(14)Hive调优——合并小文件
目录
一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量
3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐)
3.2.2 方式二:concatenate
3.2.3 方式三:使用hive的archive归档
3.2.4 方式四:hadoop getmerge
一、小文件产生的原因
- 数据源本身就包含大量的小文件,例如api,kafka消息管道等。
- 动态分区插入数据的时候,会产生大量的小文件,从而导致map数量剧增;;
- reduce 数量越多,小文件也越多,小文件数量=ReduceTask数量*分区数;
- hive中的小文件是向 hive 表中导入数据时产生;
向 hive 中导入数据的几种方式:
(1)直接向表中插入数据
insert into table t_order2 values (1,'zhangsan',88),(2,'lisi',61);这种方式每次插入时都会产生一个小文件,多次插入少量数据就会出现多个小文件,故这种方式生产环境基本不使用;
(2)通过load方式加载数据
-- 导入文件
load data local inpath "/opt/module/hive_data/t_order.txt" overwrite into table t_order;
-- 导入文件夹
load data local inpath "/opt/module/hive_data/t_order" overwrite into table t_order;使用 load方式可以导入文件或文件夹,当导入一个文件时,hive表就有一个文件,当导入文件夹时,hive表的文件数量为文件夹下所有文件的数量;
(3)通过查询方式加载数据
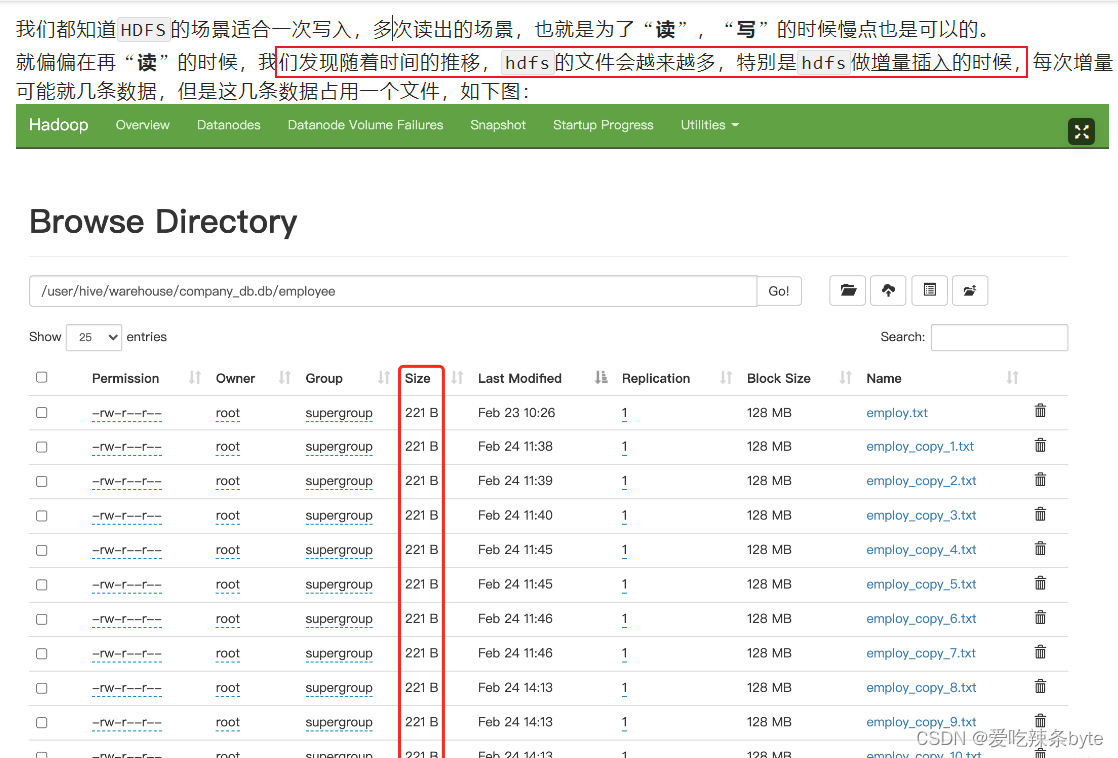
insert overwrite t_order select oid,uid from t_order2这种方式是生产环境中经常用的,也是最容易产生小文件的方式。insert 导入数据时会启动MR任务,MR-reduce的个数与输出文件个数一致。
因此,hdfs的文件数量= reduceTask数量* 分区数,有些fetch本地抓取任务(例如:简单的 select * from tableA)仅有map阶段,那此时文件个数 = mapTask数量*分区数
二、小文件的危害
小文件通常是指文件大小要比HDFS块大小(一般是128M)还要小很多的文件。
-
NameNode在内存中维护整个文件系统的元数据镜像、其中每个HDFS文件元数据信息(位置、大小、分块等)对象约占150字节,如果小文件过多会占用大量内存,会直接影响NameNode性能。相对的,HDFS读写小文件也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立pipeline连接。
- 从 Hive 角度看,一个小文件会开启一个 MapTask,一个 MapTask开一个 JVM 去执行,这些任务的启动及初始化,会浪费大量的资源,严重影响性能。
三、小文件的解决方案
小文件的解决思路主要有两个方向:1.小文件的预防;2.已存在的小文件合并
3.1 小文件的预防
通过调整参数进行合并,在 hive 中执行 insert overwrite tableA select xx from tableB 之前设置如下合并参数,即可自动合并小文件。
3.1.1 减少Map数量
在Map前进行输入合并,从而减少mapper任务的数量。
- 设置map输入时的合并参数:
#Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的CombineFileInputFormat方法,该方法是在mapper中将多个文件合成一个split切片作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认开启#每个Map最大的输入数据量(这个值决定了合并后文件的数量,会影响mapper数量)
set mapred.max.split.size=256*1000*100; -- 默认是256M#一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100*100*100; -- 100M
#一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100*100*100; -- 100M- 设置map端输出时和reduce端输出时的合并参数:
#设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
#设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
#设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000; -- 256M
#当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; -- 16M- 启用压缩(小文件合并后,也可以选择启用压缩)
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
3.1.2 减少Reduce的数量
#reduce的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量,
