VOSK——离线语音库
文章目录
- 识别函数调用
- 添加自定义热词表
- 1. SetWords
- 2. SetLatticeWords
- 3. SetPartialWords
- 使用示例
- 注意
- 1. SetMaxAlternatives
- 2. SetNLSML
- 3. SetSpkModel
- 4. SetGrammar
- 使用示例
- 注意
- SetLogLevel
- 示例用法
- 注意事项
识别函数调用
在使用Vosk库进行语音识别时,PartialResult是一个术语,用于表示临时的、部分的识别结果。Vosk是一个开源的语音识别库,支持多种语言,能够在本地运行,无需依赖互联网连接。它适用于从实时音频流或预录制的音频文件中识别语音。
在语音识别过程中,Vosk提供了几种不同类型的结果:
-
PartialResult:这是在识别过程中临时得到的结果。当语音识别引擎处理音频流时,它会不断更新这个临时结果,以反映它对当前说话内容的最佳猜测。PartialResult通常包含尚未最终确认的词语,因为随着更多音频的处理,这些词语可能会被修改或更新。 -
FinalResult:当Vosk识别引擎确定一段话已经结束,它会提供一个FinalResult,这是对该段话的最终识别结果。这个结果认为是准确的,不会因为后续的音频而改变。 -
Result:在某些情况下,简单地称为Result的输出,可能指的是在特定时间点的最终识别结果。
PartialResult对于实现实时语音识别反馈特别有用,因为它允许应用程序向用户显示识别过程中的即时文本,即使该文本可能随着对后续音频的分析而变化。这提高了用户体验,使用户能够看到识别进度,并在必要时即时更正。
下面是一个处理PartialResult的简单示例,展示了如何在使用Vosk进行实时语音识别时打印临时识别结果:
from vosk import Model, KaldiRecognizer
import os
import pyaudiomodel = Model("path/to/vosk/model")
rec = KaldiRecognizer(model, 16000)p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=16000, input=True, frames_per_buffer=4096)
stream.start_stream()while True:data = stream.read(4096)if rec.AcceptWaveform(data):print(rec.Result())else:print(rec.PartialResult())
在这个示例中,每次循环中从音频流中读取数据,并使用AcceptWaveform方法处理数据。如果语音识别引擎确定当前的语音输入已经完成,它会返回True,并可以通过调用Result()方法获取最终结果。否则,可以通过PartialResult()方法获取临时的识别结果,并实时打印出来。
添加自定义热词表
在vosk库中,添加热词表(也称为词汇提升或词汇偏好设置)允许你提高特定词汇在语音识别过程中的识别准确率。这个功能特别有用,当你知道语音输入中可能会包含某些特定的词汇或短语时,比如特定的人名、地名、专业术语等。
vosk支持在创建KaldiRecognizer对象时通过JSON配置来指定热词表。你可以为每个词指定一个权重,权重越高,该词在识别过程中被选中的可能性就越大。
下面是一个如何使用热词表的示例:
from vosk import Model, KaldiRecognizer
import json# 加载模型
model = Model("path/to/model")# 假设采样率为16000Hz
rec = KaldiRecognizer(model, 16000)# 定义热词表及其权重
hot_words = ["特定词汇", "另一个词汇"]
hot_words_weights = [10.0, 5.0] # 权重越高,优先级越高# 构建热词表的JSON配置
hot_words_config = {"phrase_list": hot_words, "boost": hot_words_weights}
rec.SetWords(True)
rec.SetPartialWords(True)
rec.SetLatticeWords(True)
rec.UpdateConfig(json.dumps({"hot_words": hot_words_config}))# 使用rec进行语音识别...
在上述代码中,我们首先创建了一个KaldiRecognizer对象,并通过UpdateConfig方法设置了热词表。hot_words_config包含了热词列表和相应的权重,这个配置以JSON格式传递给UpdateConfig方法。
请注意,上面的代码示例仅为说明如何设置热词表的逻辑,并不是vosk API 的直接用法。截至我最后更新的时间(2023年4月),vosk API 并没有直接支持通过UpdateConfig方法来更新配置。实际上,要在vosk中使用热词表,通常需要通过修改语音识别模型的配置文件或在模型训练阶段指定热词表。因此,具体实现可能会根据vosk版本和模型的不同而有所差异。
建议查看vosk的官方文档或GitHub仓库中的最新信息,以获取关于如何为你的特定模型和vosk版本添加热词表的最新和最准确的方法。
在Vosk API中,存在几个set方法,这些方法允许你定制化识别器(Recognizer)的行为,特别是关于它如何返回识别结果。这些方法包括SetWords、SetLatticeWords和SetPartialWords等。这些方法的作用主要是控制识别结果中词汇的详细程度和格式。以下是这些方法的简要说明:
1. SetWords
SetWords(bool)方法用于控制识别结果中是否应该包含单词级别的详细信息。当设置为True时,Vosk将在识别结果中返回每个词的详细信息,如词本身、开始时间、结束时间等。这对于需要对识别结果进行深入分析的应用非常有用。
2. SetLatticeWords
SetLatticeWords(bool)方法用于控制是否在生成语音识别的“格”(Lattice)时包含词信息。语音识别的格是一种数据结构,它包含了多个可能的识别路径及其概率。这个选项通常用于高级应用,比如需要后处理格以提取更精细信息的情况。开启这个选项可能会增加内存的使用。
3. SetPartialWords
SetPartialWords(bool)方法控制临时(部分)识别结果是否应包含单词级别的详细信息。当设置为True时,即使是临时的识别结果也会尽可能包含每个词的详细信息。这对于实时反馈应用场景很有帮助,因为它允许用户即时看到识别的细节。
使用示例
以下是如何在创建KaldiRecognizer对象时使用这些设置的示例:
from vosk import Model, KaldiRecognizermodel = Model("path/to/model")
rec = KaldiRecognizer(model, 16000)rec.SetWords(True) # 开启词信息的详细输出
