Python爬虫实战入门:爬取360模拟翻译(仅实验)
文章目录
- 需求
- 所需第三方库
- requests
- 实战教程
- 打开网站
- 抓包
- 添加请求头等信息
- 发送请求,解析数据
- 修改翻译内容以及实现中英互译
- 完整代码
需求
目标网站:
https://fanyi.so.com/#
要求:爬取360翻译数据包,实现翻译功能
所需第三方库
requests
简介
requests 模块是 python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
实战教程
打开网站
https://fanyi.so.com/#

进入网站之后鼠标右击检查,或者F12来到控制台,点击网络,然后刷新。
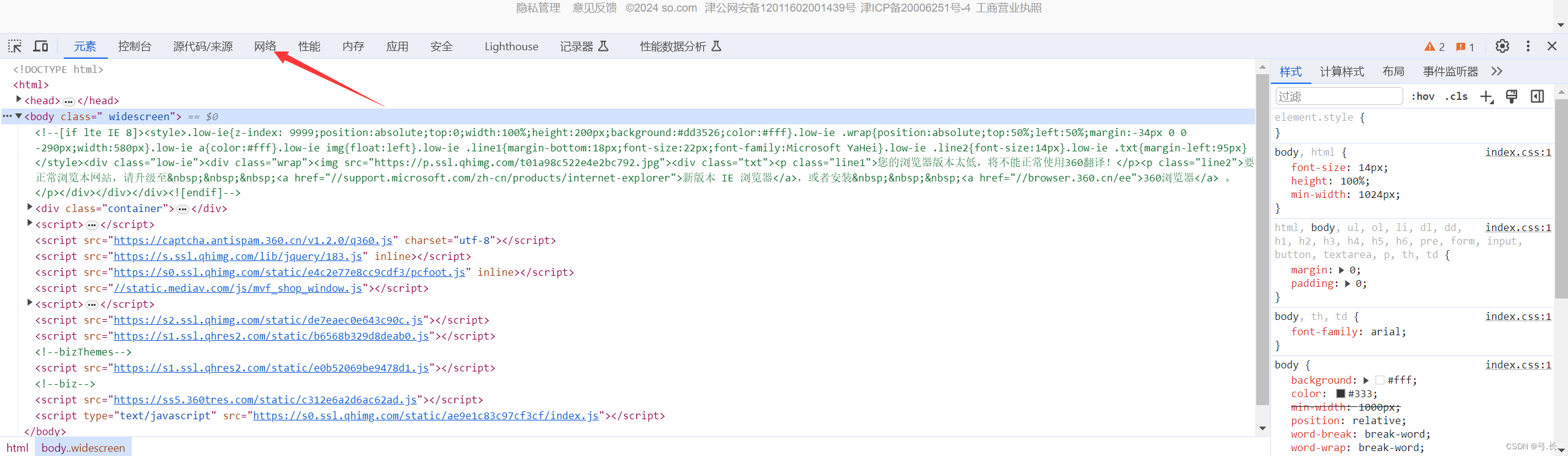
抓包
点击网络刷新之后,在点击Fetch/XHR,随意输入一个单词,点击翻译会发现出现一个数据包,这个数据包就是我们所需要的。

