频率主义线性回归和贝叶斯线性回归
整体概述
频率主义(Frequentist)线性回归和贝叶斯(Bayesian)线性回归是统计学中用于数据分析和预测的两种主要方法,特别是在建模关于因变量和自变量之间线性关系的上下文中。尽管两种方法都用于线性回归分析,但它们在解释参数、估计方法和结果的不确定性方面有所不同。
频率主义线性回归
频率主义线性回归建立在经典统计学的原则上,尤其是参数估计的频率主义概念。在频率主义视角下,模型参数被认为是固定的未知常数,我们的目标是基于样本数据去估计这些常数。频率主义线性回归的目标是找到一个线性模型来描述因变量Y和一组自变量X之间的关系:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p X p + ϵ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_p X_p + \epsilon Y=β0+β1X1+β2X2+…+βpXp+ϵ
其中, β 0 , β 1 , . . . , β p \beta_0, \beta_1, ..., \beta_p β0,β1,...,βp是模型参数,而 ϵ \epsilon ϵ是误差项,通常假设为独立同分布的正态分布。
参数估计常用最小二乘法(OLS),目标是最小化误差项的平方和。频率主义的置信区间和假设检验(如t检验、F检验)用于评估模型参数的不确定性和显著性。
贝叶斯线性回归
贝叶斯线性回归遵循贝叶斯统计的原则,模型的参数被视为随机变量而非固定未知常数。这种方法将先验知识或者信念和样本数据结合起来,以估计参数。贝叶斯回归的基本形式与频率主义线性回归相同,但在估计参数时采用的是贝叶斯定理:
P ( Θ ∣ D a t a ) = P ( D a t a ∣ Θ ) ⋅ P ( Θ ) P ( D a t a ) P(\Theta | Data) = \frac{P(Data | \Theta) \cdot P(\Theta)}{P(Data)} P(Θ∣Data)=P(Data)P(Data∣Θ)⋅P(Θ)
这里的 P ( Θ ∣ D a t a ) P(\Theta | Data) P(Θ∣Data) 是给定数据后参数 Θ \Theta Θ 的后验概率, P ( D a t a ∣ Θ ) P(Data | \Theta) P(Data∣Θ)是给定参数下数据的似然, P ( Θ ) P(\Theta) P(Θ) 是参数的先验概率,而 P ( D a t a ) P(Data) P(Data) 是证据(或边缘概率),作为归一化常数。
在贝叶斯回归中,不是寻找一组固定的参数估计,而是利用计算或模拟方法(如马尔可夫链蒙特卡洛,MCMC)来得到参数的后验分布。这允许我们直接从后验分布中得到参数估计的不确定性(表现为分布的形状),也能通过分布的特征(如均值、中位数、百分位数区间)来总结参数的估计。
比较
- 参数解释:频率主义视角下,参数是固定的,而在贝叶斯视角下,参数是具有分布的随机变量。
- 先验知识:贝叶斯方法可以整合先验知识,频率主义方法则通常不考虑先验知识。
- 不确定性评估:贝叶斯方法通过后验分布直接提供参数的不确定性评估,而频率主义方法使用置信区间和假设检验来进行不确定性评估。
- 计算复杂性:贝叶斯方法通常计算上更为复杂,需要使用MCMC等模拟技术,而频率主义方法如OLS在计算上更简单直接。
每种方法都有其优势和局限性,应用哪种方法取决于具体的问题、数据和分析目标。
频率主义线性回归
频率主义线性回归是一种统计方法,用于估计和推断一个或多个自变量(解释变量)与因变量(响应变量)之间的线性关系。在频率主义框架中,参数被认为是固定的,且数据是随机的。这一观点反映了一个信念,即在重复实验的条件下,某事件的频率趋近于其真实概率。
线性回归模型
线性回归模型可以表示为:
Y = X β + ϵ Y = X\beta + \epsilon Y=Xβ+ϵ
其中,
- Y Y Y 是一个 n × 1 n \times 1 n×1的向量,表示因变量的观测值;
- X X X 是一个 n × p n \times p n×p 的矩阵,其中 n n n是样本大小, p p p是参数的数量(包括截距),表示自变量;
- β \beta β是一个 p × 1 p \times 1 p×1 的向量,表示未知的回归系数;
- ϵ \epsilon ϵ 是一个 n × 1 n \times 1 n×1的向量,表示误差项,假设 ϵ ∼ N ( 0 , σ 2 I ) \epsilon \sim N(0, \sigma^2I) ϵ∼N(0,σ2I),即误差项独立同分布,且呈正态分布。
最小二乘估计
在频率主义线性回归中,通常使用最小二乘法(Ordinary Least Squares, OLS)来估计参数 β \beta β。最小二乘估计旨在最小化误差项的平方和:
S ( β ) = ( Y − X β ) ′ ( Y − X β ) S(\beta) = (Y - X\beta)'(Y - X\beta) S(β)=(Y−Xβ)′(Y−Xβ)
通过对 S ( β ) S(\beta) S(β)求导并设其为零,可以得到 β \beta β 的OLS估计:
β ^ = ( X ′ X ) − 1 X ′ Y \hat{\beta} = (X'X)^{-1}X'Y β^=(X′X)−1X′Y
其中 β ^ \hat{\beta} β^是参数的估计值。
置信区间
置信区间是用来估计模型参数不确定性的一种方法。对于每个回归系数 β i \beta_i βi,我们可以计算一个置信区间,该区间以一定的置信水平(如95%)覆盖真实参数值。置信区间基于回归系数的抽样分布,通常假设为正态分布,可以表示为:
β i ^ ± t α / 2 , n − p ⋅ S E ( β i ^ ) \hat{\beta_i} \pm t_{\alpha/2, n-p} \cdot SE(\hat{\beta_i}) βi^±tα/2,n−p⋅SE(βi^)
其中,
- t α / 2 , n − p t_{\alpha/2, n-p} tα/2,n−p 是自由度为 n − p n-p n−p 的t分布的临界值;
- S E ( β i ^ ) SE(\hat{\beta_i}) SE(βi^) 是估计系数 β i ^ \hat{\beta_i} βi^的标准误差。
假设检验
假设检验用于评估模型系数是否显著不同于零(或其他指定的值)。最常用的是t检验,用于单个系数,以及F检验,用于模型中的多个系数。t检验的零假设是系数等于零 ( H 0 : β i = 0 ) (H_0: \beta_i = 0) (H0:βi=0),备择假设是系数不等于零 ( H 1 : β i ≠ 0 ) (H_1: \beta_i \neq 0) (H1:βi=0)。
t统计量计算为:
t = β i ^ − 0 S E ( β i ^ ) t = \frac{\hat{\beta_i} - 0}{SE(\hat{\beta_i})} t=SE(βi^)βi^−0
如果 (t) 的绝对值大于t分布的临界值,我们拒绝零假设,认为这个系数显著不为零。
F检验通常用于同时检验多个系数是否显著。它比较模型中所有解释变量与只有截距项的简化模型的拟合度。F统计量是比例,反映了两个模型中未解释变化的比例减少:
F = ( S S E 0 − S S E 1 ) / ( p − 1 ) S S E 1 / ( n − p ) F = \frac{(SSE_0 - SSE_1)/(p-1)}{SSE_1/(n-p)} F=SSE1/(n−p)(SSE0−SSE1)/(p−1)
其中,
