基于 RisingWave、Instaclustr 和 Apache Superset 对维基百科实时监控
得益于 RisingWave 和 Kafka 等流处理工具, 数据工程师能实时洞察流数据中的重要信息。这能够助力制定决策,并在多个层面改善用户体验,包括推荐系统、金融、物流、汽车、制造业、 IIOT 设备和零售。
在这篇博客中,我们会把 RisingWave 和部署在 Instaclustr 云上的 Kafka 以及 Apache Superset 结合起来,用于监控维基百科编辑情况。我们将深入了解这三个工具如何无缝集成、合作实现监控目标。
RisingWave 是一个与 PostgreSQL 兼容的流数据库,具有真正的云原生架构,拥有低成本高效益、可扩展等特点。基于 RisingWave,用户仅使用 SQL 就能从流数据中获取目标信息。
Instaclustr 是一个集成了众多流行开源工具(如 Kafka、PostgreSQL、Cassandra 和 Redis)的完全托管平台。它提供了方便的 Kafka Connect 集成,包括专用的 ZooKeeper 服务。通过这种 100% 开源方案,Instaclustr 提供了无缝使用 Kafka 的体验。
技术栈
我们将从 Wikipedia API 获取实时数据,捕获维基百科文章的编辑和贡献者信息,然后将它们发布到 Kafka Topic。
随后,数据将被导入 RisingWave。基于这些数据,我们将创建物化视图来执行一系列操作,如聚合、时间窗口操作、数据转换等,以从数据中提取有价值的信息。
最后,我们会把处理后的数据从 RisingWave 导出到 Apache Superset,从而将数据可视化,用更具体直观的方式查看贡献者们对维基百科的实时编辑。

技术栈
在 Instaclustr 云上部署 Kafka
为开始生成事件,我们需要一个 Kafka 集群。在本文的演示中,我们将用 Instaclustr 云创建一个 Kafka 集群。
创建 Kafka 集群
首先,请注册免费的 Instaclustr 账号以获得访问 Kafka 服务的权限。您可以通过访问 [Instaclustr 云] 平台来创建账户。

Instaclustr 云账户注册
接着,请参考 Instaclustr 云提供的 Apache Kafka 快速上手指南,在 Instaclustr 云上创建一个 Kafka 集群。
成功创建 Kafka 集群后,请添加您计算机的 IP 地址到集群中,以便产生和使用数据。

