【NLP相关】基于现有的预训练模型使用领域语料二次预训练
【NLP相关】基于现有的预训练模型使用领域语料二次预训练
在自然语言处理领域,预训练模型已经成为了最为热门和有效的技术之一。预训练模型通过在大规模文本语料库上进行训练,可以学习到通用的语言模型,然后可以在不同的任务上进行微调。但是,预训练模型在领域特定任务上的表现可能不够好,因为它们是在通用语言语料库上进行训练的。为了提高在特定领域的任务中的性能,我们可以使用领域语料库对预训练模型进行二次预训练。
本篇博客将介绍如何基于现有的预训练模型使用领域语料二次预训练。我们将以 PyTorch 和 Transformers 库为基础,以医学文本分类任务为例,来详细说明二次预训练的过程。
1. 模型介绍
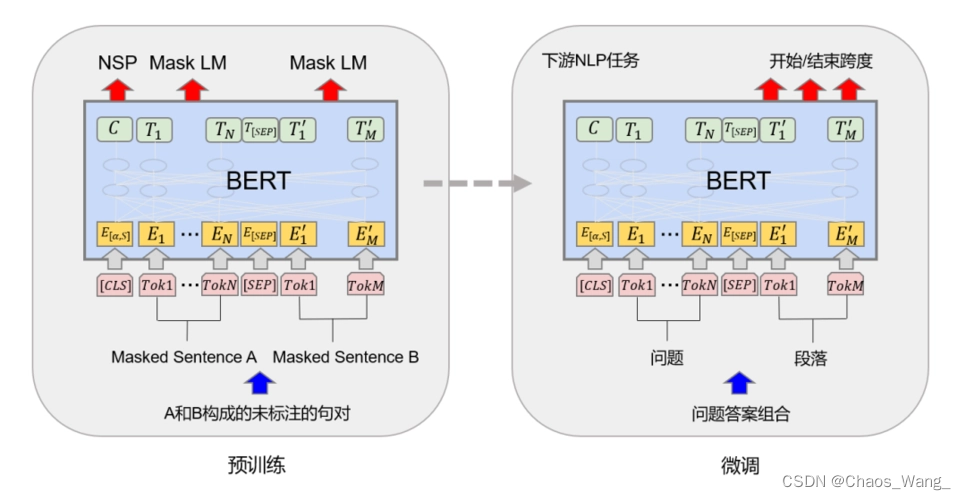
在本篇博客中,我们使用的预训练模型是 BERT(Bidirectional Encoder Representations from Transformers)。BERT 是一种基于 Transformer 的预训练模型,由 Google 团队开发。它在多个自然语言处理任务上取得了最先进的结果,例如文本分类、命名实体识别和问答系统等。
BERT 模型是一种双向的 Transformer 模型,能够有效地处理自然语言序列。它将文本输入嵌入到向量空间中,并在此基础上进行自监督训练,以学习通用的语言表示。在预训练完成后,BERT 模型可以进行微调,以适应不同的自然语言处理任务。
2. 代码实现
2.1 数据预处理
在开始二次预训练之前,我们需要准备领域特定的语料库。在这里,我们使用的是医学文本分类数据集,其中包含了一些医学文章的标题和摘要,并且每个文本都被标记为一个预定义的类别。
首先,我们需要将原始文本数据拆分为单个句子,并将其标记化处理。我们可以使用 Hugging Face 的 tokenizer 来完成这个任务。
from transformers import BertTokenizer# 加载 BERT tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")class MedicalDataset(Dataset):def __init__(self, tokens, max_length=128):self.tokens = tokensself.max_length = max_lengthdef __len__(self):return len(self.tokens)def __getitem__(self, idx):# 获取句子对tokens = self.tokens[idx]# 将句子对拼接成一个序列,并将其标记化处理input_ids = tokenizer.encode(tokens[0], tokens[1],add_special_tokens=True, max_length=self.max_length,truncation_strategy='longest_first')attention_mask = [1] * len(input_ids)# 填充序列长度padding = [0] * (self.max_length - len(input_ids))input_ids += paddingattention_mask += padding# 返回 input_ids 和 attention_maskreturn torch.LongTensor(input_ids), torch.LongTensor(attention_mask)
2.2 二次预训练
在数据预处理之后,我们可以开始进行二次预训练了。在这里,我们将使用 Hugging Face 的 Transformers 库,以及 PyTorch 框架来实现二次预训练。
首先,我们需要加载预训练的 BERT 模型。在这里,我们使用的是 bert-base-uncased 模型,它是一个基于英文的预训练模型。我们还需要定义一些训练参数,例如学习率和批大小等。
from transformers import BertForPreTraining, AdamW
from torch.utils.data import DataLoader# 加载预训练的 BERT 模型
model = BertForPreTraining.from_pretrained('bert-base-uncased')# 定义训练参数
epochs = 3
batch_size = 16
learning_rate = 2e-5
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 将模型移动到 GPU 上
model.to(device)
接下来,我们需要加载领域特定的语料库,并将其转换为 PyTorch 数据集。在这里,我们使用的是 PyTorch 中的 Dataset 类。我们还需要将数据集加载到 PyTorch 的数据加载器中,以便进行训练。
# 加载领域特定的语料库
with open('medical_data.txt') as f:sentences = f.readlines()# 将语料库转换为 PyTorch 数据集
