架构师技能9-深入mybatis:Creating a new SqlSession到查询语句耗时特别长
开篇语录:以架构师的能力标准去分析每个问题,过后由表及里分析问题的本质,复盘总结经验,并把总结内容记录下来。当你解决各种各样的问题,也就积累了丰富的解决问题的经验,解决问题的能力也将自然得到极大的提升。
励志做架构师的撸码人,认知很重要,可以订阅:架构设计专栏
撸码人平时大多数时间都在撸码或者撸码的路上,很少关注框架的一些底层原理,当出现问题时没能力第一时间解决问题,出现问题后不去层层剖析问题产生的原因,后续也就可能无法避免或者绕开同类的问题。因此不要单纯做Ctrl+c和Ctrl+V,而是一边仰望星空(目标规划),一边脚踏实地去分析每个问题。
一、背景
我们最近在使用mybatis执行批量数据插入,数据插入非常慢:每批次5000条数据大概耗时在3~4分钟左右。架构师的职责之一是疑难技术点攻关:要主动积极解决系统出现的问题,过后由表及里分析问题的本质,复盘总结经验,并把总结内容记录下来分享给团队,确保后续如何智慧地绕开同类问题。
以下是排查问题的过程和思路:
二、定位问题
1、全面打印日志:
日志是排查问题的第一手资料。
logback设置mybatis相关日志打印:
<logger name="org.mybatis.spring" level="DEBUG"/> <logger name="org.apache.ibatis" level="DEBUG"/> <!-- <logger name="java.sql.PreparedStatement" level="DEBUG"/>--> <!-- <logger name="java.sql.Statement" level="DEBUG"/>--> <!-- <logger name="java.sql.Connection" level="DEBUG"/>--> <!-- <logger name="java.sql.ResultSet" level="DEBUG"/>-->
2、初步定位问题
发现Creating a new SqlSession到查询语句耗时特别长:

