MySQL 索引原理以及 SQL 优化
索引
- 索引:一种有序的存储结构,按照单个或者多个列的值进行排序。
- 索引的目的:提升搜索效率。
- 索引分类:
- 数据结构
- B+ 树索引(映射的是磁盘数据)
- hash 索引(快速锁定内存数据)
- 全文索引
- 将存储在数据库中的整本书和整篇文章中的任意内容信息查找出来的技术。
- 在短字符串中用 LIKE %;在全文索引中用 match 和 against。
- 一般使用 elasticsearch。
- 物理存储
- 聚集索引(聚簇索引):主键所对应的 B+ 树。(包含主键 ID 和表数据)
- 辅助索引(二级索引):除了主键之外的其它索引。(只包含 key 和主键 ID)
- 回表查询:辅助索引 B+ 树通过 key 查找到主键 ID,然后通过主键 ID 查找聚簇索引 B+ 树从而得到表记录。
struct zcoder_tb {int id; // primary keystring name; // keystring phone; // keyshort age; }; map<int, zcoder_tb> // 聚簇索引 map<string, int> // 辅助索引 map<string, int> // 辅助索引 - 列属性
- 主键索引:非空唯一索引,一个表只有一个主键索引;
在 innodb 中,主键索引的 B+ 树包含表数据信息。PRIMARY KEY(key1, key2) - 唯一索引:不可以出现相同的值,可以有 NULL 值。
UNIQUE(key1, key2) - 普通索引:允许出现相同的索引内容 。
INDEX(key1, key2) -- OR KEY(key1, key2) - 前缀索引:只比较长字符串的前几个字符。
- 主键索引:非空唯一索引,一个表只有一个主键索引;
- 列的个数
- 单列索引
- 组合索引:对表上的多个列进行索引。
INDEX(key1, key2) UNIQUE(key1, key2) PRIMARY KEY(key1, key2)
- 数据结构
- 索引代价
- 占用空间(有多个索引,就有多个 B+ 树)。
- 维护的代价:DML 操作变慢(如果修改的字段有索引(非聚簇索引),除了要修改聚簇索引 B+ 树,还要修改对应的辅助索引 B+ 树)。