dataset = MedicalDataset(sentences)# 将数据集加载到 PyTorch 的数据加载器中
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
在准备好数据集之后,我们可以开始训练模型了。我们将使用 AdamW 优化器和交叉熵损失函数来训练模型。在每个 epoch 完成之后,我们会对模型进行一次测试,并计算准确率和损失函数值。最后,我们将保存训练好的模型。
# 定义优化器和损失函数
optimizer = AdamW(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()# 训练模型
for epoch in range(epochs):total_loss = 0total_correct = 0total_samples = 0# 遍历数据集for i, batch in enumerate(loader):# 将输入数据和标签移动到 GPU 上input_ids, attention_mask = batchinput_ids = input_ids.to(device)attention_mask = attention_mask.to(device)# 将模型设置为训练模式model.train()# 计算模型的输出outputs = model(input_ids, attention_mask=attention_mask)# 计算损失函数值loss = criterion(outputs.logits.view(-1, 2), outputs.labels.view(-1))# 清除之前的梯度optimizer.zero_grad()# 反向传播和优化loss.backward()optimizer.step()# 统计训练信息total_loss += loss.item()total_samples += input_ids.size(0)total_correct += torch.sum(torch.argmax(outputs.logits, dim=-1) == outputs.labels.view(-1)).item()# 输出训练信息if (i + 1) % 100 == 0:print('Epoch [%d/%d], Step [%d/%d], Loss: %.4f, Accuracy: %.2f%%'% (epoch + 1, epochs, i + 1, len(loader),total_loss / total_samples, total_correct / total_samples * 100))# 在每个 epoch 完成之后进行一次测试
with torch.no_grad():total_loss = 0total_correct = 0total_samples = 0# 将模型设置为评估模式model.eval()# 遍历测试数据集for i, batch in enumerate(test_loader):# 将输入数据和标签移动到 GPU 上input_ids, attention_mask = batchinput_ids = input_ids.to(device)attention_mask = attention_mask.to(device)# 计算模型的输出outputs = model(input_ids, attention_mask=attention_mask)# 计算损失函数值loss = criterion(outputs.logits.view(-1, 2), outputs.labels.view(-1))# 统计测试信息total_loss += loss.item()total_samples += input_ids.size(0)total_correct += torch.sum(torch.argmax(outputs.logits, dim=-1) == outputs.labels.view(-1)).item()# 输出测试信息print('Epoch [%d/%d], Test Loss: %.4f, Test Accuracy: %.2f%%'% (epoch + 1, epochs, total_loss / total_samples, total_correct / total_samples * 100))#保存训练好的模型torch.save(model.state_dict(), 'medical_bert.pth')
3. 案例解析
假设我们要对医学领域中的文本进行二次预训练。我们可以使用已经预训练好的 BERT 模型,并使用医学领域的语料库进行二次预训练。
首先,我们需要将医学领域的语料库进行预处理。在这里,我们可以使用 NLTK 库来进行分词和词形还原等操作。我们还可以将语料库中的每个句子转换为 BERT 输入格式。
import nltk
