0.7365 - val_acc: 0.7766
scores=model_rnn.evaluate(_test,x_test)
25000/25000 [==============================] - 14s 567us/step
scores[1]#提高了大概两个百分点
0.82084
用LSTM模型进行IMDb情感分析
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
model_lstm=Sequential()
model_lstm.add(Embedding(output_dim=32,input_dim=2000,input_length=100))
model_lstm.add(Dropout(0.25))
model_lstm.add(LSTM(32))
model_lstm.add(Dense(units=256,activation='relu'))
model_lstm.add(Dropout(0.25))
model_lstm.add(Dense(units=1,activation='sigmoid'))
model_lstm.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 100, 32) 64000
_________________________________________________________________
dropout_3 (Dropout) (None, 100, 32) 0
_________________________________________________________________
lstm_1 (LSTM) (None, 32) 8320
_________________________________________________________________
dense_3 (Dense) (None, 256) 8448
_________________________________________________________________
dropout_4 (Dropout) (None, 256) 0
_________________________________________________________________
dense_4 (Dense) (None, 1) 257
=================================================================
Total params: 81,025
Trainable params: 81,025
Non-trainable params: 0
_________________________________________________________________
scores=model_rnn.evaluate(_test,x_test)
25000/25000 [==============================] - 13s 522us/step
scores[1]
0.82084
可以看出和RMNN差不多,这可能因为事评论数据的时间间隔不大,不能充分体现LSTM的优越性
相关文章:

用keras对电影评论进行情感分析
文章目录 下载IMDb数据读取IMDb数据建立分词器将评论数据转化为数字列表让转换后的数字长度相同加入嵌入层建立多层感知机模型加入平坦层加入隐藏层加入输出层查看模型摘要 训练模型评估模型准确率进行预测查看测试数据预测结果完整函数用RNN模型进行IMDb情感分析用LSTM模型进行…...
每日OJ题_算法_递归④力扣24. 两两交换链表中的节点
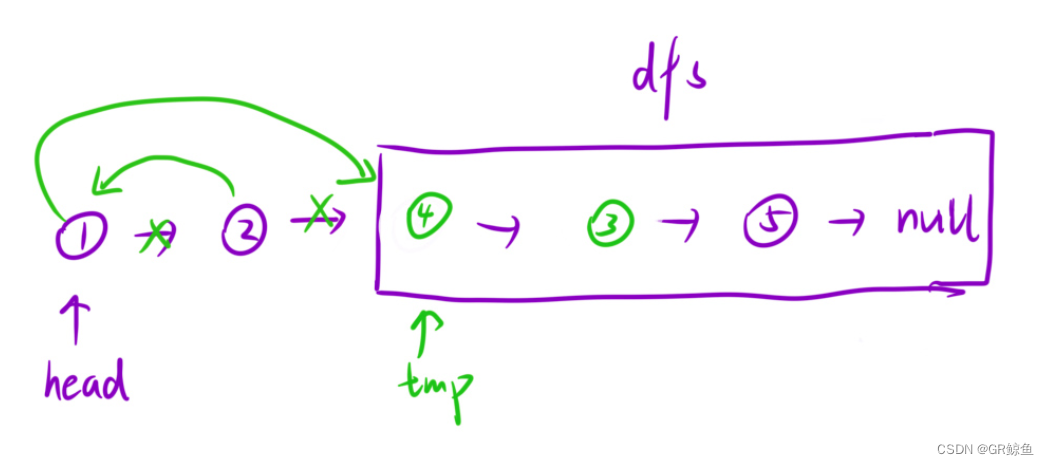
目录 ④力扣24. 两两交换链表中的节点 解析代码 ④力扣24. 两两交换链表中的节点 24. 两两交换链表中的节点 难度 中等 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即…...

