05 Flink 的 WordCount
前言
本文对应于 spark 系列的 Spark 的 WordCount
这里主要是 从宏观上面来看一下 flink 这边的几个角色, 以及其调度的整个流程
一个宏观 大局上的任务的处理, 执行
基于 一个本地的 flink 集群
测试用例
/*** com.hx.test.Test01WordCount** @author Jerry.X.He* @version 1.0* @date 2021/4/12 10:14*/
public class Test01WordCount {// com.hx.test.Test01WordCount// -Xmx100M -XX:+UseSerialGC -XX:+TraceClassUnloadingpublic static void main(String[] args) throws Exception {// ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();String jarPath = "D:\\IdeaWorkStations\\HelloFlink\\target\\HelloFlink-0.0.1.jar";ExecutionEnvironment env = ExecutionEnvironment.createRemoteEnvironment("127.0.0.1", 8081, jarPath);env.setParallelism(1);String inputPath = "D:\\IdeaWorkStations\\HelloFlink\\src\\main\\resources\\Test01WordCount.txt";DataSource<String> inputDs = env.readTextFile(inputPath);DataSet<Tuple2<String, Integer>> result = inputDs.flatMap(new MyFlatMapMapper()).map(new MyMapMapper()).groupBy(0).sum(1);result.print();System.gc();System.in.read();System.out.println(" end ");}/*** MyFlatMapMapper** @author Jerry.X.He* @version 1.0* @date 2021/4/12 10:24*/private static class MyFlatMapMapper implements FlatMapFunction<String, String> {private static List<byte[]> dummyBytes = new ArrayList<>();static {try {for (int i = 0; i < 10; i++) {byte[] tmpBytes = FileUtils.readAllBytes(Paths.get("D:\\IdeaWorkStations\\HelloFlink\\target\\logs\\ROOT.2021-12-27-9.log"));dummyBytes.add(tmpBytes);}} catch (Exception e) {e.printStackTrace();} finally {new Thread(new MyRunnable()).start();}}@Overridepublic void flatMap(String line, Collector<String> out) throws Exception {String[] splits = line.split("\\s+");for (String split : splits) {out.collect(split);}}}/*** MyRunnable** @author Jerry.X.He* @return* @date 2021/12/27 16:16*/public static class MyRunnable implements Runnable {@Overridepublic void run() {System.err.println(" MyRunnable.run before ");IoUtils.sleep(1000_000);System.err.println(" MyRunnable.run after ");}}/*** MyMapMapper** @author Jerry.X.He* @version 1.0* @date 2021/4/12 10:29*/private static class MyMapMapper implements MapFunction<String, Tuple2<String, Integer>> {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return new Tuple2<>(word, 1);}}}
Test01WordCount.txt 内容如下

