pytorch神经网络入门代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms# 定义神经网络结构
class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, num_classes):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 设置超参数
input_size = 784 # MNIST数据集的输入大小是28x28=784
hidden_size = 784
num_classes = 10learning_rate = 0.01
num_epochs = 10# 加载MNIST数据集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())# 数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=100, shuffle=False)# 实例化模型
model = SimpleNN(input_size, hidden_size, num_classes)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):# 将输入数据转换为一维向量images = images.reshape(-1, 28*28)# 前向传播outputs = model(images)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))# 测试模型
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.reshape(-1, 28*28)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))# 获取模型参数
params = model.parameters()# 打印每个参数的名称和值
for name, param in model.named_parameters():print(f'Parameter name: {name}')print(f'Parameter value: {param}')以下代码测试正确率为:99.37%
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms# 定义适合MNIST数据集的CNN模型
class MNISTCNN(nn.Module):def __init__(self):super(MNISTCNN, self).__init__()# 卷积块 1self.conv_block1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2))# 卷积块 2self.conv_block2 = nn.Sequential(nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2))# 全连接层self.fc_layer = nn.Sequential(nn.Linear(64 * 7 * 7, 512), # 假设经过前面的卷积和池化后特征图大小为7x7nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(512, 10) # MNIST有10个类别)def forward(self, x):x = self.conv_block1(x)x = self.conv_block2(x)# 将卷积层输出展平为一维向量x = x.view(x.size(0), -1)# 通过全连接层x = self.fc_layer(x)return x# 创建模型实例
model = MNISTCNN()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 加载MNIST数据集并预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)# 使用DataLoader加载批量数据
batch_size = 64
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 开始训练
num_epochs = 10
for epoch in range(num_epochs):for inputs, labels in train_loader:# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad() # 清空梯度缓存loss.backward() # 计算梯度optimizer.step() # 更新参数# 每个epoch结束时打印损失print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 测试模型
model.eval() # 将模型切换到评估模式(禁用Dropout和BatchNorm等)
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Test Accuracy: {100 * correct / total}%')
相关文章:

pytorch神经网络入门代码
import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms# 定义神经网络结构 class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, num_classes):super(SimpleNN, self).__init_…...

代码随想录算法训练营第三十四天|860.柠檬水找零 406.根据身高重建队列 452. 用最少数量的箭引爆气球
860.柠檬水找零 链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 细节: 1. 首先根据题意就是只有5.的成本,然后就开始找钱,找钱也是10.和5. 2. 直接根据10 和 5 进行变量定义,然后去循环…...

Ditto:提升剪贴板体验的宝藏软件(复制粘贴效率翻倍、文本处理好助手)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、什么是Ditto?二、下载安装三、如…...

【自然语言处理-工具篇】spaCy<2>--模型的使用
前言 之前已经介绍了spaCy的安装,接下来我们要通过下载和加载模型去开始使用spaCy。 下载模型 经过训练的 spaCy 管道可以作为 Python 包安装。这意味着它们是应用程序的一个组件,就像任何其他模块一样。可以使用 spaCy download的命令安装模型,也可以通过将 pip 指向路径或…...

Java之通过Jsch库连接Linux实现文件传输
Java之通过JSch库连接Linux实现文件传输 文章目录 Java之通过JSch库连接Linux实现文件传输1. JSch2. Java通过Jsch连接Linux1. poxm.xml2. 工具类3. 调用案例 1. JSch 官网:JSch - Java Secure Channel (jcraft.com) JSch是SSH2的纯Java实现。 JSch 允许您连接到 ss…...

Nginx七层负载均衡之动静分离
思路: servera:负载均衡服务器 serverb:静态服务器 serverc:动态服务器 serverd:默认服务器 servera(192.168.233.132): # 安装 Nginx 服务器 yum install nginx -y#关闭防火墙和selinux systemctl stop firewalld setenforce 0# 切换到 Nginx 配置文…...

