【PyTorch][chapter 17][李宏毅深度学习]【无监督学习][ Auto-encoder]
前言:
本篇重点介绍AE(Auto-Encoder) 自编码器。这是深度学习的一个核心模型.
自编码网络是一种基于无监督学习方法的生成类模型,自编码最大特征输出等于输入
Yann LeCun&Bengio, Hinton 对无监督学习的看法.

目录:
-
AE 模型原理
-
De-noising auto-encoder
-
文字检索应用例子(Text Retrieval)
-
影像相似度比较例子 Similar Image Search
- CNN-AE
-
Pytorch 例子
-
堆叠自编码网络(Stacked Autoencoders)
一 AE模型原理
1.1 模型简介

AE 编码集主要由两个部分组成:
编码器(Encoder): 输入 向量 , 输出向量 O
解码器(Decoder): 输入向量 O, 输出向量
模型跟DNN 基本一致
1.2 损失函数
使用均方差作为损失函数
loss = mse_loss(,
)
1.3 手写数字识别效果图
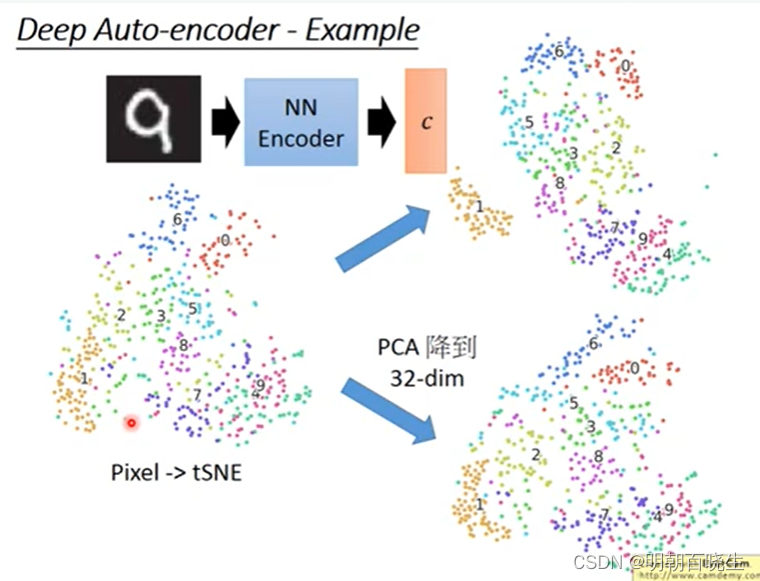
在手写数字识别中,相对t-SNE,PCA等模型,AE 有更好的效果.
二 De-noising auto-encoder
Vincent在2008年的论文中提出了AutoEncoder的改良版——DAE
"Extracting and Composing Robust Features","提取,编码出具有鲁棒性的特征"
人类具有认知被阻挡的破损图像能力,此源于我们高等的联想记忆感受机能。
我们能以多种形式去记忆(比如图像、声音,甚至如上图的词根记忆法),所以即便是数据破损丢失,我们也能回想起来,所以在输入中即使加入了噪声也不会影响模型的性能,只会使得鲁棒性更强.
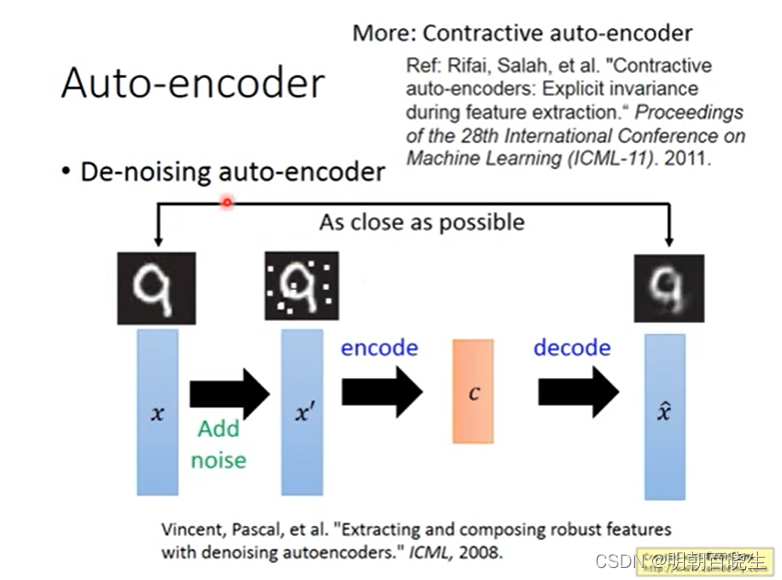
2.1 流程:
输入:
向量
step1: 增加噪声:
方案1:
以一定概率分布(通常使用二项分布)去擦除原始矩阵,即每个值都随机置0.
方案2:
以一定的概率(高斯分布)产生噪声n,针对输入向量x,得到
step2:
经过AE 编码器,重构出
2.2 损失函数
loss = mse_loss(,
)
三 文字检索应用例子(Text Retrieval)
3.1 传统方案
最初的Bag-of-words ,也叫做“词袋”,在信息检索中,Bag-of-words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现。
例子:
应用于文本的BoW简单实例
文章1 John likes to watch movies. Mary likes too.
文章2 John also likes to watch football games.
step1 建立词典
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| John | likes | to | watch | movies | also | football | games | mary | too |
step2 文章词向量表示
文章1:向量a= [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
文章2:文章b = [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
step3 文章相似度
3.2 Auto-Encoder 方案
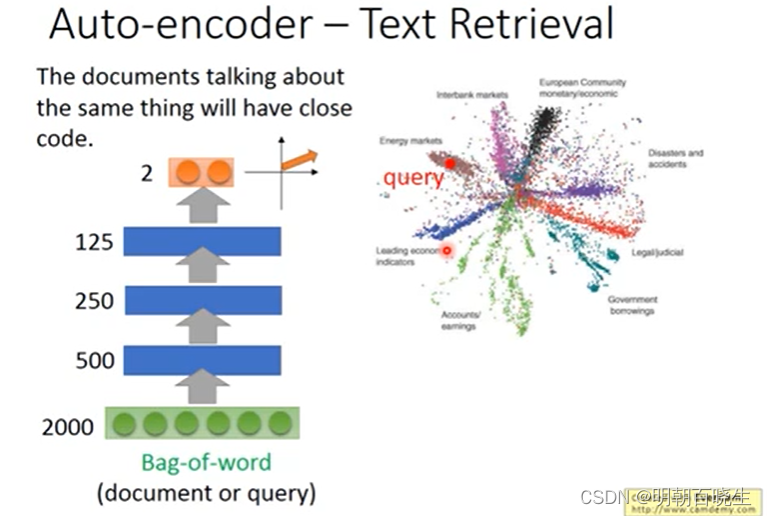
文章1: 先通过AE 编码器进行降维得到向量a
文章2: 先通过AE 编码器进行降维得到向量b
然后通过 a,b 计算向量之间的余弦相似度
四 影像相似度比较例子 Similar Image Search
4.1 传统方案
传统的图像算法: 一般用 感知哈希算法(Perceptual Hash,PHash) 深度学习里面人脸识别算法,提取特征后然后算相似度