点击这个数据包,然后点击标头,这里就有我们所需要的请求网址
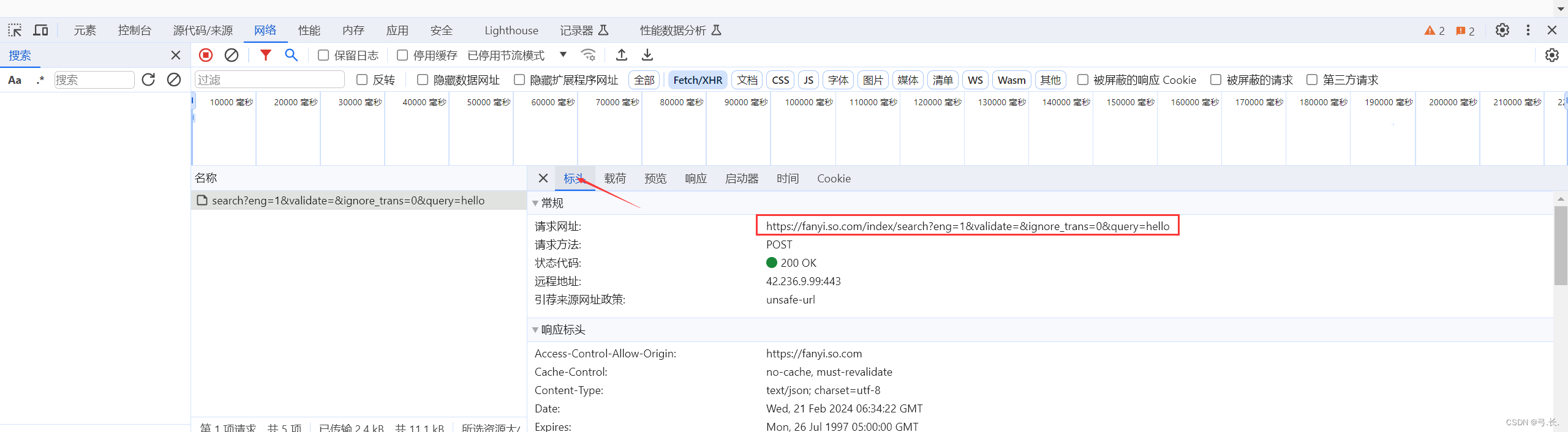
# 导入requests模块
import requests# 请求网址
url = 'https://fanyi.so.com/index/search?eng=1&validate=&ignore_trans=0&query=hello'
添加请求头等信息
一般网站都会设置一定的反爬机制。很多爬虫向服务器请求数据,或者爬虫要请求很多信息时,会给服务器造成很大压力,严重时可能导致服务器宕机,那么,针对爬虫就会产生对应的反爬机制,比如识别user-agent就是一个初级的反爬机制,当访问者没有携带user-agent时,网站就会默认访问者是爬虫,从而可以拒绝提供信息反馈。
在标头下面有请求标头,把这些全部复制下来就行。

# 获取请求头信息
headers = {'Accept': 'application/json, text/plain, */*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Content-Length': '0','Cookie': 'QiHooGUID=F02A63E0BCB72DB4A01C21FA023475E1.1703769301607; Q_UDID=00b0237e-501b-1360-b2eb-96b79d1ac5ec; __guid=144965027.253643186935022000.1703769305042.223; count=2','Origin': 'https://fanyi.so.com','Pro': 'fanyi','Referer': 'https://fanyi.so.com/','Sec-Ch-Ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"','Sec-Ch-Ua-Mobile': '?0','Sec-Ch-Ua-Platform': '"Windows"','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
发送请求,解析数据
在获取请求网址那里可以看到,这个数据包是POST请求。也就是说我们需要额外的参数。点击载荷,下面这些就是我们所需要的数据。

# post请求所需要的额外参数(数据类型为字典数据类型)
data_dic = {'eng': 1,'ignore_trans': 0,'query': 'hello'
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
解析数据,打印翻译内容
点击预览可以看到,fanyi就是我们之前输入的单词翻译后的内容。现在只需要通过字典的形式取取值就可以得到翻译后的内容。
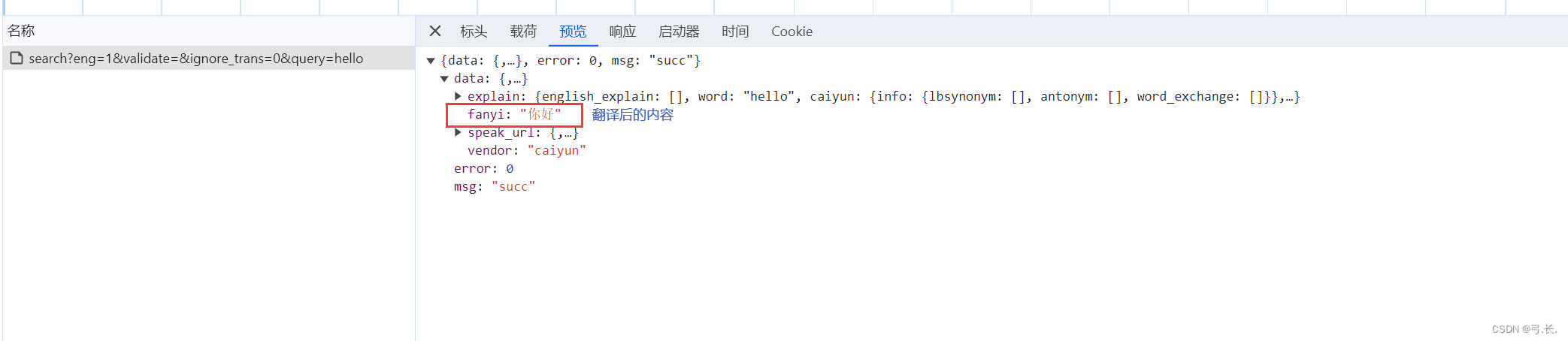
data_dic = {'eng': 1,'ignore_trans': 0,'query': 'hello'
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
# 将响应内容转化成json数据类型
data = res.json()
# 打印翻译内容
print(data['data']['fanyi'])

