云数据库 Redis 性能深度评测(阿里云、华为云、腾讯云、百度智能云)
在当今的云服务市场中,阿里云、腾讯云、华为云和百度智能云都是领先的云服务提供商,他们都提供了全套的云数据库服务,其中 Redis属于RDS 之后第二被广泛应用的服务,本次测试旨在深入比较这四家云服务巨头在Redis云数据库性能方面的表现,为企业在选择合适的云数据库时提供重要的参考依据。
我们将针对阿里云、腾讯云、华为云和百度智能云的 Redis 云数据库进行全方位的性能测试,包括读写性能、并发处理能力等方面的测试。通过这些测试,我们将对这四家云服务提供商的Redis云数据库进行客观、公正的比较,以便企业能够根据自身业务需求选择最适合的云数据库服务。
通过本次测试,我们希望为企业提供一份详实的报告,以便企业在选择Redis云数据库服务时能够做出明智的决策。同时,我们也希望通过本次测试推动云服务提供商在技术和服务方面不断创新和提升,为企业提供更加优质、高效的云服务。
测试结论
标准版评测详细数据和结论
详细数据
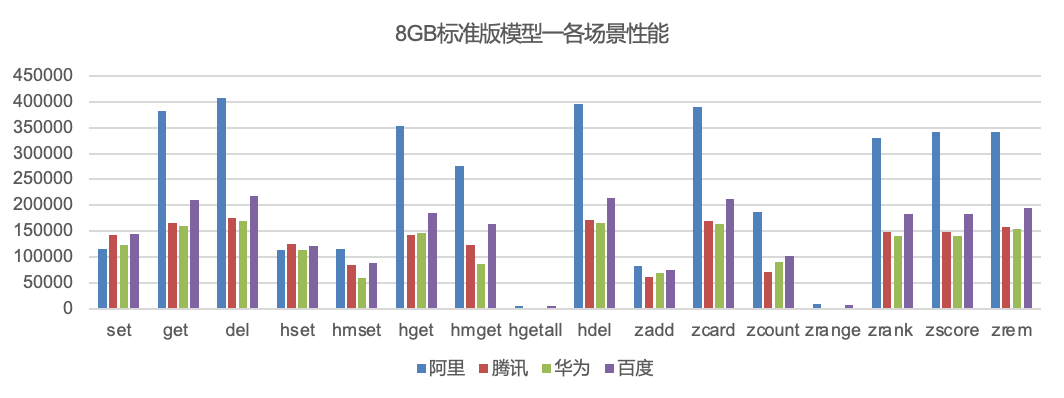
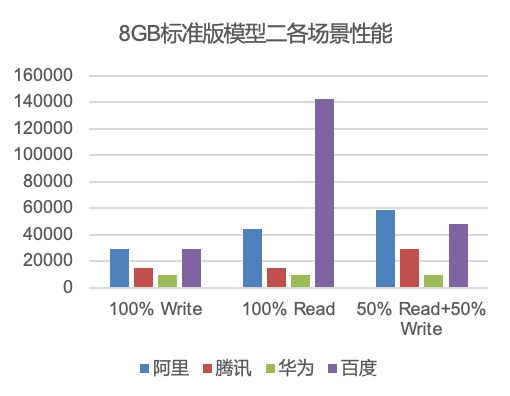
标准版对比总结:
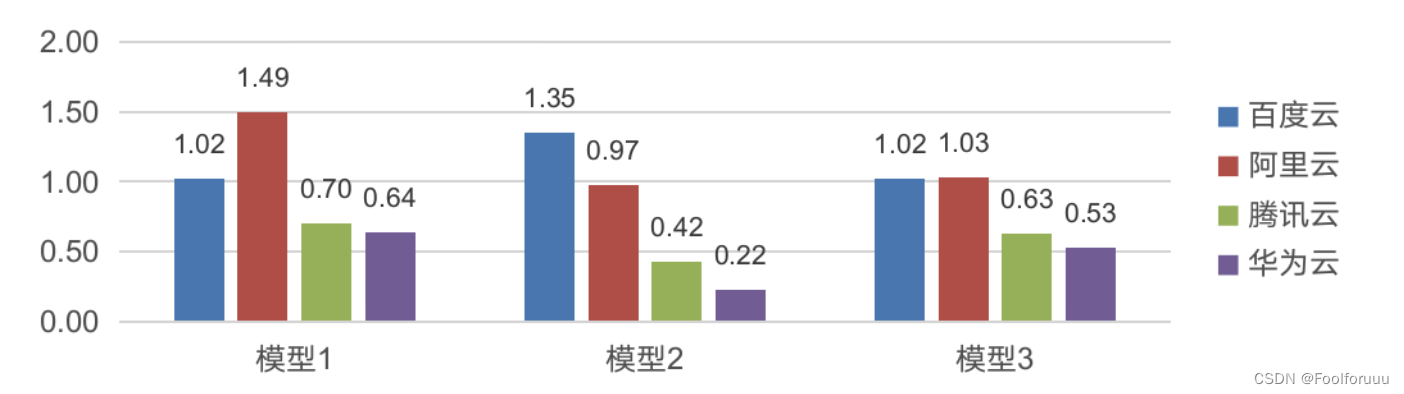
-
阿里云:整体性能排名第一,其中模型1中9/16个场景,模型3小Key读相关场景性能表现明显优于其它所有竞品
-
百度智能云:全部29个场景中,9个场景排名第一,19个场景性能表现优于腾讯云与华为云;
-
腾讯云:兼容Redis6.0,实际是1主1从3proxy部署架构,整体性能表现和华为差不多
-
华为云:兼容Redis6.0, 1主1从部署,整体性能表现和腾讯差不多
我们把测试数据加权之后,标准版的整体排名:阿里云(1.262)>百度智能云(1.053)>腾讯云(0.644)>华为云(0.537)
集群版评测结论
详细数据
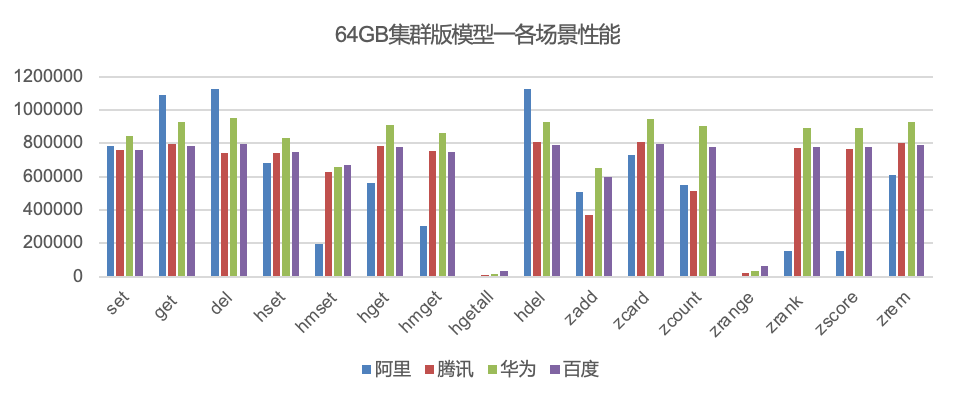
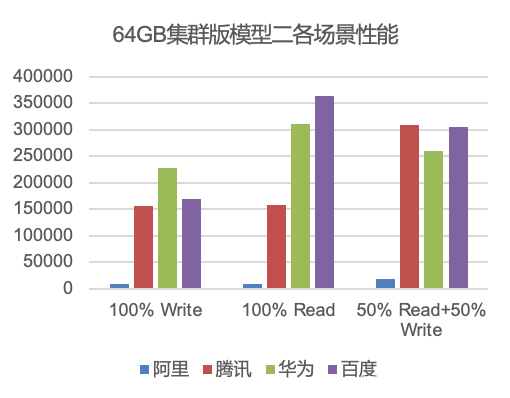
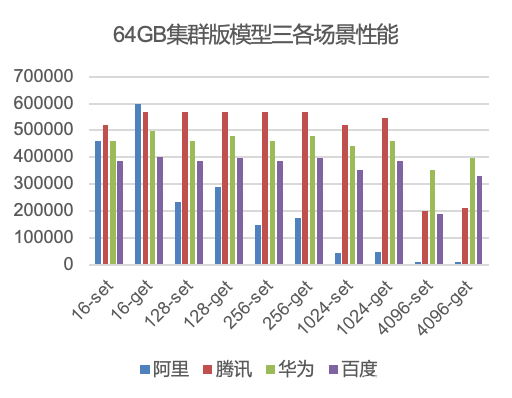
集群版本对比结论
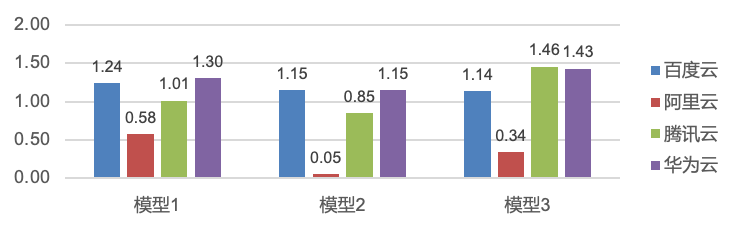
-
阿里云:在大key场景下性能退化严重,如hgetall、zrange、模型2、模型3涉及大key操作的场景性能打不上去
-
百度智能云:各场景性能表现都比较好,没有明显性能短板
-
腾讯云:在模型3-4KB以下场景性能均优于华为和百度
我们把测试数据加权之后,集群版本整体排名:华为云(1.328)>百度智能云(1.197)>腾讯云(1.124)>阿里云(0.373)
测试环境
| 厂商 | 云服务器1台 | 标准版8GB实例1台 | 集群版64GB实例1台 |
| 阿里云 Tair for Redis | 规格族:计算型 c8y 实例规格:ecs.c8y.4xlarge vCPU :16 vCPU 内存:32 GiB 处理器主频/睿频:2.75 GHz/- 内网带宽:最高 16 Gbps | 付费模式:按量付费 商品类型:Tair for Redis 存储介质:内存 可用区类型:单可用区 实例类型:高可用 版本兼容性:Redis 6.0 架构类型:不启用集群 读写分离:关闭 分片规格:8GB 副本数:2副本 | 付费模式:按量付费 商品类型:Tair for Redis 存储介质:内存 可用区类型:单可用区 实例类型:高可用 版本兼容性:Redis 6.0 架构类型:启用集群 连接模式:代理模式 分片规格:8GB 副本数:2副本 分片数量:8 |
| 腾讯云 云数据库 Redis | 规格族:计算型C6 实例规格:C6.4XLARGE32 vCPU :16 vCPU 内存:32 GiB 处理器主频/睿频:Intel Ice Lake(3.2GHz/3.5Ghz) 内网带宽:最高 18 Gbps | 计费模式:按量付费 产品版本:内存版 兼容版本:6.2 架构版本:标准架构 内存容量:8GB 副本数量:1个(1主1副本) | 计费模式:按量付费 产品版本:内存版 兼容版本:6.2 架构版本:集群架构 分片数量:8片 分片容量:8GB 副本数量:1个(1主1副本) |
| 华为云 分布式缓存服务Redis版 | 规格族:通用计算增强型c6s 实例规格:c6s.4xlarge.2 vCPU :16 vCPU 内存:32 GiB 处理器主频/睿频:Intel Cascade Lake 2.6GHz 内网带宽:最高 7.5 Gbps | 计费模式:按需计费 缓存类型:Redis 版本号:6.0 实例类型:主备 CPU架构:x86计算 副本数:2 实例规格:redis.ha.xu1.large.r2.8(8GB) | 计费模式:按需计费 缓存类型:Redis 版本号:5.0 实例类型:Proxy集群 CPU架构:x86计算 规格选择模式:自定义分片 单分片容量:8GB 实例规格:redis.proxy.xu1.large.s8.64(64GB) |
| 百度智能云云数据库 SCS | 规格族:计算型C5 实例规格:bcc.c5.c16m32 vCPU :16 vCPU 内存:32 GiB 处理器主频/睿频:Intel Xeon Platinum 8350C-2.6GHz 内网带宽:最高 6 Gbps | 计费模式:后付费 引擎类型: Redis 版本类型:社区版 架构类型:标准版 引擎版本:6.0 存储类型:高性能内存型 节点规格:cache.n1.large 副本数量: 2 | 计费模式:后付费 引擎类型: Redis 版本类型:企业版 架构类型:集群版 引擎版本:6.0 存储类型:高性能内存型 节点规格:cache.n1.large 分片数量:8片 副本数量: 2 |
测试工具
工具1:
压测工具:测试采用Redis Labs推出的多线程压测工具memtier_benchmark
使用方法:具体使用方法请参见 memtier_benchmark 虚机配置memtier-benchmark
使用到的测试选项:
