文章复现 | 差异分析和PPI网络构建
原文链接:差异分析和PPI网路图绘制教程
写在前面
在原文中,作者获得285个DEG,在此推文中共获得601个DEG。小杜的猜想是标准化的水段不同的原因吧,或是其他的原因。此外,惊奇的发现发表医学类的文章在附件中都不提供相关的信息文件,如DEG数据、GO、KEGG富集信息,或是其他相关的文件。唉!!!难道是怕别人复现结果不一致?仅仅提供对读者不关心的文件信息,我们猜想,这是不是期刊要求必须有附件,所以才产生两个文件呢????

获得本期教程数据和代码,后台回复关键词:20240218
若我们的分享对你有用,希望您可以点赞+收藏+转发,这是对小杜最大的支持。
2.4.1 原文中差异分析

原文中的结果描述,, we screened 471DEGs between therenal fibrosis group and the control group in GSE76882 using the R package “limma”

原文中图形


2.4.2 关于GSE76882数据集
共有274个数据集,其中99个对照组,175个肾纤维化样本。

作者这里就只是简单的分类而已,若细致的分,这里有些数据是可以不被使用的。

对下载的数据集进行分析可获得,前175列数据作为处理组,后99列数据作为对照组。
注意:你需要核对下载后的数据集与GEO数据库中信息是否一致。

2.4.3 差异分析
我们并不知道作者使用那种标准化手段处理数据。首先,我使用log2(x+1)的方式进行标准化,并使用其后面的数据进行差异分析。
2.4.3.1 数据标准化
##'@GSE76882标准化
df02 <- read.csv("00.GEO_RawData/GSE76882_uniq.exp.csv",header = T, row.names = 1)
nor82 <- log2(df02+1)
nor82[1:10,1:10]
write.csv(nor82,"01.GEO_norData/GSE76882_Nor.csv")
2.4.3.2 差异分析代码
- 创建文件夹和导入相关的包
dir.create('02.DEGs_analysis', recursive = TRUE)
library(limma)
library(dplyr)
- 导入数据
csv文件或TXT文件格式
##'##'@读取txt文件格式
#df <- read.table("***.txt", header = T, sep = "\t", row.names = 1, check.names = F)
##'@读取csv文件格式
df <- read.csv("01.GEO_norData/GSE76882_Nor.csv", header = T, check.names = F)

3. 创建比对文件信息
(1) 若你的数据样本不是统一的,需要知道详细信息代表什么。你可以这样创建。
group.list <- c(rep("normal", 25), rep("tumor",24), rep("tumor",42), rep("normal",99)) %>% factor(., levels = c("normal", "tumor"), ordered = F)
获得临床信息方法一
(2)若表达矩阵信息与我们这里一致,那么你可以直接创建即可。
**问:**如何将我们的表达矩阵按分类进行排列。
可以使用下来方法
A. 手动在execl中进行排列,在50个样本数据以内可以使用此方法。
B. 使用一下的方法(仅供参考)

复制这些信息到execl中,排列顺序。

输出样本信息数据

使用R语言进行重新排列矩阵的列
##'@读取csv文件格式
df <- read.csv("01.GEO_norData/GSE76882_Nor.csv", header = T)
df[1:10,1:10]
##'@样本信息顺序,已在execl中排序
df3 <- read.csv("02.DEGs_analysis/001_样本信息.csv",header = F)
head(df3)
##'@样本顺序转换为字符向量
sample_order <- as.character(df3$V1)
##'@对表达量矩阵的列进行重新排列
df_reordered <- df[,c("X",sample_order)]df_reordered[1:10,1:10]


