ubuntu22.04@laptop OpenCV Get Started: 015_deep_learning_with_opencv_dnn_module
ubuntu22.04@laptop OpenCV Get Started: 015_deep_learning_with_opencv_dnn_module
- 1. 源由
- 2. 应用Demo
- 2.1 C++应用Demo
- 2.2 Python应用Demo
- 3. 使用 OpenCV DNN 模块进行图像分类
- 3.1 导入模块并加载类名文本文件
- 3.2 从磁盘加载预训练 DenseNet121 模型
- 3.3 读取图像并准备为模型输入
- 3.4 通过模型进行前向传播
- 3.5 数据分析及标记输出
- 3.6 效果
- 4. 使用 OpenCV DNN 模块进行目标检测
- 4.1 使用 OpenCV DNN 进行图像目标检测
- 4.1.1 导入模块并加载类名文本文件
- 4.1.2 从磁盘加载预训练 MobileNet SSD 模型
- 4.1.3 读取图像并前向传播
- 4.1.4 数据分析及标记输出
- 4.2 使用 OpenCV DNN 进行视频目标检测
- 5. 总结
- 6. 参考资料
- 7. 补充
1. 源由
计算机视觉领域自20世纪60年代末以来就存在。图像分类和物体检测是计算机视觉中一些最古老的问题,研究人员尝试解决这些问题已经数十年。
目前,使用神经网络和深度学习,已经达到了一个阶段,计算机可以开始以高精度实际理解和识别对象,甚至在许多情况下超过人类。
要了解有关神经网络和深度学习与计算机视觉的知识,OpenCV DNN 模块是一个很好的起点。由于其高度优化的 CPU 性能,即使没有非常强大的GPU,初学者也可以轻松体验。
2. 应用Demo
015_deep_learning_with_opencv_dnn_module是基于OpenCV DNN的物体分类和物体检测的示例程序。
2.1 C++应用Demo
C++应用Demo工程结构:
015_deep_learning_with_opencv_dnn_module/CPP$ tree .
.
├── classify
│ ├── classify.cpp
│ └── CMakeLists.txt
└── detection├── detect_img│ ├── CMakeLists.txt│ └── detect_img.cpp└── detect_vid├── CMakeLists.txt└── detect_vid.cpp4 directories, 6 files
确认OpenCV安装路径:
$ find /home/daniel/ -name "OpenCVConfig.cmake"
/home/daniel/OpenCV/installation/opencv-4.9.0/lib/cmake/opencv4/
/home/daniel/OpenCV/opencv/build/OpenCVConfig.cmake
/home/daniel/OpenCV/opencv/build/unix-install/OpenCVConfig.cmake$ export OpenCV_DIR=/home/daniel/OpenCV/installation/opencv-4.9.0/lib/cmake/opencv4/
C++应用Demo工程编译执行:
$ cd classify
$ mkdir build
$ cd build
$ cmake ..
$ cmake --build . --config Release
$ cd ..
$ ./build/classify
$ cd detection/detect_img
$ mkdir build
$ cd build
$ cmake ..
$ cmake --build . --config Release
$ cd ..
$ ./build/detect_img
$ cd detection/detect_vid
$ mkdir build
$ cd build
$ cmake ..
$ cmake --build . --config Release
$ cd ..
$ ./build/detect_vid
2.2 Python应用Demo
Python应用Demo工程结构:
015_deep_learning_with_opencv_dnn_module/Python$ tree .
.
├── classification
│ └── classify.py
├── detection
│ ├── detect_img.py
│ └── detect_vid.py
└── requirements.txt2 directories, 4 files
Python应用Demo工程执行:
$ workoncv-4.9.0
$ cd classification
$ python classify.py
$ cd ..
$ cd detection
$ python detect_img.py
$ python detect_vid.py
3. 使用 OpenCV DNN 模块进行图像分类
我们将使用在非常著名的 ImageNet 数据集上使用 Caffe 框架训练的神经网络模型。
具体来说,我们将使用 DensNet121 深度神经网络模型进行分类任务。其优势在于它在 ImageNet 数据集的 1000 个类别上进行了预训练。我们可以期望该模型已经见过我们想要分类的任何图像。这使我们可以从一个广泛的图像范围中进行选择。
以下是对图像进行分类时将遵循的步骤:
- 从磁盘加载类名文本文件并提取所需的标签。
- 从磁盘加载预训练的神经网络模型。
- 从磁盘加载图像并准备图像,使其符合深度学习模型的正确输入格式。
- 将输入图像通过模型进行前向传播,并获取输出。
- 将获取的输出数据,分析后标记识别物体输出。
3.1 导入模块并加载类名文本文件
我们将使用的 DenseNet121 模型是在 1000 个 ImageNet 类别上进行训练的。我们需要一种方式将这 1000 个类别加载到内存中,并且能够轻松地访问它们。这些类别通常以文本文件的形式提供。其中一个文件称为 classification_classes_ILSVRC2012.txt,其中以以下格式包含所有类别的名称。
tench, Tinca tinca
goldfish, Carassius auratus
great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
tiger shark, Galeocerdo cuvieri
hammerhead, hammerhead shark
每一行包含了与单个图像相关的所有标签或类名。例如,第一行包含了 tench 和 Tinca Tinca。这两个名称都属于同一种鱼类。类似地,第二行有两个属于金鱼的名称。通常,第一个名称是几乎所有人都能认识的最常见的名称。
C++:
std::vector<std::string> class_names;ifstream ifs(string("../../input/classification_classes_ILSVRC2012.txt").c_str());string line;while (getline(ifs, line)){class_names.push_back(line);}
Python:
# read the ImageNet class names
with open('../../input/classification_classes_ILSVRC2012.txt', 'r') as f:image_net_names = f.read().split('\n')
# final class names (just the first word of the many ImageNet names for one image)
class_names = [name.split(',')[0] for name in image_net_names]
3.2 从磁盘加载预训练 DenseNet121 模型
正如之前讨论的,我们将使用一个使用 Caffe 深度学习框架进行训练的预训练 DenseNet121 模型。
我们将需要模型权重文件(.caffemodel)和模型配置文件(.prototxt)。
C++:
// load the neural network modelauto model = readNet("../../input/DenseNet_121.prototxt", "../../input/DenseNet_121.caffemodel", "Caffe");
Python:
# load the neural network model
model = cv2.dnn.readNet(model='../../input/DenseNet_121.caffemodel', config='../../input/DenseNet_121.prototxt', framework='Caffe')
通过使用 OpenCV DNN 模块中的 readNet() 函数加载模型,该函数接受三个输入参数。
- model: 这是预训练权重文件的路径。在我们的情况下,它是预训练的 Caffe 模型。
- config: 这是模型配置文件的路径,在这种情况下是 Caffe 模型的 .prototxt 文件。
- framework: 最后,我们需要提供我们加载模型的框架名称。对于我们来说,它是 Caffe 框架。
3.3 读取图像并准备为模型输入
我们将像往常一样使用 OpenCV 的 imread() 函数从磁盘读取图像。请注意,需要处理一些其他细节:使用 DNN 模块加载的预训练模型不会直接将读取的图像作为输入。
C++:
// load the image from diskMat image = imread("../../input/image_1.jpg");// create blob from imageMat blob = blobFromImage(image, 0.01, Size(224, 224), Scalar(104, 117, 123));
Python:
# load the image from disk
image = cv2.imread('../../input/image_1.jpg')
# create blob from image
blob = cv2.dnn.blobFromImage(image=image, scalefactor=0.01, size=(224, 224), mean=(104, 117, 123))
在读取图像时,我们假设它位于当前目录的上两级目录,并在 input 文件夹内。接下来的几个步骤非常重要,有一个 blobFromImage() 函数,它将图像准备成正确的格式以输入模型。让我们详细了解一下所有参数。
- image: 这是我们刚刚使用 imread() 函数读取的输入图像。
- scalefactor: 这个值按照提供的值对图像进行缩放。它有一个默认值为1,表示不进行缩放。
- size: 这是图像将被调整到的大小。我们提供的大小为 224×224,因为大多数在 ImageNet 数据集上训练的分类模型都希望输入的大小是这个尺寸。
- mean: mean 参数非常重要。这实际上是从图像的 RGB 色道中减去的平均值。这样做可以对输入进行标准化,并使最终的输入对不同的光照尺度具有不变性。
还有一件事需要注意。所有深度学习模型都期望以批量形式输入。然而,在这里我们只有一张图像。尽管如此,blobFromImage() 函数产生的 blob 输出实际上具有 [1, 3, 224, 224] 的形状。请注意,blobFromImage() 函数添加了一个额外的批量维度。这将是神经网络模型的最终和正确的输入格式。
3.4 通过模型进行前向传播
进行预测有两个步骤。
- 将输入 blob 设置为我们从磁盘加载的神经网络模型。
- 使用 forward() 函数将 blob 通过模型进行前向传播,这将给出所有的输出。
C++:
// set the input blob for the neural networkmodel.setInput(blob);// forward pass the image blob through the modelMat outputs = model.forward();
Python:
# set the input blob for the neural network
model.setInput(blob)
# forward pass image blog through the model
outputs = model.forward()
3.5 数据分析及标记输出
输出是一个数组,保存了所有的预测结果。但在我们能够正确地查看输出和类标签之前,还需要完成一些预处理步骤。
[[-1.44623446e+00]
[-6.37421310e-01]
[-1.04836571e+00]
[-8.40160131e-01]
…
]
当前,输出的形状为 (1, 1000, 1, 1),如果保持这样的形状,提取类标签会比较困难。因此,下面的代码块重新调整了输出的形状,然后我们可以轻松地获取正确的类标签,并将标签 ID 映射到类名。
C++:
Point classIdPoint;double final_prob;minMaxLoc(outputs.reshape(1, 1), 0, &final_prob, 0, &classIdPoint);int label_id = classIdPoint.x;// Print predicted class.string out_text = format("%s, %.3f", (class_names[label_id].c_str()), final_prob);// put the class name text on top of the imageputText(image, out_text, Point(25, 50), FONT_HERSHEY_SIMPLEX, 1, Scalar(0, 255, 0),2);imshow("Image", image);imwrite("../../outputs/result_image.jpg", image);
Python:
final_outputs = outputs[0]
# make all the outputs 1D
final_outputs = final_outputs.reshape(1000, 1)
# get the class label
label_id = np.argmax(final_outputs)
# convert the output scores to softmax probabilities
probs = np.exp(final_outputs) / np.sum(np.exp(final_outputs))
# get the final highest probability
final_prob = np.max(probs) * 100.
# map the max confidence to the class label names
out_name = class_names[label_id]
out_text = f"{out_name}, {final_prob:.3f}"# put the class name text on top of the image
cv2.putText(image, out_text, (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0),2)
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.imwrite('../../outputs/result_image.jpg', image)
3.6 效果
DenseNet121 模型准确地将图像预测为一只老虎,且置信度达到了 91%。结果相当不错。