- 索引的使用场景
- where
- group by
- order by
- 不使用索引的场景
- 不使用 where / / /group by / / /order by
- 列中的数据区分度不高
- 经常修改的列
- 表数据量少
- innodb 中 B+ 树(多路平衡搜索树)
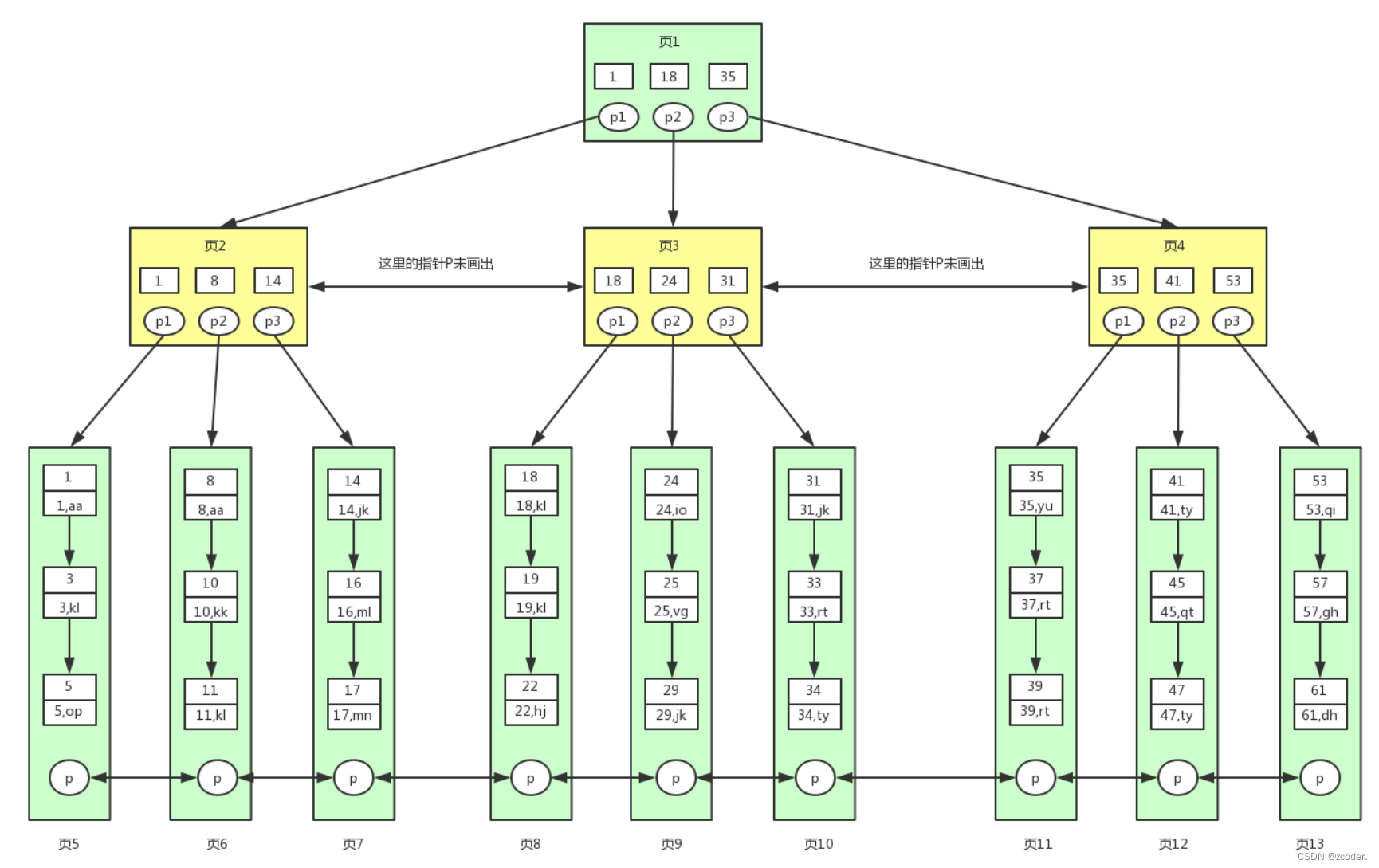
- 特征:
- 非叶子节点只存储索引信息(只存储 key)。
- 叶子节点还存储数据信息(存储 key 和 value)。
- 叶子节点之间依次相连。
- 节点的大小为 16 KB,映射的是连续的磁盘页(通过 mmap 映射磁盘数据)。
- 一个叶子节点至少存储两行数据,如果某一行数据大于 16 KB,则会截取一部分数据进行存储,并保留一个地址位(记录另一个 B+ 树所对应的地址),然后把剩余的数据存储在另一个 B+ 树中。
- 为什么采用 “多路” 的树结构
- 一个节点多条链路,相较于平衡二叉搜索树是一个更加矮胖的结构,树的高度较低,较少的磁盘 IO 次数来索引数据。
- 为什么非叶子节点只存储索引信息
- B+ 树节点映射固定大小的磁盘数据,可以包含更多的索引信息,能快速锁定数据所在叶子节点的位置。
- 为什么叶子节点依次相连
- 便于范围查询,避免中序遍历回溯去查找下一个节点。
- 索引信息和数据信息的分层管理,便于高效地组织磁盘数据,快速实现单点和范围查询。
- 特征:
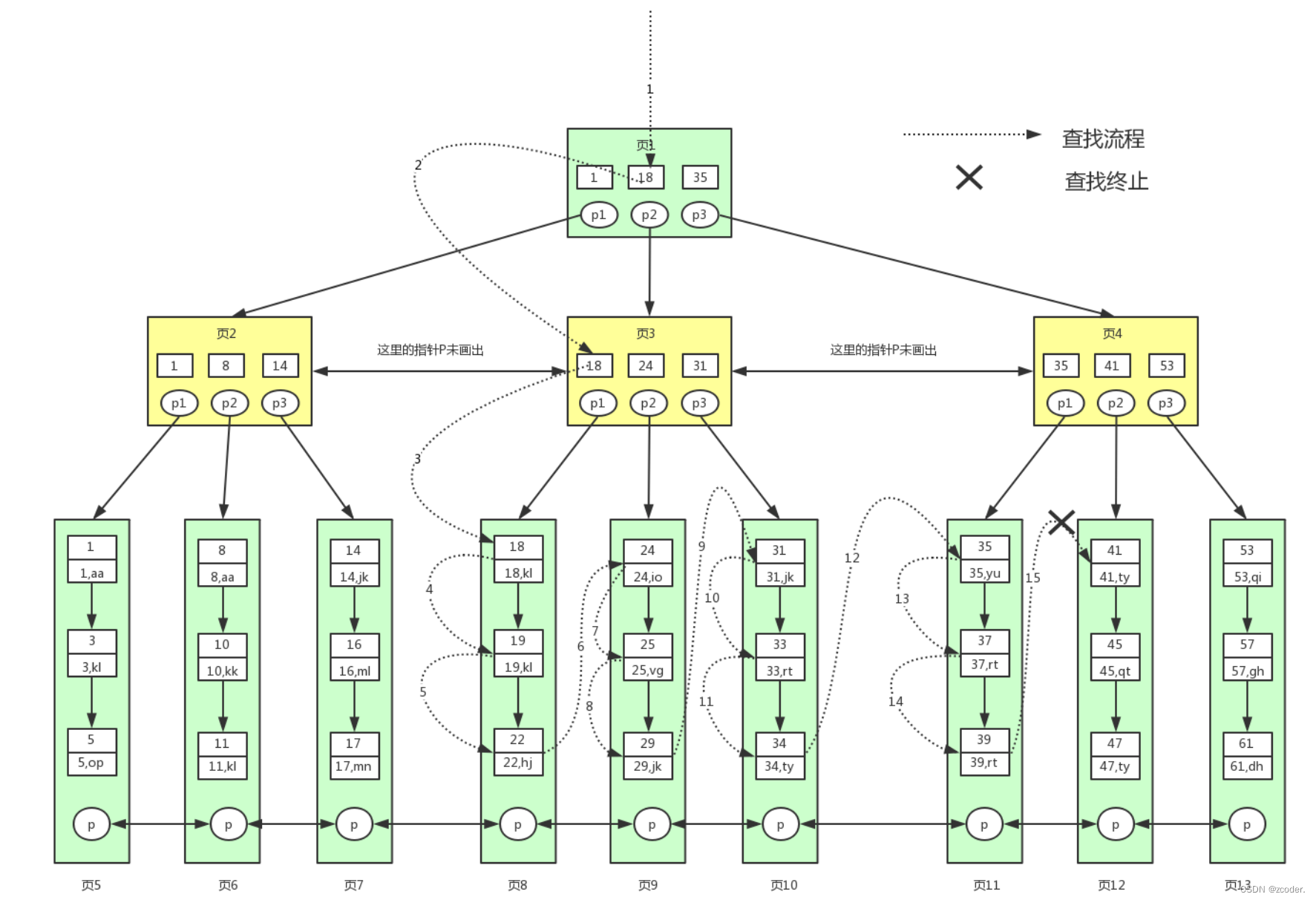
- 聚簇索引查找流程
select * from user where id >= 18 and id < 40;
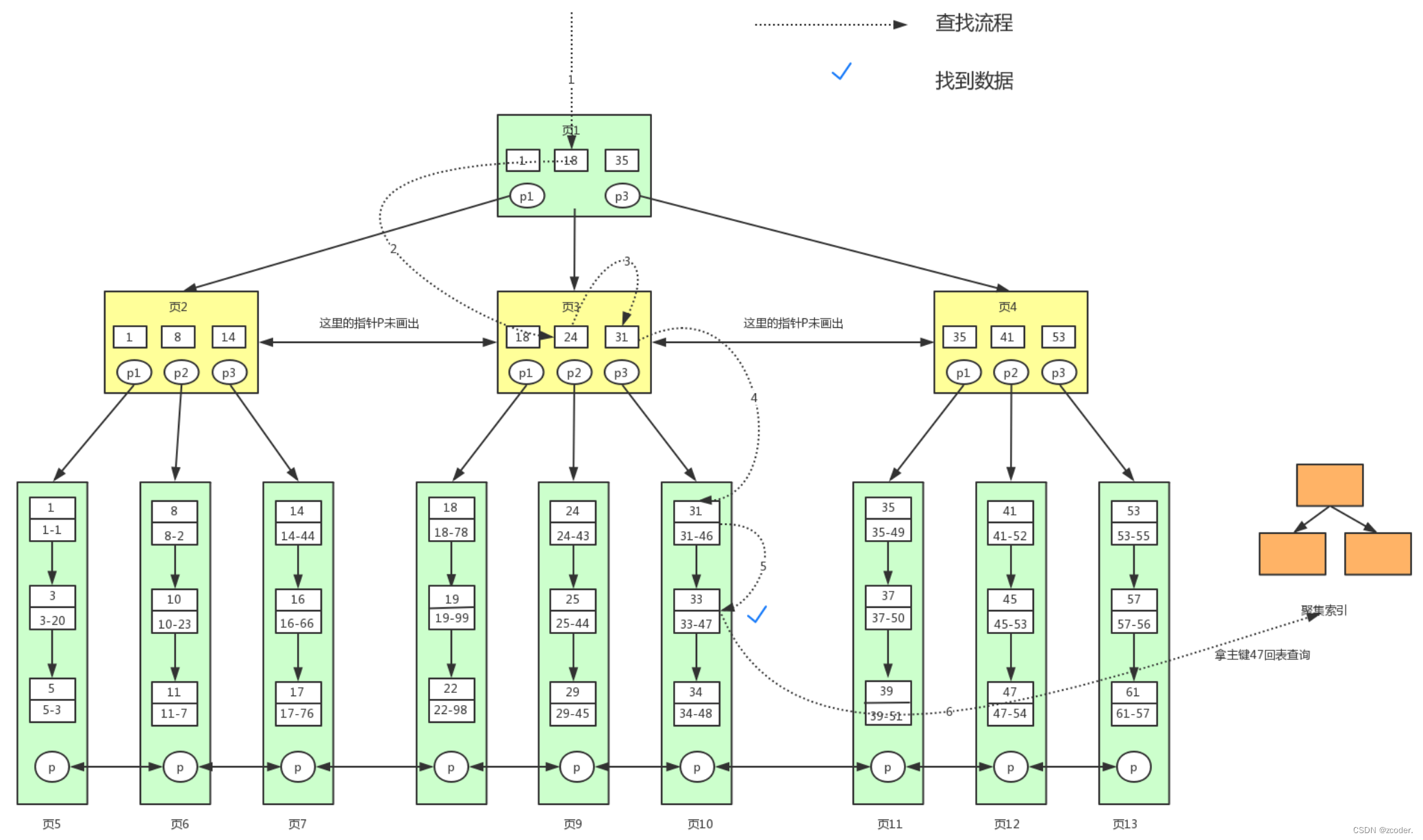
- 辅助索引查找流程
- 辅助索引的叶子节点不包含行记录的全部数据,只存储了用来排序的 key 和一个 bookmark,该书签存储了聚集索引的 key。
-- 某个表 包含 id、name、lockyNum; id是主键,lockyNum 是辅助索引;
select * from user where lockyNum = 33;
- innodb 体系结构