- S S E 0 SSE_0 SSE0 是没有解释变量的模型的误差平方和;
- S S E 1 SSE_1 SSE1 是完整模型的误差平方和;
- p p p 是完整模型中参数的数量;
- n n n 是样本大小。
如果F统计量的值大于F分布的临界值,我们拒绝零假设,认为模型中至少有一个系数显著不为零。
通过这些方法,频率主义线性回归不仅为我们提供了对数据的最佳线性拟合,而且还允许我们进行推断,评估模型系数的显著性以及估计系数的可靠性。
贝叶斯线性回归
贝叶斯线性回归通过结合先验分布和数据的似然来更新关于回归参数的信念,得到参数的后验分布。由于后验分布通常难以解析计算,尤其是在参数空间较大或模型复杂时,马尔可夫链蒙特卡洛(MCMC)方法被广泛用于生成后验分布的近似样本。这些样本可以用于参数估计、预测以及计算可信区间。
以下是贝叶斯线性回归估计和预测的详细步骤,包括使用MCMC方法和计算可信区间的说明。
模型设定
首先,设定一个贝叶斯线性回归模型:
Y = X β + ϵ , ϵ ∼ N ( 0 , σ 2 I ) Y = X\beta + \epsilon, \quad \epsilon \sim N(0, \sigma^2I) Y=Xβ+ϵ,ϵ∼N(0,σ2I)
- Y Y Y是观测的响应变量;
- X X X 是设计矩阵,包含自变量;
- β \beta β 是回归系数,需要估计;
- ϵ \epsilon ϵ是误差项,假设服从以0为均值、 σ 2 \sigma^2 σ2为方差的正态分布。
先验分布设定
接着,给定参数 β \beta β 和 σ 2 \sigma^2 σ2 的先验分布。这些先验可以是无信息先验,例如正态先验或者均匀先验,也可以是包含先前知识的信息先验。
后验分布
根据贝叶斯定理,后验分布与似然函数和先验分布成正比:
p ( β , σ 2 ∣ Y , X ) ∝ p ( Y ∣ X , β , σ 2 ) p ( β ) p ( σ 2 ) p(\beta, \sigma^2 | Y, X) \propto p(Y | X, \beta, \sigma^2) p(\beta) p(\sigma^2) p(β,σ2∣Y,X)∝p(Y∣X,β,σ2)p(β)p(σ2)
其中 p ( β , σ 2 ∣ Y , X ) p(\beta, \sigma^2 | Y, X) p(β,σ2∣Y,X) 是后验分布, p ( Y ∣ X , β , σ 2 ) p(Y | X, \beta, \sigma^2) p(Y∣X,β,σ2) 是似然函数, p ( β ) p(\beta) p(β) 和 p ( σ 2 ) p(\sigma^2) p(σ2)是先验分布。
MCMC采样
MCMC方法允许我们从复杂的后验分布中抽取样本。最常用的MCMC算法是吉布斯采样(Gibbs sampling)和梅特罗波利斯-哈斯廷斯算法(Metropolis-Hastings algorithm)。这些算法通过构建一个随机游走的马尔可夫链,最终收敛到后验分布。
- 吉布斯采样在每个步骤中条件于其他所有参数对每个参数进行采样。
- 梅特罗波利斯-哈斯廷斯算法可以采样整个参数向量,并利用接受-拒绝规则来确保样本来自正确的分布。
后验分析
当MCMC收敛后,我们可以通过分析生成的样本来估计后验分布。这包括:
- 参数估计:通过取MCMC样本的平均值或中位数作为参数的估计值。
- 预测:使用样本生成预测分布,通过在每个采样步骤上将新数据点的预测值 (X_{new}\beta) 累积起来并应用后验分布。
- 可信区间计算:计算参数的可信区间,这可以通过对MCMC样本进行排序并取出相应的百分位数来实现。例如,95%的可信区间由2.5%和97.5%的分位数确定。
可信区间(Credible Intervals)
与频率主义的置信区间不同,贝叶斯的可信区间提供了一个区间,使得有高概率(如95%)参数的真实值会落在这个区间内。计算步骤如下:
- 对每个参数的MCMC样本进行排序。
- 对于95%的可信区间,选取2.5%的分位数作为下限,97.5%的分位数作为上限。
诊断和验证
最后,对MCMC算法进行诊断,确保它已经收敛到目标后验分布。可以使用迹图、自相关图以及收敛诊断统计量,如Gelman-Rubin统计量进行检查。
综上所述,贝叶斯线性回归利用MCMC方法生成后验分布的样本,允许我们进行参数估计、预测以及可信区间的计算。这为包含不确定性和先验信念的统计建模提供了一种强大的工具。
示例:
例题
根据 x 0 , x 1 x_0,x_1 x0,x1值预测 y y y值。我们划分为训练集、验证集和测试集。数据保存在train_set.csv和test_set.csv。使用以下评价指标:R²、MSE、RMSE、MAE。
R平方 (R²) 或决定系数:衡量模型解释变量能力的比例,值在0到1之间,1表示模型能够完美预测因变量。
均方误差 (MSE):衡量模型预测误差的平均值的大小,计算公式是预测值与实际值差的平方的平均。
均方根误差 (RMSE):MSE的平方根,它的量纲与因变量一致,因此更易于解释。
平均绝对误差 (MAE):衡量预测值与实际值之间差的绝对值的平均大小,与MSE类似,但是对异常值的敏感度较低。
频率主义线性回归
首先我们使用scikit-learn的线性回归模型进行学习和推断。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score# 加载数据
data = pd.read_csv('train_set.csv')
test_data = pd.read_csv('test_set.csv') # 将x0和x1两列转换为一个Numpy数组
train_X = data[['x0', 'x1']].values
test_X = test_data[['x0', 'x1']].values
# 将y列转换为一个Numpy数组
train_y = data['y'].values
test_y = test_data[['y']].values
# 现在X是一个包含x0和x1的Numpy数组,y是一个单独的Numpy数组
print(train_X.shape,train_y.shape)
print(test_X.shape,test_X.shape)
# 创建模型
model = LinearRegression()
# 拟合模型
model.fit(train_X, train_y)
# 输出回归系数
print(f"Intercept: {model.intercept_}, Coefficients: {model.coef_}")
# 使用模型进行预测
y_pred = model.predict(test_X)# 计算统计指标
mse = mean_squared_error(test_y, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(test_y, y_pred)
r2 = r2_score(test_y, y_pred)# 打印统计指标
print(f'Mean Squared Error (MSE): {mse}')
print(f'Root Mean Squared Error (RMSE): {rmse}')
print(f'Mean Absolute Error (MAE): {mae}')
print(f'R-squared (R2): {r2}')'''
(400, 2) (400,)
(100, 2) (100, 2)
Intercept: 0.06634575026290213, Coefficients: [1.15689086 0.88110244]