./memtier_benchmark -s *** -a *** -p 8635 -c 4 -t 30 -n 1000000 --random-data --randomize --distinct-client-seed -d 128 --key-maximum=50331648 --key-minimum=1 --key-prefix= --ratio=1:0 --out-file=./result/result_small_128_set.log工具2:
压测工具:开源Redis的redis-benchmark工具进行压测,它是Redis官方的性能测试工具
使用方法:为了确保工具支持--thread参数,测试时候使用最新的Redis版本进行编译,参见Redis开源项目
使用到的测试选项:
./src/redis-benchmark -h r-bp1s02ae14mr****.redis.rds.aliyuncs.com -p 6379 -a testaccount:Rp829dlwa -n 3000000 -r 10000000 -c 256 -t set -d 64 --threads 16测试指标
-
OPS:每秒执行的读写操作数,单位为次/秒。
评测模型
测试模型1——基本数据结构KEY密集型测试
| workload模型 | ||
| workload模型编号 | 测试模型 | 参数设置 |
| --command | Specify a command to send in quotes. | --command="${command}" |
| --test-time | Number of seconds to run the test | --test-time=300 |
| 数据模型 | ||
| 数据模型编号 | 数据模型 | 参数设置 |
| value length-256 | 随机生成value,256字节 | -d 256 |
测试模型2——KEY分散读写测试
| workload模型 | ||
| workload模型编号 | 测试模型 | 参数设置 |
| 100% Write | 100%写操作(string set) | --ratio=1:0 |
| 100% Read | 100%读操作(string get) | --ratio=0:1 |
| 50% Read+50% Write | 50%读操作(string get)+ 50%写操作(string set) | --ratio=1:1 |
| 数据模型 | ||
| 数据模型编号 | 数据模型 | 参数设置 |
| value length | 随机生成value,数据大小在指定的范围之内 | –data-size-range=1-10240 |
测试模型3——不同写入数据大小测试
| workload模型 | ||
| workload模型编号 | 测试模型 | 参数设置 |
| -t | 测试命令,包含SET, GET | -t "${command}" |
| -n | Total number of requests (default 100000) | -n 3000000 |
| 数据模型 | ||
| 数据模型编号 | 数据模型 | 参数设置 |
| value length-256 | value长度分别为16、128、256、1024、4096字节 | -d ${value_length} |
备注:模型3测试场景和工具参考阿里tair实例内存型(兼容Redis6.0)性能白皮书,需要使用redis-benchmark对SET、GET命令进行不同写入数据大小场景的测试,并给出测试指标。
测试方法
购买Redis实例,默认开启AOF和RDB,在云服务器上通过测试工具并发连接实例进行打压
模型1测试方法
固定参数:
bench_bin="memtier_benchmark"
thread=50
client=20
host="192.168.96.31"
port=6379
password="1234qwer"
data_size=256
test_time=300
key_maximum=300
key_prefix=""
command=$1
file=$2
start_time=$(date | awk '{print$4}')echo "${bench_bin} -t ${thread} -c ${client} -s ${host} -p ${port} -a ${password} --distinct-client-seed --command="${command}" --key-prefix="${key_prefix}" --key-minimum=1 --key-maximum=${key_maximum} --random-data --data-size=${data_size} --test-time=${test_time} --out-file=out/${file}"${bench_bin} -t ${thread} -c ${client} -s ${host} -p ${port} -a ${password} --distinct-client-seed --command="${command}" --key-prefix="${key_prefix}" --key-minimum=1 --key-maximum=${key_maximum} --random-data --data-size=${data_size} --test-time=${test_time} --out-file=out/${file}end_time=$(date|awk '{print$4}')echo "${command} start: ${start_time} end: ${end_time}" >> run.log压测命令:
sh press.sh "set __key__ __data__" set
sh press.sh "get __key__" get
sh press.sh "del __key__" del
sh press.sh "hset __key__ __key__ __data__" hset