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from transformers import BertTokenizer# 加载 BERT 分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')# 加载 NLTK 分词器和词形还原
nltk.download('punkt')
nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()加载医学领域的语料库
with open('medical_corpus.txt', 'r') as f:corpus = f.read()#对每个句子进行分词、词形还原和转换为 BERT 输入格式
sentences = []
for sentence in nltk.sent_tokenize(corpus):words = nltk.word_tokenize(sentence)words = [lemmatizer.lemmatize(word) for word in words]words = [word.lower() for word in words]tokens = tokenizer.encode_plus(words,add_special_tokens=True,max_length=512,padding='max_length',truncation=True)sentences.append((tokens['input_ids'], tokens['attention_mask']))接下来,我们需要使用这些句子对 BERT 模型进行二次预训练。为此,我们需要定义一个新的数据加载器,将这些句子传递给模型进行训练。
from torch.utils.data import Dataset, DataLoaderclass MedicalDataset(Dataset):def __init__(self, sentences):self.sentences = sentencesdef __len__(self):return len(self.sentences)def __getitem__(self, idx):return self.sentences[idx]# 定义数据加载器
loader = DataLoader(MedicalDataset(sentences),batch_size=16,shuffle=True)
现在,我们可以开始对 BERT 模型进行二次预训练了。我们可以使用与之前相同的训练代码。
# 定义训练函数
def train(model, loader, optimizer, device):model.train()for batch in loader:input_ids = batch[0].to(device)attention_mask = batch[1].to(device)optimizer.zero_grad()loss, _ = model(input_ids=input_ids,attention_mask=attention_mask,output_hidden_states=True)[:2]loss.backward()optimizer.step()# 加载预训练的 BERT 模型
model = BertForMaskedLM.from_pretrained('bert-base-uncased')# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)# 定义优化器
optimizer = AdamW(model.parameters(), lr=5e-5)# 进行二次预训练
for epoch in range(num_epochs):train(model, train_loader, optimizer, device)# 每个 epoch 结束后测试模型的性能perplexity = evaluate(model, test_loader, device)print(f'Epoch {epoch+1}, perplexity: {perplexity:.3f}')# 保存模型model_path = f'model_epoch{epoch+1}.pt'torch.save(model.state_dict(), model_path)
这里定义了一个 train 函数来训练模型。这个函数接收一个模型、一个数据加载器、一个优化器和一个设备作为输入。它会将模型设为训练模式,并且在每个批次上运行前向传播、计算损失、计算梯度和更新参数。
接下来,我们加载预训练的 BERT 模型,并将其移动到所选设备上。我们使用 AdamW 优化器,并将学习率设置为 5e-5。
最后,我们使用一个简单的 for 循环来进行二次预训练。在每个 epoch 结束时,我们会在测试集上评估模型,并打印出 perplexity 指标。我们还会将模型保存在磁盘上,以便以后进行检索。
相关文章:
【NLP相关】基于现有的预训练模型使用领域语料二次预训练
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