Mean Squared Error (MSE): 0.0002869146993285752
Root Mean Squared Error (RMSE): 0.016938556589289867
Mean Absolute Error (MAE): 0.013865979260745431
R-squared (R2): 0.8927043803619303
'''
不使用任何专门的库,我们可以直接用Python中的基础功能来计算线性回归模型的参数。这可以通过计算最小二乘估计来实现,即通过解析解找到系数β的估计值,使得残差平方和最小。
线性回归模型的解析解可通过以下公式计算得到:
β = ( X T X ) − 1 X T y \beta = (X^TX)^{-1}X^Ty β=(XTX)−1XTy
这里的 β \beta β 是一个向量,包含了截距项和斜率项。
以下是一个用Python实现的简单线性回归模型的例子:
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score# 加载数据
data = pd.read_csv('train_set.csv')
test_data = pd.read_csv('test_set.csv') # 将x0和x1两列转换为一个Numpy数组
train_X = data[['x0', 'x1']].values
test_X = test_data[['x0', 'x1']].values
# 将y列转换为一个Numpy数组
train_y = data['y'].values
test_y = test_data[['y']].values
# 现在X是一个包含x0和x1的Numpy数组,y是一个单独的Numpy数组
print(train_X.shape,train_y.shape)
print(test_X.shape,test_X.shape)# 添加截距项
train_X_with_intercept = np.column_stack((np.ones((train_X.shape[0], 1)), train_X))# 计算β的估计值
beta_hat = np.linalg.inv(train_X_with_intercept.T @ train_X_with_intercept) @ train_X_with_intercept.T @ train_yprint(f"Intercept (beta_0): {beta_hat[0]}")
print(f"Coefficient of x0 (beta_1): {beta_hat[1]}")
print(f"Coefficient of x1 (beta_2): {beta_hat[2]}")# 使用模型进行预测
def predict(X, beta):X_with_intercept = np.hstack((np.ones((X.shape[0], 1)), X))y_pred = X_with_intercept @ betareturn y_pred
y_pred = predict(test_X,beta_hat)# 计算统计指标
mse = mean_squared_error(test_y, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(test_y, y_pred)
r2 = r2_score(test_y, y_pred)# 打印统计指标
print(f'Mean Squared Error (MSE): {mse}')
print(f'Root Mean Squared Error (RMSE): {rmse}')
print(f'Mean Absolute Error (MAE): {mae}')
print(f'R-squared (R2): {r2}')'''
(400, 2) (400,)
(100, 2) (100, 2)
Intercept (beta_0): 0.06634575026264328
Coefficient of x0 (beta_1): 1.156890863218591
Coefficient of x1 (beta_2): 0.8811024418527595
Mean Squared Error (MSE): 0.00028691469932902837
Root Mean Squared Error (RMSE): 0.016938556589303246
Mean Absolute Error (MAE): 0.013865979260770434
R-squared (R2): 0.8927043803617608
'''
在上述代码中,np.column_stack用来合并截距项和自变量。这种方法没有考虑矩阵(X^TX)可能不可逆的情况。在实际应用中,通常会加入一些正则化或者使用伪逆(np.linalg.pinv)来避免这种问题。
贝叶斯线性回归
我们使用Pyro库实现贝叶斯线性回归
import torch
import pyro
import pyro.distributions as dist
from pyro.infer import MCMC, NUTS
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score# 加载数据
data = pd.read_csv('train_set.csv')
test_data = pd.read_csv('test_set.csv') # 将x0和x1两列转换为一个Numpy数组
train_X0 = torch.from_numpy(data['x0'].values)
train_X1 = torch.from_numpy(data['x1'].values)
test_X0 = torch.from_numpy(test_data['x0'].values)
test_X1 = torch.from_numpy(test_data['x1'].values)
# 将y列转换为一个Numpy数组
train_y = torch.from_numpy(data['y'].values)
test_y = torch.from_numpy(test_data['y'].values)
print(test_X0.shape,test_X1.shape)def model(x0, x1, y=None):# 定义先验分布beta0 = pyro.sample("beta0", dist.Normal(0., 1.))beta1 = pyro.sample("beta1", dist.Normal(0., 1.))beta2 = pyro.sample("beta2", dist.Normal(0., 1.))sigma = pyro.sample("sigma", dist.Uniform(0., 10.))# 定义线性模型mean = beta0 + beta1 * x0 + beta2 * x1# 用于观测数据的似然函数with pyro.plate("data", len(x0)):obs = pyro.sample("obs", dist.Normal(mean, sigma), obs=y)return mean# 运行Hamiltonian Monte Carlo (HMC)算法,NUTS是HMC的一个优化版本
nuts_kernel = NUTS(model)
mcmc = MCMC(nuts_kernel, num_samples=500, warmup_steps=300)