4. 使用 OpenCV DNN 模块进行目标检测
使用 OpenCV DNN 模块,可以轻松地开始深度学习和计算机视觉中的目标检测任务。与分类任务类似,我们将加载图像、适当的模型,并将输入通过模型进行前向传播。然而,用于目标检测的预处理步骤与分类任务有所不同,这是因为在目标检测中,我们通常需要在图像上绘制检测到的对象的边界框和类别标签。
4.1 使用 OpenCV DNN 进行图像目标检测
就像分类任务一样,我们在这里也将利用预训练模型。这些模型是在 MS COCO 数据集上进行训练的,这是当前基于深度学习的目标检测模型的基准数据集。
MS COCO 数据集包含几乎 80 类对象,从人到汽车再到牙刷等各种日常物品。该数据集包含 80 种常见物体的类别。我们还将使用一个文本文件来加载 MS COCO 数据集中所有对象检测标签。
我们将使用 MobileNet SSD(Single Shot Detector),该模型是使用 TensorFlow 深度学习框架在 MS COCO 数据集上进行训练的。SSD 模型通常比其他目标检测模型更快。此外,MobileNet 的骨干网络还使它们的计算量更少。因此,使用 OpenCV DNN 学习目标检测的一个好的起点是使用 MobileNet SSD 模型。
4.1.1 导入模块并加载类名文本文件
接下来我们读取名为 object_detection_classes_coco.txt 的文件,其中包含所有类别名称,每个名称都由换行符分隔。我们将每个类别名称存储在 class_names 列表中。
class_names 列表将类似于以下内容。
[‘person’, ‘bicycle’, ‘car’, ‘motorcycle’, ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’, … ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’, ‘hair drier’, ‘toothbrush’, ‘’]
C++:
std::vector<std::string> class_names;ifstream ifs(string("../../../input/object_detection_classes_coco.txt").c_str());string line;while (getline(ifs, line)){class_names.push_back(line);}
Python:
# load the COCO class names
with open('../../input/object_detection_classes_coco.txt', 'r') as f:class_names = f.read().split('\n')# get a different color array for each of the classes
COLORS = np.random.uniform(0, 255, size=(len(class_names), 3))
4.1.2 从磁盘加载预训练 MobileNet SSD 模型
model参数接受推理文件路径作为输入,这是一个包含权重的预训练模型。
config参数接受模型配置文件的路径,这是一个Protobuf文本文件。
最后,指定了框架是TensorFlow。
C++:
// load the neural network modelauto model = readNet("../../../input/frozen_inference_graph.pb", "../../../input/ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt", "TensorFlow");
Python:
# load the DNN model
model = cv2.dnn.readNet(model='../../input/frozen_inference_graph.pb',config='../../input/ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt', framework='TensorFlow')
4.1.3 读取图像并前向传播
对于目标检测,我们在blobFromImage()函数中使用了略有不同的参数值。
指定大小为300×300,这是SSD模型几乎所有框架通常期望的输入大小。TensorFlow也是如此。
还使用了swapRB参数。通常,OpenCV以BGR格式读取图像,而目标检测模型期望输入为RGB格式。因此,swapRB参数将交换图像的R和B通道,使其成为RGB格式。
然后,将blob设置为MobileNet SSD模型,并使用forward()函数进行前向传播。
输出结构如下:
[[[[0.00000000e+00 1.00000000e+00 9.72869813e-01 2.06566155e-02 1.11088693e-01 2.40461200e-01 7.53399074e-01]]]]
- 索引位置1包含类别标签,其取值范围可以从1到80。
- 索引位置2包含置信度分数。这不是概率分数,而是模型对其检测到的属于某个类别的对象的置信度。
- 最后四个值中,前两个是x、y边界框坐标,最后一个是边界框的宽度和高度。
C++:
// read the image from diskMat image = imread("../../../input/image_2.jpg");int image_height = image.cols;int image_width = image.rows;//create blob from imageMat blob = blobFromImage(image, 1.0, Size(300, 300), Scalar(127.5, 127.5, 127.5), true, false);//create blob from imagemodel.setInput(blob);//forward pass through the model to carry out the detectionMat output = model.forward();
Python:
# read the image from disk
image = cv2.imread('../../input/image_2.jpg')
image_height, image_width, _ = image.shape
# create blob from image
blob = cv2.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123), swapRB=True)
# create blob from image
model.setInput(blob)
# forward pass through the model to carry out the detection
output = model.forward()
4.1.4 数据分析及标记输出
遍历输出中的检测结果,并在每个检测到的对象周围绘制边界框。
C++:
Mat detectionMat(output.size[2], output.size[3], CV_32F, output.ptr<float>());for (int i = 0; i < detectionMat.rows; i++){int class_id = detectionMat.at<float>(i, 1);float confidence = detectionMat.at<float>(i, 2);// Check if the detection is of good qualityif (confidence > 0.4){int box_x = static_cast<int>(detectionMat.at<float>(i, 3) * image.cols);int box_y = static_cast<int>(detectionMat.at<float>(i, 4) * image.rows);int box_width = static_cast<int>(detectionMat.at<float>(i, 5) * image.cols - box_x);int box_height = static_cast<int>(detectionMat.at<float>(i, 6) * image.rows - box_y);rectangle(image, Point(box_x, box_y), Point(box_x+box_width, box_y+box_height), Scalar(255,255,255), 2);putText(image, class_names[class_id-1].c_str(), Point(box_x, box_y-5), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0,255,255), 1);}} imshow("image", image);
Python:
# loop over each of the detection
for detection in output[0, 0, :, :]:# extract the confidence of the detectionconfidence = detection[2]# draw bounding boxes only if the detection confidence is above...# ... a certain threshold, else skipif confidence > .4:# get the class idclass_id = detection[1]# map the class id to the classclass_name = class_names[int(class_id)-1]color = COLORS[int(class_id)]# get the bounding box coordinatesbox_x = detection[3] * image_widthbox_y = detection[4] * image_height# get the bounding box width and heightbox_width = detection[5] * image_widthbox_height = detection[6] * image_height# draw a rectangle around each detected objectcv2.rectangle(image, (int(box_x), int(box_y)), (int(box_width), int(box_height)), color, thickness=2)# put the FPS text on top of the framecv2.putText(image, class_name, (int(box_x), int(box_y - 5)), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2)cv2.imshow('image', image)