sh press.sh "hmset __key__ __key__ __data__ __key__ __data__ __key__ __data__" hmset
sh press.sh "hget __key__ __key__" hget
sh press.sh "hmget __key__ __key__ __key__" hmget
sh press.sh "hgetall __key__" hgetall
sh press.sh "hdel __key__ __key__" hdel
sh press.sh "zadd __key__ __key__ __data__" zadd
sh press.sh "zcard __key__" zcard
sh press.sh "zcount __key__ 1 __key__" zcount
sh press.sh "ZRANGE __key__ 0 __key__ WITHSCORES" zrange
sh press.sh "zrank __key__ __data__" zrank
sh press.sh "zscore __key__ __data__" zscore
sh press.sh "zrem __key__ __key__" zrem模型2测试方法
以8GB标准版为例,模型的性能指标的测试方法如下所示:
希望本次的测试可以给大家提供选型参考。当能云厂商更新也很快,性能上也是你追我赶,后面我们会持续关注各个云厂商的性能变化,动态更新测试结果。
欢迎大家访问百度智能云
-
测试场景1:100% Write模型通过执行如下命令,设置value长度为1-10240字节内的随机大小,记录性能指标。
-
测试场景2:100% Read模型通过执行如下命令,在写入的数据中均匀随机读取长度为1-10240字节的数据,记录性能指标。
-
测试场景3:50% Read+50% Write模型通过执行如下命令,记录性能指标。
-
host=$1 port=$2 passwd=$3max_key=500000start_time=$(date | awk '{print$4}') ./memtier_benchmark -s ${host} -a ${passwd} -p ${port} -c 20 -t 50 --random-data --randomize --distinct-client-seed --data-size-range=1-10240 --key-maximum=${max_key} --key-minimum=1 --key-prefix= --ratio=1:0 --test-time=300 --out-file=out/${host}_${port}_set.log end_time=$(date|awk '{print$4}')echo "100% write start: ${start_time} end: ${end_time}" >> run.logstart_time=$(date | awk '{print$4}') ./memtier_benchmark -s ${host} -a ${passwd} -p ${port} -c 20 -t 50 --random-data --randomize --distinct-client-seed --data-size-range=1-10240 --key-maximum=${max_key} --key-minimum=1 --key-prefix= --ratio=0:1 --test-time=300 --out-file=out/${host}_${port}_get.log end_time=$(date|awk '{print$4}') echo "100% read start: ${start_time} end: ${end_time}" >> run.logstart_time=$(date | awk '{print$4}') ./memtier_benchmark -s ${host} -a ${passwd} -p ${port} -c 20 -t 50 --random-data --randomize --distinct-client-seed --data-size-range=1-10240 --key-maximum=${max_key} --key-minimum=1 --key-prefix= --ratio=1:1 --test-time=300 --out-file=out/${host}_${port}_set_get.log end_time=$(date|awk '{print$4}') echo "50% write + 50% read start: ${start_time} end: ${end_time}" >> run.log模型3测试方法
使用开源的redis-benchmark工具进行压测,它是Redis官方的性能测试工具,为确保redis-benchmark工具支持--threads参数,测试时推荐使用最新的Redis版本进行编译。
压测命令:
-
host=$1 port=$2 passwd=$3 key_range=1000000 #16 echo "before 16: redis-cli -h ${host} -p ${port} -a ${passwd} flushall" redis-cli -h ${host} -p ${port} -a ${passwd} flushall sleep 10start_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t set -d 16 --threads 16 > out/16_set end_time=$(date|awk '{print$4}') echo "16 bytes_SET start: ${start_time} end: ${end_time}" >> run.logstart_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t get -d 16 --threads 16 > out/16_get