3、初步排查问题:
有几个可能的原因导致创建新的SqlSession到查询语句耗时特别长:
1. 数据库连接池问题:如果连接池中没有空余的连接,则创建新的SqlSession时需要等待连接释放。可以通过增加连接池大小或者优化查询语句等方式来缓解该问题。
排除连接池问题:我们连接池比较大,通过mysql show processlist查看几乎没有慢查询的连接。
2. 网络延迟问题:如果数据库服务器和应用服务器之间的网络延迟较大,则创建新的SqlSession时会受到影响。可以通过优化网络配置或者将数据库服务器和应用服务器放在同一台机器上等方式来缓解该问题。
排除网络问题:ping mysql地址,耗时都在0.5ms左右。
3. 查询语句过于复杂:如果查询语句过于复杂,则会导致查询时间较长。可以通过优化查询语句或者增加索引等方式来缓解该问题。
排除复杂sql问题:简单insert 语句,通过mysql show processlist查看没有慢查询的连接。
<insert id="batchInsertDuplicate">INSERT INTO b_table_#{day} (<include refid="selectAllColumn"/>) VALUES<foreach collection="list" item="item" index="index" separator=",">(#{item.id ,jdbcType=VARCHAR },#{item.sn ,jdbcType=VARCHAR },#{item.ip ,jdbcType=VARCHAR },.....#{item.createTime ,jdbcType=TIMESTAMP },#{item.updateTime ,jdbcType=TIMESTAMP })</foreach>ON DUPLICATE KEY UPDATE`ip`=VALUES(`ip`),`updateTime`=VALUES(`updateTime`)
</insert>4. 数据库服务器性能问题:如果数据库服务器性能较低,则创建新的SqlSession时会受到影响。可以通过优化数据库服务器配置或者升级硬件等方式来缓解该问题。
排除数据库服务器性能问题:mysql是8核16G,通过mysql show processlist查看没有慢查询的连接。
5. 应用服务器性能问题:如果应用服务器性能较低,则创建新的SqlSession时会受到影响。可以通过优化应用服务器配置或者升级硬件等方式来缓解该问题。
暂时无法确定:top查看cpu占用比较高90%,可能原因是mybatis框架处理sql语句引起cpu飙高。
三、定位cpu飙高耗时的方法
1、优化代码:
5000条改为500条批量插入,查看每个线程的耗时依然很高,说明是mybatis框架处理sql语句耗cpu。
top -H -p 18912
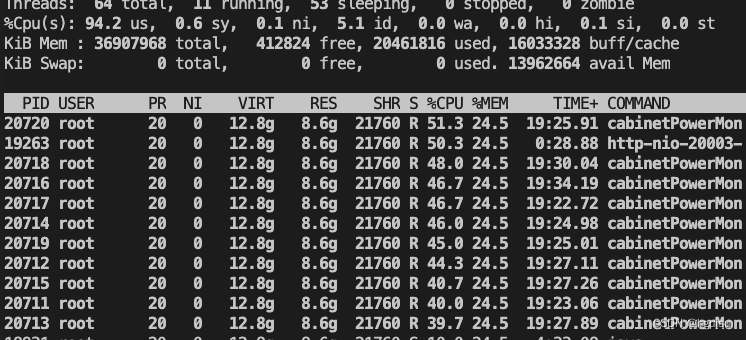
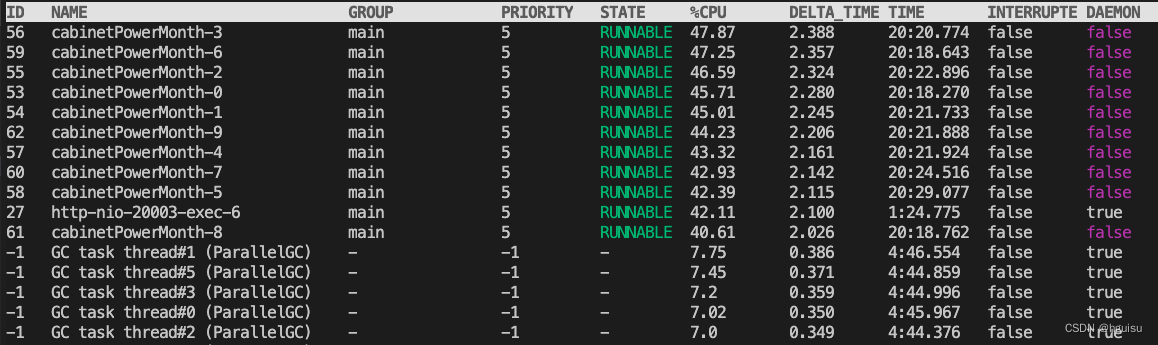
2、使用arthas定位:
curl -O https://arthas.aliyun.com/arthas-boot.jar java -jar arthas-boot.jar pid
使用dashboard可以查看每个线程耗cpu情况,和top -H 差不多:
3、trace方法耗时:
trace com.xxxx.class xxxmethod

逐步跟进去:

最后定位方法
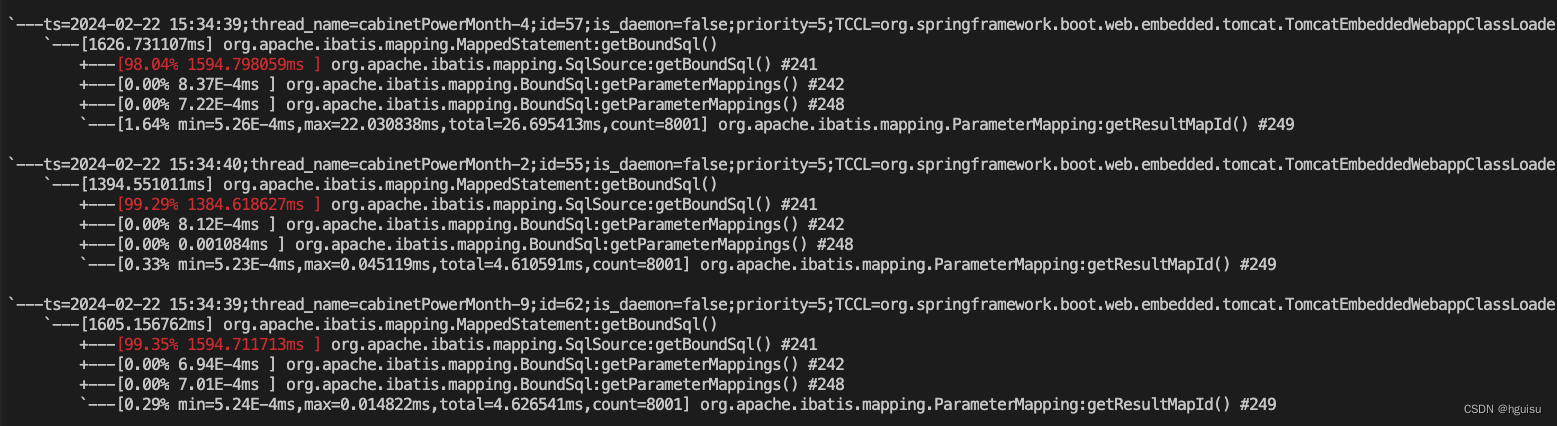
org.apache.ibatis.parsing.GenericTokenParser:parse耗时: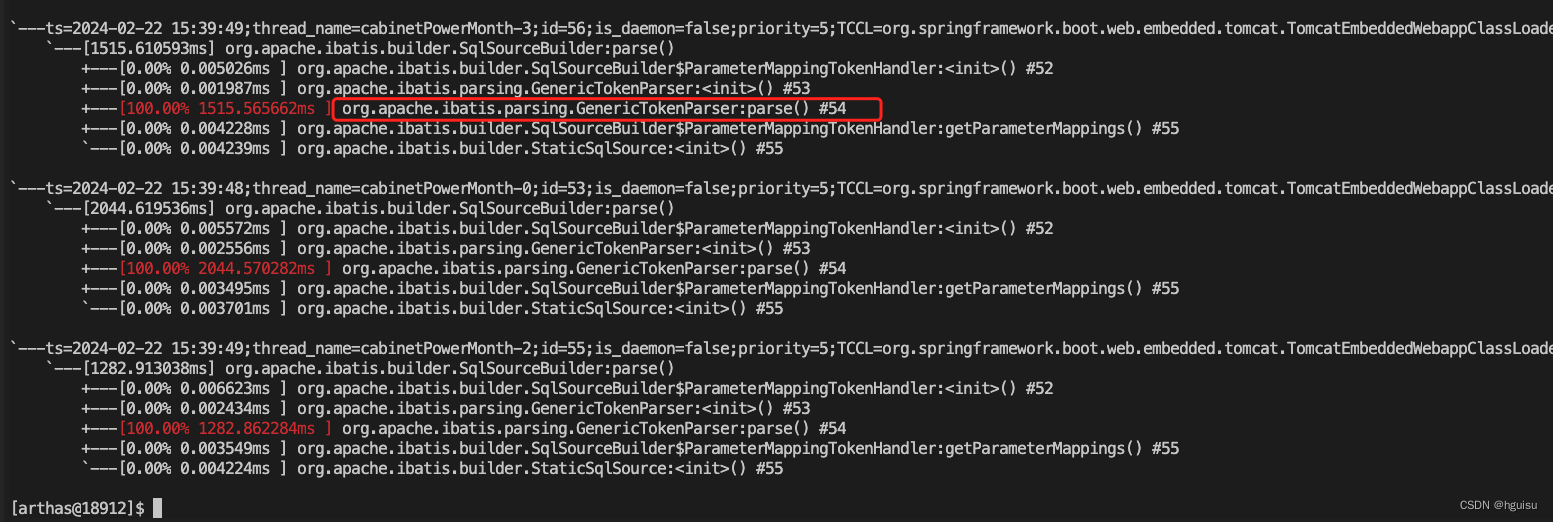
查看 org.apache.ibatis.parsing.GenericTokenParser:parse的源码:
public String parse(String text) {StringBuilder builder = new StringBuilder();if (text != null) {String after = text;int start = text.indexOf(this.openToken);for(int end = text.indexOf(this.closeToken); start > -1; end = after.indexOf(this.closeToken)) {String before;if (end <= start) {if (end <= -1) {break;}before = after.substring(0, end);builder.append(before);builder.append(this.closeToken);after = after.substring(end + this.closeToken.length());} else {before = after.substring(0, start);String content = after.substring(start + this.openToken.length(), end);String substitution;if (start > 0 && text.charAt(start - 1) == '\\') {before = before.substring(0, before.length() - 1);substitution = this.openToken + content + this.closeToken;} else {substitution = this.handler.handleToken(content);}builder.append(before);builder.append(substitution);after = after.substring(end + this.closeToken.length());}start = after.indexOf(this.openToken);}builder.append(after);}return builder.toString();}主要作用是对 SQL 进行解析,对转义字符进行特殊处理(删除反斜杠)并处理相关的参数(${}),如sql需要解析的标志${name} 替换为实际的文本。我们可以使用一个例子说明:
final Map<String,Object> mapper = new HashMap<String, Object>();
mapper.put("name", "张三");
mapper.put("pwd", "123456");//先初始化一个handler
TokenHandler handler = new TokenHandler() {@Overridepublic String handleToken(String content) {System.out.println(content);return (String) mapper.get(content);}};
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
System.out.println("************" + parser.parse("用户:${name},你的密码是:${pwd}"));通过源码发现,如果mapper定义的字段很多,for遍历条数比较大(下面红色部分):
<insert id="batchInsertDuplicate">
INSERT INTO b_table_#{day} (
<include refid="selectAllColumn"/>
) VALUES
<foreach collection="list" item="item" index="index" separator=",">
(
#{item.id ,jdbcType=VARCHAR },
#{item.sn ,jdbcType=VARCHAR },
#{item.ip ,jdbcType=VARCHAR },
.....
#{item.createTime ,jdbcType=TIMESTAMP },
#{item.updateTime ,jdbcType=TIMESTAMP }
)
</foreach>
ON DUPLICATE KEY UPDATE
`ip`=VALUES(`ip`),
`updateTime`=VALUES(`updateTime`)
</insert>
需要解析耗时较久,由于都是字符串遍历,特别耗CPU,因此可以看到cpu飙升很高。
四、解决
解决:直接执行原声sql。
不使用mapper方式拼接sql,而是手动拼接好sql,使用JdbcTemplate执行原声sql。
相关文章:
架构师技能9-深入mybatis:Creating a new SqlSession到查询语句耗时特别长
开篇语录:以架构师的能力标准去分析每个问题,过后由表及里分析问题的本质,复盘总结经验,并把总结内容记录下来。当你解决各种各样的问题,也就积累了丰富的解决问题的经验,解决问题的能力也将自然得到极大的…...
【JavaEE】_HTTP请求报头header
目录 1. Host 2. Content-Length与Content-Type 2.1 Content-Length 2.2 Content-Type 3. User-Agent(UA) 4. Referer 5. Cookie header的整体格式是“键值对”结构,一行是一个键值对,这些键值对都是HTTP定义好的、有特殊含…...