在for循环内部,首先,提取当前检测到对象的置信度分数。如前所述,可以从索引位置2获取它。
然后,有一个if块来检查检测到的对象的置信度是否高于某个阈值。只有在置信度超过0.4时才继续绘制边界框。
获取类别ID并将其映射到MS COCO类别名称。然后,为当前类别获取单一颜色来绘制边界框,并将类别标签文本放置在边界框顶部。
然后,提取边界框的x和y坐标以及边界框的宽度和高度。分别将它们与图像的宽度和高度相乘,可以为我们提供绘制矩形所需的正确值。
在最后几个步骤中,绘制边界框矩形,将类别文本写在顶部,并可视化生成的图像。
 在上面的图像中,可以看到结果似乎不错。模型几乎检测到了所有可见的对象。然而,也存在一些错误的预测。例如,在右侧,MobileNet SSD模型将自行车误检为摩托车。MobileNet SSD往往会犯此类错误,因为它们是为实时应用而设计的,会以速度换取精度。
在上面的图像中,可以看到结果似乎不错。模型几乎检测到了所有可见的对象。然而,也存在一些错误的预测。例如,在右侧,MobileNet SSD模型将自行车误检为摩托车。MobileNet SSD往往会犯此类错误,因为它们是为实时应用而设计的,会以速度换取精度。
4.2 使用 OpenCV DNN 进行视频目标检测
在视频中进行目标检测的代码与图像的代码非常相似。在视频帧上进行预测时,会有一些变化。
加载相同的 MS COCO 类别文件和 MobileNet SSD 模型。
在这里,使用 VideoCapture() 对象捕获视频。还创建了一个 VideoWriter() 对象来正确保存生成的视频帧。
将检测开始前的时间存储在 start 变量中,将检测结束后的时间存储在 end 变量中。上述时间变量帮助我们计算FPS(每秒帧数)。计算FPS并将其存储在 fps 中。
在代码的最后部分,还将计算得到的FPS写在当前帧的顶部,以了解在使用OpenCV DNN模块运行MobileNet SSD模型时可以期待的速度。
代码:略(请到Git上自行研究阅读)
- 一台过时的笔记本
dnn_object_detection_laptop
- 一台“时髦的”嵌入式设备
dnn_object_detection_embedded_device
- 一台不知道配置的PC
dnn_object_detection_pc_unknow
这里并不想表明什么观点,只是想说明不同的设备,不同的配置,其效果和性能可能完全不一样。
5. 总结
通过OpenCV的DNN模块进行了图像分类和目标检测任务,以获得实践经验。
还看到了如何使用OpenCV DNN在视频中进行目标检测,同时,也展现了不同设备,不同配置情况下,性能的一些差异。
如果需要进一步分析优化,则更需要类似多因素问题分析:
- 硬件性能
- 软件配置
- 算法性能优化
- 等等
从工程技术角度,单因素的分析相对来说会更加直观和可控,而多因素的问题相对复杂,即使现在的深度学习神经网络也是需要大量的数据和计算的代价下,才能对多因素进行判断和预测的。
这里也不得不提一下《一种部件生命期监测方法》,是一种多因素的问题分析的方法和手段,在各个细分行业上都能应用,关键问题在于如何做好业务建模和分析。
6. 参考资料
【1】ubuntu22.04@laptop OpenCV Get Started
【2】ubuntu22.04@laptop OpenCV安装
【3】ubuntu22.04@laptop OpenCV定制化安装
7. 补充
学习是一种过程,对于前面章节学习讨论过的,就不在文中重复了。
有兴趣了解更多的朋友,请从《ubuntu22.04@laptop OpenCV Get Started》开始,一个章节一个章节的了解,循序渐进。
相关文章:
ubuntu22.04@laptop OpenCV Get Started: 015_deep_learning_with_opencv_dnn_module
ubuntu22.04laptop OpenCV Get Started: 015_deep_learning_with_opencv_dnn_module 1. 源由2. 应用Demo2.1 C应用Demo2.2 Python应用Demo 3. 使用 OpenCV DNN 模块进行图像分类3.1 导入模块并加载类名文本文件3.2 从磁盘加载预训练 DenseNet121 模型3.3 读取图像并准备为模型输…...
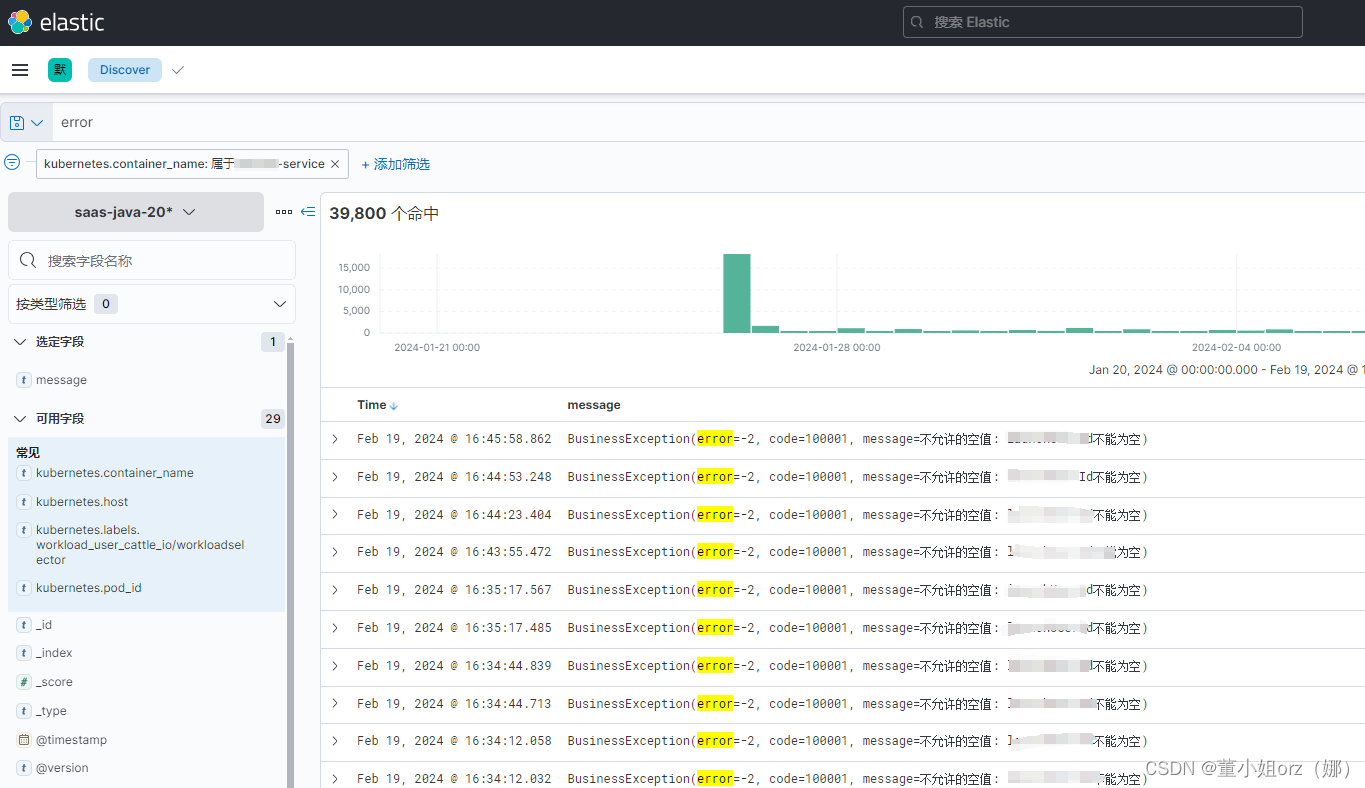
【elk查日志 elastic(kibana)】
文章目录 概要具体的使用方式一:查找接口调用历史二:查找自己的打印日志三:查找错误日志 概要 每次查日志,我都需要别人帮我,时间长了总觉得不好意思,所以这次下定决心好好的梳理一下,怎么查日…...
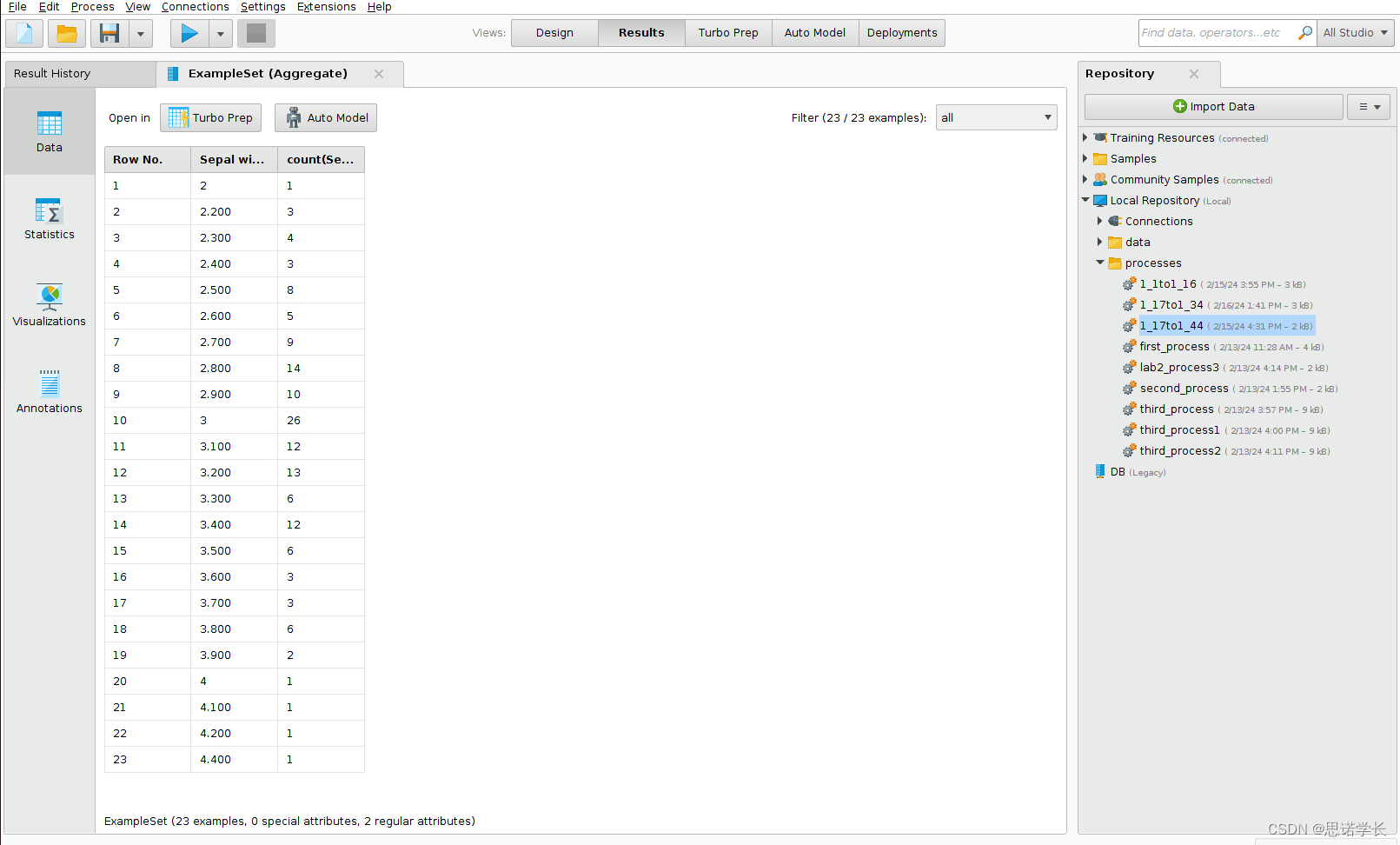
RapidMiner数据挖掘2 —— 初识RapidMiner
本节由一系列练习与问题组成,这些练习与问题有助于理解多个基本概念。它侧重于各种特定步骤,以进行直接的探索性数据分析。因此,其主要目标是测试一些检查初步数据特征的方法。大多数练习都是关于图表技术,通常用于数据挖掘。 为此…...