mcmc.run(train_X0, train_X1, train_y)# 获取后验分布的样本
posterior_samples = mcmc.get_samples()# 打印后验分布的平均值
for name, value in posterior_samples.items():print(f"{name} : {value.mean(0)}")#########预测和评价############################
# 使用后验样本来计算预测的分布
predictive = pyro.infer.Predictive(model, posterior_samples)
y_pred = predictive(test_X0, test_X1)["obs"]mse = mean_squared_error(test_y, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(test_y, y_pred)
r2 = r2_score(test_y, y_pred)# 打印统计指标
print(f'Mean Squared Error (MSE): {mse}')
print(f'Root Mean Squared Error (RMSE): {rmse}')
print(f'Mean Absolute Error (MAE): {mae}')
print(f'R-squared (R2): {r2}')'''
torch.Size([100]) torch.Size([100])
Sample: 100%|██████████████████████████████████████████| 800/800 [04:39, 2.86it/s, step size=1.76e-02, acc. prob=0.919]beta0 : 0.06777436401333638
beta1 : 1.1556829075576296
beta2 : 0.8807723691323056
sigma : 0.01814367967435664
Mean Squared Error (MSE): 0.0002873891791732731
Root Mean Squared Error (RMSE): 0.016952556714940465
Mean Absolute Error (MAE): 0.013864298414787972
R-squared (R2): 0.8925269422276634
'''
这段代码是一个使用Pyro库进行贝叶斯线性回归的统计分析和预测的例子。Pyro是一个Python库,用于概率编程,它构建在PyTorch上。代码的目的是通过MCMC(Markov Chain Monte Carlo)方法中的NUTS(No-U-Turn Sampler)算法来估计模型参数的后验分布,并基于这些参数的后验分布进行预测。
以下是代码的详细解释:
导入必要的库:
torch是一个开源机器学习库,提供了多种高级功能来处理多维数组(张量)和执行自动微分。pyro是一个基于PyTorch的概率编程库,它允许用户定义概率模型并进行推断。pyro.distributions是Pyro中包含概率分布的模块,用于定义模型中的随机变量。pyro.infer包含推断算法的模块,这里特别用到了MCMC和NUTS算法。pandas是一个数据操作和分析的库,通常用于处理结构化数据。numpy是一个包含多种数学计算工具的库。sklearn.metrics提供了一系列评估预测误差的函数。
数据加载和预处理:
- 使用
pandas库从’train_set.csv’和’test_set.csv’文件中加载训练集和测试集数据。 - 将训练集和测试集中的
x0和x1列转换为PyTorch张量,用于模型输入。 - 将训练集和测试集中的
y列(目标变量)转换为PyTorch张量。
定义模型:
model函数定义了一个贝叶斯线性回归模型,其中x0和x1是输入特征,y是可选的观测目标变量。beta0,beta1,beta2是线性模型的系数,它们被赋予了正态分布作为它们的先验。sigma是模型误差项的标准差,赋予了一个0到10的均匀分布作为先验。mean是线性回归模型的均值部分,根据系数和输入特征计算得出。- 使用
pyro.plate来指示y观测值的索引,它能够提高推断的效率。 obs是观测数据的似然,它是以mean和sigma为参数的正态分布。
MCMC推断:
- 使用NUTS算法作为MCMC推断的内核,来估计模型参数的后验分布。
- 设置采样500次并预热(warmup)300步,预热步骤帮助算法找到合适的参数开始采样,这有助于改进采样质量。
mcmc.run运行MCMC算法来采样模型的后验分布。mcmc.get_samples()获取后验分布的样本。
后验分析与预测:
- 利用后验分布的样本和
pyro.infer.Predictive来预测测试集的y值。 - 计算了均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R^2)来评估模型的预测性能。
输出结果:
- 输出的是后验分布的平均值,这些平均值表示模型参数的估计值。
- 输出各种统计指标来评价模型的预测效果,包括MSE、RMSE、MAE和R^2。
最后,注释中的输出结果显示了训练过程中得到的参数估计和评估指标的特定值。这些值表明模型拟合得相当好,因为 R 2 R^2 R2值接近1,而MSE、RMSE、MAE都相对较低,表明预测误差小。
接下来,我们不使用现成的python库,直接实现贝叶斯线性回归。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import pandas as pd
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score# 使用对数似然函数
def log_likelihood(w, data):x0, x1, y = datay_pred = w[0] + w[1] * x0 + w[2] * x1# 注意我们这里是返回对数似然return np.sum(stats.norm.logpdf(y, y_pred, 1)) # 假设误差项标准差为 1# 使用对数先验分布
def log_prior(w):# 返回参数的对数先验,这里同样假设参数的先验分布为正态分布return stats.norm.logpdf(w[0], 0, 1) + stats.norm.logpdf(w[1], 0, 1) + stats.norm.logpdf(w[2], 0, 1)# 随机提案函数(用于生成新的参数采样点)
def random_proposal(w, step_size=[0.5, 0.5, 0.5]):return np.random.normal(w, step_size)# 函数: Metropolis-Hastings 算法实现