获取临床信息方法二 (推荐)
在下载数据时就需要添加临床信息的参数
2023年《生信知识库》访问网址,此系列专栏已订阅无需重复订阅,订阅后所有教程都可以在此链接中获得。
s
如下例:
gset_GSE76882 <- getGEO("GSE76882", destdir = '.',AnnotGPL = T,GSEMatrix =T, getGPL=T)
save(gset_GSE76882 , file = 'GSE76882_eSet.Rdata')# ## 提取数据
# gset=gset[[1]]
# exprSet1 = exprs(gset)
# #exprSet1 = read.csv("GSE51588.csv",row.names = 1) #####rowname=1很重要
# exprSet1[1:5,1:5]
# # 导出结果
# write.csv(exprSet1, file = "00.GEO_RawData/GSE76882_raw.data.csv",row.names = T,quote = F)load('GSE76882_eSet.Rdata')## 提取数据
exp_GSE76882 <- exprs(gset_GSE76882[[1]])##'依旧推荐使用我们的方法
## 转换ID
##'@加载family.soft文件
anno <-data.table::fread("00.GEO_RawData/GSE76882_family.soft",skip ="ID",header = T)
anno[1:5,1:8]#colnames(anno)[6] <- "Symbol"probe2symbol <- anno %>%dplyr::select("ID","Gene Symbol") %>% dplyr::rename(probeset = "ID",symbol="Gene Symbol") %>%filter(symbol != "") %>%tidyr::separate_rows( `symbol`,sep="///")
## 导出 gene symbol数据集合
write.csv(probe2symbol,"00.GEO_RawData/GSE76882_geneSymbol_ID.csv", )
probe2symbol[1:10,1:2]
##
exprSet <- exprSet1 %>% as.data.frame() %>%rownames_to_column(var="probeset") %>% #合并的信息inner_join(probe2symbol,by="probeset") %>% #去掉多余信息dplyr::select(-probeset) %>% #重新排列dplyr::select(symbol,everything()) %>% #求出平均数(这边的点号代表上一步产出的数据)mutate(rowMean =rowMeans(.[grep("GSM", names(.))])) %>% #去除symbol中的NAfilter(symbol != "NA") %>% #把表达量的平均值按从大到小排序arrange(desc(rowMean)) %>% # symbol留下第一个distinct(symbol,.keep_all = T) %>% #反向选择去除rowMean这一列dplyr::select(-rowMean) %>% # 列名变成行名column_to_rownames(var = "symbol")## 导出数据
write.csv(exprSet,"00.GEO_RawData/GSE76882_uniq.exp.csv",row.names = T)##----------------------------------------------------------------------------
pd_GSE76882 <- pData(gset_GSE76882[[1]]) # 获取第一个样本的临床信息group_GSE76882 <- ifelse(str_detect(pd_GSE76882$title, "tumor"), "Tumor", "Normal")
table(group_GSE76882)
group <- factor(group_GSE76882, levels = c("Normal","Tumor"))
## 重新名称
group_list <- ifelse(group == "Tumor", 1,ifelse(group == "Normal", 0,NA))
group_list <- as.character(group_list)
limma分析代码
原文链接:差异分析和PPI网路图绘制教程
design <- model.matrix(~0 + BC_group, )
colnames(design) <- c("Tumor", "normal")
# Fit a linear model
fit1 <- lmFit(exptotal_df, design)##
cont.matrix_bc <- makeContrasts(Tumor - normal, levels = design)
fit2 <- contrasts.fit(fit1, cont.matrix_bc)# Estimate differential expression using eBayes
fit3 <- eBayes(fit2,0.01)
summary(fit3)
#############
tempOutput <- topTable(fit3, coef= 2, adjust.method="BH", sort.by="B", number=Inf)##
nrDEG = na.omit(tempOutput)
diffsig <- nrDEG
write.csv(diffsig, "01.limmaOut.csv") ## 输出差异分析后的基因数据集
##
## 筛选出差异表达的基因
foldChange = 1
padj = 0.05
All_diffSig <- diffsig[(diffsig$adj.P.Val < padj & (diffsig$logFC>foldChange | diffsig$logFC < (-foldChange))),]
dim(All_diffSig)
write.csv(All_diffSig, "02.diffsig.csv") ##输出差异基因数据集
## 筛选 up and down gene number
diffup <- diffsig[(diffsig$adj.P.Val < padj & (diffsig$logFC > foldChange)),]
write.csv(diffup, "03.diffup.csv")
#
diffdown <- diffsig[(diffsig$adj.P.Val < padj & (diffsig < -foldChange)),]
write.csv(diffdown, "04.diffdown.csv")

2.4.4 绘制火山图
# 绘制火山图
library(ggplot2)
library(ggrepel)
#diffsig <- read.csv("01.TGCA.all.limmaOut-02.csv", header = T, row.names = 1)
data <- diffsig
# 绘制火山图
logFC <- diffsig$logFC
deg.padj <- diffsig$P.Value
data <- data.frame(logFC = logFC, padj = deg.padj)
data$group[(data$padj > 0.05 | data$padj == "NA") | (data$logFC < logFC) & data$logFC > -logFC] <- "Not"
data$group[(data$padj <= 0.05 & data$logFC > 1)] <- "Up"
data$group[(data$padj <= 0.05 & data$logFC < -1)] <- "Down"
x_lim <- max(logFC,-logFC)
###
pdf('02.DEGs_analysis/05.volcano.pdf',width = 7,height = 6.5)
label = subset(diffsig,P.Value <0.05 & abs(logFC) > 1)
label1 = rownames(label)colnames(diffsig)[1] = 'log2FC'
Significant=ifelse((diffsig$P.Value < 0.05 & abs(diffsig$log2FC)> 1), ifelse(diffsig$log2FC > 1,"Up","Down"), "Not")ggplot(diffsig, aes(log2FC, -log10(P.Value)))+geom_point(aes(col=Significant))+scale_color_manual(values=c("#0072B5","grey","#BC3C28"))+labs(title = " ")+## 修改x轴中logFC数值geom_vline(xintercept=c(-1,1), colour="black", linetype="dashed")+## 修改Y轴中logP值,基本不会改变,可以忽略geom_hline(yintercept = -log10(0.05),colour="black", linetype="dashed")+theme(plot.title = element_text(size = 16, hjust = 0.5, face = "bold"))+## X/Y轴中命名labs(x="log2(FoldChange)",y="-log10(Pvalue)")+theme(axis.text=element_text(size=13),axis.title=element_text(size=13))+str(diffsig, max.level = c(-1, 1))+theme_bw()dev.off()


2.4.5 绘制热图
## 绘制差异热图
library(pheatmap)
DEG_id <- read.csv("02.DEGs_analysis/06_DEG_ID.csv", header = T)
## 匹配
DEG_id <- unique(DEG_id$ID)
ID <- as.factor(DEG_id)
head(ID)
dim(ID)
DEG_exp <- df03[ID,]
hmexp <- na.omit(DEG_exp)
#hmexp <- t(hmexp)
hmexp[1:10,1:10]#write.csv(hmexp, "DEG.Exp.csv")
#
annotation_col <- data.frame(Group = factor(c(rep("normal",99), rep("tumor",175))))
rownames(annotation_col) <- colnames(hmexp)pdf("02.DEGs_analysis/07.heatmap.pdf", height = 8, width = 12)
pheatmap(hmexp,annotation_col = annotation_col,color = colorRampPalette(c("blue","white","red"))(100),cluster_cols = F,cluster_rows = F,show_rownames = F,show_colnames = F,scale = "row", ## none, row, columnfontsize = 12,fontsize_row = 12,fontsize_col = 6,border = FALSE)
dev.off()

