python---Pixiv排行榜图片获取(2024.2.16)
1.提示:
使用需要安装各种import的包,都是很基础的包,直接安装即可。
自备梯子 。
切记把userid和cookie改为自己账号的参数!
userid就是点击pixiv头像,网址后面一串数,
cookie是打开排行榜后,按F12打开开发者工具,然后切换到network(网络)栏,刷新页面,找到ranking.php文件,在里面就能找到cookie信息。
2.严肃警告
- 本程序仅可用作个人爱好,商业用途严禁!
- 请自觉遵守君子协定robots.txt
- 不要给网址过大的压力,每天以及同一时段的访问量请控制在一定程度内!
3.思路:
天天有群友找我要涩图,库存根本不够哇,得想办法弄点。
pixiv的爬取有很多大佬做过了,不过我看了一些都是弄得类似于项目一样,确实都很厉害,但我的需求简单,写在一个文件里适合我这种懒蛋。
- 首先通过
RankingCrawler类的get_multi_page_json方法,获取榜单的json数据,将id添加到collector中。 - 然后通过
collector的collect方法,遍历每个id,用get_artworks_urls方法获取id页面内的所有图片的urls,将url添加到downloader中。 - 最后通过
downloader的download方法,多线程调用同class内的download_image方法同时下载图片。
4.使用方法:
一般来说都是直接run就行,所有需要修改的参数都在RankingCrawler类的init中,看一眼就明白
5.代码如下:
import os
import re
import time
import requests
import concurrent.futures as futuresfrom typing import Set, Iterable, Callable, Dict, Optional, Tuple
from tqdm import tqdmclass Downloader():def __init__(self, capacity, headers, threads, standard_time, date):self.url_group: Set[str] = set()self.capacity = capacity # 最大下载量(MB)self.store_path = date + "/" # 日期作为存储路径self.standard_time = standard_timeself.threads = threadsself.headers = headers.copy()# 添加urldef add(self, urls: Iterable[str]):for url in urls:self.url_group.add(url)# 下载单张图片def download_image(self, url: str) -> float:"""func: 1.根据url下载单张图片,返回图片大小(MB)return: 返回图片大小(MB)url example: "https://i.pximg.net/img-master/img/2024/02/10/03/09/52/115911580_p0_master1200.jpg""""# image_nameimage_name = url[url.rfind("/") + 1:]# image_idimage_id = re.search(r"/(\d+)_", url).group(1)# image_pathimage_path = self.store_path + image_name# 添加Refererself.headers.update({"Referer": f"https://www.pixiv.net/artworks/{image_id}"})# 确保存储路径存在os.makedirs(self.store_path, exist_ok=True)# 判断图片是否存在if os.path.exists(image_path):# print(f"File {image_name} already exists. Skipping download.")return 0# 下载图片, 尝试最多10次,因为是多线程下载,所以间隔时间可以稍微长一点点for i in range(10):try:response = requests.get(url, headers=self.headers, timeout=(4, self.standard_time)) # timeout(连接超时, 读取超时)if response.status_code == 200:if "content-length" not in response.headers: # 确保content-length在response.headers中,否则抛出异常raise "content-length not in response.headers"image_size = int(response.headers["content-length"])with open(image_path, "wb") as f:f.write(response.content)return image_size / (1 << 20)except Exception as e:passreturn 0# 多线程下载多张图片def download(self):# 提前封装download_image函数的固定参数,因为map函数只能传入一个参数flow_size = .0print("===== downloader start =====")with futures.ThreadPoolExecutor(self.threads) as executor:# tqdm为进度条with tqdm(total=len(self.url_group), desc="downloading") as pbar:# 多线程并发,通过futures的map方法,将url_group中的每个url传入download_image函数,并通过迭代器的方式返回每个图片的大小for image_size in executor.map(self.download_image, self.url_group):flow_size += image_sizepbar.update()pbar.set_description(f"downloading / flow {flow_size:.2f}MB")if flow_size > self.capacity:executor.shutdown(wait=False, cancel_futures=True)breakprint("===== downloader complete =====")return flow_sizeclass Collector():def __init__(self, threads, user_id, headers, downloader):self.id_group: Set[str] = set() # illust_idself.threads = threadsself.user_id = user_idself.headers = headers.copy()self.downloader = downloaderdef add(self, image_ids):self.id_group.add(image_ids)# 解析HTTP响应,提取并返回一个包含原始图像URLs的集合def select_page(self, response) -> Set[str]:"""url: https://www.pixiv.net/ajax/illust/xxxx/pages?lang=zhcollect all image urls from (page.json)Returns: Set[str]: urls"""group = set()for url in response.json()["body"]:group.add(url["urls"]["original"])return group# 对给定的URL执行HTTP GET请求,并使用指定的选择器函数处理响应数据def get_artworks_urls(self, args: Tuple[str, Callable, Optional[Dict]]) -> Optional[Iterable[str]]:# 拿到参数url, selector, additional_headers = args# 更新请求头headers = self.headersheaders.update(additional_headers)time.sleep(1)# 尝试抓取最多10次for i in range(10):try:response = requests.get(url, headers=headers, timeout=4)if response.status_code == 200:id_group = selector(response)return id_groupexcept Exception as e:print(e)time.sleep(1)# 并发地收集所有艺术作品的图像URLs,并将它们发送给下载器进行下载。def collect(self):"""collect all image ids in each artwork, and send to downloaderNOTE: an artwork may contain multiple images"""print("===== collector start =====")with futures.ThreadPoolExecutor(self.threads) as executor:with tqdm(total=len(self.id_group), desc="collecting urls") as pbar:# 生成每个illust_id对应的urlurls_list = [f"https://www.pixiv.net/ajax/illust/{illust_id}/pages?lang=zh" for illust_id in self.id_group]# 生成每个illust_id对应的请求头additional_headers = [{"Referer": f"https://www.pixiv.net/artworks/{illust_id}","x-user-id": self.user_id,}for illust_id in self.id_group]# 通过get_artworks_urls获取url下的所有图片urls,发送给downloader# futures.ThreadPoolExecutor(n_thread).map(func, iterable) 会将可迭代对象中的每个元素传入func中, 并将所有的func返回值组成一个迭代器返回for urls in executor.map(self.get_artworks_urls, zip(urls_list, [self.select_page] * len(urls_list), additional_headers)):if urls is not None:self.downloader.add(urls)pbar.update()print("===== collector complete =====")return self.id_groupclass RankingCrawler():def __init__(self):"""download artworks from ranking参数(*为可修改的):top_num: 排行榜前多少名*time_mode: 榜单时间(日, 周, 月...)