添加计算机 IP 地址到集群
将维基百科编辑数据传输到 Kafka
我们将首先使用维基百科 Python API 来获取各种信息,如用户贡献、用户详细信息和最近更改。
随后,我们会把这些数据传输到 Instaclustr 云上的 Kafka 集群中,以便后续将数据导入 RisingWave。
我们的 JSON 消息将遵循以下 schema:
"contributor": 维基百科贡献者的名字。
"title": 所编辑的维基百科文章的标题。
"edit_timestamp": 编辑的时间戳。
"registration": 该维基百科用户的注册日期。
"gender": 该维基百科用户的性别。
"edit_count": 该维基百科用户的编辑次数。以下是一个发送到 Kafka Topic 的消息样本:
{"contributor": "Teatreez","title": "Supreme Court of South Africa","edit_timestamp": "2023-12-03 18:23:02","registration": "2006-12-30 18:42:21","gender": "unknown","edit_count": "10752"
}
连接 RisingWave 与 Kafka Topic
要使用 RisingWave,请参考快速上手指南创建一个 RisingWave 集群。
随后,为了 RisingWave 和 Instaclustr 能成功连接,请先前往 Instaclustr,将您的 RisingWave 集群的 NAT 网关 IP 地址添加到 Instaclustr 云中 Kafka 集群的防火墙规则(Firewall Rules)中。这一步有利于避免潜在的连接错误。
成功创建 RisingWave 集群后,我们在 RisingWave 中创建一个 Source,用于从 Instaclustr 云中的 Kafka Topic 导入数据到RisingWave。
请使用以下查询创建一个连接到 Instaclustr 云中 Kafka Topic 的 Source,注意,各认证参数需要准确填写对应的值。
CREATE SOURCE wiki_source (contributor VARCHAR,title VARCHAR,edit_timestamp TIMESTAMPTZ,registration TIMESTAMPTZ,gender VARCHAR,edit_count VARCHAR
) WITH (connector = 'kafka',topic='Insta-topic',properties.bootstrap.server = 'x.x.x.x:9092',scan.startup.mode = 'earliest',properties.sasl.mechanism = 'SCRAM-SHA-256',properties.security.protocol = 'SASL_PLAINTEXT',properties.sasl.username = 'ickafka',properties.sasl.password = 'xxxxxx'
) FORMAT PLAIN ENCODE JSON;
然后,我们基于 Source wiki_source 创建一个名为 wiki_mv 的物化视图。注意,以下代码中,我们过滤掉了带有空值的行。
CREATE MATERIALIZED VIEW wiki_mv AS
SELECTcontributor,title,CAST(edit_timestamp AS TIMESTAMP) AS edit_timestamp,CAST(registration AS TIMESTAMP) AS registration,gender,CAST(edit_count AS INT) AS edit_count
FROM wiki_source
WHERE timestamp IS NOT NULLAND registration IS NOT NULLAND edit_count IS NOT NULL;
现在,我们可以查询物化视图,获取 Source 中的最新数据:
SELECT * FROM wiki_mv LIMIT 5;
返回结果将类似如下:
contributor | title | edit_timestamp | registration | gender | edit_count
---------------+-----------------------------+---------------------------+---------------------------+---------+-----------Omnipaedista | Template:Good and evil | 2023-12-03 10:22:02+00:00 | 2008-12-14 06:02:32+00:00 | male | 222563
PepeBonus | Moshi mo Inochi ga Egaketara| 2023-12-03 10:22:16+00:00 | 2012-06-02 13:39:53+00:00 | unknown | 20731
Koulog | Ionikos F.C. | 2023-12-03 10:23:00+00:00 | 2023-10-28 05:52:35+00:00 | unknown | 691
Fau Tzy | 2023 Liga 3 Maluku | 2023-12-03 10:23:17+00:00 | 2022-07-23 09:53:11+00:00 | unknown | 4697
Cavarrone | Cheers (season 8) | 2023-12-03 10:23:40+00:00 | 2008-08-23 11:13:14+00:00 | male | 83643(5 rows)
接下来,我们再创建几个查询:
以下查询创建了一个新的物化视图 gender_mv,将物化视图 wiki_mv 中的贡献按一分钟间隔进行聚合。该物化视图计算了多个数据,包括每个时间窗口内的总贡献数、未知性别者的贡献数,以及已知性别者的贡献数。基于此物化视图,我们可以更方便地基于性别对贡献模式进行分析和监控。
CREATE MATERIALIZED VIEW gender_mv AS
SELECT COUNT(*) AS total_contributions,
COUNT(CASE WHEN gender = 'unknown' THEN 1 END) AS contributions_by_unknown,
COUNT(CASE WHEN gender != 'unknown' THEN 1 END) AS contributions_by_male_or_female,
window_start, window_end
FROM TUMBLE (wiki_mv, edit_timestamp, INTERVAL '1 MINUTES')
GROUP BY window_start, window_end;
以下查询创建了物化视图 registration_mv ,它同样将物化视图 wiki_mv 中的贡献按一分钟间隔进行聚合,计算的信息包括:总贡献数、2020年1月1日之前注册账户的贡献数,以及2020年1月1日之后注册账户的贡献数。
CREATE MATERIALIZED VIEW registration_mv AS
SELECT COUNT(*) AS total_contributions,
COUNT(CASE WHEN registration < '2020-01-01 01:00:00'::timestamp THEN 1 END) AS contributions_by_someone_registered_before_2020,
COUNT(CASE WHEN registration > '2020-01-01 01:00:00'::timestamp THEN 1 END) AS contributions_by_someone_registered_after_2020,window_start, window_end
FROM TUMBLE (wiki_mv, edit_timestamp, INTERVAL '1 MINUTES')
GROUP BY window_start, window_end;
以下查询创建了物化视图 count_mv,将 wiki_mv 物化视图中的贡献按一分钟间隔进行聚合,然后计算:总贡献数、编辑次数少于 1000 次的贡献者的贡献数,以及编辑次数大于等于 1000 次的贡献者的贡献数。
CREATE MATERIALIZED VIEW count_mv AS
SELECTCOUNT(*) AS total_contributions,COUNT(CASE WHEN edit_count < 1000 THEN 1 END) AS contributions_less_than_1000,COUNT(CASE WHEN edit_count >= 1000 THEN 1 END) AS contributions_1000_or_more,window_start, window_end
FROM TUMBLE(wiki_mv, edit_timestamp, INTERVAL '1 MINUTES')
GROUP BY window_start, window_end;
将数据从 RisingWave 导出到 Apache Superset 进行可视化
Superset 是一个用于创建看板和可视化内容的开源工具。接下来我们将配置 Superset,从 RisingWave 读取数据并导出到 Superset 进行可视化。
连接 RisingWave 和 Superset
请按照 RisingWave 文档中的指南,配置 Superset 从 RisingWave 读取数据。在此过程中,我们会把 RisingWave 作为数据源添加到 Apache Superset 中,并使用其中的表和物化视图创建可视化和看板。
成功将 RisingWave 连接到 Apache Superset 后,您可以按照该指南剩下部分的指导,将 RisingWave 中的物化视图作为数据集进行添加,创建表、图表和整合后的看板。
可视化结果展示:表、图表和看板
下表使用wiki_mv数据集生成,显示了 Wikipedia 贡献者的名字、注册日期、性别、编辑次数以及贡献者编辑过的 Wikipedia 文章等信息。