绘制热图此方法仅是其中一种,大家可以使用前期的教程进行绘制更精美的图形。
2.6.1 PPI网络分析
- PPI网址
网址:
https://cn.string-db.org/

2. 输入基因ID

3. 选择Organisms,可以选择auto-detect,可以自动识别

4. 点击SEARCH

5. Please wait

6. 点击continue

7. 输出结果

注意:该图形可以进行拖动
8. 可以设置参数,可以默认参数设置
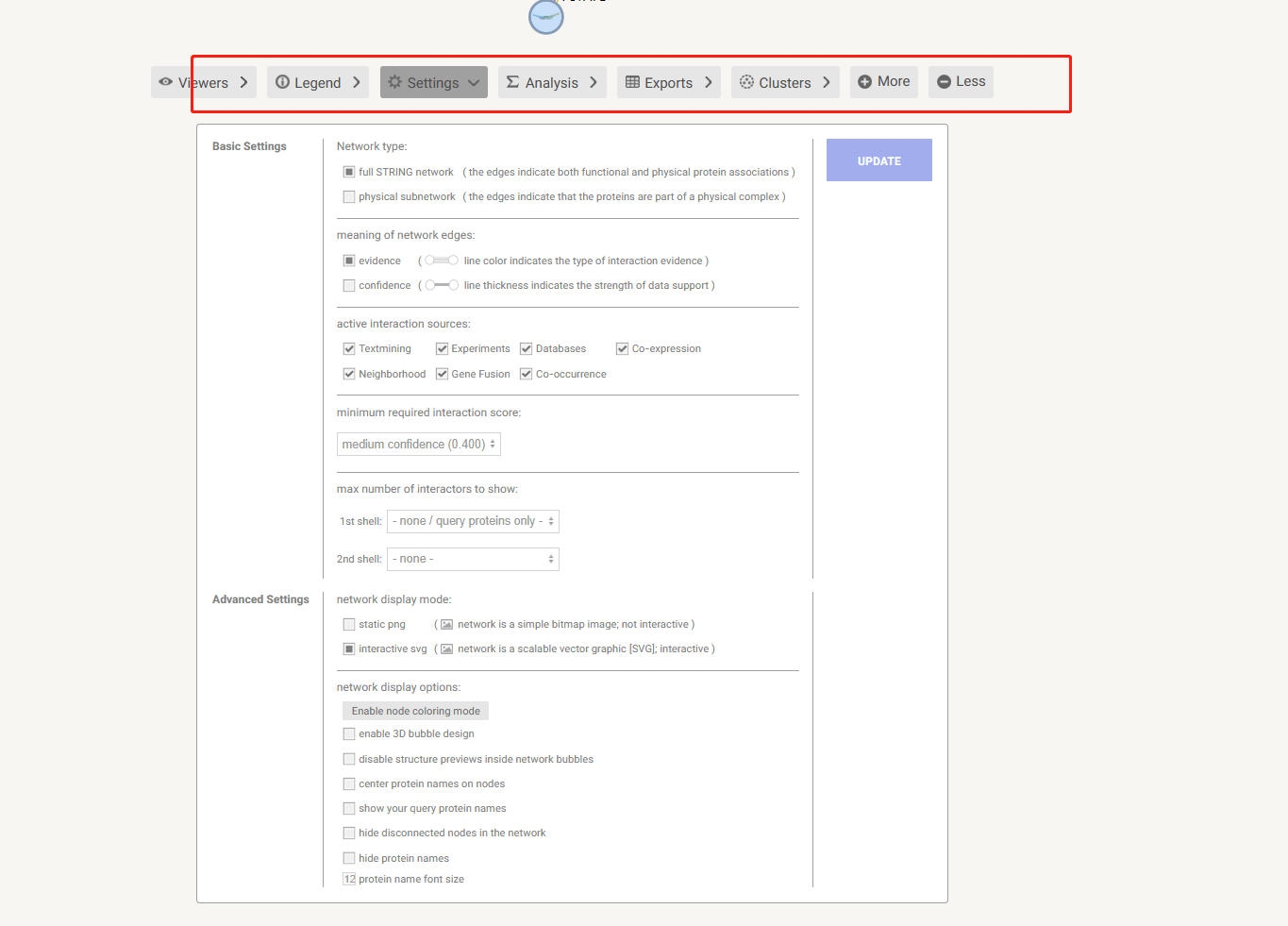
选择超过5个interactors

