Java基础(二十六):Java8 Stream流及Optional类
Java基础系列文章
Java基础(一):语言概述
Java基础(二):原码、反码、补码及进制之间的运算
Java基础(三):数据类型与进制
Java基础(四):逻辑运算符和位运算符
Java基础(五):流程控制语句
Java基础(六):数组
Java基础(七):面向对象编程
Java基础(八):封装、继承、多态性
Java基础(九):Object 类的使用
Java基础(十):关键字static、代码块、关键字final
Java基础(十一):抽象类、接口、内部类
Java基础(十二):枚举类
Java基础(十三):注解(Annotation)
Java基础(十四):包装类
Java基础(十五):异常处理
Java基础(十六):String的常用API
Java基础(十七):日期时间API
Java基础(十八):java比较器、系统相关类、数学相关类
Java基础(十九):集合框架
Java基础(二十):泛型
Java基础(二十一):集合源码
Java基础(二十二):File类与IO流
Java基础(二十三):反射机制
Java基础(二十四):网络编程
Java基础(二十五):Lambda表达式、方法引用、构造器引用
Java基础(二十六):Java8 Stream流及Optional类
目录
- 一、Stream介绍
- 1、什么是Stream
- 2、Stream特点
- 3、Stream的操作三个步骤
- 二、创建Stream实例
- 1、通过集合创建Stream
- 2、通过数组创建Stream
- 3、通过Stream的of()创建Stream
- 4、创建无限流
- 三、Stream中间操作
- 1、筛选(filter)
- 2、截断(limit)
- 3、跳过(skip)
- 4、去重(distinct)
- 5、映射(map/flatMap/mapToInt)
- 6、排序(sorted)
- 7、peek 和 forEach
- 四、Stream终止操作
- 1、匹配(allMatch/anyMatch/noneMatch)
- 2、查找(findFirst/findAny)
- 3、聚合(max/min/count)
- 4、归约(reduce)
- 5、收集(collect)
- 5.1、归集(toList/toSet/toMap)
- 5.2、统计(counting/averaging/summing/maxBy/minBy)
- 5.3、分组(partitioningBy/groupingBy)
- 5.4、接合(joining)
- 五、Optional 类
- 1、构建Optional对象
- 2、获取value值,空值的处理
- 3、处理value值,空值不处理不报错
一、Stream介绍
1、什么是Stream
- Stream 是数据渠道,用于
操作数据源(集合、数组等)所生成的元素序列 - Stream和Collection集合的区别
- Collection是一种静态的内存数据结构,讲的是数据;主要面向内存,存储在内存中
- Stream是有关计算的,讲的是计算;面向CPU,通过CPU实现计算
2、Stream特点
- Stream自己
不会存储元素 - Stream
不会改变源对象。相反,他们会返回一个持有结果的新Stream - Stream 操作是
延迟执行的- 这意味着他们会等到需要结果的时候才执行
- 即一旦执行终止操作,就执行中间操作链,并产生结果
- Stream一旦执行了终止操作,就不能再调用其它
中间操作或终止操作了
3、Stream的操作三个步骤
- 创建 Stream
- 一个数据源(如:集合、数组),获取一个流
- 中间操作
- 每次处理都会返回一个持有结果的新Stream
- 即中间操作的方法返回值仍然是Stream类型的对象
- 因此中间操作可以是个
操作链,可对数据源的数据进行n次处理 - 但是在终结操作前,并不会真正执行
- 终止操作(终端操作)
- 终止操作的方法返回值类型就不再是Stream了
- 因此一旦执行终止操作,就结束整个Stream操作了
- 一旦执行终止操作,就执行中间操作链,最终产生结果并结束Stream
二、创建Stream实例
1、通过集合创建Stream
- Java8中的Collection接口被扩展,提供了两个获取流的方法:
- default Stream<E> stream() : 返回一个顺序流
- default Stream<E> parallelStream() : 返回一个并行流
@Test
public void test01(){List<String> list = Arrays.asList("a", "b", "c", "d");//创建顺序流(顺序执行)Stream<String> stream = list.stream();//创建并行流(多线程并行执行,速度快)Stream<String> parallelStream = list.parallelStream();
}
2、通过数组创建Stream
- Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
- public static <T> Stream<T> stream(T[] array): 返回一个流
- public static IntStream stream(int[] array)
- public static LongStream stream(long[] array)
- public static DoubleStream stream(double[] array)
@Test
public void test02(){String[] arr = {"hello","world"};Stream<String> stream = Arrays.stream(arr);
}@Test
public void test03(){int[] arr = {1,2,3,4,5};IntStream stream = Arrays.stream(arr);
}
3、通过Stream的of()创建Stream
- 可以调用Stream类静态方法 of(), 通过显示值创建一个流
- 它可以接收任意数量的参数
- public static<T> Stream<T> of(T… values) : 返回一个流
@Test
public void test04(){Stream<Integer> stream = Stream.of(1,2,3,4,5);stream.forEach(System.out::println);
}
4、创建无限流
- 可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流
- public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