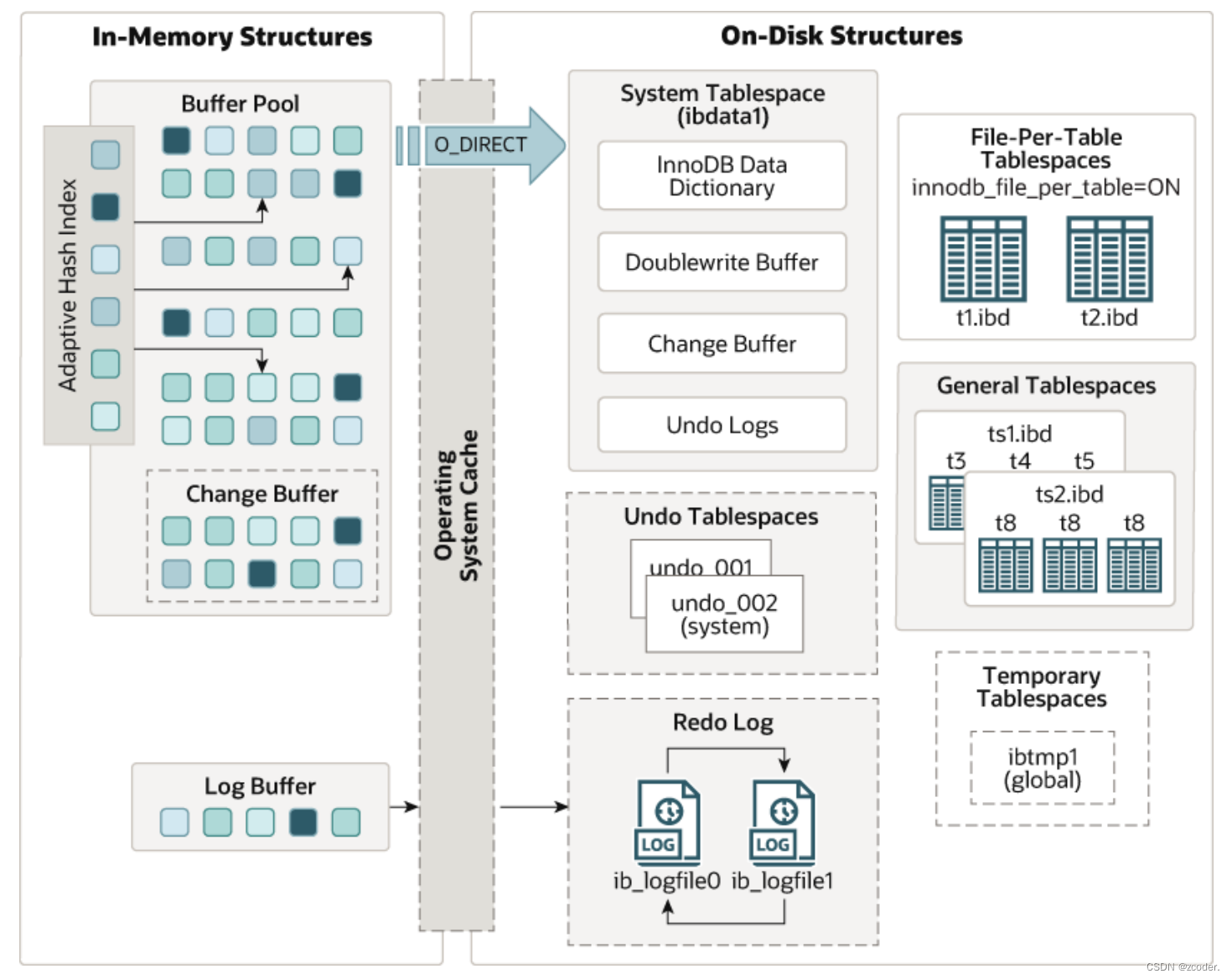
- Buffer Pool
- 缓存表和索引数据( 聚簇索引 B+ 树的数据)。
- 采用 LRU 算法,只缓存比较热的数据。
- 缓存大小为 128 MB。
- 有三个链表组织数据
- free list 组织 Buffer Pool 中未使用的缓存页。
- flush list 组织 Buffer Pool 中的脏页,也就是待刷磁盘的页。
- lru list 组织 Buffer Pool 中的冷热数据,当 Buffer Pool 没有空闲页时,将把 lru list 中最久未使用的数据淘汰。
- Buffer Pool 中的数据修改没有刷到磁盘,怎么确保内存中数据安全(mysql 关闭时,内存数据丢失)?
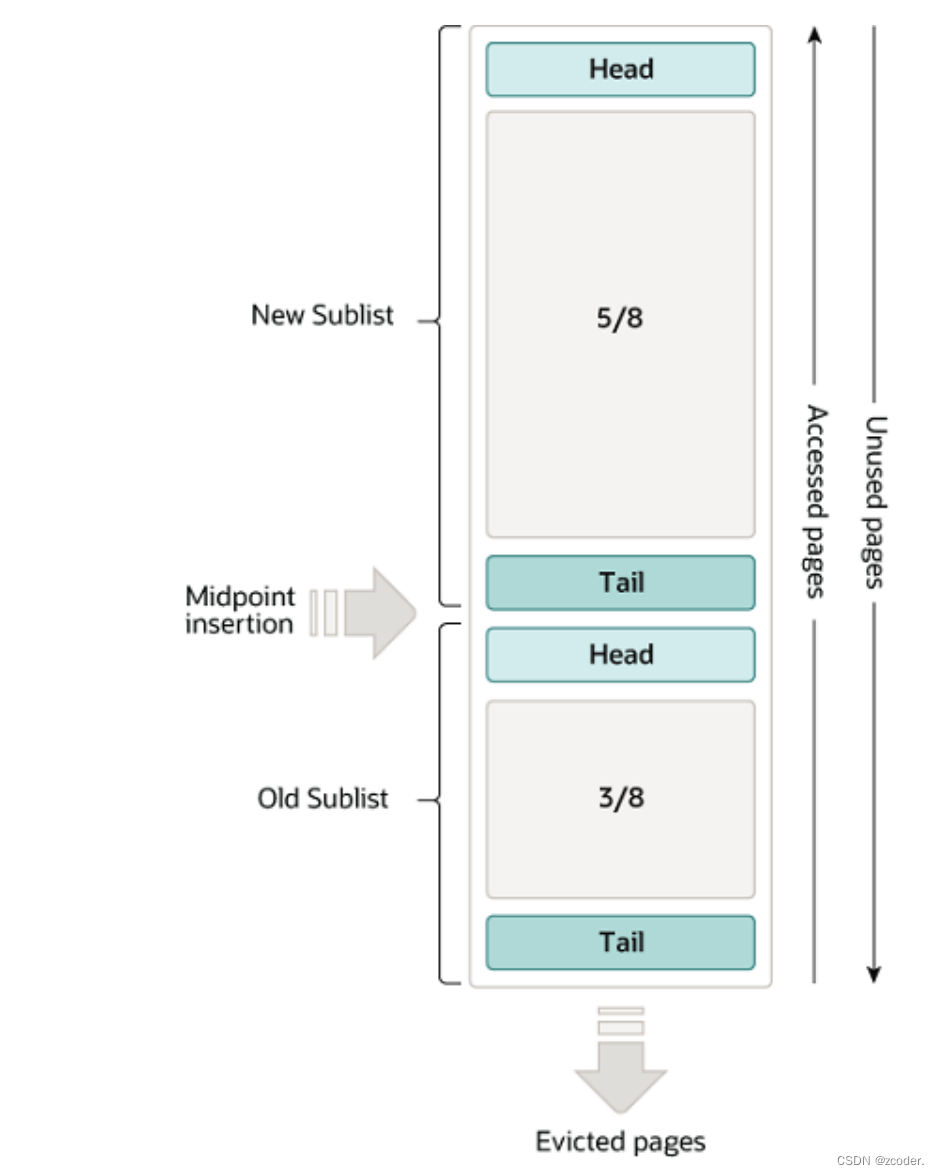
- Change Buffer
- Change Buffer 缓存辅助索引的数据变更(DML 操作),Change Buffer 中的数据将会异步 merge 到 Buffer Pool 中。
- Buffer Pool
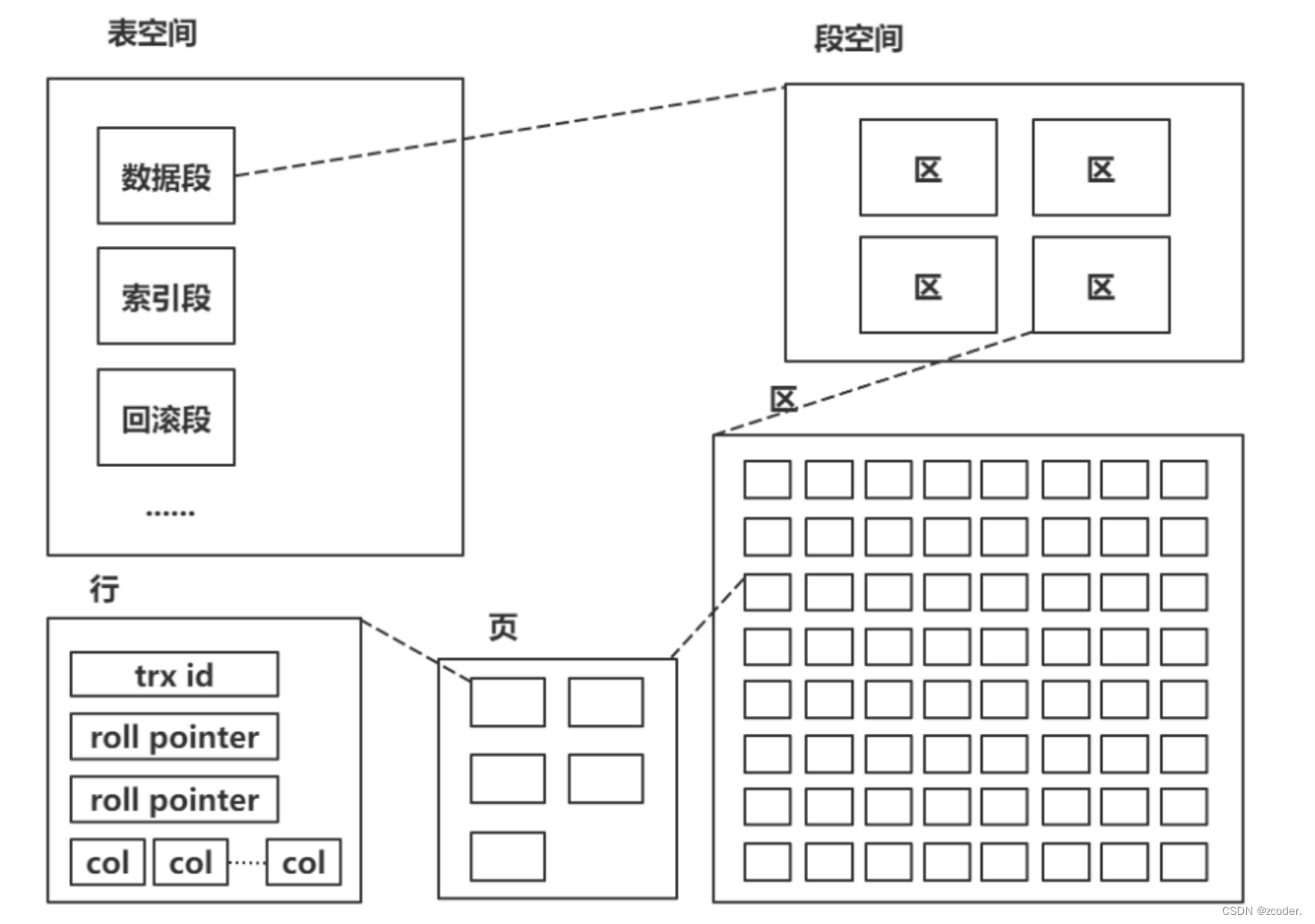
索引存储
- innodb 由段、区、页组成,段分为数据段、索引段、回滚段等。区大小为 1 MB(一个区由 64 个连续页构成),页的默认值为 16 KB,页为逻辑页,磁盘物理页大小一般为 4KB 或者 8KB。
- 为了保证区中的页连续,存储引擎一般一次从磁盘中申请 4~5 个区。
- 顺序内存 IO(数组) > > >> >> 随机内存 IO(红黑树) ≈ \approx ≈ 顺序磁盘 IO > > >> >> 随机磁盘 IO
索引覆盖
- 一种数据查询方式。
- 针对的是辅助索引。
- 直接通过辅助索引 B+ 树就能获取要查询的值,而无需通过回表查询。
- 在 select 中尽量写我们所需要的字段。
最左匹配规则
- 针对组合索引。
- 从左到右依次匹配,遇到 > 、 < 、 b e t w e e n 、 l i k e >、<、between、like >、<、between、like 就停止匹配。
- 尽量扩展索引,而不是单独创建索引。
索引下推
- 目的:减少回表次数,减少 server 层和存储引擎层的交互次数,从而提升查询效率。
- 对象:辅助索引(普通索引和联合索引场景居多)。
- 5.6 版本后支持。
- 没有索引下推机制:server 层向存储引擎层请求数据,在 server 层根据索引条件进行数据过滤。
- 有索引下推:将索引条件判断下推到存储引擎中过滤数据,最终由存储引擎进行数据汇总返回给 server 层。
索引失效
- where
- or 或 and,包含非索引字段。
- in 子查询。
- LIKE 模糊查询,通配符 % 开头。
explain select * from zcoder_tb where name like '%张'; - 索引字段参与运算。
from_unixtime(idx) = '2024-02-21'; # 索引失效 idx = unix_timestamp("2024-02-21") # 索引有效 - 索引字段发生隐式转换。
- 将列隐式转换为某个类型,实际等价于在索引列上作用了隐式转换函数。
- 在索引字段上使用 NOT、<> 、!= 。
id <> 0; # 索引失效 idx > 0 or idx < 0; # 索引有效 - 组合索引中,没有使用第一列索引。
索引原则
- 查询频次较高且数据量大的表建立索引,索引选择使用频次较高,过滤效果好的列或者组合。
- 使用短索引,节点包含的信息多,较少磁盘 IO 操作。比如: smallint,tinyint。
- 对于组合索引,考虑最左侧匹配原则和索引覆盖。
- 尽量选择区分度高的列作为索引,该列的值相同的越少越好。
- 尽量扩展索引,在现有索引的基础上,添加复合索引,最多 6 个索引。
- 不要 select *,尽量只列出需要的列字段,方便使用索引覆盖。
- 索引列,列尽量设置为非空。