Wikipedia 贡献者表
以下面积图使用count_mv数据集创建,展示了指定时间窗口内的:总贡献数、编辑次数少于 1000 次的贡献者的贡献数,以及编辑次数大于等于 1000 次的贡献者的贡献数。

Wikipedia 贡献面积图:根据贡献者编辑次数展示贡献分布
以下折线图基于gender_mv数据集生成,展示了指定时间窗口内的:总贡献数、未知性别者的贡献,以及已知性别者的贡献。

Wikipedia 贡献折线图:根据贡献者性别分析贡献模式
下图则使用registration_mv数据集创建,在 1 分钟的时间窗口内可视化了各种类型的贡献计数,包括:总贡献数、2020年1月1日之前注册的用户的贡献数,以及2020年1月1日之后注册的用户的贡献数。

Wikipedia 贡献图:根据贡献者注册日期可视化贡献情况
最后,以下是一个整合了以上各项图表的看板,让您可以全面、实时地监控 Wikipedia 编辑信息,以全面地挖掘贡献者及其所编辑文章相关的重要信息。

基于贡献者信息的 Wikipedia 编辑实时监控看板
结论
在这篇博文中,我们介绍了一种流处理解决方案,用于实时监控维基百科中不同贡献者对多篇文章的编辑情况。我们从维基百科 API 中提取数据,并将其传输到部署在 Instaclustr 云中的 Kafka Topic。然后,我们在 RisingWave 创建了 Source 以摄取 Kafka 数据,并创建物化视图进行处理分析。为了更具体直观地展示所得信息,我们又利用 Superset 的强大功能对结果进行可视化,生成各类图表和综合看板。至此,我们即可全面且动态地了解维基百科的编辑情况。
RisingWave 是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于为用户提供极致简单、高效的流数据处理与管理能力。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,并助力用户极大地简化流计算架构,轻松搭建稳定且高效的流计算应用。RisingWave 始终聆听来自社区的声音,并积极回应用户的反馈。目前,RisingWave 已汇聚了近 150 名开源贡献者和近 3000 名社区成员。全球范围内,已有上百个 RisingWave 集群在生产环境中部署。
了解更多:
官网: risingwave.com
入门教程:快速上手 | RisingWave
GitHub:risingwave.com/github
微信公众号:RisingWave中文开源社区
中文社区用户交流群:risingwave_assistant
英文社区用户交流群:https://risingwave.com/slack
相关文章:
基于 RisingWave、Instaclustr 和 Apache Superset 对维基百科实时监控
得益于 RisingWave 和 Kafka 等流处理工具, 数据工程师能实时洞察流数据中的重要信息。这能够助力制定决策,并在多个层面改善用户体验,包括推荐系统、金融、物流、汽车、制造业、 IIOT 设备和零售。 在这篇博客中,我们会把 Risin…...

建站用帝国CMS好还是WordPress好
随着互联网的迅猛发展,内容管理系统(CMS)在网站建设中扮演着越来越重要的角色。在众多CMS中,帝国CMS和WordPress因其强大的功能和广泛的用户基础而备受关注。本文将对这两种CMS进行详细比较,分析它们的优势与不足,以便用户能够根据…...
—图》)
深度学习基础之《TensorFlow框架(2)—图》
一、什么是图结构 1、图包含了一组tf.Operation代表的计算单元对象和tf.Tensor代表的计算单元之间流动的数据 图结构:数据(Tensor) 操作(Operation) 二、图相关操作 1、默认图 通常TensorFlow会默认帮我们创建一张图 查看默认图的两种方法: &#x…...