整体交互流程
Driver 提交 Job 到 JobManager, JobManager 分配任务到 TaskManager
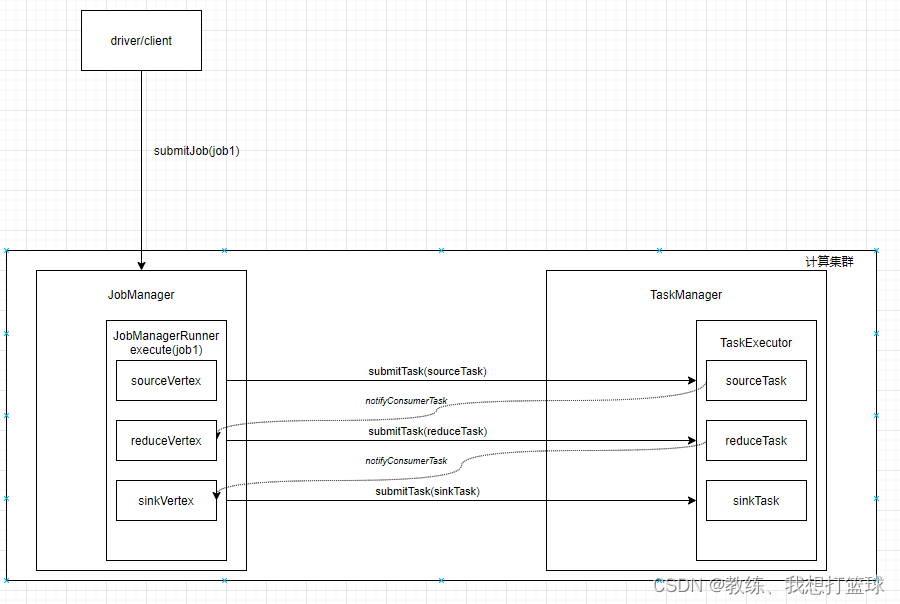
然后 TaskManager 和 JobManager 这边交互如下
Driver 这边的处理
这里是 driver 这边的根据 DataSet阶段 转换为 Plan阶段
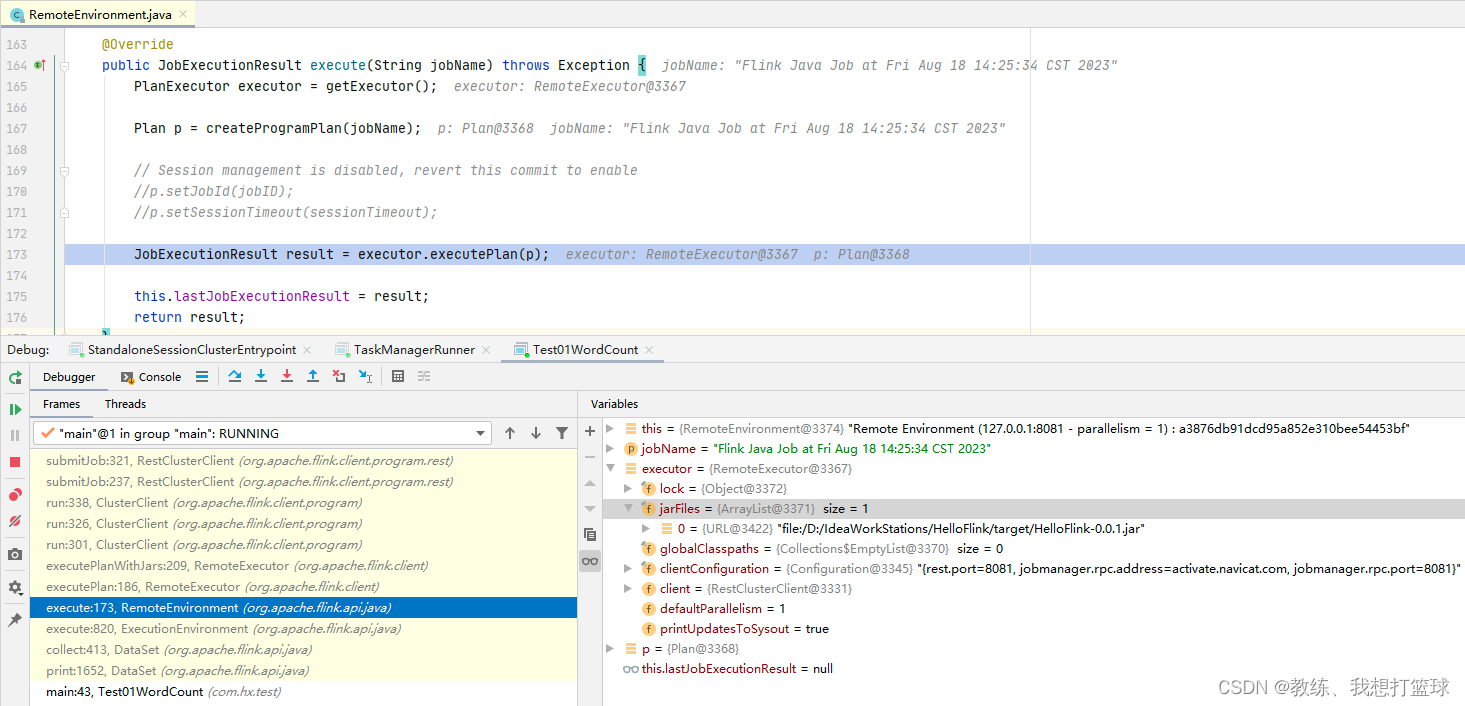
这里是 Plan阶段 转换为 OptimizedPlan阶段
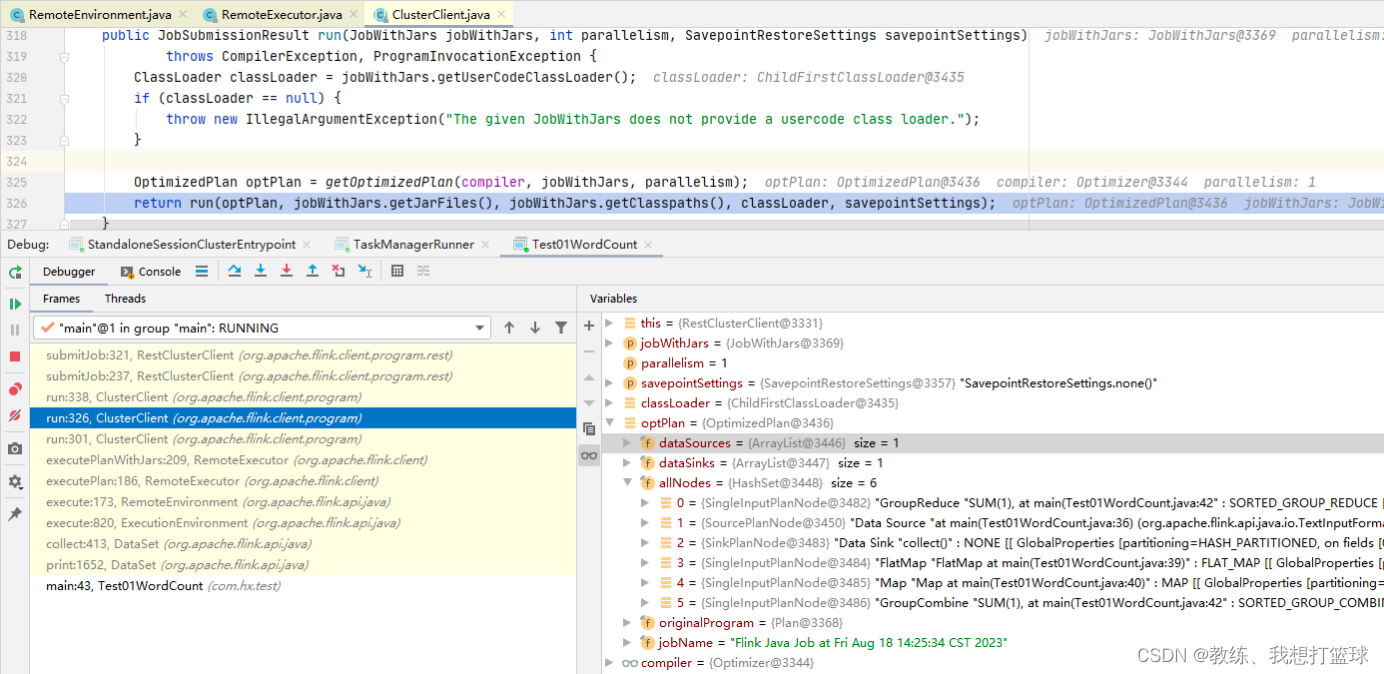
这里是 OptimizedPlan阶段 转换为 JobGraph阶段
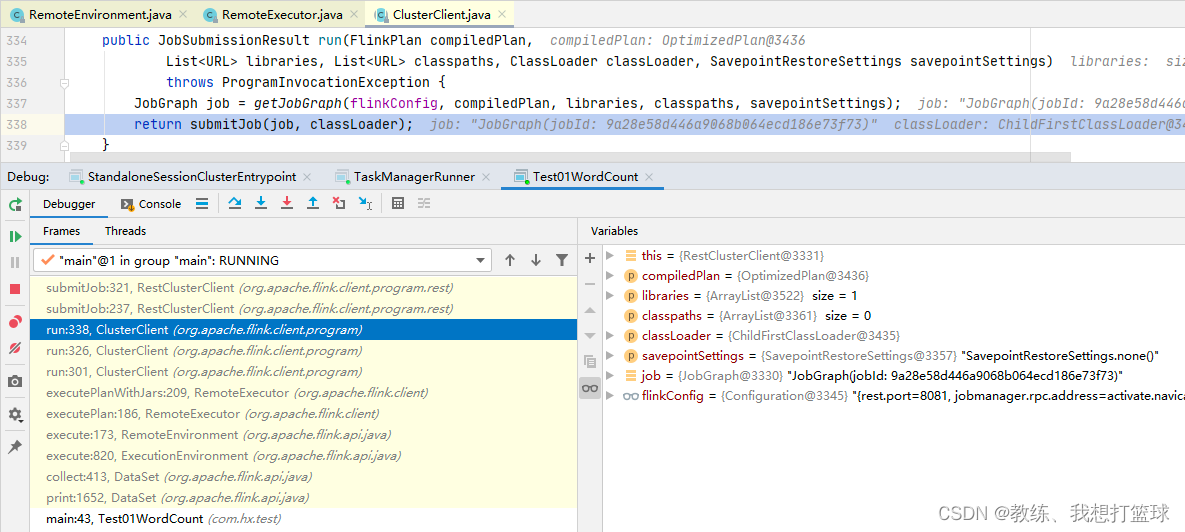
然后 提交的就是 JobGraph, 然后 等待集群响应结果信息
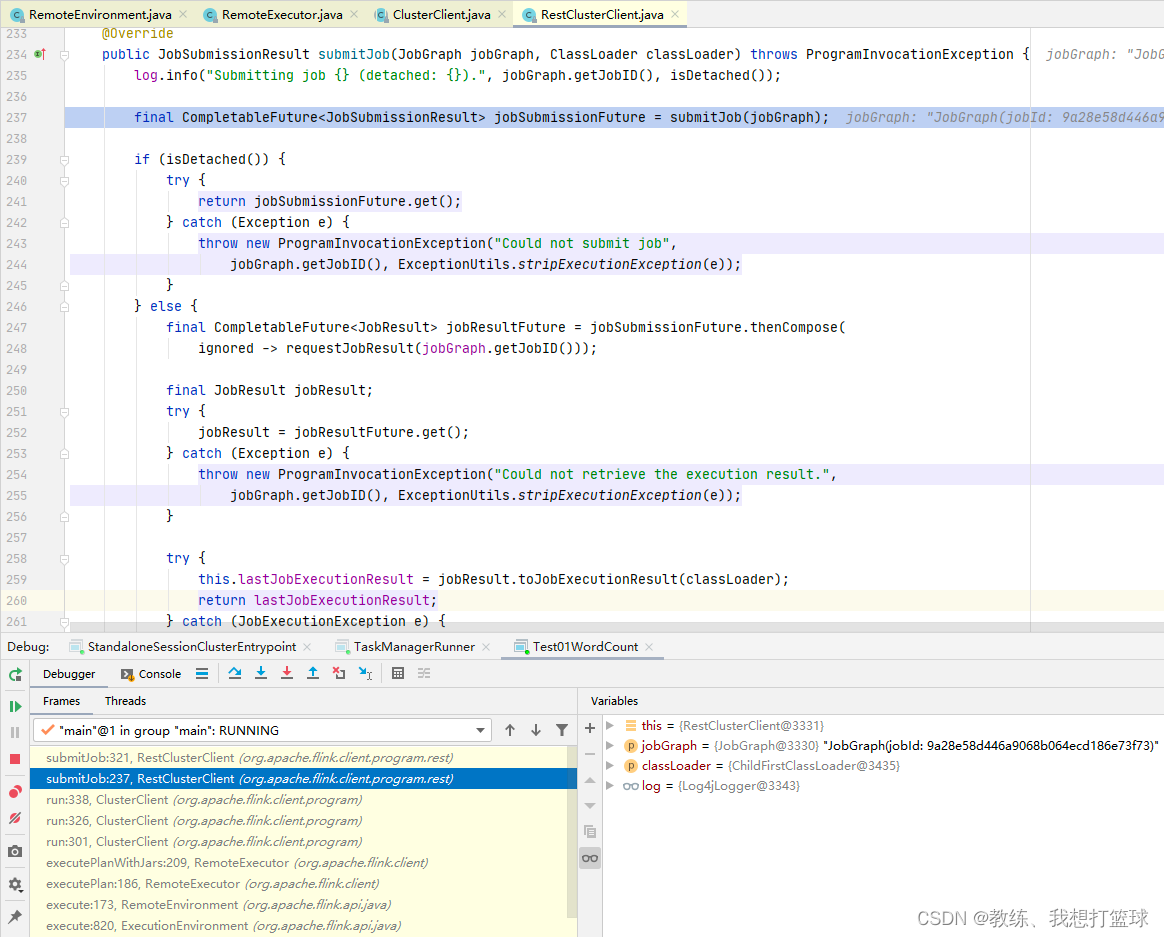
这里是将 JobGraph 序列化为 为一个临时文件, 然后提交给 flink 集群
然后 另外就是 job 这边需要使用的 jar 列表, 也需要提交给集群
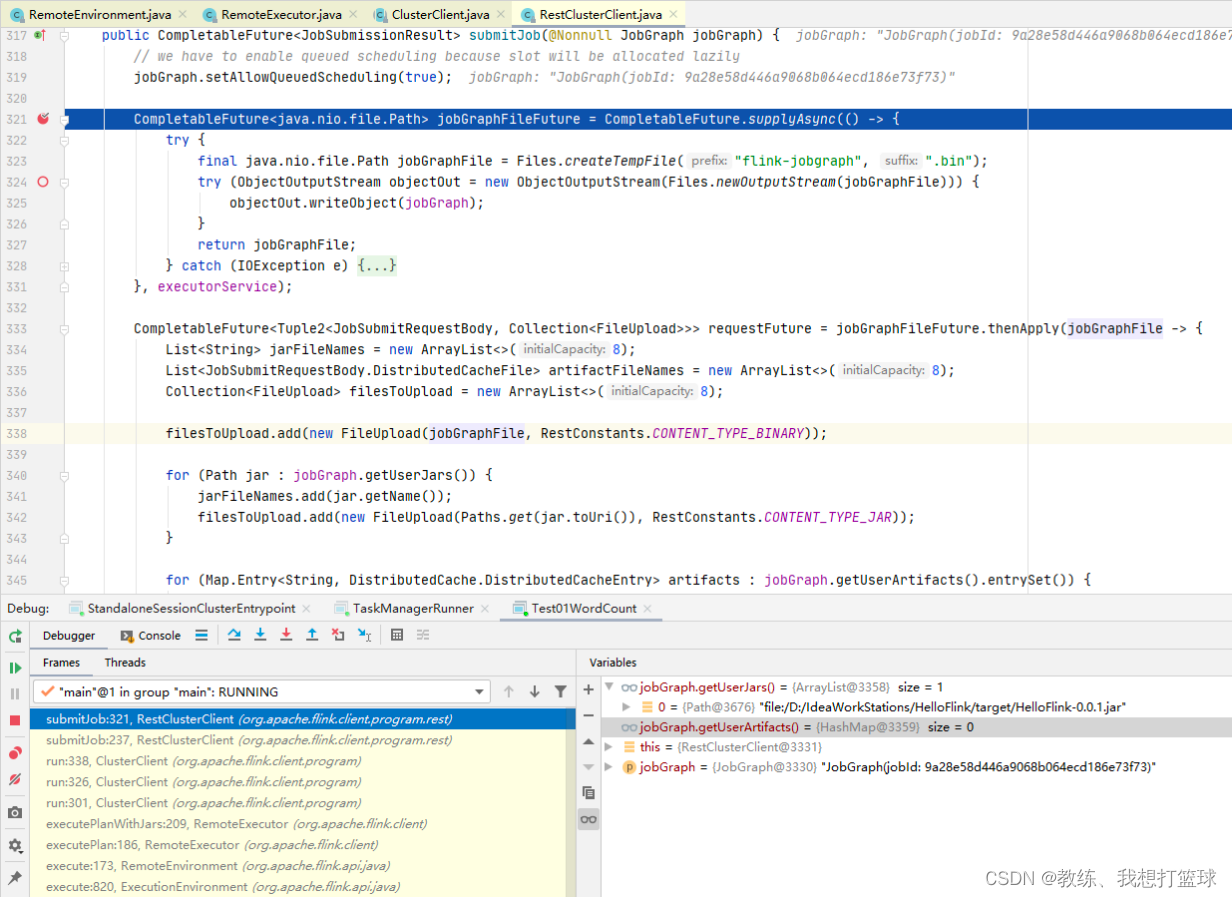
然后更详细的提交的请求内容如下, 合计传送了 47kb
然后传递的主要内容为 三部分
第一部分为元数据, 内容为 “{"jobGraphFileName": "flink-jobgraph126256148600228610.bin", "jobJarFileNames": ["HelloFlink-0.0.1.jar"], "jobArtifactFileNames": []}”
第二部分为 jobGraph 序列化之后的临时文件, “flink-jobgraph126256148600228610.bin”
第三部分为 job 执行需要的 jar 包, “HelloFlink-0.0.1.jar”
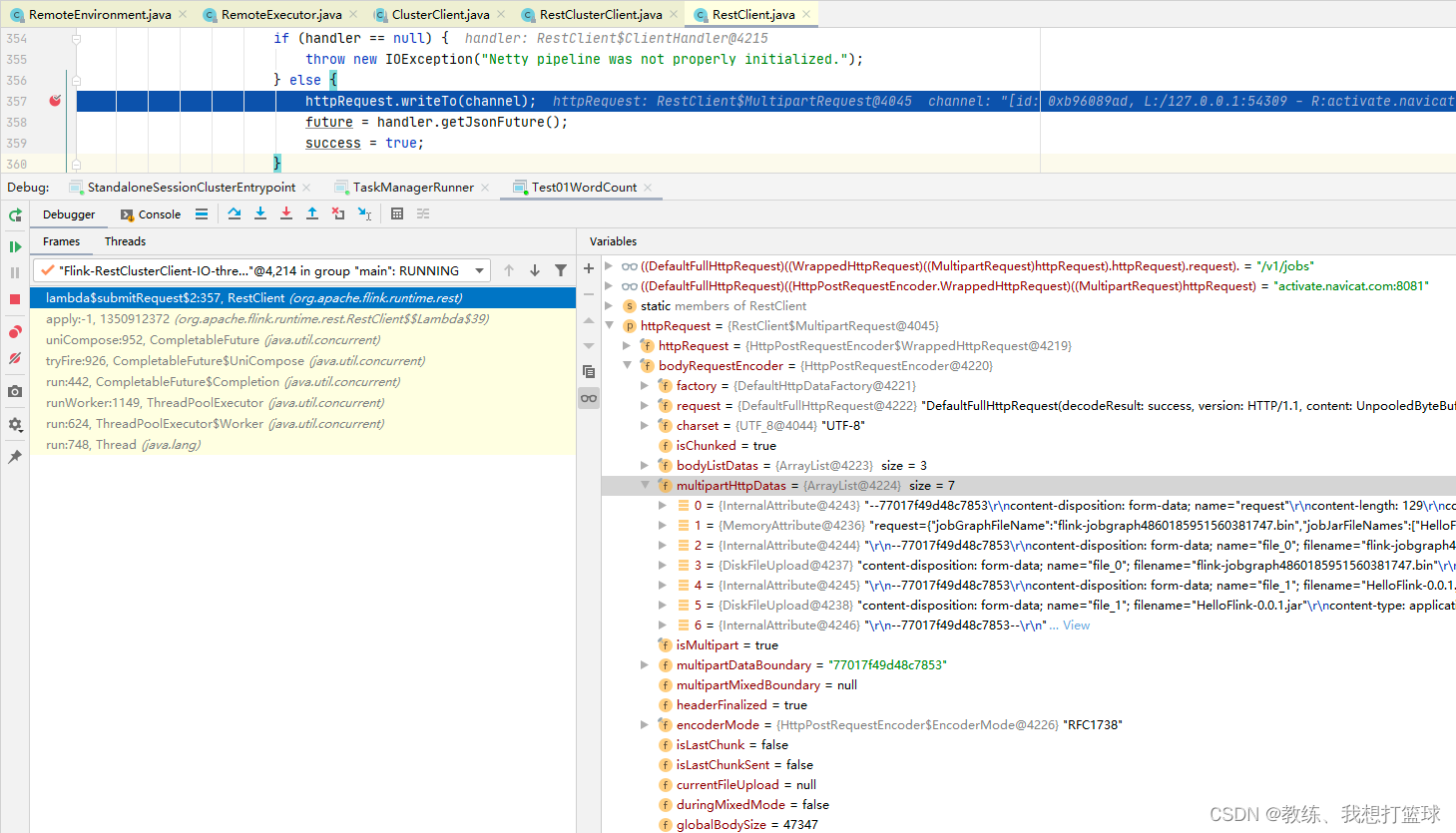
JobManager 这边的处理
JobManager 这边拿到如上 driver 这边提交的 HttpRequest 之后, 处理如下
根据 jobGraphFileName 反序列化 JobGraph, 上传 job 所需要的 jar 到 BlobServer
然后就是向 Dispatcher 提交 jobGraph
返回当前提交的 job 的相关信息, 主要是 jobId
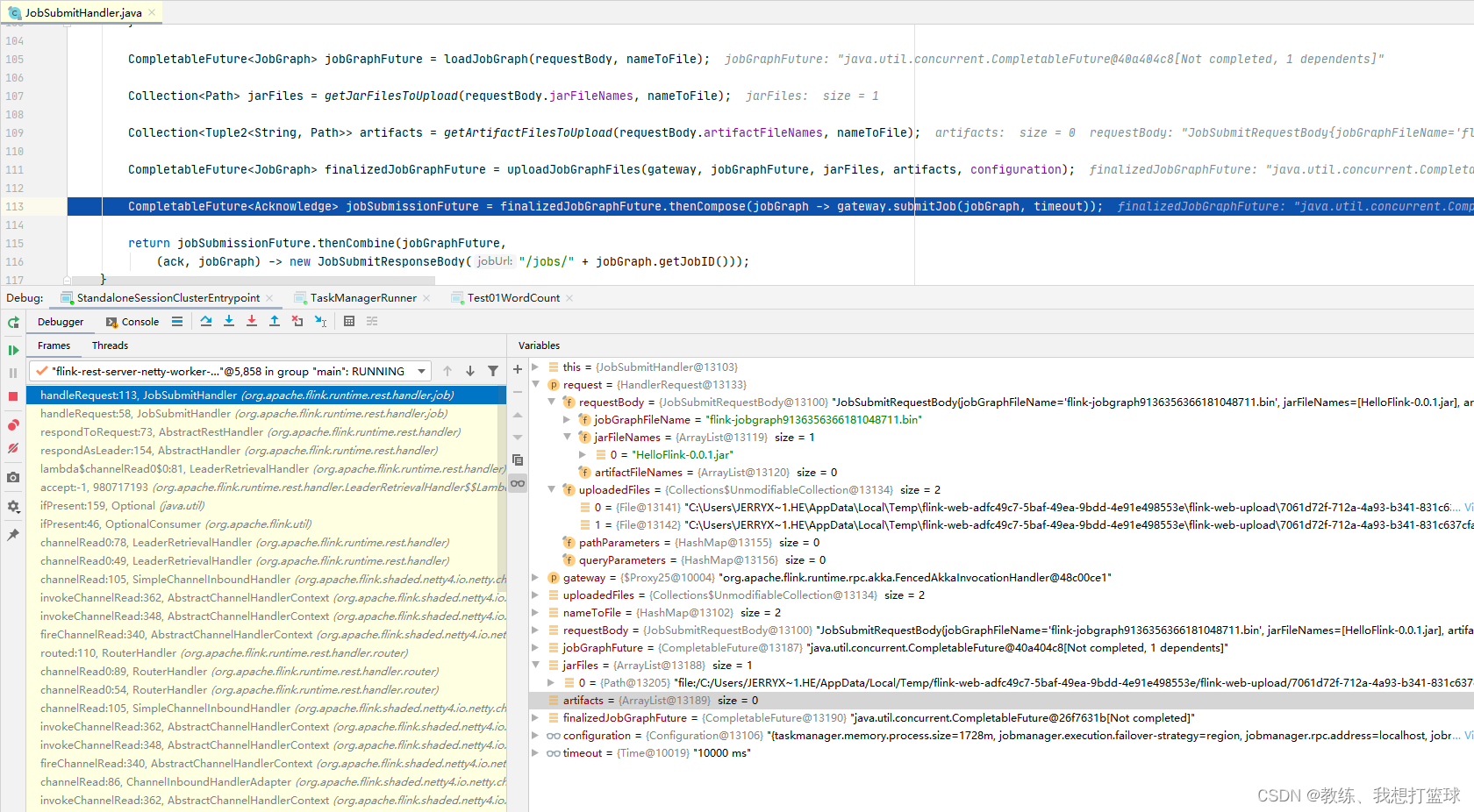
然后是 Dispatcher 这边 persistAndRunJob, 创建 JobManagerRunner, JobMaster
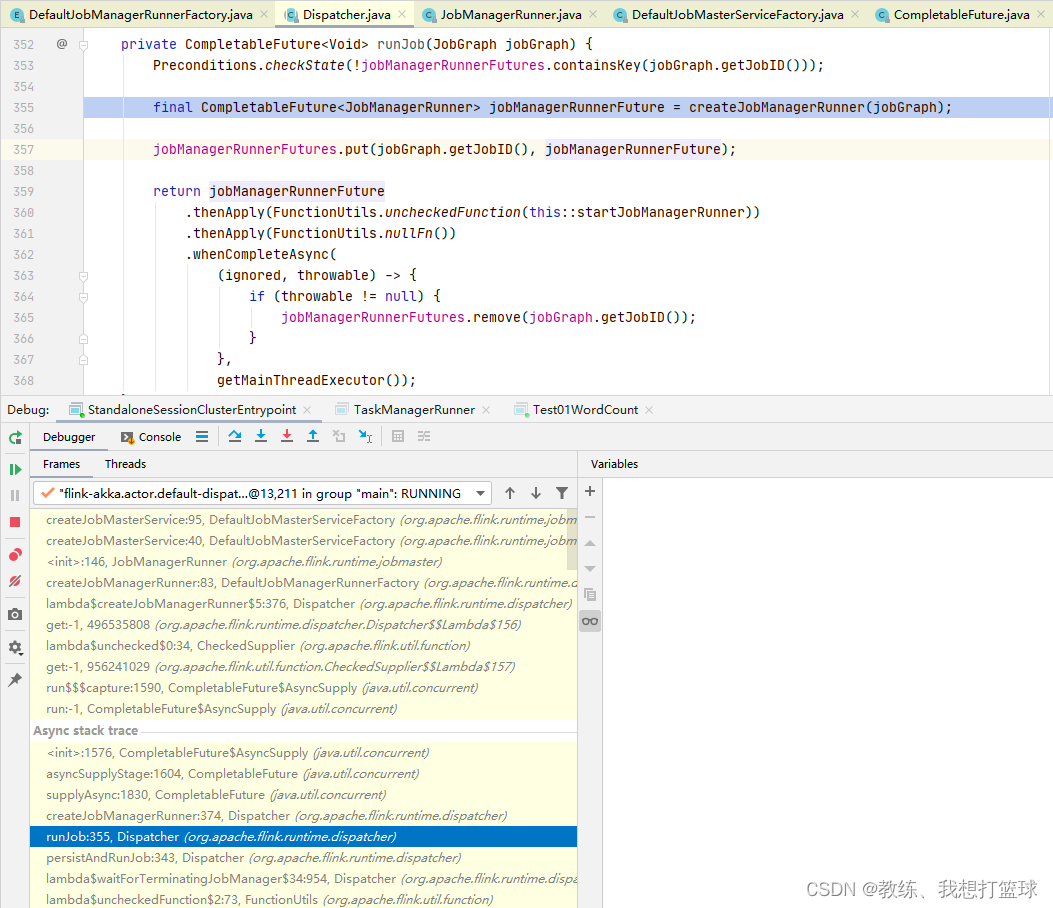
然后是 JobManagerRunner 启动 JobMaster
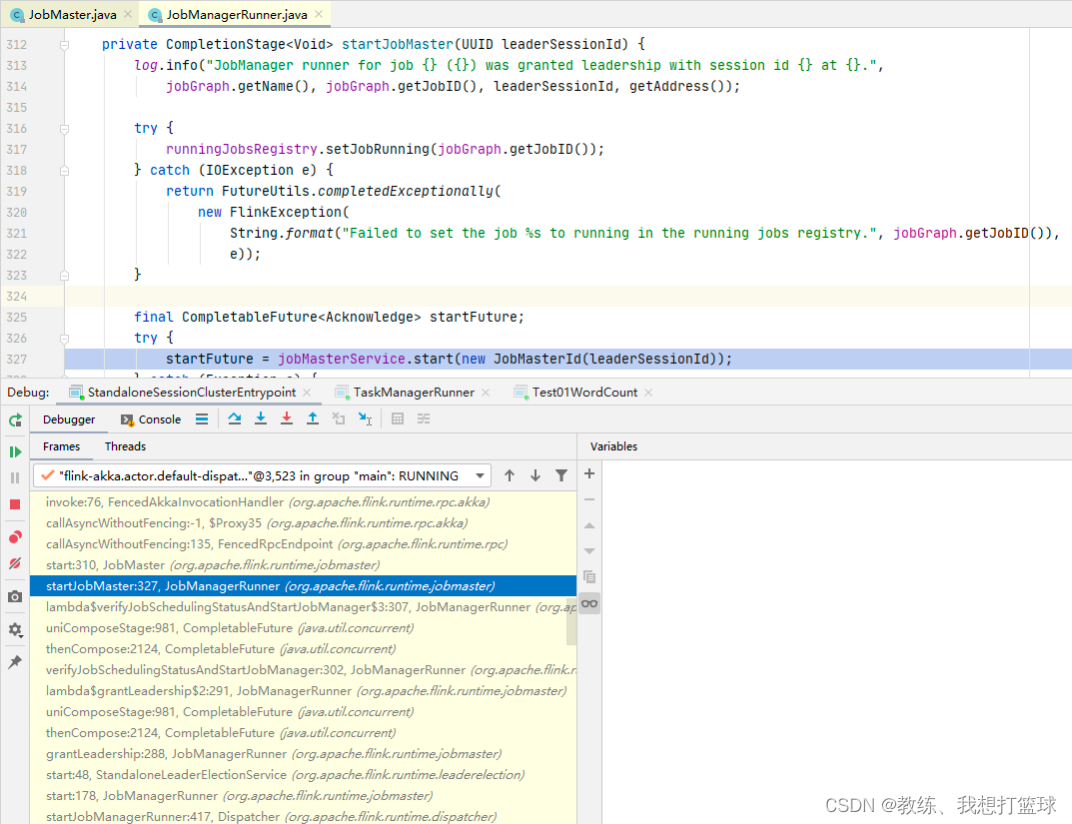
然后是 JobMaster 这边基于内部的 scheudlerNG 来开始调度任务
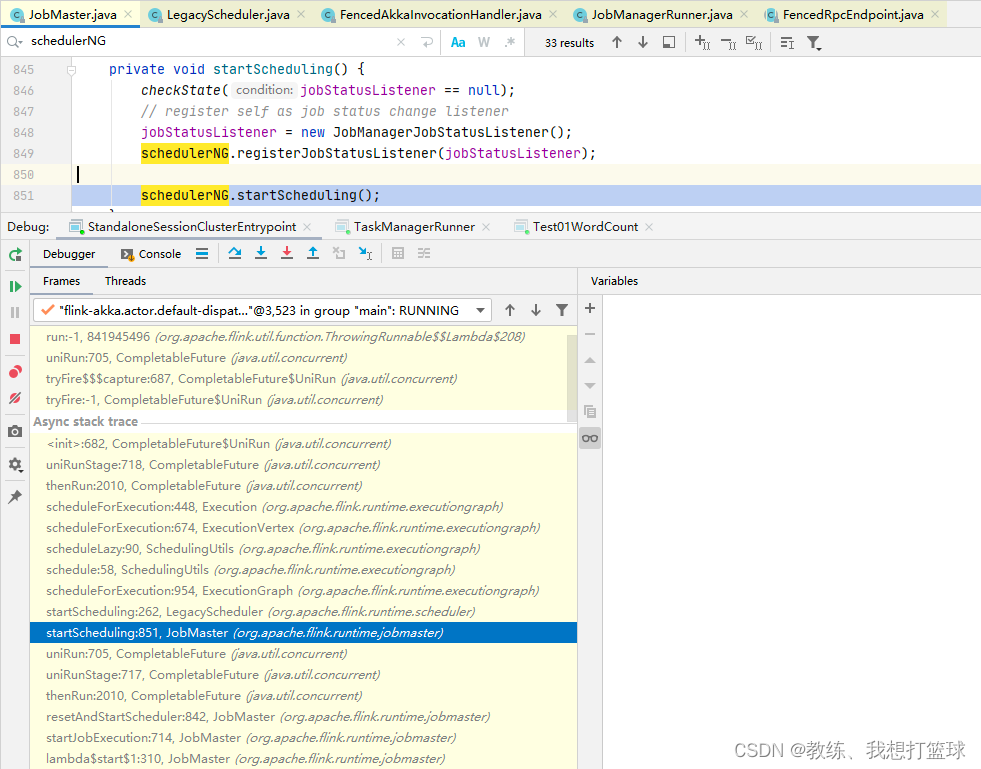
然后是根据 ExecutionVertex 封装 TaskDeploymentDescriptor, 然后 向 TaskManager 执行 job 拆解之后的任务
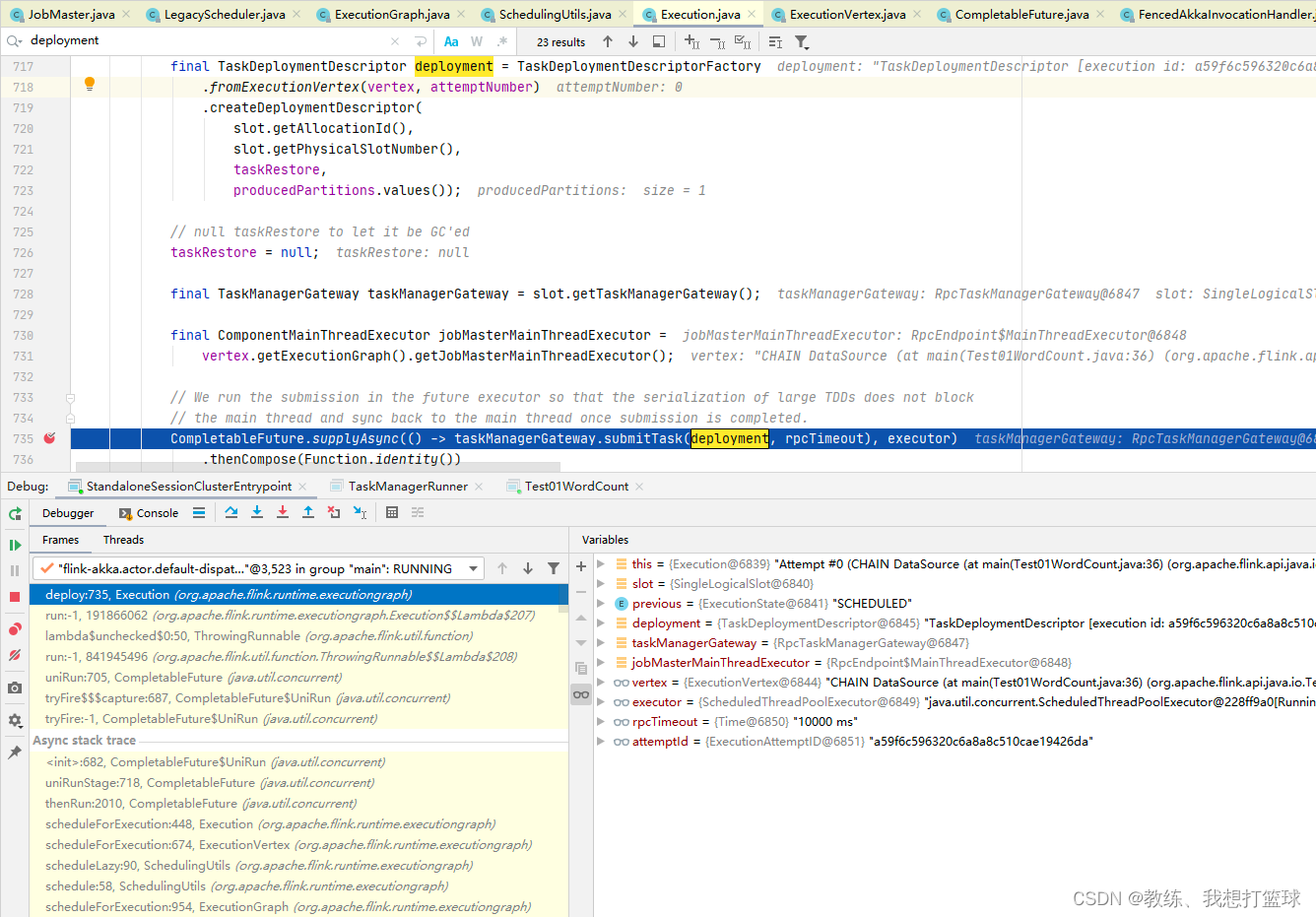
TaskManager 这边的处理
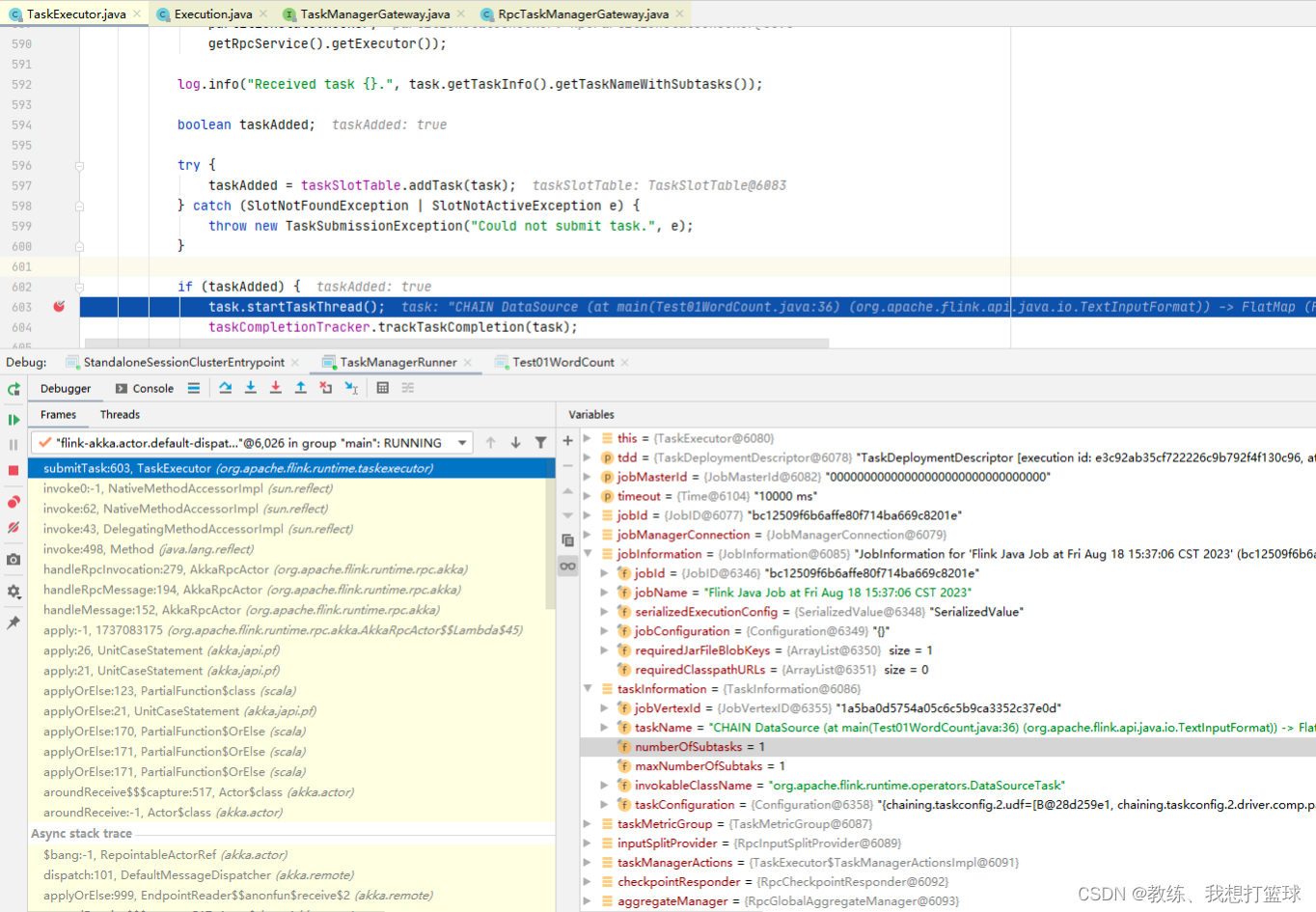
TaskExecutor 这边收到了 TaskDeploymentDescriptor 之后, 反序列化 jobInformation, taskInformation, 创建 Task, 然后执行 Task
这里可以从 taskInformation 的上下文信息, 可以看到当前 Task 属于哪一个 JobVertex, 以及改 JobVertex 总共有一个 SubTask, 以及当前 Task 是属于第几个 SubTask
然后就是 Task 这边的执行