- 对于很长的动态字符串,考虑使用前缀索引。 注意:前缀索引不能做 order by 和 group by。
有时候需要索引很长的字符串,这会让索引变的大且慢。 通常情况下可以使用某个列开始的部分字符串作为索引,这样大大的节约索引空间,从而提高索引效率。 但这会降低索引的区分度,索引的区分度是指不重复的索引值和数据表记录总数的比值。 索引的区分度越高则查询效率越高,因为区分度更高的索引可以让 MySQL 在查找的时候过滤掉更多的行。 对于 BLOB , TEXT , VARCHAR 类型的列,必要时使用前缀索引。 因为 MySQL 不允许索引这些列的完整长度,使用该方法的诀窍在于要选择足够长的前缀以保证较高的区分度。select count(distinct left(name,3))/count(*) as sel3, count(distinct left(name,4))/count(*) as sel4, count(distinct left(name,5))/count(*) as sel5, count(distinct left(name,6))/count(*) as sel6, from user; alter table user add key(name(4)); - 可选:开启自适应 hash 索引或者调整 Change Buffer。
select @@innodb_adaptive_hash_index; set global innodb_adaptive_hash_index=1; -- 默认是开启的select @@innodb_change_buffer_max_size; -- 默认值为 25,表示最多使用 1/4 的缓冲池内存空间,最大值为 50 set global innodb_change_buffer_max_size=30;
出现了 SQL 比较慢,如何解决?
- 找到 SQL 语句
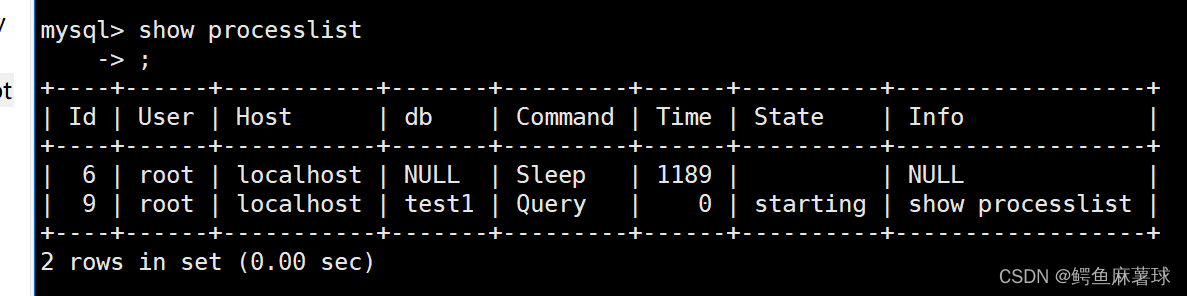
- show processlist
show processlist:查看连接线程,可以查看此时线上运行的 SQL 语句。 如果要查看完整的 SQL 语句:SHOW FULL PROCESSLIST, 然后优化该语句。 - 开启慢日志查询
-- 查看 SHOW GLOBAL VARIABLES LIKE 'slow_query%'; SHOW GLOBAL VARIABLES LIKE 'long_query%'; -- 设置 SET GLOBAL slow_query_log = ON; -- on 开启,off 关闭 SET GLOBAL long_query_time = 4; -- 单位秒;默认 10s;此时设置为 4s # 或者修改配置 slow_query_log = ON long_query_time = 4 slow_query_log_file = D:/mysql/mysql57-slow.log# 查找最近 10 条慢查询日志 mysqldumpslow -s t -t 10 -g 'select' D:/mysql/mysql57-slow.log
- show processlist
- 分析 SQL 语句
- 索引
- where
- group by
- order by
- SQL 语句
- in 和 not in 优化成联合查询
- 减少联合查询
- 工作中不要用 age 字段,而是存储他的生日(年月日)
- 索引
主键选择
- innodb 中表是索引组织表,每张表有且仅有一个主键。
- 如果显式设置 PRIMARY KEY,则该 key 作为该表的主键。
- 如果没有显式设置,则从非空唯一索引中选择:
- 只有一个非空唯一索引,则选择该索引为主键。
- 有多个非空唯一索引,则选择声明的第一个作为主键。
- 没有非空唯一索引,则自动生成一个 6 字节的 _rowid 作为主键。
相关文章:
MySQL 索引原理以及 SQL 优化
索引 索引:一种有序的存储结构,按照单个或者多个列的值进行排序。索引的目的:提升搜索效率。索引分类: 数据结构 B 树索引(映射的是磁盘数据)hash 索引(快速锁定内存数据)全文索引 …...