修改翻译内容以及实现中英互译
从之前载荷里的数据可以猜出query就是我们所输入的单词,那么我们直接用input去代替我们所要翻译的单词就可以了。
# 改变query的值
word = input('请输入你要翻译的内容:')
# post请求所需要的额外参数(数据类型为字典数据类型)
data_dic = {'eng': 1,'ignore_trans': 0,'query': word
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
# 将响应内容转化成json数据类型
data = res.json()
# 打印翻译内容
print(data['data']['fanyi'])

实现中英互译
可以看到,目前程序只能实现英译中,是无法实现中译英的。

现在我们不妨先试验一下,用360翻译实现中译英,现在我们发现,载荷数据第一行eng在英译中时的值是1,现在中译英之后就变成了0,也就说明,是英译中还是中译英就取决于这个参数。所以现在我们只要判断在程序中输入的是中文还是英文就行啦。

我们知道,python中UTF-8编码下,一个英文字符占1个字节,一个中文字符(通常是汉字)占3个字节。,所以我们只要判断程序中输入的第一个字的字节长度,就可以判断输入的是中文还是英文啦。
# 改变query的值
word = input('请输入你要翻译的内容:')
# 获取输入的内容是中文还是英文
lenght = len(word[0].encode('utf-8'))
# 判断,如果输入的是中文,这翻译为英文;如果输入的是英文,这翻译为中文
if lenght == 3:eng = 0
else:eng = 1
# post请求所需要的额外参数(数据类型为字典数据类型)
data_dic = {'eng': eng,'ignore_trans': 0,'query': word
}
# 发送请求,获取响应
res = requests.post(url, headers=headers, data=data_dic)
# 将响应内容转化成json数据类型
data = res.json()
# 打印翻译内容
print(data['data']['fanyi'])

这样我们就实现中英互译啦。当然还可以在原先的基础上在改进一下,比如可以加一个死循环,实现多次翻译等等。
完整代码
# 导入requests模块
import requests# 获取360翻译的翻译的数据包地址
url = 'https://fanyi.so.com/index/search?eng=1&validate=&ignore_trans=0&query=hello'
# 获取请求头等伪装信息
head = {'Accept': 'application/json, text/plain, */*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Content-Length': '0','Cookie': 'QiHooGUID=F02A63E0BCB72DB4A01C21FA023475E1.1703769301607; Q_UDID=00b0237e-501b-1360-b2eb-96b79d1ac5ec; __guid=144965027.253643186935022000.1703769305042.223; count=2','Origin': 'https://fanyi.so.com','Pro': 'fanyi','Referer': 'https://fanyi.so.com/','Sec-Ch-Ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"','Sec-Ch-Ua-Mobile': '?0','Sec-Ch-Ua-Platform': '"Windows"','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 运行之后可以反复翻译
while 1:# 改变query的值word = input('请输入你要翻译的内容:')# 获取输入的内容是中文还是英文lenght = len(word[0].encode('utf-8'))# 判断,如果输入的是中文,这翻译为英文;如果输入的是英文,这翻译为中文if lenght == 3:eng = 0else:eng = 1# post请求所需要的额外参数(数据类型为字典数据类型)data_dic = {'eng': eng,'ignore_trans': 0,'query': word}# 发送请求,获取响应res = requests.post(url, headers=head, data=data_dic)# 将响应内容转化成json数据类型data = res.json()# 打印翻译内容print(data['data']['fanyi'])
相关文章:
Python爬虫实战入门:爬取360模拟翻译(仅实验)
文章目录 需求所需第三方库requests 实战教程打开网站抓包添加请求头等信息发送请求,解析数据修改翻译内容以及实现中英互译 完整代码 需求 目标网站:https://fanyi.so.com/# 要求:爬取360翻译数据包,实现翻译功能 所需第三方库 …...
微服务-微服务API网关Spring-clould-gateway实战
1. 需求背景 在微服务架构中,通常一个系统会被拆分为多个微服务,面对这么多微服务客户端应该如何去调用呢? 如果根据每个微服务的地址发起调用,存在如下问题: 1.客户端多次请求不同的微服务,会增加客户端…...