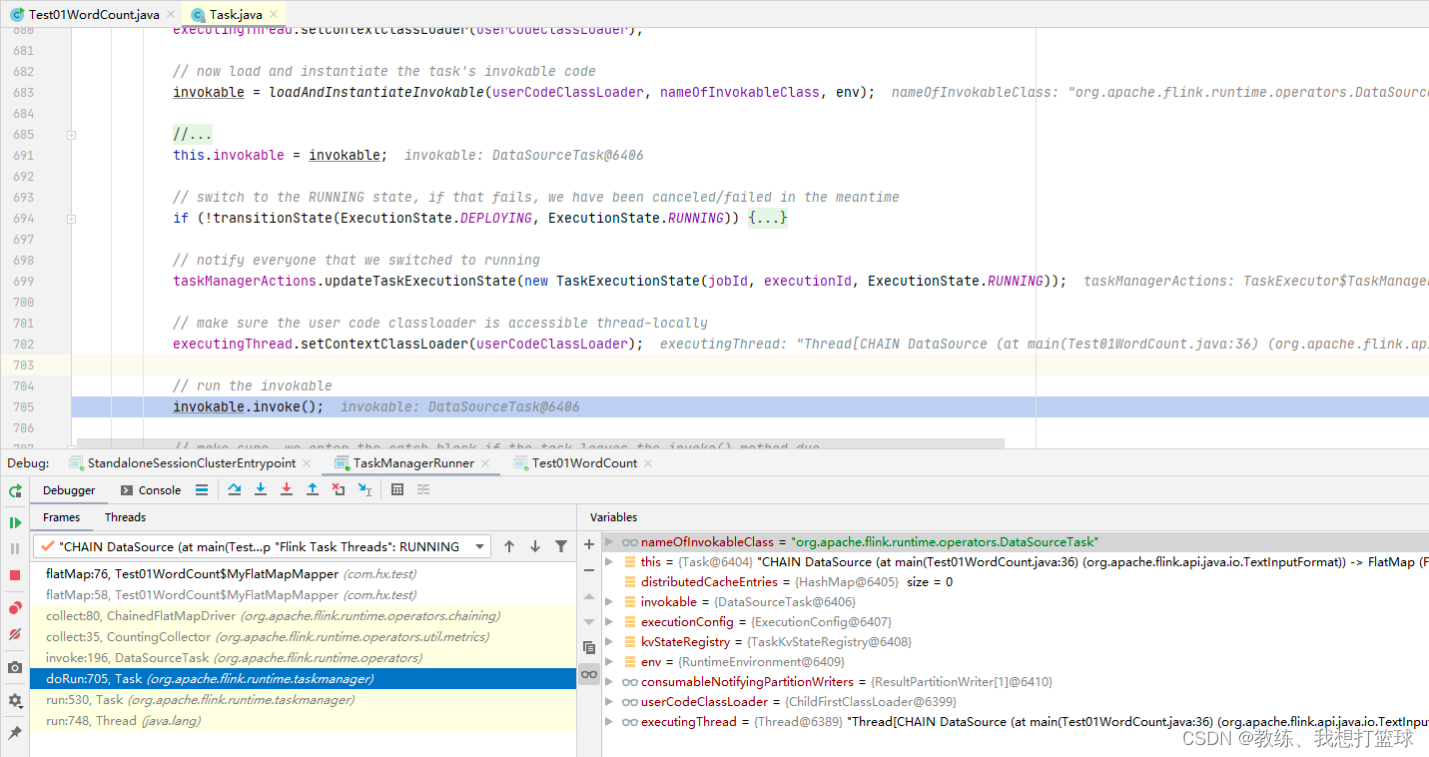
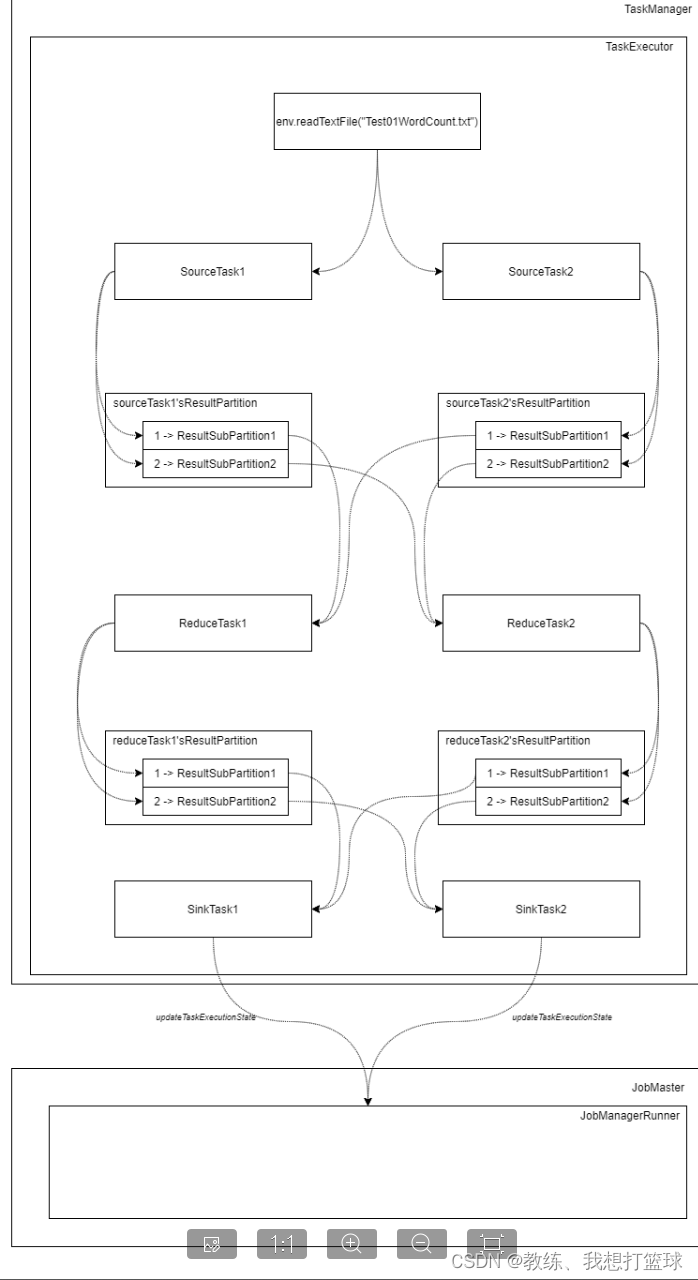
这边执行的就是基于 jar 包 和 DataSourceTask, ChainnedFlatMapDriver, ChainnedMapDriver 等等 来执行具体的业务处理
业务这边执行流程如下
DataSource 逐行读取 Test01WordCount.txt 中的字符串信息, 这里读取的是第一行 “123 234 456”
ChainedFlatMapDriver 这边是将一行的字符串转换为多行字符串, “123 234 456” 转换为 “123”, “234”, “456”
ChainedMapDriver 这边是将一个输入进行映射, 这里的是 “123” 转换为 (“123”, 1)
SynchronousChainedCombineDriver 这边是将到目前为止的结果, hash partition 之后输出到下游的 SubTask
SynchronousChainedCombineDriver 这边先是将记录写入到 sorter, 然后 close的时候, 在迭代记录将记录输出到下游
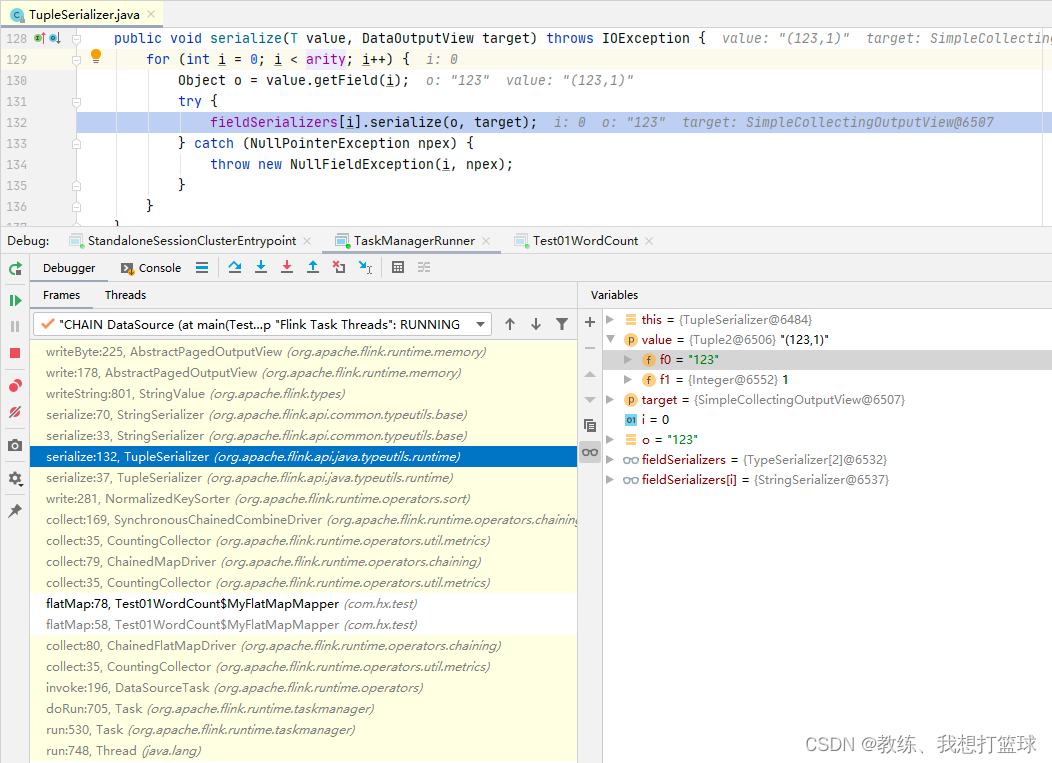
输出当前 Task 的各个记录的地方
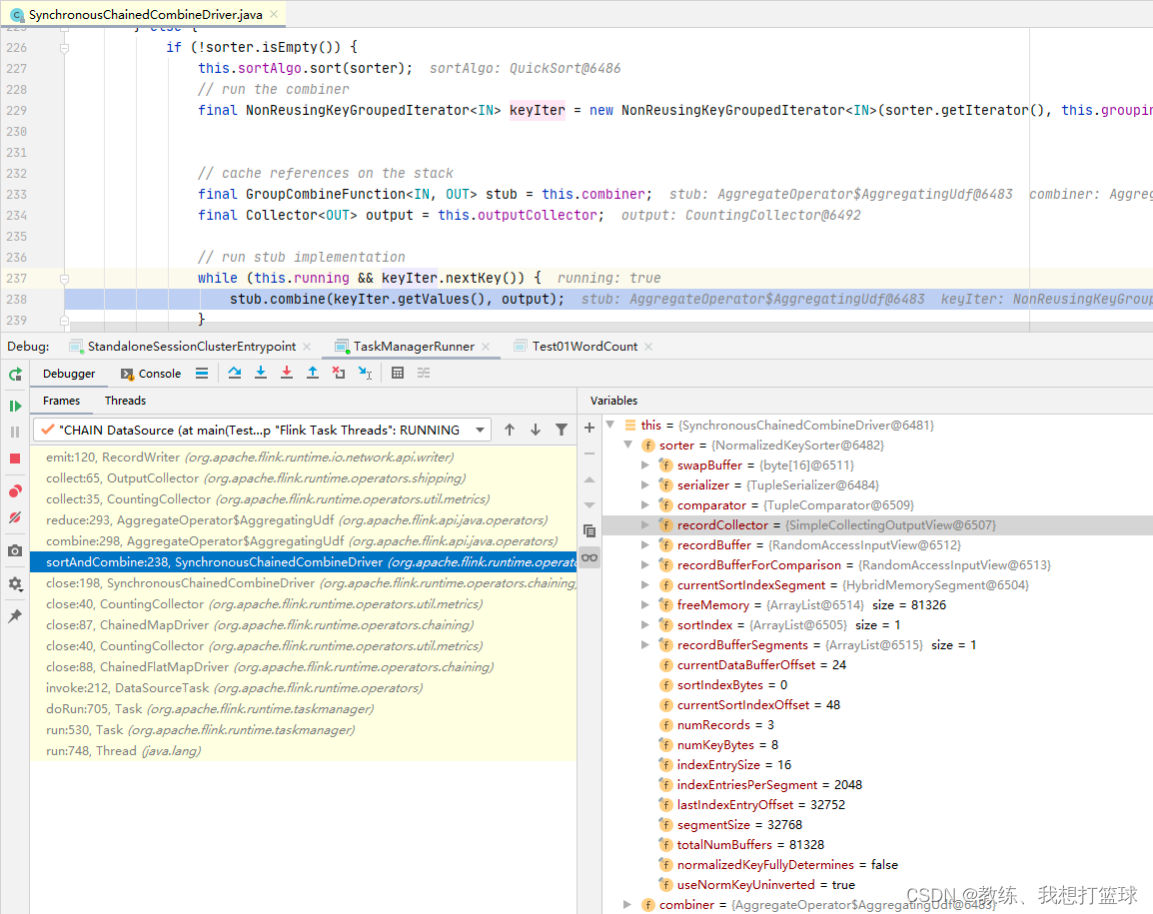
repartition 的地方
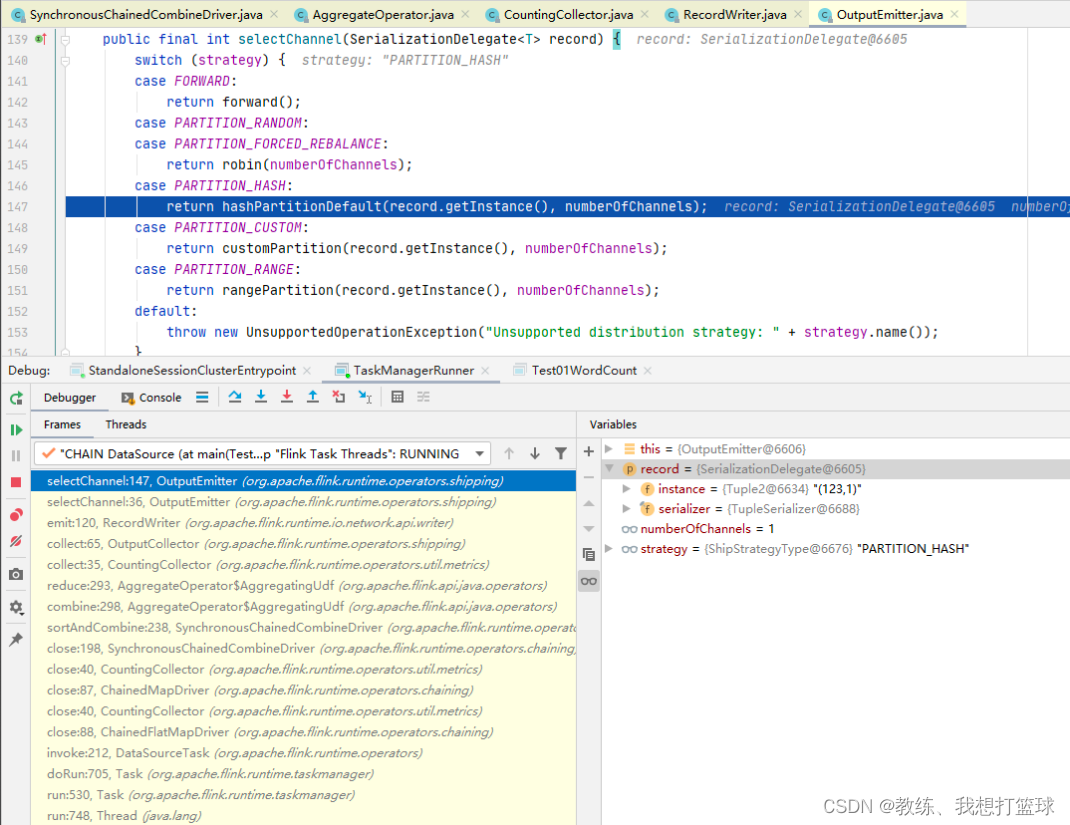
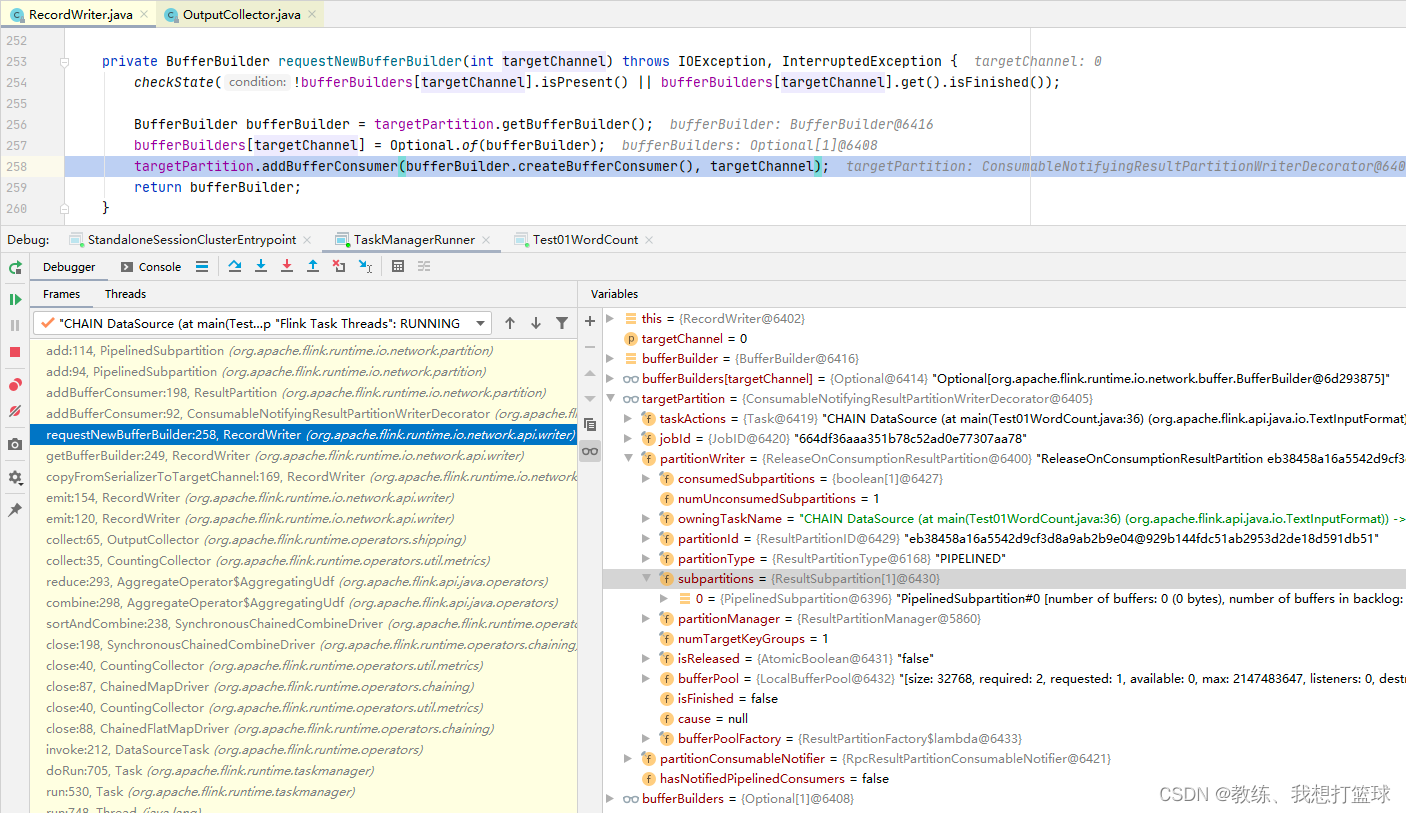
每一个 partition 的数据是写出到 RecordWriter 下面的 ReleaseOnSonsumptionResultPartition 下面的 subpartitions[partitionIndex]
然后这部分 ResultPartition 数据是维护在 ResultPartitionManager, 这个是每一个 TaskExecutor 维护一个 ResultPartitionManager 用于相同的任务之间的不同的 SubTask 的数据交互
所以说一个 SubTask 维护了一个 ReleaseOnSonsumptionResultPartition, 然后维护了 parallelism 个 subpartitions
然后下游的 SubTask 依次来遍历上游的 SubTask, 获取当前 SubTask 需要读取的 subpartitions[index] 来作为输入
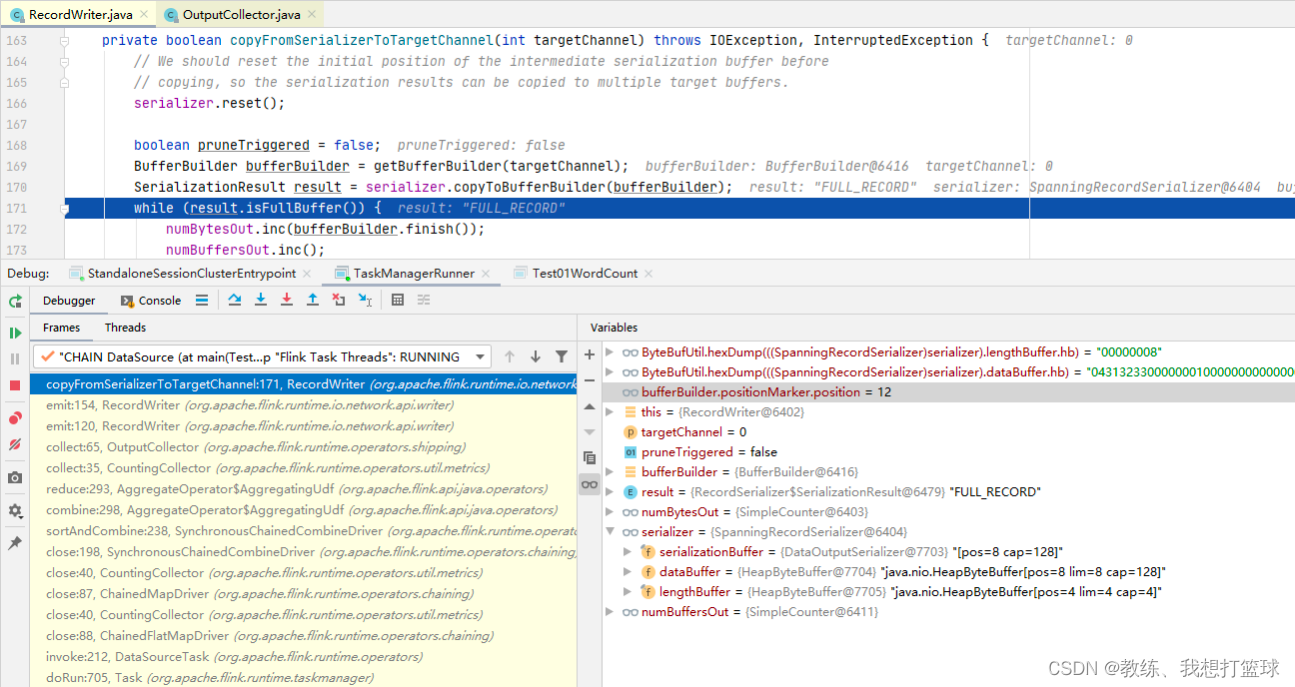
输出一条记录之后信息如下, bufferBuilder 中输出了 12 字节, 前面四个字节为长度标记 0x04 长度为 4
然后接下来 8个字节为 ”0431323300000001”, 表示的是 “123” + 1, 最前面的 0x04 表示 0x03 + 1[参见 StringValue.writeString]
然后下游的 SubTask 这边读取的是上游的 N 个 SubTask 中的当前 subpartitionIndex 部分的输出, 这里的 partitionId 为上游输入 SubTask 的 partitionId
这里当前 SubTask 会对应 parallelism 个 InputChannel, 每一个分别关联上上游 SubTask 的输出
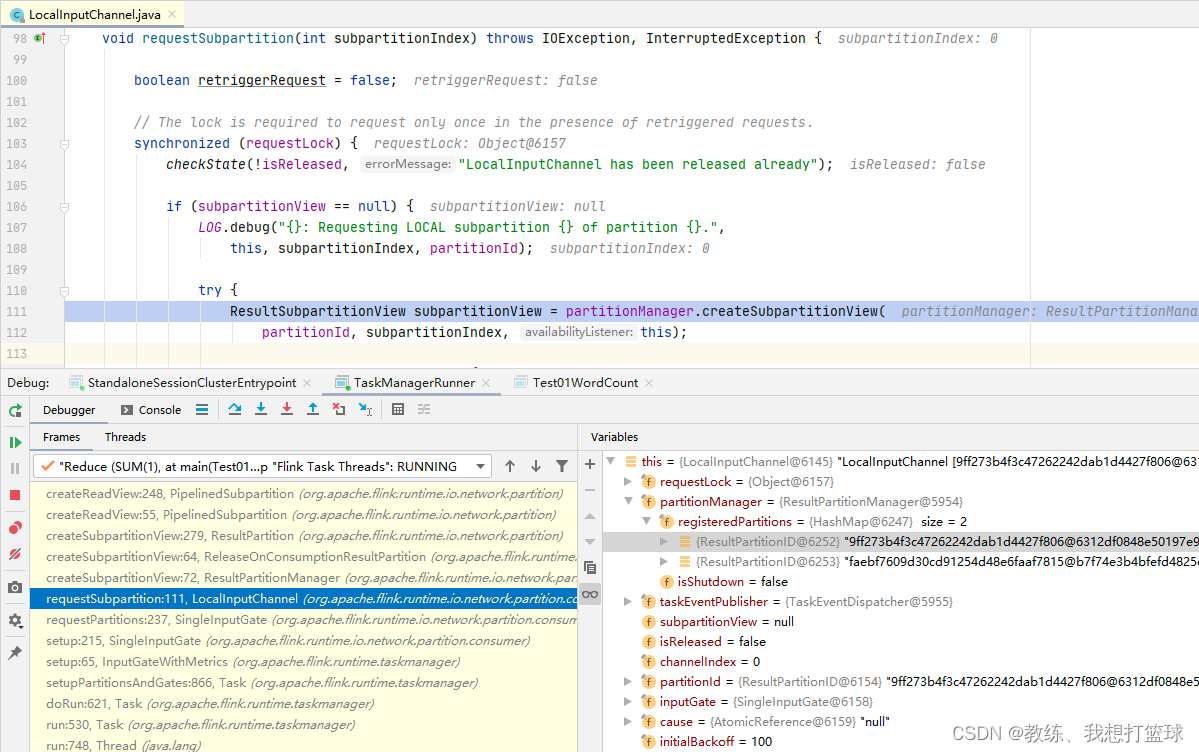
各个 SubTask 的数据交互
上游任务启动的时候, 会向 PartitionManager 注册输出的 ResultPartition 的信息
然后这里的 partition.getPartitionId 是来自于当前 SubTask 的 partition, 每一个 SubTask 单独生成一个
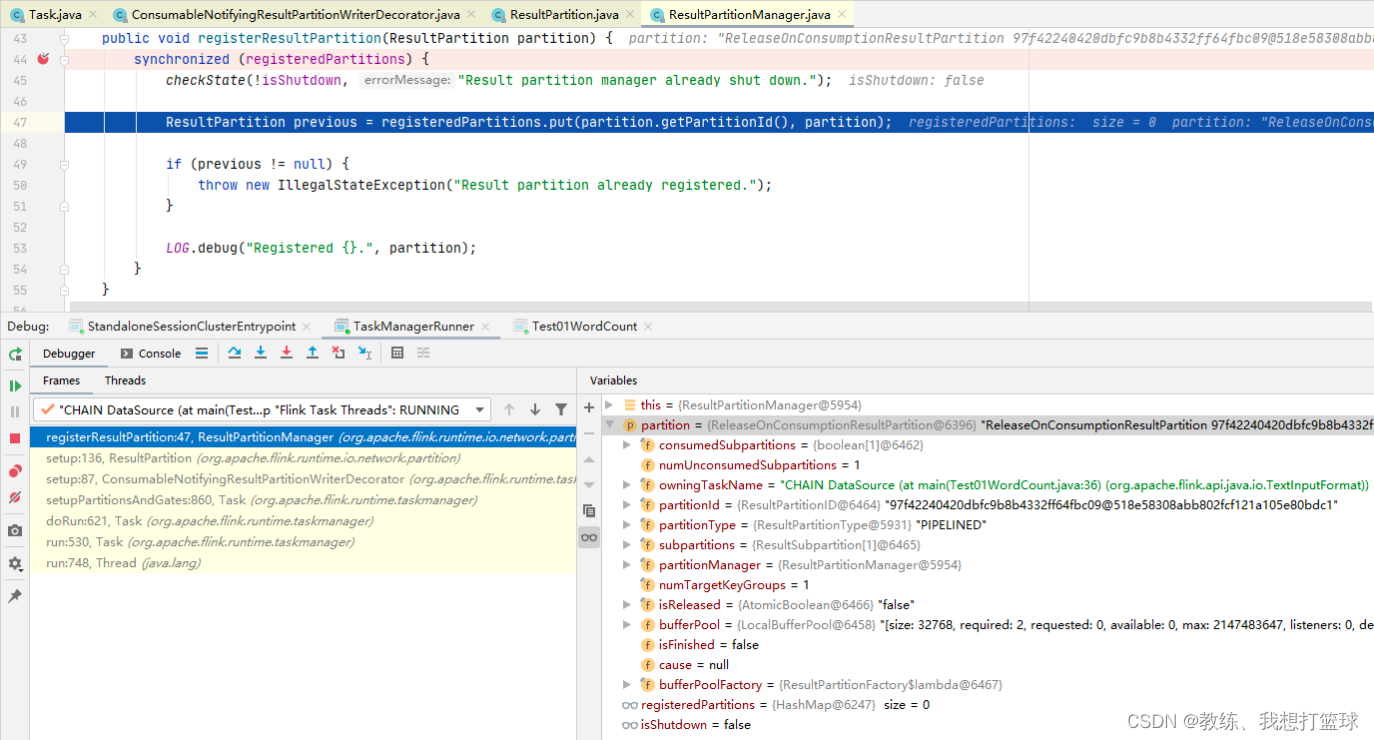