置信度设置

UPDATE

9. Anaysis

10. Exports

2.6.2 下载PPI结果
- 下载图片
- 输出结果文件
- 节点信息

最终分析结果


网络图输入文件

若你的Cytoscape版本较高,可以直接在PPI网页上点击send networkto Cytoscape中,在Cytoscape中直接打开。
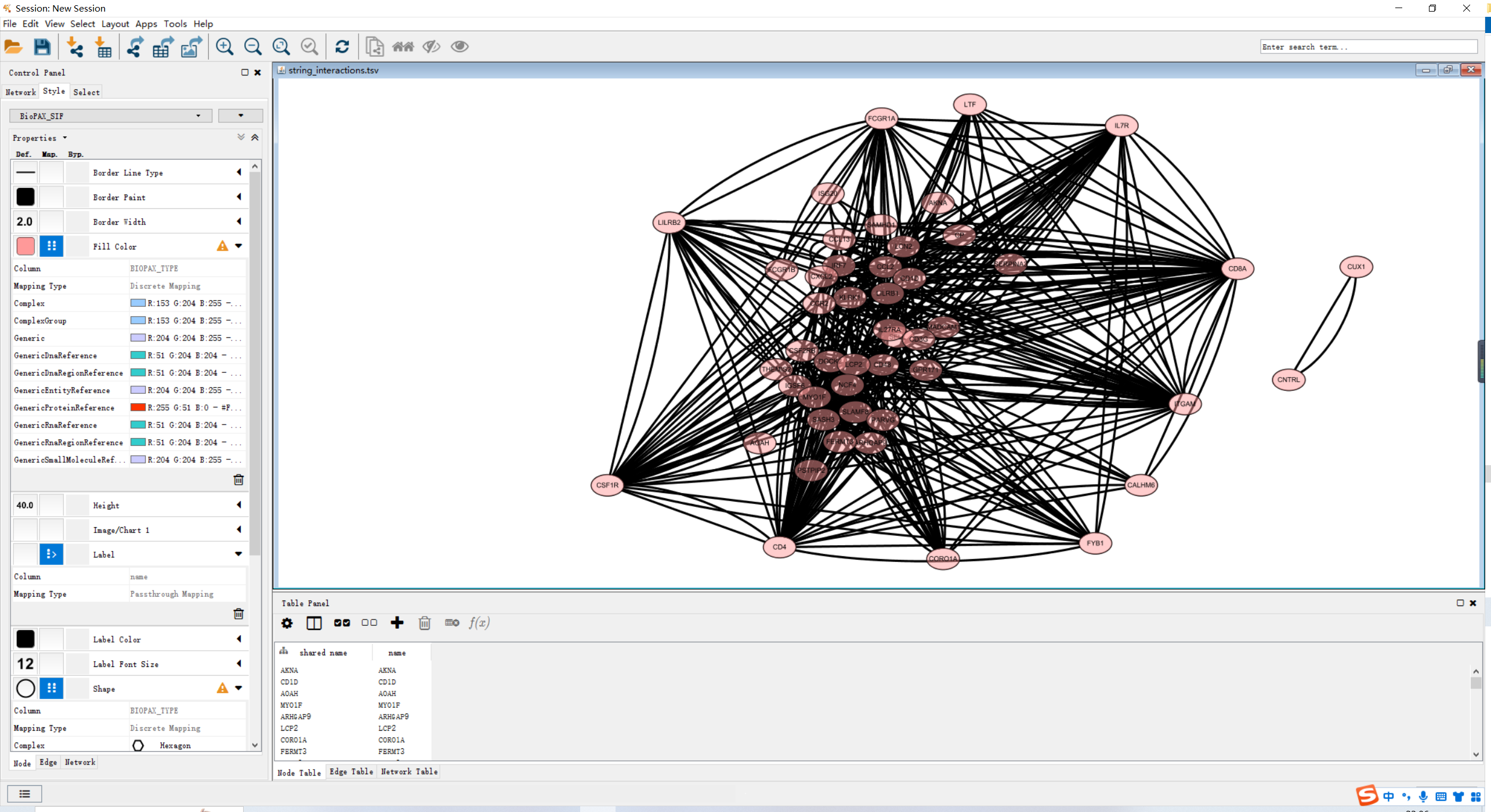
直接使用network节点信息导入,再进行调整即可。
原文链接:差异分析和PPI网路图绘制教程
详细调整参数,可以自己根据网上的教程进行制作即可。
若我们的分享对你有用,希望您可以点赞+收藏+转发,这是对小杜最大的支持。
往期文章:
1. 复现SCI文章系列专栏
2. 《生信知识库订阅须知》,同步更新,易于搜索与管理。
3. 最全WGCNA教程(替换数据即可出全部结果与图形)
-
WGCNA分析 | 全流程分析代码 | 代码一
-
WGCNA分析 | 全流程分析代码 | 代码二
-
WGCNA分析 | 全流程代码分享 | 代码三
-
WGCNA分析 | 全流程分析代码 | 代码四
-
WGCNA分析 | 全流程分析代码 | 代码五(最新版本)
4. 精美图形绘制教程
- 精美图形绘制教程
5. 转录组分析教程
转录组上游分析教程[零基础]
一个转录组上游分析流程 | Hisat2-Stringtie
小杜的生信筆記 ,主要发表或收录生物信息学的教程,以及基于R的分析和可视化(包括数据分析,图形绘制等);分享感兴趣的文献和学习资料!!
相关文章:
文章复现 | 差异分析和PPI网络构建
原文链接:差异分析和PPI网路图绘制教程 写在前面 在原文中,作者获得285个DEG,在此推文中共获得601个DEG。小杜的猜想是标准化的水段不同的原因吧,或是其他的原因。此外,惊奇的发现发表医学类的文章在附件中都不提供相…...