end_time=$(date|awk '{print$4}') echo "16 bytes_GET start: ${start_time} end: ${end_time}" >> run.log#128 echo "before 128: redis-cli -h ${host} -p ${port} -a ${passwd} flushall" redis-cli -h ${host} -p ${port} -a ${passwd} flushall sleep 10start_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t set -d 128 --threads 16 > out/128_set end_time=$(date|awk '{print$4}') echo "128 bytes_SET start: ${start_time} end: ${end_time}" >> run.logstart_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t get -d 128 --threads 16 > out/128_get end_time=$(date|awk '{print$4}') echo "128 bytes_GET start: ${start_time} end: ${end_time}" >> run.log#256 echo "before 256: redis-cli -h ${host} -p ${port} -a ${passwd} flushall" redis-cli -h ${host} -p ${port} -a ${passwd} flushall sleep 10start_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t set -d 256 --threads 16 > out/256_set end_time=$(date|awk '{print$4}') echo "256 bytes_SET start: ${start_time} end: ${end_time}" >> run.logstart_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t get -d 256 --threads 16 > out/256_get end_time=$(date|awk '{print$4}') echo "256 bytes_GET start: ${start_time} end: ${end_time}" >> run.log#1024 echo "before 1024: redis-cli -h ${host} -p ${port} -a ${passwd} flushall" redis-cli -h ${host} -p ${port} -a ${passwd} flushall sleep 10start_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t set -d 1024 --threads 16 > out/1024_set end_time=$(date|awk '{print$4}') echo "1024 bytes_SET start: ${start_time} end: ${end_time}" >> run.logstart_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t get -d 1024 --threads 16 > out/1024_get end_time=$(date|awk '{print$4}') echo "1024 bytes_GET start: ${start_time} end: ${end_time}" >> run.log#4096 echo "before 4096: redis-cli -h ${host} -p ${port} -a ${passwd} flushall" redis-cli -h ${host} -p ${port} -a ${passwd} flushall sleep 10start_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t set -d 4096 --threads 16 > out/4096_set end_time=$(date|awk '{print$4}') echo "4096 bytes_SET start: ${start_time} end: ${end_time}" >> run.logstart_time=$(date | awk '{print$4}') ./redis-benchmark -h ${host} -p ${port} -a ${passwd} -n 3000000 -r ${key_range} -c 256 -t get -d 4096 --threads 16 > out/4096_get end_time=$(date|awk '{print$4}') echo "4096 bytes_GET start: ${start_time} end: ${end_time}" >> run.log总体结论和分析
综合性能排名:百度智能云>腾讯云>华为云>阿里云
-
百度智能云标准版本和集群版本都排名第二,综合性能表现优于所有竞品,总体第一名,腾讯综合排名第二;
-
通过测试我们发现阿里和华为长板特长,短板也特短,尤其是阿里云大key场景存在性能问题,尤其集群版拉低整体评分,排名第四
-
华为排名第三。
相关文章:
云数据库 Redis 性能深度评测(阿里云、华为云、腾讯云、百度智能云)
在当今的云服务市场中,阿里云、腾讯云、华为云和百度智能云都是领先的云服务提供商,他们都提供了全套的云数据库服务,其中 Redis属于RDS 之后第二被广泛应用的服务,本次测试旨在深入比较这四家云服务巨头在Redis云数据库性能方面的…...