在 TaskManager 这边传递过程如下, TaskDeploymentDescriptor.producedPartitions.shuffleDescriptor.resultPartitionID -> ReleaseOnConsumptionResultPartition -> ResultPartition
然后再到 后面的 ResultPartition.setup 的向 PartitionManager 注册
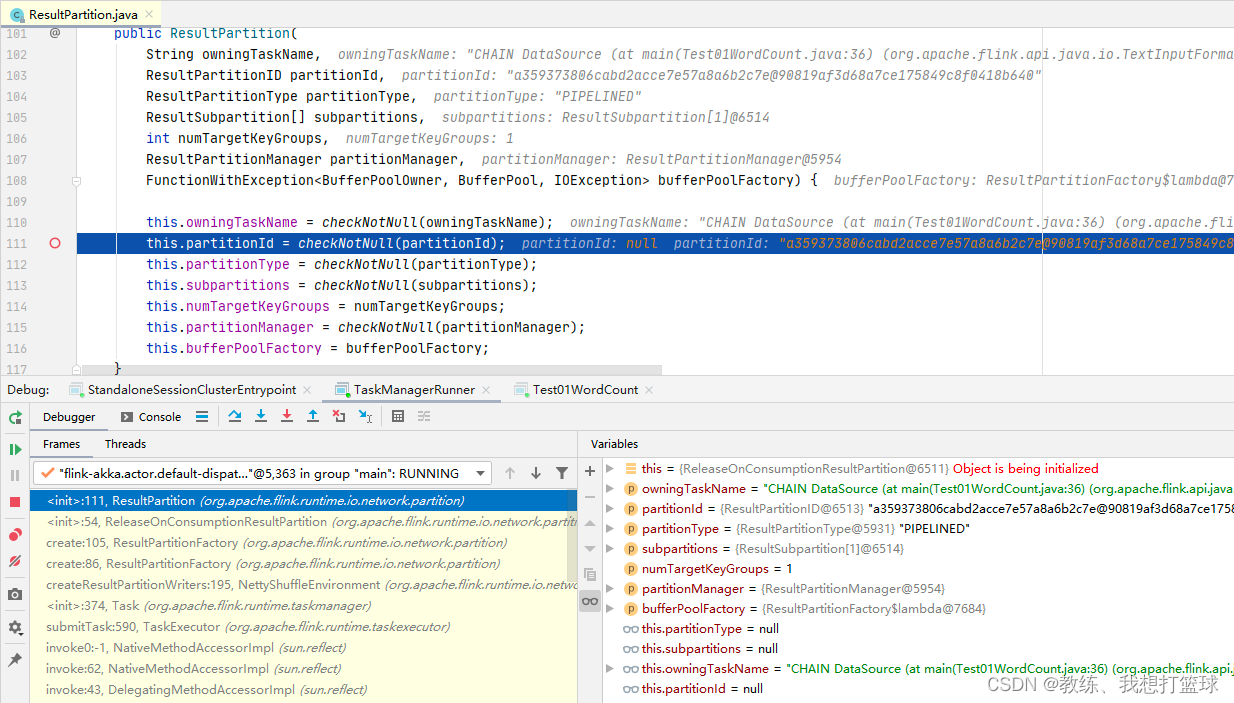
然后 JobManager 这边是生成这个 shuffleDescriptor 相关, 传递流程如下
IntermediateResultPartition -> Vertex.resultPartitions -> Partition -> PartitionDescriptor -> NettyShuffleDescriptor
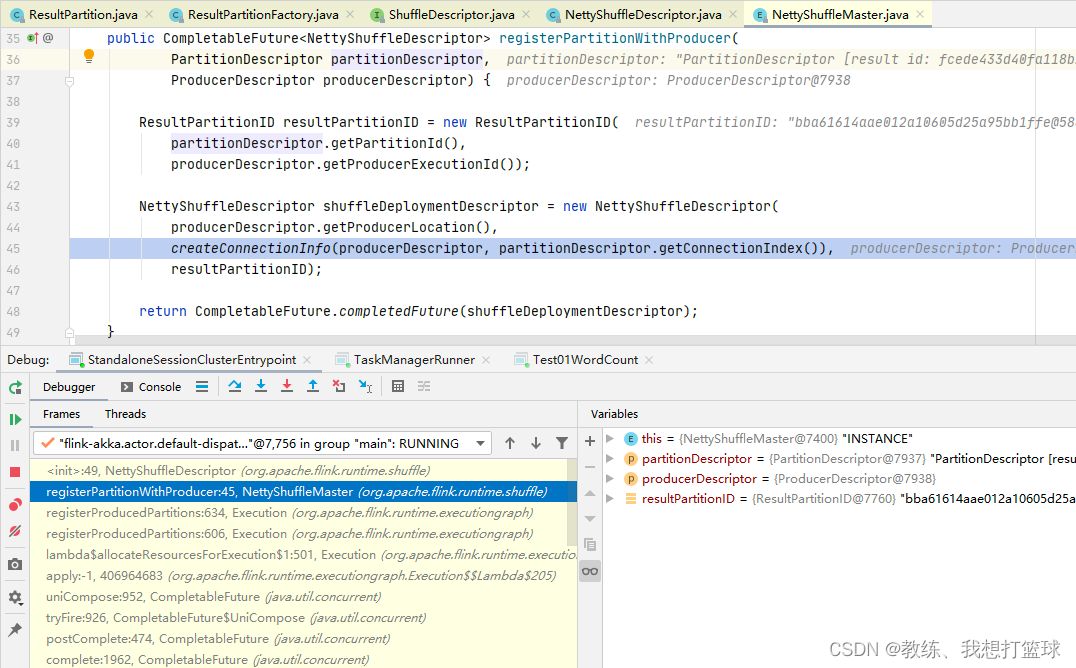
然后 Vertex.resultPartitions 这边初始化如下, 里面的组合了一个 IntermediateResultPartition, 它的 partitionId 是传递到后面 NettyShuffleDescriptor 的 partitionID, 然后这个 partitionId 是随机生成的
根据上下文来看, 就是每一个 SubTask 一个
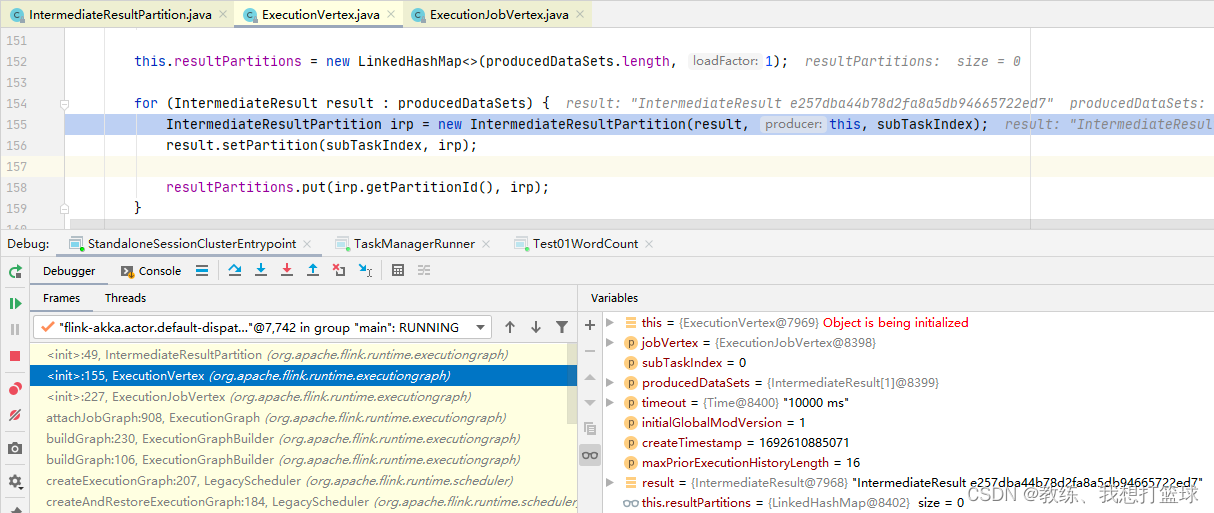
然后我们看一下 下游的 SubTask 这边来消费上游的 SubTask 的处理, 这里获取的是 InputChannel 的 partitionId
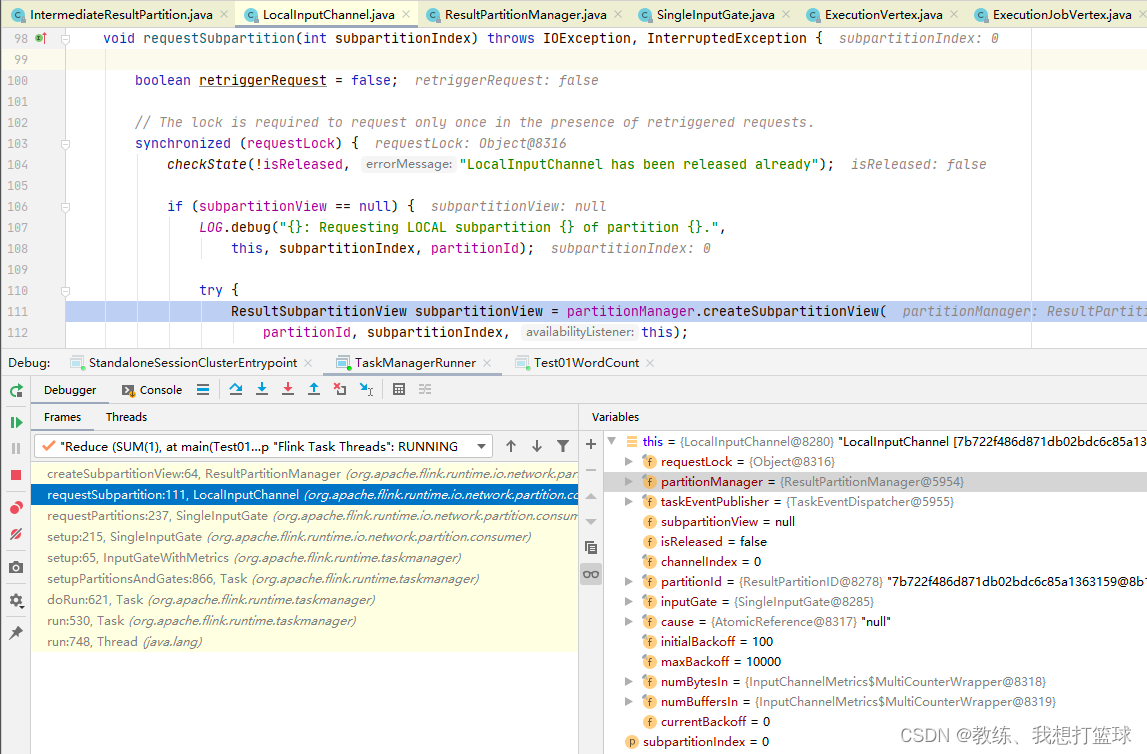
InputChannel 的 partitionId 是来自于上游的 inputChannelDescriptor.partitionId, 这样就把整个流程串联起来了
下游的 SubTask 可以读取到所有上游SubTask 的结果信息
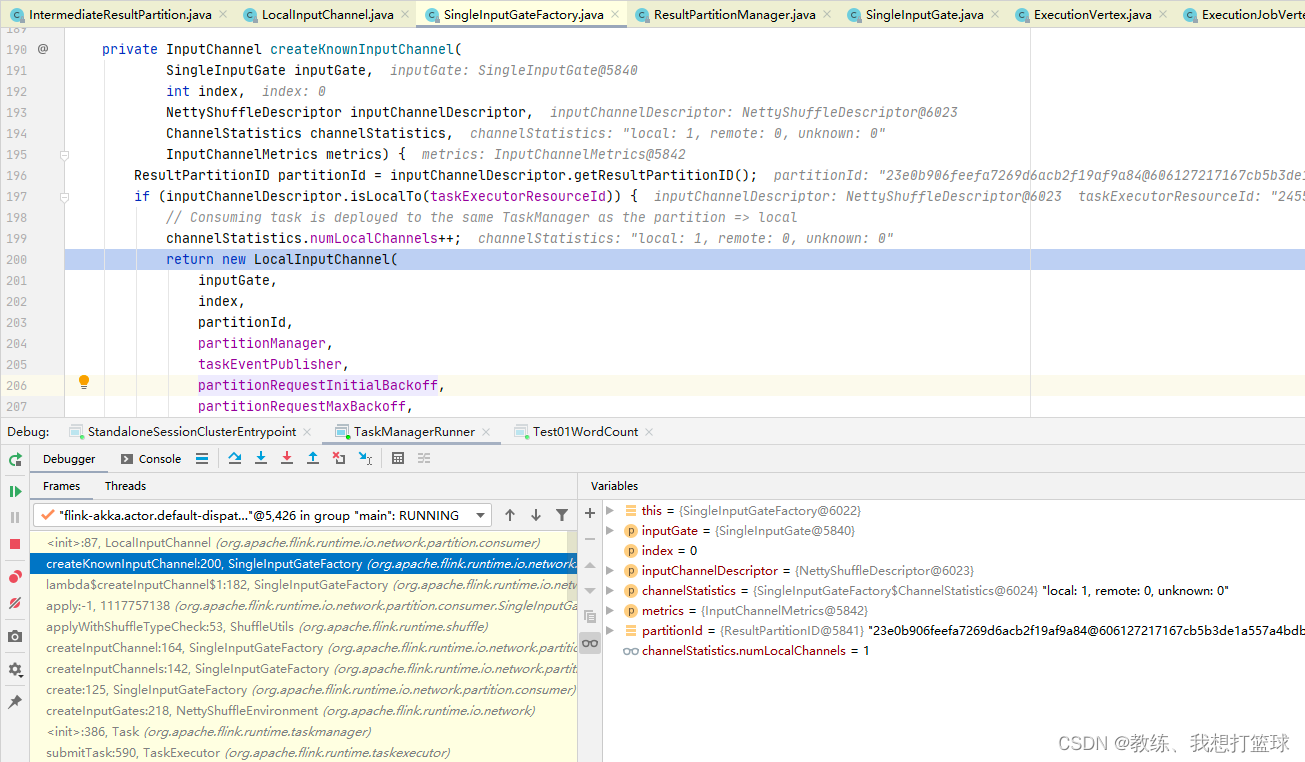
各个 Task 执行的通知
Task 和 Task 之间是有依赖关系的, 下游的 Task 相对于 上游的Task 称之为 consumers
当上游的 Task 有数据提交到之后, 这里会通知到 JobMaster 通知 partitionId 已经在产出数据了
然后 jobMaster 通知该 Task 的下游的 Task 开始执行
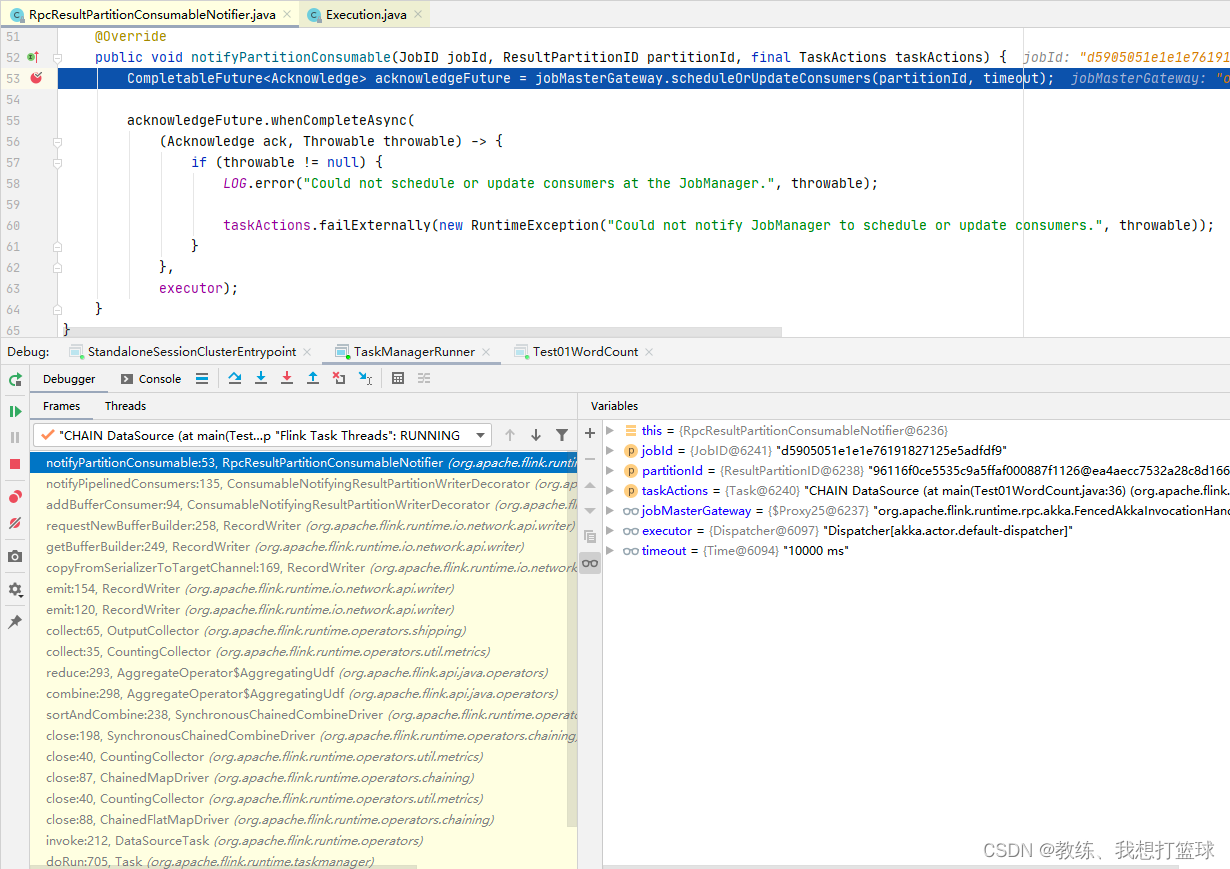
然后 JobMaster 这边收到 scheduleOrUpdateConsumers 之后的处理如下
开始 调度下游的 consumers, 即下游的 SubTask 开始申请资源, 然后 执行 等等
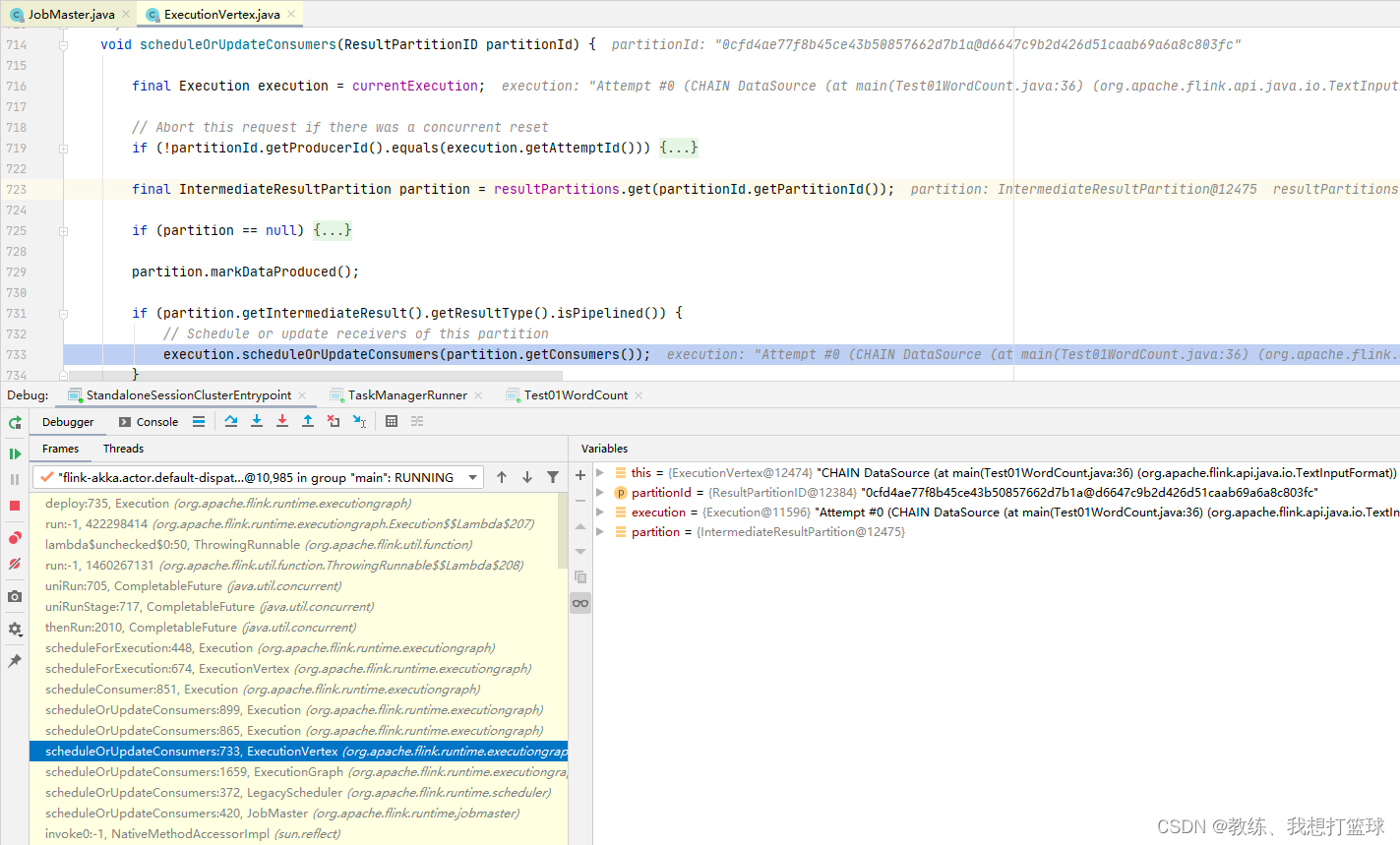
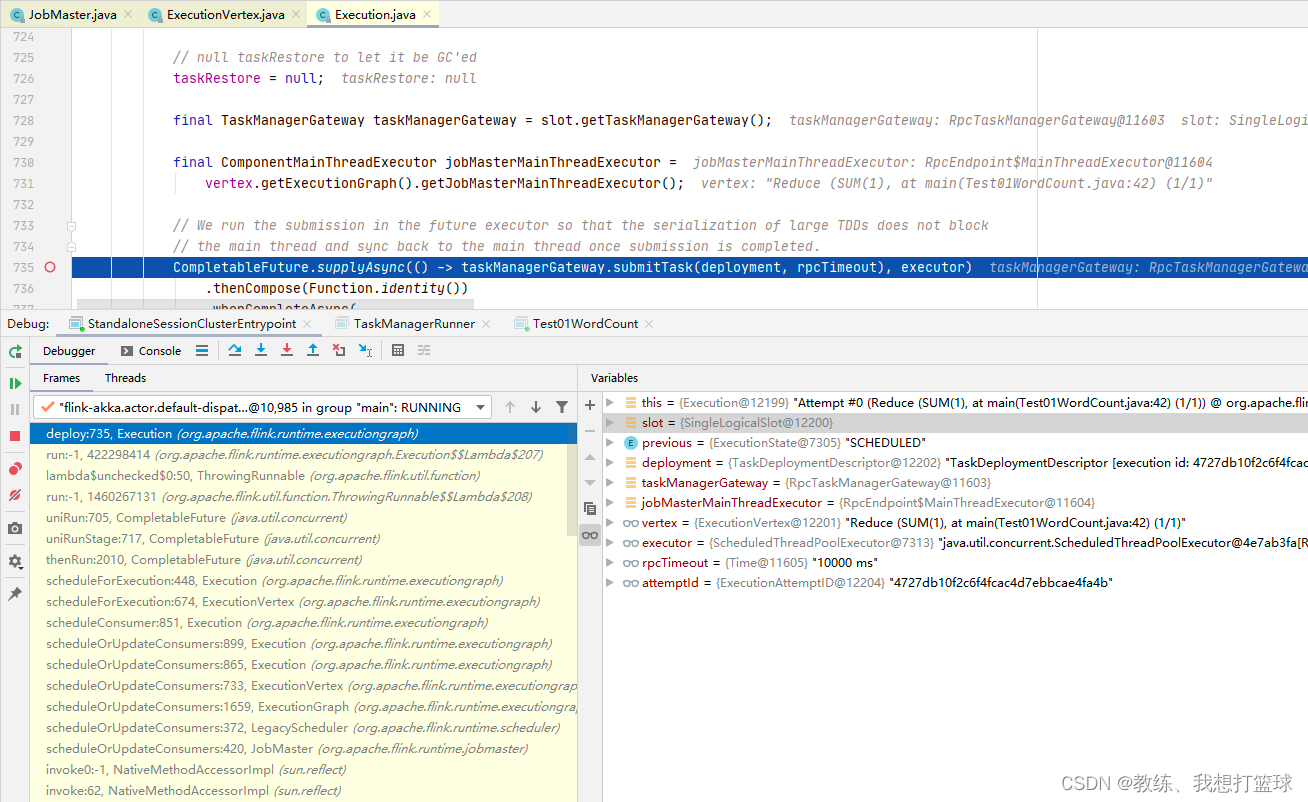
计算结果的交互
首先是 driver 这边
Job 提交了之后, 会执行 requestJobResult, 这里面是向 JobManager 这边发送 http 请求, 获取 给定的 Job 的执行结果
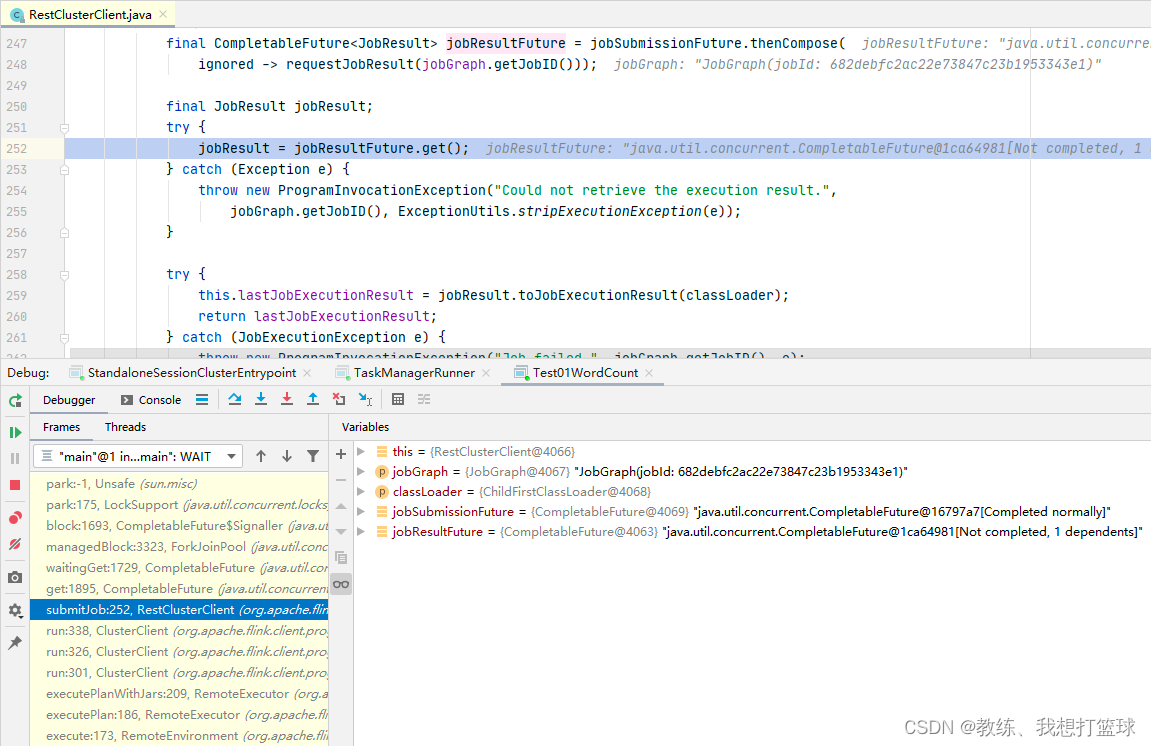
发送的 http 请求如下, 请求的是 “/v1/jobs/682debfc2ac22e73847c23b1953343e1/execution-result”
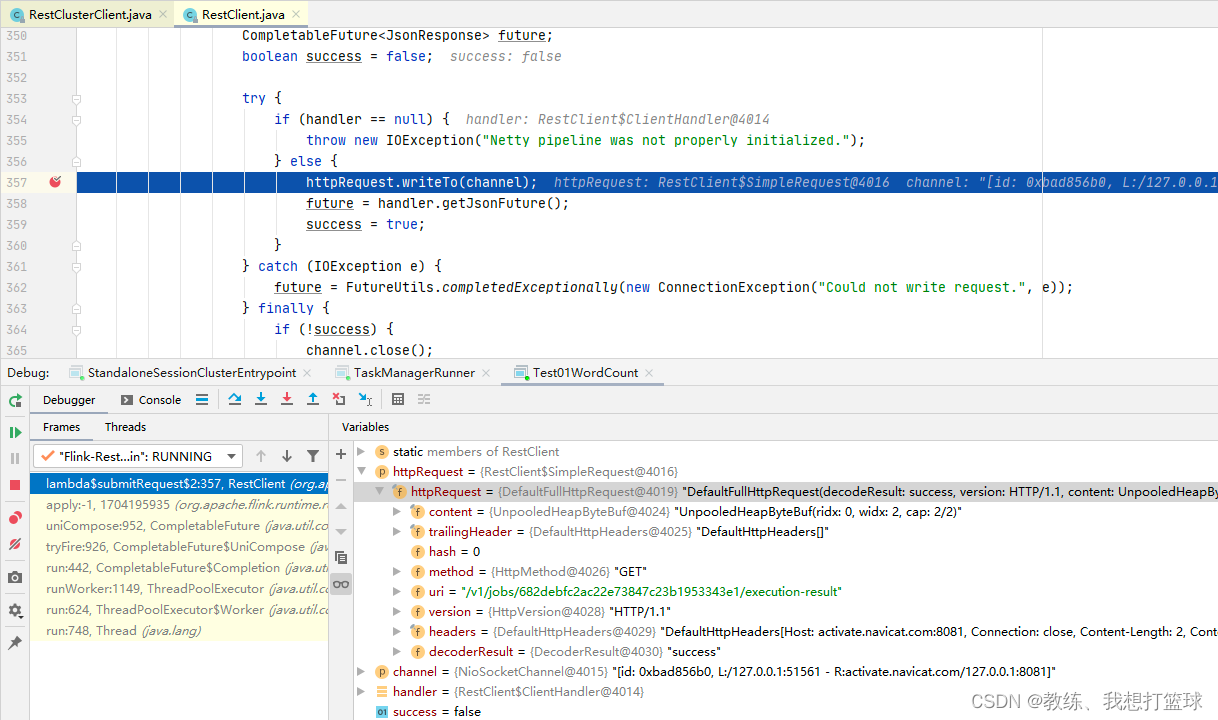
然后 JobMaster 这边的处理如下, 我们这里 需要关注的是 这个 accumulatorResults, 这里面暂存的我们计算的结果
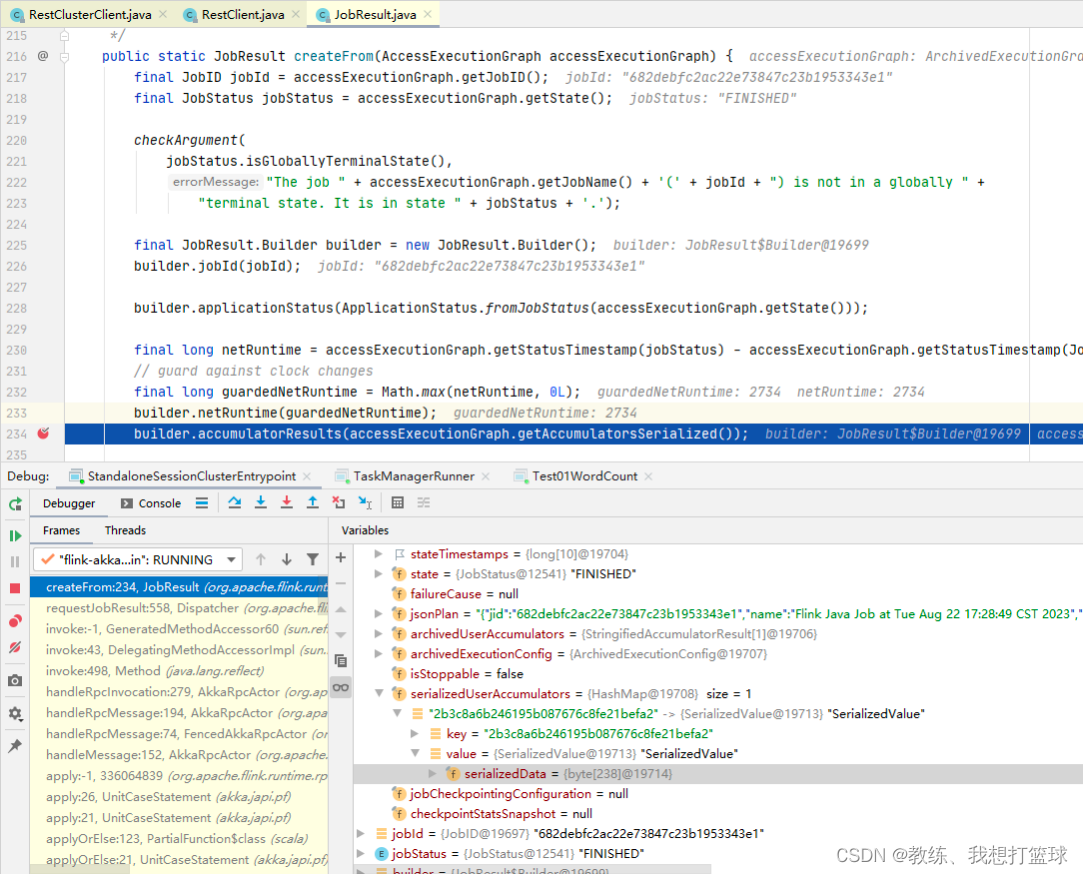
然后这个 accumulatorResults 的数据来自于各个 Task 执行完成之后通知到 JobMaster 这边的 accumulators
如下图 这里是 Task 执行完成之后提交更新任务执行状态的请求到 JobMaster, state 中携带了 accumulators

