Kafka集群安装与部署
集群规划

准备工作
安装
安装包下载:链接:https://pan.baidu.com/s/1BtSiaf1ptLKdJiA36CyxJg?pwd=6666
Kafka安装与配置
1、上传并解压安装包
tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/moudle/
2、修改解压后的文件名称
mv kafka_2.12-3.3.1/ kafka ![]()
3、进入到/opt/module/kafka目录,修改配置文件
cd /opt/moudle/kafka/config/vim server.properties输入以下内容:
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=0#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop102:9092
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/moudle/kafka/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
4、分发安装包
xsync kafka/5、分别在hadoop103和hadoop104上修改配置文件
/opt/module/kafka/config/server.properties中的broker.id及advertised.listeners
注:broker.id不得重复,整个集群中唯一。
[root@hadoop103 module]$ vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop103:9092
[root@hadoop104 module]$ vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop104:9092
6、配置环境变量
(1)在/etc/profile.d/my_env.sh文件中增加kafka环境变量配置
vim /etc/profile.d/my_env.sh增加如下内容
#KAFKA_HOME
export KAFKA_HOME=/opt/moudle/kafka
export PATH=$PATH:$KAFKA_HOME/bin
(2)刷新一下环境变量。
source /etc/profile(3)分发环境变量文件到其他节点,并source。
[root@hadoop102 moudle]$ sudo /home/user/bin/xsync /etc/profile.d/my_env.sh
[root@hadoop103 moudle]$ source /etc/profile
[root@hadoop104 moudle]$ source /etc/profile
7、启动集群
(1)先启动Zookeeper集群,然后启动Kafka。
在Hadoop102上执行
zk.sh start(2)依次在hadoop102、hadoop103、hadoop104节点上启动Kafka。
进入/opt/moudle/kafka
bin/kafka-server-start.sh -daemon config/server.properties注意:配置文件的路径要能够到server.properties。
(3)查看进程
xcall jps8、关闭集群
(1)依次在hadoop102、hadoop103、hadoop104节点上停止Kafka。
/opt/moudle/kafka
bin/kafka-server-stop.sh(2)查看进程
xcall jps集群启停脚本
1)在/home/user/bin目录下创建文件kf.sh脚本文件
cd /home/user/binvim kf.sh脚本如下:
#! /bin/bashcase $1 in
"start"){for i in hadoop102 hadoop103 hadoop104doecho " --------启动 $i Kafka-------"ssh $i "/opt/moudle/kafka/bin/kafka-server-start.sh -daemon /opt/moudle/kafka/config/server.properties"done
};;
"stop"){for i in hadoop102 hadoop103 hadoop104doecho " --------停止 $i Kafka-------"ssh $i "/opt/moudle/kafka/bin/kafka-server-stop.sh "done
};;
esac
2)添加执行权限
chmod +x kf.sh3)启动集群命令
kf.sh start4)停止集群命令
kf.sh stop注意:停止Kafka集群时,一定要等Kafka所有节点进程全部停止后再停止Zookeeper集群。因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
相关文章:

Kafka集群安装与部署
集群规划 准备工作 安装 安装包下载:链接:https://pan.baidu.com/s/1BtSiaf1ptLKdJiA36CyxJg?pwd6666 Kafka安装与配置 1、上传并解压安装包 tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/moudle/2、修改解压后的文件名称 mv kafka_2.12-3.3.1/ kafka…...
C++初阶(十一) list
一、list的介绍及使用 1.1 list的介绍 list的文档介绍 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点…...
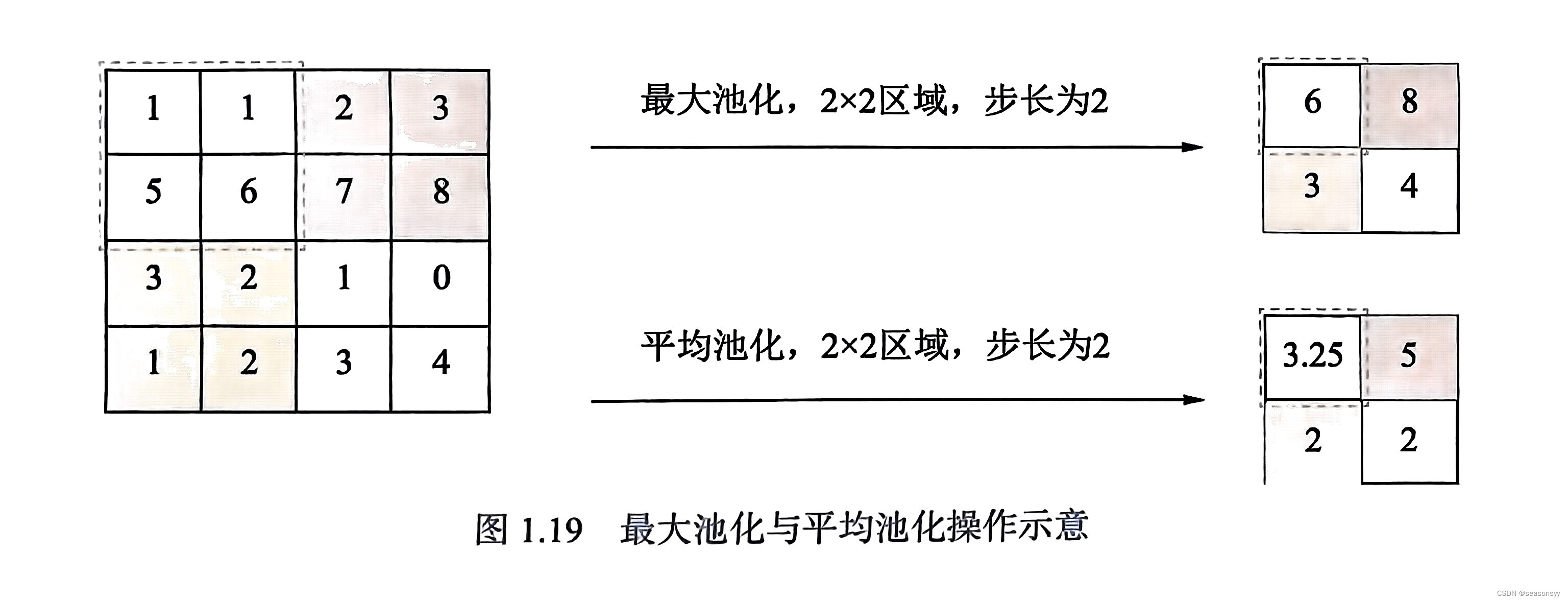
图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化
图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化 卷积神经网络的一些基本概念:图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化 1.图像卷积、步长、填充 图像卷积:卷积核矩阵在一个原始图像矩阵上 “从上往下、…...
CMake进行C/C++与汇编混合编程
1. 前提 这篇文章记录一下怎么用CMake进行项目管理, 并用C/C和汇编进行混合编程, 为了使用这项技术, 必须在VS的环境中安装好cmake组件 由于大部分人不会使用C/C与汇编进行混合编程的情况。所以这篇文章并不适用于绝大部分人不会对其中具体细节进行过多叙述。只是做一些简单的…...

缓存预热!真香
预热一般指缓存预热,一般用在高并发系统中,为了提升系统在高并发情况下的稳定性的一种手段。 缓存预热是指在系统启动之前或系统达到高峰期之前,通过预先将常用数据加载到缓存中,以提高缓存命中率和系统性能的过程。缓存预热的目…...

VS中设置#define _CRT_SECURE_NO_WARNINGS的原因和设置方式
原因: 在编译老的用C语言的开源项目的时候,可能因为一些老的.c文件使用了strcpy,scanf等不安全的函数,而报警告和错误,而导致无法编译通过。 解决方案: 我们有两种解决方案: 1、在指定的源文件的开头定…...
【网站项目】155在线考试与学习交流网页平台
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...
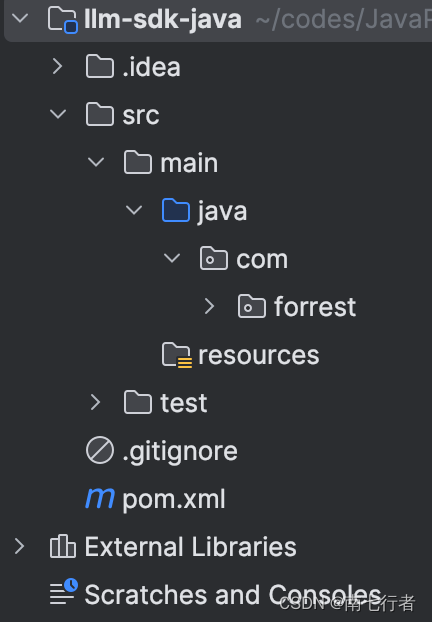
解决IDEA的Project无法正常显示的问题
一、问题描述 打开IDEA,结果发现项目结构显示有问题: 二、解决办法 File -> Project Structure… -> Project Settings (选Modules),然后导入Module 结果: 补充: IDEA提示“The imported module settings a…...