入门级10寸加固行业平板—EM-I10J
亿道信息以其坚固耐用的智能终端设备而闻名,近日发布了一款理想入门级 10 英寸加固平板电脑—I10J。 EM-I10J 这是一款 10 英寸的平板电脑,主要运行 Windows 10操作系统,带有硬化塑料外壳,具有 IP65 防水防尘功能和 MIL-STD 8…...

gem5 garnet 合成流量: packet注入流程
代码流程 下图就是全部. 剩下文字部分是细节补充,但是内容不变: bash调用python,用python配置好configuration, 一个cpu每个tick运行一次,requestport发出pkt. bash 启动 python文件并配置 ./build/NULL/gem5.debug configs/example/garnet_synth_traffic.py \--num-cpus…...
java实现排序算法(上)
排序算法 冒泡排序 时间和空间复杂度 要点 每轮冒泡不断地比较比较相邻的两个元素,如果它们是逆序的,则需要交换它们的位置下一轮冒泡,可以调整未排序的右边界,减少不必要比较 代码 public static int[] test(int[] array) {// 外层循环控制遍历次数for (int i 0; i <…...
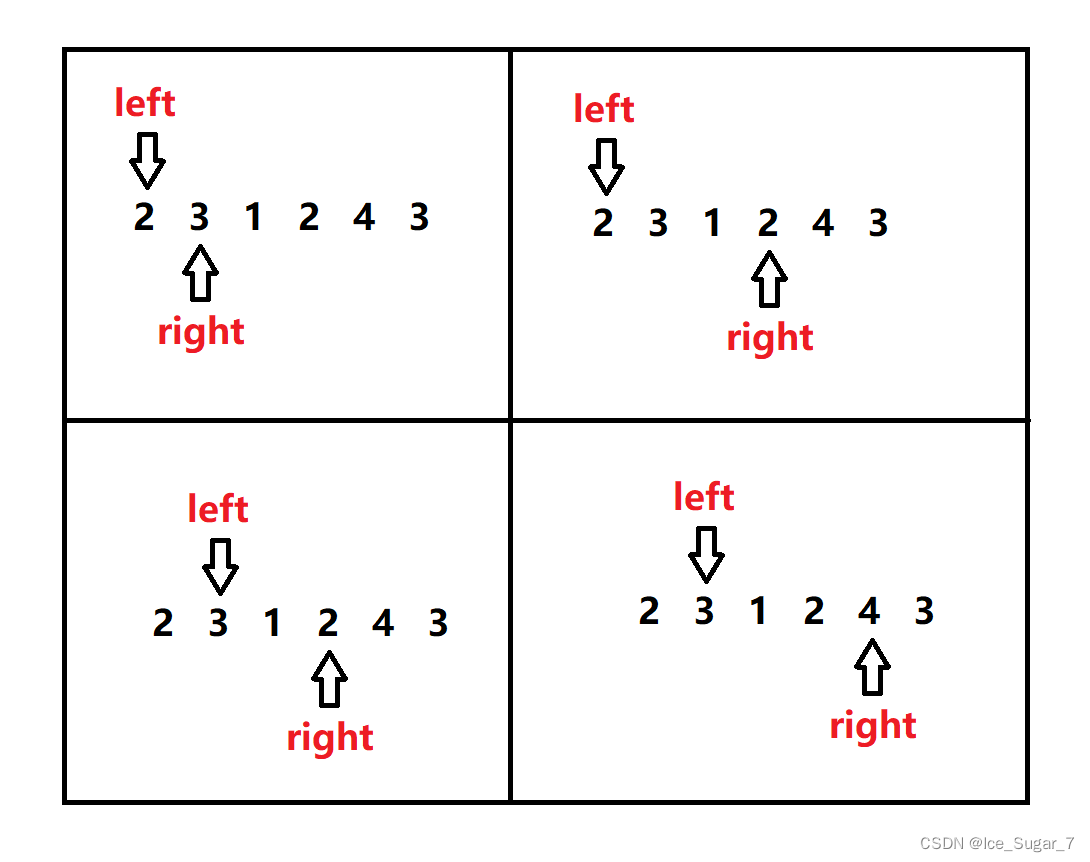
「算法」滑动窗口
前言 算法需要多刷题积累经验,所以我行文重心在于分析解题思路,理论知识部分会相对简略一些 正文 滑动窗口属于双指针,这两个指针是同向前行,它们所夹的区间就称为“窗口” 啥时候用滑动窗口? 题目涉及到“子序列…...

Windows11(非WSL)安装Installing llama-cpp-python with GPU Support
直接安装,只支持CPU。想支持GPU,麻烦一些。 1. 安装CUDA Toolkit (NVIDIA CUDA Toolkit (available at https://developer.nvidia.com/cuda-downloads) 2. 安装如下物件: gitpythoncmakeVisual Studio Community (make sure you install t…...