305_C++_定义了一个定时器池 TimerPool 类和相关的枚举类型和结构体
头文件:定义了一个定时器池 TimerPool 类和相关的枚举类型和结构体 #ifndef TIMERPOOL_H #define TIMERPOOL_H #include "rsglobal.h" #include "taskqueue.h" #incl...
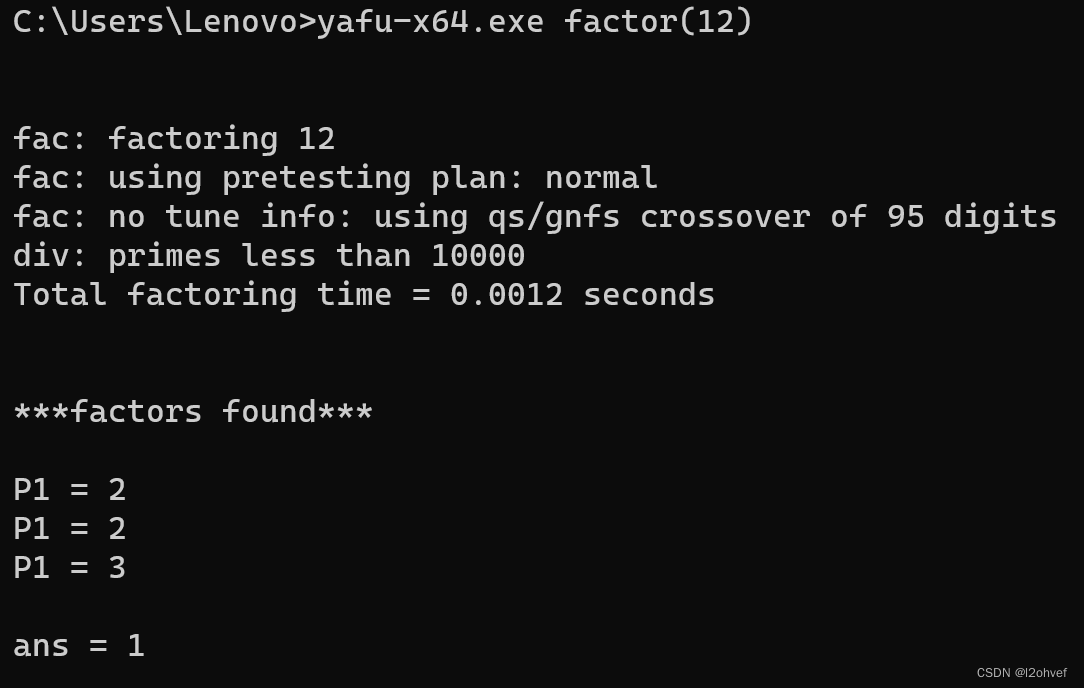
大整数因数分解工具——yafu
一、安装 yafu--下载链接 二、配置环境变量,直接从cmd打开 1.找到yafu-x64.exe 所在的文件路径 2.点击设置——系统——系统信息——高级系统设置——环境变量——点击PATH(上下都可以)——新建 添加yafu-x64.exe 所在路径——点击确定 3…...
和关系型数据库(SQL)区别详解)
非关系型数据库(NOSQL)和关系型数据库(SQL)区别详解
前言: 在我们的日常开发中,关系型数据库和非关系型数据库的使用已经是一个成熟的软件产品开发过程中必不可却的存储数据的工具了。那么用了这么久的关系数据库和非关系型数据库你们都知道他们之间的区别了吗?下面我们来详细的介绍一下。 关系…...

7.Cloud-GateWay
0.概述 https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/ 1.入门配置 1.1 POM <!--新增gateway--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sta…...

