BeautifulSoup的使用与入门
1. 介绍
BeautifulSoup是用来从HTML、XML文档中提取数据的一个python库,安装如下:
pip install beautifulsoup4它支持多种解析器,包括python标准库、lxml HTML解析器、lxml XML解析器、html5lib等。结合稳定性和速度,这里推荐使用lxml HTML解析器。安装:
pip install lxml如果lxml不能正确解析内容,这是可以使用html5lib。安装:
pip install html5lib2. 使用
2.1 一般流程
beautifulsoup的使用流程一般包括:1.导入库 2.实例化对象 3.调用对象
在实例化对象的时候要传入两个参数,一个是待解析的html或xml字符串(markup),另一个是选择的解析器(features)。如果未指定解析器,会调用默认解析器。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_str, 'lxml')
2.2 选择器
要定位到指定的地方提取想要的数据,就需要借助选择器进行定位。beautifulsoup有三种选择器:节点选择器、方法选择器、css选择器。
节点选择器的使用
选取标签:节点选择器是通过HTML标签进行定位的,使用方法是实例化soup对象后直接加.tag,tag就是html标签名。
import requests from bs4 import BeautifulSoupurl = 'https://www.baidu.com' response = requests.get(url=url) response.encoding = response.apparent_encoding soup = BeautifulSoup(response.text, 'lxml') print(soup.a)# out:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
这样选取的缺点是:如果有多个相同标签,只会提取第一个标签,其他的被忽略。
获取标签信息:在获取到的标签的基础上,还可以进一步获取标签名、属性、值
print(soup.a) print(soup.a.name) print(soup.a.attrs) print(soup.a.string)# out:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
a
{'href': 'http://news.baidu.com', 'name': 'tj_trnews', 'class': ['mnav']}
新闻
嵌套选择:如果一个标签里还包含一个子标签,我们还可以通过嵌套选择的方法取出子标签
print(soup.head.title) print(soup.head.title.string)# out:
<title>百度一下,你就知道</title>
百度一下,你就知道
子标签列举: 有两种方式,包括contents(返回列表)、children(返回可迭代对象)。该方法会把所有子标签取出,这样我们就可以拿到指定位置的子标签。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.tr.contents) print(soup.tr.children) for index, child in enumerate(soup.tr.children):print(f'({index}):{child}')# out:
[<th>IP</th>, <th>PORT</th>, <th>匿名度</th>, <th>类型</th>, <th>位置</th>, <th>响应速度</th>, <th>录取时间<div>test</div></th>]
<list_iterator object at 0x000001C4BF512E00>
(0):<th>IP</th>
(1):<th>PORT</th>
(2):<th>匿名度</th>
(3):<th>类型</th>
(4):<th>位置</th>
(5):<th>响应速度</th>
(6):<th>录取时间<div>test</div></th>
父标签列举:.parent会列出标签的父标签,.parents会列出所有的祖先元素并整合在可迭代对象里。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.div.parent) print(soup.div.parents) for index, parents in enumerate(soup.tr.parents):print(f'({index}):{parents}')# out:
<th>录取时间
<div>test</div>
</th>
<generator object PageElement.parents at 0x0000028479C541C0>
(0):<body><tr>
<th>IP</th>
<th>PORT</th>
<th>匿名度</th>
<th>类型</th>
<th>位置</th>
<th>响应速度</th>
<th>录取时间
<div>test</div>
</th>
</tr></body>
(1):<html><body><tr>
<th>IP</th>
<th>PORT</th>
<th>匿名度</th>
<th>类型</th>
<th>位置</th>
<th>响应速度</th>
<th>录取时间
<div>test</div>
</th>
</tr></body></html>
兄弟节点选取: next_sibling获取下一个兄弟节点,next_siblings获取后续所有兄弟节点,previous_sibling获取前一个兄弟节点,previous_siblings获取前面所有兄弟节点。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.th.next_sibling) print(soup.th.next_siblings) print(list(soup.th.next_siblings)[1].previous_sibling) print(soup.th.previous_siblings)# out:
<th>PORT</th>
<generator object PageElement.next_siblings at 0x000001EB1EEB4280>
<th>PORT</th>
<generator object PageElement.previous_siblings at 0x000001EB1EEB4280>
CSS选择器的使用
使用CSS选择器,只需要调用select()方法,结合CSS语法即可定位到元素。
在css语法中,我们可以使用类选择器、id选择器、标签选择器、以及混合使用来定位。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.select('th'))# out:
[<th>IP</th>, <th>PORT</th>, <th>匿名度</th>, <th>类型</th>, <th>位置</th>, <th>响应速度</th>, <th>录取时间<div>test</div></th>]
我们只需传入css同样的定位语法即可 ,返回结果为列表。
获取节点的属性和文本用法与前面的节点选择器相同。
方法选择器的使用
使用方法选择器主要使用其中的find()和findALL()方法,finaALL方法需要传入的参数有name,attrs,text,kwargs。
name为定位条件,可以为标签名如'a',也可以是多个标签名组成的列表,还可以是正则表达式。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.findAll(name='th'))# out:
[<th>IP</th>, <th>PORT</th>, <th>匿名度</th>, <th>类型</th>, <th>位置</th>, <th>响应速度</th>, <th>录取时间<div>test</div></th>]
attrs为属性,可根据属性定位标签。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div id='te'>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.findAll(attrs={"id":"te"}))# out:
[<div id="te">test</div>]
string为文本,可以搜索文本信息,常与其他name或attr混用来获取标签。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div id='te'>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.findAll(name='th', string='匿名度'))# out:
[<th>匿名度</th>]
kwargs为关键字参数,比attr使用更方便,传入指定关键字参数以定位标签。class与python中的关键字冲突了,所以需要加下划线避免冲突。
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div class='te'>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.findAll(class_='te'))# out:
[<div class="te">test</div>]
limit为限制参数,限制返回结果的数量
from bs4 import BeautifulSoup hh = '''<tr><th>IP</th><th>PORT</th><th>匿名度</th><th>类型</th><th>位置</th><th>响应速度</th><th>录取时间<div class='te'>test</div></th></tr>''' soup = BeautifulSoup(hh, 'lxml') print(soup.findAll(name='th', limit=3))# out:
[<th>IP</th>, <th>PORT</th>, <th>匿名度</th>]
find方法 :相比于find_all()方法,除了limit参数不能用,其他参数均与find_all()方法相同,不过find方法只会返回一个值,而不是像find_all返回所有值。
相关文章:

