【机器学习】数据清洗——基于Pandas库的方法删除重复点

🎈个人主页:豌豆射手^
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
【机器学习】数据清洗 ——基于Pandas库的方法删除重复点
- 一 drop_duplicates() 介绍
- 二 删除重复行
- 三 指定删除重复点时的列
- 四 保留第一个或最后一个出现的重复点
- 五 原地修改DataFrame
- 六 总结
引言
在机器学习领域,高质量的数据是构建强大模型的基石。而数据清洗作为数据预处理的关键步骤之一,对于确保数据质量至关重要。
本博客将重点介绍基于Pandas库的强大功能,特别是drop_duplicates()方法,来处理数据中的重复点。通过深入了解这一方法及其不同应用场景,读者将能够更有效地进行数据清洗,为机器学习任务打下坚实的基础。

一 drop_duplicates() 介绍
drop_duplicates() 方法是 Pandas 库中用于删除 DataFrame 中重复数据的方法。
它返回一个新的 DataFrame,其中不包含重复的行或列。
这个方法有几个重要的参数:
subset:指定要用来判断重复的列或列的组合。默认为 None,表示考虑整个 DataFrame 的所有列。
keep:指定保留重复值的方式。可以是 ‘first’(默认值,保留第一个出现的重复值)、‘last’(保留最后一个出现的重复值)或
False(删除所有重复值)。
inplace:指定是否在原 DataFrame 上直接进行修改,而不是返回一个新的 DataFrame。默认为 False。

二 删除重复行
Pandas提供了drop_duplicates()方法,可以用于删除DataFrame中的重复行。
这个方法会返回一个新的DataFrame,其中不包含重复的行。
示例:
import pandas as pd# 假设df是一个包含重复点的DataFrame
df = pd.DataFrame({'A': [1, 2, 2, 3, 3],'B': ['a', 'b', 'b', 'c', 'c']})# 使用drop_duplicates()方法删除重复行
df_unique = df.drop_duplicates()print(df_unique)
输出:
A B
0 1 a
1 2 b
3 3 c
在上面的例子中,原始DataFrame df 包含重复的行,经过drop_duplicates()方法处理后,返回了一个新的DataFrame df_unique,其中不包含重复的行。

三 指定删除重复点时的列
drop_duplicates()方法还可以接受subset参数,用于指定删除重复点时的列。
默认情况下,该方法会考虑所有的列,但你也可以通过subset参数指定特定的列进行重复点的判断。
示例
import pandas as pd# 创建一个包含重复点的DataFrame
# 注意列A中有重复值,但列B中的值是不同的
df = pd.DataFrame({'A': [1, 1, 2, 2, 3],'B': ['a', 'b', 'c', 'd', 'e']
})print("原始DataFrame:")
print(df)# 使用drop_duplicates()方法,并指定subset参数为列A
# 这意味着只会基于列A的值来判断和删除重复点
df_c = df.drop_duplicates(subset=['A'])print("\n基于列处理后的DataFrame:")
print(df_c)#使用drop_duplicates()方法,不指定subset参数为列A
df_r = df.drop_duplicates()
print("\n基于行处理后的DataFrame:")
print(df_r)输出
原始DataFrame:A B
0 1 a
1 1 b
2 2 c
3 2 d
4 3 e基于列处理后的DataFrame:A B
0 1 a
2 2 c
4 3 e基于行处理后的DataFrame:A B
0 1 a
1 1 b
2 2 c
3 2 d
4 3 e
代码分析:
以上代码首先创建了一个包含重复数据的 DataFrame,其中列 A 中有重复值,但列 B 中的值是不同的。
接着使用 drop_duplicates() 方法,并指定 subset 参数为列 A,这意味着只会基于列 A的值来判断和删除重复的数据点。
处理后的 DataFrame df_c 中只保留了列 A 中的唯一值,并保留了每个唯一值对应的第一个出现的行。
然后,代码使用 drop_duplicates() 方法没有指定 subset 参数,这意味着将考虑整个 DataFrame 的所有列进行去重。
因为B列全是不同的数据,故DataFrame 并没有发生变化。