4.2 Auto-Encoder

step1: 通过AE 编码器对输入向量x 进行降维,得到code1,code2
step2: 计算code1,code2 之间的余弦相似度

五 CNN-AE
AE 编码器除了使用DNN模型外,还可以使用CNN 模型.如下图所示。
相对CNN 主要区别是两个模块:
Deconvolution 反卷积
Unpooling 反池化

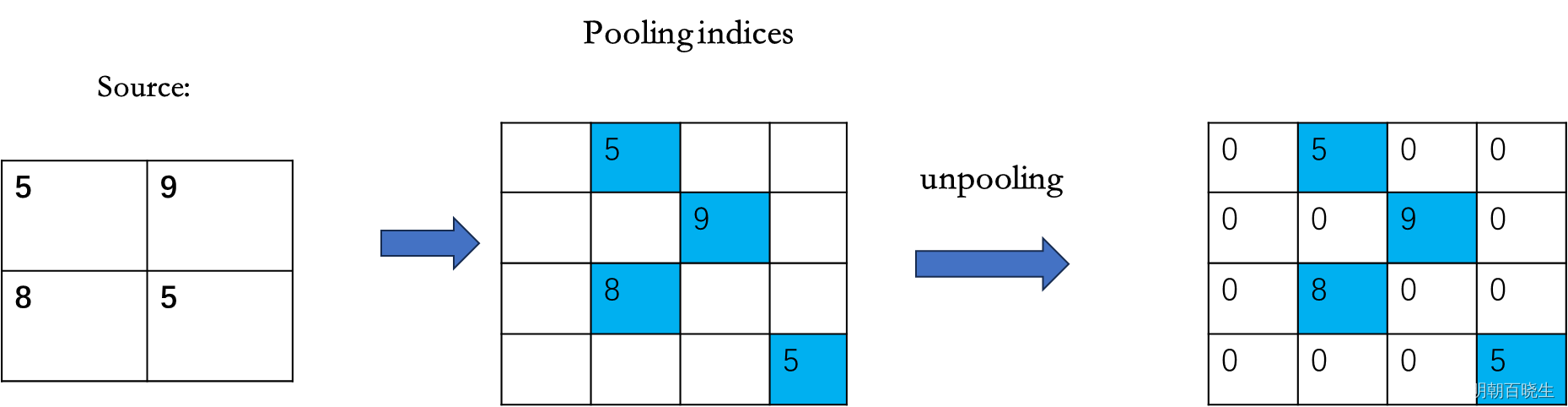
5.1 Unpooling 反池化
是MaxPooling 的反过程
MaxPooling:

Unpooling
5.2 Deconvolution 反卷积
卷积操作:
图像A 经过卷积核,得到特征图B
原图像尺寸为h ,卷积核 k, padding=p , stride =s ,
输出特征图尺寸:
反卷积:
已知特征图尺寸o, 使用相同的卷积核: k,p,s
输出原图像尺寸:
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 20 14:18:59 2024@author: chengxf2
"""import torchdef conv2d():'''·· 输入:batch_size,一个batch中样本的个数 3channels,通道数,RGB 图为3,灰度图为1height, 图片的高 5width_1, 图片的宽 5卷积核:channels,通道数,和上面保持一致,也就是当前层的深度 1output ,输出的深度 4【需要4个filter】kernel_size: 卷积核大小stride: 步长padding:填充系数'''x = torch.randn(3,1,24,24)conv = torch.nn.Conv2d(in_channels=1, out_channels=4, kernel_size=2, stride=2,padding=1) res = conv(x)print("\n 卷积输出",res.shape)return resdef deConv(x):'''in_channels(int):输入张量的通道数out_channels(int):输出张量的通道数kernel_size(int or tuple):卷积核大小stride(int or tuple,optional):卷积步长,决定上采样的倍数padding(int or tuple, optional):对输入图像进行padding,输入图像尺寸增加2*paddingoutput_padding(int or tuple, optional):对输出图像进行padding,输出图像尺寸增加paddinggroups:分组卷积(必须能够整除in_channels和out_channels)bias:是否加上偏置dilation:卷积核之间的采样距离(即空洞卷积)padding_mode(str):padding的类型另外,对于可以传入tuple的参数,tuple[0]是在height维度上,tuple[1]是在width维度上'''conv = torch.nn.ConvTranspose2d(in_channels=4, out_channels=1, kernel_size=2,stride=2,padding=1)out =conv(x)print("\n 反卷积 输出",out.shape)if __name__ == "__main__":res = conv2d()deConv(res)六 AE PyTorch 例子
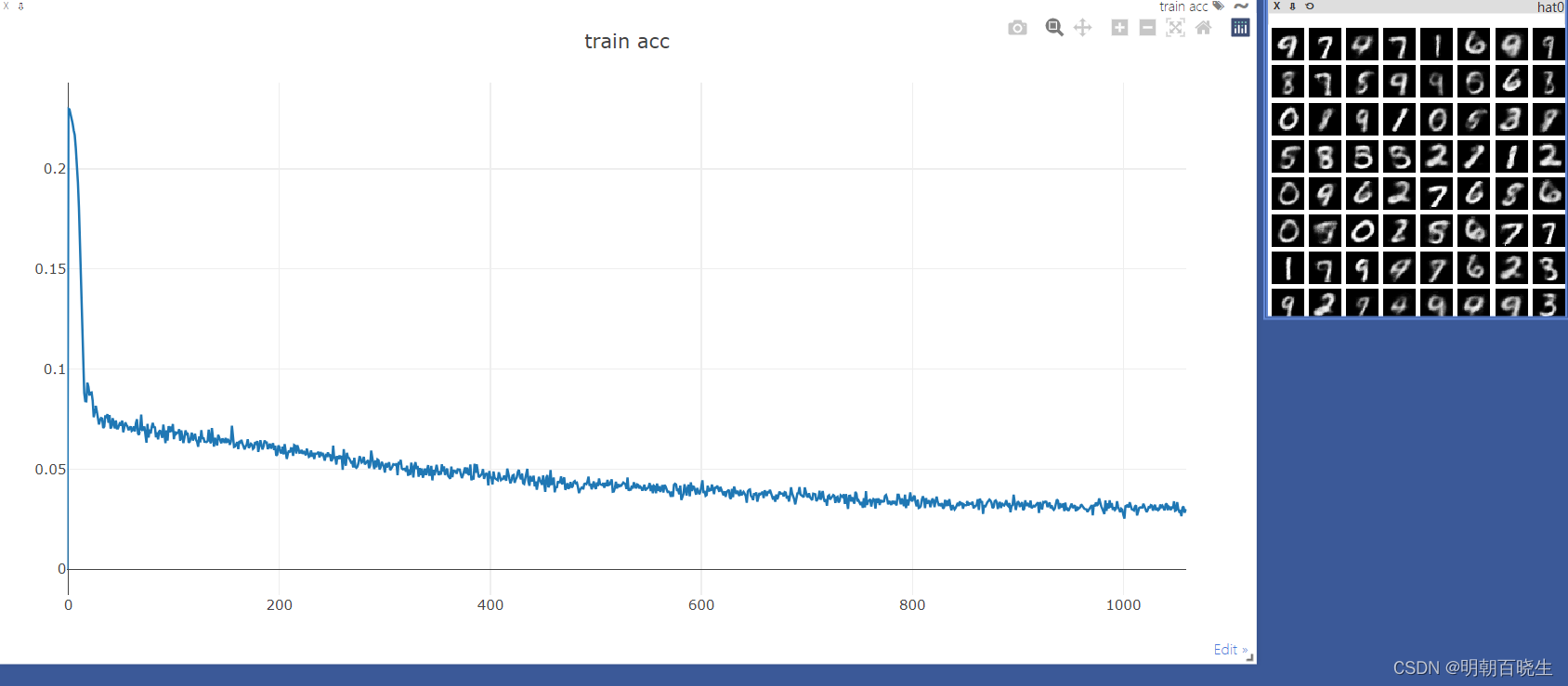
两个模块
main.py
autoEncoder.py
5.1 autoEncoder.py
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 20 14:44:21 2024@author: chengxf2
"""import torch
import torch.nn as nnclass AE(nn.Module):def __init__(self):super(AE,self).__init__()#编码器self.encoder = nn.Sequential(nn.Linear(in_features=784, out_features=256),nn.ReLU(),nn.Linear(in_features=256, out_features=128),nn.ReLU(),nn.Linear(in_features=128, out_features=64),nn.ReLU(),nn.Linear(in_features=64, out_features=16),nn.ReLU())#解码器self.decoder = nn.Sequential(nn.Linear(in_features=16, out_features=64),nn.ReLU(),nn.Linear(in_features=64, out_features=128),nn.ReLU(),nn.Linear(in_features=128, out_features=256),nn.ReLU(),nn.Linear(in_features=256, out_features=784),nn.Sigmoid())def forward(self, x):batch, channel,width,height = x.shapex = x.view(-1, 28*28)#low dimensional vectora = self.encoder(x)#print("\n a.shape ",a.shape)hatX = self.decoder(a)hatX = hatX.view(batch,channel,width,height)return hatX5.2 main.py
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 20 15:01:54 2024@author: chengxf2
"""import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import time