C++学习Day08之函数模板和普通函数的区别以及调用规则
目录 一、程序及输出1.1 区别1.1.1 自动类型推导,不可以发生隐式类型转换的1.1.2 普通函数 可以发生隐式类型转换 1.2 调用规则 二、分析与总结 一、程序及输出 1.1 区别 1.1.1 自动类型推导,不可以发生隐式类型转换的 1.1.2 普通函数 可以发生隐式类型…...
Kaggle实践之《Home Credit Default Risk》的逐步优化
记录下每一次的改进及其score。 1、只用训练集的特征简单处理 特征只用训练集的特征,把string型的特征全部进行one-hot转化,然后随机1:4分成测试集训练集,模型也调参直接出结果。 最终的score是训练集80.13%、验证集76.33%、线上74.28%。 …...
django rest framework 学习笔记-实战商城2
01收货地址模型类和视图定义_哔哩哔哩_bilibili 本博客借鉴至大佬的视频学习笔记 地址信息的管理:增删改查的实现 # 序列化器配置 class AddrSerializer(serializers.ModelSerializer):"""收货地址的模型序列化器"""class Meta:mo…...

WEB 3D技术 three.js 3D贺卡(4) 添加鼠标滚轮移动屏幕 改变贺卡文字功能
好,上文 WEB 3D技术 three.js 3D贺卡(3) 点光源灯光动画效果 那么 我们来做一下 鼠标滚动相机和滚动时不同文字的切换 首先 我们要设置多个场景 其实也不能完全叫场景 也可以说多个位置 反正简单说就是多个位置 展现多个场景 我们先在代码的最下面 加上一个对象数…...
爬虫在网页抓取的过程中可能会遇到哪些问题?
在网页抓取(爬虫)过程中,开发者可能会遇到多种问题,以下是一些常见问题及其解决方案: 1. IP封锁: 问题:封IP是最常见的问题,抓取的目标网站会识别并封锁频繁请求的IP地址。 解决方案…...