四 保留第一个或最后一个出现的重复点
drop_duplicates()方法默认保留第一个出现的重复点,但你也可以通过keep参数指定保留最后一个出现的重复点,或者将所有重复点都删除。
示例
import pandas as pd# 创建一个包含重复点的DataFrame
df = pd.DataFrame({'A': [1, 1, 2, 2, 3, 3],'B': ['a', 'b', 'c', 'd', 'e', 'f']
})print("原始DataFrame:")
print(df)# 保留第一个出现的重复点
df_first = df.drop_duplicates(subset=['A'],keep='first')print("\n保留第一个出现的重复点处理后的DataFrame:")
print(df_first)# 保留最后一个出现的重复点
df_last = df.drop_duplicates(subset=['A'],keep='last')print("\n保留最后一个出现的重复点处理后的DataFrame:")
print(df_last)
运行结果:
原始DataFrame:A B
0 1 a
1 1 b
2 2 c
3 2 d
4 3 e
5 3 f保留第一个出现的重复点处理后的DataFrame:A B
0 1 a
2 2 c
4 3 e保留最后一个出现的重复点处理后的DataFrame:A B
1 1 b
3 2 d
5 3 f
代码分析:
以上代码首先创建了一个包含重复数据的 DataFrame,其中列 A 中有重复值,但列 B 中的值是不同的,并且相同列A对应的B元素是不一样的。
接着,使用 drop_duplicates() 方法并指定 subset 参数为列 A,同时设置 keep 参数为 ‘first’,这意味着保留每个重复值中的第一个出现的数据点。
处理后的 DataFrame df_first 中只保留了列 A 中的唯一值,并保留了每个唯一值对应的第一个出现的行。
然后,再次使用 drop_duplicates() 方法指定 subset 参数为列 A,但这次设置 keep 参数为’last’,这意味着保留每个重复值中的最后一个出现的数据点。
处理后的 DataFrame df_last 中只保留了列 A 中的唯一值,并保留了每个唯一值对应的最后一个出现的行。
从代码结果可以看出,因为相同列A对应的B元素是不一样的,所以这两种方式删除重复点后的结果也是不一样
总体而言,这段代码演示了通过 drop_duplicates() 方法结合 subset 和 keep 参数来实现不同的去重策略,分别保留第一个和最后一个出现的重复点,从而得到两个不同的处理后的 DataFrame。

五 原地修改DataFrame
默认情况下,drop_duplicates()方法返回一个新的DataFrame,而不改变原始DataFrame。
但你也可以通过inplace参数将修改应用到原始DataFrame上。
示例
import pandas as pd# 创建一个包含重复数据的 DataFrame
data = {'A': [1, 1, 2, 2, 3],'B': ['a', 'b', 'c', 'c', 'd']
}
df = pd.DataFrame(data)# 显示原始 DataFrame
print("原始 DataFrame:")
print(df)# 删除重复点,并显示修改后的结果
df.drop_duplicates(inplace=True)
print("\n删除重复点后的 原始DataFrame:")
print(df)
运行结果:
原始 DataFrame:A B
0 1 a
1 1 b
2 2 c
3 2 c
4 3 d删除重复点后的 原始DataFrame:A B
0 1 a
1 1 b
2 2 c
4 3 d
在这个例子中,通过inplace=True参数,我们在原地修改了DataFrame,不再返回新的DataFrame,同时原始DataFrame也发生了改变,变为了删除重复值的样子。
将inplace参数改为False,我们会发现输出结果中,原始dataframe并没有发生改变,如:
import pandas as pd# 创建一个包含重复数据的 DataFrame
data = {'A': [1, 1, 2, 2, 3],'B': ['a', 'b', 'c', 'c', 'd']
}
df = pd.DataFrame(data)# 显示原始 DataFrame
print("原始 DataFrame:")
print(df)# 删除重复点,并显示修改后的结果
df.drop_duplicates(inplace=False)
print("\n删除重复点后的 原始DataFrame:")
print(df)输出结果:
原始 DataFrame:A B
0 1 a
1 1 b
2 2 c
3 2 c
4 3 d删除重复点后的 原始DataFrame:A B
0 1 a
1 1 b
2 2 c
3 2 c
4 3 d
六 总结
在本博客中,我们深入探讨了机器学习中数据清洗的关键任务之一——删除重复点的方法,重点介绍了基于Pandas库的drop_duplicates()方法。
我们详细讨论了如何使用这一方法删除数据中的重复行,以及在多列情况下如何指定删除重复点的列,强调了方法的灵活性。
同时,我们解释了通过keep参数选择保留第一个或最后一个出现的重复点的策略,并提及了在处理大型数据集时需要注意的内存效率问题。
通过掌握这一技能,读者将能够更加轻松、灵活和高效地进行数据清洗,确保所使用的数据是准确、可靠且高质量的,为机器学习任务的成功打下坚实的基础。

这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是甜美的江,让我们我们下次再见


相关文章:
【机器学习】数据清洗——基于Pandas库的方法删除重复点
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...
)
顺序表增删改查(c语言)
main函数: #include <stdio.h>#include "./seq.h"int main(int argc, const char *argv[]){SeqList* list create_seqList();insert_seqList(list,10);insert_seqList(list,100);insert_seqList(list,12);insert_seqList(list,23);show_seqList(l…...