#通过设置reduce的数量,利用distribute by使得数据均衡的进入每个reduce。
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;#第二种是设置每个reduceTask的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=512*1000*1000; -- 默认是1G,这里为设置为5G#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;insert overwrite table A partition(dt)
select * from B
distribute by cast(rand()*10 as int);解释:如设置reduce数量为10,则使用cast(rand()*10 as int),生成0-10之间的随机整数,根据【随机整数 % 10】计算分区编号,这样数据就会均衡的分发到各reduce中,防止出现有的文件过大或过小3.2 已存在的小文件合并
对集群上已存在的小文件进行定时或实时的合并操作,定时操作可在访问低峰期操作,如凌晨2点,合并操作主要有以下几种方式:
3.2.1 方式一:insert overwrite (推荐)
执行流程总体如下:
(1)创建备份表(创建备份表时需和原表的表结构一致)
create table test.table_hive_back like test.table_hive ;(2)设置合并文件相关参数,并使用insert overwrite 语句读取原表,再插入备份表
- 设置合并文件相关参数
使用 hive的merger合并参数,在正式 insert overwrite 之前做一个合并,合并的时候注意设置好压缩,不然文件会比较大。
- 合并文件至备份表中,执行前保证没有数据写入原表
#如果有多级分区,将分区名放到partition中
insert overwrite table test.table_hive_back partition(batch_date)
select * from test.table_hive;
ps:insert overwrite table test.table_hive_back 备份表的时候,可以使用distribute by 命令设置合并后的batch_date分区下的文件数据量
insert overwrite table 目标表 [partition(hour=...)] select * from 目标表
distribute by cast( rand() * 具体最后落地生成多少个文件数 as int);
insert overwrite:会重写数据,先进行删除后插入(不用担心如果overwrite失败,数据没了,这里面是有事务保障的);
distribute by分区:能控制数据从map端发往到哪个reduceTask中,distribute by的分区规则:分区字段的hashcode值对reduce 个数取模后, 余数相同的数据会分发到同一个reduceTask中。
rand()函数:生成0-1的随机小数,控制最终输出多少个文件。
# 使用distribute by rand()将数据随机分配给reduce,这样可以使得每个reduce处理的数据大体一致。 避免出现有的文件特别大, 有的文件特别小,例如:控制dt分区目录下生成100个文件,那么hsql如下:
insert overwrite table A partition(dt)select * from B
distribute by cast(rand()*100 as int);#cast(rand()*100 as int) 可以生成0-100的随机整数如果合并之后的文件竟然还变大了,可能是 select from的原数据是被压缩的,但是insert overwrite目标表的时候,没有设置输出文件压缩功能,解决方案:
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
(3)确认表数据一致后,将原表修改名称为临时表tmp,将备份表修改名称为原表
- 先查看原表和备份表数据量,确保表数据一致
#查看原表和备份表数据量
set hive.compute.query.using.stats=false ;
set hive.fetch.task.conversion=none;
SELECT count(*) FROM test.table_hive;
SELECT count(*) FROM test.table_hive_back ;- 将原表修改名称为临时表tmp,将备份表修改名称为原表
alter table test.table_hive rename to test.table_hive_tmp;
alter table test.table_hive_back rename to test.table_hive ;(4)查看合并后的分区数和小文件数量
正常情况下:hdfs文件系统上的table_hive表的分区数量没有改变,但是每个分区的几个小文件已经合并为一个文件。
#统计合并后的分区数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive
#统计合并后的分区数下的文件数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive/batch_date=20210608例如:

(5)观察一段时间后再删除临时表
drop table test.table_hive_tmp ;
ps:注意修改hive表名的时候,对应表的存储路径会发生变化,如果有新的任务上传数据到具体路径,需要注意可能需要修改。
3.2.2 方式二:concatenate
对于orc文件,可以使用hive自带的 concatenate 命令,自动合并小文件
#对于非分区表
alter table test concatenate;#对于分区表
alter table test [partition(...)] concatenate
#例如:alter table test partition(dt='2021-05-07',hr='12') concatenate;注意:
- concatenate 命令只支持 rcfile和 orc文件类型。
- concatenate命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令。
- 当多次使用concatenate后文件数量不变化,这个跟参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小size。
3.2.3 方式三:使用hive的archive归档
每日定时脚本,对于已经产生小文件的hive表使用har归档,然后已归档的分区不能insert overwrite ,必须先unarchive
#用来控制归档是否可用
set hive.archive.enabled=true;#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;#控制需要归档文件的大小
set har.partfile.size=256000000;#对表的某个分区进行归档
alter table test_rownumber2 archive partition(dt='20230324');#对已归档的分区恢复为原文件
alter table test_rownumber2 unarchive partition(dt='20230324');
3.2.4 方式四:hadoop getmerge
对于txt格式的文件可以使用hadoop getmerge命令来合并小文件。使用 getmerge 命令先合并数据到本地,再通过put命令回传数据到hdfs。
- 将hdfs上分区为pdate=20220815,文件路径为 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* 下载到linux 本地进行合并文件,本地路径为:/home/hadoop/pdate/20220815
hadoop fs -getmerge /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* /home/hadoop/pdate/20220815;
- 将hdfs源分区数据删除
hadoop fs -rm /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
- 在hdfs上新建分区
hadoop fs -mkdir -p /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815
- 将本地合并后的文件回传到hdfs上
hadoop fs -put /home/hadoop/pdate/20220815 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
参考文章:
HIVE中小文件问题_hive小文件产生的原因-CSDN博客
Hive教程(09)- 彻底解决小文件的问题-阿里云开发者社区
0704-5.16.2-如何使用Hive合并小文件-腾讯云开发者社区-腾讯云
相关文章:
(14)Hive调优——合并小文件
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...