【Linux】Framebuffer 应用
# 前置知识 LCD 操作原理 在 Linux 系统中通过 Framebuffer 驱动程序来控制 LCD。 Frame 是帧的意思, buffer 是缓冲的意思,这意味着 Framebuffer 就是一块内存,里面保存着一帧图像。 Framebuffer 中保存着一帧图像的每一个像素颜色值&…...

markdown绘制流程图相关代码片段记录
有时候会使用typora来绘制一些流程图,进行编码之类的工作,在网络搜集了一些笔记,做个记录,方便日后进行复习,相关的记录如下: 每次作图时,代码以「graph <布局方向>」开头,如…...
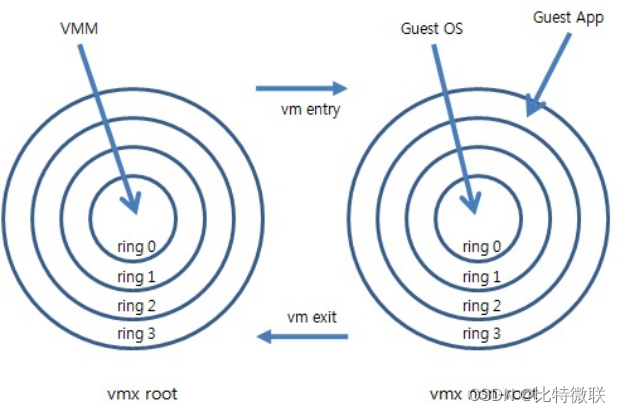
云计算基础-计算虚拟化-CPU虚拟化
CPU指令系统 在CPU的工作原理中,CPU有不同的指令集,如下图,CPU有4各指令集:Ring0-3,指令集是在服务器上运行的所有命令,最终都会在CPU上执行,但是CPU并不是说所有的命令都是一视同仁的…...