rec.SetLatticeWords(True) # 在格中包含词信息
rec.SetPartialWords(True) # 临时结果也包含词信息
注意
- 不是所有版本的Vosk都支持上述所有方法。具体可用的方法取决于你使用的Vosk版本。
- 开启这些详细输出选项可能会对性能有一定影响,尤其是在资源受限的环境下。因此,根据应用的需求合理选择。
- Vosk的API和功能可能会随着版本更新而变化。建议查阅最新的Vosk文档或GitHub仓库以获取最新信息。
这些设置函数提供了灵活性,让开发者能够根据应用场景的具体需求来调整语音识别的输出细节。
Vosk API提供了多种配置选项,让开发者可以调整语音识别的行为以适应不同的应用场景。除了之前提到的SetWords、SetLatticeWords和SetPartialWords之外,还有其他几个配置方法,如SetMaxAlternatives、SetNLSML、SetSpkModel和SetGrammar。下面是这些方法的详细说明:
1. SetMaxAlternatives
SetMaxAlternatives(int maxAlternatives)方法用于设置语音识别结果中返回的最大替代句子数量。这个设置允许你获取到不仅仅是最可能的识别结果,还可以得到其他可能的替代结果。例如,如果你设置maxAlternatives为3,那么识别器将尝试返回最多三个识别结果,按可能性排序。
2. SetNLSML
SetNLSML(bool enable)方法控制是否以NLSML(Natural Language Semantics Markup Language)格式输出识别结果。NLSML是一种用于描述语音识别结果及其语义解释的标记语言。开启这个选项可以让你得到更丰富的结果描述,包括词汇的语义信息,但这通常用于特定需要进行语义分析的应用场景。
3. SetSpkModel
SetSpkModel(SpkModel spkModel)方法允许你设置一个说话人识别模型(speaker model)。这使得Vosk不仅能够识别说话的内容,还能识别是谁在说话。这对于需要区分不同说话人或执行说话人验证的应用非常有用。SpkModel是一个专门的模型,需要与语音识别模型一起使用。
4. SetGrammar
SetGrammar(List<string> grammar)方法允许你定义一个语法列表,识别器将只识别列表中的词或短语。这对于创建有限词汇或命令控制的应用非常有用,因为它可以大大提高特定词汇的识别准确率并减少错误识别。
使用示例
以下是如何使用这些设置的示例:
from vosk import Model, KaldiRecognizer, SpkModelmodel = Model("path/to/model")
spk_model = SpkModel("path/to/spk_model")
rec = KaldiRecognizer(model, 16000)rec.SetMaxAlternatives(3) # 设置最大替代句子数量
rec.SetNLSML(True) # 开启NLSML格式输出
rec.SetSpkModel(spk_model) # 设置说话人识别模型
rec.SetGrammar(["yes", "no", "stop", "go"]) # 设置识别语法列表
注意
- 这些方法的可用性和行为可能取决于你使用的Vosk版本,以及模型的支持情况。并非所有模型都支持说话人识别或特定的配置选项。
- 使用这些高级配置时,可能需要额外的模型文件(如说话人识别模型),或者在识别特定词汇时需要额外的配置步骤。
- 总是建议查阅Vosk的最新文档或GitHub仓库以获取最新和最准确的信息,因为Vosk库可能会随时间更新和改进。
这些高级配置选项为开发者提供了进一步定制化语音识别行为的能力,使得Vosk可以更好地适应各种不同的应用需求。
SetLogLevel
SetLogLevel是Vosk API中用于设置日志级别的函数。这个设置允许开发者控制库输出日志的详细程度,有助于调试应用程序或减少日志输出以优化性能。日志级别通常包括错误、警告、信息、调试等级别,不同级别会输出不同详细程度的日志信息。
在Vosk中,SetLogLevel函数可以用来设置这些日志级别,但是具体如何使用(包括函数的参数和可用的日志级别)可能会根据Vosk的版本和具体实现有所不同。在某些版本或配置中,可能需要直接调用底层库(如Kaldi)的日志设置函数。
示例用法
虽然Vosk的公开文档中可能没有明确提到SetLogLevel函数,但是如果存在,其用法可能类似于以下形式:
from vosk import SetLogLevel# 设置日志级别
SetLogLevel(0) # 假设0代表最低的日志输出级别,如错误信息
注意事项
- 版本差异:不同版本的Vosk可能在日志管理上有所不同。建议查阅你所使用的Vosk版本的文档或源代码了解具体的日志设置方法。
- 日志级别:具体可用的日志级别和它们的数字代码可能会根据Vosk的实现而变化。通常,较低的数字表示更高的日志级别,意味着更少的日志输出。
- 性能考虑:在生产环境中,适当减少日志输出可以帮助提高应用性能和减少日志文件的大小。
- 调试:在开发和调试期间,提高日志级别以获得更详细的输出可能会很有帮助,尤其是在排查问题时。
如果SetLogLevel函数或其等效功能在你使用的Vosk版本中不可用,或者你需要更具体的指导,建议参考Vosk的官方文档或在其GitHub仓库中搜索相关讨论。此外,考虑到Vosk是基于Kaldi语音识别工具包开发的,Kaldi相关的日志设置也可能适用。
问题出现的原因是在构造关键词字符串时,外围的单引号'被错误地包含在了最终的字符串中。根据错误信息,Vosk期望的格式是一个没有外围单引号的JSON数组字符串。在Python中构造这样的字符串时,你需要确保结果字符串是以双引号"包裹的JSON格式,且不应该包含最外层的单引号。
你的代码中start_ = "'["和end_ = "]'"这两行添加了不必要的单引号。正确的方式是构造一个纯粹的JSON字符串,不包括外层的单引号,然后直接传递给KaldiRecognizer。
以下是一个修正后的示例代码,它正确地构造了所需的格式:
keywords = ['天王盖地虎', '你好', '亲爱的']# 使用json.dumps来直接生成JSON格式的字符串
import json
kw_str = json.dumps(keywords)# 现在kw_str是正确格式的JSON字符串:["天王盖地虎", "你好", "亲爱的"]
# 注意:这里不需要手动添加外围的单引号或双引号,json.dumps 已经正确处理# 使用kw_str时直接作为参数传递
rec = KaldiRecognizer(model, wf.getframerate(), kw_str)
这种方法利用了json.dumps()函数直接将关键词列表转换为JSON格式的字符串,无需手动构造字符串,避免了引号使用上的错误。这样可以确保传递给KaldiRecognizer的字符串是正确的格式,符合Vosk期望的参数形式。
相关文章:

VOSK——离线语音库
文章目录 识别函数调用添加自定义热词表1. SetWords2. SetLatticeWords3. SetPartialWords使用示例注意1. SetMaxAlternatives2. SetNLSML3. SetSpkModel4. SetGrammar使用示例注意SetLogLevel示例用法注意事项 识别函数调用 在使用Vosk库进行语音识别时,PartialRe…...
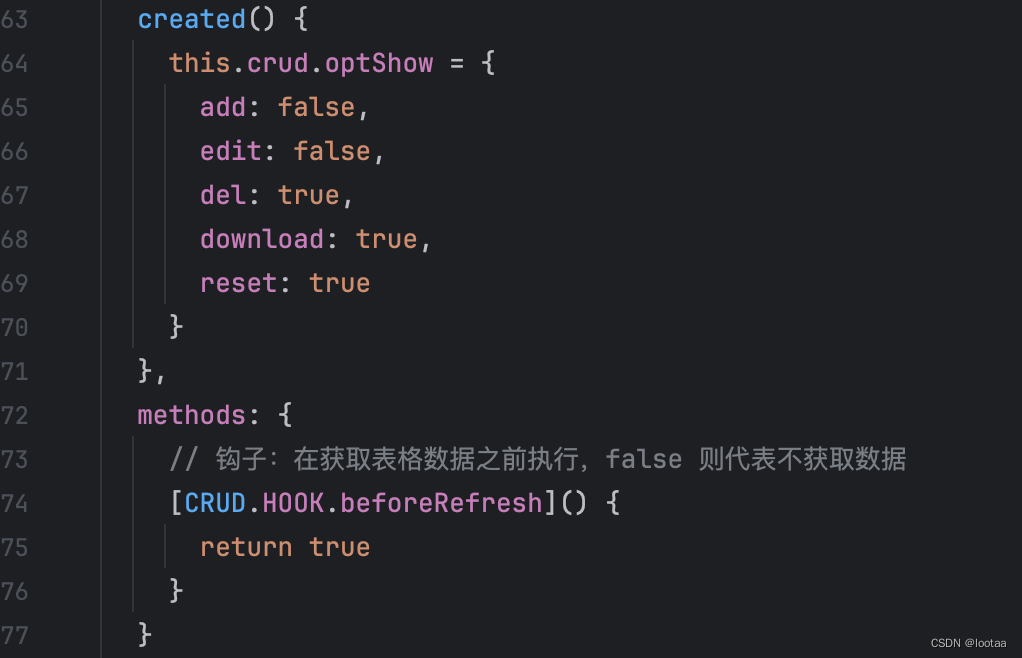
ELAdmin 隐藏添加编辑按钮
使用场景 做了一个监控模块,数据都是定时生成的,所以不需要手动添加和编辑功能。 顶部不显示 可以使用 true 或者 false 控制现实隐藏 created() {this.crud.optShow {add: false,edit: false,del: true,download: true,reset: true}},如果没有 crea…...