CDF和PDF的比较
以下内容来自ChatGPT,科技改变生活 Cumulative Distribution Function (CDF)(累积分布函数)和 Probability Density Function (PDF)(概率密度函数)是统计学和概率论中两个重要的概念,用于描述随机变量的性…...

编译基本过程 预处理器
编译基本过程 源代码(main.c)->预处理器(cpp)->编译器(gcc/clang/msvc)->汇编器(as)->链接器(ld)->可执行文件(main.exe) 预处理器 C语言中预处理器:执行预处理命令(文件包含、宏替换、条件编译)处理注释(将所有注释替换为空格)处理续行符(将所有…...

模拟算法.
1.什么是模拟 在信息奥赛中,有一类问题是模拟一个游戏的对弈过程或者模拟一项任务的操作过程.比如乒乓球在比赛中模拟统计记分最终判断输赢的过程等等,这些问题通常很难通过建立数学模型用特定的算法来解决因为它没有一种固定的解法,需要深刻理解出题者对过程的解释一般只能采…...

ClickHouse--10--临时表、视图、向表中导入导出数据
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.临时表1.1 特征1.2 创建一个临时表 2.视图2.1 普通视图2.2 物化视图 3.向表中导入导出数据3.1 案例 1.临时表 1.1 特征 ClickHouse 支持临时表,临时表…...

Python一些可能用的到的函数系列124 GlobalFunc
说明 GlobalFunc是算网的下一代核心数据处理基础。 算网是一个分布式网络,为了能够实现真的分布式计算(加快大规模任务执行效率),以及能够在很长的时间内维护不同版本的计算方法,需要这样一个对象/服务来支撑。Globa…...

python中线程/线程池,进程/进程池的创建
创建子线程 # 创建子线程t1 threading.Thread(targetjob,args(1,))# 执行子线程t1.start()# 等待子线程执行print("waiting threading")t1.join()print("threading done")创建子进程 # 创建子进程p1 multiprocessing.Process(targetjob,args(1,),name&qu…...

【c++】vector的增删查改
1.先定义一个类对象vector 为了防止和库里面发生冲突,定义一个命名空间,将类对象放在命名空间 里面 #include<iostream> using namespace std; namespace zjw {class vector {public:private:}; }2.定义变量,需要一个迭代器ÿ…...
【研究生复试】计算机软件工程人工智能研究生复试——资料整理(速记版)——JAVA
1、JAVA 2、计算机网络 3、计算机体系结构 4、数据库 5、计算机租场原理 6、软件工程 7、大数据 8、英文 自我介绍 1. Java 1. 和 equals的区别 比较基本数据类型是比较的值,引用数据类型是比较两个是不是同一个对象,也就是引用是否指向同 一个对象&…...

JVM-JVM中对象的生命周期
申明:文章内容是本人学习极客时间课程所写,文字和图片基本来源于课程资料,在某些地方会插入一点自己的理解,未用于商业用途,侵删。 原资料地址:课程资料 对象的创建 常量池检查:检查new指令是否能在常量池…...
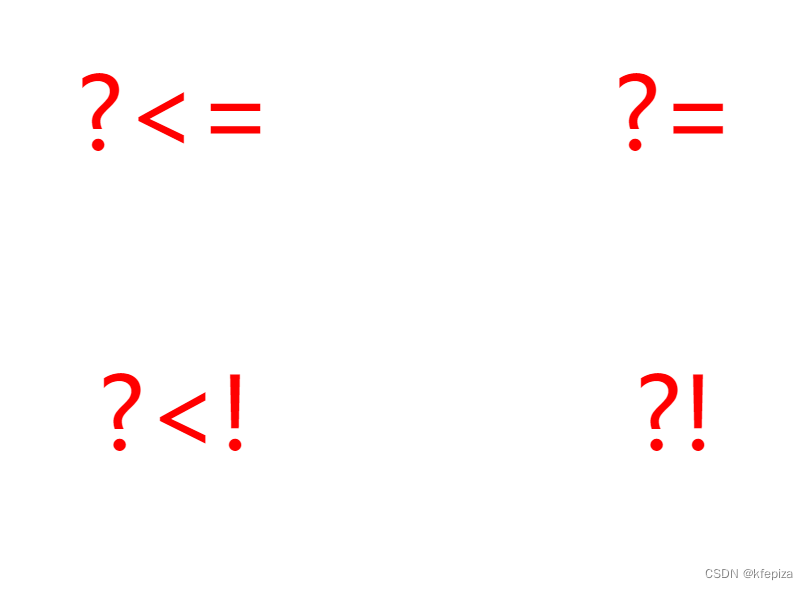
RegExp正则表达式左限定右限定左右限定,预查询,预查寻,断言 : (?<= , (?= , (?<! , (?!
RegExp正则表达式左限定右限定左右限定,预查询,预查寻,断言 : (?< , (? , (?<! , (?! 有好多种称呼 (?< , (? , (?<! , (?! 有好多种称呼 , 我称为: 左限定, 右限定, 左否定, 右否定 (?<左限定) (?右限定)(?<!左否定) (?!右限定) 再…...