MySQL数据库⑪_C/C++连接MySQL_发送请求
目录 1. 下载库文件 2. 使用库 3. 链接MySQL函数 4. C/C链接示例 5. 发送SQL请求 6. 获取查询结果 本篇完。 1. 下载库文件 要使用C/C连接MySQL,需要使用MySQL官网提供的库。 进入MySQL官网选择适合自己平台的mysql connect库,然后点击下载就行…...
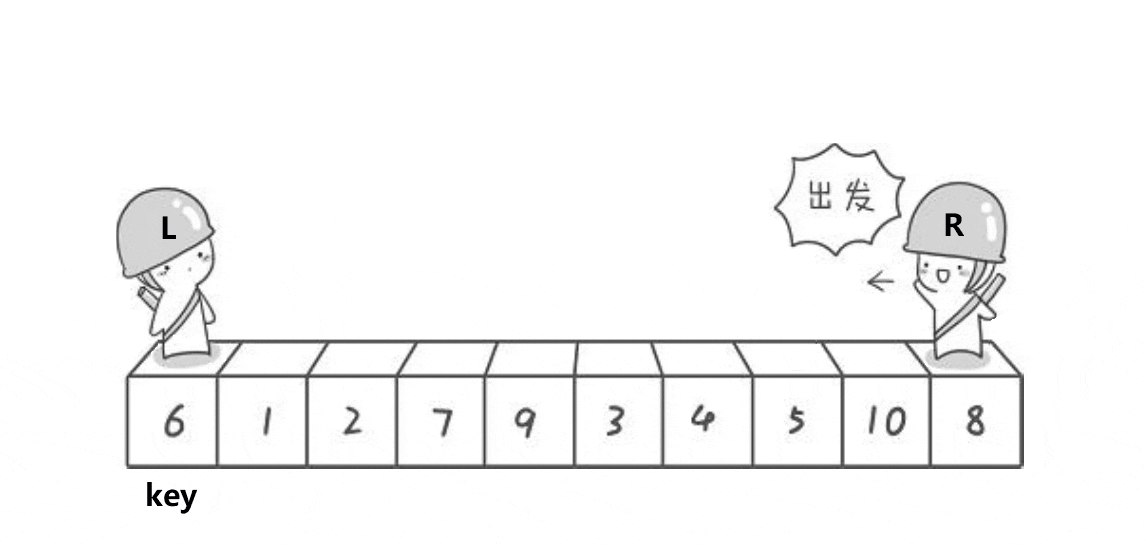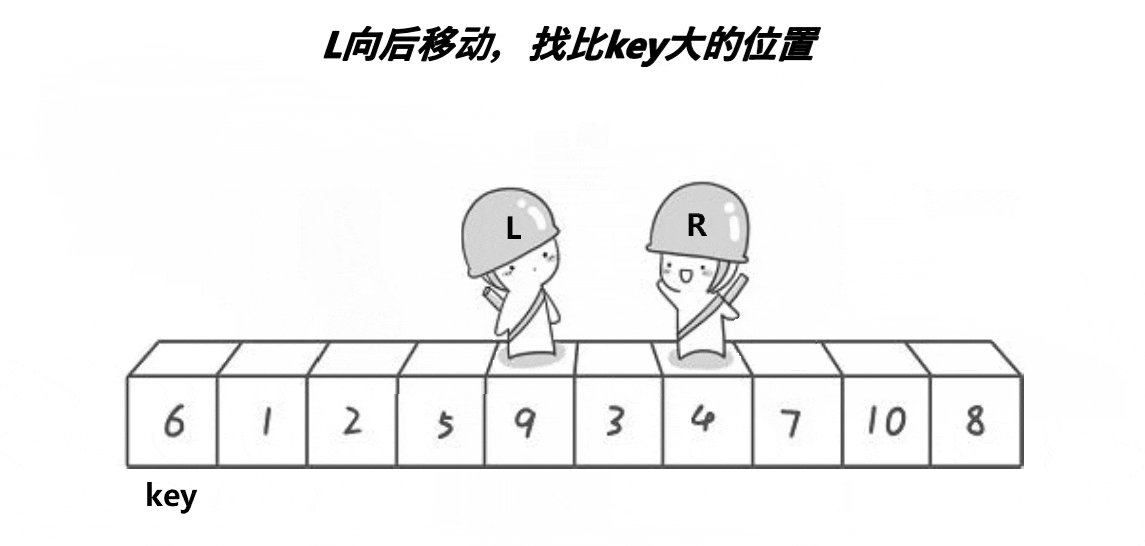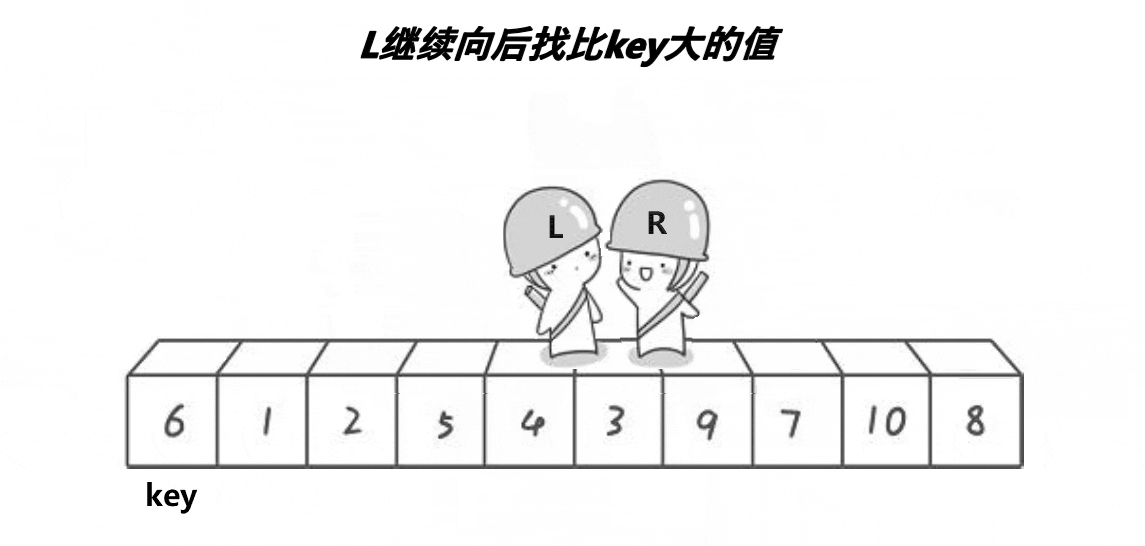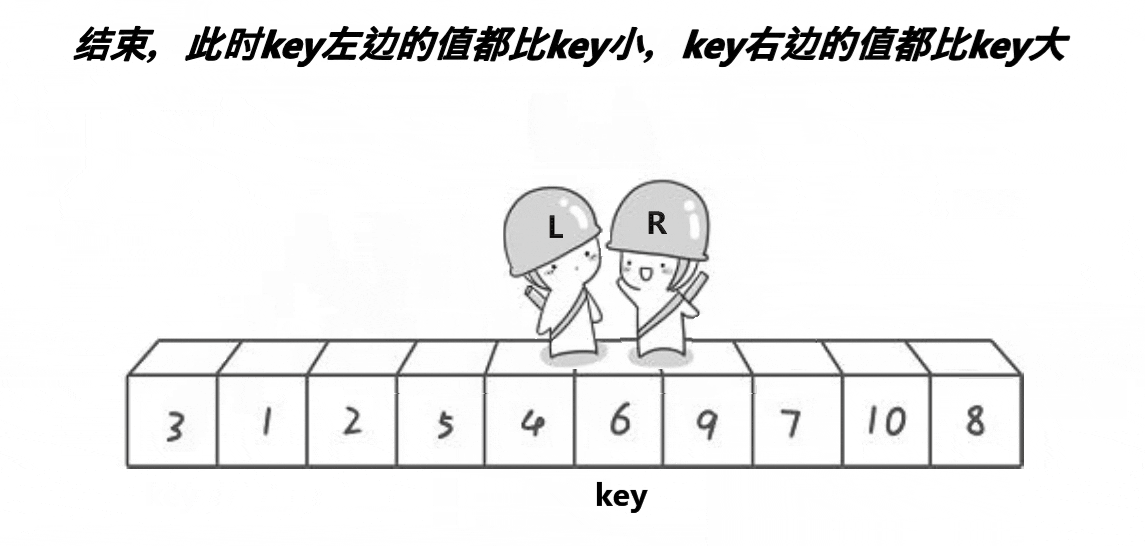
选择排序和快速排序(1)
目录 选择排序 基本思想 选择排序的实现 图片实现 代码实现 快速排序 基本思想 快速排序的实现 图片实现 代码实现 选择排序 基本思想 每一次从待排序的数据元素中选出最小(最大)的元素,存放在序列的起始位置,直到全部…...
得物面试:Redis用哈希槽,而不是一致性哈希,为什么?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: Redis为何用哈希槽而不用一致性哈希? 最近…...