随想录刷题笔记 —二叉树篇10 450删除二叉搜索树节点 669修剪二叉搜索树 108有序数组转换为二叉搜索树
450删除二叉搜索树节点 删除结点分为2种情况: 1.结点的孩子只有一个或没有,则直接用孩子或空替代 2.结点的孩子有两个,用左孩子替代,将左孩子的右孩子移到结点右子树的最左结点 解法一:递归 class Solution {publ…...

Docker基础篇(二)
docker run -d docker run -d 容器名或容器ID docker run -d 后台生成容器,并退出容器(除容器中在运行脚本) docker run -it 交互生成容器 docker run -d centos /bin/sh -c “while true; do echo zen; sleep 2;done” 查看容器中的进程…...
时序数据库TimescaleDB,实战部署全攻略
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

Gson 库的使用
Gson 是由 Google 开发的一个流行的 Java 库,用于处理 JSON 数据的序列化和反序列化。它提供了简单易用的 API,使得在 Java 应用程序中操作 JSON 数据变得非常方便。 以下是 Gson 库的一些主要特点和用法 简单易用 Gson 提供了一个简单而直观的 API,使得在 Java 应用程序中…...
Java Swing游戏开发学习1
不使用游戏引擎,只使用Java SDK开发游戏的学习。 游戏原理 图片来自RyiSnow视频讲解 原理结合实际代码 public class GamePanel extends Jpanel implements Runnable {...run(){}// 详情看下图... }项目结构 运行效果 代码code 在我的下载里面可以找到&#x…...
Stable Diffusion 模型的概念、类型、下载、安装、使用
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 大家好,我是水滴~~ 我们在《Stable Diffusion WebUI 界面介绍》 时,第一个就讲到了 Stable Diffusion 模型,那么这个模型是什么?该从哪儿下载&…...