浅谈Websocket
由于 http 存在⼀个明显的弊端(消息只能有客户端推送到服务器端,⽽服务器端不能主动推送到客户端),导致如果服务器如果有连续的变化,这时只能使⽤轮询,⽽轮询效率过低,并不适合。于是 WebSocket 被发明出来 WebSocket 是⼀种在 Web 应⽤程序中实现双向通信的协议。与传…...

JavaScript闭包详细介绍
文章目录 什么是闭包优点:变量持久化:封装私有变量:模块化:函数工厂: 缺点:内存占用:调试困难:过度使用导致性能下降: 什么是闭包 闭包是指有权访问另一个函数作用域中的…...

pytorch神经网络入门代码
import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms# 定义神经网络结构 class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, num_classes):super(SimpleNN, self).__init_…...

代码随想录算法训练营第三十四天|860.柠檬水找零 406.根据身高重建队列 452. 用最少数量的箭引爆气球
860.柠檬水找零 链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 细节: 1. 首先根据题意就是只有5.的成本,然后就开始找钱,找钱也是10.和5. 2. 直接根据10 和 5 进行变量定义,然后去循环…...

Ditto:提升剪贴板体验的宝藏软件(复制粘贴效率翻倍、文本处理好助手)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、什么是Ditto?二、下载安装三、如…...

【自然语言处理-工具篇】spaCy<2>--模型的使用
前言 之前已经介绍了spaCy的安装,接下来我们要通过下载和加载模型去开始使用spaCy。 下载模型 经过训练的 spaCy 管道可以作为 Python 包安装。这意味着它们是应用程序的一个组件,就像任何其他模块一样。可以使用 spaCy download的命令安装模型,也可以通过将 pip 指向路径或…...

Java之通过Jsch库连接Linux实现文件传输
Java之通过JSch库连接Linux实现文件传输 文章目录 Java之通过JSch库连接Linux实现文件传输1. JSch2. Java通过Jsch连接Linux1. poxm.xml2. 工具类3. 调用案例 1. JSch 官网:JSch - Java Secure Channel (jcraft.com) JSch是SSH2的纯Java实现。 JSch 允许您连接到 ss…...

Nginx七层负载均衡之动静分离
思路: servera:负载均衡服务器 serverb:静态服务器 serverc:动态服务器 serverd:默认服务器 servera(192.168.233.132): # 安装 Nginx 服务器 yum install nginx -y#关闭防火墙和selinux systemctl stop firewalld setenforce 0# 切换到 Nginx 配置文…...