def metropolis_hastings(log_likelihood_computer, log_prior_computer, random_proposal, iterations, data, initial_values=[0,0,0], step_size=[0.5, 0.5, 0.5]):# 初始参数值w = initial_values# 保存所有采样值samples = [w]# 计算初始参数的对数先验和对数似然log_prior_current = log_prior_computer(w)log_likelihood_current = log_likelihood_computer(w, data)log_posterior_current = log_likelihood_current + log_prior_currentfor i in range(iterations):# 生成新的参数采样点w_new = random_proposal(w, step_size)# 计算新采样点的对数先验和对数似然log_prior_new = log_prior_computer(w_new)log_likelihood_new = log_likelihood_computer(w_new, data)log_posterior_new = log_likelihood_new + log_prior_new# 对数接受概率log_acceptance_probability = min(0, log_posterior_new - log_posterior_current)# 接受或拒绝新采样点accept = np.log(np.random.rand()) < log_acceptance_probabilityif accept:# 更新当前参数值w = w_new.copy()log_prior_current = log_prior_newlog_likelihood_current = log_likelihood_newlog_posterior_current = log_posterior_newsamples.append(w.copy())return np.array(samples)# 预测新数据点
def predict(posterior_samples, x0_new, x1_new):prediction_mean_list = []for item in range(len(x0_new)):# 计算每个样本的预测值predictions = posterior_samples[:, 0] + posterior_samples[:, 1] * x0_new[item] + posterior_samples[:, 2] * x1_new[item]prediction_mean = np.mean(predictions)prediction_mean_list.append(prediction_mean)return np.array(prediction_mean_list) # 加载数据
data = pd.read_csv('train_set.csv')
test_data = pd.read_csv('test_set.csv')
# 模拟数据
np.random.seed(42) # 设置随机种子
true_w0 = 1
true_w1 = 3
true_w2 = -2
x0_data = data['x0'].values
x1_data = data['x0'].values
y_data = data['y'].values
test_X0 = test_data['x0'].values
test_X1 = test_data['x1'].values
test_y = test_data['y'].values
print(x0_data.shape,x1_data.shape,y_data.shape)# 运行 Metropolis-Hastings 算法
iterations = 10000
samples = metropolis_hastings(log_likelihood, log_prior, random_proposal, iterations, data=(x0_data, x1_data, y_data))# 查看参数的后验分布
burn_in = 8000 # 预热期间的样本数
posterior_samples = samples[burn_in+1:]
posterior_samples_mean = np.mean(posterior_samples,axis=0)
print(posterior_samples_mean)
y_pred = predict(posterior_samples,test_X0,test_X1)mse = mean_squared_error(test_y, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(test_y, y_pred)
r2 = r2_score(test_y, y_pred)# 打印统计指标
print(f'Mean Squared Error (MSE): {mse}')
print(f'Root Mean Squared Error (RMSE): {rmse}')
print(f'Mean Absolute Error (MAE): {mae}')
print(f'R-squared (R2): {r2}')
这段代码是一个 Python 脚本,它实现了贝叶斯线性回归模型,并通过 Metropolis-Hastings 算法(一种马尔可夫链蒙特卡洛方法)来进行参数估计。脚本中用到了 NumPy、SciPy、Pandas、和 scikit-learn 这些库。
以下是代码的具体步骤和组成部分的解释:
- 导入必要的库:
numpy用于数组和矩阵运算;matplotlib.pyplot通常用于绘制图形,但在这段代码中并未使用;scipy.stats用于统计操作,这里主要用于正态分布的概率密度函数;pandas用于数据操作和分析,特别是用于读取 CSV 文件和数据处理;sklearn.metrics提供了用于评估预测误差的函数。
- 定义对数似然函数
log_likelihood,它接收参数w(模型的权重)和数据data,并根据正态分布返回给定数据下模型参数w的对数似然值。 - 定义对数先验分布
log_prior,它基于模型参数w的正态分布先验,返回参数的对数先验概率。 - 定义随机提案函数
random_proposal,它用于在 Metropolis-Hastings 算法中生成新的参数样本,通过添加正态分布噪声实现。 - 实现 Metropolis-Hastings 算法的
metropolis_hastings函数。这个函数执行以下步骤:
- 初始化参数值;
- 在每次迭代中生成新的参数样本;
- 根据新旧样本的对数后验概率差计算接受率;
- 用一个随机数与接受率比较来确定是否接受新样本;
- 重复上述过程直到完成指定次数的迭代;
- 返回所有的样本。
- 定义
predict函数,它使用后验样本来预测新数据点的响应值的均值。 - 加载训练和测试数据集。
- 设置随机种子以确保结果的可重复性。
- 从训练数据中提取输入特征
x0_data,x1_data和目标变量y_data。 - 运行 Metropolis-Hastings 算法以获得模型参数的样本。
- 定义并移除后验样本中的“烧入”期,这是模拟的开始部分,可能还没有收敛。
- 计算去除“烧入”样本后的后验样本的均值。
- 使用训练好的模型和后验样本对测试数据集进行预测。
- 计算并打印出模型预测的统计指标,包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和 R-squared 值。
代码的主要目的是展示如何通过贝叶斯方法和 MCMC 算法来进行线性回归模型的参数估计,并对新数据进行预测,最后评估模型的预测性能。这是机器学习和统计模型中的一种常见方法,特别是在涉及到不确定性估计和概率编程时。
相关文章:

频率主义线性回归和贝叶斯线性回归
整体概述 频率主义(Frequentist)线性回归和贝叶斯(Bayesian)线性回归是统计学中用于数据分析和预测的两种主要方法,特别是在建模关于因变量和自变量之间线性关系的上下文中。尽管两种方法都用于线性回归分析ÿ…...
)
【感知算法】Dempster-Shafer理论(下)
尝试DS理论应用到自动驾驶地图众包更新。 地图特征变化判断 a mass function is applied to quantify the evidence of the existence. existence state: existenct、non-existent、tenative、conflict ∃ ∄ Ω ϕ \exist \\ \not\exist \\ \Omega \\ \phi ∃∃Ωϕ ma…...

通过conda安装cudatoolikit和cudnn
通过conda安装cudatoolikit和cudnn 安装cudatoolkit安装cudnn安装cudatoolkit-dev 安装cudatoolkit conda install cudatoolkit11.3 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ 安装cudnn conda install cudnn8.5 -c https://mirrors.tuna.tsinghua.edu.…...

vue中使用jsx语法
请注意,在 Vue 中使用 JSX 时,你仍然需要通过 h 函数(通常是一个别名,对应于 createElement 函数)来创建虚拟 DOM 元素。在下面的例子中,h 函数作为 render 函数的参数传入,但在 JSX 语法中你通…...
我的NPI项目之Android USB 系列(一) - 遥望和USB的相识
和USB应该是老朋友了,从2011年接触Android开发开始,就天天和USB打交道了。那时候还有不 对称扁头的usb/方口的usb,直到如今使用广泛的防反插USB3.0 type-C。 但是,一直有一个不是很清楚的问题萦绕在心头,那就是。先有…...
K8s进阶之路-命名空间级-服务发现 :
服务发现: Service(东西流量):集群内网络通信、负载均衡(四层负载)内部跨节点,节点与节点之间的通信,以及pod与pod之间的通信,用Service暴露端口即可实现 Ingress&#…...