接下来是封装 ArchivedExecutionGraph, 这里封装的 accumulators 是使用的各个 Task 执行完成之后响应的 accumulators
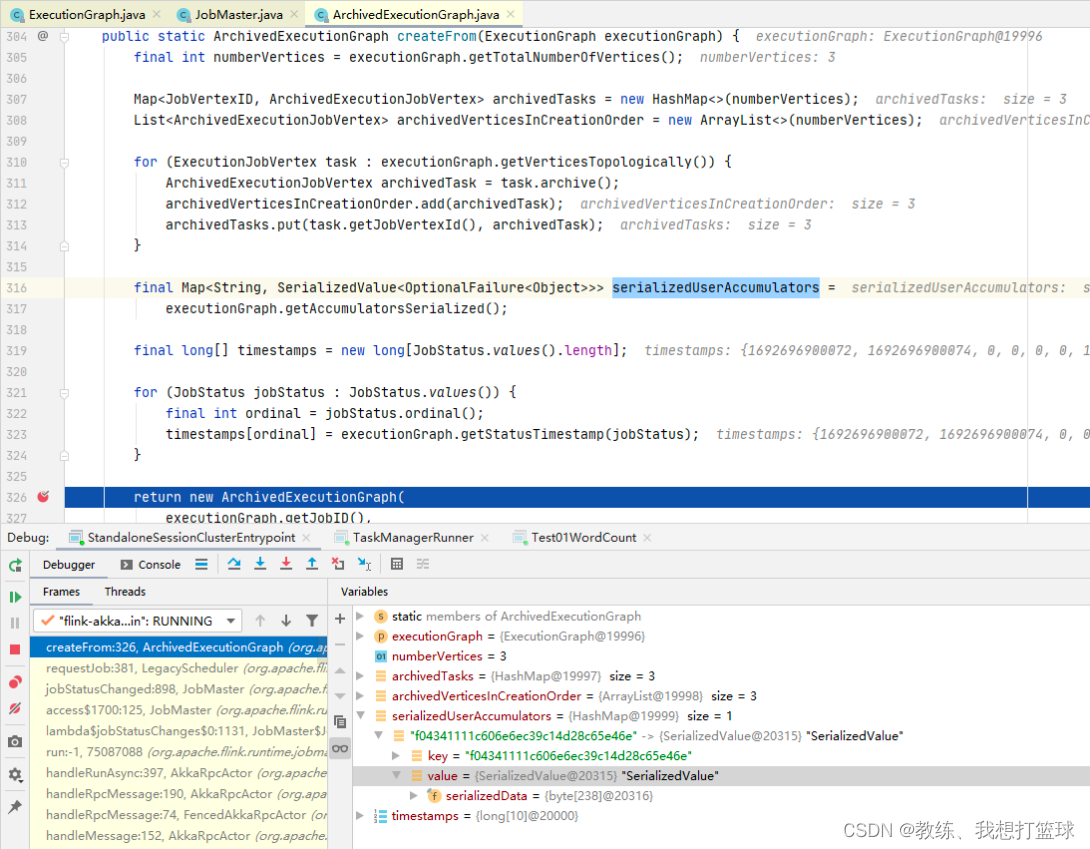
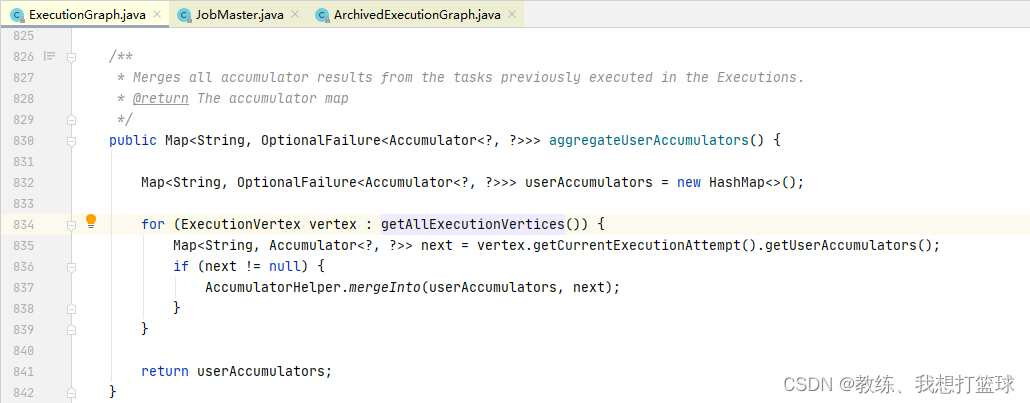
然后 executionGraph.getAccumulatorsSerialized 遍历的基础 accumulatos 是来自于如下, 可以看到的是遍历的当前执行计划的所有的 Vertex 的 accumulators
然后 结合上上一张图可以看到的是 这里是从 vertex.attempt 中获取的数据, 然后 vertex.attempt 的数据是来自于 ExecutionGraph.updateStateInternal
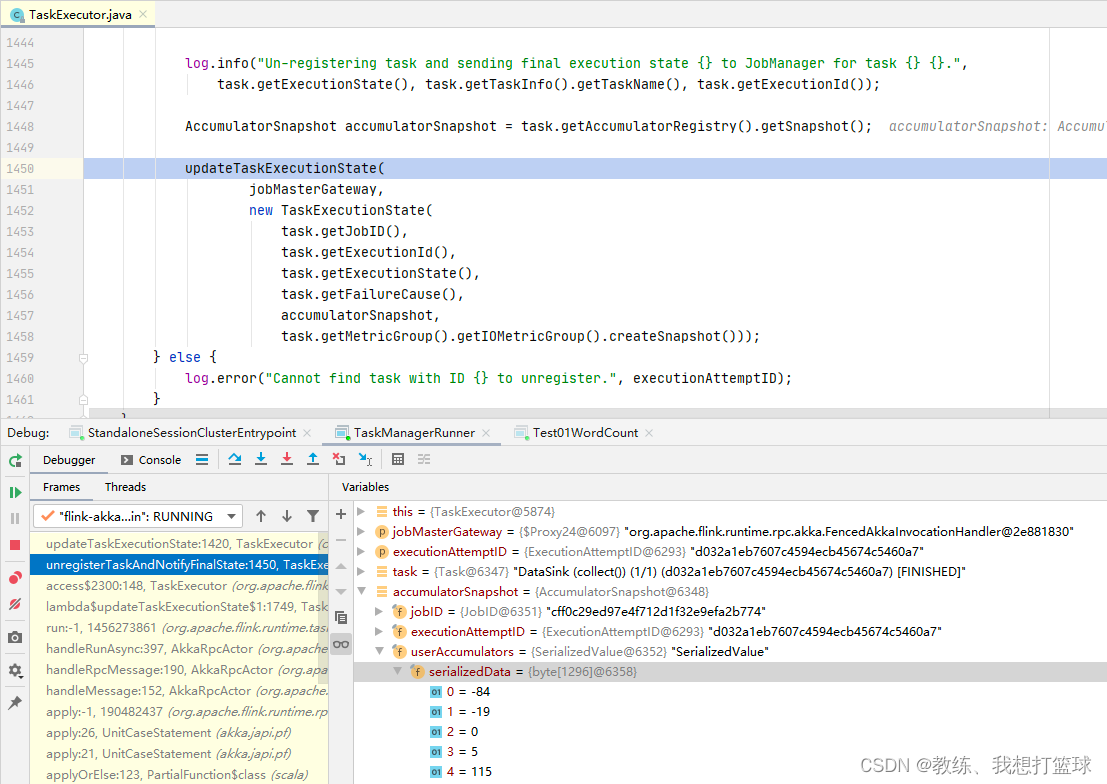
然后外层 JobMaster.jobStatusChanged 将这上面生成的 ArchivedExecutionGraph 设置到了 JobManagerRunner.resultFuture 中
Task 这边, 任务执行完成之后, 将 accumulators 封装到 TaskExecutionState, 然后响应给 JobMaster
完
相关文章:
05 Flink 的 WordCount
前言 本文对应于 spark 系列的 Spark 的 WordCount 这里主要是 从宏观上面来看一下 flink 这边的几个角色, 以及其调度的整个流程 一个宏观 大局上的任务的处理, 执行 基于 一个本地的 flink 集群 测试用例 /*** com.hx.test.Test01WordCount** author Jerry.X.He* ver…...
2024云服务器ECS_云主机_服务器托管_e实例-阿里云
阿里云服务器ECS英文全程Elastic Compute Service,云服务器ECS是一种安全可靠、弹性可伸缩的云计算服务,阿里云提供多种云服务器ECS实例规格,如ECS经济型e实例、通用算力型u1、ECS计算型c7、通用型g7、GPU实例等,阿里云服务器网al…...
掌握这8大工具,自媒体ai写作之路畅通无阻! #经验分享#科技#媒体
这些宝藏AI 写作神器,我不允许你还不知道~国内外免费付费都有,还有AI写作小程序分享,大幅度提高写文章、写报告的效率,快来一起试试吧! 1.元芳写作 这是一个微信公众号 面向专业写作领域的ai写作工具,写作…...
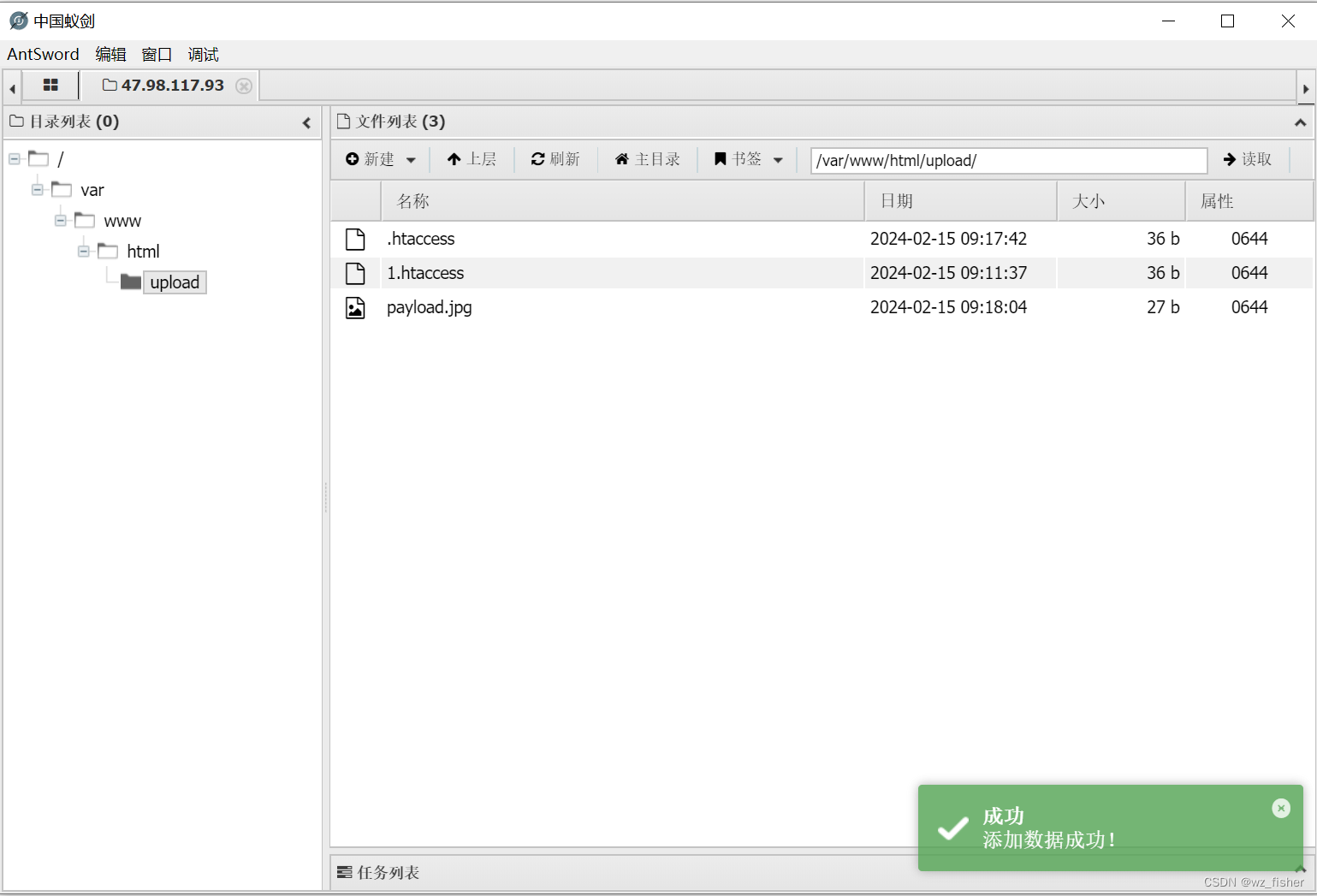
CTFHub技能树web之文件上传(一)
一.前置知识 文件上传漏洞:文件上传功能是许多Web应用程序的常见功能之一,但在实施不当的情况下,可能会导致安全漏洞。文件上传漏洞的出现可能会使攻击者能够上传恶意文件,执行远程代码,绕过访问控制等。 文件类型验证…...

