分布式场景怎么Join | 京东云技术团队
背景
最近在阅读查询优化器的论文,发现System R中对于Join操作的定义一般分为了两种,即嵌套循环、排序-合并联接。在原文中,更倾向使用排序-合并联接逻辑。
考虑到我的领域是在处理分库分表或者其他的分区模式,这让我开始不由得联想我们怎么在分布式场景应用这个Join逻辑,对于两个不同库里面的不同表我们是没有办法直接进行Join操作的。查阅资料后发现原来早有定义,即分布式联接算法。
分布式联接算法
跨界点处理数据即分布式联接算法,常见的有四种模型:Shuffle Join(洗牌联接)、Broadcast Join(广播联接)、MapReduce Join(MapReduce联接)、Sort-Merge Join(排序-合并联接)。
接下来将进行逐一了解与分析,以便后续开发的应用。
Shuffle Join(洗牌联接)
先上原理解释:
Shuffle Join的核心思想是将来自不同节点的数据重新分发(洗牌),使得可以联接的数据行最终位于同一个节点上。 通常,对于要联接的两个表,会对联接键应用相同的哈希函数,哈希函数的结果决定了数据行应该被发送到哪个节点。这样,所有具有相同哈希值的行都会被送到同一个节点,然后在该节点上执行联接操作。
可能解释完还是有点模糊,举个例子,有两张表,分别以id字段进行分库操作,且哈希算法相同(为了简单,这里只介绍分库场景,分库分表同理。算法有很多种,这里举例是hash算法),那么这两张表的分片或许可以在同一个物理库中,这样我们不需要做大表维度的处理,我们可以直接下推Join操作到对应的物理库操作即可。
在ShardingSphere中,这种场景类似于绑定表的定义,如果两张表的算法相同,可以直接配置绑定表的关系,进行相同算法的连接查询,避免复杂的笛卡尔积。
这样做的好处是可以尽量下推到数据库操作,在中间件层面我们可以做并行处理,适合大规模的数据操作。
但是,这很理想,有多少表会采用相同算法处理呢。
Broadcast Join(广播联接)
先上原理解释:
当一个表的大小相对较小时,可以将这个小表的全部数据广播到所有包含另一个表数据的节点上。 每个节点上都有小表的完整副本,因此可以独立地与本地的大表数据进行联接操作,而不需要跨节点通信。
举个例子,有一张非常小的表A,还有一张按照ID分片的表B,我们可以在每一个物理库中复制一份表A,这样我们的Join操作就可以直接下推到每一个数据库操作了。
这种情况比Shuffle Join甚至还有性能高效,这种类似于ShardingSphere中的广播表的定义,其存在类似于字典表,在每一个数据库都同时存在一份,每次写入会同步到多个节点。
这种操作的好处显而易见,不仅支持并行操作而且性能极佳。
但是缺点也显而易见,如果小表不够小数据冗余不说,广播可能会消耗大量的网络带宽和资源。
MapReduce Join(MapReduce联接)
先上原理解释:
MapReduce是一种编程模型,用于处理和生成大数据集,其中的联接操作可以分为两个阶段:Map阶段和Reduce阶段。 Map阶段:每个节点读取其数据分片,并对需要联接的键值对应用一个映射函数,生成中间键值对。 Reduce阶段: 中间键值对会根据键进行排序(在某些实现中排序发生在Shuffle阶段)和分组,然后发送到Reduce节点。 在Reduce节点上,具有相同键的所有值都会聚集在一起,这时就可以执行联接操作。
MapReduce Join不直接应用于传统数据库逻辑,而是适用于Hadoop这样的分布式处理系统中。但是为了方便理解,还是用SQL语言来分析,例如一条SQL:
SELECT orders.order_id, orders.date, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id;
会被转换为两个SQL:
SELECT customer_id, order_id, date FROM orders;
SELECT customer_id, name FROM customers;