BeautifulSoup的使用与入门
1. 介绍 BeautifulSoup是用来从HTML、XML文档中提取数据的一个python库,安装如下: pip install beautifulsoup4 它支持多种解析器,包括python标准库、lxml HTML解析器、lxml XML解析器、html5lib等。结合稳定性和速度,这里推荐使用lxml HT…...
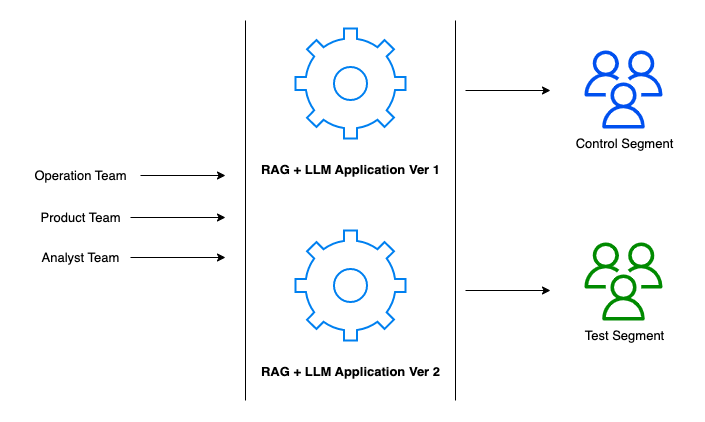
LLM之RAG实战(二十七)| 如何评估RAG系统
有没有想过今天的一些应用程序是如何看起来几乎神奇地智能的?这种魔力很大一部分来自于一种叫做RAG和LLM的东西。把RAG(Retrieval Augmented Generation)想象成人工智能世界里聪明的书呆子,它会挖掘大量信息,准确地找到…...