rtt设备io框架面向对象学习-脉冲编码器设备
目录 1.脉冲编码器设备基类2.脉冲编码器设备基类的子类3.初始化/构造流程3.1设备驱动层3.2 设备驱动框架层3.3 设备io管理层 4.总结5.使用 1.脉冲编码器设备基类 此层处于设备驱动框架层。也是抽象类。 在/ components / drivers / include / drivers 下的pulse_encoder.h定义…...
)
华为OD机试真题- 攀登者2-2024年OD统一考试(C卷)
题目描述: 攀登者喜欢寻找各种地图,并且尝试攀登到最高的山峰。地图表示为一维数组,数组的索引代表水平位置,数组的高度代表相对海拔高度。其中数组元素0代表地面。例如[0,1,4,3,1,0,0,1,2,3,1,2,1,0], 代表如下图所示的地图,地图中有两个山脉位置分别为 1,2,3,4,5和8,9,1…...
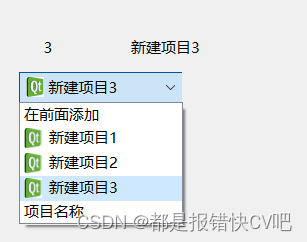
19.Qt 组合框的实现和应用
目录 前言: 技能: 内容: 1. 界面 2.槽 3.样式表 参考: 前言: 学习QCombox控件的使用 技能: 简单实现组合框效果 内容: 1. 界面 在ui编辑界面找到input widget里面的comboBoxÿ…...
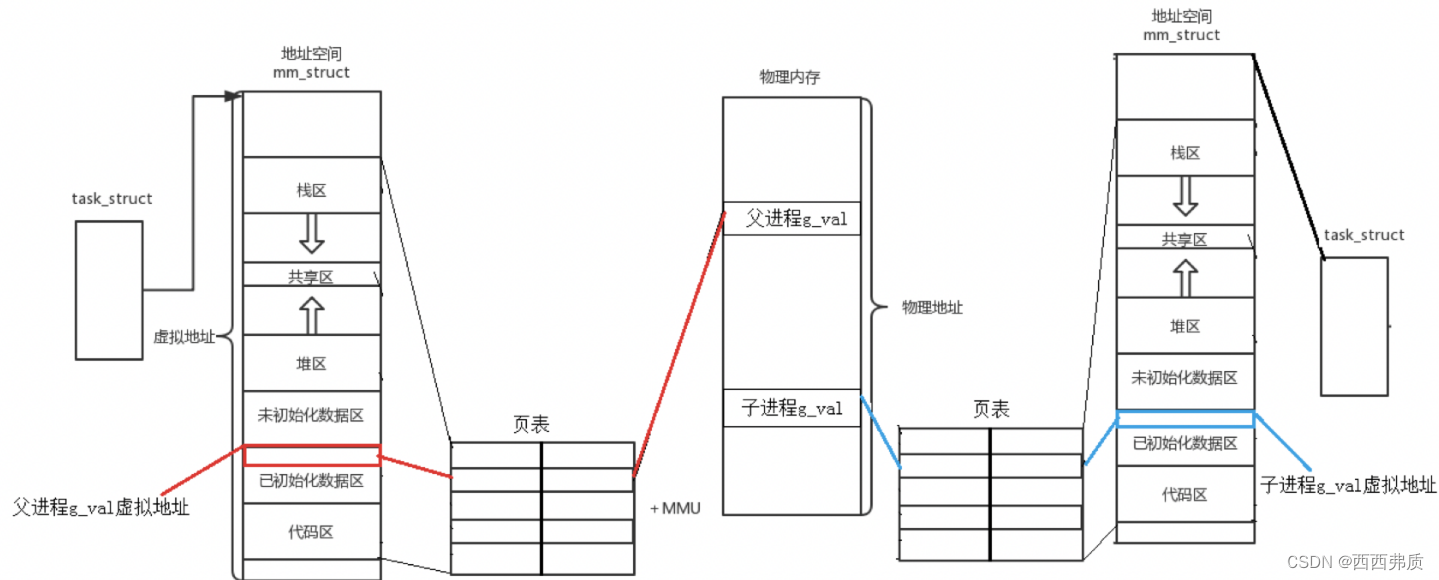
【Linux】进程地址空间的理解