ECMAScript modules规范示例详解
ECMAScript modules(简称 ES modules)是JavaScript的标准模块系统。每个模块都是一个独立的JavaScript文件,可以在其中定义导出的变量、函数或类,并从其他模块中导入这些变量、函数或类。以下是ES modules规范的一些示例和详解&am…...

【OpenFeign常用配置】
OpenFeign常用配置 快速入门:1、引入依赖2、启用OpenFeign 实践1、引入依赖2、开启连接池功能3、模块划分4、日志5、重试 快速入门: OpenFeign是一个声明式的http客户端,是spring cloud在eureka公司开源的feign基础上改造而来。其作用及时基于…...
第2.1章 StarRocks表设计——概述
注:本篇文章阐述的是StarRocks-3.2版本的表设计相关内容。 建表是使用StarRocks非常重要的一环,规范化的表设计在某些场景下能使查询性能有数倍的提升。StarRocks的表设计涉及到的知识点主要包括数据表类型、数据分布(分区分桶及排序键&#…...
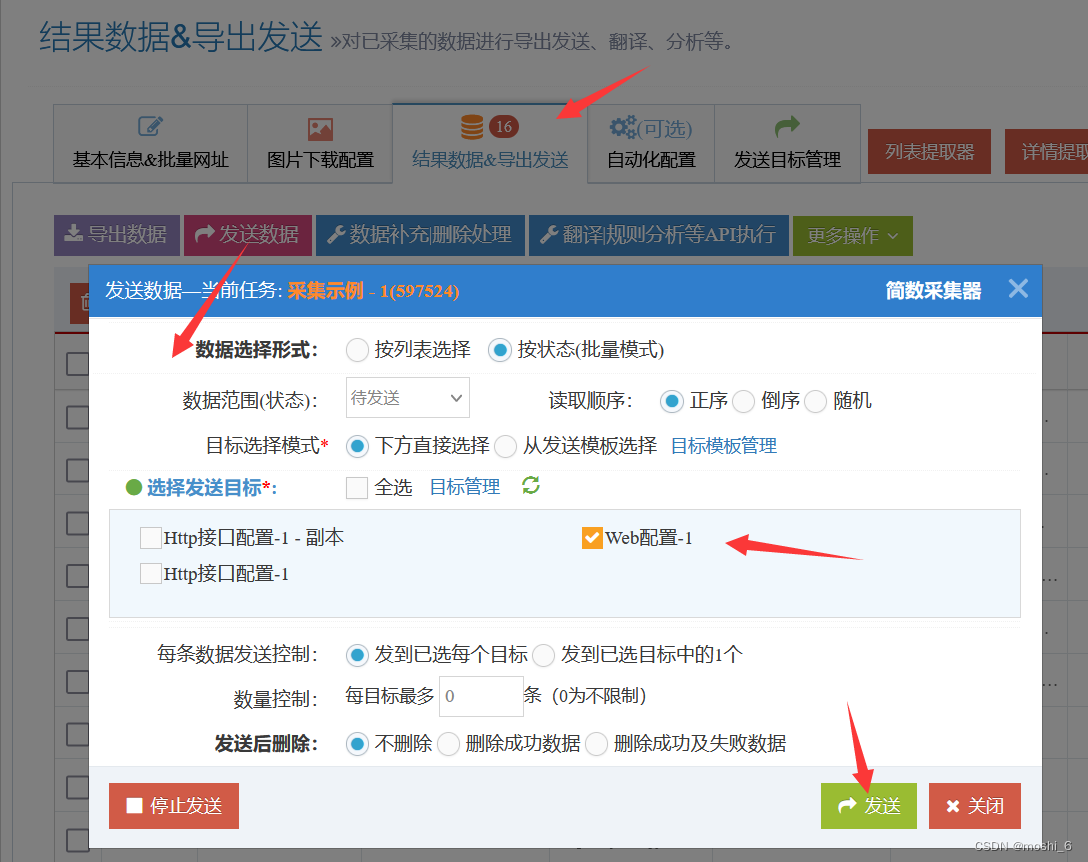
WooCommerce商品采集与发布插件
如何采集商品或产品信息,并自动发布到Wordpress系统的WooCommerce商品? 推荐使用简数采集器,操作简单方便,且无缝衔接WooCommerce插件,快速完成商品的采集与发布。 简数采集器的智能自动生成采集规则和可视化操作功能…...