- public static<T> Stream<T> generate(Supplier<T> s)
@Test
public void test05() {// 迭代累加,获取前五个Stream<Integer> stream = Stream.iterate(1, x -> x + 2);stream.limit(5).forEach(System.out::println);System.out.println("**********************************");// 一直生成随机数,获取前五个Stream<Double> stream1 = Stream.generate(Math::random);stream1.limit(5).forEach(System.out::println);
}
输出结果:
1
3
5
7
9
**********************************
0.1356905695577818
0.33576714141304886
0.7325647295361851
0.29218866245097375
0.24849848127040652
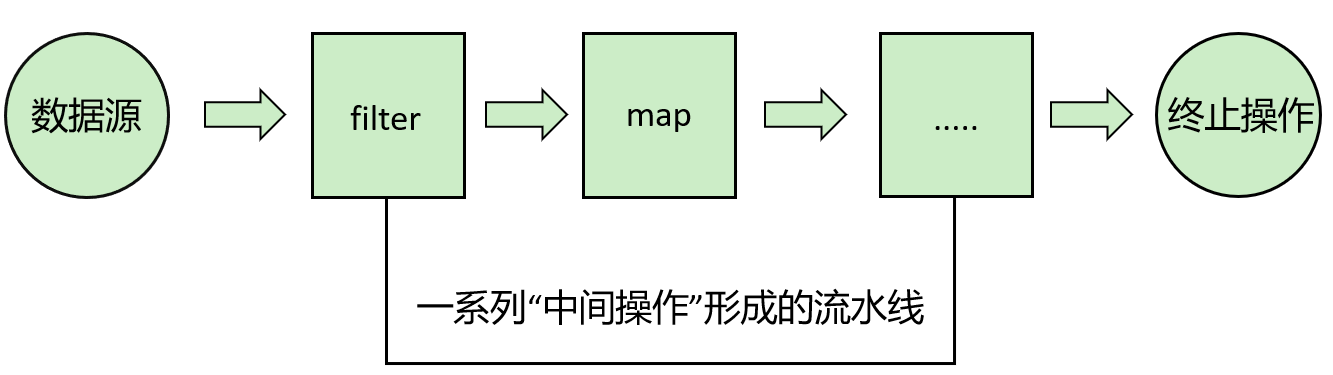
三、Stream中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理- 而在终止操作时一次性全部处理,称为“惰性求值”
准备测试数据
// @Data 注在类上,提供类的get、set、equals、hashCode、toString等方法
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {// idprivate int id;// 名称private String name;// 年龄private int age;// 工资private double salary;
}public class EmployeeData {public static List<Employee> getEmployees(){List<Employee> list = new ArrayList<>();list.add(new Employee(1001, "马化腾", 34, 6000.38));list.add(new Employee(1002, "马云", 2, 19876.12));list.add(new Employee(1003, "刘强东", 33, 3000.82));list.add(new Employee(1004, "雷军", 26, 7657.37));list.add(new Employee(1005, "李彦宏", 65, 5555.32));list.add(new Employee(1006, "比尔盖茨", 42, 9500.43));list.add(new Employee(1007, "任正非", 26, 4333.32));list.add(new Employee(1008, "扎克伯格", 35, 2500.32));return list;}
}
1、筛选(filter)
- 查询员工表中薪资大于7000的员工信息
// 获取员工集合数据
List<Employee> employeeList = EmployeeData.getEmployees();
Stream<Employee> stream = employeeList.stream();
stream.filter(emp -> emp.getSalary() > 7000).forEach(System.out::println);
2、截断(limit)
- 获取员工集合数据的前十个员工信息
employeeList.stream().limit(10).forEach(System.out::println);
3、跳过(skip)
- 返回一个删除前五个员工信息的数据,与limit(n)互补
employeeList.stream().skip(5).forEach(System.out::println);
4、去重(distinct)
- 通过流所生成元素的hashCode()和equals()去除重复元素
- 需要重写hashCode和equals方法,否则不能去重
employeeList.add(new Employee(1009, "马斯克", 40, 12500.32));
employeeList.add(new Employee(1009, "马斯克", 40, 12500.32));
employeeList.add(new Employee(1009, "马斯克", 40, 12500.32));
employeeList.add(new Employee(1009, "马斯克", 40, 12500.32));employeeList.stream().distinct().forEach(System.out::println);
5、映射(map/flatMap/mapToInt)
- map:获取员工姓名长度大于3的员工的姓名
//方式1:Lambda表达式
employeeList.stream().map(emp -> emp.getName()).filter(name -> name.length() > 3).forEach(System.out::println);
//方式2:方法引用第三种 类 :: 实例方法名
employeeList.stream().map(Employee::getName).filter(name -> name.length() > 3).forEach(System.out::println);
- flatMap:当处理嵌套集合时,可以使用flatMap将嵌套集合展平成一个新的Stream
List<List<Integer>> nestedList = Arrays.asList(Arrays.asList(1, 2, 3),Arrays.asList(4, 5, 6),Arrays.asList(7, 8, 9)
);nestedList.stream().flatMap(item -> item.stream()).forEach(System.out::println);
- mapToInt:将流中每个元素映射为int类型
// 获取名字长度的总和
List<String> list1 = Arrays.asList("Apple", "Banana", "Orange", "Grapes");
IntStream intstream = list1.stream().mapToInt(String::length);
int sum = intstream.sum();
- mapToDouble:将流中每个元素映射为Double类型
- mapToLong:将流中每个元素映射为Long类型