智慧公厕管理系统:让城市智慧驿站更加智慧舒适
智慧公厕管理系统是城市智慧驿站中不可或缺的一部分,它通过全方位的信息化解决方案,为公共厕所的使用、运营和管理提供了一种智能化的方式。作为城市智慧驿站的重要组成部分,智慧公厕管理系统发挥着重要的作用,为城市社会民生提供…...
图形渲染基础学习
原文链接:游戏开发入门(三)图形渲染_如果一个面只有三个像素进行渲染可以理解为是定点渲染吗?-CSDN博客 游戏开发入门(三)图形渲染笔记: 渲染一般分为离线渲染与实时渲染,游戏中我们用的都是…...

每日学习总结20240219
每日总结 20240219 1.文件类型.csv CSV文件是一种以逗号分隔值(Comma-Separated Values)为标记的文本文件,它可以用来存储表格数据。每一行表示一条记录,而每一条记录中的字段则使用逗号或其他特定的分隔符进行分隔。 常用场景…...

K8s进阶之路-安装部署K8s
参考:(部署过程参考的下面红色字体文档链接就可以,步骤很详细,重点部分在下面做了标注) 安装部署K8S集群文档: 使用kubeadm方式搭建K8S集群 GitBook 本机: master:10.0.0.13 maste…...
springboot集成elk实现日志采集可视化
一、安装ELK 安装ELK组件请参考我这篇博客:windows下安装ELK(踩坑记录)_windows上安装elk教程-CSDN博客 这里不再重复赘述。 二、编写logstash配置 ELK组件均安装好并成功启动,进入到logstash组件下的config文件夹,创建logstash.conf配置…...

leetcode 148. 排序链表 java解法
Problem: 148. 排序链表 思路 这是一个链表排序的问题,由于要求时间复杂度为 O(nlogn),适合使用归并排序(Merge Sort)来解决。 解题方法 首先,使用快慢指针找到链表的中间节点,将链表分成两部分。然后&…...
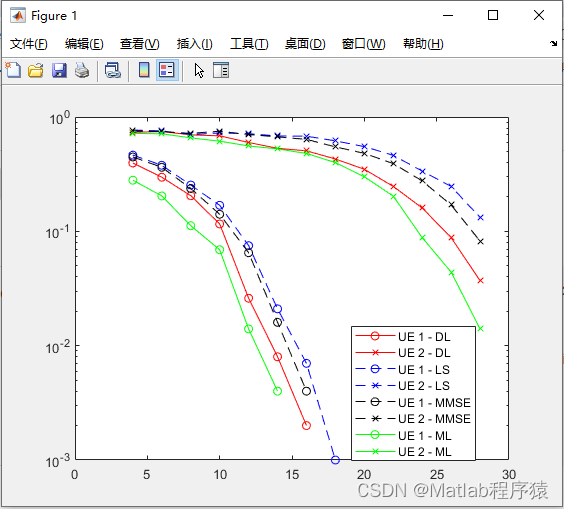
【MATLAB源码-第140期】基于matlab的深度学习的两用户NOMA-OFDM系统信道估计仿真,对比LS,MMSE,ML。
操作环境: MATLAB 2022a 1、算法描述 深度学习技术在无线通信领域的应用越来越广泛,特别是在非正交多址接入(NOMA)和正交频分复用(OFDM)系统中,深度学习技术被用来提高信道估计的性能和效率。…...

运动重定向学习笔记
目录 深度学习 重定向 2020年的模型: 重定向之后的bvh: 深度学习 重定向 输入是bvh,输出也是bvh...

导出Excel,支持最佳
列表信息导出为Excel文件, 依赖pom: Sheet, Row:<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId> </dependency>XSSFWorkbook <dependency><groupId>org.apache.poi</…...

【WPF】获取父控件数据
MaxHeight"{Binding PathActualHeight, RelativeSource{RelativeSource ModeFindAncestor, AncestorTypeUserControl}}" 参考文献 https://www.cnblogs.com/-Timosthetic/p/16021865.html...
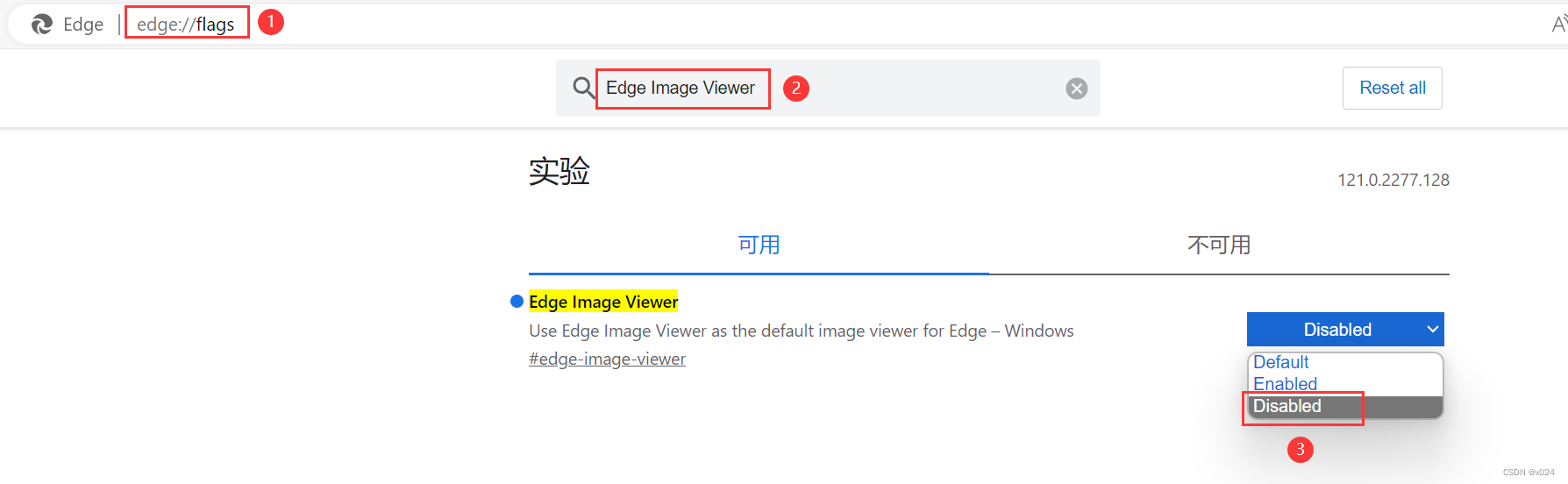
解决Edge浏览器,微博无法查看大图(Edge Image Viewer)
使用Edge浏览器浏览微博或其它带校验的图片时,会导致无法查看。 主要原因为Edge自带了一个Edge Image Viewer, 但是该图片查看器无法查看带校验数据的图片,所以导致查看时一片空白。 解决方法 地址栏输入 edge://flags/搜索 Edge Image Viewer选择 Disa…...
PMP含金量在国内怎么样?
其一、PMP(项目管理师)证书含金量高吗? PMP认证是由美国项目管理学会(PMI)在全球范围内推出的针对项目经理的资格认证体系,其证书含金量可以说是非常高。 统计表明,全球年销售收入在5亿美元以上的企业中有86%聘用了具有项目管理资质的项目经…...
java中容易被忽视的toString()方法
之前一直认为toString就是将数据转换成字符类型,直到最近写出了一个bug才对toString有了新的认识 不同数据类型,toString() 有不同的操作 定义一个student类,包含姓名 String类型、性别 String类型、年龄 int 类型、分数列表 String类型的li…...
如何使用Docker搭建YesPlayMusic网易云音乐播放器并发布至公网访问
文章目录 1. 安装Docker2. 本地安装部署YesPlayMusic3. 安装cpolar内网穿透4. 固定YesPlayMusic公网地址 本篇文章讲解如何使用Docker搭建YesPlayMusic网易云音乐播放器,并且结合cpolar内网穿透实现公网访问音乐播放器。 YesPlayMusic是一款优秀的个人音乐播放器&am…...