Linux Docker 关闭开机启动
说说自己为什么需要关闭自启动:Linux中安装Docker后,自启动会占用80和443端口,然后使用自己的SSL认证,导致自己Nginx配置的SSL认证失效,网站通过https打开显示不安全。 Docker是一个容器化平台,它可以让开…...
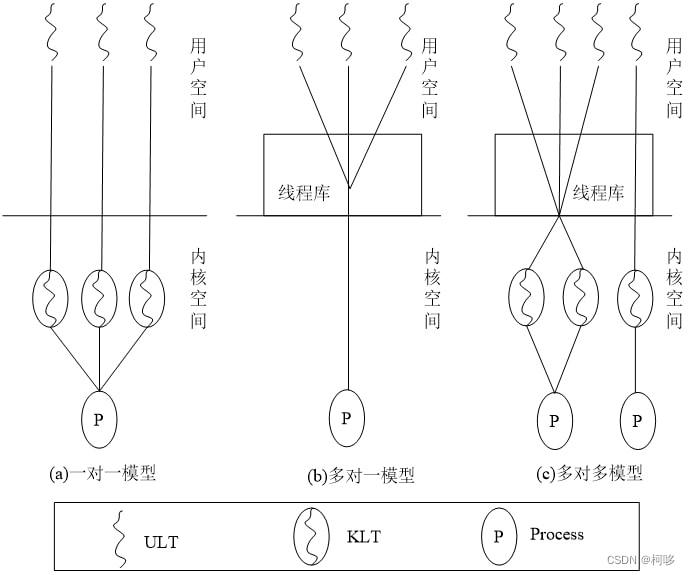
处理器管理补充——线程
传送门:操作系统——处理器管理http://t.csdnimg.cn/avaDO 1.1 线程的概念 回忆:[未引入线程前] 进程有两个基本属性:拥有资源的独立单位、处理器调度和分配的基本单位。 引入线程以后,线程将作为处理器调度和运行的基本单位&…...

RESTful 风格是指什么
RESTful(Representational State Transfer)是一种基于 HTTP 协议的软件架构风格,用于设计网络应用程序的接口。它的设计理念是利用 HTTP 协议中的方法(如 GET、POST、PUT、DELETE 等)来对资源进行 CRUD,使得…...

Python 二维矩阵加一个变量运算该如何避免 for 循环
Python 二维矩阵加一个变量运算该如何避免 for 循环 引言正文方法1------使用 for 循环方法2------不使用 for 循环引言 今天写代码的时候遇到了一个问题,比如我们需要做一个二维矩阵运算,其中一个矩阵是 2x2 的,另一个是 2x1 的。在这个二维矩阵中,其中各个参数会随着一个…...
Nginx 配置详解
官网:http://www.nginx.org/ 序言 Nginx是lgor Sysoev为俄罗斯访问量第二的rambler.ru站点设计开发的。从2004年发布至今,凭借开源的力量,已经接近成熟与完善。 Nginx功能丰富,可作为HTTP服务器,也可作为反向代理服务…...

python读写文件操作的三大基本步骤
目录 基本步骤 常用函数 open()函数 close()函数 read()函数 readlines()函数 readline()函数 write()函数 writelines()函数 with语句 读写操作的应用: 拷贝文件 with 语句的嵌套 逐行拷贝 基本步骤 1. 打开文件:open(filepath, mode, en…...

《Go 简易速速上手小册》第3章:数据结构(2024 最新版)
文章目录 3.1 数组与切片:Go 语言的动态队伍3.1.1 基础知识讲解3.1.2 重点案例:动态成绩单功能描述实现代码扩展功能 3.1.3 拓展案例 1:数据分析功能描述实现代码扩展功能 3.1.4 拓展案例 2:日志过滤器功能描述实现代码扩展功能 3…...