110 C++ decltype含义,decltype 主要用途
一,decltype 含义和举例 decltype有啥返回啥,auto则不一样,auto可能会舍弃一些东西。 decltype 是 C11提出的说明符。主要作用是:返回操作数的数据类型。 decltype 是用来推导类型,decltype对于一个给定的 变量名或…...
)
PYTHON 120道题目详解(85-87)
85.Python中如何使用enumerate()函数获取序列的索引和值? enumerate()函数是Python的内置函数,它可以将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。 以下是一个…...
【Linux】Linux编译器-gcc/g++ Linux项目自动化构建工具-make/Makefile
目录 Linux编译器-gcc/g使用 1.背景知识 Linux中头文件的目录在 Linux 库 条件编译的典型应用 2.gcc如何完成 动态库 vs 静态库 debug && release Linux项目自动化构建工具-make/Makefile 背景 用法 特殊符号 Linux编译器-gcc/g使用 1.背景知识 预处理&am…...

sqlserver 子查询 =,in ,any,some,all的用法
在 SQL Server 中,子查询常用于嵌套在主查询中的子句中,以便根据子查询的结果集来过滤主查询的结果,或者作为主查询的一部分来计算结果。 以下是 、IN、ANY、SOME 和 ALL 运算符在子查询中的用法示例: 使用 运算符进行子查询&a…...

基于MapVGL的地理信息三维度数据增长可视化
写在前面 工作中接触,简单整理博文内容为 基于MapVGL的地理信息维度数据增长可视化 Demo理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都…...

天锐绿盾|防泄密系统|计算机文件数据\资料安全管理软件
“天锐绿盾”似乎是一款专注于防泄密和计算机文件数据/资料安全管理的软件。在信息安全日益受到重视的今天,这样的软件对于保护企业的核心数据资产和防止敏感信息泄露至关重要。 通用地址:www.drhchina.com 防泄密系统的主要功能通常包括: 文…...

leetcode刷题(罗马数字转数字)
1.题目描述 2.解题思路 这时候已经给出了字母对应的数字,我们只需要声明一个字典,将罗马数字和数字之间的对应关系声明即可。其中可能涉及到会出现两个连续的罗马字母代表一个数字,这时候我们需要判断遍历的字符和将要遍历的下一个字符是否存…...

什么是NAT网关?联通云NAT网关有什么优势
在当今云计算时代,网络安全和连接性是企业发展的关键因素之一。NAT网关(Network Address Translation Gateway)是一种网络设备,它可以在私有网络和公共网络之间进行地址转换,从而使得内部网络中的设备能够与外部网络进…...
CVE-2023-41892 漏洞复现
CVE-2023-41892 开题,是一个RCE Thanks for installing Craft CMS! You’re looking at the index.twig template file located in your templates/ folder. Once you’re ready to start building out your site’s front end, you can replace this with someth…...
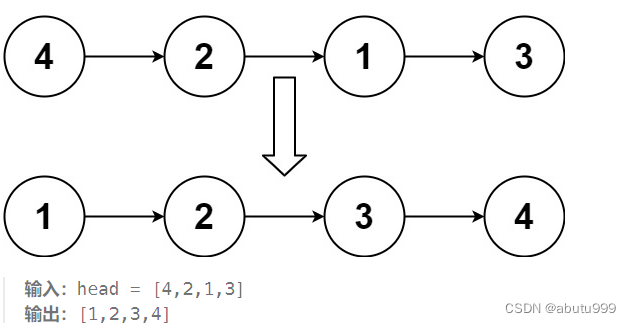
【每日一题】06 排序链表
问题描述 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 求解 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* sortList(struct ListNode* head) {struct…...
【精品】关于枚举的高级用法
枚举父接口 public interface BaseEnum {Integer getCode();String getLabel();/*** 根据值获取枚举** param code* param clazz* return*/static <E extends Enum<E> & BaseEnum> E getEnumByCode(Integer code, Class<E> clazz) {Objects.requireNonN…...
Vue2学习第一天
Vue2 学习第一天 1. 什么是 vue? Vue 是一套用于构建用户界面的渐进式框架。 2. vue 历史 vue 是在 2013 年创建的,vue3 是 2020 出现的,现在主要是用 vue2,创新公司用的是 vue3 vue 的作者是尤雨溪,vue 的搜索热度比 react…...
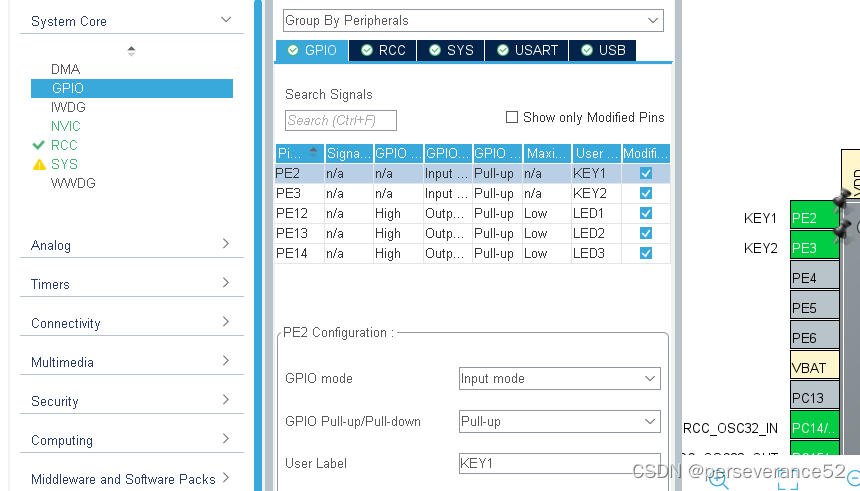
HAL STM32通过multi_button库处理按键事件
HAL STM32通过multi_button库处理按键事件 📍作者:0x1abin的multi_button库:https://github.com/0x1abin/MultiButton 📘MultiButton简介 MultiButton 是一个小巧简单易用的事件驱动型按键驱动模块,可无限量扩展按键,…...