Linux 驱动开发基础知识——LED 模板驱动程序的改造:设备树(十一)
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...

学习文档:QT QTreeWidget及其代理
学习文档:QT QTreeWidget及其代理 1. QT QTreeWidget简介 QT QTreeWidget是QT框架中的一个重要组件,用于显示树形数据结构。它提供了一种方便的方式来展示并操作带有层次关系的数据。QTreeWidget可以显示包含多个列的树形视图,每个项目可以…...

代码随想录算法训练营——总结篇
不知不觉跟完了代码训练营为期两个月的训练,现在来做个总结吧~ 记得去年12月上旬的时候,我每天都非常浮躁。一方面,经历了三个多月的秋招,我的日常学习和实验室进展被完全打乱,导致状态很差;另一方面&#…...
更改WordPress作者存档链接author和用户名插件Change Author Link Structure
WordPress作者存档链接默认情况为/author/Administrator(用户名),为了防止用户名泄露,我们可以将其改为/author/1(用户ID),具体操作可参考『如何将WordPress作者存档链接中的用户名改为昵称或ID…...
Kernelized Correlation Filters KCF算法原理详解(阅读笔记)(待补充)
KCF 目录 KCF预备知识1. 岭回归2. 循环移位和循环矩阵3. 傅里叶对角化4. 方向梯度直方图(HOG) 正文1. 线性回归1.1. 岭回归1.2. 基于循环矩阵获取正负样本1.3. 基于傅里叶对角化的求解 2. 使用非线性回归对模型进行训练2.1. 应用kernel-trick的非线性模型…...
安卓游戏开发之图形渲染技术优劣分析
一、引言 随着移动设备的普及和性能的提升,安卓游戏开发已经成为一个热门领域。在安卓游戏开发中,图形渲染技术是关键的一环。本文将对安卓游戏开发中常用的图形渲染技术进行分析,比较它们的优劣,并探讨它们在不同应用场景下的适用…...
python+django+vue汽车票在线预订系统58ip7
本课题使用Python语言进行开发。基于web,代码层面的操作主要在PyCharm中进行,将系统所使用到的表以及数据存储到MySQL数据库中 使用说明 使用Navicat或者其它工具,在mysql中创建对应名称的数据库,并导入项目的sql文件; 使用PyChar…...

2024-2-19
编译安装php下载依赖包时遇到的报错 [rootmasternamed ~]# yum -y install php-mcrypt \ > libmcrypt \ > libmcrypt-devel \ > autoconf \ > freetype \ > gd \ > libmcrypt \ > libpng \ > libpng-devel \ > libjpeg \ > libxml2 \…...

ARM体系在linux中的中断抢占
上一篇说到系统调用等异常通过向量el1_sync做处理,中断通过向量el1_irq做处理,然后gic的工作都是为中断处理服务,在rtos中,我们一般都会有中断嵌套和优先级反转的概念,但是在linux中,中断是否会被其他中断抢…...
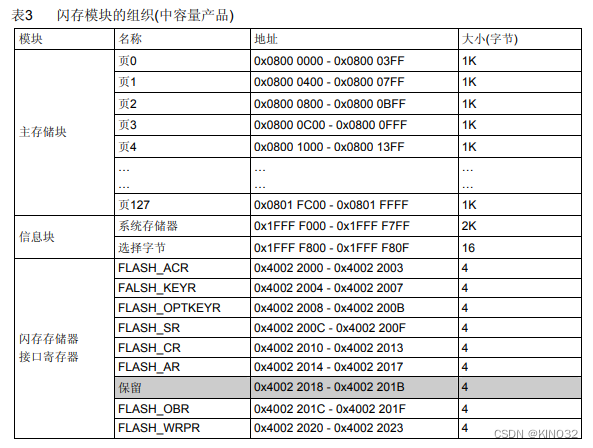
STM32的FLASH操作
时间记录:2024/2/19 一、STM32F103C8T6FLASH介绍 (1)flash大小64K,地址0x08000000-0x08010000 (2)此芯片内存大小属于中容量产品,根据数据手册可知中容量产品一个扇区的大小为1K (…...