使用git进行项目管理--git使用及其常用命令
使用git进行项目管理 文章目录 使用git进行项目管理git使用1.添加用户名字2.添加用户邮箱3.git初始化4.add5.commit6.添加到gitee仓库7.推送到gitee8.切换版本git常用命令git add把指定的文件添加到暂存区中添加所有修改、已删除的文件到暂存区中添加所有修改、已删除、新增的文…...

Mybatis_CRUD使用
目录1 Mybatis简介环境说明:预备知识:1.1 定义1.2 持久化为什么需要持久化服务呢?1.3 持久层1.4 为什么需要Mybatis2 依赖配置3 CRUDnamespaceselect (查询用户数据)※传值方式:于方法中传值使用Map传值insert (插入用…...

JVM的过程内分析和过程间分析有什么区别?
问: 目前所有常见的Java虚拟机对过程间分析的支持都相 当有限,要么借助大规模的方法内联来打通方法间的隔阂,以过程内分析(Intra-Procedural Analysis, 只考虑过程内部语句,不考虑过程调用的分析ÿ…...

LearnDash测验报告如何帮助改进您的课程
某一个场景。Pennywell 大学有一门课程“Introduction to Linear Algebra”。上学期进行了两次测验。20% 的学生在第一次测验中不及格,而 80% 在第二次测验中不及格。在进一步评估中,观察到第一次测验不及格的学生在第二次测验中也不及格。在第二次测验中…...
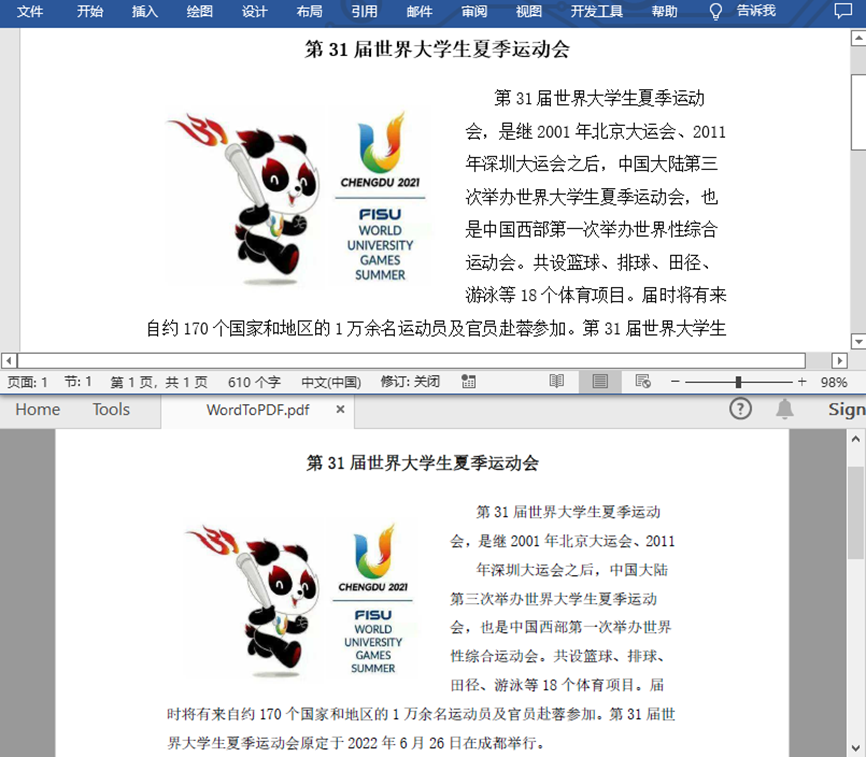
如何通过Java将Word转换为PDF