随机过程及应用学习笔记(一)概率论(概要)
概率是随机的基础,在【概率论(概要)】这个部分中仅记录学习随机过程及应用的基本定义和结果。 前言 首先,概率论研究的基础是概率空间。概率空间由一个样本空间和一个概率测度组成,样本空间包含了所有可能的结果&…...
洛谷_P1059 [NOIP2006 普及组] 明明的随机数_python写法
这道题的关键在于去重和排序,去重可以联想到集合,那排序直接使用sort方法。 n int(input()) data set(map(int,input().split( ))) data list(data) data.sort() print(len(data)) for i in data:print(i,end )...

爆火的人工智能开源open-interpreter源码解析
今天这篇文章带大家一起来阅读下github上爆火的开源项目 open-interpreter的源代码,相当于是一个可以本地部署的openai code-interpreter。 今天这期我们透过现象看本质,一起来剖析下他的源码。 体验open-interpreter的视频地址 open-interpreter&…...
)
POM设计模式思路,详解POM:概述与介绍,POM思路梳理+代码示例(全)
概述 在UI自动化测试中,POM模式是一种设计思路,它的核心思想是方法的封装。它将方法类和页面元素进行分离,增强了代码的可维护性。值得注意的是,这种分层的设计模式,最好也是从线性代码开始,逐步将代码进行…...
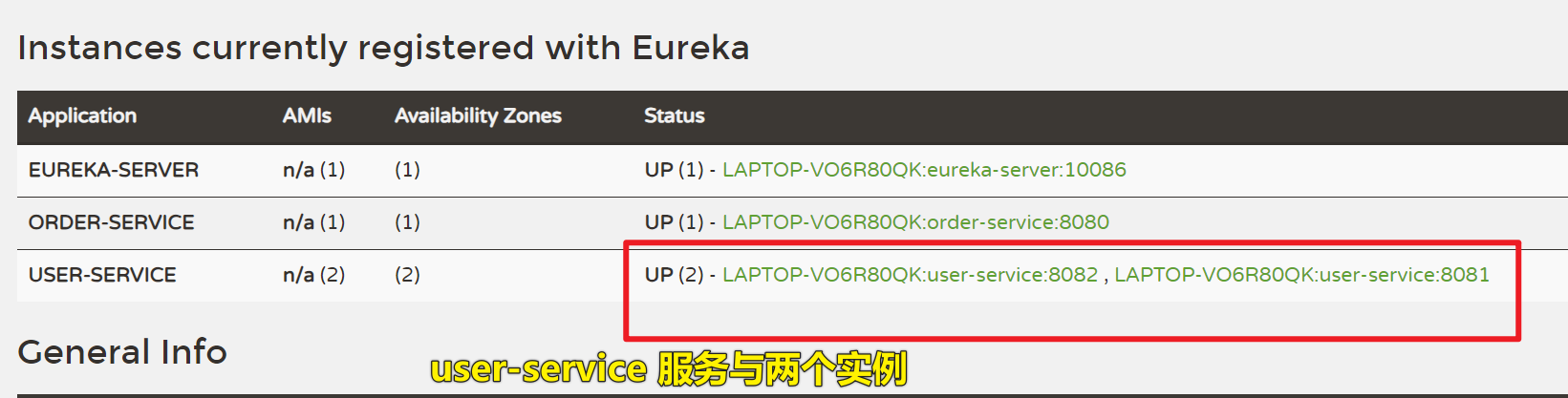
1、学习 Eureka 注册中心
学习 Eureka 注册中心 一、创建 Eureka 微服务0、SpringBoot 和 SpringCloud 版本1、引入 Eureka 服务端依赖2、启动类加 EnableEurekaServer 注解3、配置 yaml 文件,把 Eureka 服务注册到 Eureka 注册中心4、访问 Eureka 服务端,查看注册中心的服务列表…...