matlab发送串口数据,并进行串口数据头的添加,我们来看下pwm解析后并通过串口输出的效果
uintt16位的话会在上面前面加上00,16位的话一定是两个字节,一共16位的数据 如果是unint8的话就不会, 注意这里给的是13,但是现实的00 0D,这是大小端的问题,在matlanb里设置,我们就默认用这个模式…...

二分、快排、堆排与双指针
二分 int Binary_Search(vector<int> A,int key){int nA.size();int low0,highn-1,mid;while(low<high){mid(lowhigh)/2;if(A[mid]key)return mid;else if(A[mid]>key)highmid-1;elselowmid1; }return -1; }折半插入排序 ——找到第一个 ≥ \ge ≥tem的元素 voi…...

微信小程序步数返还的时间戳为什么返回的全是1970?
微信小程序步数返还的时间戳为什么返回的全是1970? 将返回的时间 乘以 1000 再 new Date() 转化就对了 微信返回的是秒S单位的,我们要转化为毫秒ms单位,才能进行格式化日期。 微信给我们下了个坑, 参考: https://d…...

Python函数——函数介绍
一、引言 在Python编程中,函数是构建高效代码的关键。通过创建可重用的代码块,我们可以使程序更加清晰、易读且易于维护。在本文中,我们将深入了解Python函数的基本概念及其特性。 二、Python函数的基本概念 函数是一段具有特定功能的代码块…...