Android---Retrofit实现网络请求:Java 版
简介 在 Android 开发中,网络请求是一个极为关键的部分。Retrofit 作为一个强大的网络请求库,能够简化开发流程,提供高效的网络请求能力。 Retrofit 是一个建立在 OkHttp 基础之上的网络请求库,能够将我们定义的 Java 接口转化为…...

使用静态CRLSP配置MPLS TE隧道
正文共:1591 字 13 图,预估阅读时间:4 分钟 静态CRLSP(Constraint-based Routed Label Switched Paths,基于约束路由的LSP)是指在报文经过的每一跳设备上(包括Ingress、Transit和Egress…...

gentoo安装笔记
最近比较闲,所以挑战一下自己,在自己的台式电脑上安装gentoo 下面记录了我亲自安装的步骤,作为以后我再次安装时参考所用。 整体步骤 一般来将一个linux发行版的安装步骤其实大体上都差不多,基本分为一下几步: 1. …...

Git如何使用 五分钟快速入门
Git如何使用 五分钟快速入门 Git是一个分布式版本控制系统,它可以帮助开发人员跟踪和管理项目的代码变更。与传统的集中式版本控制系统(如SVN)不同,Git允许开发人员在本地存储完整的代码仓库,并且可以独立地进行代码修…...

FreeRTOS学习笔记——(FreeRTOS临界段代码保护及调度器挂起与恢复)
这里写目录标题 1,临界段代码保护简介(熟悉)2,临界段代码保护函数介绍(掌握)3,任务调度器的挂起和恢复(熟悉) 1,临界段代码保护简介(熟悉…...
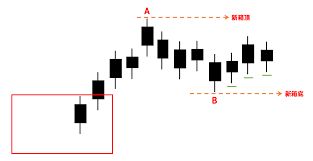
箱形理论在交易策略中的实战应用与优化
箱形理论,简单来说,就是将价格波动分成一段一段的方框,研究这些方框的高点和低点,来推测价格的趋势。 在上升行情中,价格每突破新高价后,由于群众惧高心理,可能会回跌一段,然后再上升…...
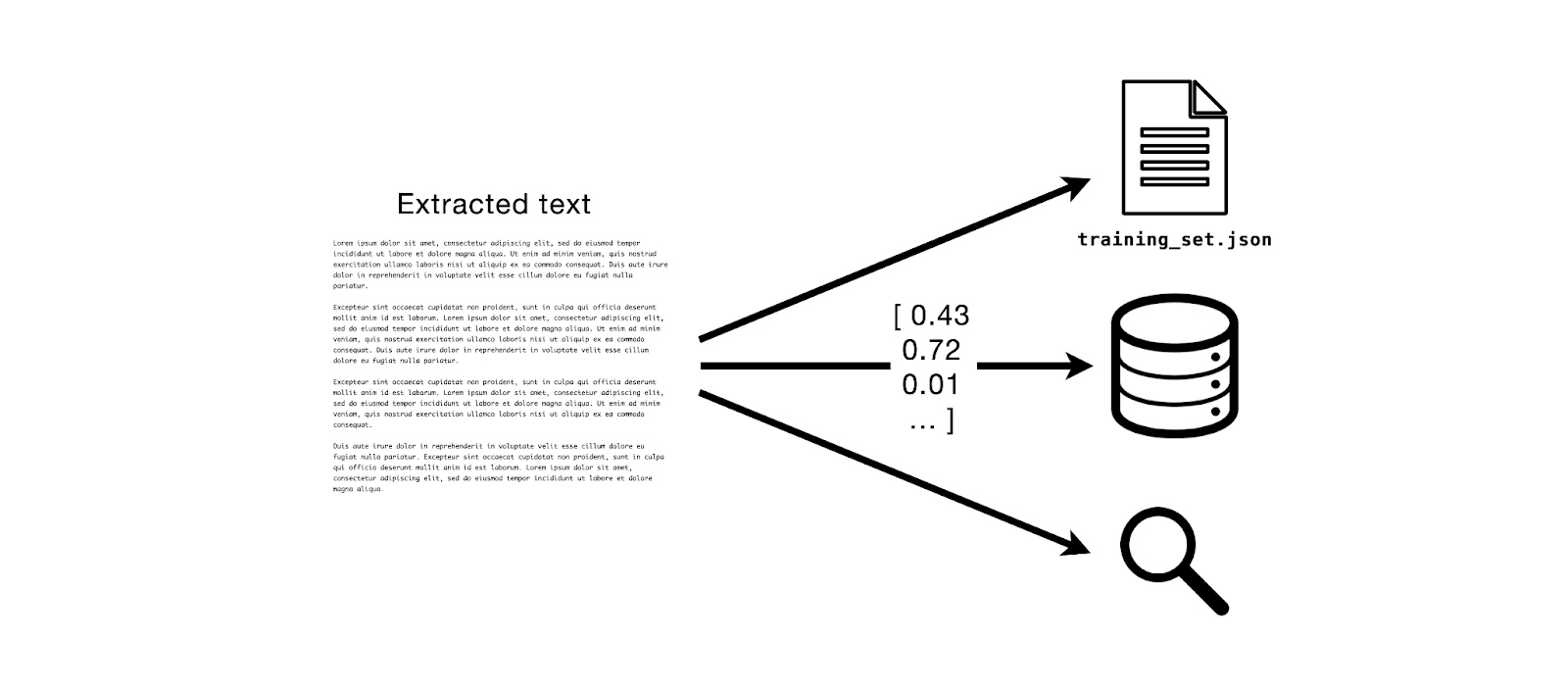
MinIO 和 Apache Tika:文本提取模式
Tl;dr: 在这篇文章中,我们将使用 MinIO Bucket Notifications 和 Apache Tika 进行文档文本提取,这是大型语言模型训练和检索增强生成 LLM和RAG 等关键下游任务的核心。 前提 假设我想构建一个文本数据集,然后我可以用它来微调 LLM.为了做…...
)
c编译器学习05:与chibicc类似的minilisp编译器(待续)
minilisp项目介绍 项目地址:https://github.com/rui314/minilisp 作者也是rui314,commits也是按照模块开发提交的。 minilisp只有一个代码文件:https://github.com/rui314/minilisp/blob/master/minilisp.c 加注释也只有996行。 代码结构&a…...
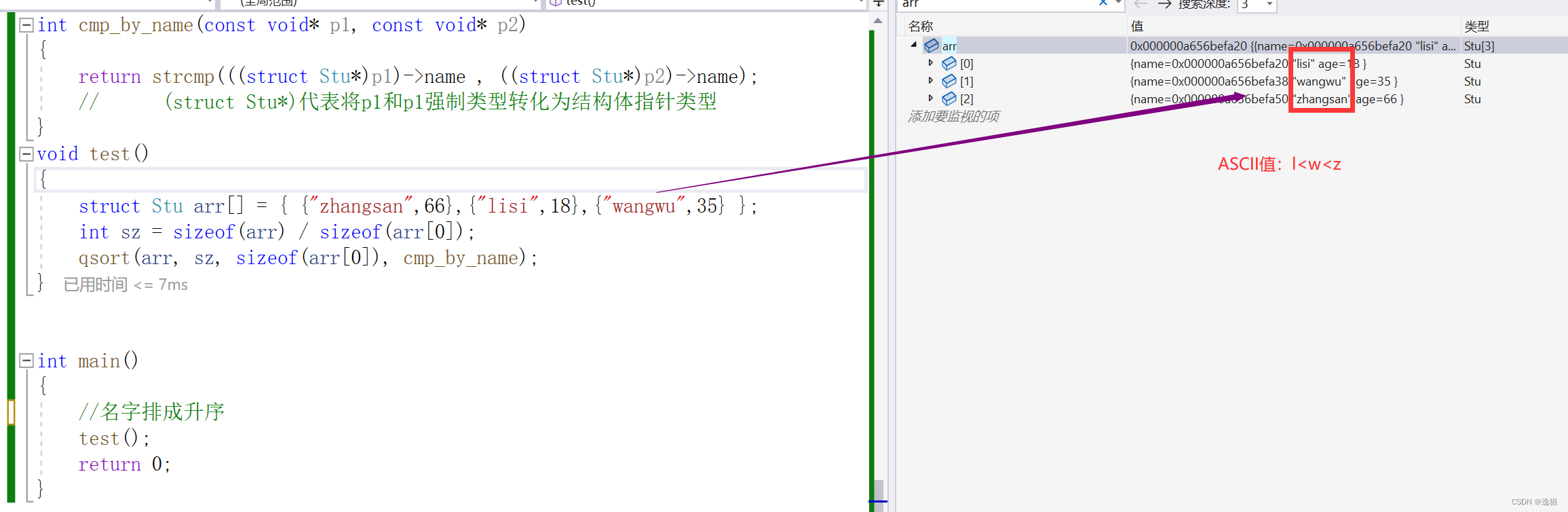
手撕qsort函数
前言 本篇主要讲解的是qsort函数细节以及运用实例。 紧跟我的脚步一起手撕qsort函数吧~ 欢迎关注个人主页:逸狼 更多优质内容: 拿捏c语言指针(上) 拿捏c语言指针(中) 拿捏c语言指针(下&…...