Web3区块链游戏:创造虚拟世界的全新体验
随着区块链技术的不断发展,Web3区块链游戏正逐渐崭露头角,为玩家带来了全新的虚拟世界体验。传统游戏中的中心化结构和封闭经济体系已经被打破,取而代之的是去中心化的游戏环境和真实所有权的数字资产。本文将深入探讨Web3区块链游戏的特点、…...

单机启动/开机启动SpringBoot服务的正确方式
此操作只针对于测试环境或单机部署的情况下,使用Jenkins自动化部署或docker部署SpringBoot服务请忽略。 SpringBoot单机启动和集群启动的区别: 部署方式:单机启动可以直接运行jar文件或使用IDE启动应用程序,而双机集群启动需要将…...

[C#]winform基于opencvsharp结合CSRNet算法实现低光图像增强黑暗图片变亮变清晰
【算法介绍】 "Conditional Sequential Modulation for Efficient Global Image Retouching" 是一种图像修饰方法,主要用于对图像进行全局的高效调整。该方法基于深度学习技术,通过引入条件向量来实现对图像特征的调制,以达到改善…...

抓包分析 TCP 协议
TCP 协议是在传输层中,一种面向连接的、可靠的、基于字节流的传输层通信协议。 环境准备 对接口测试工具进行分类,可以如下几类: 网络嗅探工具:tcpdump,wireshark 代理工具:fiddler,charles&…...

代码随想录算法训练营day27 | 93.复原IP地址、78.子集、90.子集II
93.复原IP地址 和C不同,使用列表存储已经分割的数据,而不是直接操作字符串。为了使用这个列表搞了老久,主要问题出在,在判断终止条件的时候,path也需要回溯一下 class Solution:def __init__(self):self.result []s…...

RuntimeError: CUDA out of memory.【多种场景下的解决方案】
RuntimeError: CUDA out of memory.【多种场景下的解决方案】 🌈 个人主页:高斯小哥 🔥 高质量专栏:【Matplotlib之旅:零基础精通数据可视化】 🏆🏆关注博主,随时获取更多关于深度学…...