electron Tab加载动画开启和关闭
记个开发中的bug,以此为鉴。眼懒得时候手勤快点儿,不要想当然!!! 没有转载的价值,请勿转载搬运呦。 WebContents API: Event: did-finish-load 导航完成时触发,即选项卡的旋转…...

深度学习发展的艺术
将人类直觉和相关数学见解结合后,经过大量研究试错后的结晶,产生了一些成功的深度学习模型。 深度学习模型的进展是理论研究与实践经验相结合的产物。科学家和工程师们借鉴了人类大脑神经元工作原理的基本直觉,并将这种生物学灵感转化为数学模…...

las数据转pcd数据
las数据转pcd数据 一、算法原理1.介绍las2.主要函数 二、代码三、结果展示3.1 las数据3.2 las转换为pcd 四、相关数据链接 一、算法原理 1.介绍las LAS文件按每条扫描线排列方式存放数据,包括激光点的三维坐标、多次回波信息、强度信息、扫描角度、分类信息、飞行航带信息、飞…...
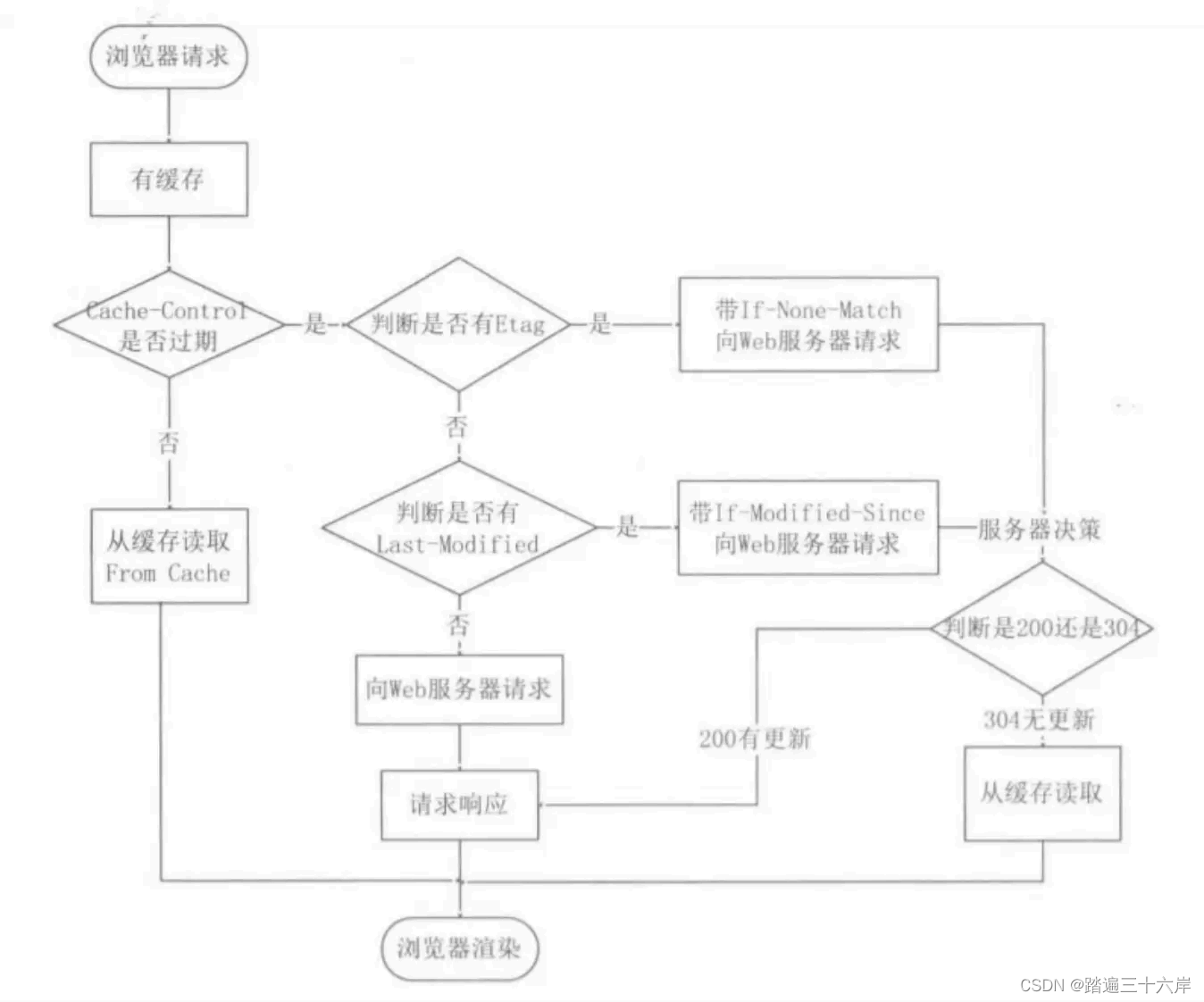
HTTP缓存技术
大家好我是苏麟 , 今天说说HTTP缓存技术 . 资料来源 : 小林coding 小林官方网站 : 小林coding (xiaolincoding.com) HTTP缓存技术 HTTP 缓存有哪些实现方式? 对于一些具有重复性的 HTTP 请求,比如每次请求得到的数据都一样的,我们可以把这对「请求-响…...