Intv_AI_MK11助力后端开发:构建基于大模型的智能API服务
Intv_AI_MK11助力后端开发:构建基于大模型的智能API服务 1. 智能API服务的时代机遇 最近跟几个做后端开发的朋友聊天,发现大家都在讨论同一个问题:如何把大模型能力快速集成到现有系统中。传统做法要么调用第三方API(贵且慢&…...

本地连接MySql数据库报错??
提示: idea本地连接数据库,然后Failed Copy Search Error Troubleshooting DBMS: MySQL (no ver.) Case sensitivity: plainmixed, delimitedexact Communications link failure The last packet sent successfully to the server was 0 millisec…...

Wan2.2-I2V-A14B开源生态:集成Ollama本地模型管理的混合部署方案
Wan2.2-I2V-A14B开源生态:集成Ollama本地模型管理的混合部署方案 1. 引言 最近在AI应用开发中,我们经常面临一个两难选择:既想使用强大的云端大模型能力,又希望保留本地部署的隐私优势。今天要介绍的这套混合部署方案࿰…...

OpenClaw飞书集成:Kimi-VL-A3B-Thinking多模态机器人配置教程
OpenClaw飞书集成:Kimi-VL-A3B-Thinking多模态机器人配置教程 1. 为什么选择OpenClaw飞书Kimi-VL-A3B-Thinking组合 去年我在处理团队知识库时,发现一个痛点:每当同事在飞书群聊里分享产品截图或设计稿时,总要手动保存图片再上传…...

Qwen3-14B-Int4-AWQ辅助系统设计:从需求到UML类图与序列图的自动生成
Qwen3-14B-Int4-AWQ辅助系统设计:从需求到UML类图与序列图的自动生成 1. 系统设计的新助手 想象一下这样的场景:你刚开完需求讨论会,脑子里装满了各种功能模块和交互流程的构想。现在需要把这些想法转化为规范的UML设计文档,但手…...

基于Qwen3.5-2B的数据库课程设计智能指导系统
基于Qwen3.5-2B的数据库课程设计智能指导系统 1. 课程设计的痛点与解决方案 每到学期末,计算机专业的学生们都会面临一个共同的挑战——数据库课程设计。从选题到ER图设计,再到SQL编写和报告撰写,整个过程往往让学生们感到无从下手。传统的…...

为什么你的MCP接入总失败?揭秘CPython解释器层与MCP v2.3.1握手协议的3个隐式约束条件
第一章:MCP服务器接入失败的典型现象与根因定位MCP(Microservice Control Plane)服务器接入失败是微服务治理平台部署初期高频出现的问题,其表象多样但根因高度集中。常见现象包括客户端持续报错 connection refused、健康检查超时…...

面试现场的“AI 对话感”:为什么 2026 年的面试官更喜欢“像跟 AI Pair Programming”一样的沟通节奏?
在 2026 年的北美科技大厂面试中,随着智能代码助手的全面普及,资深工程师们的日常工作习惯已经被彻底重塑。他们每天有大量的时间是在与极其高效、结构化的大语言模型进行 Pair Programming(结对编程)。这种潜移默化的习惯改变&am…...

都是微软亲儿子,WPF凭啥干不掉WinForm?这3个场景说明白了
大家好,我是码农刚子。 前两天有个刚入行的兄弟问我:“现在学桌面开发,是学WinForm还是WPF?我看网上也有人问都是基于.NET平台,WPF能取代Winform吗?” 我听完笑了笑。这个问题吧,就跟“C#能不能取代Java”一…...

MacBook安装OpenClaw:M系列芯片运行Kimi-VL-A3B-Thinking优化指南
MacBook安装OpenClaw:M系列芯片运行Kimi-VL-A3B-Thinking优化指南 1. 为什么要在M系列MacBook上部署OpenClaw 去年我入手了M2 Max芯片的MacBook Pro,原本只是用来做日常开发,直到发现它能流畅运行多模态大模型。作为一个长期被Windows平台G…...