6、排序(sorted)
- sorted():自然排序(从小到大),流中元素需实现Comparable接口,否则报错
//sorted() 自然排序
Integer[] arr = new Integer[]{345,3,64,3,46,7,3,34,65,68};
String[] arr1 = new String[]{"GG","DD","MM","SS","JJ"};Arrays.stream(arr).sorted().forEach(System.out::println);
Arrays.stream(arr1).sorted().forEach(System.out::println);//因为Employee没有实现Comparable接口,所以报错!
employeeList.stream().sorted().forEach(System.out::println);
- sorted(Comparator com):Comparator排序器自定义排序
// 根据工资自然排序(从小到大)
employeeList.stream().sorted(Comparator.comparing(Employee::getSalary)).forEach(System.out::println);
// 根据工资倒序(从大到小)
employeeList.stream().sorted(Comparator.comparing(Employee::getSalary).reversed()).forEach(System.out::println);
7、peek 和 forEach
- 相同点:peek和forEach都是遍历流内对象并且对对象进行一定的操作
- 不同点:forEach返回void结束Stream操作,peek会继续返回Stream对象
employeeList.stream().map(Employee::getName).peek(System.out::println).filter(name -> name.length() > 3).forEach(System.out::println);
四、Stream终止操作
- 终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void
- 流进行了终止操作后,不能再次使用
1、匹配(allMatch/anyMatch/noneMatch)
- allMatch(Predicate p):检查是否匹配所有元素
- 是否所有的员工的年龄都大于18
boolean allMatch = employeeList.stream().allMatch(emp -> emp.getAge() > 18);
- anyMatch(Predicate p):检查是否至少匹配一个元素
- 是否存在年龄大于18岁的员工
boolean anyMatch = employeeList.stream().anyMatch(emp -> emp.getAge() > 18);
- noneMatch(Predicate p):检查是否没有匹配所有元素
- 是不是没有年龄大于18岁的员工,没有返回true,存在返回false
boolean noneMatch = employeeList.stream().noneMatch(emp -> emp.getAge() > 18);
2、查找(findFirst/findAny)
- findFirst():返回第一个元素
Optional<Employee> first = employeeList.stream().findFirst();
Employee employee = first.get();
- findAny():返回当前流中的任意元素
Optional<Employee> any = employeeList.stream().findAny();
Employee employee = any.get();
ps:集合中数据为空,会抛异常No value present,后面会将Optional类的空值处理
3、聚合(max/min/count)
- max(Comparator c):返回流中最大值,入参与排序sorted的比较器一样,必须自然排序
- 返回最高工资的员工
Optional<Employee> max = employeeList.stream().max(Comparator.comparingDouble(Employee::getSalary));
Employee employee = max.get();
- min(Comparator c):返回流中最小值,入参与排序sorted的比较器一样,必须自然排序
- 返回最低工资的员工
Optional<Employee> min = employeeList.stream().min(Comparator.comparingDouble(Employee::getSalary));
Employee employee = min.get();
- count():返回流中元素总数
- 返回所有工资大于7000的员工的个数
long count = employeeList.stream().filter(emp -> emp.getSalary() > 7000).count();
4、归约(reduce)
- reduce(BinaryOperator b):可以将流中元素反复结合起来,得到一个值。返回 Optional<T>
// 计算1-10的自然数的和
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Optional<Integer> reduce6 = list.stream().reduce(Integer::sum);
Integer sum = reduce6.get();// 计算公司所有员工工资的总和
Optional<Double> reduce7 = employeeList.stream().map(Employee::getSalary).reduce(Double::sum);
Double aDouble = reduce7.get();
- reduce(T identity, BinaryOperator b):可以将流中元素反复结合起来,得到一个值。返回 T
- T identity:累加函数的初始值
- 不需要先获取Optional再get(),直接可以获取结果,
推荐使用
// 计算1-10的自然数的和
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer reduce1 = list.stream().reduce(0, (x1, x2) -> x1 + x2);
Integer reduce2 = list.stream().reduce(0, (x1, x2) -> Integer.sum(x1, x2));