零碳园区绿电直供技术的挑战与解决方案
一、难点问题 二次系统+储能推高初投 篇幅有限仅展示了部分 根据650号文 ,绿电直连项目必须配置继电保护、安全稳定控制装置和通信设备等二次系统 ,以确保项目的安全性和稳定性。这些强制性配置显著增加了项目的初始投资成本。 专线造价与全周…...

嵌入式Linux应用开发实战:DR1平台GDB调试、Python优化与MQTT通信
1. 项目概述:从零到一,构建嵌入式Linux应用的实战手册最近在DR1平台上折腾了几个应用项目,从简单的数据采集到复杂的网络通信,整个过程踩了不少坑,也积累了不少心得。DR1作为一款资源受限但功能完整的嵌入式平台&#…...
)
JDK 17 + Hadoop 3.3.5 + Spark 3.3.2 集群搭建保姆级避坑指南(CentOS 8.5 + VMware)
JDK 17 Hadoop 3.3.5 Spark 3.3.2 集群搭建实战避坑手册 当你第一次尝试在本地环境搭建大数据集群时,是否曾被各种兼容性问题、配置错误和莫名其妙的报错折磨得焦头烂额?本文将带你完整走一遍从零开始搭建基于JDK 17、Hadoop 3.3.5和Spark 3.3.2的集群…...

面试题目总结
面试心态 越是置自己于低位,就越难获得面试官的青睐。面试官其实更喜欢逻辑清晰,不卑不亢,带点锋芒的应聘者。 不要以通过面试为目的,不然很难摆脱被凝视的状态。要以自我成长与提升为中心。要记住,每一次面试不是成功…...

GJB 128B-2021标准变更深度解析:VDMOS产品试验方法的影响与应对
1. GJB 128B-2021标准变更的核心要点 对于从事VDMOS产品研发和质量控制的工程师来说,2022年3月正式实施的GJB 128B-2021标准带来了不少值得关注的调整。相比旧版标准,这次修订在试验条件、热平衡判定、静电防护等多个关键环节都做出了具体规定。我仔细研…...

AIGC 检测怎么识别 ChatGPT 写作指纹?嘎嘎降 AI 帮你 AI 率从 85% 降到 5%
AIGC 检测怎么识别 ChatGPT 写作指纹?嘎嘎降 AI 帮你 AI 率从 85% 降到 5% 很多同学好奇——为什么 ChatGPT 改写论文之后送知网检测 AI 率反而涨了?真相是——ChatGPT 的输出有自己独特的"写作指纹"——AIGC 检测算法早就识别了这种指纹。这篇…...

OPNsense-从零部署:硬件选型与虚拟机安装实战
1. 为什么选择OPNsense? 第一次听说OPNsense是在三年前帮朋友公司排查网络问题时。当时他们用的某商业防火墙频繁死机,我试着在旧服务器上部署了OPNsense临时救急,没想到这台"临时工"不仅稳定运行了两年多,还解锁了流量…...

高效解决Windows 11 LTSC系统Microsoft Store缺失的完整实战指南
高效解决Windows 11 LTSC系统Microsoft Store缺失的完整实战指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 24H2 LTSC版本以其卓越的…...

Perplexity视频搜索不精准?揭秘4类常见误操作及实时修正方案
更多请点击: https://codechina.net 第一章:Perplexity视频搜索不精准?揭秘4类常见误操作及实时修正方案 Perplexity 的视频搜索功能依赖于跨模态语义理解,但用户常因输入方式或上下文设置不当导致结果偏离预期。以下四类高频误操…...

财务RPA只能自动执行吗?它还能结合大模型,进化成财务分析助手
提到财务RPA,多数人对它的认知还停留在“自动化工具”层面,能724小时不间断处理发票录入、凭证生成、银行对账等重复性财务工作,替代人工完成机械操作,实现“降本增效”。但事实上,随着大模型技术与财务场景的深度融合…...