Eclipse中Run As On Server和Run As Java Application
一、名词释义 run java application (作为Java应用程序运行)是运行 java main方法。 run on server是启动一个web 应用服务器。 二、两者的区别 Eclipse中可以创建java project 也可以创建java web poject 。java project是可以直接在命令行运行,或者…...
【MySQL】库的操作——MySQL数据库 、库的操作、表的操作、字符集和校验规则、备份和恢复
文章目录 MySQL1. 库的操作2. 表的操作3. 字符集和校验规则3.1 查看系统默认字符集以及校验规则3.2 查看数据库支持的字符集3.3 查看数据库支持的字符集校验规则 4. 备份和恢复4.1 备份4.2 还原 MySQL 1. 库的操作 连接服务器 mysql -h 127.0.0.1 -P 3306 -u root -pmysql -u…...

pytorch 用F.normalization的逆归一化如何操作
逆归一化的时候再把这个数乘回去就行了 magnitude a.norm(p2, dim1, keepdimTrue) # NEW atorch.nn.functional.normalize(a, p2, dim1) a_or a* magnitude # NEW print(a_or) Outputs: tensor([]1,2,3)...

LabVIEW多通道压力传感器实时动态检测
LabVIEW多通道压力传感器实时动态检测 介绍了一种基于LabVIEW的多通道压力传感器实时动态检测系统,解决压阻式压力传感器温度补偿过程的复杂度,提高测量的准确性。通过自动轮询检测方法,结合硬件检测模型和多通道检测系统设计,本…...

Jenkins解决Host key verification failed (2)
Jenkins解决Host key verification failed 分析原因情况 一、用OpenSSH的人都知ssh会把你每个你访问过计算机的公钥(public key)都记录在~/.ssh/known_hosts。当下次访问相同计算机时,OpenSSH会核对公钥。如果公钥不同,OpenSSH会发出警告,避免…...
C#,数值计算,矩阵的乔莱斯基分解(Cholesky decomposition)算法与源代码
一、安德烈路易斯乔尔斯基 安德烈路易斯乔尔斯基出生于法国波尔多以北的查伦特斯海域的蒙古扬。他在波尔多参加了Lyce e,并于1892年11月14日获得学士学位的第一部分,于1893年7月24日获得第二部分。1895年10月15日,乔尔斯基进入莱科尔理工学院…...