*content: 内容(插画, 漫画, 动图...)*headers: 请求头*threads: 线程数*capacity: 最大流量容量(MB)*standard_time: 标准等待时间user_id: 自己的用户id*date: 任意结束日期(不能为当日日期!最多为当日日期-2天)* (例:20240218,mode=monthly,那么就是抓取20240118到20240218的榜单)切记cookie和user_id要是同一个账号的"""self.top_num = 50self.time_mode = "monthly" # daily_air, weekly, monthlyself.content = "illust"self.headers = {"Cookie": "first_visit_datetime_pc=2022-08-02+15%3A36%3A28; p_ab_id=1; p_ab_id_2=7; p_ab_d_id=1023356603; yuid_b=QXQ4QA; privacy_policy_notification=0; a_type=1; d_type=1; login_ever=yes; _im_vid=01HM1N03159737XTWCJAJ2BY5P; QSI_S_ZN_5hF4My7Ad6VNNAi=v:0:0; _gcl_au=1.1.652233640.1707984789; _im_uid.3929=b.427a030d239f8f0f; _pbjs_userid_consent_data=3524755945110770; _im_vid=01HM1N03159737XTWCJAJ2BY5P; _pubcid=72d87e02-9d02-4eba-b647-77676ef3673c; device_token=29dcd2275dd3ad33f978780a8732d797; __utmc=235335808; cf_clearance=dm9BjZDgPR_7P6FyF01hMvFo6_YHMMnXeuNeh27eCBI-1708345123-1.0-AXR4V4yJkDaYgijBkHd9UVuIBnEInvPrmHN34DpD3t5tIpehWxrAgQ1r9I7+vQIyMtEzFrjhs+mdmnry7qq6l+Y=; _gid=GA1.2.2041924151.1708345235; FCNEC=%5B%5B%22AKsRol__CNeOIOGzfarvWVE024ABJyuS0JuZ-a4EVu2bO3v6IulUgGzLEasagVrBZ8eiP7sMcLdj_PBN2pCXdLdRknBjvSJpTzg49MUAwkwk207sqOnAyn5LgYIxGDYKQBmDpY-jP4z9ZvoV_d7DxVjb4ZueshxsXQ%3D%3D%22%5D%5D; cto_bundle=ZTCen19jalZ0ZGVPMm1QN3ljUmJ0ZjBlazdXenp1JTJGeFIwNUNOb001V2ZCTHNveGVrNzFzUWlDcSUyRllKeFl3a2lZciUyRnpLWXRzOFgwVk41OXRKWCUyRlZCMWxEYTdkR0tmJTJGQzBNaUZ6JTJCNUgwJTJCcjAzdkhNcVhQRlVqTkNRUzB1Mm01QjBZVUFHZUl3UkglMkJRWXpUUHMyUEdMMDQzUlFBJTNEJTNE; cto_bidid=6NqvDl9EUWVHTDZEMjdZVEVad0g2Skh0bDdtMVpCJTJGNiUyRjlBQ3N0JTJCeVZaeUU0dWIzemIzRlVsWjZVWnlDcFh4VnJVQ0xNRERtRCUyQnRDRmU0UkQlMkZOdERHUWJsMmJDREVzdks3SXJjVFNFWXBpOFI2bVklM0Q; cto_dna_bundle=gW3ZBF85WlVTMUslMkYzb3lGS2J1ekVhb2pXaVgyQnF5ZkFyelBXZUIyMEMlMkYlMkZOWnZGbkhVaFBjT1pRcmhvdEdzTlhOcTdKY05RaGt2UVFnSkt2SSUyQmFrWWZ4ZjVBJTNEJTNE; __cf_bm=Gkb0bQ.CRssgRal1ghknMYEnCsmNswZBWIuaMx2X7oM-1708357221-1.0-ATqghKCzNg+KhPGDn/t/63H7GOrNexnTOvVEISsYAqKF7zA+HAvxfHu8TDs+TqTzF5NFX8xRefd66F65w5OJEqjrVf2VjhiR6yBOMzrOJuG5; __utma=235335808.1308491601.1659422191.1708353783.1708357223.12; __utmz=235335808.1708357223.12.5.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utmt=1; cc1=2024-02-20%2000%3A40%3A32; PHPSESSID=22198038_H87q1tYtLEbhlcvsrAd5IZGu6xOHyQ8o; c_type=22; privacy_policy_agreement=0; b_type=2; _ga_MZ1NL4PHH0=GS1.1.1708357236.5.1.1708357301.0.0.0; __utmv=235335808.|2=login%20ever=yes=1^3=plan=normal=1^5=gender=female=1^6=user_id=22198038=1^9=p_ab_id=1=1^10=p_ab_id_2=7=1^11=lang=zh=1; __utmb=235335808.3.10.1708357223; _ga=GA1.2.1308491601.1659422191; _gat_UA-1830249-3=1; _ga_75BBYNYN9J=deleted","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"}self.threads = 12self.capacity = 10000self.standard_time = 10self.user_id = "22198038"self.date = "20240115"self.downloader = Downloader(self.capacity, self.headers, self.threads, self.standard_time, self.date)self.collector = Collector(self.threads, self.user_id, self.headers, self.downloader)# 拿到榜单的json数据,将id添加到collector中def get_multi_page_json(self, time_mode=None, content=None, date=None):# 处理ai榜单if time_mode is not None:self.time_mode = time_modeif self.time_mode == "daily_ai":self.top_num = 50if content is not None:self.content = contentif date is not None:self.date = date# 抓取for i in range(1, self.top_num // 50 + 1):"""example: 1.https://www.pixiv.net/ranking.php?mode=monthly&content=illust&date=20240215&p=1&format=json2.https://www.pixiv.net/ranking.php?mode=daily_ai&content=all&date=20240215&p=1&format=json"""url = f"https://www.pixiv.net/ranking.php?mode={self.time_mode}&content={self.content}&date={self.date}&p={i}&format=json"headers = self.headersheaders.update({"Referer": f"https://www.pixiv.net/ranking.php?mode={self.time_mode}&date={self.date}","x-requested-with": "XMLHttpRequest"})response = requests.get(url, headers=headers, timeout=(4, self.standard_time))if response.status_code == 200:art_works = response.json()["contents"]for i in art_works:self.collector.add(str(i["illust_id"]))else:print(f"Failed to get json data from: {url}")time.sleep(1)def run(self):self.get_multi_page_json()# self.get_multi_page_json(time_mode="daily_ai", content="all")self.collector.collect()self.downloader.download()if __name__ == "__main__":RankingCrawler().run()"""思路整理:1.首先通过RankingCrawler类的get_multi_page_json方法,获取榜单的json数据,将id添加到collector中2.然后通过collector的collect方法,遍历每个id,用get_artworks_urls方法获取id页面内的所有图片的urls,将url添加到downloader中3.最后通过downloader的download方法,多线程调用同class内的download_image方法同时下载图片"""
喜欢的话不妨点个赞吧?有人互动的感觉才能支撑我继续发文章呀~
相关文章:
)
python---Pixiv排行榜图片获取(2024.2.16)
1.提示: 使用需要安装各种import的包,都是很基础的包,直接安装即可。 自备梯子 。 切记把userid和cookie改为自己账号的参数! userid就是点击pixiv头像,网址后面一串数, cookie是打开排行榜后,…...
QT3作业
1 2. 使用手动连接,将登录框中的取消按钮使用qt4版本的连接到自定义的槽函数中,在自定义的槽函数中调用关闭函数,将登录按钮使用t5版本的连接到自定义的槽函数中,在槽函数中判断ui界面上输入的账号是否为"admin"&#…...