select滑动分页请求数据
需求背景 Antd 的 select 组件支滑动分页获取后端数据 实现滑动加载数据 定义变量 const allLoadedRef useRef<boolean>(true); // 是否触底 const [current, setCurrent] useState<number>(1); // 当前页 const [list, setList] useState([]); // 列表定义…...

【Go channel如何控制goroutine并发执行顺序?】
多个goroutine并发执行时,每一个goroutine抢到处理器的时间点不一致,gorouine的执行本身不能保证顺序。即代码中先写的gorouine并不能保证先执行 思路:使用channel进行通信通知,用channel去传递信息,从而控制并发执行…...
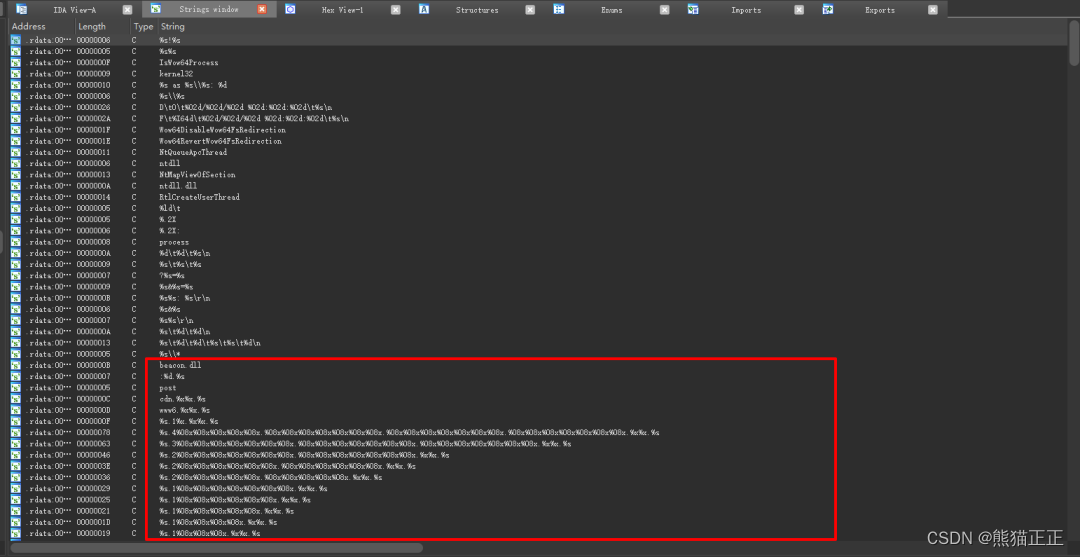
逆向分析Cobalt Strike安装后门
Cobalt Strike简介 Cobalt Strike是一款基于java的渗透测试神器,也是红队研究人员的主要武器之一,功能非常强大,非常适用于团队作战,Cobalt Strike集成了端口转发、服务扫描,自动化溢出,多模式端口监听&am…...
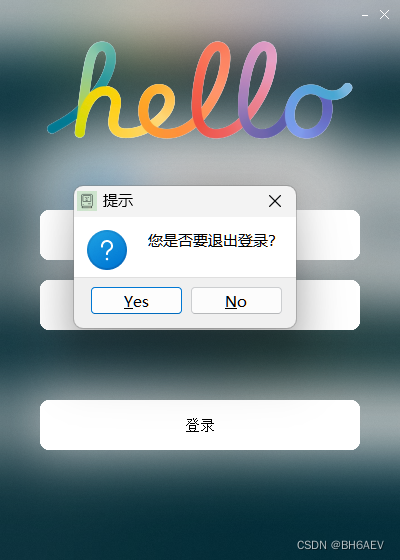
【嵌入式学习】QT-Day3-Qt基础
1> 思维导图 https://lingjun.life/wiki/EmbeddedNote/20QT 2> 完善登录界面 完善对话框,点击登录对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后…...