docker 备份 mysql
使用 Docker 执行 MySQL 备份是一个实用的操作,可以帮助你确保数据的安全性和可恢复性。这里有一步步的指导帮你完成: 1. 确定 MySQL 容器名称或 ID 首先,你需要知道运行 MySQL 数据库的容器的名称或 ID。可以通过下面的命令查看所有正在运…...
使用C# Net6连接国产达梦数据库记录
达梦官网:http://www.dameng.com/ 1 下载达梦并进行安装 下载地址:官网首页——服务与合作——下载中心(https://www.dameng.com/list_103.html) 根据需要自行下载需要的版本,测试版本为:x86 win64 DM8版…...
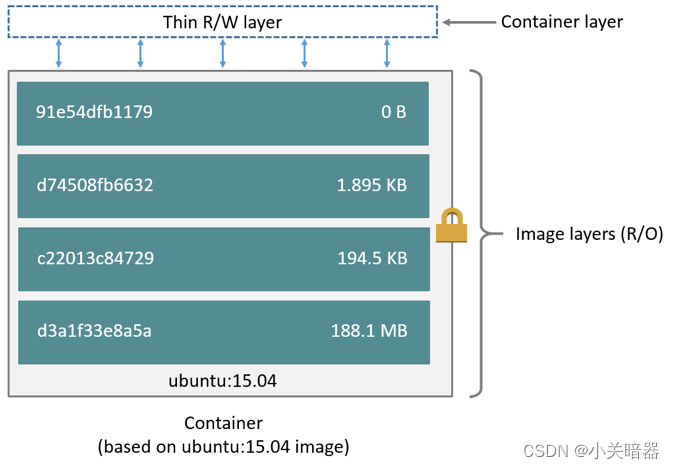
docker (八)-dockerfile制作镜像
一 dockerfile dockerfile通常包含以下几个常用命令: FROM ubuntu:18.04 WORKDIR /app COPY . . RUN make . CMD python app.py EXPOSE 80 FROM 打包使用的基础镜像WORKDIR 相当于cd命令,进入工作目录COPY 将宿主机的文件复制到容器内RUN 打包时执…...
springcloud-网关(gateway)
springcloud-网关(gateway) 概述 \Spring Cloud Gateway旨在提供一种简单而有效的方式来路由到API,并为其提供跨领域的关注,如:安全、监控/指标和容错 常用术语 Route(路由): 网关的基本构件。它由一个ID、一个目的地…...
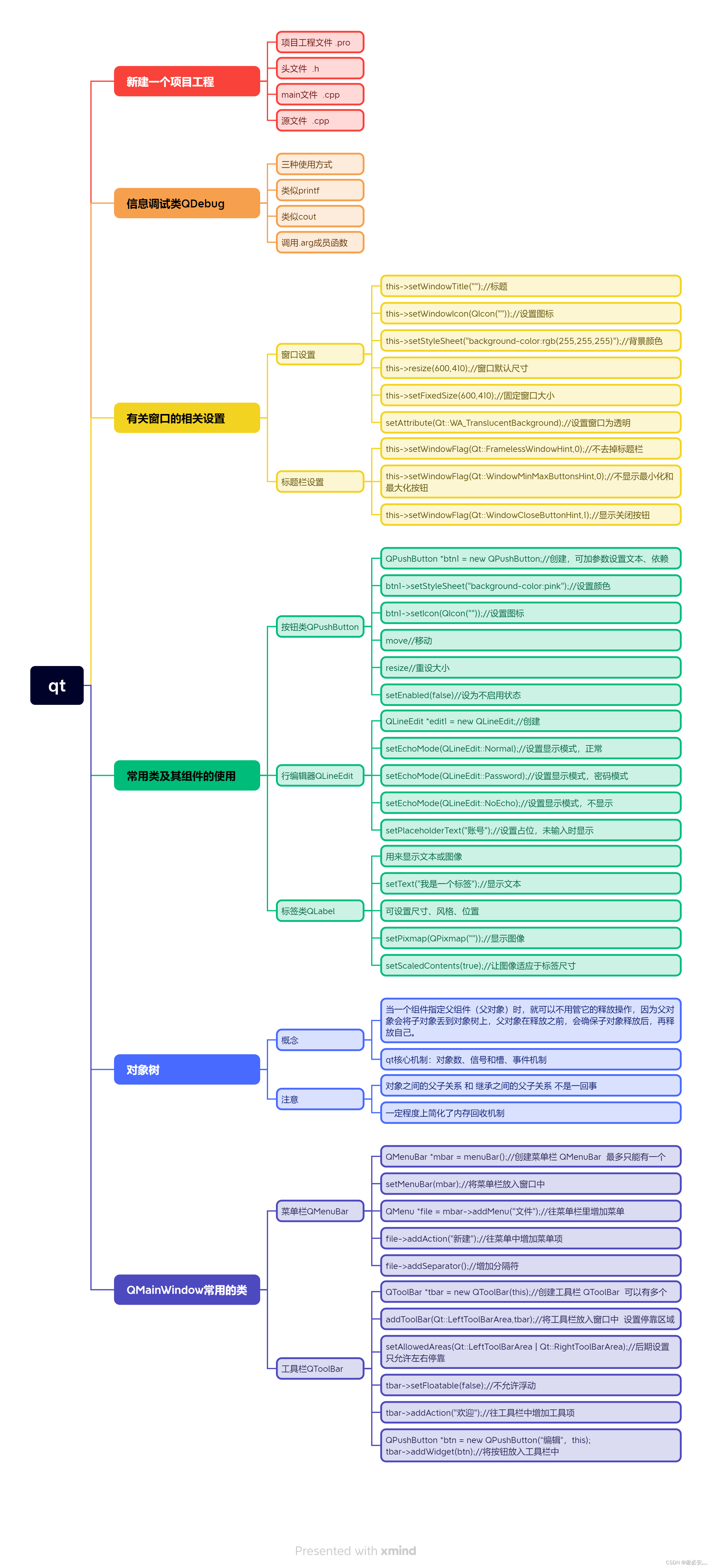
2.20 day2 QT
自由发挥登录窗口的应用场景,实现一个登录窗口界面 #include "widget.h"Widget::Widget(QWidget *parent): QWidget(parent) {//窗口相关设置this->setWindowTitle("登入页面"); //设置 窗口 标题this->setWindowIcon(QIcon("D:…...
【C++语法基础】4.分支和循环结构(✨新手推荐阅读)
前言 在C编程中,分支和循环结构是控制程序流程的基本工具。分支结构允许程序根据特定条件执行不同的代码块,而循环结构则允许程序重复执行某个代码块。 分支结构 if 语句 if 语句是最基本的分支结构,它根据条件的真假来决定是否执行某段代…...
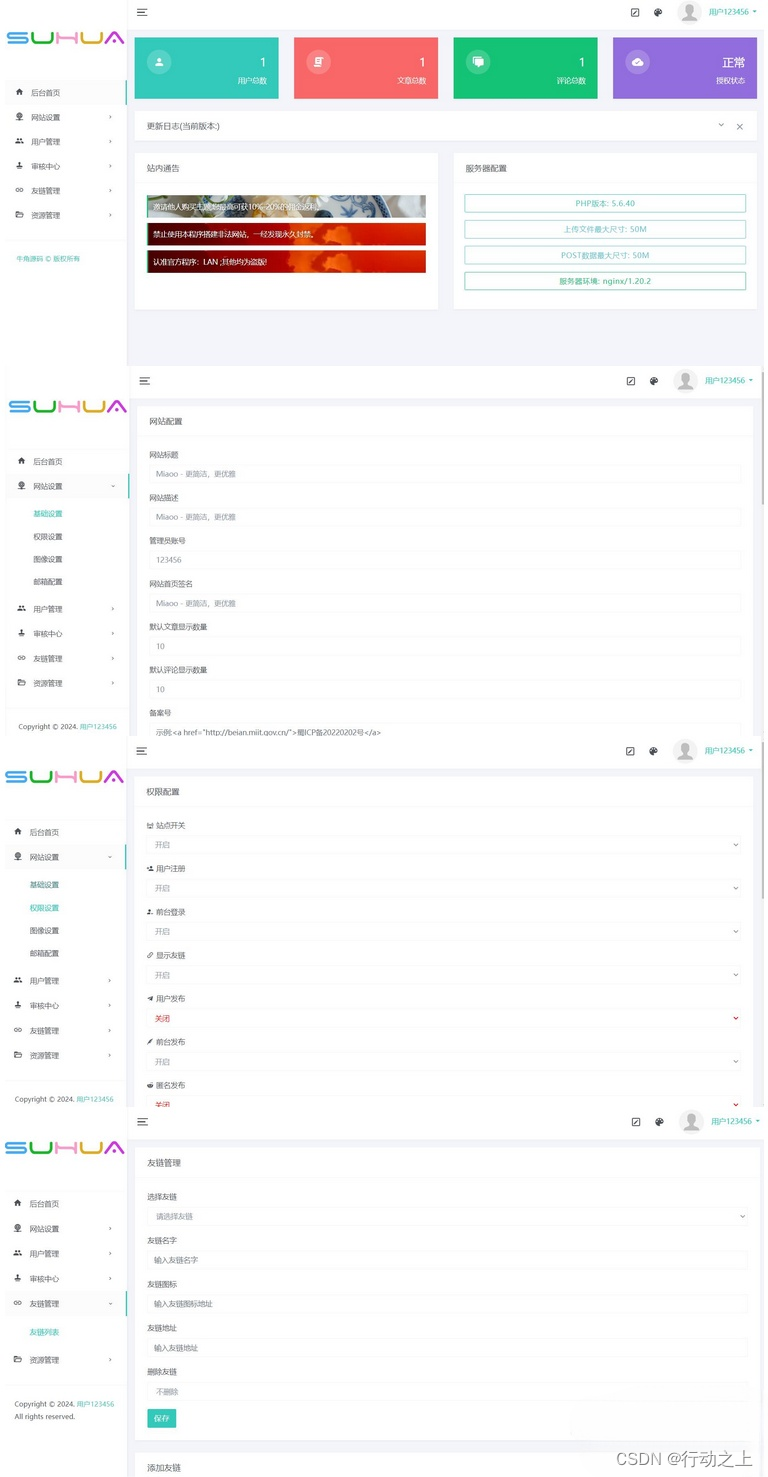
朋友圈程序全开源版源码,附带系统搭建教程
前台一键发布图文,视频,音乐。发布内容支持定位或自定义位置信息。支持将发布内容设为广告模式消息站内通知或邮件通知。支持其他用户注册,支持其他用户发布文章,管理自己的文章。拥有丰富的后台管理功能,一键操作。安装环境 Nginx ≥1.22 …...