雷达模拟触摸屏,支持tuio\鼠标\Touch
案例展示: 雷达精度测试 星秒雷达互动软件测试 功能说明: 雷达互动系统支持各种品牌雷达,支持4-256点校准(校准点越大精度越高 ,而市场上基本都是4点校准 ,碰到大面积范围无法保证精准度)&…...
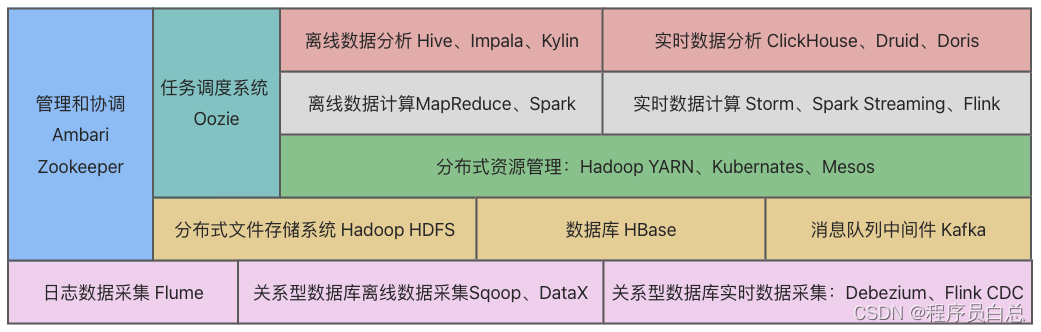
一文了解大数据生态
大数据一词最早指的是传统数据处理应用软件无法处理的过于庞大或过于复杂的数据集。 现在,对“大数据”一词的使用倾向于使用预测分析、用户行为分析或者其他一些从大数据中提取价值的高级数据分析方法,很少用于表示特定规模的数据集。 定义 大数据是…...
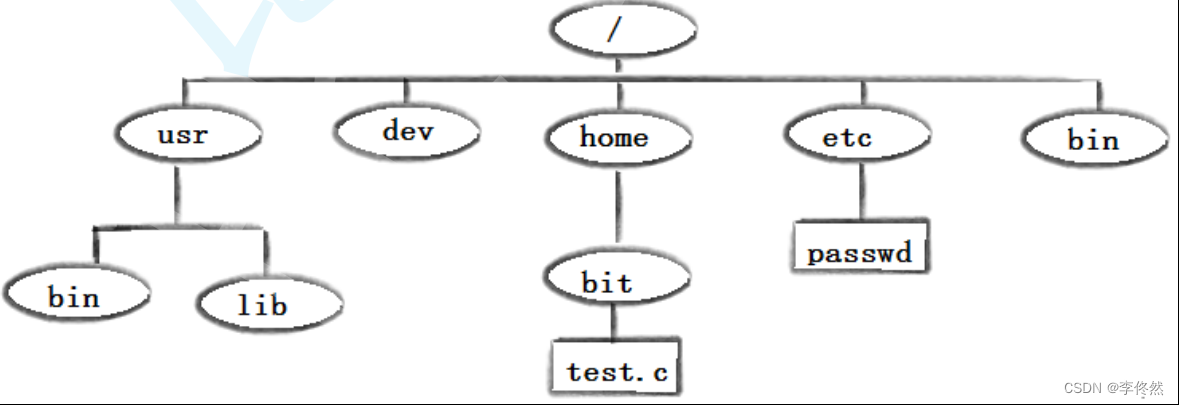
Linux篇:指令
一 基本常识: 1. 文件文件内容文件的属性 2. 文件的操作对文件内容的操作对文件属性的操作 3. 文件的类型: d:目录文件 -:普通文件 4. 指令是可执行程序,指令的代码文件在系统的某一个位置存在的。/u…...
)