Integer reduce3 = list.stream().reduce(0, Integer::sum);
// 计算1-10的自然数的乘积
Integer reduce4 = list.stream().reduce(1, (x1, x2) -> x1 * x2);// 计算公司所有员工工资的总和
Double reduce5 = employeeList.stream().map(Employee::getSalary).reduce(0.0, Double::sum);
5、收集(collect)
- collect(Collector c):将流转换为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法
Collector接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)Collectors实用类提供了很多静态方法,可以方便地创建常见收集器实例,如下
5.1、归集(toList/toSet/toMap)
- toList():把流中元素收集到List
- 获取所有员工姓名集合
List<String> nameList1 = employeeList.stream().map(Employee::getName).collect(Collectors.toList());
// jdk16以后,collect(Collectors.toList())可以简写为.toList()
List<String> nameList2 = employeeList.stream().map(Employee::getName).toList();
- toSet():把流中元素收集到Set
- 获取所有员工年龄set集合,可以去重
Set<Integer> ageList = employeeList.stream().map(Employee::getAge).collect(Collectors.toSet());
- toMap():把流中元素收集到Map
- Function.identity():t -> t,相当于参数是什么,返回什么
如下如果key重复,会抛异常java.lang.IllegalStateException: Duplicate key xxx
// key-名称 value-员工对象
Map<String, Employee> employeeNameMap = employeeList.stream().collect(Collectors.toMap(Employee::getName, Function.identity()));
// key-名称 value-工资
Map<String, Double> nameSalaryMap = employeeList.stream().collect(Collectors.toMap(Employee::getName, Employee::getSalary));
- toMap的第三个参数则是
key重复后如何操作value的内容 - key重复可以只要旧的value数据,也可以新的value+旧的value等等
// key-名称 value-员工对象
Map<String, Employee> employeeNameMap = employeeList.stream().collect(Collectors.toMap(Employee::getName, Function.identity(),(oldValue,newValue) -> oldValue));
// key-名称 value-工资
Map<String, Double> nameSalaryMap = employeeList.stream().collect(Collectors.toMap(Employee::getName, Employee::getSalary,(oldValue,newValue) -> oldValue + newValue));
5.2、统计(counting/averaging/summing/maxBy/minBy)
- counting():计算流中元素的个数
Long count = employeeList.stream().collect(Collectors.counting());
// 相当于
Long count2 = employeeList.stream().count();
- averagingInt:计算流中元素Integer属性的平均值
- averagingDouble:计算流中元素Double属性的平均值
- averagingLong:计算流中元素Long属性的平均值
- 返回值都是Double
Double aDouble = employeeList.stream().collect(Collectors.averagingInt(Employee::getAge));
Double bDouble = employeeList.stream().collect(Collectors.averagingDouble(Employee::getSalary));
- summingInt:计算流中元素Integer属性的总和
- summingDouble:计算流中元素Double属性的总和
- summingLong:计算流中元素Long属性的总和
Integer count = employeeList.stream().collect(Collectors.summingInt(Employee::getAge));
Double total = employeeList.stream().collect(Collectors.summingDouble(Employee::getSalary));
- maxBy():计算流最大值
- minBy():计算流最小值
// 最大值
Optional<Employee> employee = employeeList.stream().collect(Collectors.maxBy(Comparator.comparingDouble(Employee::getSalary)));
// 最小值
Optional<Employee> employee = employeeList.stream().collect(Collectors.minBy(Comparator.comparingDouble(Employee::getSalary)));
- summarizingInt():汇总统计包括总条数、总和、平均数、最大值、最小值
IntSummaryStatistics summaryStatistics = employeeList.stream().collect(Collectors.summarizingInt(Employee::getAge));