项目在linux上的简单部署
本文章只介绍项目的简单部署,暂时没有Docker部署。 项目部署有两种方式,一种是直接命令部署,第二种是用脚本,脚本本身也是将命令进行封装来执行。 命令 项目通过maven打包,启动命令: # 启动命令 nohup …...
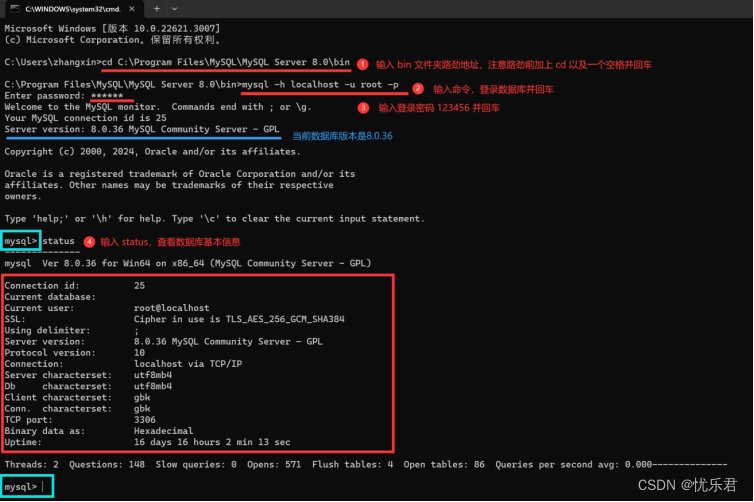
MySQL安装教程(详细版)
今天分享的是Win10系统下MySQL的安装教程,打开MySQL官网,按步骤走呀~ 宝们安装MySQL后,需要简单回顾一下关系型数据库的介绍与历史(History of DataBase) 和 常见关系型数据库产品介绍 呀,后面就会进入正式…...
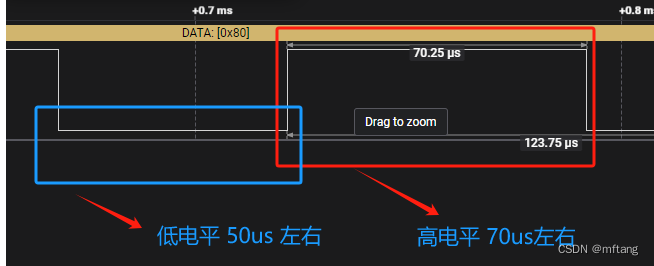
Linux platform tree下的单总线驱动程序设计(DHT11)
目录 概述 1 认识DHT11 1.1 DHT11特性 1.2 DHT11数据格式 1.3 DHT11与MCU通信 1.4 DHT11信号解析 1.4.1 起始信号 1.4.2 解析信号0 1.4.3 解析信号1 2 驱动开发 2.1 硬件接口 2.2 更新设备树 2.2.1 添加驱动节点 2.2.2 编译.dts 2.2.3 更新板卡中的.dtb 2.3 驱…...
)
自研爬虫框架的经验总结(理论及方法)
背景: 由于业务需要,承接一部分的数据采集工作。目前市场内的一些通用框架不太适合。故而进行了自研。 对比自研和目前成熟的框架,自研更灵活适配,可以自己组装核心方法;后者对于新场景的适配需要对框架本身有较高的理…...