蔚来面试解答
你的问题包含了多个方面,我会尽力逐一回答: 锁机制及锁膨胀过程: 锁机制是并发编程中用于控制多线程对共享资源访问的一种机制,以避免资源冲突导致的数据不一致问题。锁膨胀是指锁在运行时根据竞争情况可以升级的过程,…...

Springboot 中使用 Redisson+AOP+自定义注解 实现访问限流与黑名单拦截
🏷️个人主页:牵着猫散步的鼠鼠 🏷️系列专栏:Java全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...
Java使用企业邮箱发送预警邮件
前言:最近接到一个需求,需要根据所监控设备的信息,在出现问题时发送企业微信进行预警。 POM依赖 <!-- 邮件 --> <dependency><groupId>com.sun.mail</groupId><artifactId>jakarta.mail</artifactId>…...
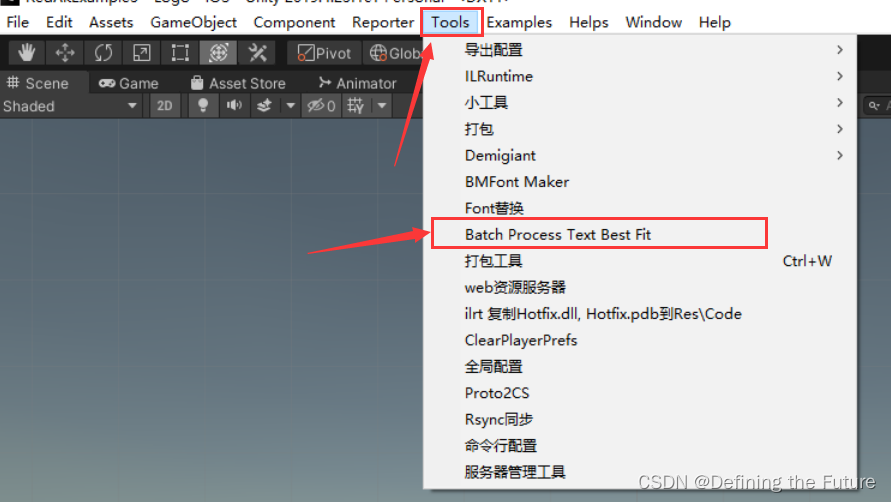
Unity编辑器扩展之是否勾选Text组件BestFit选项工具(此篇教程也可以操作其他组件的属性)
想要批量化是否勾选项目预制体资源中Text组件BestFit属性(此篇教程也可以操作其他组件的属性,只不过需要修改其中对应的代码),可以采用以下步骤。 1、在项目的Editor文件中,新建一个名为TextBestFitBatchProcessor的…...