305_C++_定义了一个定时器池 TimerPool 类和相关的枚举类型和结构体
头文件:定义了一个定时器池 TimerPool 类和相关的枚举类型和结构体 #ifndef TIMERPOOL_H #define TIMERPOOL_H #include "rsglobal.h" #include "taskqueue.h" #incl...
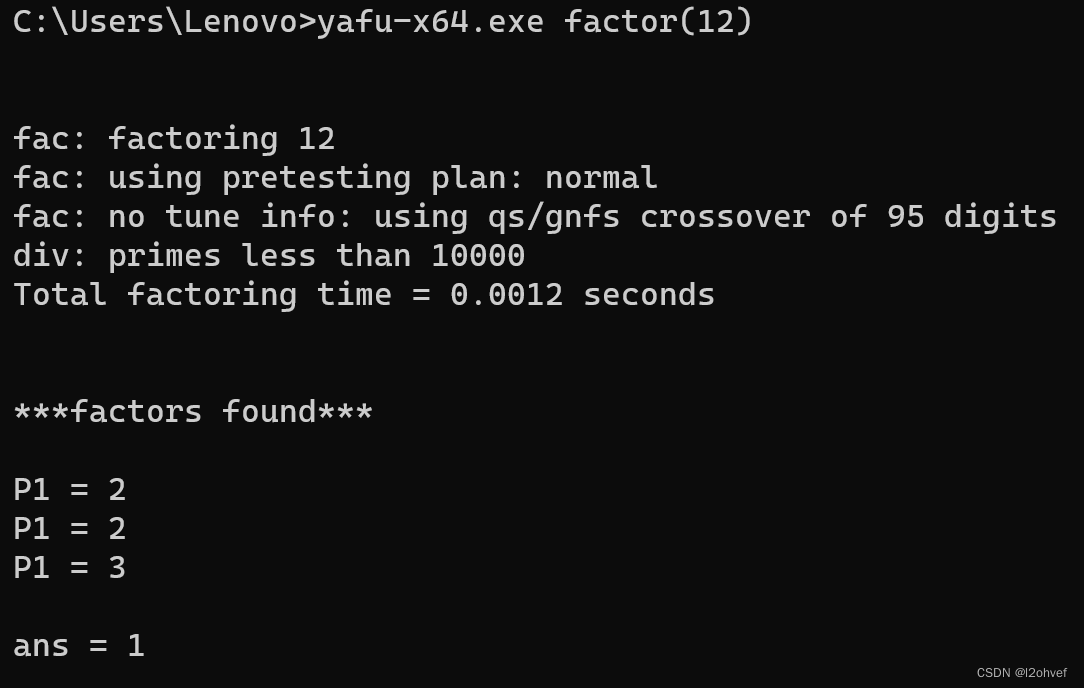
大整数因数分解工具——yafu
一、安装 yafu--下载链接 二、配置环境变量,直接从cmd打开 1.找到yafu-x64.exe 所在的文件路径 2.点击设置——系统——系统信息——高级系统设置——环境变量——点击PATH(上下都可以)——新建 添加yafu-x64.exe 所在路径——点击确定 3…...
和关系型数据库(SQL)区别详解)
非关系型数据库(NOSQL)和关系型数据库(SQL)区别详解
前言: 在我们的日常开发中,关系型数据库和非关系型数据库的使用已经是一个成熟的软件产品开发过程中必不可却的存储数据的工具了。那么用了这么久的关系数据库和非关系型数据库你们都知道他们之间的区别了吗?下面我们来详细的介绍一下。 关系…...

7.Cloud-GateWay
0.概述 https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/ 1.入门配置 1.1 POM <!--新增gateway--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sta…...

【Linux】Framebuffer 应用
# 前置知识 LCD 操作原理 在 Linux 系统中通过 Framebuffer 驱动程序来控制 LCD。 Frame 是帧的意思, buffer 是缓冲的意思,这意味着 Framebuffer 就是一块内存,里面保存着一帧图像。 Framebuffer 中保存着一帧图像的每一个像素颜色值&…...