AI术语速查卡:50个高频词的实战解读与避坑指南
1. 这不是词典,是AI时代的生存速查卡你有没有过这种体验:刚打开一篇AI技术文章,三句话里冒出“transformer”“fine-tuning”“latent space”——每个词都像蒙着雾的玻璃窗,看得见轮廓,摸不着边界?开会时同…...
)
保姆级教程:在Ubuntu 22.04上配置VNC Server,并用VNC Viewer远程桌面(解决加密报错)
深度解析Ubuntu 22.04 VNC远程桌面配置与加密协议调优实战 在分布式开发和远程协作成为主流的今天,掌握高效的远程桌面技术已成为开发者和运维人员的必备技能。Ubuntu作为最受欢迎的Linux发行版之一,其内置的VNC服务为远程访问提供了原生支持,…...

AI时代软件工程教育:同理心融入技术课程的教学实践
1. 项目概述:当代码遇见人心最近几年,我一直在高校和培训机构里讲授软件工程相关的课程,从传统的软件生命周期、设计模式,到如今火热的敏捷开发、DevOps。一个越来越强烈的感受是:我们的技术教育,似乎正在与…...
)
SAP财务实操:FBV0/FB08凭证冲销与FBV1预制凭证的完整流程(附BADI增强代码)
SAP财务凭证处理实战:从冲销到增强的全链路解决方案 月末关账前发现凭证金额错误怎么办?批量处理上百张供应商发票如何避免手工录入?这些场景恰恰是SAP财务模块中FBV0、FBV1、FB08等事务代码的核心战场。本文将带您穿透事务代码的表层操作&am…...

AutoDL新手避坑:Ubuntu 20.04安装Xfce4桌面环境,告别VNC黑屏
AutoDL云平台Xfce4桌面环境配置全攻略:从零搭建到VNC可视化开发 对于刚接触AutoDL等云GPU平台的新手开发者而言,命令行操作往往成为第一道门槛。当需要运行PaddleX这类图形化AI开发工具时,配置可用的远程桌面环境更是常见痛点。本文将彻底解决…...

避坑指南:Ubuntu 20.04上VINS-Fusion环境搭建,从源码修改到手机数据实测的完整流程
Ubuntu 20.04下VINS-Fusion环境搭建全流程避坑手册 当你在Ubuntu 20.04上尝试搭建VINS-Fusion环境时,可能会遇到各种令人头疼的问题。从依赖项安装到源码修改,再到手机摄像头数据的适配,每一步都可能隐藏着意想不到的"坑"。本文将带…...

Open Generative AI与Stable Diffusion对比:开源AI生成平台的5大优势
Open Generative AI与Stable Diffusion对比:开源AI生成平台的5大优势 【免费下载链接】Open-Generative-AI Open-source alternative to AI video platforms — Free AI image & video generation studio with 200 models (Flux, Midjourney, Kling, Sora, Veo)…...

别再为查重和 AIGC 检测头秃!okbiye 降重 + 降 AIGC 双功能,论文安全过审的最后一道防线
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 一、前言:论文提交前,你最怕的两个 “隐形杀手” 论文写到定稿,才发现重复率超标、AIGC 检测不过&am…...
:LiveZoom 实时放大——无闪屏放大与多屏演示技巧)
《Sysinternals实战指南》ZoomIt 学习笔记(11.12):LiveZoom 实时放大——无闪屏放大与多屏演示技巧
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

从 0 到 1 搭建 RuoyiOffice:30 分钟跑通后端+前端+移动端
从 0 到 1 搭建 RuoyiOffice:30 分钟跑通后端前端移动端 🌐 演示地址:http://ruoyioffice.com | 📦 源码1:https://gitcode.com/zhouzhongyan/ruoyi-office-vben.git | 📦 源码2:https://gitcod…...