MyBatis Plus中的动态表名实践
随着数据库应用的不断发展,面对复杂多变的业务需求,动态表名的处理变得愈发重要。在 MyBatis Plus(以下简称 MP)这一优秀的基于 MyBatis 的增强工具的支持下,我们可以更便捷地应对动态表名的挑战。本文将深入研究如何在…...
JAVA IDEA 项目打包为 jar 包详解
前言 如下简单 maven 项目,现在 maven 项目比较流行,你还没用过就OUT了。需要打包jar 先设置:点击 File > Project Structure > Artifacts > 点击加号 > 选择JAR > 选择From modules with dependencies 一、将所有依赖和模…...

概率基础——几何分布
概率基础——几何分布 介绍 在统计学中,几何分布是描述了在一系列独立同分布的伯努利试验中,第一次成功所需的试验次数的概率分布。在连续抛掷硬币的试验中,每次抛掷结果为正面向上的概率为 p p p,反面向上的概率为 1 − p 1-p …...

JavaScript的内存管理与垃圾回收
前言 JavaScript提供了高效的内存管理机制,它的垃圾回收功能是自动的。在我们创建新对象、函数、原始类型和变量时,所有这些编程元素都会占用内存。那么JavaScript是如何管理这些元素并在它们不再使用时清理它们的呢? 在本节中,…...
Neo4j导入数据之JAVA JDBC
目录结构 前言设置neo4j外部访问代码整理maven 依赖java 代码 参考链接 前言 公司需要获取neo4j数据库内容进行数据筛查,neo4j数据库咱也是头一次基础,辛辛苦苦安装好整理了安装neo4j的步骤,如今又遇到数据不知道怎么创建,关关难…...

LeetCode 2878.获取DataFrame的大小
DataFrame players: ------------------- | Column Name | Type | ------------------- | player_id | int | | name | object | | age | int | | position | object | | … | … | ------------------- 编写一个解决方案,计算并显示 players 的 行数和列数。 将结…...

索引失效的 12 种情况
目录 一、未使用索引字段进行查询 二、索引列使用了函数或表达式 三、使用了不等于(! 或 <>)操作符 四、LIKE 操作符的模糊查询 五、对索引列进行了数据类型转换 六、使用 OR 连接多个条件 七、表中数据量较少 八、索引列上存在大量重复值…...

Spring及工厂模式概述
文章目录 Spring 身世什么是 Spring什么是设计模式工厂设计模式什么是工厂设计模式简单的工厂设计模式通用的工厂设计 总结 在 Spring 框架出现之前,Java 开发者使用的主要是传统的 Java EE(Java Enterprise Edition)平台。Java EE 是一套用于…...