System.out.println(summaryStatistics);// IntSummaryStatistics{count=8, sum=263, min=2, average=32.875000, max=65}
5.3、分组(partitioningBy/groupingBy)
- partitioningBy():根据true或false进行分区
- 将员工按薪资是否高于6000分组
Map<Boolean, List<Employee>> listMap = employeeList.stream().collect(Collectors.partitioningBy(emp -> emp.getSalary() > 6000));
- groupingBy():根据某属性值对流分组,属性为K,结果为V
- 将员工年龄分组
Map<Integer, List<Employee>> collect = employeeList.stream().collect(Collectors.groupingBy(Employee::getAge));
- 将员工按年龄分组,再汇总不同年龄的总金额
Map<Integer, Double> collect = employeeList.stream().collect(Collectors.groupingBy(Employee::getAge, Collectors.summingDouble(Employee::getSalary)));
- 将员工按年龄分组,获取工资集合
Map<Integer, List<Double>> integerListMap = employeeList.stream().collect(Collectors.groupingBy(Employee::getAge, Collectors.mapping(Employee::getSalary, Collectors.toList())));
- 先按员工年龄分组,再按工资分组
Map<Integer, Map<Double, List<Employee>>> collect = employeeList.stream().collect(Collectors.groupingBy(Employee::getAge, Collectors.groupingBy(Employee::getSalary)));
5.4、接合(joining)
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
// 结果:A-B-C
五、Optional 类
Optional类内部结构(value为实际存储的值)
public final class Optional<T> {// 空Optional对象,value为nullprivate static final Optional<?> EMPTY = new Optional<>();// 实际存储的内容private final T value;// 私有的构造private Optional() {this.value = null;}...
}
1、构建Optional对象
@Test
public void optionalTest(){Integer value1 = null;Integer value2 = 10;// 允许传递为null参数Optional<Integer> a = Optional.ofNullable(value1);// 如果传递的参数是null,抛出异常NullPointerExceptionOptional<Integer> b = Optional.of(value2);// 空对象,value为nullOptional<Object> c = Optional.empty();
}
2、获取value值,空值的处理
@Test
public void optionalTest() {Integer value1 = null;Optional<Integer> a = Optional.ofNullable(value1);System.out.println("value值是否为null:" + a.isPresent());System.out.println("获取value值,空报错空指针:" + a.get());System.out.println("获取value值,空返回默认值0:" + a.orElse(0));System.out.println("获取value值,空返回Supplier返回值:" + a.orElseGet(() -> 100));System.out.println("获取value值,空抛出异常:" + a.orElseThrow(() -> new RuntimeException("value为空")));
}
3、处理value值,空值不处理不报错
- ifPresent方法内会判断不为空才操作
@Test
public void optionalTest() {Integer value1 = 10;Optional<Integer> a = Optional.ofNullable(value1);// 空不处理,非空则根据Consumer消费接口处理a.ifPresent(o -> System.out.println("ifPresent value值:" + o)); // 10// 空不处理,filter过滤a.filter(o -> o > 1).ifPresent(o -> System.out.println("filter value值:" + o)); // 10// 空不处理,map映射a.map(o -> o + 10).ifPresent(o -> System.out.println("map value值:" + o)); // 20// 空不处理,flatMap映射a.flatMap(o -> Optional.of(o + 20)).ifPresent(o -> System.out.println("flatMap value值:" + o)); // 30
}
相关文章:
Java基础(二十六):Java8 Stream流及Optional类
Java基础系列文章 Java基础(一):语言概述 Java基础(二):原码、反码、补码及进制之间的运算 Java基础(三):数据类型与进制 Java基础(四):逻辑运算符和位运算符 Java基础(五):流程控制语句 Java基础(六)࿱…...
qt - 19种精美软件样式
qt - 19种精美软件样式 一、效果演示二、核心程序三、下载链接 一、效果演示 二、核心程序 #include "mainwindow.h"#include <QtAdvancedStylesheet.h> #include <QmlStyleUrlInterceptor.h>#include "ui_mainwindow.h" #include <QDir&g…...