Word是我们日常编辑文档内容时十分常用的一种文档格式。但相比之下,PDF文档的格式、布局更为固定,不易被更改。在保存或传输较为重要的文档内容时,PDF文档格式也时很多人的不二选择。很多时候我们都会遇到需要将Word转换为PDF的情况。下面我就…...
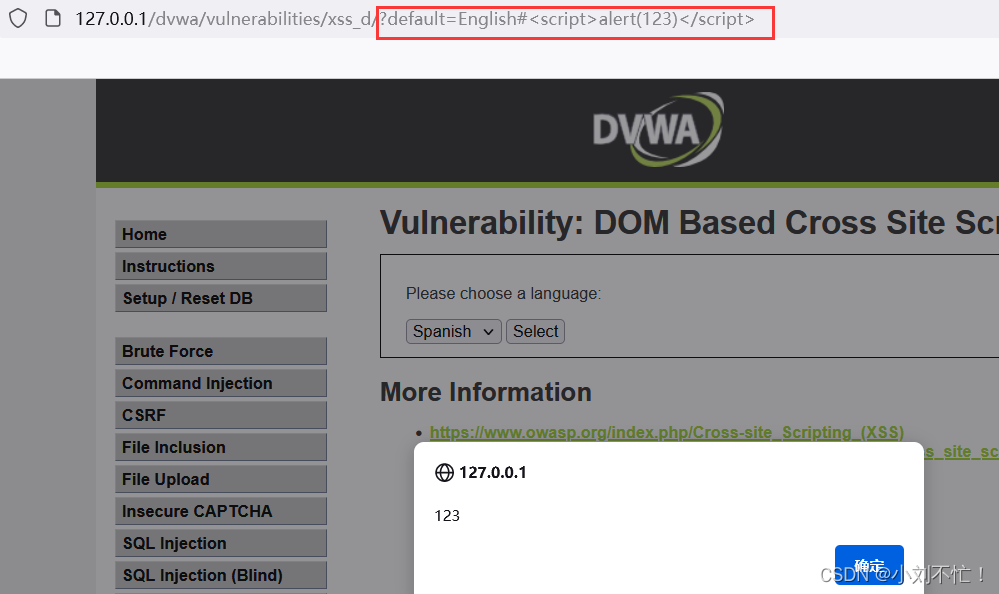
DOM型XSS
DOM型XSSDOM是什么DOM型XSSDOM型XSS实操DOM是什么 DOM就是Document。 文档是由节点构成的集合,在DOM里存在许多不同类型的节点,主要有:元素节点、文本节点,属性节点。 元素节点:好比< body >< p >< h …...
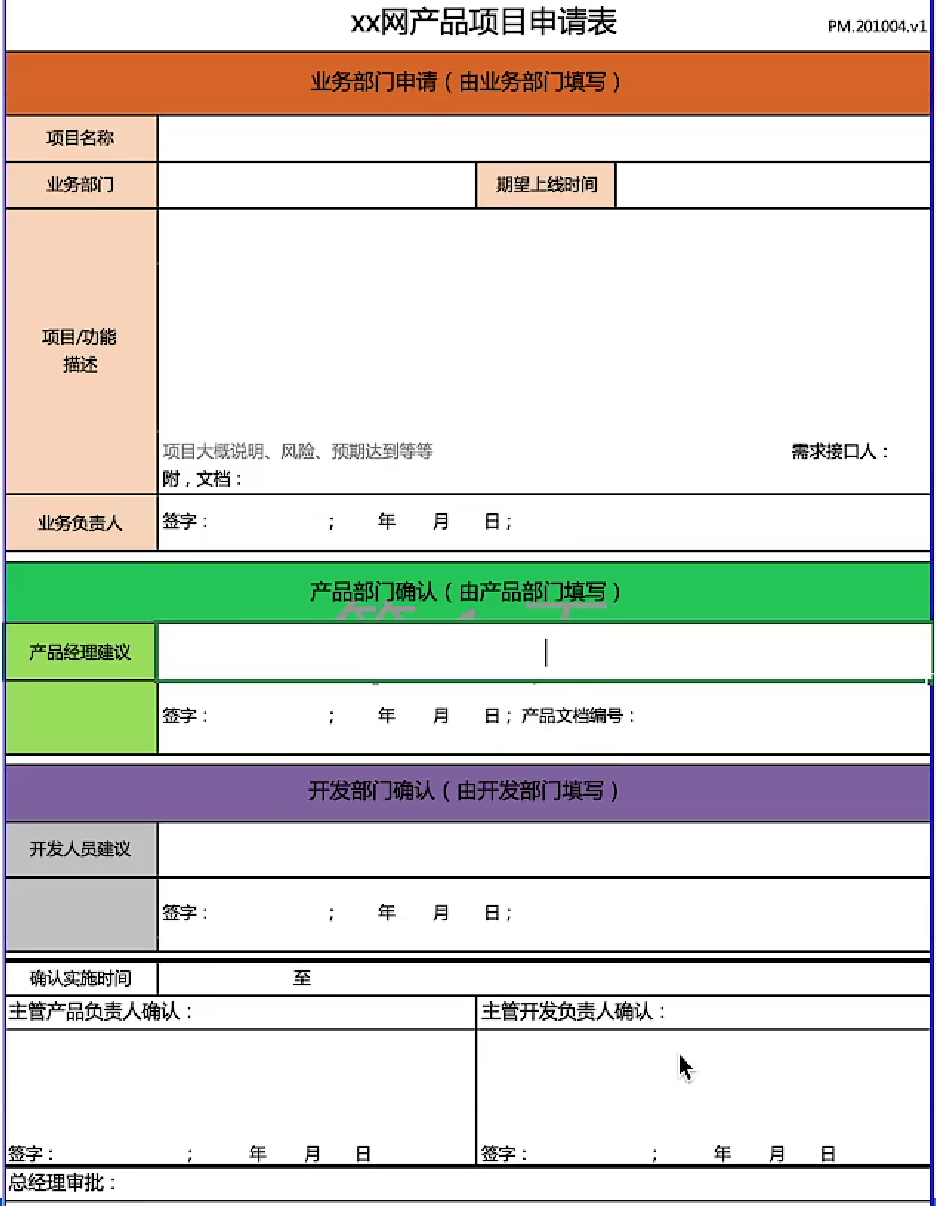
04-项目立项:项目方案、可行性分析、产品规划、立项评审
文章目录4.1 项目方案立项阶段4.2 可行性分析4.3 产品规划4.4 立项评审4.4.1 立项说明书的主要内容4.4.2 立项评审流程章节总结4.1 项目方案 学习目标: 能够输出产品项目方案 项目开发设计流程的主要阶段: 立项阶段 → 设计阶段 → 开发阶段 → 测试阶…...
)
数据分享|NPP VIIRS夜间灯光数据(2012-2020逐月)
2011年10月美国的“索米”国家极轨卫星伙伴卫星(Suomi National Polar-orbiting Partnership or Suomi NPP)发射,它搭载的VIIRS传感器上有一个称为DNB(Day Night Band)的波段能够在500米分辨率(比原来的OLS提高6倍)的尺度上对地表开展每天覆盖全球一次的高灵敏度(比OLS提…...