相机图像质量研究(30)常见问题总结:图像处理对成像的影响--重影
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...
问题记录——c++ sort 函数 和 严格弱序比较
引出 看下面这段cmp函数的定义 //按照vector第一个元素升序排序 static bool cmp(const vector<int>& a, const vector<int>& b){return a[0] < b[0]; }int eraseOverlapIntervals(vector<vector<int>>& intervals) {//按区间左端排序…...
)
手把手教你用ROS小车仿真搞定LIO-SAM建图与NDT定位(附避坑配置)
从零实现ROS仿真环境下的LIO-SAM建图与NDT定位全流程指南 在机器人自主导航领域,激光雷达与惯性测量单元(IMU)的融合建图定位技术已成为工业级应用的主流方案。本文将基于steer_mini_gazebo仿真平台,完整演示如何配置LIO-SAM实时建图系统与Autoware的ND…...
)
CodeBlocks 20.03 安装与汉化保姆级教程(附中文包下载与常见问题解决)
CodeBlocks 20.03 安装与汉化全流程实战指南 对于刚接触C/C开发的初学者来说,选择一款合适的集成开发环境(IDE)是迈入编程世界的第一步。CodeBlocks以其轻量级、跨平台和开源免费的特性,成为众多教育机构和自学者的首选。本文将带你从零开始,…...

Inter字体终极指南:如何为现代数字界面选择最佳开源字体方案?
Inter字体终极指南:如何为现代数字界面选择最佳开源字体方案? 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为数字屏幕精心设计的开源无衬线字体系统,通过科学…...
)
告别卡顿!用WebRTC-Streamer在浏览器里丝滑播放海康/大华监控(附完整代码)
告别卡顿!用WebRTC-Streamer在浏览器里丝滑播放海康/大华监控(附完整代码) 监控视频的实时查看一直是许多开发者和运维人员头疼的问题。传统的解决方案如Flash早已被淘汰,而基于FLV.js的方案又常常面临延迟高、卡顿、标签页切换暂…...

别再只画光路了!用OpticStudio偏振光瞳图,一眼看懂你的激光系统偏振态
激光系统偏振态可视化:OpticStudio偏振光瞳图实战指南 在激光光学系统设计中,偏振态管理往往是被低估的关键环节。一个常见的误区是设计师过度关注几何光路而忽视偏振演变,直到系统出现无法解释的能量损耗或信号失真时才追悔莫及。传统的光线…...
)
手把手教你用STM32F103驱动TLC7528双路DAC(附完整代码与避坑指南)
手把手教你用STM32F103驱动TLC7528双路DAC(附完整代码与避坑指南) 在嵌入式开发中,数字模拟转换器(DAC)是实现数字信号到模拟信号转换的关键组件。TLC7528作为一款经典的双路8位DAC芯片,以其高性价比和简单…...
)
2023B卷,跳格子(1)
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,跳格子(1) 。 1.1 ☘️题目详情 题目: 小明和朋友…...

3分钟解决游戏操作冲突:Hitboxer SOCD工具让你的键盘操作职业化
3分钟解决游戏操作冲突:Hitboxer SOCD工具让你的键盘操作职业化 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在玩《街头霸王6》时连招总是失败?或者在《Apex英雄》中急停转向时…...

图像采集卡与相机内置采集:架构差异、性能对比与选型指南
1. 项目概述:从“外挂”到“内置”的采集路径之争在视觉系统集成或工业检测项目里,选型阶段总会遇到一个基础但关键的问题:图像采集卡和相机内置的采集功能,到底该用哪个?这可不是一个简单的“哪个更好”的问题&#x…...

OBS高级遮罩插件:15种专业遮罩技术的完整技术解析与实战应用
OBS高级遮罩插件:15种专业遮罩技术的完整技术解析与实战应用 【免费下载链接】obs-advanced-masks Advanced Masking Plugin for OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-masks 在视频制作与直播领域,遮罩技术是区分业余与…...