零基础,两个月,如何蓝桥杯备战?
本文约4000字,阅读时长8~12分钟。 首先说明,目前0算法基础,想在两个月后的蓝桥杯拿奖,有一定难度,但也不是完全没可能。在这么短的时间内选择正确的方法,做高性价比的事就尤为重要。 我是蓝桥云课省赛无忧…...
基于Java+小程序点餐系统设计与实现(源码+部署文档)
博主介绍: ✌至今服务客户已经1000、专注于Java技术领域、项目定制、技术答疑、开发工具、毕业项目实战 ✌ 🍅 文末获取源码联系 🍅 👇🏻 精彩专栏 推荐订阅 👇🏻 不然下次找不到 Java项目精品实…...

炫酷3D按钮
一.预览 该样式有一种3D变换的高级感,大家可以合理利用这些样式到自己的按钮上 二.代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice…...

世界顶级名校计算机专业学习使用教材汇总
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-IauYk2cGjEyljid0 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...

通过ffmpeg实现rtsp rtmp rtmps 推流
安卓端推流直接引用 implementation com.arthenica:mobile-ffmpeg-full:4.4 包 记得添加网络权限 <uses-permission android:name"android.permission.INTERNET" /> 基本方法: public static long executionId; Override protected void onCr…...

基于springboot+vue的高校学科竞赛系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...
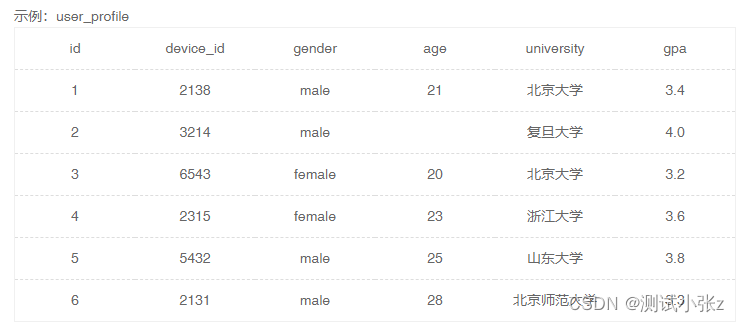
SQL 练习题目(入门级)
今天发现了一个练习SQL的网站--牛客网。里面题目挺多的,按照入门、简单、中等、困难进行了分类,可以直接在线输入SQL语句验证是否正确,并且提供了测试表的创建语句,也可以方便自己拓展练习,感觉还是很不错的一个网站&a…...