from torch import optim,nn
from autoEncoder import AE
import visdomdef main():batchNum = 64lr = 1e-3epochs = 20device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")torch.manual_seed(1234)viz = visdom.Visdom()viz.line([0],[-1],win='train_loss',opts =dict(title='train acc'))tf= transforms.Compose([ transforms.ToTensor()])mnist_train = datasets.MNIST('mnist',True,transform= tf,download=True)train_data = DataLoader(mnist_train, batch_size=batchNum, shuffle=True)mnist_test = datasets.MNIST('mnist',False,transform= tf,download=True)test_data = DataLoader(mnist_test, batch_size=batchNum, shuffle=True)global_step =0model =AE().to(device)criteon = nn.MSELoss().to(device) #损失函数optimizer = optim.Adam(model.parameters(),lr=lr) #梯度更新规则print("\n ----main-----")for epoch in range(epochs):start = time.perf_counter()for step ,(x,y) in enumerate(train_data):#[b,1,28,28]x = x.to(device)#print("\n x shape",x.shape)x_hat = model(x)#print("\n xHat",x_hat.shape)loss = criteon(x_hat, x)#backpropoptimizer.zero_grad()loss.backward()optimizer.step()viz.line(Y=[loss.item()],X=[global_step],win='train_loss',update='append')global_step +=1end = time.perf_counter() interval = end - startprint("\n 每轮训练时间 :",int(interval))print(epoch, 'loss:',loss.item())x,target = iter(test_data).next()x = x.to(device)with torch.no_grad():x_hat = model(x)tip = 'hat'+str(epoch)#print(x[0])print("\n ----")#print(x_hat[0])#viz.images(x,nrow=8, win='x',opts=dict(title='x'))viz.images(x_hat,nrow=8, win='x_hat',opts=dict(title=tip))if __name__ == '__main__':main()
六 Stacked Autoencoders
Bengio等人在2007年的 Greedy Layer-Wise Training of Deep Networks 中,
仿照stacked RBM构成的DBN,提出Stacked AutoEncoder.
堆叠式自编码器通过将多个自编码器连接在一起来构建一个深层的神经网络结构。每个自编码器的隐藏层都作为下一个自编码器的输入层,逐层堆叠在一起。这种堆叠的方式使得每个自编码器都可以学习到更高级别的数据特征表示。
堆叠式自编码器的训练过程分为两个阶段。
1,每个自编码器都被独立地训练以学习到数据的低维表示。
2 使用已训练好的自编码器来初始化下一个自编码器的编码器部分,然后再次进行训练,以学习到更高级别的特征表示。
这个过程可以重复多次,以构建更深层次的堆叠式自编码器.
建议看一下这个代码:AutoEncoder: 堆栈自动编码器 Stacked_AutoEncoder - 知乎
简答的说先训练出一个AE, 把该AE 的隐藏层作为下个AE 的输入,
反复迭代训练
参考:
自编码器(AE、VAE)的原理与代码实现 - 知乎
16: Unsupervised Learning - Auto-encoder_哔哩哔哩_bilibili
神经网络-AE&VAE基础 - 知乎
自编码网络(附代码实现)-CSDN博客
浅析Bag-of-words及Bag-of-features原理_bag of words-CSDN博客
https://www.cnblogs.com/neopenx/p/4378635.html
AutoEncoder: 堆栈自动编码器 Stacked_AutoEncoder - 知乎
相关文章:
【PyTorch][chapter 17][李宏毅深度学习]【无监督学习][ Auto-encoder]
前言: 本篇重点介绍AE(Auto-Encoder) 自编码器。这是深度学习的一个核心模型. 自编码网络是一种基于无监督学习方法的生成类模型,自编码最大特征输出等于输入 Yann LeCun&Bengio, Hinton 对无监督学习的看法. 目录: AE 模型原…...