Go 1.22 对 net/http 包的路由增强功能详解
目录 方法匹配(Method Matching) 通配符(Wildcards) 路径前缀匹配 优先规则 兼容性 API 变更 小结 参考资料 Go 1.22 版本对 net/http 包的路由功能进行了增强,引入了方法匹配(method matching&…...
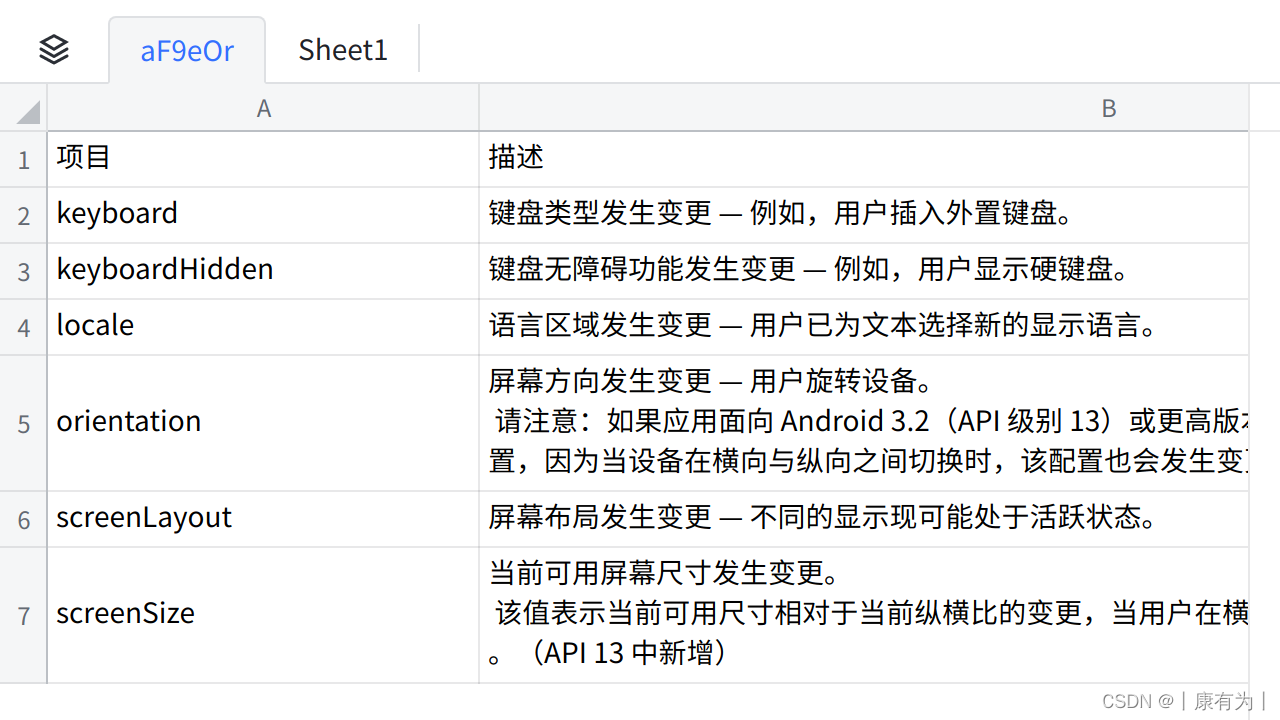
【安卓基础3】Activity(一)
🏆作者简介:|康有为| ,大四在读,目前在小米安卓实习,毕业入职 🏆本文收录于 安卓学习大全,欢迎关注 🏆安卓学习资料推荐: 视频:b站搜动脑学院 视频链接 &…...