这个过程就是Map阶段,即读取orders和customers表的数据,并为每条记录输出键值对,键是customer_id,值是记录的其余部分。
下一个阶段可有可无,即Shuffle阶段。如果不在这里排序可能会在Map阶段执行SQL时候排序/分组或者在接下来的Reduce阶段进行额外排序/分组。在这个阶段主要将收集到的数据按照customer_id排序分组,以确保相同的customer_id的数据达到Reduce阶段。
Reduce阶段将每个对应的customer_id进行联接操作,输出并返回最后的结果。
这种操作普遍应用于两个算法完全不相同的表单,也是一种标准的处理模型,在这个过程中,我们以一张逻辑表的维度进行操作。这种算法可能会消耗大量内存,甚至导致内存溢出,并且在处理大数据量时会相当耗时,因此不适合需要低延迟的场景。
额外补充
内存溢出场景普遍在如下场景:
1.大键值对数量:如果Map阶段产生了大量的键值对,这些数据需要在内存中进行缓存以进行排序和传输,这可能会消耗大量内存。
2.数据倾斜:如果某个键非常常见,而其他键则不那么常见,那么处理这个键的Reducer可能会接收到大量的数据,导致内存不足。这种现象称为数据倾斜。
3.大值列表:在Reduce阶段,如果某个键对应的值列表非常长,处理这些值可能会需要很多内存。
4.不合理的并行度:如果Reduce任务的数量设置得不合适(太少或太多),可能会导致单个任务处理不均匀,从而导致内存问题。
我能想到的相应解决方案:
•内存到磁盘的溢写:当Map任务的输出缓冲区满了,它会将数据溢写到磁盘。这有助于限制内存使用,但会增加I/O开销。
•通过设置合适的Map和Reduce任务数量,可以更有效地分配资源,避免某些任务过载。具体操作可以将Map操作的分段比如1~100,100~200,Reduce阶段开设较少的并发处理。
•优化数据分布,比如使用范围分区(range partitioning)或哈希分区(hash partitioning)来减少数据倾斜。
Sort-Merge Join(排序-合并联接)
先上原理解释:
在分布式环境中,Sort-Merge Join首先在每个节点上对数据进行局部排序,然后将排序后的数据合并起来,最后在合并的数据上执行联接操作。 这通常涉及到多阶段处理,包括局部排序、数据洗牌(重新分发),以及最终的排序和合并。
举个理解,还是上面的SQL。
SELECT orders.order_id, orders.date, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id;
1.对orders表按customer_id进行排序。
2.对customers表按customer_id进行排序。
3.同时遍历两个已排序的表,将具有相同customer_id的行配对。
这个就有点类似于原生的排序-合并联接了。也是数据库场景的标准处理办法。
对于已经排序的数据集或数据分布均匀的情况,这种方法非常有效。如果数据未预先排序,这种方法可能会非常慢,因为它要求数据在联接之前进行排序。
当然,这个算法也会造成内存溢出的场景,解决方案如下:
1.当数据集太大而无法一次性加载到内存中时,可以使用外部排序算法。外部排序算法会将数据分割成多个批次,每个批次单独排序,然后将排序后的批次合并。这种方法通常涉及到磁盘I/O操作,因此会比内存中操作慢。
2.对于合并步骤,可以使用流式处理技术,一次只处理数据的一小部分,并持续将结果输出到下一个处理步骤或存储系统。这样可以避免一次性加载大量数据到内存中。
3.当内存不足以处理数据时,可以使用磁盘空间作为临时存储。数据库管理系统通常有机制来处理内存溢出,比如创建磁盘上的临时文件来存储过程中的数据。
4.在分布式系统中,可以将数据分散到多个节点上进行处理,这样每个节点只需要处理数据的一部分,从而减少单个节点上的内存压力。
作者:京东科技 张俊杰
来源:京东云开发者社区 转载请注明来源
相关文章:

分布式场景怎么Join | 京东云技术团队
背景 最近在阅读查询优化器的论文,发现System R中对于Join操作的定义一般分为了两种,即嵌套循环、排序-合并联接。在原文中,更倾向使用排序-合并联接逻辑。 考虑到我的领域是在处理分库分表或者其他的分区模式,这让我开始不由得…...

24-k8s的附件组件-Metrics-server组件与hpa资源pod水平伸缩
一、概述 Metrics-Server组件目的:获取集群中pod、节点等负载信息; hpa资源目的:通过metrics-server获取的pod负载信息,自动伸缩创建pod; 参考链接: 资源指标管道 | Kubernetes https://github.com/kuberne…...
)
Spring RabbitMQ 配置多个虚拟主机(vhost)
文章目录 前言一、相关文章二、相关代码1.yml文件配置2.RabbitMq配置类3.接收MQ消息前言 在日常开发中,同时需要用到RabbitMQ多个虚拟机(vhost)。应用场景:需要接收多个交换机的数据,而交换机都在不同的虚拟机(vhost) 一、相关文章 Docker安装RabbitMQ 【SpringCloud…...
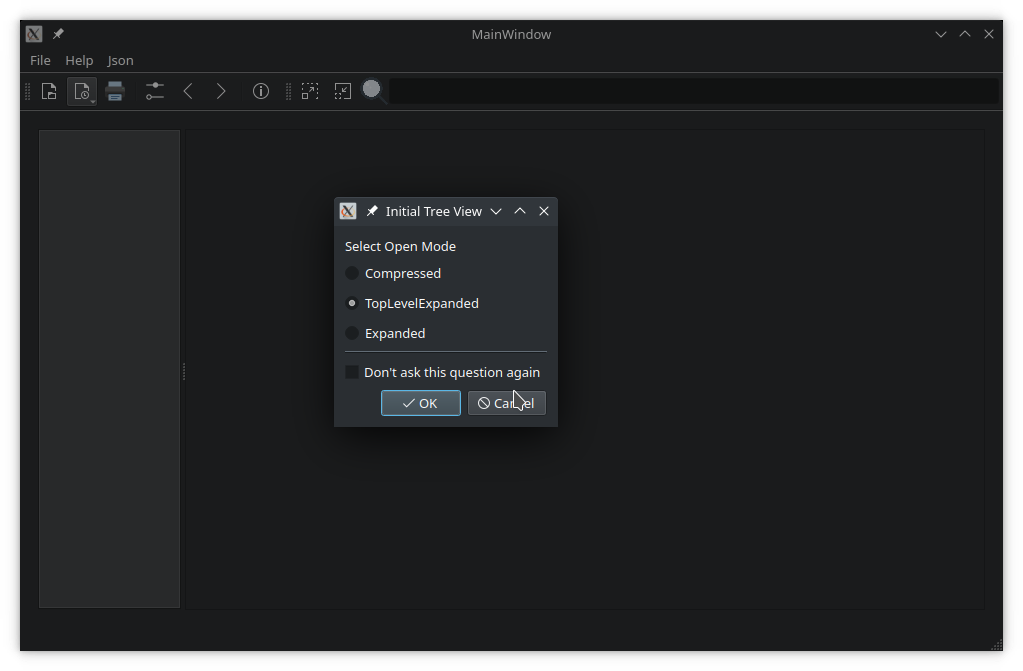