运维SRE-19 网站Web中间件服务-http-nginx
Ans自动化流程 1.网站集群核心协议:HTTP 1.1概述 web服务:网站服务,网站协议即可. 协议:http协议,https协议 服务:Nginx服务,Tengine服务....1.2 HTTP协议 http超文本传输协议,负责数据在网站…...
类型)
C语言—自定义(构造)类型
2.20,17.56 1.只有当我们使用结构体类型定义变量/结构体数组,系统才会为结构体的成员分配内存空间,用于存储对应类型的数据 2.strct 结构体 一起作为结构体类型标识符 嘿嘿暂时先这样,我会回来改的1、定义一个表示公交线路的结构体,要…...
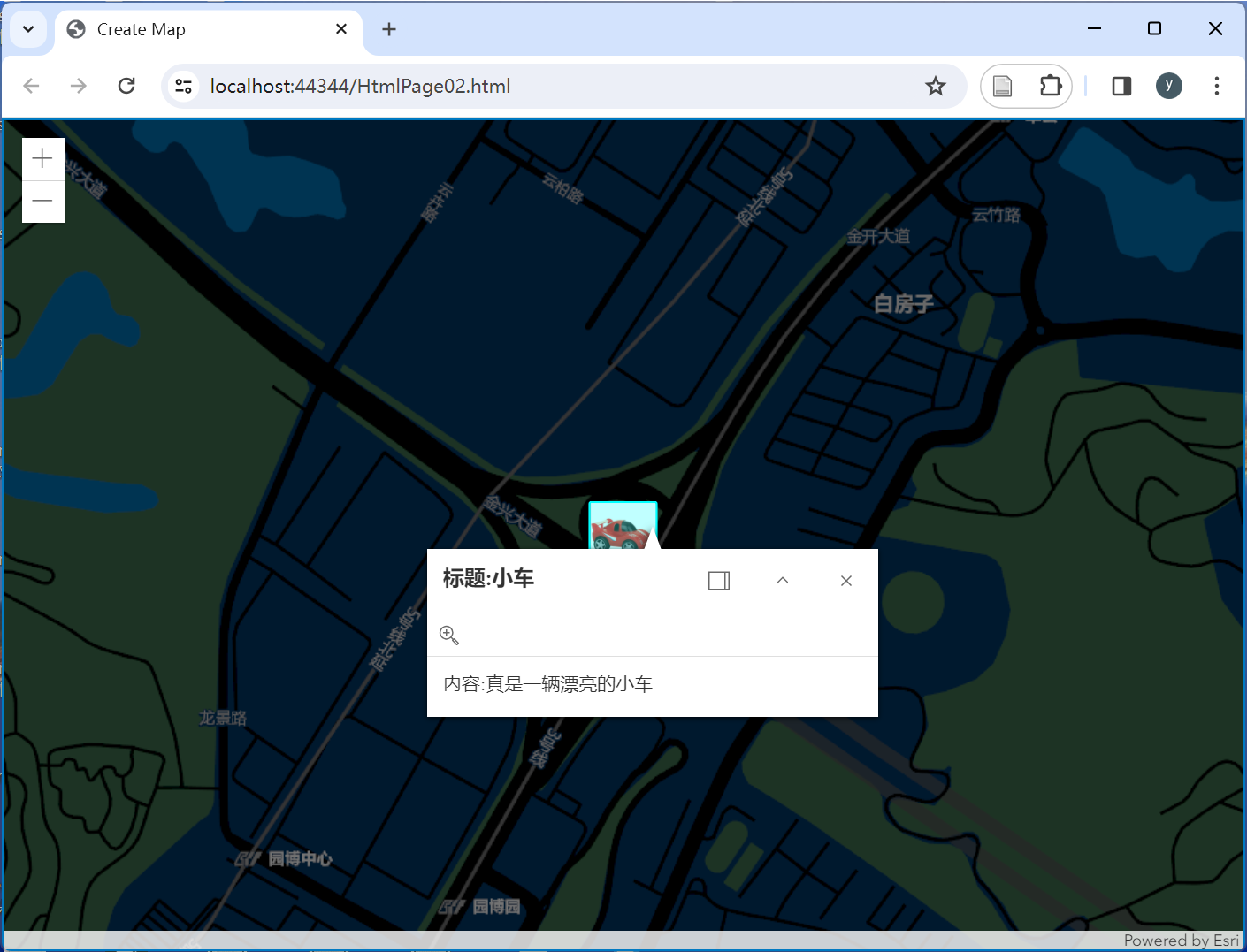
ArcgisForJS如何实现添加含图片样式的点要素?
文章目录 0.引言1.加载底图2.获取点要素的坐标3.添加含图片样式的几何要素4.完整实现 0.引言 ArcGIS API for JavaScript 是一个用于在Web和移动应用程序中创建交互式地图和地理空间分析应用的库。本文在ArcGIS For JavaScript中使用Graphic对象来创建包含图片样式的点要素。 …...
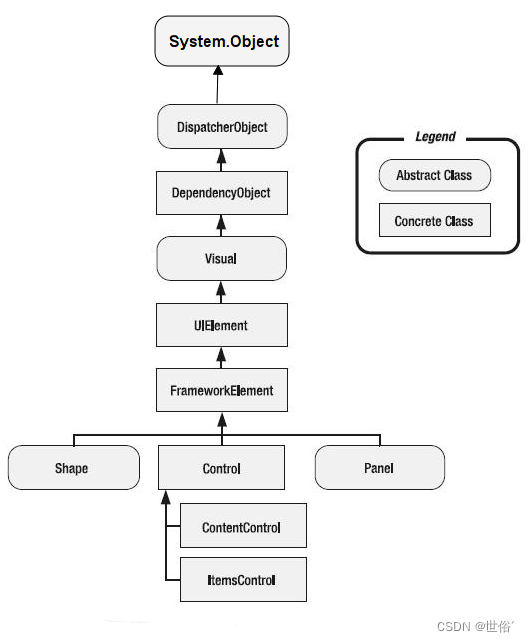
C#之WPF学习之路(2)
目录 控件的父类 DispatcherObject类 DependencyObject类 DependencyObject 类的关键成员和方法 Visual类 Visual 类的主要成员和方法 UIElement类 UIElement 类的主要成员和功能 FrameworkElement类 FrameworkElement 类的主要成员和功能 控件的父类 在 WPF (Windo…...
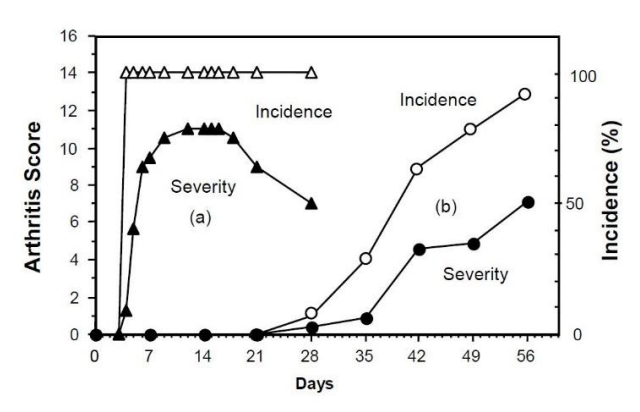
胶原抗体诱导小鼠关节炎模型
胶原诱导性关节炎小鼠(CIA)作为人类类风湿关节炎模型应用广泛,但CIA引起的关节炎起病比较缓慢,造模周期较长,一般为6-8周(1-12)。Chondrex公司已开发出单一种单克隆抗体合剂诱导的小鼠关节炎模型(CAIA),明显缩短了造模…...