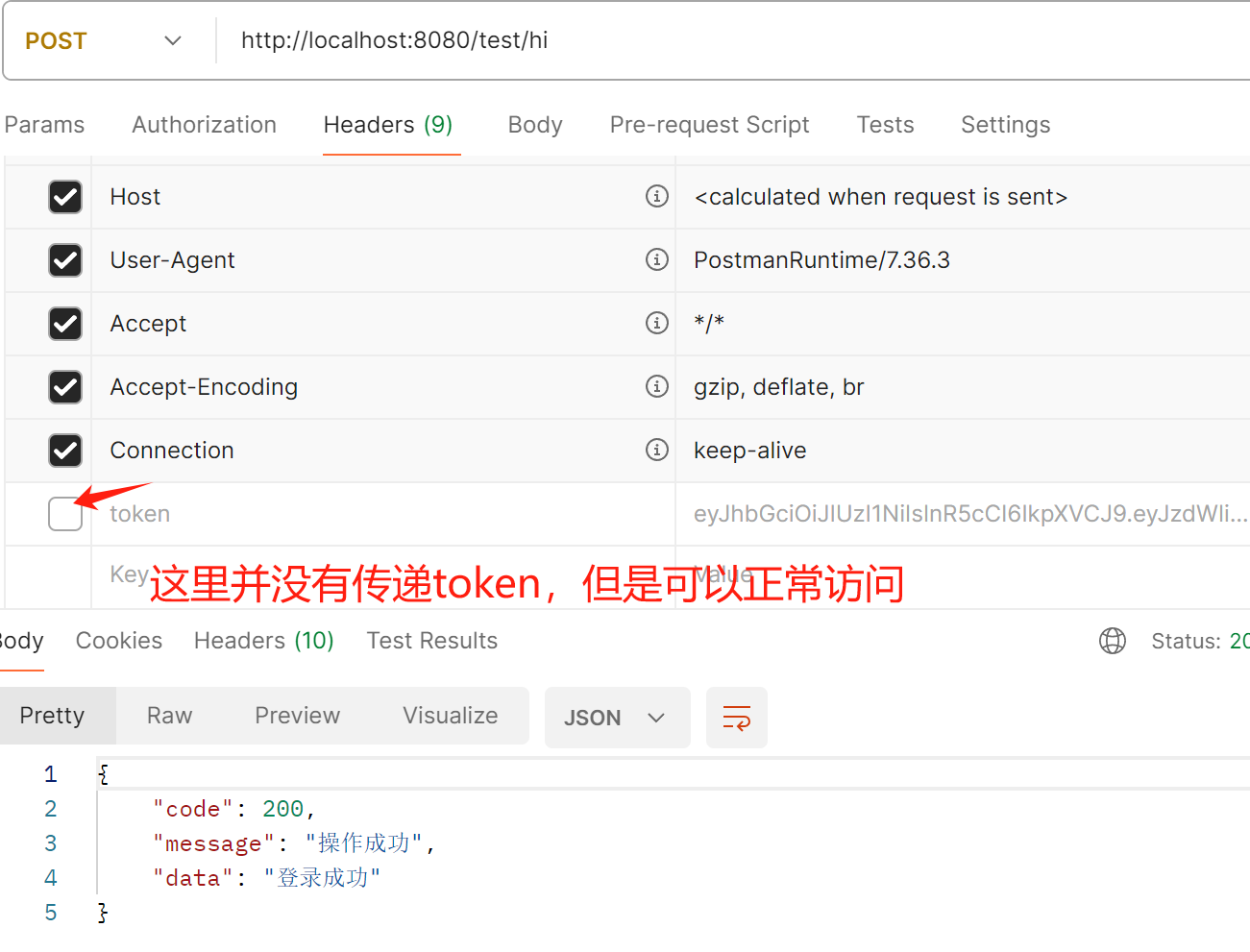
SpringBoot基于JWT的token做登录认证
背景 我们在基于Session做登录认证的时候,会有一些问题,因为Session存储到服务器端,然后通过客户端的Cookie进行匹配,如果正确,则通过认证,否则不通过认证。这在简单的系统中可以这么使用,并且…...
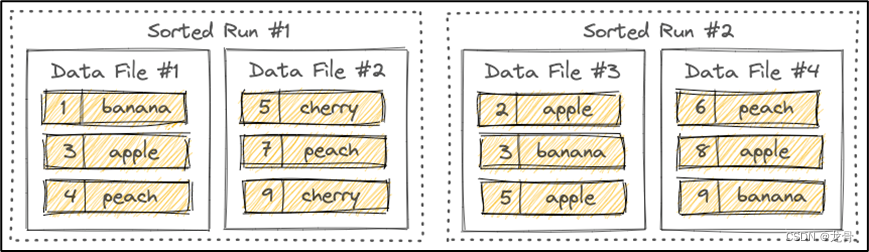
[ 2024春节 Flink打卡 ] -- Paimon
2024,游子未归乡。工作需要,flink coding。觉知此事要躬行,未休,特记 Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,…...