Modern C++ std::variant的实现原理
前言 std::variant是C17标准库引入的一种类型,用于安全地存储和访问多种类型中的一种。它类似于C语言中的联合体(union),但功能更为强大。与联合体相比,std::variant具有类型安全性,可以判断当前存储的实际…...

⭐北邮复试刷题LCR 018. 验证回文串__双指针 (力扣119经典题变种挑战)
LCR 018. 验证回文串 给定一个字符串 s ,验证 s 是否是 回文串 ,只考虑字母和数字字符,可以忽略字母的大小写。 本题中,将空字符串定义为有效的 回文串 。 示例 1: 输入: s “A man, a plan, a canal: Panama” 输出: true 解释…...

C++面试:数据库的权限管理数据库的集群和高可用
目录 一、数据库的权限管理 1. 用户和角色管理 用户管理 实例举例(以MySQL为例): 角色管理 实例举例(以MySQL为例): 总结 2. 权限和授权 用户和角色管理 用户管理 角色管理 权限和授权 权限 授…...

个人搭建部署gpt站点
2024搭建部署gpt 参照博客 https://cloud.tencent.com/developer/article/2266669?areaSource102001.19&traceIdRmFvGjZ9BeaIaFEezqQBj博客核心点 准备好你的 OpenAI API Key; 点击右侧按钮开始部署: Deploy with Vercel,直接使用 Github 账号登…...

samber/lo 库的使用方法: condition
samber/lo 库的使用方法: condition samber/lo 是一个 Go 语言库,使用泛型实现了一些常用的操作函数,如 Filter、Map 和 FilterMap。汇总目录页面 这个库函数太多,因此我决定按照功能分别介绍,本文介绍的是 samber/l…...

Chrome插件精选 — 缓存清理
Chrome实现同一功能的插件往往有多款产品,逐一去安装试用耗时又费力,在此为某一类型插件挑选出比较好用的一款或几款,尽量满足界面精致、功能齐全、设置选项丰富的使用要求,便于节省一个个去尝试的时间和精力。 1. Chrome清理大师…...

Redis之缓存穿透问题解决方案实践SpringBoot3+Docker
文章目录 一、介绍二、方案介绍三、Redis Docker部署四、SpringBoot3 Base代码1. 依赖配置2. 基本代码 五、缓存优化代码1. 校验机制2. 布隆过滤器3. 逻辑优化 一、介绍 当一种请求,总是能越过缓存,调用数据库,就是缓存穿透。 比如当请求一…...

每日shell脚本之超级整合程序3.0
每日shell脚本之超级整合程序3.0 本期带来之前的升级版2.0整合脚本程序,学习工作小利器,同时模块化构建方便二次开发。 上图 上源码 #!/usr/bin/bash # *******************************************# # * CDDN : M乔木 # # * qq邮箱 …...

Docker介绍与使用
Docker介绍与使用 目录: 一、Docker介绍 1、Docker概述与安装 2、Docker三要素 二、Docker常用命令的使用 1、镜像相关命令 2、容器相关命令 三、Docker实战之下载mysql、redis、zimg 一、Docker介绍 Docker是一个开源的应用容器引擎,让开发者可以打包…...

Gin框架: 使用go-ini配置参数与不同环境下的配置部署
关于 INI 配置文件与go-ini 1 )概述 在INI配置文件中可以处理各种数据的配置INI文件是一种简单的文本格式,常用于配置软件的各种参数go-ini 是地表 最强大、最方便 和 最流行 的 Go 语言 INI 文件操作库 Github 地址:https://github.com/go-…...

探究网络工具nc(netcat)的使用方法及安装步骤
目录 🐶1. 什么是nc(netcat)? 🐶2. nc(netcat)的基本使用方法 2.1 🥙使用 nc 进行端口监听 2.2 🥙使用 nc 进行端口扫描 2.3 🥙使用 Netcat 进行文件传输…...
深入浅出JVM(四)之类文件结构
深入浅出JVM(四)之类文件结构 Java文件编译成字节码文件后,通过类加载机制到Java虚拟机中,Java虚拟机能够执行所有符合要求的字节码,因此无论什么语言,只要能够编译成符合要求的字节码文件就能够被Java虚拟…...
)
Anaconda下的pkgs占用空间13G,如何安全的清理(已解决)
方法一:让Anaconda自行决定清理 执行命令 conda clean -p 我的Anaconda安装在D盘,具体位置如下。你的应该也能找到对应的位置 D:\*****\**\Anaconda3\pkgs (base) C:\Users\Liu_J>conda clean -p WARNING: C:\Users\***\.conda\pkgs does not ex…...

压缩感知常用的重建算法
重建算法的基本概念 在压缩感知(Compressed Sensing, CS)框架中,重建算法是指将从原始信号中以低于奈奎斯特率采集得到的压缩测量值恢复成完整信号的数学和计算过程。由于信号在采集过程中被压缩,因此重建算法的目标是找到最符合…...

c语言经典测试题2
1.题1 我们来思考一下它的结果是什么? 我们来分析一下:\\是转义为字符\,\123表示的是一个八进制,算一个字符,\t算一个字符,加上\0,应该有13个,但是strlen只计算\0前的字符个数。所以…...
⭐北邮复试刷题105. 从前序与中序遍历序列构造二叉树__递归分治 (力扣每日一题)
105. 从前序与中序遍历序列构造二叉树 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,…...