基于STM32的光照检测系统设计
基于STM32的光照检测系统设计 摘要: 随着物联网和智能家居的快速发展,光照检测系统在智能环境控制中扮演着越来越重要的角色。本文设计了一种基于STM32的光照检测系统,该系统能够实时检测环境光强度,并根据光强度调节照明设备,实现智能照明控制。本文首先介绍了系统的总体…...
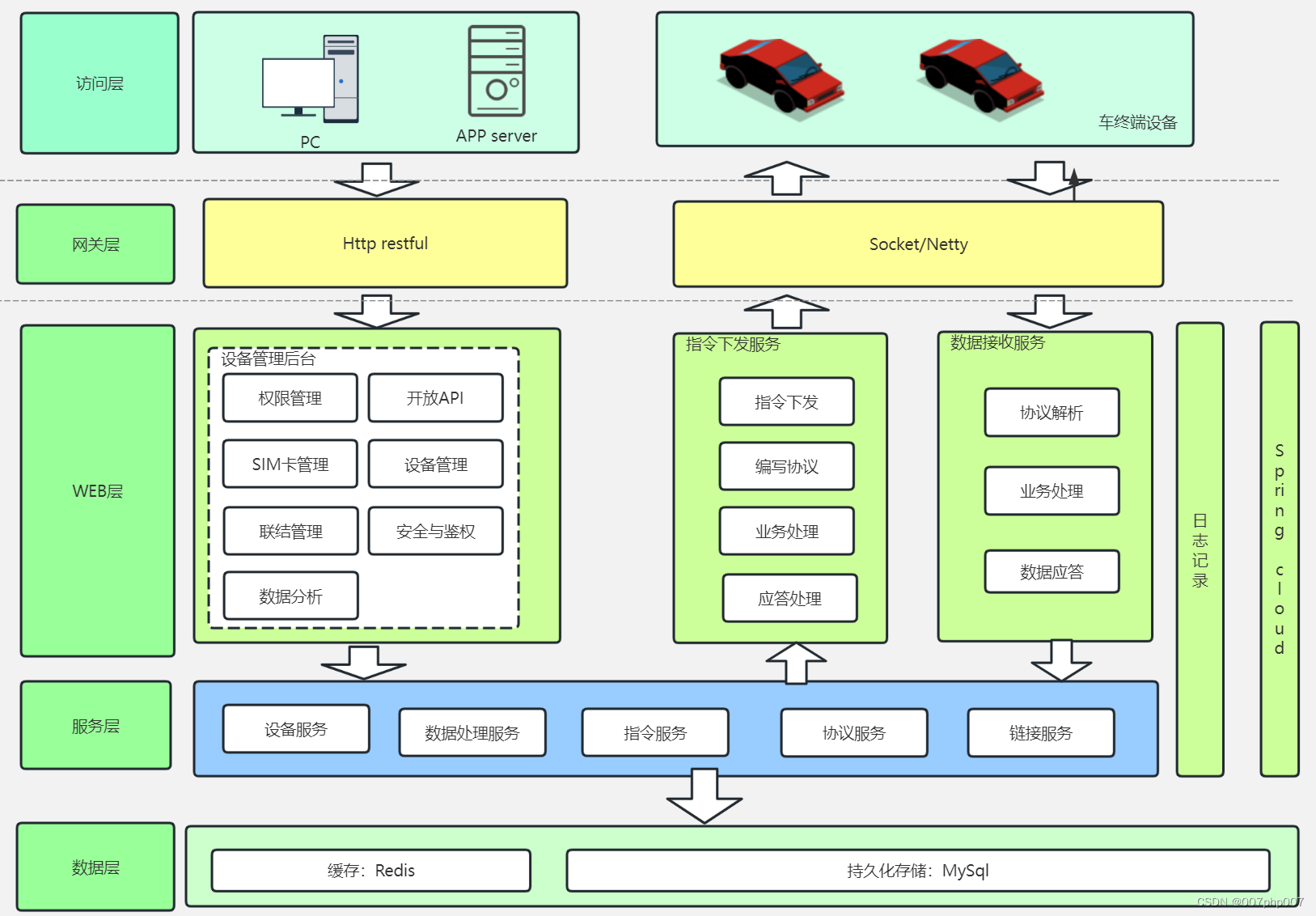
车辆管理系统设计与实践
车辆管理系统是针对车辆信息、行驶记录、维护保养等进行全面管理的系统。本文将介绍车辆管理系统的设计原则、技术架构以及实践经验,帮助读者了解如何构建一个高效、稳定的车辆管理系统。 1. 系统设计原则 在设计车辆管理系统时,需要遵循以下设计原则&…...
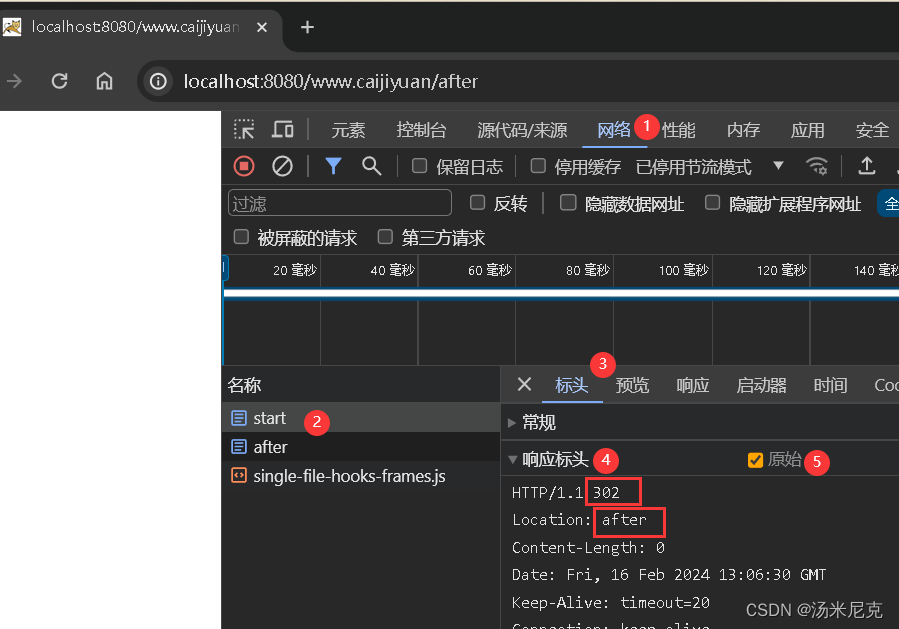
板块一 Servlet编程:第四节 HttpServletResponse对象全解与重定向 来自【汤米尼克的JAVAEE全套教程专栏】
板块一 Servlet编程:第四节 HttpServletResponse对象全解与重定向 一、什么是HttpServletResponse二、响应数据的常用方法三、响应乱码问题字符流乱码字节流乱码 四、重定向:sendRedirect请求转发和重定向的区别 在上一节中,我们系统的学习了…...