网络概论笔记
概论 网络研究的是节点和边 移动互联到物联网时代,只有有互联网,网络就不会落伍 协议:对等层面的实体固定的通信规则 协议包括:语法,语义,格式,次序,动作 网络是任意连接的 服务…...
软工2023个人作业二——软件案例分析
项目内容这个作业属于哪个课程2023年北航敏捷软件工程这个作业的要求在哪里个人作业-软件案例分析我在这个课程的目标是学习并掌握现代软件开发和项目管理技术,体验敏捷开发工作流程这个作业在哪个具体方面帮助我实现目标从软件工程角度分析比较我们所熟悉的软件&am…...
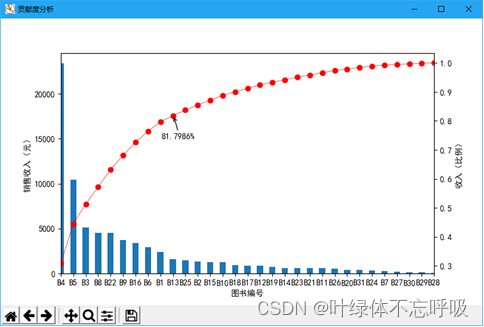
python数据分析表格文档Excel数据分析器统计源码
wx供重浩:创享软件 对话框发送:python表格 获取完整源码源文件说明文档可执行文件等 在PyCharm中运行《Excel数据分析师》即可进入如图1所示的系统主界面。在该界面中,通过顶部的工具栏可以选择所要进行的操作。 具体的操作步骤如下ÿ…...
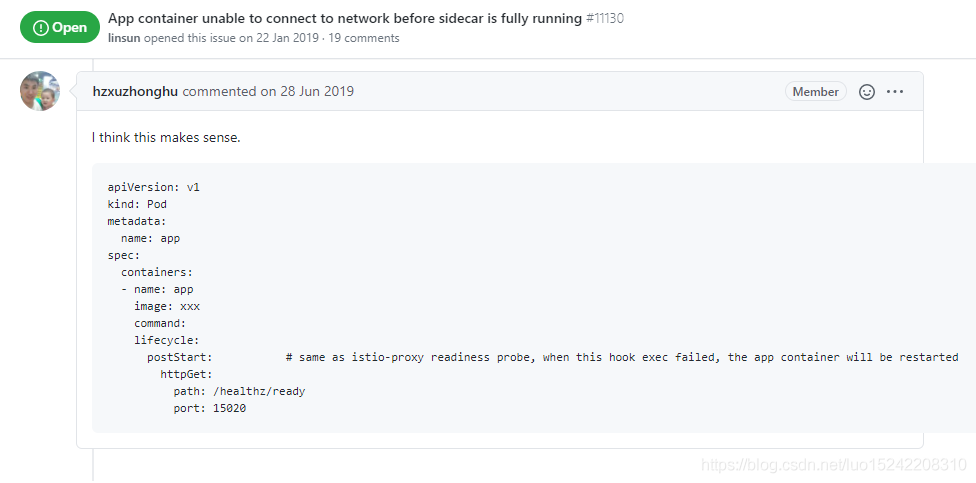
Istio Sidecar启动顺序 - 导致的应用容器网络不通
目录一、问题二、Istio 1.7及其之后版本的解决方案2.1 方式1:安装Istio时全局设置2.2 方式2:在应用Deployment通过annotation设置2.3 holdApplicationUntilProxyStarts启用效果三、Istio 1.7之前的解决方案一、问题 线上应用集成了Spring Cloud K8S Con…...