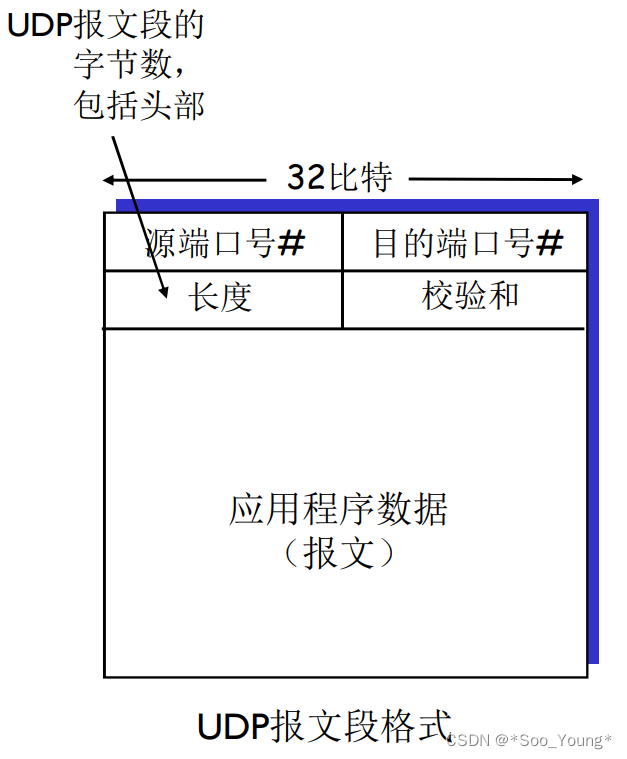
中科大计网学习记录笔记(十四):多路复用与解复用 | 无连接传输:UDP
前言: 学习视频:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程 该视频是B站非常著名的计网学习视频,但相信很多朋友和我一样在听完前面的部分发现信…...
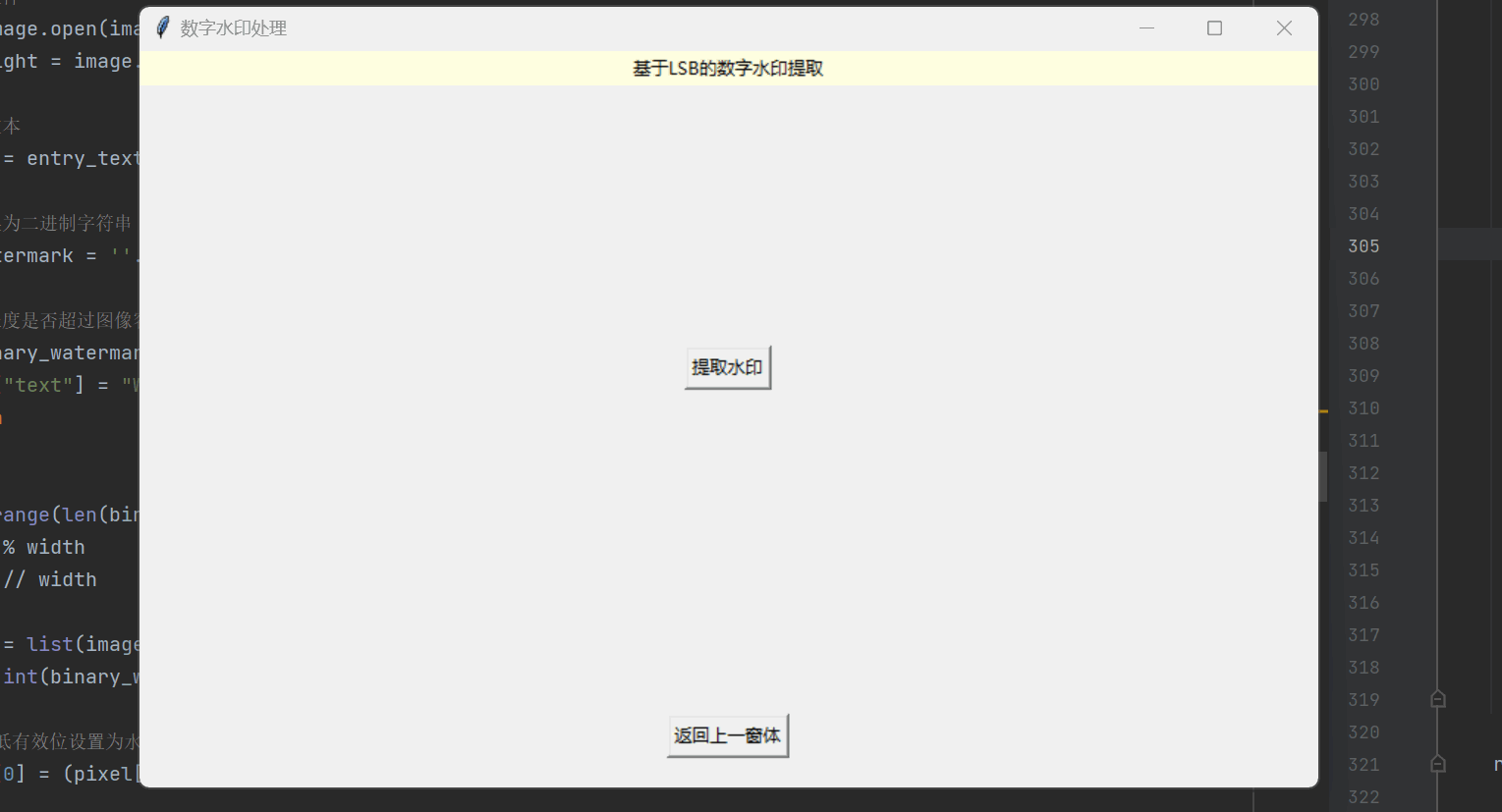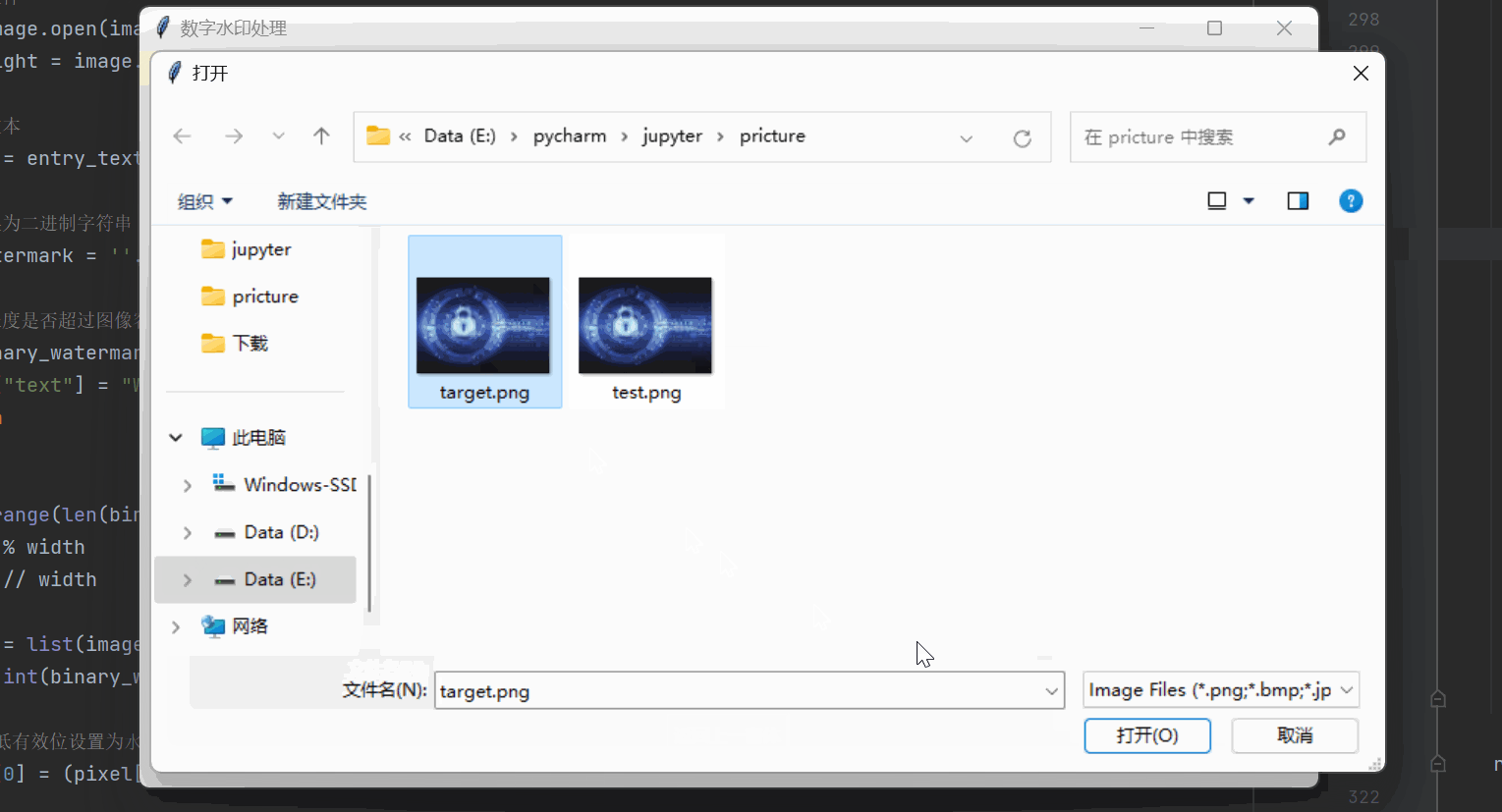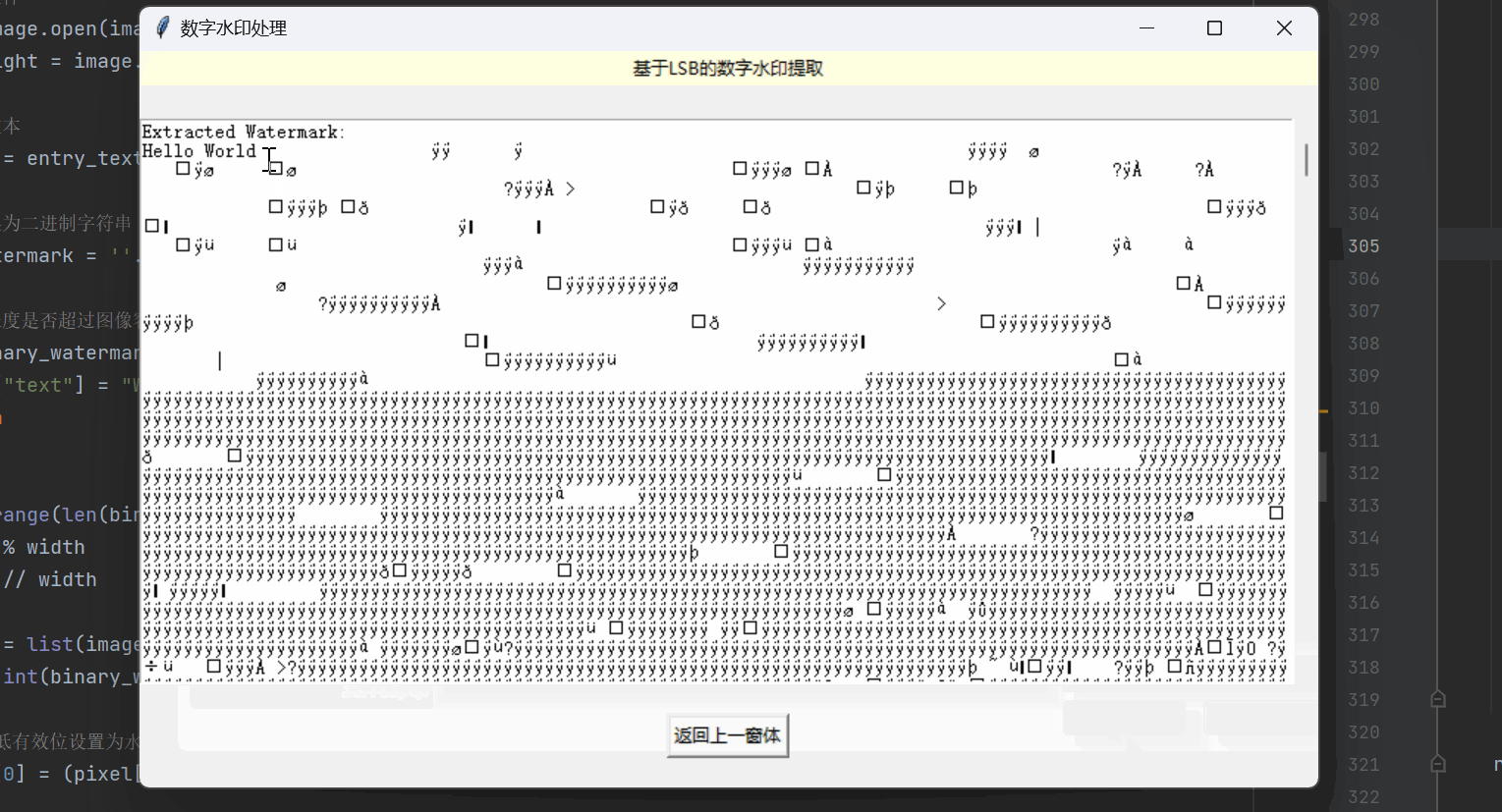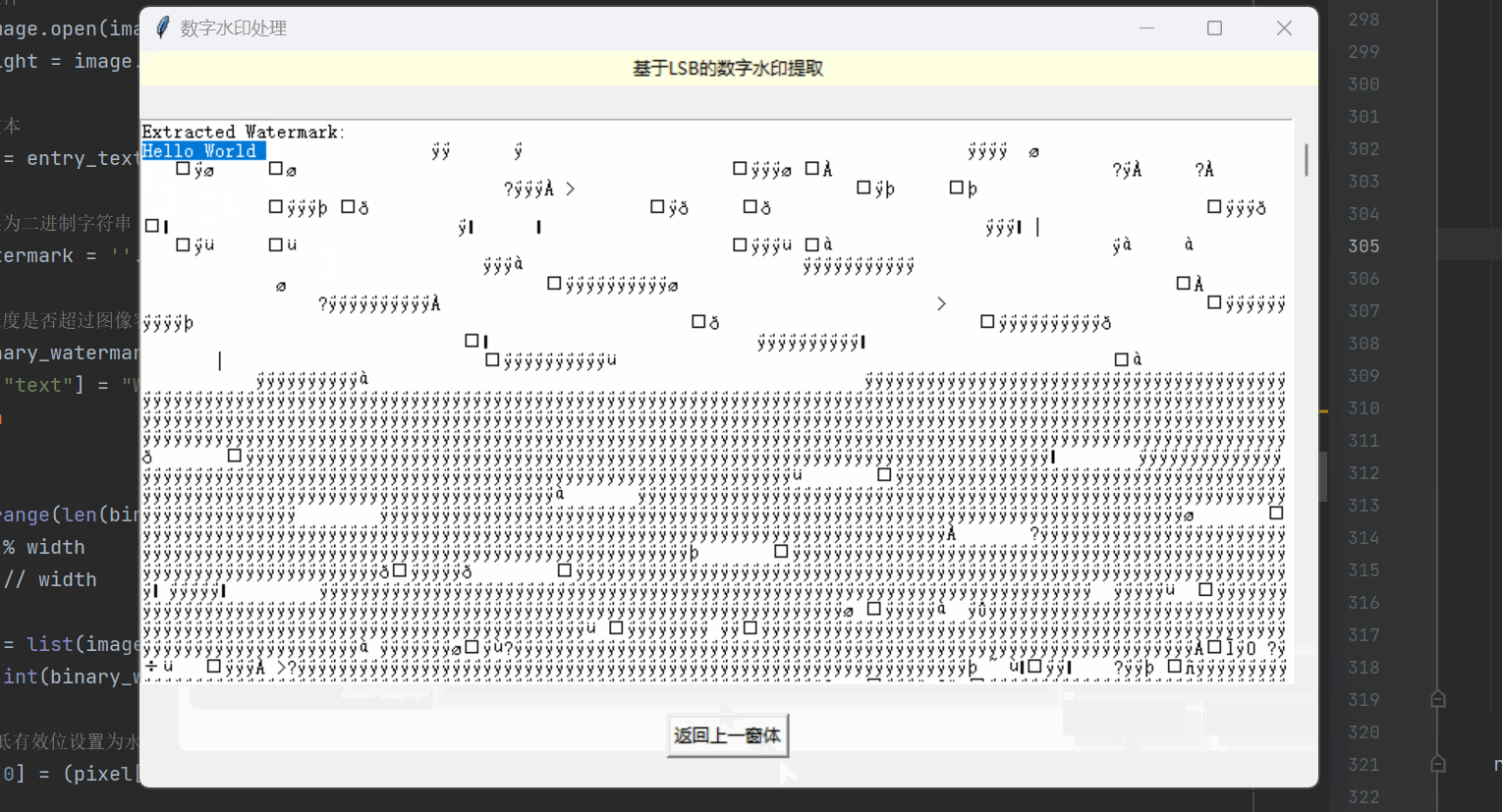
机器学习 | 实现图像加密解密与数字水印处理