进程地址空间的理解 一,什么是程序地址空间二,页表和虚拟地址空间三,为什么要有进程地址空间 一,什么是程序地址空间 在我们写程序时,都会有这样下面的内存结构,来存放变量和代码等数据。 一个进程要执行…...
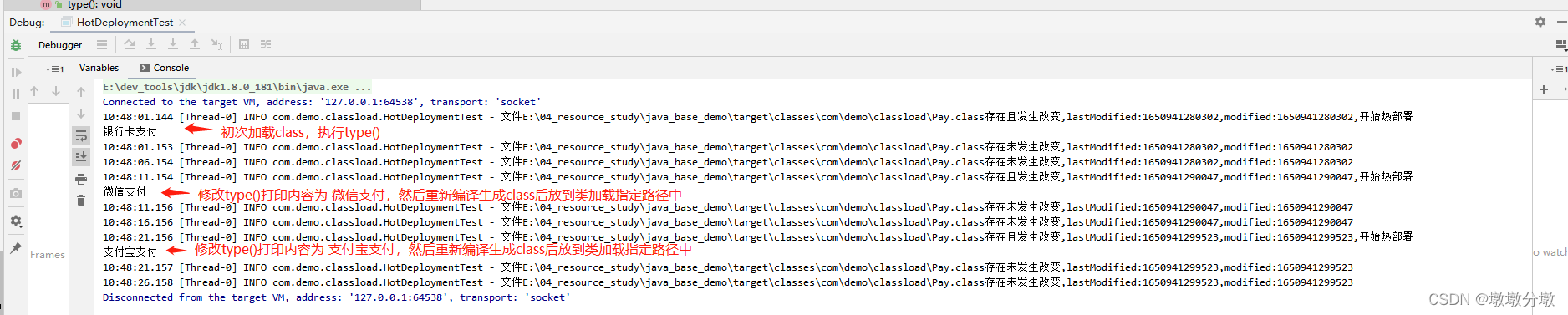
【Jvm】类加载机制(Class Loading Mechanism)原理及应用场景
文章目录 Jvm基本组成一.什么是JVM类的加载二.类的生命周期阶段1:加载阶段2:验证阶段3:准备阶段4:解析阶段5:初始化 三.类初始化时机四.类加载器1.引导类加载器(Bootstrap Class Loader)2.拓展类…...
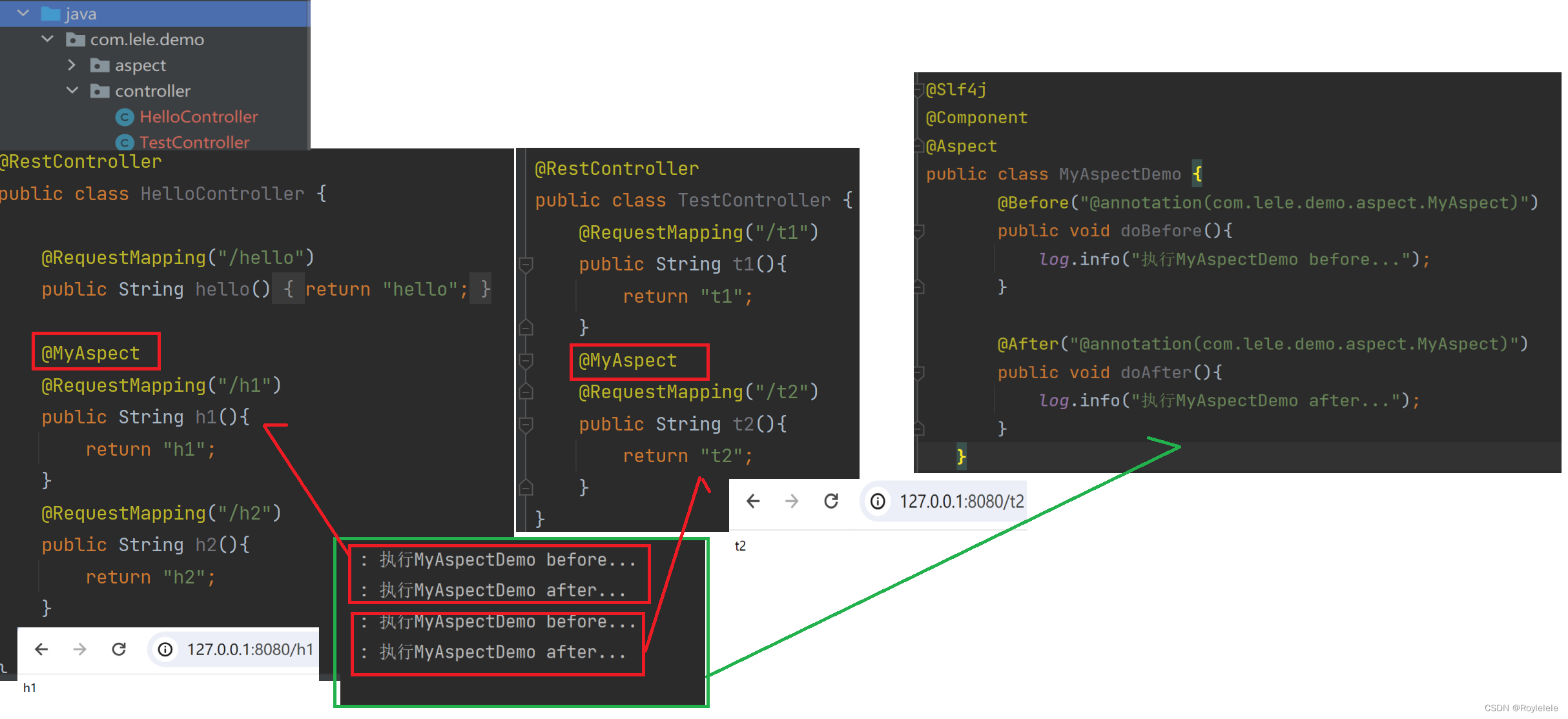
Spring AOP的实现方式
AOP基本概念 Spring框架的两大核心:IoC和AOP AOP:Aspect Oriented Programming(面向切面编程) AOP是一种思想,是对某一类事情的集中处理 面向切面编程:切面就是指某一类特定的问题,所以AOP可…...
Linux------环境变量
目录 前言 一、环境变量 二、添加PATH环境变量 三、HOME环境变量 四、查看所有环境变量 1.指令获取 2.代码获取 2.1 getenv 2.2main函数的第三个参数 2.3 全局变量environ 五、环境变量存放地点 六、添加自命名环境变量 七、系统环境变量具有全局属性 八、环境变…...