markdown绘制流程图相关代码片段记录
有时候会使用typora来绘制一些流程图,进行编码之类的工作,在网络搜集了一些笔记,做个记录,方便日后进行复习,相关的记录如下: 每次作图时,代码以「graph <布局方向>」开头,如…...
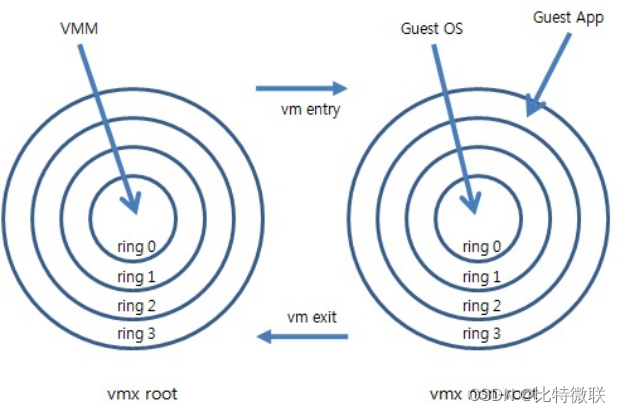
云计算基础-计算虚拟化-CPU虚拟化
CPU指令系统 在CPU的工作原理中,CPU有不同的指令集,如下图,CPU有4各指令集:Ring0-3,指令集是在服务器上运行的所有命令,最终都会在CPU上执行,但是CPU并不是说所有的命令都是一视同仁的…...