集百家所长的开放世界游戏,艾尔莎H311-PRO带你玩转《幻兽帕鲁》
随着近几年开放世界游戏热潮的兴起,如今这类游戏可以说是像雨后春笋般不断推出,比如《幻兽帕鲁》就是近期非常火热的一个代表,它不仅集合了生存、建造、宠物养成等多种元素,而且可爱的卡通画风格更是老少皆宜。那么,这…...
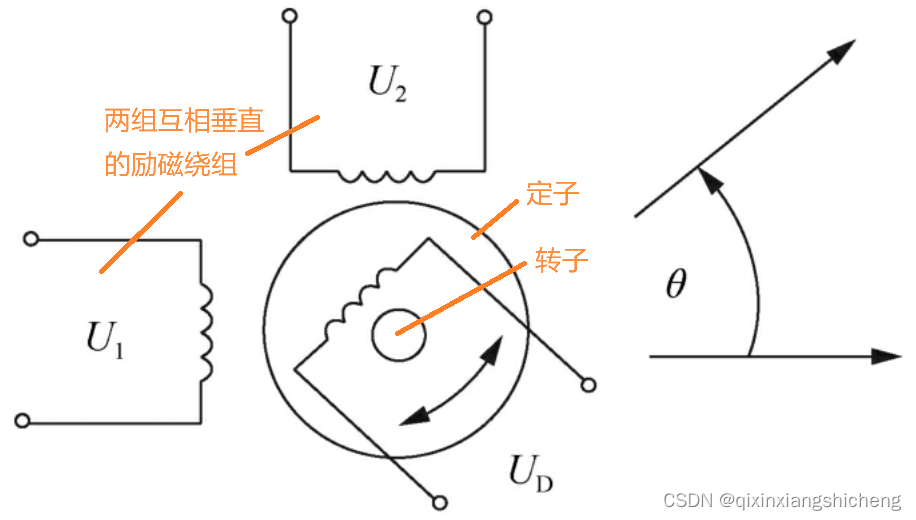
机器人内部传感器阅读笔记及心得-位置传感器-旋转变压器、激光干涉式编码器
旋转变压器 旋转变压器是一种输出电压随转角变化的检测装置,是用来检测角位移的,其基本结构与交流绕线式异步电动机相似,由定子和转子组成。 旋转变压器的原理如图1所示,定子相当于变压器的一次侧,有两组在空间位置上…...

深度学习的学习笔记帖子2
人脸数据集的介绍: https://zhuanlan.zhihu.com/p/362356480 https://blog.csdn.net/bjbz_cxy/article/details/122210641 CASIAWebFace人脸数据集等的github: https://github.com/deepinsight/insightface/blob/master/recognition/datasets/README.md…...