vue 使用docx库生成word表格文档
在Vue.js中生成Word表格文档,可以通过前端库来实现。这些库可以帮助我们轻松地将HTML表格转换为Word文档(通常是.docx格式)。以下是一些流行的前端库,它们可以用于在Vue项目中生成Word表格文档: docx…...

ElementUI table表格组件实现双击编辑单元格失去焦点还原,支持多单元格
在使用ElementUI table表格组件时有时需要双击单元格显示编辑状态,失去焦点时还原表格显示。 实现思路: 在数据中增加isFocus:false.控制是否显示在table中用cell-dblclick双击方法 先看效果: 上源码:在表格模板中用scope.row…...
Java基于SpringBoot+Vue的图书管理系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

【云安全】Hypervisor与虚拟机
Hypervisor 也被称为虚拟机监视器(Virtual Machine Monitor,VMM),主要作用是让多个操作系统可以在同一台物理机上运行。 Type-1 Hypervisor 与 Typer-2 Hypervisor Type-1 Hypervisor 直接安装在物理服务器上,不依赖…...

JS文本加密方法探究
在前端开发中,有时候我们需要对敏感文本进行简单的加密,以提高安全性。本文将介绍一种基于 JavaScript 实现的文本加密方法,使用了 Base64、Unicode 和 ROT13 编码。 示例代码 function encodeText(text) {// Base64编码var base64Encoded …...
推荐彩虹知识付费商城免授权7.0源码
彩虹知识付费商城免授权7.0源码,最低配置环境 PHP7.2 1、上传源码到网站根目录,导入数据库文件:xydai.sql 2、修改数据库配置文件:/config.php 3、后台:/admin 账号:admin 密码:123456 4、前…...
【天衍系列 04】深入理解Flink的ElasticsearchSink组件:实时数据流如何无缝地流向Elasticsearch
文章目录 01 Elasticsearch Sink 基础概念02 Elasticsearch Sink 工作原理03 Elasticsearch Sink 核心组件04 Elasticsearch Sink 配置参数05 Elasticsearch Sink 依赖管理06 Elasticsearch Sink 初阶实战07 Elasticsearch Sink 进阶实战7.1 包结构 & 项目配置项目配置appl…...
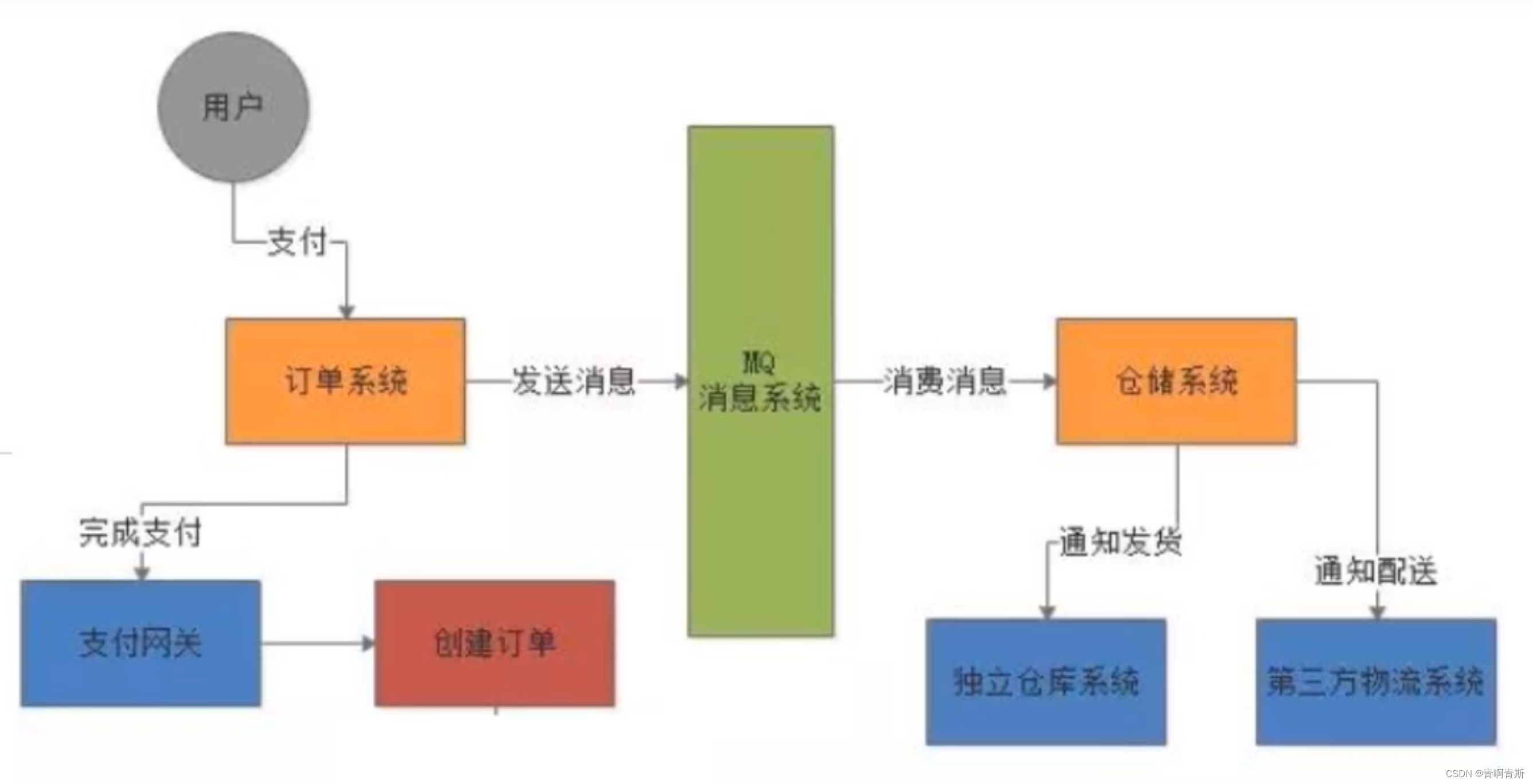
一、ActiveMQ介绍
ActiveMQ介绍 一、JMS1.jms介绍2.jms消息传递模式3.JMS编码总体架构 二、消息中间件三、ActiveMQ介绍1.引入的原因1.1 原因1.2 遇到的问题1.3 解决思路 2.定义3.特点3.1 异步处理3.2 应用系统之间解耦3.3 实际-整体架构 4.作用 一、JMS 1.jms介绍 jms是java消息服务接口规范&…...