MySQL数据库⑪_C/C++连接MySQL_发送请求
目录 1. 下载库文件 2. 使用库 3. 链接MySQL函数 4. C/C链接示例 5. 发送SQL请求 6. 获取查询结果 本篇完。 1. 下载库文件 要使用C/C连接MySQL,需要使用MySQL官网提供的库。 进入MySQL官网选择适合自己平台的mysql connect库,然后点击下载就行…...
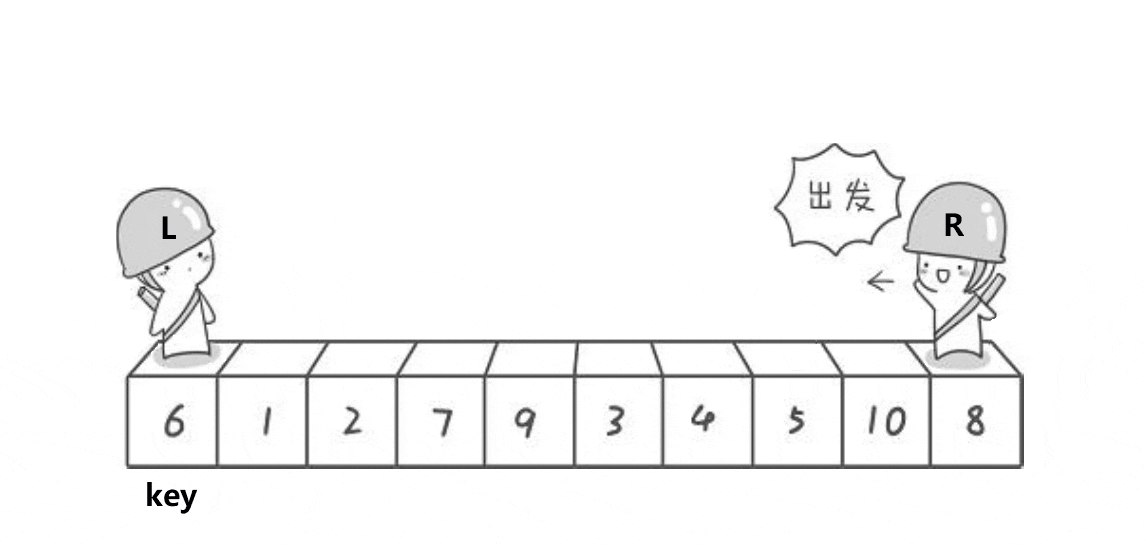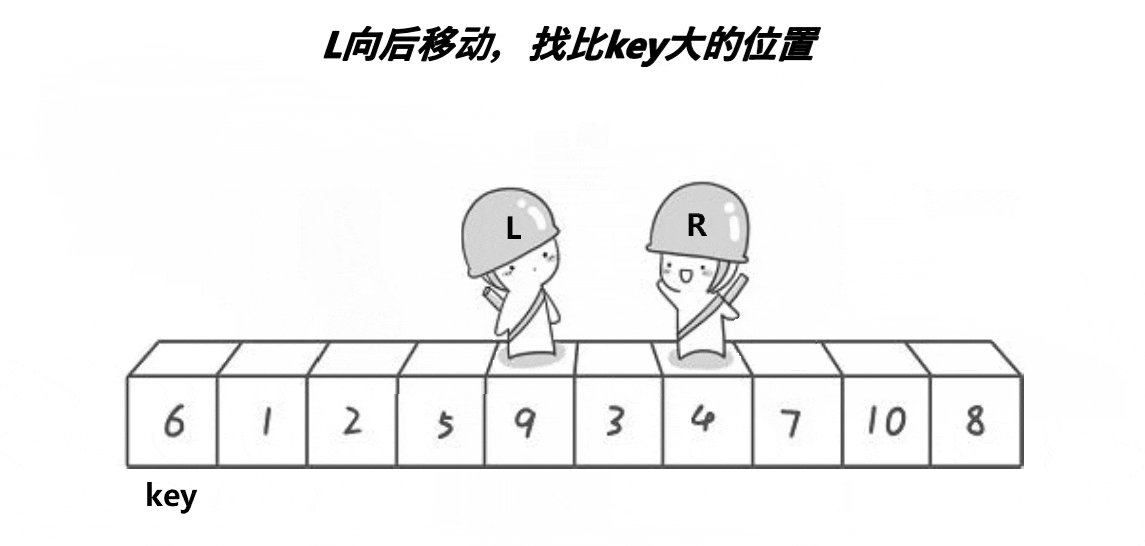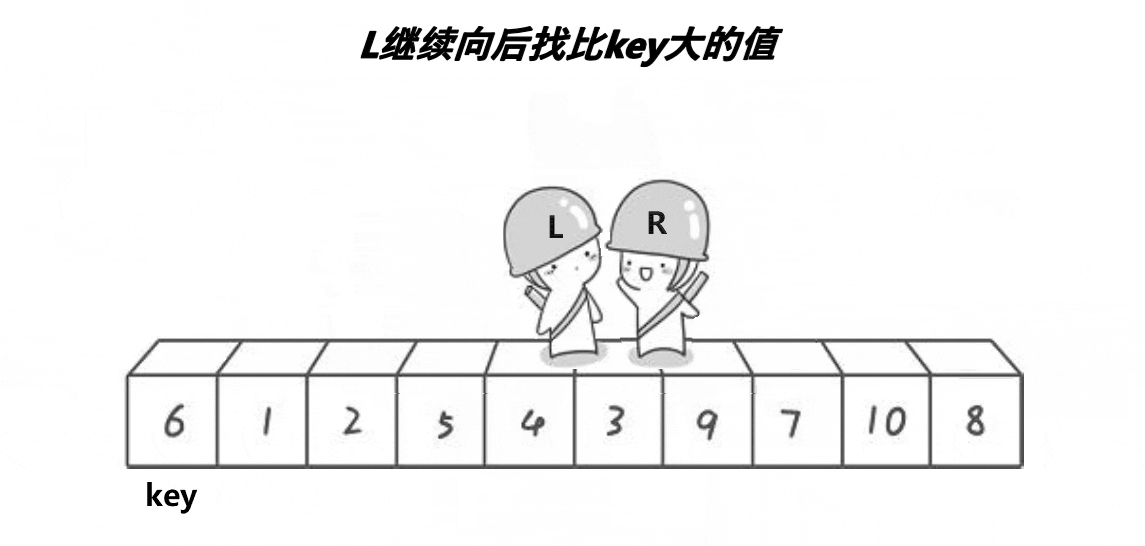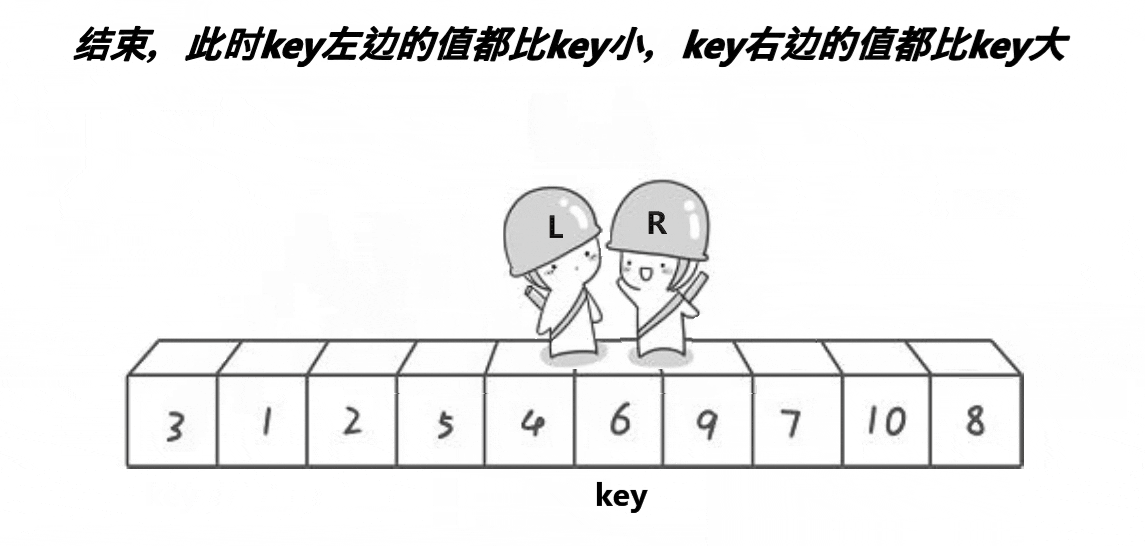
选择排序和快速排序(1)
目录 选择排序 基本思想 选择排序的实现 图片实现 代码实现 快速排序 基本思想 快速排序的实现 图片实现 代码实现 选择排序 基本思想 每一次从待排序的数据元素中选出最小(最大)的元素,存放在序列的起始位置,直到全部…...
得物面试:Redis用哈希槽,而不是一致性哈希,为什么?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: Redis为何用哈希槽而不用一致性哈希? 最近…...
)
STC15单片机定时器T0配置详解:从1T/12T模式选择到1秒精准定时(附完整代码)
STC15单片机定时器T0配置实战:1秒精准定制的全流程解析 从理论到实践的定时器T0深度探索 在嵌入式系统开发中,定时器功能如同系统的心跳,为各类任务提供精准的时间基准。STC15系列单片机凭借其高性能和丰富的外设资源,成为许多开…...