目录 实现窗口可视化 数字图像加密 窗口布局设置 基于混沌Logistic的图像加密 基于三重DES的图像加密 数字图像解密 窗口布局设置 基于混沌Logistic的图像解密 基于三重DES的图像解密 基于LSB的数字水印提取 窗口布局设置 水印的嵌入与提取 实现窗口可视化 这里…...
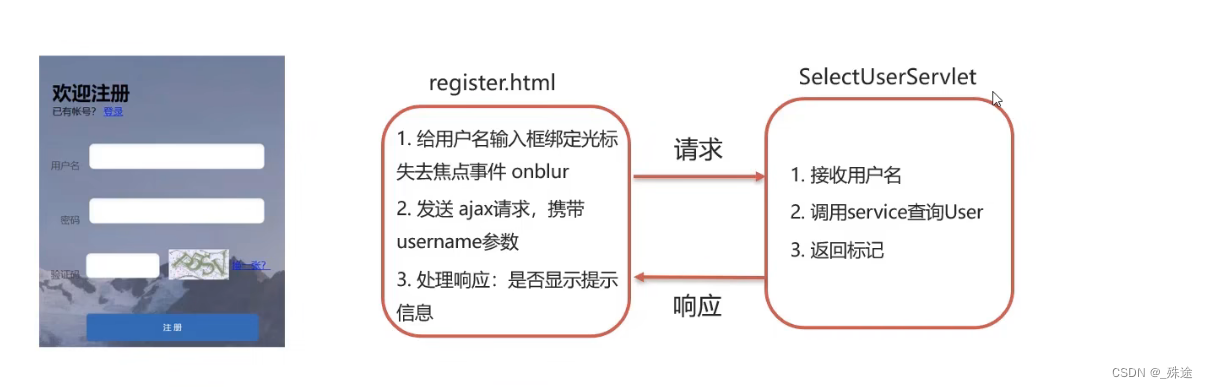
AJAX.
概念:AJAX:异步的 JavaScript 和 XML AJAX作用: 1.与服务器进行数据交换: 通过AJAX可以给服务器发送请求,并获取服务器响应的是数据 使用了AJAX和服务器进行通讯,就可以使用HTML和AJAX来替换JSP页面了 2.异步交互:可以在不重新加载整个页面的…...
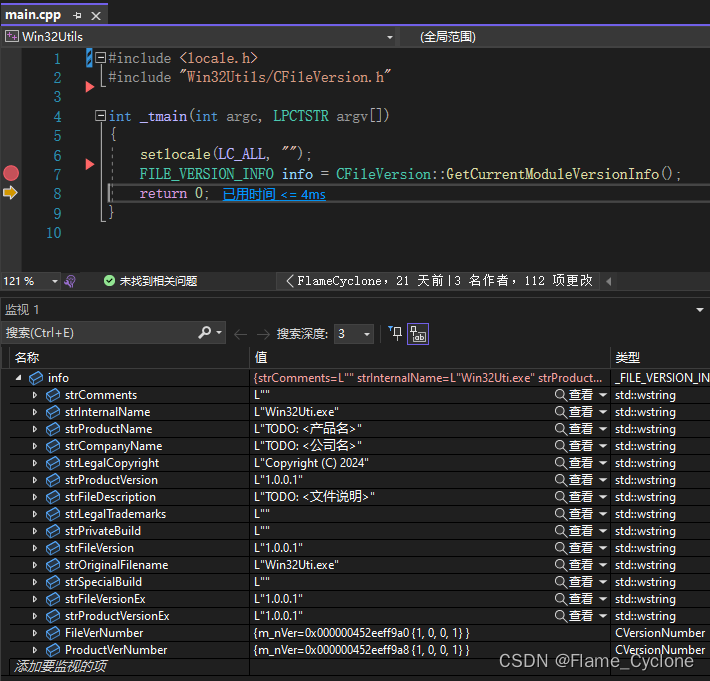
Win32 获取EXE/DLL文件版本信息
CFileVersion.h #pragma once#include <windows.h> #include <string> #include <tchar.h>#ifdef _UNICODE using _tstring std::wstring; #else using _tstring