【杭州游戏业:创业热土,政策先行】
在前面的文章中,我们探讨了上海、北京、广州、深圳等城市的游戏产业现状。现在,我们切换视角,来看看另一个游戏创业热土——杭州的发展情况 最近第19届亚运会在杭州举办,本次亚运会上,电子竞技首次获准列为正式比赛项…...

Python-pdfplumber读取PDF内容
文章目录 前言一、pdfplumber模块1.1 pdfplumber的特点1.2 pdfplumber.PDF类1.3pdfplumber.Page类 二 pdfplumber的使用2.1 加载PDF2.2 pdfplumber.PDF 类2.3 pdfplumber.Page 类2.4 读取PDF2.5 读取PDF文档信息2.6 查看总页数2.7 查看总页数读取第一页的宽度,页高等…...

js设计模式汇总
目录 前言: 单篇目录: 工厂模式 单例模式 发布订阅模式 观察者模式 中介者模式 建造者模式 解释器模式 依赖注入模式 享元模式 路由模式 计算属性模式 委托者模式 访问者模式 外观模式 备忘录模式 过滤器模式 模板方法模式 状态模式 桥接模式 原型模式 组…...

【Java面试】MongoDB
目录 1、mongodb是什么?2、mongodb特点什么是NoSQL数据库?NoSQL和RDBMS有什么区别?在哪些情况下使用和不使用NoSQL数据库?NoSQL数据库有哪些类型?启用备份故障恢复需要多久什么是master或primary什么是secondary或slave系列文章版…...
在苹果电脑MAC上安装Windows10(双系统安装的详细图文步骤教程)
在苹果电脑MAC上安装Windows10(双系统安装的详细图文步骤教程) 一、准备工作准备项1:U盘作为系统安装盘准备项2:您需要安装的系统镜像 二、启动转换助理步骤1:找到启动转换助理步骤2:启动转换助理步骤3&…...
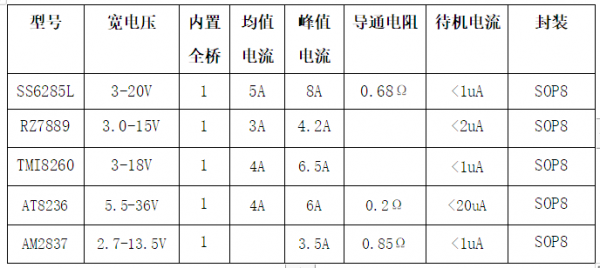
18V/5A桥式驱动芯片-SS6285L兼容替代RZ7889
SS6285L是一款由工采网代理的率能DC双向马达驱动电路芯片;该芯片采用SOP8封装,符合ROHS规范,引脚框架100%无铅;它适用于玩具等类的电机驱动、自动阀门电机驱动、电磁门锁驱动等应用。 (1)产品描述ÿ…...

C++ Primer 笔记(总结,摘要,概括)——第3章 字符串、向量和数组
目录 3.1 命名空间的using声明 3.2 标准库类型string 3.2.1 定义和初始化string对象 3.2.2 string对象上的操作 3.2.3 处理string对象中的字符 3.3 标准库类型vector 3.3.1 定义和初始化vector对象 3.3.2 向vector对象中添加元素 3.3.3 其他vector操作 3.4 迭代器介绍 3.4.…...
Sora:OpenAI引领AI视频新时代
Sora - 探索AI视频模型的无限可能 随着人工智能技术的飞速发展,AI视频模型已成为科技领域的新热点。而在这个浪潮中,OpenAI推出的首个AI视频模型Sora,以其卓越的性能和前瞻性的技术,引领着AI视频领域的创新发展。让我们将一起探讨…...

[FPGA开发工具使用总结]VIVADO在线调试(1)-信号抓取工具的使用
目录 1简介2 添加观测信号的几种方法2.1 通过定制IP核添加2.2 通过约束文件添加2.3 通过GUI生成DEBUG约束文件2.4 两种方法的优点与缺点 3在线调试方法3.1 器件扫描设置3.2 触发条件设置3.3 触发窗口设置3.4 采样过程控制 4常见问题4.1 时钟域的选择4.2 缺少LTX文件4.3 ILA无时…...