Linux eject命令教程:如何控制可移动介质的弹出和收回(附案例详解和注意事项)
Linux eject命令介绍 eject命令在Linux中用于弹出可移动介质,通常是CD-ROM、软盘、磁带或JAZ或ZIP磁盘。您还可以使用此命令来控制一些多盘CD-ROM切换器,一些设备支持的自动弹出功能,以及关闭一些CD-ROM驱动器的光盘托盘。 Linux eject命令…...
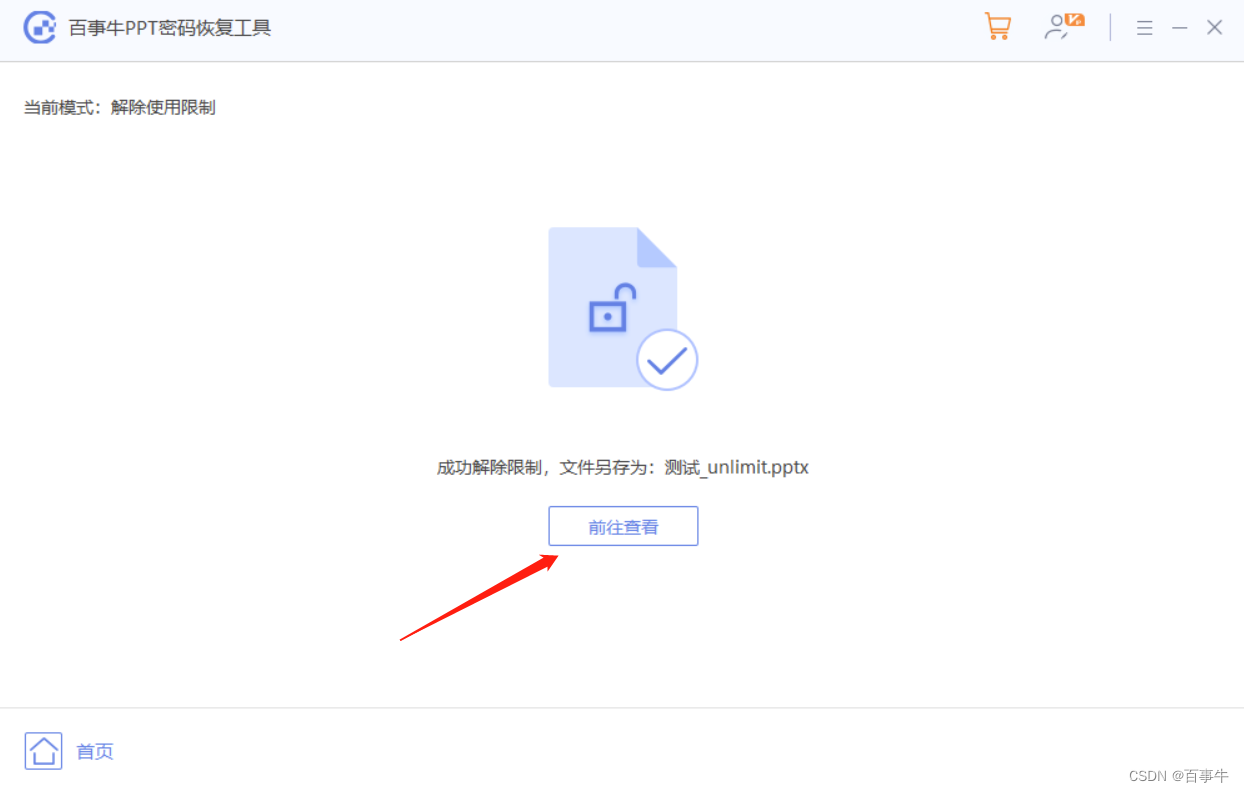
【已解决】PPT无法复制内容怎么办?
想要复制PPT文件里的内容,却发现复制不了,怎么办? 这种情况,一般是PPT文件被设置了以“只读方式”打开,“只读方式”下的PPT无法进行编辑更改,也无法进行复制粘贴的操作。 想要解决这个问题,我…...
六大设计原则 (SOLID)
一、设计原则概述 古人云: 有道无术,术可求.有术无道,止于术. 而设计模式通常需要遵循一些设计原则,在设计原则的基础之上衍生出了各种各样的设计模式。设计原则是设计要求,设计模式是设计方案,使用设计模式的代码则是具体的实现。 设计模式中主要有六大设计原则,简称为SOL…...