std::string; #endif// 版本号辅助类 class CVersionNumber { public:// 无参构造CVersionN…...
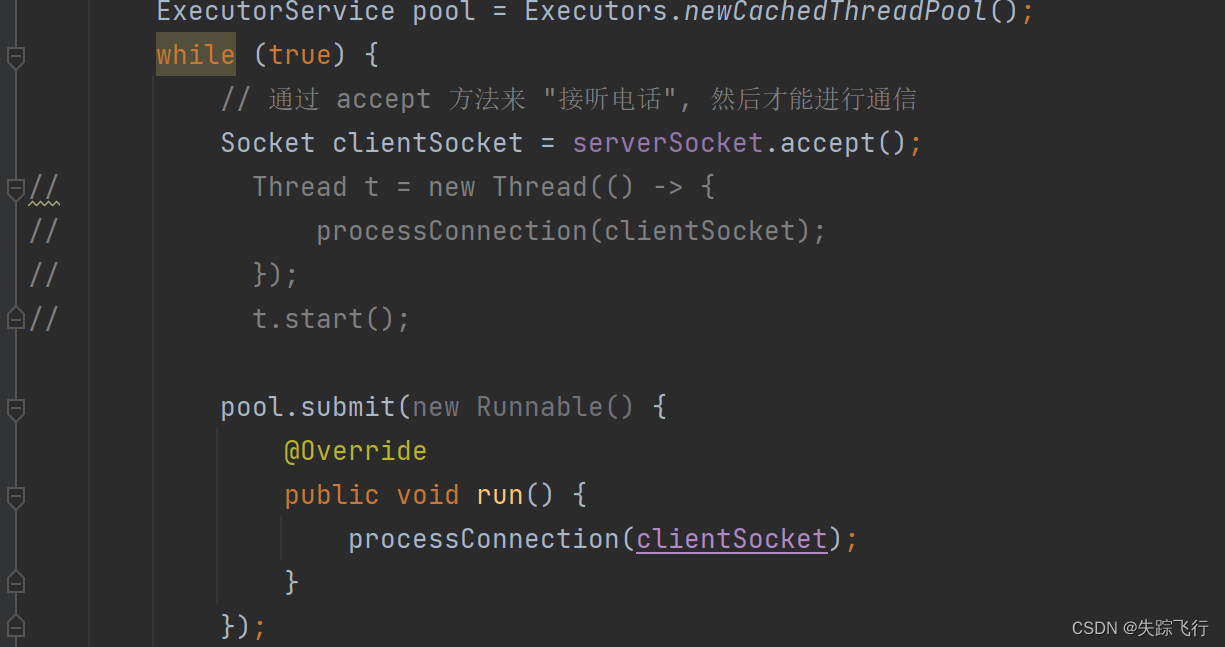
回显服务器的制作方法
文章目录 客户端和服务器TCP和UDP的特点UDP socket api的使用DatagramSocketDatagramPacketInetSocketAddress API 做一个简单的回显服务器UDP版本的回显服务器TCP版本的回显服务器 客户端和服务器 在网络中,主动发起通信的一方是客户端,被动接受的这一方…...
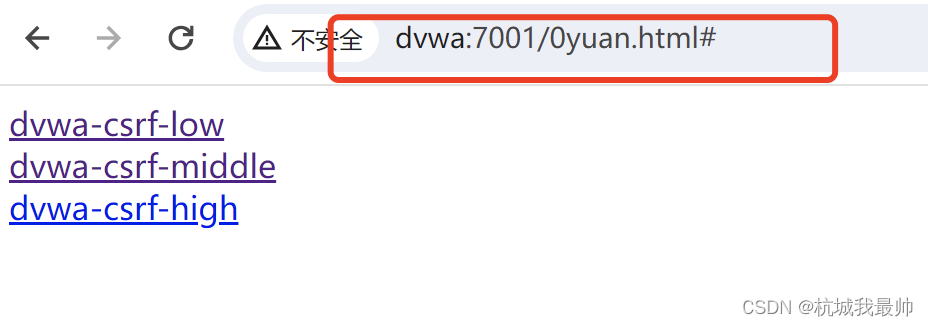
w28DVWA-csrf实例
DVWA-csrf实例 low级别 修改密码:修改的密码通过get请求,暴露在url上。 写一个简单的html文件,里面伪装修改密码的文字,代码如下: <html><body><a href"http://dvwa:7001/vulnerabilities/csr…...