配置基于 AWS CRT 的 HTTP 客户端
基于 AWS CRT 的 HTTP 客户端包括同步 AwsCrtHttpClient 和异步 AwsCrtAsyncHttpClient。基于 AWS CRT 的 HTTP 客户端具有以下 HTTP 客户端优势: 更快的 SDK 启动时间 更小的内存占用空间 降低的延迟时间 连接运行状况管理 DNS 负载均衡 SDK 中基于 AWS CRT …...
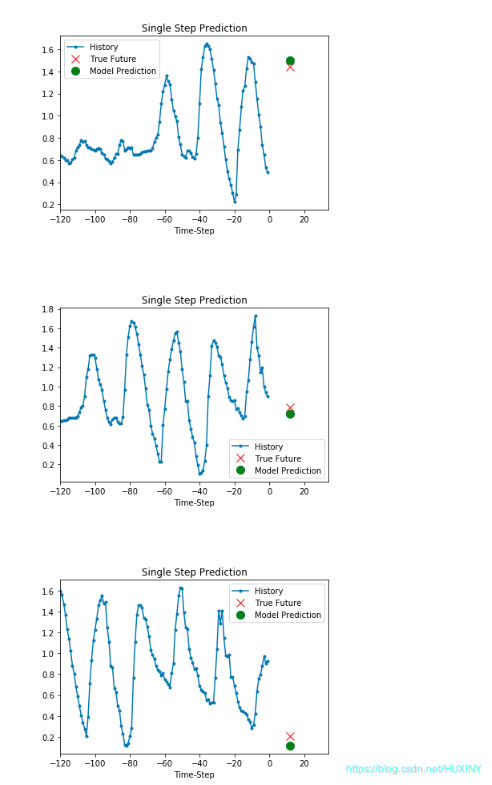
挑战杯 基于LSTM的天气预测 - 时间序列预测
0 前言 🔥 优质竞赛项目系列,今天要分享的是 机器学习大数据分析项目 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/po…...
我为什么不喜欢关电脑?
程序员为什么不喜欢关电脑? 你是否注意到,程序员们似乎从不关电脑?别以为他们是电脑上瘾,实则是有他们自己的原因!让我们一起揭秘背后的原因,看看程序员们真正的“英雄”本色! 一、上大学时。 …...

Unity【角色/摄像机移动控制】【1.角色移动】
本文主要总结实现角色移动的解决方案。 1. 创建脚本:PlayerController 2. 创建游戏角色Player,在Player下挂载PlayerController脚本 3. 把Camera挂载到Player的子物体中,调整视角,以实现相机跟随效果 3. PlayerController脚本代码…...