计算机网络——14CDN
CDN 视频流化服务和CDN:上下文 视频流量:占据着互连网大部分的带宽 Netflix,YouTube:占据37%,16%的下行流量 挑战:规模性-如何服务~1B用户? 单个超级服务器无法提供服务(为什么&am…...
Docker技术仓库
数据卷 为什么用数据卷? 宿主机无法直接访问容器中的文件容器中的文件没有持久化,导致容器删除后,文件数据也随之消失容器之间也无法直接访问互相的文件 为解决这些问题,docker加入了数据卷机制,能很好解决上面问题…...

Kotlin学习 6
1.接口 interface Movable {var maxSpeed: Intvar wheels: Intfun move(movable: Movable): String}class Car(var name: String, override var wheels: Int 4, _maxSpeed: Int) : Movable {override var maxSpeed: Int _maxSpeedget() fieldset(value) {field value}overr…...
⭐北邮复试刷题LCR 052. 递增顺序搜索树__DFS (力扣119经典题变种挑战)
LCR 052. 递增顺序搜索树 给你一棵二叉搜索树,请 按中序遍历 将其重新排列为一棵递增顺序搜索树,使树中最左边的节点成为树的根节点,并且每个节点没有左子节点,只有一个右子节点。 示例 1: 输入:root [5,…...
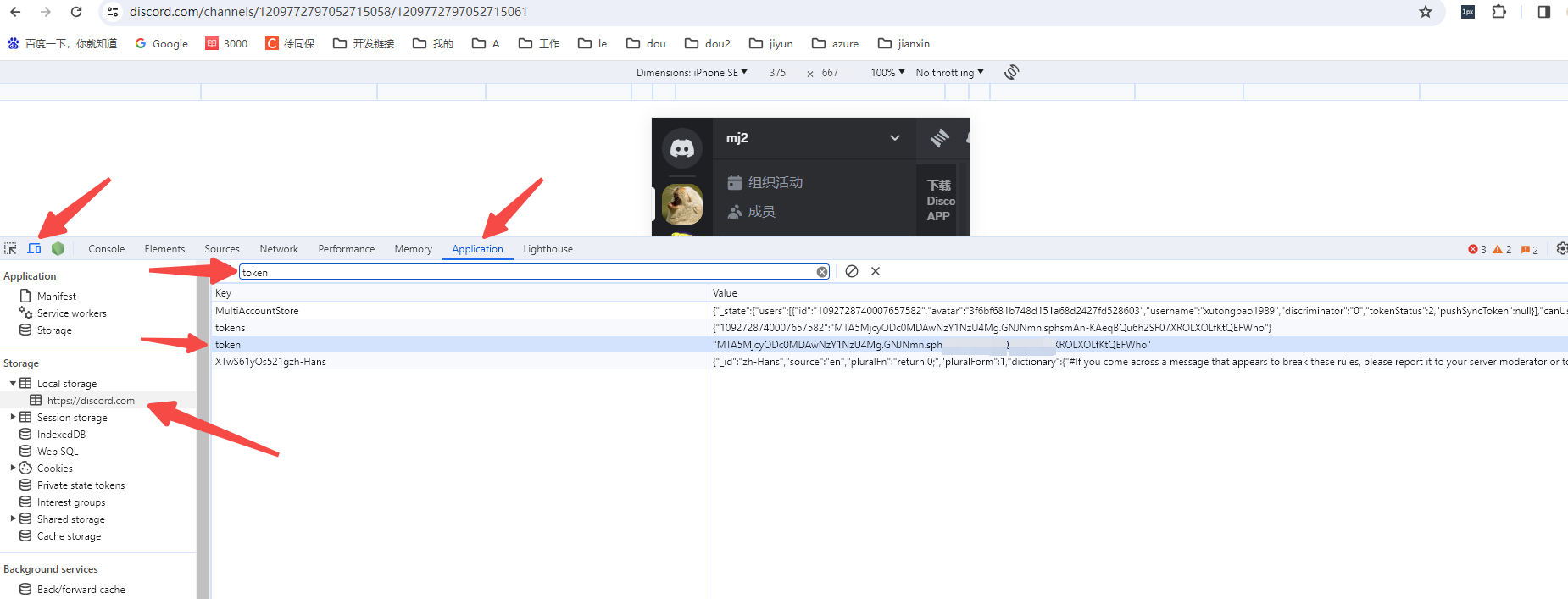
获取discord上自己创建的服务器的服务器ID、频道ID以及discord的登录token(用于第三方登录)
在服务器图标上右键点击-》复制服务器ID 在频道上右键点击-》复制频道ID F12->手机模式-》application-》local storage-》填写过滤条件【token】 我开发的chatgpt网站: https://chat.xutongbao.top...