漫谈:C/C++ char 和 unsigned char 的用途
C/C的字符默认是有符号的,这一点非常的不爽,因为很少有人用单字节表达有符号数,毕竟,ASCII码是无符号的,对字符的绝大多数处理都是基于无符号的。 这一点在其它编程语言上就好很多,基本上都提供了byte这种类…...

安全保护制度
安全保护制度 第九条 计算机信息系统实行安全等级保护。安全等级的划分标准和安全等级保护的具体办法,由公安部会同有关部门制定。 第十条 计算机机房应当符合国家标准和国家有关规定。 在计算机机房附近施工,不得危害计算机信息系统的安全。 第十一条 进行国际联网的计算…...

沁恒CH32V30X学习笔记07---多功能按键框架使用
多功能按键框架使用 参考开源框架: GitHub - 0x1abin/MultiButton: Button driver for embedded system 框架使用说明: ch32gpio基本驱动 https://blog.csdn.net/u010261063/article/details/136157718 MultiButton 简介 MultiButton 是一个小巧简单易用的事件驱动型按…...

如何看显卡是几G?
created: 2024-02-20T09:22:13 (UTC 08:00) tags: [] source: https://www.sysgeek.cn/windows-check-gpu-model/ author: 海猴子 6 种简单方法:如何在 Windows 中轻松查看显卡型号 - 系统极客 Excerpt 不确定你的显卡型号?使用这 6 个简单有效的方法&a…...
虚拟机--pc端和macOS端互通
windows开启虚拟化 要在Windows系统中开启虚拟化,您可以按照以下步骤操作: 准备工作: 确保您的计算机CPU支持虚拟化技术。在BIOS中开启相应的虚拟化支持。 开启虚拟化: 打开控制面板,点击程序或功能项&am…...

(14)Hive调优——合并小文件
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...

Linux 驱动开发基础知识——LED 模板驱动程序的改造:设备树(十一)
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...

学习文档:QT QTreeWidget及其代理
学习文档:QT QTreeWidget及其代理 1. QT QTreeWidget简介 QT QTreeWidget是QT框架中的一个重要组件,用于显示树形数据结构。它提供了一种方便的方式来展示并操作带有层次关系的数据。QTreeWidget可以显示包含多个列的树形视图,每个项目可以…...