Oracle12cR2之Job定时作业调度器详解
Oracle12cR2之Job定时作业调度器详解 文章目录 Oracle12cR2之Job定时作业调度器详解1.Oracle Job1. 关于Job2. 使用方法 2. Job详细说明1. 查看Job的相关视图2.SYS.DBA_JOBS视图字段详细说明 3. 创建及查看Job1. 创建Job2. 查看运行中的Job 1.Oracle Job 1. 关于Job 在 Oracle…...
python自学...
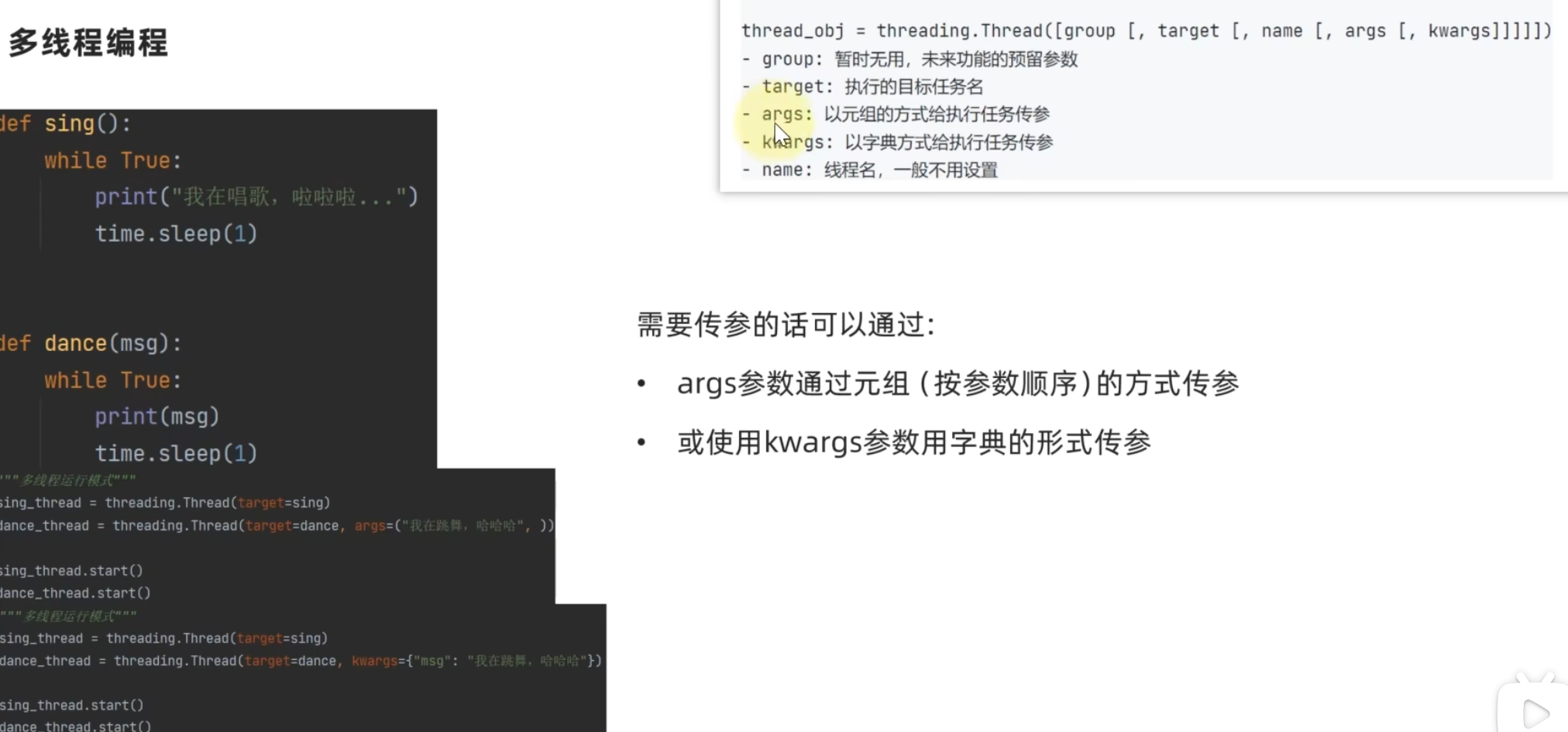
一、稍微高级一点的。。。 1. 闭包(跟js差不多) 2. 装饰器 就是spring的aop 3. 多线程...

OpenClaw 局域网访问配置文档
OpenClaw 局域网访问配置文档 概述 本文档详细说明了如何配置 OpenClaw 以允许局域网内的其他设备访问,包括所有相关配置参数的作用和说明。 当前配置状态 网关服务信息 服务端口: 18789 绑定模式: lan (局域网访问) 认证方式: password (密码认证) 访问密码: xxxxxx 详细…...

突破视频内容壁垒:B站视频转文字的智能解决方案
突破视频内容壁垒:B站视频转文字的智能解决方案 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 在信息爆炸的时代,视频已成为知识传播…...

注意力机制:AI 也会“走神“和“专注“——信息选择的智慧
注意力机制:AI 也会"走神"和"专注"——信息选择的智慧(Version B) 📚 《从零到一造大脑:AI架构入门之旅》专栏 专栏定位:面向中学生、大学生和 AI 初学者的科普专栏,用大白话和生活化比喻带你从零理解人工智能 本系列共 42 篇,分为八大模块: 📖…...
)
保姆级教程:用PyTorch 1.13.1在GPU上跑通PointNet分类与分割(附自写推理脚本)
从零实现PointNet分类与分割:PyTorch 1.13.1 GPU实战指南 当你第一次接触3D点云处理时,可能会被各种复杂的数学公式和算法吓退。但PointNet的出现改变了这一局面——这个开创性的网络架构直接处理原始点云数据,无需复杂的体素化或网格化预处理…...

DeepSeekubernetes-1.35.3/kubernetes-1.35.3/test/utils/ktesting/examples/logging/example_test.go 源码分析
我来分析 Kubernetes 测试工具 ktesting 中的日志示例文件 example_test.go。这个文件展示了如何在 Kubernetes 测试中使用结构化日志。 文件概述 这是 Kubernetes v1.35.3 中 test/utils/ktesting 包的示例文件,展示了如何使用 ktesting 框架进行带有结构化日志的测…...

**用Python实现高效分子结构建模与能量计算:从零开始构建你的计算化学工具链**在现代计算化学中,**Python已成
用Python实现高效分子结构建模与能量计算:从零开始构建你的计算化学工具链 在现代计算化学中,Python已成为科研人员首选的编程语言之一,它不仅语法简洁、生态丰富,还具备强大的科学计算能力。本文将带你一步步搭建一个基于Python的…...

AI辅助开发:让快马智能生成代码优化50台云桌面的动态资源调度策略
今天想和大家分享一个特别实用的技术实践——如何用AI辅助开发来优化云桌面的资源调度。最近在做一个项目,需要在一台主机上运行50台云桌面,这对资源调度提出了很高的要求。传统的静态分配方式显然不够灵活,于是我开始探索AI辅助开发的解决方…...

如何统计不同电话号码的个数?—位图法
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

思源宋体:3大核心优势+5步落地指南,免费商用中文字体解决方案
思源宋体:3大核心优势5步落地指南,免费商用中文字体解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在数字化设计与开发中,中文字体的选择一…...

《数字孪生为什么90%都是假的》——没有空间数据的“孪生”,只是一个会动的PPT
一、摘要(Executive Summary)近年来,“数字孪生(Digital Twin)”成为智慧城市、工业互联网与数字基础设施建设中的核心关键词。然而,在大量实际项目中,所谓“数字孪生系统”仅停留在三维建模与数…...