机房预约系统(个人学习笔记黑马学习)
1、机房预约系统需求 1.1系统简介 学校现有几个规格不同的机房,由于使用时经常出现“撞车“现象,现开发一套机房预约系统,解决这一问题。 1.2身份简介 分别有三种身份使用该程序 学生代表:申请使用机房教师:审核学生的预约申请管理员:给学生、教师创建账…...

7、内网安全-横向移动PTH哈希PTT票据PTK密匙Kerberos密码喷射
用途:个人学习笔记,有所借鉴,欢迎指正 目录 一、域横向移动-PTH-Mimikatz&NTLM 1、Mimikatz 2、impacket-at&ps&wmi&smb 二、域横向移动-PTK-Mimikatz&AES256 三、域横向移动-PTT-漏洞&Kekeo&Ticket 1、漏…...

【前端】夯实基础 css/html/js 50个练手项目(持续更新)
文章目录 前言Day 1 expanding-cardsDay 2 progress-steps 前言 发现一个没有用前端框架的练手项目,很适合我这种纯后端开发夯实基础,内含50个mini project,学习一下,做做笔记。 项目地址:https://github.com/bradtr…...
环境变量配置保姆级教程,附常见报错排查)
Win11系统下JDK1.8(jdk-8u121)环境变量配置保姆级教程,附常见报错排查
Win11系统Java开发环境配置全指南:从安装到故障排查 1. 为什么Java环境配置如此重要? 对于每一位Java开发者来说,正确配置开发环境是迈入编程世界的第一步。想象一下,当你满怀期待地写下第一个"Hello World"程序&#x…...

Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图
Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图 在ROS开发中,地图可视化工具Mapviz因其强大的插件系统和高度可定制性备受青睐。然而,Ubuntu20.04环境下安装Mapviz时,Qt版本冲突和OpenCV链接错误…...

CANN Ascend C SIMT log10f函数
log10f 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/can…...

五分钟完成Python环境配置,用Taotoken调用大模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成Python环境配置,用Taotoken调用大模型API 对于希望快速体验不同大模型能力的Python开发者而言,通…...
)
ADAU1452/1467硬件设计避坑:手把手教你从原理图到SigmaStudio的通道映射(含AD1938实例)
ADAU1452/1467硬件设计实战:从原理图到SigmaStudio的通道映射全解析 在嵌入式音频系统设计中,ADAU1452和ADAU1467作为业界广泛使用的数字信号处理器,其硬件接口配置一直是工程师面临的典型挑战。特别是当系统需要连接多通道编解码器ÿ…...

集团化全员学习企业在线学习平台选型指南|政企专属解决方案
在数字化人才培养浪潮下,集团化全员学习已成为央企、国企、大型上市公司的核心战略,而一款稳定、可管控、高合规的企业在线学习平台,是支撑万人级培训的核心底座。传统分散式培训存在管理混乱、标准不统一、效果不可追溯等痛点,本…...

使用TaoTokenCLI工具一键配置多开发环境下的API接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用TaoTokenCLI工具一键配置多开发环境下的API接入 在团队协作或个人多项目开发中,为每个项目或每台机器手动配置大模…...

别再死磕原生OpenStack了!华为云Stack HCS 8.0的极简部署与高可用设计,真香!
华为云Stack HCS 8.0:企业私有云部署的革命性突破 当企业IT架构师面对私有云平台选型时,部署复杂性和系统可靠性往往成为最令人头疼的两大难题。原生OpenStack以其高度灵活性和开源特性吸引了大量技术团队,但随之而来的却是漫长的部署周期、繁…...
)
别再只用BackgroundImage了!C# WinForm窗体背景图5种方法全解析(含PictureBox与资源文件实战)
别再只用BackgroundImage了!C# WinForm窗体背景图5种方法全解析 当我们需要为WinForm窗体添加背景图时,很多开发者会条件反射地使用BackgroundImage属性。这种习惯性选择虽然简单,但在实际项目中可能会遇到性能瓶颈、内存泄漏或适配问题。本文…...

W5500 TCP客户端开发避坑指南:从寄存器配置到稳定通信的5个关键步骤
W5500 TCP客户端开发避坑指南:从寄存器配置到稳定通信的5个关键步骤 在嵌入式网络通信领域,W5500作为一款硬件集成TCP/IP协议栈的以太网控制器,因其易用性和稳定性备受开发者青睐。然而,当项目从实验室demo转向实际部署时…...