3696. 构造有向无环图
Powered by:NEFU AB-IN Link 文章目录3696. 构造有向无环图题意思路代码3696. 构造有向无环图 题意 Codeforces Round 656 (Div. 3) E 给定一个由 n个点和 m条边构成的图。 不保证给定的图是连通的。 图中的一部分边的方向已经确定,你不能改变它们的方向。 剩下的边…...
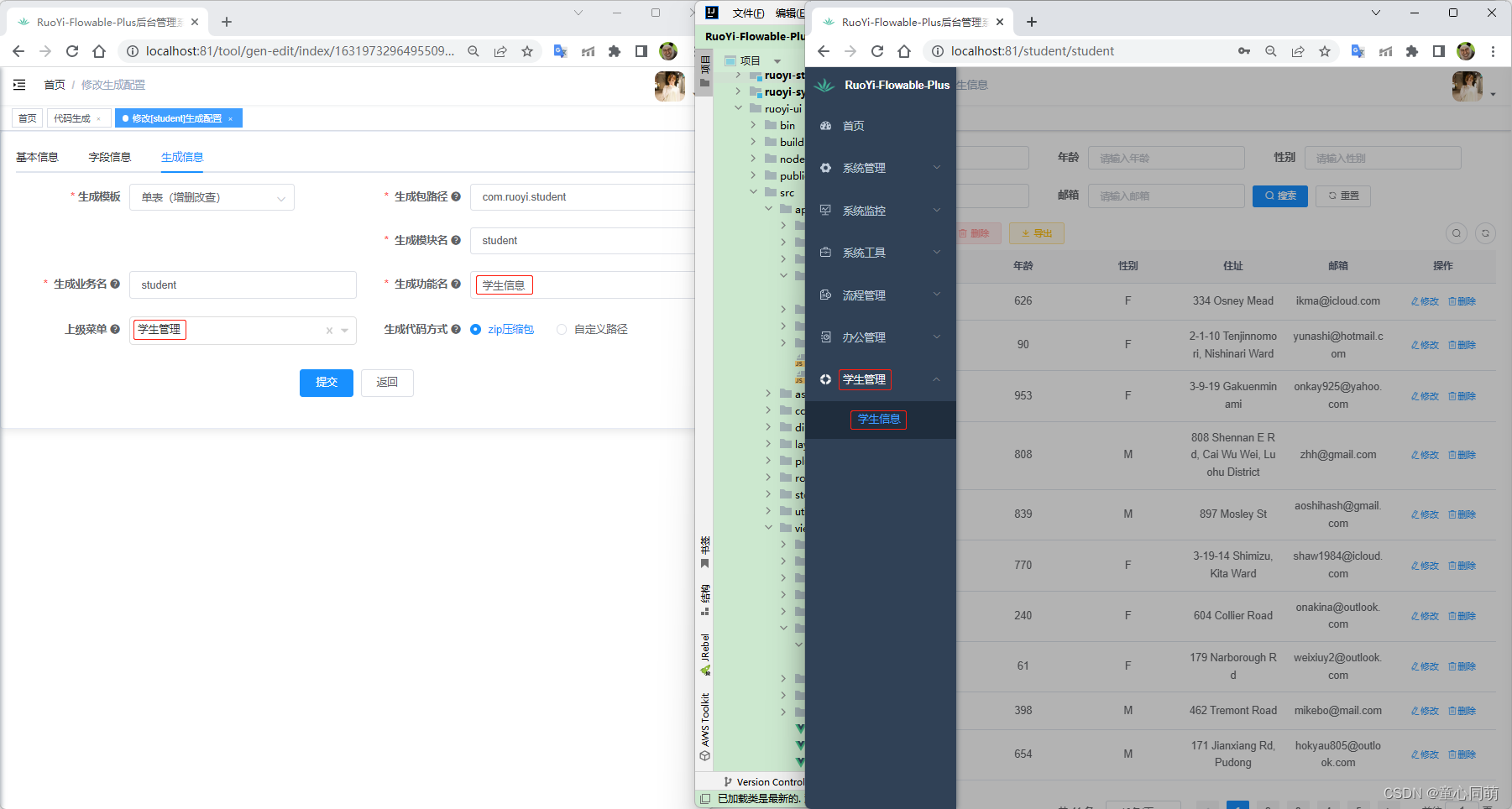
RuoYi-Flowable-Plus(代码生成)
RuoYi-Flowable-Plus搭建 若依所有扩展项目的代码生成功能都是一样的,RuoYi-Flowable-Plus为例来演示。 模块创建 1.创建新模块ruoyi-student2.编辑RuoYi-Flowable-Plus\pom.xml <dependency><groupId>com.ruoyi</groupId><artifactId>ruoy…...