【牛客】寒假训练营1 I-It‘s bertrand paradox. Again! 题解
传送门:It’s bertrand paradox. Again! 标签:随机 题目大意 有两个人分别用两种方式在二维平面上随机生成1e5个圆,每个圆上的每一个点(x,y)都满足-100<x<100且-100<y<100,现在将某个人生成的1e5个圆的圆心和半径告…...

各种手型都合适,功能高度可定制,雷柏VT9PRO mini和VT9PRO游戏鼠标上手
去年雷柏推出了一系列支持4KHz回报率的鼠标,有着非常敏捷的反应速度,在游戏中操作体验十分出色。尤其是这系列4K鼠标不仅型号丰富,而且对玩家的操作习惯、手型适应也很好,像是VT9系列就主打轻巧,还有专门针对小手用户的…...

sql建库,建表基础操作
当涉及到SQL建库和建表操作时,以下是一个简单的示例: 1. 建库(创建数据库) sql复制代码 CREATE DATABASE mydatabase; 上述语句将创建一个名为mydatabase的数据库。 2. 选择数据库 在创建表之前,需要选择要在其中…...

算法训练营day32,贪心算法6
import "strconv" //738. 单调递增的数字 func monotoneIncreasingDigits(n int) int { str : strconv.Itoa(n) nums : []byte(str) length : len(nums) if length < 1 { return n } for i : length - 1; i > 0; i-- { //如果前一个数字比当前值大࿰…...
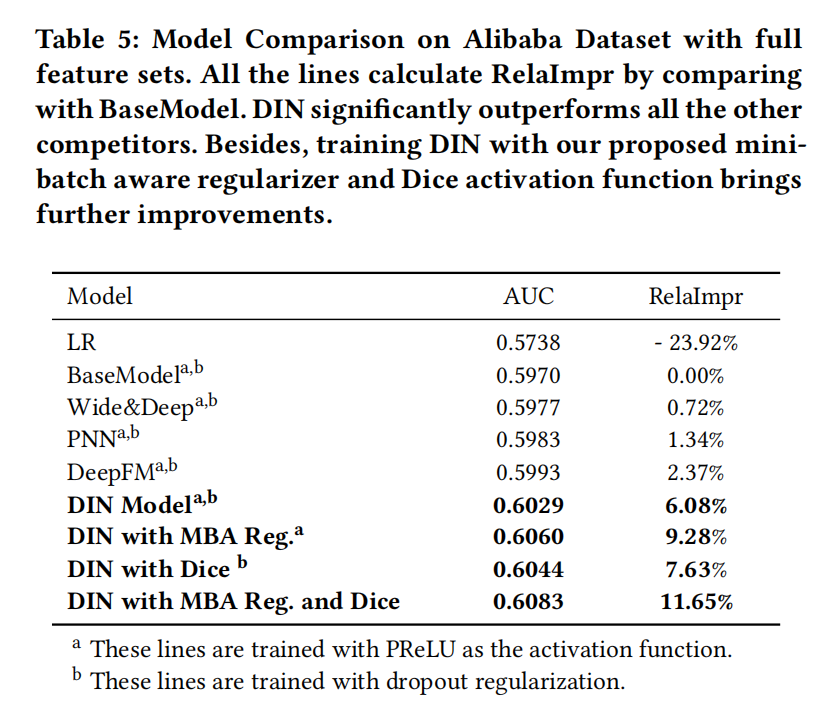
CTR之行为序列建模用户兴趣:DIN
在前面的文章中,已经介绍了很多关于推荐系统中CTR预估的相关技术,今天这篇文章也是延续这个主题。但不同的,重点是关于用户行为序列建模,阿里出品。 概要 论文:Deep Interest Network for Click-Through Rate Predict…...

Java使用Redis实现分页功能
分页功能实现应该是比较常见的,对于redis来说,近期刷题就发现了lrange、zrange这些指令,这个指令怎么使用呢? 我们接下来就来讲解下。 目录 指令简介lrangezrange Java实现Redis实现分页功能 指令简介 lrange lrange 是 Redis 中…...

Qt标准对话框设置
Qt标准对话框设置,设置字体、调色板、进度条等。 #include "mainwindow.h" #include "ui_mainwindow.h"MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), ui(new Ui::MainWindow) {ui->setupUi(this); }MainWindow::~MainWi…...