图纸透明加密:保护机械图纸安全的新方法
随着信息技术的不断发展,机械制造行业对于图纸安全的需求越来越高。机械图纸是企业的核心竞争力之一,泄露可能导致严重的商业损失和技术风险。为了解决这一问题,图纸透明加密成为了一种新的保护机械图纸安全的方法。本文将介绍图纸透明加密的…...
基于springboot + vue实现的前后端分离-酒店管理系统
项目介绍 基于springboot vue实现的酒店管理系统一共有酒店管理员和用户这两种角色。 管理员功能 登录:管理员可以通过登录功能进入系统,确保只有授权人员可以访问系统。用户管理:管理员可以添加、编辑和删除酒店的用户,包括前…...

79.SpringBoot的核心注解
一、SpringBoot的核心注解 SpringBootApplication注解:这个注解标识了一个SpringBoot工程,它实际上是另外三个注解的组合,这三个注解是:SpringBootConfiguration:这个注解实际就是一个Configuration,表示启…...

OpenHarmony系统定制:实现开机自启动应用与Launcher替换实战
1. 项目概述:为OpenHarmony设备定义“开机即用”的体验最近在基于触觉智能的RK3566开发板上折腾OpenHarmony 4.1,一个很实际的需求浮出水面:如何让系统开机后,默认就打开我指定的应用?这不仅仅是开发者的自娱自乐&…...

极限竞速涂装转换神器:Forza Painter终极免费指南
极限竞速涂装转换神器:Forza Painter终极免费指南 【免费下载链接】forza-painter Import images into Forza 项目地址: https://gitcode.com/gh_mirrors/fo/forza-painter 还在为《极限竞速:地平线》中的车辆涂装设计而苦恼吗?想要将…...

如何免费定制你的Windows系统:5个简单步骤掌握Windhawk开源工具
如何免费定制你的Windows系统:5个简单步骤掌握Windhawk开源工具 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 你是否觉得Windows系统缺少了…...

别再手动算稳心了!用Maxsurf Stability模块,从Rhino模型到结果曲线保姆级教程
从Rhino到Maxsurf Stability:船舶稳性分析的智能化工作流实践 船舶设计领域的技术迭代正在悄然改变传统工作模式。记得三年前参与某型游艇设计项目时,团队还在用Excel表格手动计算稳性参数,每次修改船型都意味着重新推导整套公式。直到接触Ma…...

谷歌报告:AI 加速云攻击,企业需自动化防御应对第三方漏洞与身份入侵
AI 加速攻击,云端企业成重灾区 2026 年 3 月,谷歌安全调查人员和工程师团队发布《云威胁展望报告》,基于 2025 年下半年的观察得出结论:AI 正助力攻击者以前所未有的速度利用漏洞,如今大多数云攻击目标是薄弱的第三方软…...

5分钟掌握Cherry MX键帽3D建模:打造你的专属机械键盘
5分钟掌握Cherry MX键帽3D建模:打造你的专属机械键盘 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 你是否曾想过亲手设计一套完全属于自己的机械键盘键帽?…...

第11代酷睿工业主板PICO-TGU4:边缘AI与机器视觉的紧凑型解决方案
1. 项目概述:当紧凑型工业主板遇上第11代酷睿在工业自动化、边缘计算和智能零售这些领域里,我们常常面临一个经典的矛盾:一方面,应用场景对计算性能的要求越来越高,无论是机器视觉的实时图像处理,还是AI推理…...

深入UE渲染管线:从.usf文件到FGlobalShader,理解全局Shader的完整生命周期与最佳实践
深入UE渲染管线:从.usf文件到FGlobalShader,理解全局Shader的完整生命周期与最佳实践 当我们需要在Unreal Engine中实现一个全新的后处理效果或定制底层渲染管线时,全局Shader(Global Shader)往往是必经之路。与材质编…...

UnityPackage Extractor终极指南:快速提取Unity资源包的免费工具
UnityPackage Extractor终极指南:快速提取Unity资源包的免费工具 【免费下载链接】unitypackage_extractor Extract a .unitypackage, with or without Python 项目地址: https://gitcode.com/gh_mirrors/un/unitypackage_extractor 在Unity开发工作流中&…...

抖音批量下载工具终极指南:从零开始实现高效无水印下载
抖音批量下载工具终极指南:从零开始实现高效无水印下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...