分布式场景怎么Join | 京东云技术团队
背景 最近在阅读查询优化器的论文,发现System R中对于Join操作的定义一般分为了两种,即嵌套循环、排序-合并联接。在原文中,更倾向使用排序-合并联接逻辑。 考虑到我的领域是在处理分库分表或者其他的分区模式,这让我开始不由得…...

24-k8s的附件组件-Metrics-server组件与hpa资源pod水平伸缩
一、概述 Metrics-Server组件目的:获取集群中pod、节点等负载信息; hpa资源目的:通过metrics-server获取的pod负载信息,自动伸缩创建pod; 参考链接: 资源指标管道 | Kubernetes https://github.com/kuberne…...
)
Spring RabbitMQ 配置多个虚拟主机(vhost)
文章目录 前言一、相关文章二、相关代码1.yml文件配置2.RabbitMq配置类3.接收MQ消息前言 在日常开发中,同时需要用到RabbitMQ多个虚拟机(vhost)。应用场景:需要接收多个交换机的数据,而交换机都在不同的虚拟机(vhost) 一、相关文章 Docker安装RabbitMQ 【SpringCloud…...
「Qt Widget中文示例指南」如何实现文档查看器?(一)
Qt 是目前最先进、最完整的跨平台C开发工具。它不仅完全实现了一次编写,所有平台无差别运行,更提供了几乎所有开发过程中需要用到的工具。如今,Qt已被运用于超过70个行业、数千家企业,支持数百万设备及应用。 文档查看器是一个显…...
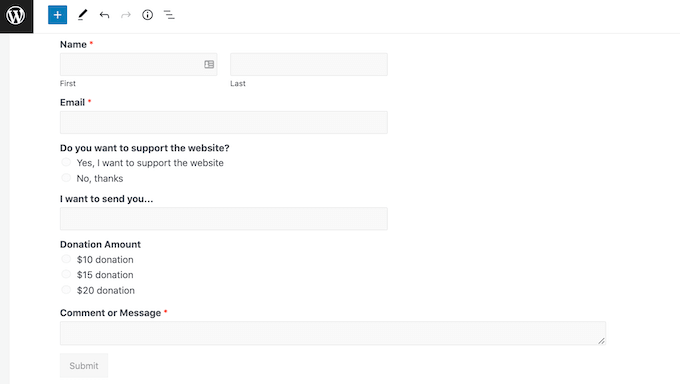
如何创建WordPress付款表单(简单方法)
您是否正在寻找一种简单的方法来创建付款功能WordPress表单? 小企业主通常需要创建一种简单的方法来在其网站上接受付款,而无需设置复杂的购物车。简单的付款表格使您可以轻松接受自定义付款金额、设置定期付款并收集自定义详细信息。 在本文中&#x…...
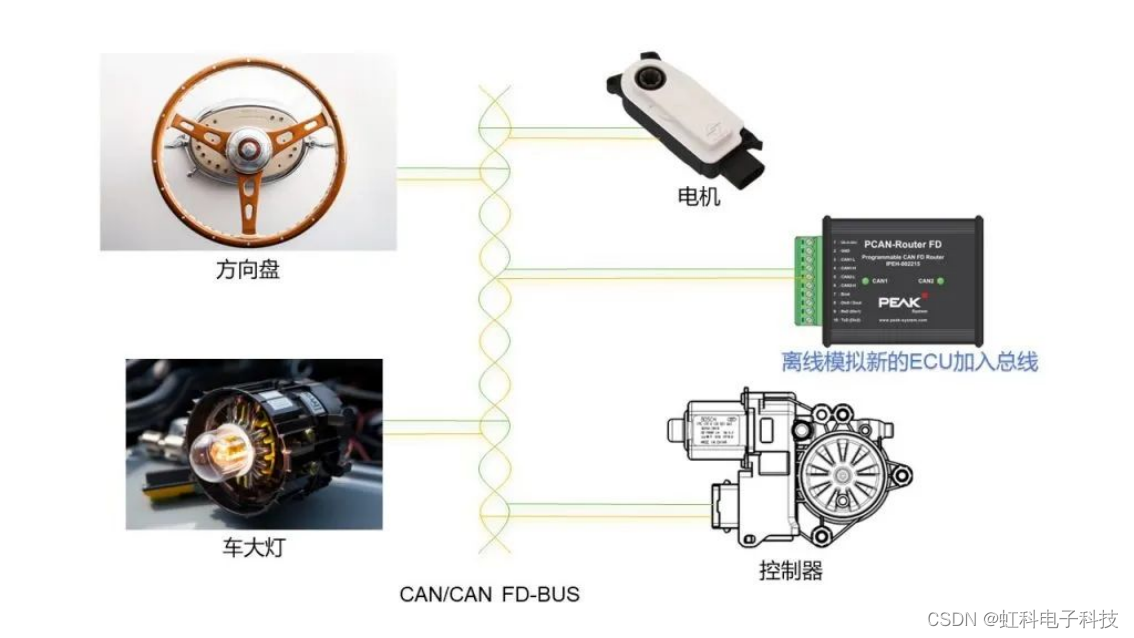
虹科方案 | 释放总线潜力:汽车总线离线模拟解决方案
来源:虹科汽车智能互联 虹科方案 | 释放总线潜力:汽车总线离线模拟解决方案 原文链接:https://mp.weixin.qq.com/s/KGv2ZOuQMLIXlOiivvY6aQ 欢迎关注虹科,为您提供最新资讯! #汽车总线 #ECU #汽车网关 导读 传统的…...