USACO 2024年1月铜组 MAJORITY OPINION
第一题:MAJORITY OPINION 标签:思维、模拟 题意:给定一个长度为 n n n的序列 a a a,操作:若区间 [ i , j ] [i,j] [i,j]内某个数字 k k k出现的次数 大于区间长度的一半,可以将区间内的所有数都换成这个数…...
Windows 重启 explorer 的正确做法
目录 一、关于 Restart Manager 二、重启管理器实例 三、完整实现代码和测试 本文属于原创文章,转载请注明出处: https://blog.csdn.net/qq_59075481/article/details/136179191。 我们往往使用 TerminateProcess 并传入 PID 和特殊结束代码 1 或者…...

linux基础学习(10):基本权限与相关命令
1.基本权限 用ls -l查看当前目录文件时,可以看到文件的基本权限 其由10位组成,其中: 第1位:代表文件类型。 - d lbc普通文件目录文件软链接文件块设备文件,也就是硬盘等存储设备的文件字符设备文件,是鼠…...

木马植入方式及防范手段
木马植入方式: 1. 诱骗下载和安装:通过欺骗、社交工程等手段,诱使用户下载和安装包含木马的软件或文件。 2. 隐秘附加:将木马隐藏在合法软件的背后,并伴随软件一起安装,用户在不知情的情况下也会安装木马。…...

Unity3D中刚体、碰撞组件、物理组件的区别详解
前言 Unity3D提供了丰富的功能和组件,其中包括刚体、碰撞组件和物理组件。这些组件在游戏开发中起着非常重要的作用,能够让游戏世界更加真实和有趣。本文将详细介绍这三种组件的区别以及如何在Unity3D中实现它们。 对惹,这里有一个游戏开发…...