「Qt Widget中文示例指南」如何实现文档查看器?(一)
Qt 是目前最先进、最完整的跨平台C开发工具。它不仅完全实现了一次编写,所有平台无差别运行,更提供了几乎所有开发过程中需要用到的工具。如今,Qt已被运用于超过70个行业、数千家企业,支持数百万设备及应用。 文档查看器是一个显…...
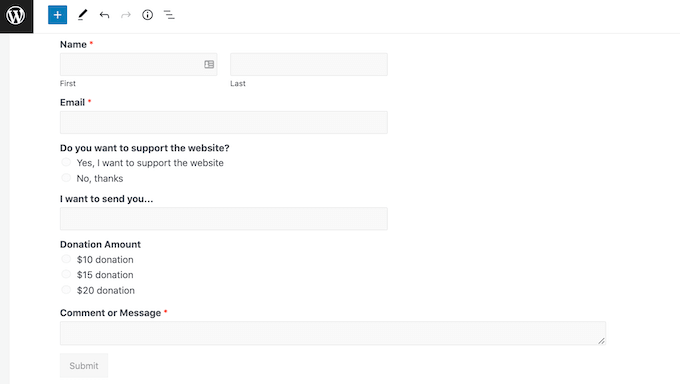
如何创建WordPress付款表单(简单方法)
您是否正在寻找一种简单的方法来创建付款功能WordPress表单? 小企业主通常需要创建一种简单的方法来在其网站上接受付款,而无需设置复杂的购物车。简单的付款表格使您可以轻松接受自定义付款金额、设置定期付款并收集自定义详细信息。 在本文中&#x…...
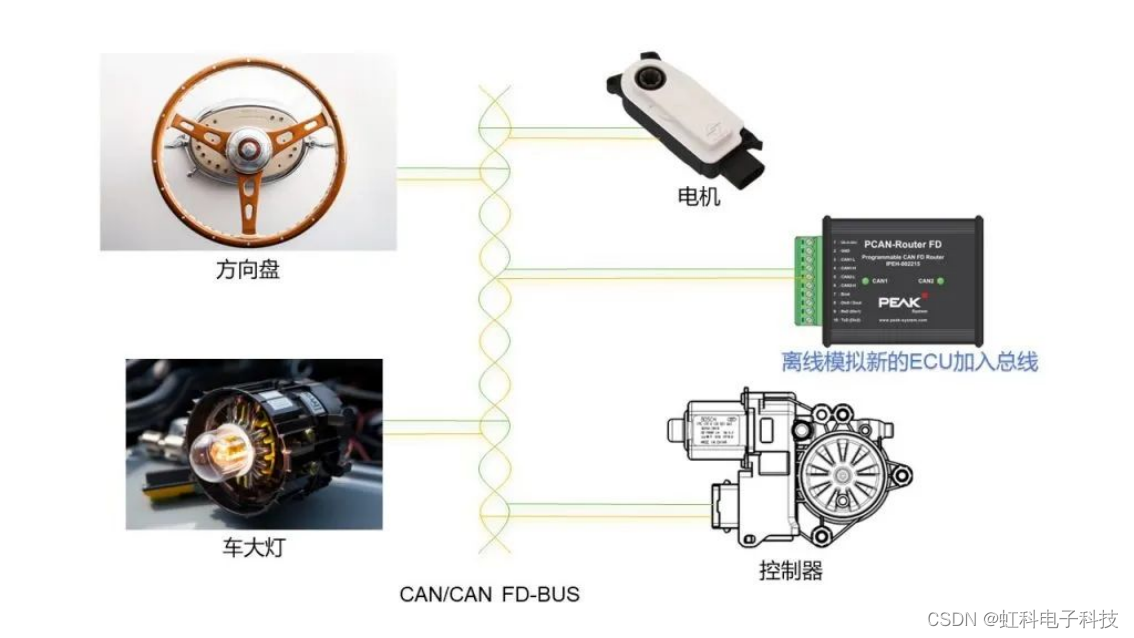
虹科方案 | 释放总线潜力:汽车总线离线模拟解决方案
来源:虹科汽车智能互联 虹科方案 | 释放总线潜力:汽车总线离线模拟解决方案 原文链接:https://mp.weixin.qq.com/s/KGv2ZOuQMLIXlOiivvY6aQ 欢迎关注虹科,为您提供最新资讯! #汽车总线 #ECU #汽车网关 导读 传统的…...