代码随想录算法训练营——总结篇
不知不觉跟完了代码训练营为期两个月的训练,现在来做个总结吧~ 记得去年12月上旬的时候,我每天都非常浮躁。一方面,经历了三个多月的秋招,我的日常学习和实验室进展被完全打乱,导致状态很差;另一方面&#…...
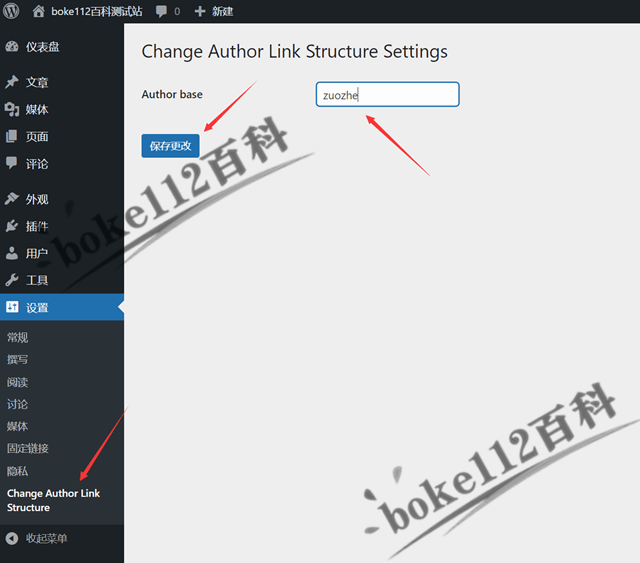
更改WordPress作者存档链接author和用户名插件Change Author Link Structure
WordPress作者存档链接默认情况为/author/Administrator(用户名),为了防止用户名泄露,我们可以将其改为/author/1(用户ID),具体操作可参考『如何将WordPress作者存档链接中的用户名改为昵称或ID…...
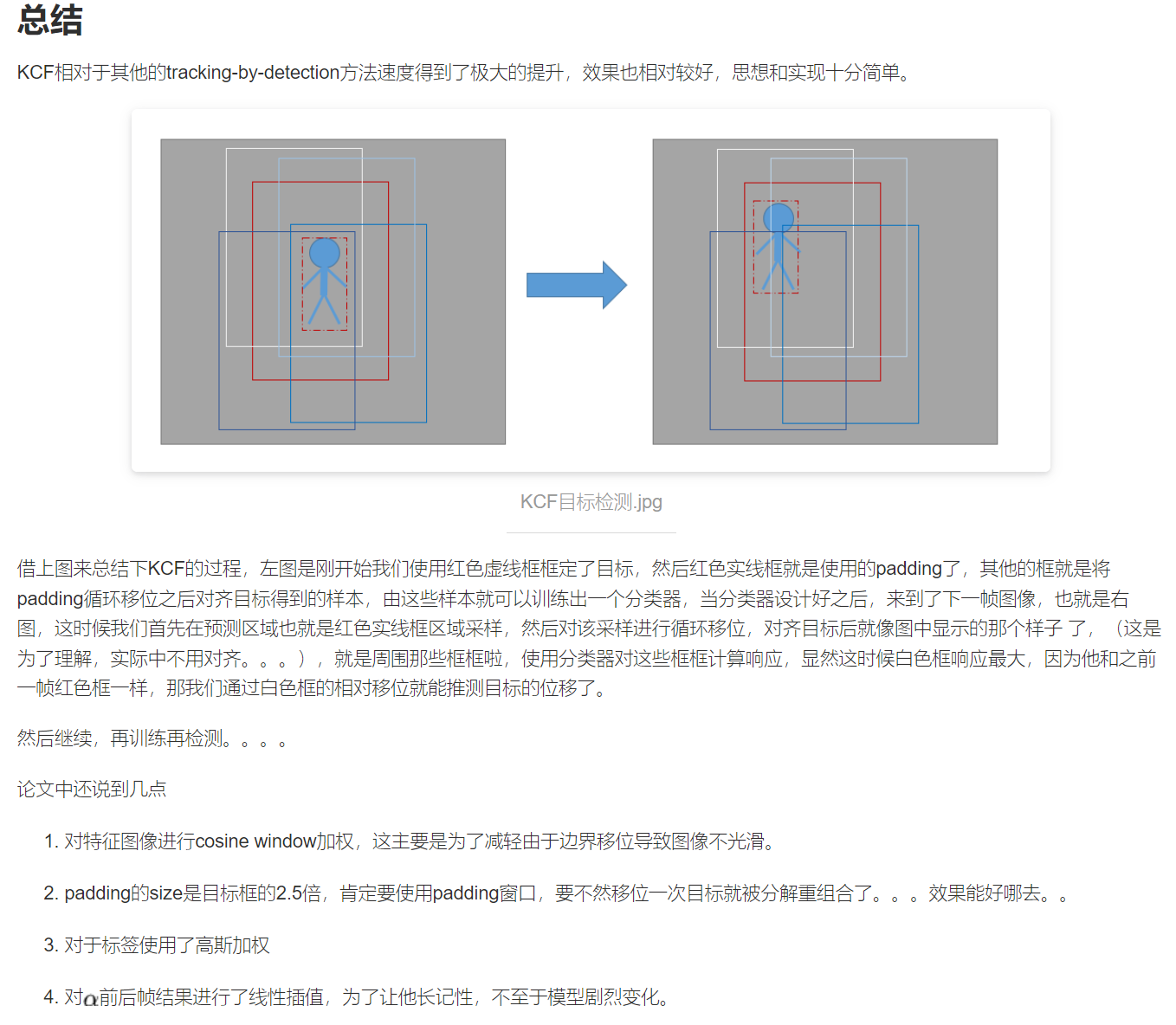
Kernelized Correlation Filters KCF算法原理详解(阅读笔记)(待补充)
KCF 目录 KCF预备知识1. 岭回归2. 循环移位和循环矩阵3. 傅里叶对角化4. 方向梯度直方图(HOG) 正文1. 线性回归1.1. 岭回归1.2. 基于循环矩阵获取正负样本1.3. 基于傅里叶对角化的求解 2. 使用非线性回归对模型进行训练2.1. 应用kernel-trick的非线性模型…...
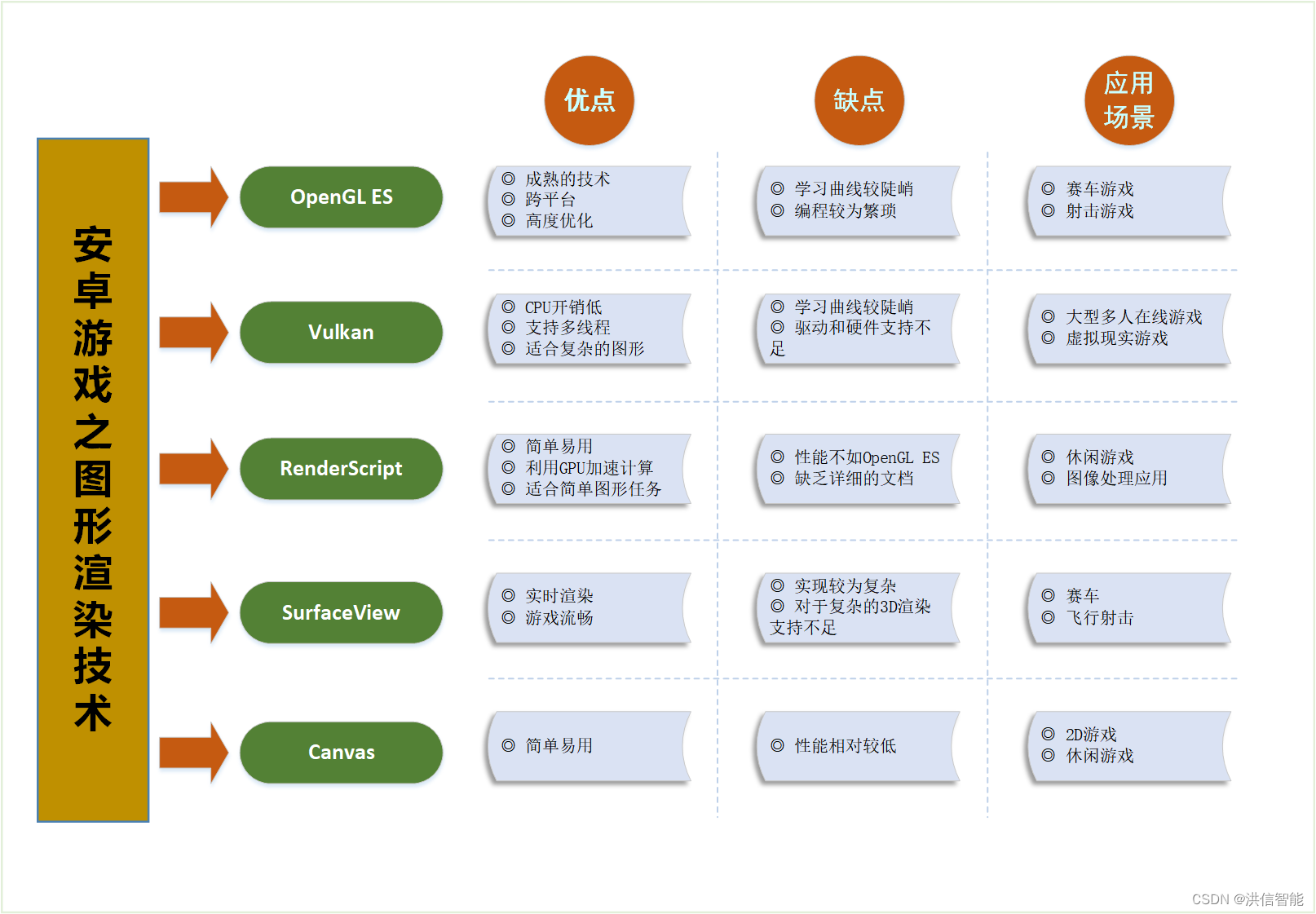
安卓游戏开发之图形渲染技术优劣分析
一、引言 随着移动设备的普及和性能的提升,安卓游戏开发已经成为一个热门领域。在安卓游戏开发中,图形渲染技术是关键的一环。本文将对安卓游戏开发中常用的图形渲染技术进行分析,比较它们的优劣,并探讨它们在不同应用场景下的适用…...
python+django+vue汽车票在线预订系统58ip7
本课题使用Python语言进行开发。基于web,代码层面的操作主要在PyCharm中进行,将系统所使用到的表以及数据存储到MySQL数据库中 使用说明 使用Navicat或者其它工具,在mysql中创建对应名称的数据库,并导入项目的sql文件; 使用PyChar…...