AI 高性能笔记本电脑高效紧凑型功率 MOSFET 完整选型方案
随着 AI 算力在笔记本电脑中的爆发式增长(如本地大模型、智能温控、性能调度),电源架构对功率 MOSFET 提出严苛要求:超高电流密度、极低损耗、超小封装、逻辑电平驱动。微碧半导体(VBsemi)基于先进的 Trenc…...

减肥成功的人,都有这 4 个共同点
减肥成功的人,都有这 4 个共同点 为什么你总是减肥失败,而有的人却轻松瘦下来不反弹? 今天告诉你真相 👇 01| 吃够基础代谢值 ❌ 极端节食 → 代谢下降 → 越减越肥 ✅ 男生 ≥1400 大卡,女生 ≥1100 大卡 …...
)
仅限内部团队流通的Perplexity调试日志解析手册:5类query失败根因定位图谱(含curl+curl-debug完整链路)
更多请点击: https://codechina.net 第一章:Perplexity技术文档查询 Perplexity 是一种衡量语言模型预测能力的核心指标,其值越低,表明模型对给定文本序列的不确定性越小,预测越精准。在技术文档查询场景中࿰…...

UE5新手避坑指南:从导入FBX模型到材质贴图,搞定你的第一个Submarine Actor
UE5新手避坑实战:从模型导入到材质优化的全流程解决方案 当第一次打开虚幻引擎5的编辑器界面时,大多数初学者都会被其强大的功能和复杂的界面所震撼。作为次世代游戏开发的核心工具,UE5带来了Nanite虚拟几何体、Lumen全局光照等革命性技术&a…...
)
Perplexity营养分析准确率跃升至92.4%(临床营养师实测验证版)
更多请点击: https://codechina.net 第一章:Perplexity营养饮食查询 Perplexity 是一款基于大语言模型的实时问答引擎,其核心优势在于可直接引用权威来源(如 USDA FoodData Central、WHO 营养指南、PubMed 文献等)进…...

【语音检测】基于matlab GUI短时自相关的基音周期检测【含Matlab源码 15451期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

网络排障利器netstat:从TCP状态机到实战故障排查
1. 网络排障的“听诊器”:为什么是netstat?在服务器运维、后端开发或者日常处理网络问题的过程中,我们经常会遇到一些让人头疼的场景:服务端口明明启动了,客户端却死活连不上;服务器负载莫名飙升࿰…...

Cadence Allegro实战:除了Shape Keepout,还有哪些方法能精准控制铺铜区域?
Cadence Allegro实战:5种精准控制铺铜区域的进阶技巧 在复杂PCB设计中,铺铜区域的控制往往决定了信号完整性和EMC性能。Shape Keepout虽然是设计师最熟悉的工具,但Allegro其实提供了更丰富的"Areas"类命令集。本文将深入解析Route …...
)
告别WinForm!用C#和MetroFramework快速搭建现代化工控上位机UI(附完整源码)
用C#和MetroFramework打造现代化工控上位机界面的实战指南 在工业自动化领域,上位机软件的用户体验往往被忽视。许多工程师仍然在使用传统的WinForm开发界面,这些界面虽然功能完备,但视觉效果和交互体验已经远远落后于现代软件的标准。本文将…...