欲速则不达,慢就是快!
引言 随着生活水平的提高,不少人的目标从原先的解决温饱转变为追求内心充实,但由于现在的时间过得越来越快以及其他外部因素,我们对很多东西的获取越来越没耐心,例如书店经常会看到《7天精通Java》、《3天掌握XXX》等等之类的书籍…...

ubuntu22.04@Jetson OpenCV安装
ubuntu22.04Jetson OpenCV安装 1. 源由2. 分析3. 证实3.1 jtop安装3.2 jtop指令3.3 GPU支持情况 4. 安装OpenCV4.1 修改内容4.2 Python2环境【不需要】4.3 ubuntu22.04环境4.4 国内/本地环境问题4.5 cudnn版本问题 5. 总结6. 参考资料 1. 源由 昨天用Jetson跑demo程序发现帧率…...
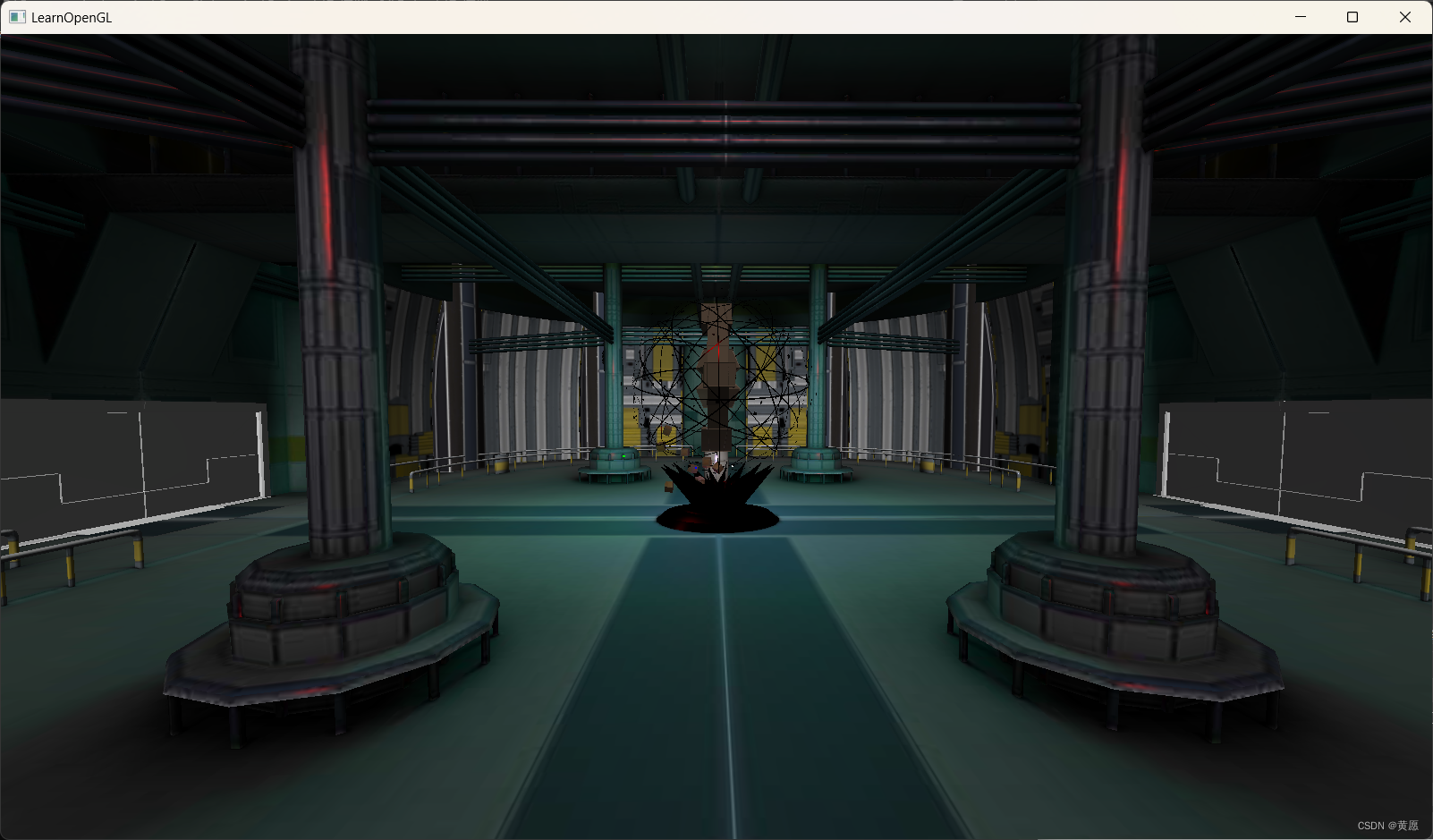
OpenGL学习——17.模型
前情提要:本文代码源自Github上的学习文档“LearnOpenGL”,我仅在源码的基础上加上中文注释。本文章不以该学习文档做任何商业盈利活动,一切著作权归原作者所有,本文仅供学习交流,如有侵权,请联系我删除。L…...

6.2 数据库
本节介绍Android的数据库存储方式--SQLite的使用方法,包括:SQLite用到了哪些SQL语法,如何使用数据库管理操纵SQLitem,如何使用数据库帮助器简化数据库操作,以及如何利用SQLite改进登录页面的记住密码功能。 6.2.1 SQ…...

计算机设计大赛 深度学习人体跌倒检测 -yolo 机器视觉 opencv python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习的人体跌倒检测算法研究与实现 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🥇学长这里给一个题目综合评分(每项满…...