欲速则不达,慢就是快!
引言 随着生活水平的提高,不少人的目标从原先的解决温饱转变为追求内心充实,但由于现在的时间过得越来越快以及其他外部因素,我们对很多东西的获取越来越没耐心,例如书店经常会看到《7天精通Java》、《3天掌握XXX》等等之类的书籍…...

ubuntu22.04@Jetson OpenCV安装
ubuntu22.04Jetson OpenCV安装 1. 源由2. 分析3. 证实3.1 jtop安装3.2 jtop指令3.3 GPU支持情况 4. 安装OpenCV4.1 修改内容4.2 Python2环境【不需要】4.3 ubuntu22.04环境4.4 国内/本地环境问题4.5 cudnn版本问题 5. 总结6. 参考资料 1. 源由 昨天用Jetson跑demo程序发现帧率…...
OpenGL学习——17.模型
前情提要:本文代码源自Github上的学习文档“LearnOpenGL”,我仅在源码的基础上加上中文注释。本文章不以该学习文档做任何商业盈利活动,一切著作权归原作者所有,本文仅供学习交流,如有侵权,请联系我删除。L…...

6.2 数据库
本节介绍Android的数据库存储方式--SQLite的使用方法,包括:SQLite用到了哪些SQL语法,如何使用数据库管理操纵SQLitem,如何使用数据库帮助器简化数据库操作,以及如何利用SQLite改进登录页面的记住密码功能。 6.2.1 SQ…...

计算机设计大赛 深度学习人体跌倒检测 -yolo 机器视觉 opencv python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习的人体跌倒检测算法研究与实现 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🥇学长这里给一个题目综合评分(每项满…...

本地模拟发送、接收RabbitMQ数据
文章目录 前言一、相关文章二、相关代码1.模拟的 Channel 类2.接收消息3.模拟推送MQ数据前言 日常开发中,当线上RabbitMQ坏境还没准备好时,可在本地模拟发送、接收消息 一、相关文章 Docker安装RabbitMQ 【SpringCloud】整合RabbitMQ六大模式应用(入门到精通) Spring R…...

如何在15分钟内完成Windows系统优化和软件批量安装:WinUtil完全指南
如何在15分钟内完成Windows系统优化和软件批量安装:WinUtil完全指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否曾为新…...

2026网盘怎么选:别只盯“不限速”,更该看同步稳定性与数据安全
很多人换网盘的导火索是“限速”,但真正拉开体验差距的,往往是:同步是否稳定、复杂网络下是否容易失败、多人协作有没有权限与版本控制、数据安全与合规是否站得住脚。下面这篇不再只比较“快不快”,而是用更贴近长期使用的维度&a…...

我用AI一周做了个口播视频平台,现在开源了
做独立开发这两年,我一直在想一个问题:一个人到底能做到什么程度? 上周我给出了自己的答案——我用 DeepSeek 定义需求 CodeBuddy 辅助编码,一个人从零搞了一个 AI 口播视频生成平台,取名智播坊。输入文案࿰…...

移动端部署福音?YOLOv5结合EfficientNetV2主干网络的轻量化改造与性能实测
YOLOv5与EfficientNetV2融合:移动端目标检测的轻量化实践 在移动端和边缘计算设备上部署目标检测模型始终面临计算资源有限、功耗敏感等挑战。本文将深入探讨如何通过将YOLOv5与EfficientNetV2主干网络结合,构建一个真正适合嵌入式设备的轻量化目标检测…...

LeetCode 409:最长回文串 | 哈希表统计字符频率
LeetCode 409:最长回文串 | 哈希表统计字符频率 引言 最长回文串(Longest Palindrome)是 LeetCode 第 409 题,难度为 Easy。题目要求在给定字符串中构造最长的回文串,返回其长度。这道题虽然简单,但蕴含了回…...

uView 2.0性能优化终极秘籍:按需引入与打包体积精简完整教程
uView 2.0性能优化终极秘籍:按需引入与打包体积精简完整教程 【免费下载链接】uView2.0 uView UI,是全面兼容nvue的uni-app生态框架,全面的组件和便捷的工具会让您信手拈来,如鱼得水 项目地址: https://gitcode.com/gh_mirrors/…...

深度解析游戏资源加密机制:构建安全增强模块的完整实现
深度解析游戏资源加密机制:构建安全增强模块的完整实现 【免费下载链接】wuwa-mod Wuthering Waves pak mods 项目地址: https://gitcode.com/GitHub_Trending/wu/wuwa-mod WuWa-Mod作为《鸣潮》(Wuthering Waves)游戏模组开发项目,通过AES加密解…...

交互式振动传感器工作原理
交互式振动传感器通过实时采集机械振动数据,结合无线通信与智能算法,实现设备状态监测与预警反馈。 其工作原理基于以下核心环节:一、核心工作流程振动感知:传感器元件:采用MEMS三轴加速度计(如ADXL3…...

原神帧率解锁工具:如何安全突破60FPS限制获得流畅体验
原神帧率解锁工具:如何安全突破60FPS限制获得流畅体验 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 《原神》作为一款画面精美的开放世界游戏,默认的60FPS帧率限…...

如何快速掌握DLSS Swapper:游戏性能优化终极指南
如何快速掌握DLSS Swapper:游戏性能优化终极指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾经因为游戏中的DLSS版本过时而无法享受最新的性能提升?或者新版本DLSS导致游戏闪退让你…...