如何让Obsidian实现电脑端和安卓端同步
Obsidian是一款知名的笔记软件,支持Markdown语法,它允许用户在多个设备之间同步文件。要在安卓设备上实现同步,可以使用remote save插件,以下是具体操作步骤: 首先是安装电脑端的obsidian,然后依次下载obs…...

windows系统中jenkins构建报错提示“拒绝访问”
一.背景 之前徒弟在windows中安装的jenkins,运行的时候用的是java -jar jenkins.war来运行的。服务器只有1个盘符C盘。今天说构建错误了,问我修改了啥,我年前是修改过构建思路的。 二.问题分析 先看jenkins构建任务的日志,大概是xcopy命令执…...

服务器防火墙的应用技术有哪些?
随着互联网的发展,网络安全问题更加严峻。服务器防火墙技术作为一种基础的网络安全技术,对于保障我们的网络安全至关重要。本文将介绍服务器防火墙的概念和作用,以及主要的服务器防火墙技术,包括数据包过滤、状态检测、代理服务、…...

硬件工程选型解析:钡特电源VB6-48S03MD与金升阳URB4803YMD-6WR3属工业标准模块电源
在工业硬件研发、设备调试与批量量产过程中,小功率隔离供电模块的稳定性、封装规范性与工况适配性,是硬件研发工程师重点核查的核心参数,直接决定工控终端、通信设备与电力监测装置的运行稳定性。在6W级48V转3.3V主流供电方案中,钡…...

Heavy Fighter动画包:Unity战斗系统根运动与状态机深度解析
1. 这套动画包不是“拿来就能用”的资源,而是需要你亲手校准的战斗系统骨架我在2021年接手一个横版ARPG项目时,美术总监甩给我三套Mecanim动画包,其中一套就是Heavy Fighter Mecanim Animation Pack。当时我第一反应是“终于不用手调IK了”&a…...

JMeter断言实战:从误配到分层校验的避坑指南
1. 为什么断言不是“加个检查框”就完事了?很多人第一次在 JMeter 里点开“添加 → 断言 → 响应断言”,填上“包含文本:success”,跑完看绿色小勾就以为接口测试闭环了。我带过三届测试团队,新同事交来的脚本里&#…...

2026毕业答辩PPT模板实测:三个平台的真实体验与避坑建议
又到毕业答辩季,不少同学论文写完了,却被PPT卡住:排版乱、配色杂、结构不清,明明内容扎实,呈现效果却大打折扣。作为经常接触办公工具的博主,我实测了几个常见的PPT模板与制作平台,重点针对本科…...

开源 AI Agent Harness Engineering 模型与闭源模型的对比
开源 AI Agent Harness Engineering 模型与闭源模型的对比 摘要 如果把AI Agent比作自动驾驶汽车,那么AI Agent Harness就是这辆车的操作系统:它负责管控任务规划、工具调用、记忆管理、容错重试等所有核心逻辑,是Agent落地工程化的核心支撑…...

LDDC终极指南:如何快速获取精准的逐字歌词
LDDC终极指南:如何快速获取精准的逐字歌词 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地址: https:/…...

终极指南:如何用AhabAssistantLimbusCompany彻底解放《Limbus Company》游戏时间
终极指南:如何用AhabAssistantLimbusCompany彻底解放《Limbus Company》游戏时间 【免费下载链接】AhabAssistantLimbusCompany AALC,PC端Limbus Company小助手。AALC,Limbus Company Assistant on PC 项目地址: https://gitcode.com/gh_mi…...
第1小节:光学物镜核心原理)
0601光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第1小节:光学物镜核心原理
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第1小节:光学物镜核心原理(硬核无水分,从物理本质到工程实现) 前置硬核声明 EUV物镜是光刻机的“原子级眼睛”,13.5nm波长决定透射方案…...

如何高效配置Diva Mod Manager:初音未来MOD管理完整操作指南
如何高效配置Diva Mod Manager:初音未来MOD管理完整操作指南 【免费下载链接】DivaModManager 项目地址: https://gitcode.com/gh_mirrors/di/DivaModManager Diva Mod Manager是一款专为《初音未来:Project Diva Mega Mix》设计的MOD管理工具&a…...

Multisim 13.0 保姆级教程:手把手教你搭建丙类谐振功放,从波形观察到参数分析
Multisim 13.0 丙类谐振功放仿真全流程实战指南 在电子工程领域,高频电路设计一直是让初学者望而生畏的课题。传统实验室受限于设备成本和操作风险,很难为学生提供充分的实践机会。而Multisim作为电路仿真领域的标杆工具,为学习者打开了一扇安…...