本地模拟发送、接收RabbitMQ数据
文章目录 前言一、相关文章二、相关代码1.模拟的 Channel 类2.接收消息3.模拟推送MQ数据前言 日常开发中,当线上RabbitMQ坏境还没准备好时,可在本地模拟发送、接收消息 一、相关文章 Docker安装RabbitMQ 【SpringCloud】整合RabbitMQ六大模式应用(入门到精通) Spring R…...
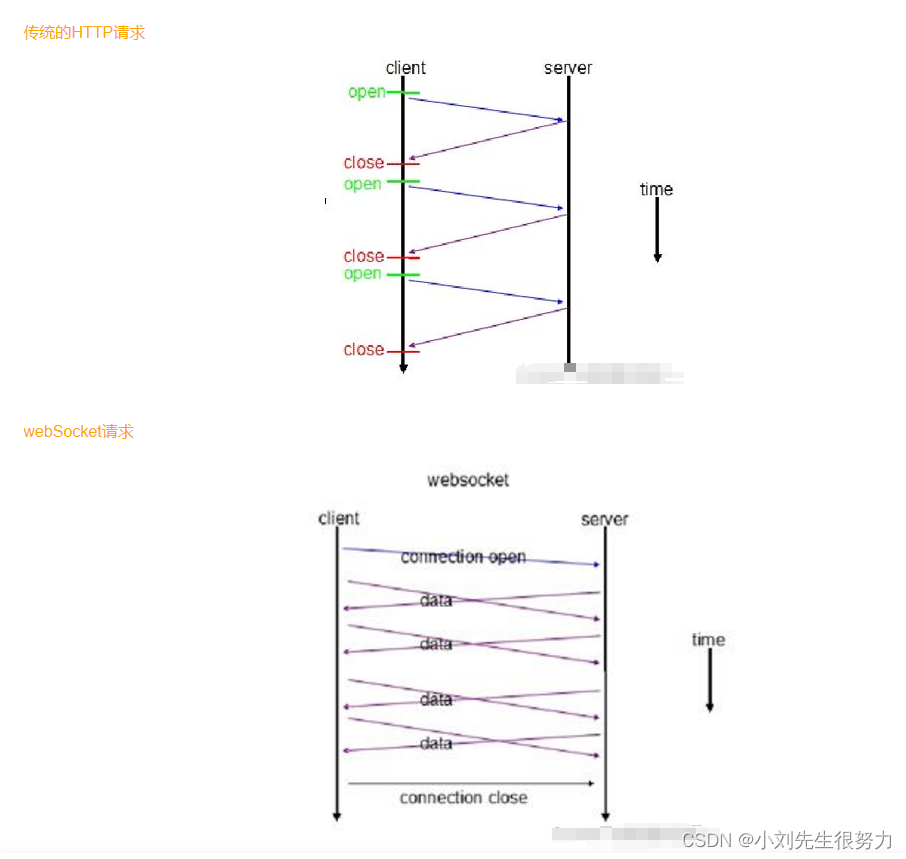
前端 webSocket 的使用
webSocket使用 注意要去监听websocket 对象事件,处理我们需要的数据 我是放在了最外层的index 内,监听编辑状态,去触发定义的方法。因为我这个项目是组件化开发,全部只有一个总编辑按钮,我只需监听是否触发了编辑即可…...

opencv图像处理(一)
一. OpenCV 简介 OpenCV 是一个跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。 应用领域 1、人机互动 2、物体识别 3、图像分割 4、人脸识别 5、动作识别 6、运动跟踪 7、机器人 8、运动分析 9、机器视觉 10、…...
消息队列-RabbitMQ:workQueues—工作队列、消息应答机制、RabbitMQ 持久化、不公平分发(能者多劳)
4、Work Queues Work Queues— 工作队列 (又称任务队列) 的主要思想是避免立即执行资源密集型任务,而不得不等待它完成。我们把任务封装为消息并将其发送到队列,在后台运行的工作进程将弹出任务并最终执行作业。当有多个工作线程时,这些工作…...

前端秘法基础式(HTML)(第二卷)
目录 一.表单标签 1.表单域 2.表单控件 2.1input标签 2.2label/select/textarea标签 2.3无语义标签 三.特殊字符 一.表单标签 用来完成与用户的交互,例如登录系统 1.表单域 <form>通过action属性,将用户填写的数据转交给服务器 2.表单控件 2.1input标签 type…...