计算机视觉所需要的数学基础
计算机视觉领域中使用的数学知识广泛而深入,以下是一些关键知识点及其在计算机视觉中的应用: 线性代数: - 矩阵运算:用于图像的表示和处理,如图像旋转、缩放、裁剪等。 - 向量空间:用于描述图像中的…...
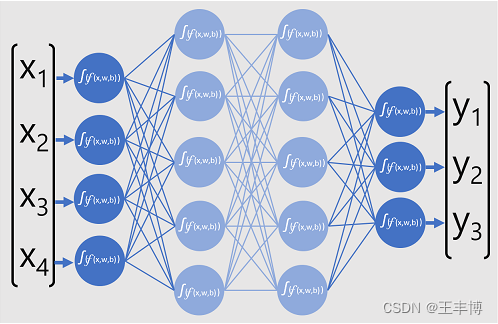
ChatGPT魔法1: 背后的原理
1. AI的三个阶段 1) 上世纪50~60年代,计算机刚刚产生 2) Machine learning 3) Deep learning, 有神经网络, 最有代表性的是ChatGPT, GPT(Generative Pre-Trained Transformer) 2. 深度神经网络 llya Suts…...

【c/c++】获取时间
在一些应用的编写中我们有时候需要用到时间,或者需要一个“锚点”来确定一些数的值。在c/c中有两个用来确定时间的函数:time/gettimeofday 一、time time_t time(time_t *timer);time 函数返回当前时间的时间戳(自 1970 年 1 月 1 日以来经…...
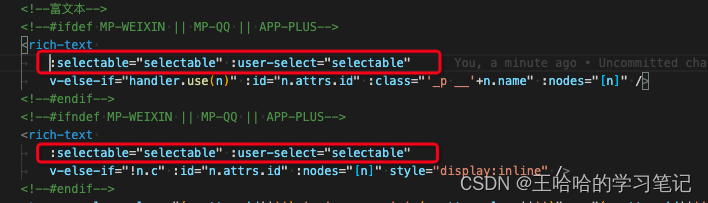
uniapp富文本文字长按选中(用于复制,兼容H5、APP、小程序三端)
方案:使用u-parse的selectable属性 <u-parse :selectable"true" :html"content"></u-parse> 注意:u-parse直接使用是不兼容小程序的,需要对u-parse进行改造: 1. 查看u-parse源码发现小程序走到以…...

常见的几种Web安全问题测试简介
Web项目比较常见的安全问题 1.XSS(CrossSite Script)跨站脚本攻击 XSS(CrossSite Script)跨站脚本攻击。它指的是恶意攻击者往Web 页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web 里面的html 代码会被执行,从而达到恶意用户的特殊…...
linux信号机制[一]
目录 信号量 时序问题 原子性 什么是信号 信号如何产生 引入 信号的处理方法 常见信号 如何理解组合键变成信号呢? 如何理解信号被进程保存以及信号发送的本质? 为什么要有信号 信号怎么用? 样例代码 core文件有什么用呢&#…...

elementui 中el-date-picker 选择年后输出的是Wed Jan 01 2025 00:00:00 GMT+0800 (中国标准时间)
文章目录 问题分析 问题 在使用 el-date-picker 做只选择年份的控制器时,出现如下问题:el-date-picker选择年后输出的是Wed Jan 01 2025 00:00:00 GMT0800 (中国标准时间),输出了两次如下 分析 在 el-date-picker 中,我们使用…...

三分钟搞定B站缓存视频:m4s转MP4的傻瓜式完整教程
三分钟搞定B站缓存视频:m4s转MP4的傻瓜式完整教程 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是不是也遇到过这样的烦恼&#…...
)
别再手动reshape了!用einops.rearrange优雅处理PyTorch张量维度(附实战代码)
用einops.rearrange重塑PyTorch张量:告别混乱的维度操作 深度学习开发中最令人头疼的莫过于张量维度的变换。你是否曾在凌晨三点盯着屏幕,试图理解自己昨天写的permute和reshape组合到底在做什么?或者花费半小时调试一个维度不匹配的错误&…...

基于Unsloth与LoRA的高效大语言模型微调工程化实践指南
1. 项目概述:一个为Unsloth优化的AI开发伴侣 如果你最近在折腾大语言模型(LLM)的微调,尤其是想在自己的消费级显卡上跑起来,那你大概率听说过或者正在用Unsloth。这个开源库通过一系列巧妙的优化(比如融合…...

小学期学习记录
第十一周观看了前四个视频,了解了低通滤波器的作用以及进行了仿真。...
)
告别电流畸变!手把手教你用PR调节器搞定开绕组电机零序电流(附Simulink仿真模型)
开绕组电机零序电流抑制实战:PR调节器参数整定与Simulink仿真指南 当开绕组永磁同步电机(OEW-PMSM)运行在考虑永磁体三次谐波反电动势的场景时,工程师们常会遇到一个棘手问题——三倍频零序电流导致的相电流畸变和转矩脉动。这种现…...

ETAS ISOLAR-A配置AUTOSAR COM模块实战:从DBC导入到信号超时监控的完整避坑指南
ETAS ISOLAR-A配置AUTOSAR COM模块实战:从DBC导入到信号超时监控的完整避坑指南 在汽车电子领域,AUTOSAR COM模块作为通信堆栈的核心组件,承担着信号路由、协议转换和通信控制的关键职能。对于使用ETAS ISOLAR-A工具链的工程师而言࿰…...

MLX90614红外测温传感器:从原理到Arduino实战应用指南
1. 项目概述:从接触式到非接触式的测温革新在嵌入式开发和物联网项目中,温度测量是一个永恒的主题。从传统的热敏电阻、DS18B20,到热电偶,我们习惯了将探头紧贴甚至刺入被测物体来获取读数。但你是否遇到过这样的困境:…...

【亲测免费】 CISP-DSG 数据安全培训教材课件标准版
CISP-DSG 数据安全培训教材课件标准版 【下载地址】CISP-DSG数据安全培训教材课件标准版 本仓库提供的是“注册数据安全治理专业人员”(Certified Information Security Professional - Data Security Governance,简称 CISP-DSG)的培训教材课…...

MTKClient实战手册:联发科芯片调试的5个专业技巧解决常见问题
MTKClient实战手册:联发科芯片调试的5个专业技巧解决常见问题 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient 当你的联发科设备遇到无法连接、分区读写失败或固件提取困难时&am…...

SFT与RL:AI训练的黄金搭档,何时介入才能事半功倍?
本文探讨了SFT(监督微调)和RL(强化学习)在AI训练中的协同作用。SFT负责建立模型的基础能力,确保其遵循格式和指令;RL在此基础上优化输出质量,使其更符合人类使用习惯。文章详细分析了何时进行RL…...