思维方式系列文章目录 -《清单革命》实践
思维方式系列文章目录 -《清单革命》 文章目录 思维方式系列文章目录 -《清单革命》前言一、《清单革命》思维导图二、清单制作原则 前言 请记住,现在开始心灵转变,人人都会犯错,而错误分为:无知之错、无能之错。 无知之错&#…...

城市综合管廊远程监控与智慧运维系统方案
某新区城市建设综合管廊,涵盖电力、燃气、供排水、通信等多种生命线,部署有风机、排水泵、电动阀门、气体传感器、温湿度传感器、液位传感器等设备,核心控制器为西门子PLC(S7协议),负责采集管廊内气体浓度、…...

5分钟掌握GoReleaser:自动化发布Go项目的终极指南 [特殊字符]
5分钟掌握GoReleaser:自动化发布Go项目的终极指南 🚀 【免费下载链接】goreleaser Release engineering, simplified 项目地址: https://gitcode.com/gh_mirrors/go/goreleaser 还在为每次发布Go项目而烦恼吗?手动构建二进制文件、打包…...

Wayback Machine浏览器扩展:时光倒流神器,一键保存网页历史
Wayback Machine浏览器扩展:时光倒流神器,一键保存网页历史 【免费下载链接】wayback-machine-webextension A web browser extension for Chrome, Firefox, Edge, and Safari 14. 项目地址: https://gitcode.com/gh_mirrors/wa/wayback-machine-webex…...

3步解锁跨平台系统部署:WinDiskWriter让macOS用户轻松制作Windows启动盘
3步解锁跨平台系统部署:WinDiskWriter让macOS用户轻松制作Windows启动盘 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UE…...
)
占坑uvm之stop_sequence()
最近遇到个仿真报错:parent sequence * should not finish before all items from itself and items from descendent sequences are peocessed.观察log发现,目前已进去reset区间,各sequencer正在进行stop_sequences。结合仿真log错误信息提示…...

5步快速上手ComfyUI JoyCaption插件:AI图片字幕生成的终极指南
5步快速上手ComfyUI JoyCaption插件:AI图片字幕生成的终极指南 【免费下载链接】ComfyUI_SLK_joy_caption_two ComfyUI Node 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_SLK_joy_caption_two 你知道吗?现在你可以用AI为任何图片自动生…...

免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南
免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经因为忘记压…...

Windows进程注入技术深度解析:从DLL注入到反射式加载
1. 项目概述与核心价值在Windows安全研究、恶意软件分析乃至一些高级的软件开发场景中,“进程注入”是一个绕不开的核心技术点。简单来说,它指的是将一个代码模块(通常是DLL)或一段代码(Shellcode)加载到另…...

七牛云:批量将标准存储文件转为归档直读存储
📋 整体流程图 下载安装 qshell → 配置密钥 → 列出符合条件的文件 → 生成批量转换清单 → 执行转换建议先看看不同类型有何区别,选择适合自己的:存储类型_产品简介_对象存储 - 七牛开发者中心https://developer.qiniu.com/kodo/3956/kodo…...

Microchip安卓配件开发平台:MCU与安卓系统高效协同实战指南
1. 项目概述:当单片机巨头拥抱安卓生态作为一名在嵌入式领域摸爬滚打了十几年的老工程师,我经历过从8位机到32位ARM,再到各种RTOS的变迁。但最近几年,一个趋势越来越明显:越来越多的智能设备,特别是那些需要…...