2024-2-19
编译安装php下载依赖包时遇到的报错 [rootmasternamed ~]# yum -y install php-mcrypt \ > libmcrypt \ > libmcrypt-devel \ > autoconf \ > freetype \ > gd \ > libmcrypt \ > libpng \ > libpng-devel \ > libjpeg \ > libxml2 \…...

终极免费指南:如何用Wand-Enhancer深度解锁WeMod完整功能与远程控制
终极免费指南:如何用Wand-Enhancer深度解锁WeMod完整功能与远程控制 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer Wand-Enhancer是一个开源…...

Linux 服务器安装 CC Switch GUI 工具 + VNC 远程桌面完整教程
Linux 服务器安装 CC Switch GUI 工具 VNC 远程桌面完整教程 前言 CC Switch 是一款 All-in-One 的 AI 助手启动器,集成了 Claude Code、Codex 和 Gemini CLI 等工具。但它是 GTK 图形界面程序,在无桌面环境的 Linux 服务器上直接运行会报错ÿ…...
)
别再死记公式了!用Multisim仿真带你直观理解星三角变换(Y-Δ)
用Multisim仿真破解星三角变换:从公式恐惧到电路直觉 记得第一次在实验室里面对三相电路板时,那些密密麻麻的接线和闪烁的指示灯让我完全摸不着头脑。教授在黑板上写满Y-Δ变换公式时,我的笔记本上只留下了一堆问号——直到我发现仿真软件这…...

边缘AI落地实战:模型轻量化、硬件加速与端侧部署全链路解析
1. 项目概述:为什么“把AI带到边缘设备”不是一句口号,而是正在发生的产业迁移 “Bringing AI To Edge Devices”——这个标题乍看像科技发布会的PPT副标题,但在我过去十年跑遍深圳华强北模组厂、杭州海康产线、苏州工业视觉集成商和北京智能…...

如何快速上手res-downloader:跨平台资源下载工具终极指南
如何快速上手res-downloader:跨平台资源下载工具终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 想要轻松…...

Jupyter C内核:在Notebook中实现C语言交互式编程的完整指南
Jupyter C内核:在Notebook中实现C语言交互式编程的完整指南 【免费下载链接】jupyter-c-kernel Minimal Jupyter C kernel 项目地址: https://gitcode.com/gh_mirrors/ju/jupyter-c-kernel Jupyter C内核是一个开源项目,为Jupyter Notebook提供完…...

别再只看benchmark!Claude的“类人延迟响应”背后藏着7种语境锚定策略
更多请点击: https://intelliparadigm.com 第一章:类人延迟响应的本质:为什么“慢”才是更高级的智能 人类在面对复杂问题时,并非即时作答,而是经历感知、检索、权衡、修正等多阶段认知循环——这种可观察的“延迟”&…...

利用Taotoken模型广场为不同AI任务选择最佳模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同AI任务选择最佳模型 在实际开发中,我们常常面临一个选择:面对内容生成、代码编…...

gibMacOS深度技术解析:跨平台macOS组件下载与构建系统
gibMacOS深度技术解析:跨平台macOS组件下载与构建系统 【免费下载链接】gibMacOS Py2/py3 script that can download macOS components direct from Apple 项目地址: https://gitcode.com/gh_mirrors/gi/gibMacOS gibMacOS是一款基于Python开发的跨平台macOS…...

3步快速上手:Windows安卓应用安装器的终极指南
3步快速上手:Windows安卓应用安装器的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想在Windows电脑上直接运行安卓应用?告别…...