GPT-4稀疏激活机制解析:1.8万亿参数为何仅用2%
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区被反复引用、误读、放大,甚至成为AI算力焦虑的具象化符号。但作为从2017年就开始部署LSTM语音模型、2019年…...
》第4.2条直指Agent记忆泄露风险:3类必查缓存节点+2分钟自检脚本)
紧急!财政部新发《AI增强型审计工作指引(试行)》第4.2条直指Agent记忆泄露风险:3类必查缓存节点+2分钟自检脚本
更多请点击: https://kaifayun.com 第一章:AI Agent审计行业应用 AI Agent在审计行业的深度渗透正重塑传统作业范式。不同于规则驱动的RPA工具,AI Agent具备目标分解、工具调用、多步推理与自主反馈能力,可动态适配审计场景中的非…...

CANN-昇腾NPU-推理服务高可用-怎么做到99.99%可用性
99% 可用性意味着一年宕机时间 < 53 分钟。推理服务要做到这个指标,需要解决:NPU 故障、OOM、网络中断、版本回滚失败。这篇讲在昇腾NPU上的具体做法。 可用性计算 99.9% 8.76 小时/年 99.99% 52.6 分钟/年 99.999% 5.26 分钟/年99% 是多数在…...

不止于看见,更在于改变——双碳传媒的全球工业服务生态
在数字化与智能化重塑世界的今天,传统的工业传播边界正在被打破。双碳传媒(秦皇岛)有限公司,正以AI技术为核心驱动,重新定义全球工业服务的生态格局。我们深知,服务国家战略与顶级企业,需要的是…...

为什么你的AI搜索总不准?2026年5款高精度免费工具底层架构拆解:向量引擎、重排序模块与Query理解差异全曝光
更多请点击: https://intelliparadigm.com 第一章:为什么你的AI搜索总不准?——2026年免费高精度AI搜索工具全景洞察 AI搜索不准,根源常被误判为“模型不够大”,实则多源于查询理解失焦、上下文截断、知识新鲜度缺失与…...

从RTL代码到SDC约束:手把手教你为PLL/DCM生成的时钟写对时序约束
从RTL代码到SDC约束:手把手教你为PLL/DCM生成的时钟写对时序约束 在数字芯片设计流程中,时钟约束的正确性直接影响着时序收敛的效率和质量。很多工程师能够熟练编写RTL代码,却在转换为SDC约束时遇到困惑——特别是当设计中使用PLL、DCM或自定…...

告别手动测量!用ArcGIS Pro和CAD联动,5步搞定复杂河道平均宽度计算
5步实现ArcGIS Pro与CAD协同计算复杂河道平均宽度的工程实践 在水利工程、环境评估和流域规划中,河道平均宽度是计算流量、评估生态承载力的关键参数。传统手工测量方法不仅耗时费力,对于蜿蜒曲折的自然河道更是难以保证精度。我曾参与过多个河道整治项目…...
)
别再手动接线了!用ESP-01S转接板5分钟搞定AT固件烧录(附固件下载)
5分钟极简ESP-01S固件烧录指南:转接板避坑全攻略 当你第一次拿到ESP-01S模块时,是否被那密密麻麻的引脚和复杂的接线图吓到?作为物联网开发的入门神器,ESP-01S确实性价比极高,但传统的手动接线烧录方式让不少新手望而…...

Claude Desktop Debian版开源协议解析:MIT与Apache 2.0双许可完全指南
Claude Desktop Debian版开源协议解析:MIT与Apache 2.0双许可完全指南 【免费下载链接】claude-desktop-debian Claude Desktop for Linux 项目地址: https://gitcode.com/GitHub_Trending/cl/claude-desktop-debian Claude Desktop Debian版是一款为Linux系…...

Unity WebGL文本输入解决方案:WebGLInput原理与集成指南
1. 为什么Unity WebGL的文本输入让人反复抓狂“WebGL平台不能打字”——这句话在Unity开发者社区里出现的频率,几乎和“打包报错”“内存泄漏”一样高。我第一次遇到这个问题是在2021年,给一个教育类Web应用做跨平台迁移:iOS和Android端的Inp…...