LeetCode刷题| Leetcode 45. 跳跃游戏,1190. 反转每对括号间的子串,781. 森林中的兔子,739. 每日温度
45. 跳跃游戏 题目链接: 45. 跳跃游戏 II - 力扣(LeetCode) 思路:这道题思路不难记,遍历数组每个位置,更新下一次的范围,当当前位置已经在当前范围之外时,步数一定得加一ÿ…...
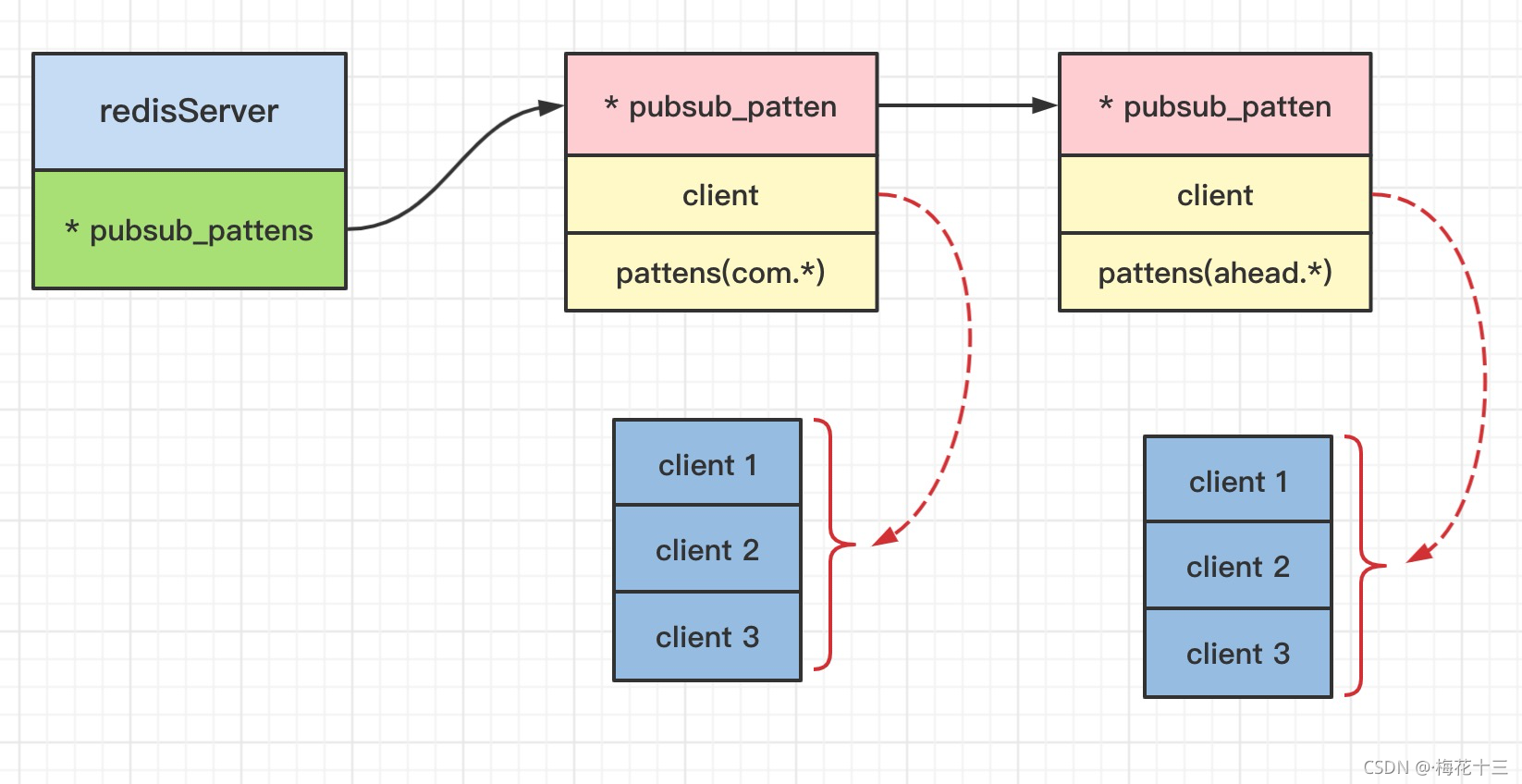
Redis(03)——发布订阅
基础命令 基于频道 publish channel message:将信号发送到指定的频道pubsub subcommand [argument [argyment]]:查看订阅或发布系统状态subscribe channel [channel]:订阅一个或多个频道的信息unsubscribe [channel [channel]]:退…...
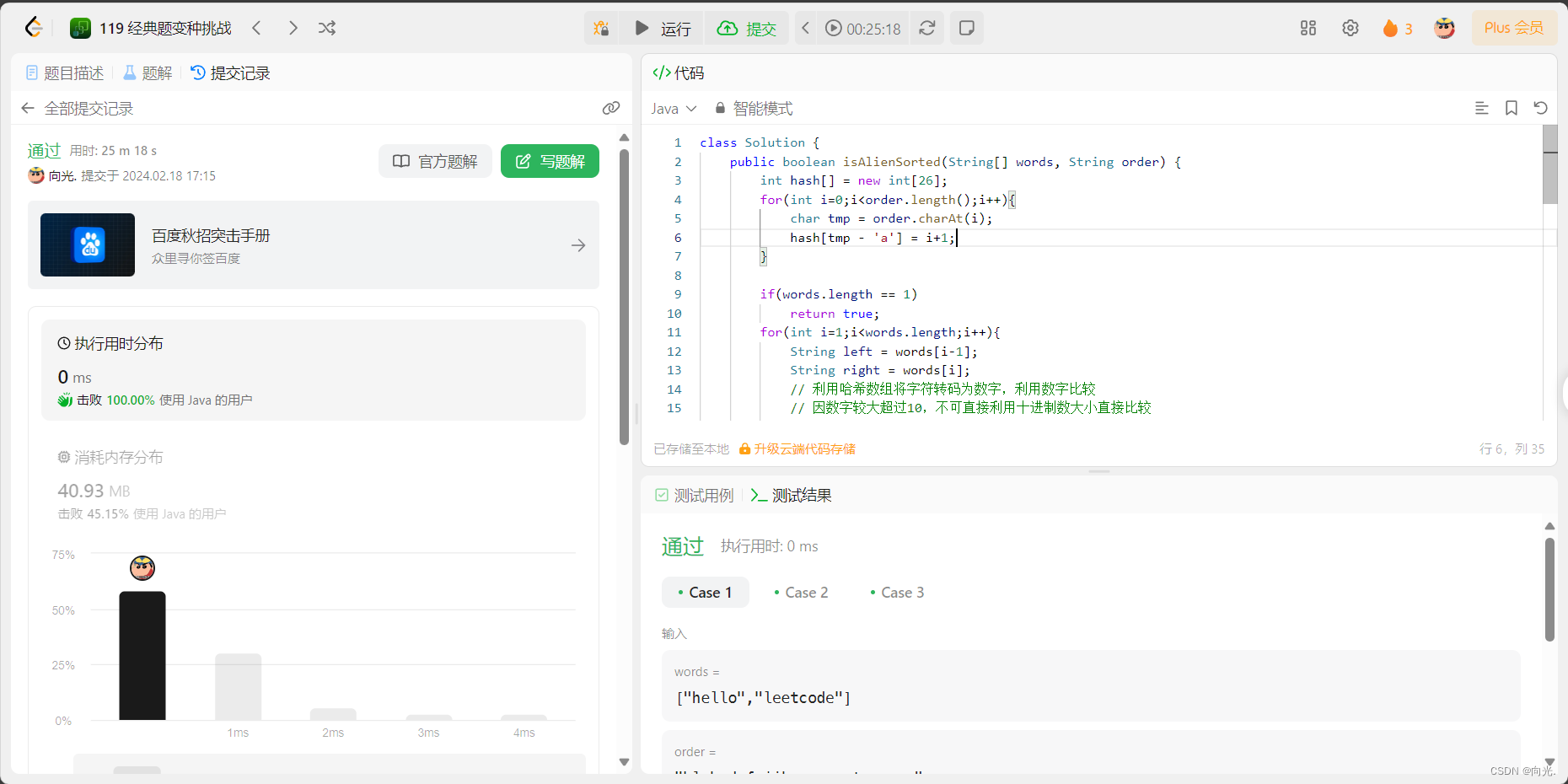
⭐北邮复试刷题LCR 034. 验证外星语词典__哈希思想 (力扣119经典题变种挑战)
LCR 034. 验证外星语词典 某种外星语也使用英文小写字母,但可能顺序 order 不同。字母表的顺序(order)是一些小写字母的排列。 给定一组用外星语书写的单词 words,以及其字母表的顺序 order,只有当给定的单词在这种外…...
)
ECMAScript 6+ 新特性 ( 二 )
2.12. class类 ES6 提供了更接近传统语言的写法,引入了 Class(类)这个概念,作为对象的模板。通过 class 关键字,可以定义类。 ES6 的 class 可以看作只是一个语法糖,它的绝大部分功能ES5 都可以做到&…...