Linux ip route命令
理解ip route命令 ip route是Linux系统中的一个非常常用的命令,它用于配置和管理Linux的路由表。通过ip route命令,管理员可以查看、添加、删除或修改Linux系统的路由表,从而决定数据包如何在网络中传输。例如,当一台Linux机器需要…...

TDD 工作流深度实践:测试驱动开发遇上 AI 智能体
作者注:本文基于 ECC 项目的 TDD 工作流 Skill,展示如何在 AI 编码助手的辅助下严格执行测试驱动开发。项目开源地址:github.com/affaan-m/ECC摘要 测试驱动开发(TDD)是保障代码质量的金标准,但在实际落地中…...

Agent+可穿戴设备:心率、睡眠、活动数据如何变成有价值的健康建议
可穿戴设备每天都会产生心率、睡眠、步数、活动强度等数据,但开发者真正要解决的不是“采集更多指标”,而是把这些指标转成可解释、可追踪、可配置的健康提示。本文从工程角度搭建一个简化版 Agent 服务,演示如何完成数据接入、趋势计算、规则…...

深入Keil5编译器:解读#1295-D警告背后的C语言函数原型进化史
深入Keil5编译器:解读#1295-D警告背后的C语言函数原型进化史 当你在Keil5环境下打开一个遗留的单片机项目时,那个看似微不足道的#1295-D: Deprecated declaration警告可能正暗示着一段跨越四十年的编程语言进化史。这个关于函数声明的警告不是Keil5的任…...

Milk-V Duo开发板深度评测:双核RISC-V Linux系统实战与性能优化
1. 开箱初印象:当“小钢炮”遇上“大算力”刚拿到Milk-V Duo开发板时,我承认我愣了一下。包装盒比常见的信用卡还要小一圈,第一反应是“这怕不是个配件或者核心模块吧?”直到拆开静电袋,这块精致得如同艺术品的开发板本…...

Arm架构AMU性能监控原理与实践指南
1. Arm架构活动监视器(AMU)核心原理活动监视器(Activity Monitors Unit, AMU)是Armv8/v9架构中用于性能监控的关键硬件模块。作为处理器微架构的一部分,AMU通过专用硬件计数器实时采集CPU执行过程中的各类性能事件数据。与传统的性能监控单元(PMU)相比,A…...

如何永久保存微信聊天记录?WeChatMsg让你轻松实现数据自主管理
如何永久保存微信聊天记录?WeChatMsg让你轻松实现数据自主管理 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...

Solidworks 2018+ 机器人模型避坑指南:用SW2URDF插件导出URDF,再导入Webots R2023a完整流程
SolidWorks 2018机器人模型导入Webots全流程避坑指南 在机器人仿真领域,将SolidWorks设计的机械模型准确导入Webots仿真环境是一个关键但充满挑战的环节。许多工程师和学生在初次尝试这一流程时,往往会在版本兼容性、文件路径、坐标系设置等环节遭遇各种…...

探索Artisan:用开源软件解码咖啡烘焙的数据科学
探索Artisan:用开源软件解码咖啡烘焙的数据科学 【免费下载链接】artisan artisan: the worlds most trusted roasting software 项目地址: https://gitcode.com/gh_mirrors/ar/artisan 在咖啡烘焙的世界里,每一次烘焙都是一次精确的化学反应。从…...

Spring Boot 面试题详解:Spring Boot 核心原理、自动配置、启动流程、IoC 容器、Web 请求链路、事务、Actuator 与 JVM 线上排障全攻略
1. Spring Boot 到底是什么?为什么 Java 后端几乎绕不开它?1.1 它不是新语言,也不是替代 Spring,而是 Spring 应用的工程化脚手架Spring Boot 的出现,本质上是为了解决传统 Spring 项目启动慢、配置多、依赖难配、上线…...
)
从‘硬连接’到‘软融合’:拆解U-Net++中那些被重新设计的跳跃连接(Skip Connections)
从‘硬连接’到‘软融合’:拆解U-Net中那些被重新设计的跳跃连接 在医学图像分割领域,U-Net架构因其对称的编码器-解码器结构和跳跃连接设计,成为众多研究的基础框架。然而,当我们面对脑肿瘤、肺结节等尺寸差异显著的病灶时&#…...