PTA-统计英文字母和数字字符[2]
本题要求编写程序,输入N个字符,统计其中英文字母、数字字符和其他字符的个数。 输入格式: 输入在第一行中给出正整数N,第二行输入N个字符,最后一个回车表示输入结束,不算在内。 输出格式: 在一行内按照 letter 英…...

Elasticsearch:将 IT 智能和业务 KPI 与 AI 连接起来 - 房间里的大象
作者:Fermi Fang 大象寓言的智慧 在信息技术和商业领导力的交叉点,蒙眼人和大象的古老寓言提供了一个富有洞察力的类比。 这个故事起源于印度次大陆,讲述了六个蒙住眼睛的人第一次遇到大象的故事。 每个人触摸大象的不同部位 —— 侧面、象牙…...
基于芯驰 X9HP PTG4.1 在 yocto 中添加 Linux 应用
1.参考例程并添加应用 1.1 参考例程 (1)查看自带的串口测试例程 uart_test ,查看 bb 文件怎么写的。 1.2 添加 printf-test 应用 (1)在 yocto/meta-semidrive/recipes-bsp/ 目录中 copy 自带例程 uart-test 改名为 …...

【微服务安全】OpenID Connect 简介:现代应用程序的身份验证
OpenID Connect (OIDC) 是一个建立在 OAuth 2.0 之上的开放身份验证协议。它简化了应用程序以一种标准化和可互操作的方式验证用户身份并获取其基本个人资料信息的方式。可以将其视为应用程序“知道你是谁”的一种安全方式,而无需你创建单独的帐户或透露你的密码。 …...
:谁制造了“诸侯”?)
集团总部失控(二):谁制造了“诸侯”?
集团管控失灵,常见的归因是子公司“不听话”“各自为政”“挑战规则”。这些现象确实存在,但若深究其根源,往往会发现:子公司的问题只是表层,更深层的原因埋藏在总部自身的治理逻辑与管理方式中。 一、历史形成的权威…...

Mac Mouse Fix:3步让你的普通鼠标超越苹果触控板体验
Mac Mouse Fix:3步让你的普通鼠标超越苹果触控板体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾为macOS上鼠标功能受限…...

网络安全自学顺序|千万不要搞反了
网络安全自学顺序|千万不要搞反了 想入行网络安全?别瞎学!这帮你少走半年弯路👇 从0到1进阶路径(按顺序学): 1.计算机网络基础(TCP/IP、OSI模型) 2.Linux系统与命令行…...

东南大学论文模板终极指南:3步搞定毕业设计排版难题
东南大学论文模板终极指南:3步搞定毕业设计排版难题 【免费下载链接】SEUThesis 东南大学论文模板 项目地址: https://gitcode.com/gh_mirrors/seu/SEUThesis 对于每一位东南大学的学子来说,毕业季最头疼的往往不是论文内容本身,而是繁…...

如何在浏览器中零安装查看SQLite数据库?完全指南
如何在浏览器中零安装查看SQLite数据库?完全指南 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer 你是否曾遇到过这样的情况:收到一个SQLite数据库文件需要快速查看…...

如何告别网盘限速?9大主流平台直链解析完整指南
如何告别网盘限速?9大主流平台直链解析完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 /…...

创业团队如何建立技术文化
创业团队如何建立技术文化 前言 我们团队从3个人发展到10个人,文化问题开始凸显: 有人觉得应该追求代码完美,有人觉得快速上线更重要有人喜欢加班赶进度,有人坚持 Work-Life Balance有人保守求稳,有人激进创新 后来我意…...

Wedding-website开发者指南:理解项目架构与代码实现原理
Wedding-website开发者指南:理解项目架构与代码实现原理 【免费下载链接】wedding-website Our Wedding Website 👫 项目地址: https://gitcode.com/gh_mirrors/we/wedding-website Wedding-website是一个专为婚礼设计的开源网站项目,…...

免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南
免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ࿰…...

8. Python 模块与包 深度解析
Python 模块与包 深度解析 目录 模块与包的概念模块基础 2.1 模块即 .py 文件2.2 import 语句与 from ... import2.3 模块搜索路径 sys.path 模块的编译与缓存包 4.1 常规包与 __init__.py4.2 命名空间包4.3 相对导入与绝对导入 __name__ 与 "__main__"模块与包的组…...