JS游戏项目合集【附源码】
文章目录 一:迷宫小游戏二:俄罗斯方块三:压扁小鸟 一:迷宫小游戏 【迷宫游戏】是一款基于HTML5技术开发的游戏,玩法简单。玩家需要在一个迷宫中找到出口并成功逃脱,本项目还有自动寻路(Track&a…...

React中hooks使用限制及保存函数组件状态
React Hooks 的限制主要有两条: 不要在循环、条件或嵌套函数中调用 Hook; 在 React 的函数组件中调用 Hook。 首先,Hooks是一个对象,大致结构如下: const hook: Hook {memoizedState: null,baseState: null,baseQ…...

用git命令来上传项目到GitHub我自己的仓库
目录 在GitHub上创建仓库并使用git命令上传到仓库的步骤如下: 其他操作 怎么退出git/COMMIT_EDITMSG [unix] 相关报错 error: src refspec main does not match any error: failed to push some refs to https://github.com/Liu22Jun16Liang/MyQt error: fail…...

.NET有哪些微服务框架
1.概述 想要对.net的微服务方案进行一下调查,看有什么可选的方案和框架,与spring clound相比.net 创建微服务是相对较麻烦的。 ID名称说明1Service FabricSteeltoe是帮助.NET开发的服务接入Spring Cloud技术栈的官方支持工具。也就是说,微服…...

uniapp中打开蓝牙需要哪些权限
在uniApp中进行蓝牙连接,需要获取以下权限: 蓝牙权限:用于扫描和连接蓝牙设备。定位权限:用于获取设备的位置信息,以便确定设备与蓝牙设备之间的距离。存储权限:用于读取和写入与蓝牙设备相关的数据。 获…...
virtualbox虚拟机运行中断,启动报错“获取 VirtualBox COM 对象失败”
文章目录 问题现象排查解决总结 问题现象 2月7日下午四点多,我已经休假了,某县的客户运维方打来电话,说平台挂了,无法访问客户是提供的一台Windows server机器部署平台,是使用virtualbox工具安装的CentOS7.9虚拟机和运…...