【机器学习学习脉络】
机器学习学习脉络 基础知识 数学基础 线性代数概率论与数理统计微积分最优化理论 编程基础 Python编程语言数据结构与算法软件工程原则 计算机科学基础 操作系统网络通信数据库系统 机器学习概论 定义与发展历程机器学习的主要任务和应用领域基本术语和概念 监督学习 线…...

golang命令行工具gtcli,实现了完美集成与结构化的gin脚手架,gin-restful-api开箱即用
关于gtools golang非常奈斯,gin作为web框架也非常奈斯,但我们在开发过程中,前期搭建会花费大量的时间,且还不尽人意。 为此我集成了gin-restful-api的模板gin-layout,还有脚手架一键生成项目。 集成相关 ginviperz…...

如何用Python+Perplexity API实时监控招聘动态,提前48小时锁定新岗?——资深猎头不愿透露的自动化情报系统
更多请点击: https://codechina.net 第一章:Perplexity招聘信息搜索 Perplexity AI 作为一家快速发展的生成式人工智能公司,其招聘动态常通过官方渠道及技术社区实时更新。掌握高效、精准的招聘信息检索方法,是开发者与研究人员了…...

MAA明日方舟自动化工具终极指南:如何用智能助手彻底解放游戏时间
MAA明日方舟自动化工具终极指南:如何用智能助手彻底解放游戏时间 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: h…...
)
用Python和罗技驱动DLL实现《穿越火线》红名自动检测与开枪(保姆级避坑指南)
Python游戏自动化开发实战:基于颜色识别的智能交互系统设计 在数字娱乐领域,自动化技术正悄然改变着用户的交互体验。本文将深入探讨如何利用Python构建一套安全、高效的屏幕元素识别与自动化交互系统,重点解析颜色识别算法的核心实现与硬件接…...

PHPWord替换word模板内容时,存在表格,且不确定表格行数的处理方式
PHPWord替换word模板内容时,存在表格,且不确定表格行数的处理方式 想得到的目标表格 表格可能存在若干行,需要循环生成,插入到word模板中 word模板 实现过程 1、Composer安装 phpword composer require phpoffice/phpword2、实现代码 //模拟数据 $data = [[...

uni-app项目里遇到‘get’ of undefined?别慌,可能是Vue3条件编译惹的祸
uni-app开发中"get of undefined"错误深度解析:Vue3条件编译的隐秘陷阱 1. 错误现象背后的真相 当你在uni-app项目中看到控制台抛出Cannot read property get of undefined时,这种看似简单的类型错误往往隐藏着更深层的框架适配问题。不同于常…...

全面掌握AMD Ryzen硬件调试:SMUDebugTool完整使用指南
全面掌握AMD Ryzen硬件调试:SMUDebugTool完整使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

GELab-Zero:面向 Android 的开源移动端 GUI Agent,让 AI 像人一样用手机
GELab-Zero:面向 Android 的开源移动端 GUI Agent,让 AI 像人一样用手机 一、项目介绍:什么是 GELab-Zero?二、移动端 GUI Agent 的技术难点三、项目亮点:GELab-Zero 值得学习的地方1. 模型和基础设施一起开源2. 本地运…...

dropin-minimal-css框架质量评估标准:如何选择最适合的CSS框架
dropin-minimal-css框架质量评估标准:如何选择最适合的CSS框架 【免费下载链接】dropin-minimal-css Drop-in switcher for previewing minimal CSS frameworks 项目地址: https://gitcode.com/gh_mirrors/dr/dropin-minimal-css 在当今前端开发的世界中&…...

Armv9 SME2架构下BFloat16计算优化与机器学习加速
1. SME2指令集与BFloat16计算优化解析在Armv9架构的SME2扩展中,BFloat16(简称BF16)支持成为机器学习加速的关键特性。这种16位浮点格式通过截断IEEE 754单精度浮点的尾数位(从23位减至7位),同时保留完整的8…...

用Python实现编译器前端:从Kaleidoscope到LLVM IR的实践指南
1. 项目概述:从“玩具”到“宝藏”的编译器学习之旅如果你对编译原理这门计算机科学的“硬核”课程感到既敬畏又头疼,觉得那些词法分析、语法树、中间代码优化等概念如同天书,那么你很可能已经尝试过一些经典的“龙书”配套项目,比…...