训练CV模型常用的方法与技巧
最近参加一个CV比赛,看到有参赛者分享了自己训练图像识别模型时常用到的小技巧,故对其进行记录、整理,方便未来继续学习。整理了很多,它们不一定每次有用,但请记在心中,说不定未来某个任务它们就发挥了作用…...

[Java·算法·中等]LeetCode22. 括号生成
每天一题,防止痴呆题目示例分析思路1题解1分析思路2题解2分析思路3题解3👉️ 力扣原文 题目 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 输入:n 3 输出&…...

Git项目合并实践
Git项目合并实践 一、前言 环境 操作系统:Windows 10 专业版 代码托管平台:Gitee 场景 同一个项目,在某一个时间点,被另外一个团队拷贝和修改,并且代码不在同一个仓库,最后需要合并项目 不是同一个项…...

C++实战md5、base64算法实现(附源码)
C++常用功能源码系列 文章目录 C++常用功能源码系列前言一、常用加密算法1. md5是什么二、源码1. md52. base64、decode总结前言 本文是C/C++常用功能代码封装专栏的导航贴。部分来源于实战项目中的部分功能提炼,希望能够达到你在自己的项目中拿来就用的效果,这样更好的服务…...
P6专题:P6 EPPM和PPM基本概念
目录 引言 Oracles Primavera P6 Enterprise Project Portfolio Management(P6 EPPM) Oracles Primavera P6 Professional Project Management 引言 Oracle Primavera系列软件专注于项目密集型企业,其整个项目生命周期内所有项目的组合管…...

Z-Image-Turbo-辉夜巫女保姆级教程:从部署到出图,小白也能轻松玩转
Z-Image-Turbo-辉夜巫女保姆级教程:从部署到出图,小白也能轻松玩转 1. 前言:为什么选择Z-Image-Turbo-辉夜巫女 如果你正在寻找一个简单易用、效果惊艳的AI图像生成工具,Z-Image-Turbo-辉夜巫女绝对值得尝试。这个基于阿里巴巴通…...

node2vec在Spark上的分布式实现:处理大规模图的终极解决方案
node2vec在Spark上的分布式实现:处理大规模图的终极解决方案 【免费下载链接】node2vec 项目地址: https://gitcode.com/gh_mirrors/no/node2vec 想要处理包含数千万甚至上亿节点的大规模图网络数据吗?node2vec在Spark上的分布式实现为你提供了处…...

终极指南:告别鼠标!Spectacle窗口动作组合让复杂布局一键生成 [特殊字符]
终极指南:告别鼠标!Spectacle窗口动作组合让复杂布局一键生成 🚀 【免费下载链接】spectacle Spectacle allows you to organize your windows without using a mouse. 项目地址: https://gitcode.com/gh_mirrors/sp/spectacle 想要提…...

手柄适配终极方案:DS4Windows实现跨平台控制器无缝体验
手柄适配终极方案:DS4Windows实现跨平台控制器无缝体验 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 当你兴冲冲地将PlayStation手柄连接到PC,却发现游戏完全没有…...

免费文档下载终极指南:kill-doc 让您轻松获取全网文档资源
免费文档下载终极指南:kill-doc 让您轻松获取全网文档资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为…...

RavenDB全文搜索与NGram分析器的实际应用
引言 在现代的数据库系统中,全文搜索功能已成为一个不可或缺的部分。RavenDB,作为一个强大的NoSQL数据库,提供了丰富的文本搜索功能。特别是通过使用NGram分析器,可以大大提升搜索的灵活性和准确性。本文将深入探讨RavenDB的全文搜索机制,特别是NGram分析器在索引和查询时…...

3分钟掌握OpenSpeedy:完全免费的开源游戏变速工具终极指南
3分钟掌握OpenSpeedy:完全免费的开源游戏变速工具终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy OpenSpeedy是一款专为Windows平台设计的开源游戏变速工…...

CoPaw复杂逻辑推理与数学解题能力极限测试
CoPaw复杂逻辑推理与数学解题能力极限测试 1. 开场:挑战AI的认知边界 今天我们要做一个有趣的实验——对CoPaw进行一场高强度的逻辑与数学能力压力测试。就像给运动员做极限体能测试一样,我们将用一系列高难度题目来检验这个AI模型的推理能力边界。 测…...

Java中的修饰符,类,接口,多态
最近学了Java中的修饰符,类,接口,多态1.修饰符学了public,默认,protected,private。public是公用的,都能访问。默认的话只能在同类中和同包中调用,而protected则可以在同类中&#x…...
)
QT开发环境搭建:如何在Linux上快速配置Python和C++支持(含清华镜像源加速)
Linux下高效搭建QT开发环境:Python与C双语言支持实战指南 在Linux系统上搭建QT开发环境是许多跨平台应用开发者的必经之路。不同于Windows或macOS的一键式安装,Linux环境下的配置往往需要处理更多依赖关系和系统级设置。本文将带你从零开始,在…...