【JVM篇】什么是运行时数据区
文章目录 🍔什么是运行时数据区⭐程序计数器⭐栈🔎Java虚拟机栈🎈栈帧的内容 🔎本地方法栈 ⭐堆⭐方法区 🍔什么是运行时数据区 运行时数据区指的是jvm所管理的内存区域,其中分为两大类 线程共享…...

CANN-Ascend-C存储体系-昇腾NPU的四级缓存怎么用才算对
写 Ascend C 算子,最常犯的错误不是计算写错,是数据搬运写错。昇腾NPU有四级存储,每一级的容量、带宽、延迟都不同。数据该放在哪一级、什么时候搬、搬多少,直接决定算子性能。 四级存储级别名称容量带宽延迟用途L0HBM(…...

论文修改踩坑无数?paperxie 帮你一站式搞定查重与 AIGC 降重难题
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/weight?type1https://www.paperxie.cn/weight?type1 作为一名被论文查重和 AIGC 检测反复折磨过的过来人,我深知毕业季里,对着飘红的查重报告和居高…...

OAuthlib错误排查实战:从invalid_grant到server_error的根因定位
1. 为什么OAuthlib的错误信息总让你一头雾水?刚接手一个老项目,登录流程突然崩了,控制台只甩出一行红字:invalid_grant。我下意识去翻OAuthlib文档,结果发现它压根不解释这个错误到底意味着什么——它只告诉你“授权无…...
安装 NVIDIA 显卡驱动)
麒麟系统(桌面版)安装 NVIDIA 显卡驱动
麒麟系统(桌面版)安装 NVIDIA 显卡驱动 一、确认系统和显卡信息 # 查看系统版本 cat /etc/kylin-release# 查看内核版本 uname -r# 查看显卡型号 lspci | grep -i nvidia二、更新系统并安装编译依赖 sudo apt update && sudo apt upgrade -y sud…...

DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全
DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全 一句话收益:掌握从 SharedPreferences 迁移到 Jetpack DataStore 的完整路径,彻底消除主线程 I/O 阻塞与类型安全隐患。 适用版本:Android API 21&…...

Keil MDK C166工具链Watch窗口数组显示异常解决方案
1. 问题现象与影响范围解析在Keil MDK开发环境中使用C166工具链时,开发者可能会遇到一个棘手的调试器显示问题:Watch窗口中的数组和指针数值显示异常。具体表现为数组地址计算错误,进而导致所有数组成员的数值显示都不正确。这个问题不仅影响…...

2026年国内镜像站安全与效率评测:GPT-5.5的真实体验
在国内访问海外大模型,延迟高、连接不稳、支付合规是老生常谈的三座大山。为了完成本次GPT-5.5的全流程实测,我借助库拉AI聚合平台完成了所有调用——该平台支持国内外主流AI模型的统一对接,国内可直连访问,注册用户每日提供可用额…...

利用 AI 导出鸭将 DeepSeek 内容一键转为 PDF
在日常使用 AI 助手进行技术调研或文档整理时,我们常常会遇到一个痛点:生成的优质内容往往停留在网页对话框中,难以直接转化为便于归档、打印或离线阅读的格式。尤其是像 DeepSeek 这样输出结构清晰、代码片段丰富的长文,如果只能…...

【限时解密】:OpenAI DevDay未公布的Agent Runtime协议草案V2.1——它正悄然定义下一代智能体互操作标准
更多请点击: https://kaifayun.com 第一章:AI Agent智能体未来趋势 AI Agent正从单一任务执行者演变为具备自主目标分解、跨工具协同与持续环境反馈的类人智能体。其发展不再局限于模型规模扩张,而转向认知架构升级、可信机制构建与人机协作…...

Burp Suite安装失败原因与Java环境精准配置指南
1. 为什么Burp Suite的安装总让人卡在第一步?——从“打不开”到“能用”的真实断点 你是不是也经历过:下载完Burp Suite官方压缩包,双击 burpsuite_pro.jar 没反应?或者弹出一句“找不到Java环境”就戛然而止?又或…...