深度解析Sora的核心技术
Sora要解决的核心问题 Sora面临的挑战是将不同类型的视觉信息,如视频、文本、图像和声音等,整合为一种共同的表征形式。这种转换是实现统一训练过程的关键,旨在将各类数据集中到一个训练框架中,以便于进行大规模的统一学习。简而…...

设计模式面试系列-02
1. Java 中工厂模式有什么优势? 1、工厂模式是最常用的实例化对象模式,是用工厂方法代替new操作的一种模式。 2、利用工厂模式可以降低程序的耦合性,为后期的维护修改提供了很大的便利。 3、将选择实现类、创建对象统一管理和控制,从而将调用者跟我们的实现类解耦。 2. …...

MKdocs添加顶部公告栏
效果如图: docs/overrides下新建main.html ,针对main.html文件 树状结构如下: $ tree -a . ├── .github │ ├── .DS_Store │ └── workflows │ └── PublishMySite.yml ├── docs │ └── index.md │ └──overrides │…...

Android全新UI框架之常用ComposeUI组件
在Compose中,每个组件都是一个带有Composable注解的函数,被称为Composable。Compose已经预置了很多基于MD设计规范的Composable组件。 在布局方面,Compose提供了Column、Row、Box三种布局组件(感觉跟flutter差不多),类似于传统视图…...

网络防御保护综合练习
一、实验拓扑 二、实验要求 1, Fw1和Fw2组成主备模式的双机热备 2,DMZ区存在两台服务器,现在要求生产区的设备仅能在办公时间(9:00 - 18:00)访问,办公区的设备全天都可以访问。 3,办…...

深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透
深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透 引言 在波场(TRON)生态中,TRC-20 代币标准扮演着至关重要的角色,它不仅是承载如USDT等巨量稳定币的基石,更是连接DeFi、GameFi和NFT等…...

LNMP架构拆分实战:从单机到分布式集群的演进与优化
1. 项目概述:从单机LNMP到分布式架构的必然演进如果你正在运维一个基于LNMP(Linux, Nginx, MySQL/MariaDB, PHP)架构的网站,并且发现随着用户量的增长,网站响应越来越慢,甚至偶尔出现数据库连接失败、页面加…...

如何用SMUDebugTool完全掌控AMD Ryzen处理器性能
如何用SMUDebugTool完全掌控AMD Ryzen处理器性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.com/gh_mir…...

会议记录差点搞砸,直到遇见这个“录音转文字”神器
上周三下午,我差点因为一场两小时的跨部门评审会被老板“请喝茶”。事情是这样的:作为产品经理,我负责主持一场涉及技术、运营、销售三方的季度复盘会。会上大家争论激烈,我一边控场一边记笔记,结果手忙脚乱——技术总…...

HDR 图像的双层结构——元数据生成与 hdrDecompose/hdrCompose 完整解析
文章目录HDR 图到底怎么存的?三个核心操作的关系元数据生成代码详解HDR 分解与合成代码详解HdrMetadataType 四种类型对比像素格式与 HDR 类型对应关系StorageLink 串联四个页面的设计思路踩坑记录写在最后一直以来我以为 HDR 图就是"更亮的图"࿰…...

C++虚函数从原理到实践:多态实现、设计模式与性能优化
1. 项目概述:从“魔法”到“利器”的认知转变虚函数,对于很多刚接触C的开发者来说,常常被看作一种“黑魔法”——知道它能实现多态,但具体怎么用、什么时候用、用不好会有什么坑,心里却没底。我见过不少项目࿰…...

BarTender如何在线刷新许可证
1、在BarTender服务端打开Administration Console注意:此操作需要服务端连接外网,登录本地管理员账户2、点击许可并等待右侧弹出许可证界面选中需要操作的许可证并点击右侧刷新按钮3、许可证刷新成功4、刷新完成后观察刷新后的许可证前方是否有感叹号如果…...

20260520 OVN网络整体实验
OVN网络整体实验 [rootcontroller ~ 16:26:09]# source keystonerc_admin [rootcontroller ~(keystone_admin)]# openstack network agent list --------------------------------------------------------------------------------------------------------------------------…...
)
别再死记硬背了!用Python+DEAP库5分钟搞定NSGA-II多目标优化(附完整代码)
用PythonDEAP库5分钟实现NSGA-II多目标优化实战 当我们需要同时优化多个相互冲突的目标时,比如在机器学习中既要模型精度高又要推理速度快,传统单目标优化方法就捉襟见肘了。NSGA-II(非支配排序遗传算法II)作为多目标优化领域的标…...
)
STM32F103 平行替代方案全面分析(2026 年最新)
STM32F103 作为全球最经典的 Cortex-M3 MCU,凭借成熟的生态和广泛的应用基础统治了中低端嵌入式市场十余年。但近年来受国际供应链波动影响,其价格持续走高(2026 年 5 月 STM32F103C8T6 批量价约 8-12 元,部分型号甚至超过 20 元&…...