子网络划分与互通,上网行为审计
网络环境需求:在办公网络环境中,由于公司部门的划分,以及服务器、电脑、手机等设备类型,一般都需要划分多个网段,便于进行网络管理,并提升网络通信效率。各个子网段管理员控制设备的接入,子网段之间需要进行局域网通信,发送消息和文件,通常使用飞秋。服务器网段,禁止…...

如何快速删除node_module依赖包
利用npm:输入 npm install rimraf -g rimraf node_modules...

async/await 的用法
一、async和await定义 async 是异步的意思,而 await 是等待的意思,await 用于等待一个异步任务执行完成的结果。 1.async/await 是一种编写异步代码的新方法(以前是采用回调和 promise)。 2. async/await 是建立在 promise 的基础…...
JAVA面试汇总总结更新中ing
本人面试积累面试题 基础RocketMQSpring登录技能操作线程事务微服务JVMKAFKAMYSQLRedislinux 基础 1.面向对象的三个特征 封装,继承,多态,有时候也会加上抽象。 2.多态的好处 允许不同类对象对同一消息做出响应,即同一消息可以根…...

vue-利用属性(v-if)控制表单(el-form-item)显示/隐藏
表单控制属性 v-if 示例: 通过switch组件作为开关,控制表单的显示与隐藏 <el-form-item label"创建数据集"><el-switch v-model"selectFormVisible"></el-switch></el-form-item><el-form-item label&…...

别再死记硬背了!用Python写个语法分析器,帮你彻底搞懂英语非谓语动词
用Python构建英语非谓语动词分析器:从语法规则到代码逻辑 引言:当编程遇上英语语法 英语学习中最令人头疼的部分莫过于非谓语动词——那些不做谓语的动词形式,包括不定式、分词和动名词。传统学习方法要求死记硬背各种规则和例外,…...

通过Taotoken CLI工具一键配置开发环境中的多工具API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境中的多工具API密钥 在团队协作开发或需要同时使用多个AI工具的项目中,手动为每个…...

B站视频转换终极指南:3分钟掌握m4s转MP4永久保存技巧
B站视频转换终极指南:3分钟掌握m4s转MP4永久保存技巧 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾因B站视频突然下架而痛…...

避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南
避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南 在芯片设计领域,可测试性设计(DFT)是确保产品质量的关键环节。而作为DFT的重要组成部分,存储器内建自测试(MBIST)的实现质量直接影响着…...

D1021UK,125W高功率输出的推挽式DMOS RF FET射频晶体管
简介今天我要向大家介绍的是 TT Electronics/Semelab 的金金属化多用途硅DMOS RF FET晶体管——D1021UK。这是一款专为HF/VHF/UHF通信频段(1 MHz至400 MHz)设计的推挽式(Push-Pull)射频功率场效应管,在28V工作电压下可…...

IGBT开关波形实测分析:用示波器抓取米勒平台与拖尾电流,优化你的驱动参数
IGBT开关波形实战解析:从示波器捕获到驱动参数优化 当你在实验室里面对一块IGBT电路板,示波器屏幕上跳动的波形往往藏着关键的设计秘密。那些看似平常的米勒平台、拖尾电流和电压尖峰,实际上是功率器件在向你诉说它的工作状态。本文将带你深入…...

思源宋体TTF实战秘籍:三步搞定专业中文字体配置
思源宋体TTF实战秘籍:三步搞定专业中文字体配置 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找合适的中文字体而烦恼吗?Source Han Serif C…...
)
别再手动调position了!用MATLAB tiledlayout搞定双坐标轴图(R2019b+保姆级教程)
MATLAB双坐标轴绘图革命:tiledlayout全攻略 在科研绘图和工程可视化领域,双坐标轴图表是展示多维度数据的利器。传统MATLAB绘图方法需要手动计算position属性,代码冗长且难以维护。R2019b版本引入的tiledlayout功能彻底改变了这一局面&#x…...
)
别再手动算考勤了!我用Python+企业微信API写了个自动统计脚本(附源码)
告别手工考勤:Python企业微信API自动化统计实战指南 每次月底统计考勤时,行政同事总要加班到深夜,手动核对上百条打卡记录。迟到、早退、外勤打卡...各种状态让人眼花缭乱。作为技术团队的一员,我决定用Python企业微信API打造一个…...

Perplexity搜索功能隐藏入口全解锁:9个未公开Pro技巧,第7个连官方文档都没写!
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索功能隐藏入口全解锁:现象与价值重估 Perplexity.ai 的公开界面长期以简洁问答框为核心,但其底层实际嵌套了多组未在UI中显式暴露的高级搜索能力——包括语义过滤、…...