神经网络权重初始化
诸神缄默不语-个人CSDN博文目录
(如果只想看代码,请直接跳到“方法”一节,开头我介绍我的常用方法,后面介绍具体的各种方案)
神经网络通过多层神经元相互连接构成,而这些连接的强度就是通过权重(Weight)来表征的。权重是可训练的参数,意味着它们会在训练过程中根据反向传播算法自动调整,以最小化网络的损失函数。
每个神经元接收到的输入信号会与相应的权重相乘,然后所有这些乘积会被累加在一起,最后可能还会加上一个偏置项(Bias),形成该神经元的净输入。这个净输入随后会被送入激活函数,产生神经元的输出,进而传递给下一层的神经元。在这个过程中,权重决定了信号传递的强度和方向,是调整和控制网络学习过程的关键。
从数学角度看,权重可以被组织成矩阵或张量的形式,以支持高效的矩阵运算和便于处理来自网络上一层的所有输入及其对下一层的影响。训练开始时,权重通常会被初始化为小的随机值,这是为了打破对称性并允许网络学习。随着训练的进行,通过梯度下降算法等优化方法,权重会逐渐调整,以使得网络的预测输出尽可能接近真实标签。
总之,神经网络的权重是连接网络中各层之间的桥梁,它们的值决定了网络的行为和性能,通过训练不断优化这些权重,神经网络能够学习到复杂的数据表示和模式,完成各种复杂的任务。
在深度学习中,神经网络的权重初始化对模型的训练效率和最终性能有着至关重要的影响。适当的初始化方法可以帮助加速收敛,避免陷入局部最小值,同时也可以防止训练过程中的梯度消失或梯度爆炸问题。相反,不当的权重初始化可能导致模型训练效果不佳,甚至无法收敛。
文章目录
- 权重初始化的必要性
- 不认真对待的危害
- 权重初始化方法
- 1. 随机初始化
- 2. Xavier/Glorot 初始化
- 3. He/Kaiming 初始化
- 4. SVD 初始化
- 结论
- 本文撰写过程中使用到的其他参考资料
权重初始化的必要性
- 加速收敛:合适的初始化方法能够使神经网络更快地收敛到较低的误差。
- 避免梯度问题:通过控制权重的初始范围,可以帮助避免训练过程中的梯度消失或爆炸问题。
- 影响泛化能力:初始化不仅影响训练速度和稳定性,也间接影响模型的泛化能力。
不认真对待的危害
- 训练时间延长:不合适的初始化可能导致模型需要更长的时间来收敛。
- 性能下降:极端情况下,不合适的初始化会导致模型无法从训练数据中学习有效的特征,从而严重影响模型性能。
- 训练失败:在某些情况下,错误的初始化方法甚至会导致训练完全失败(例如,梯度消失或爆炸)。
权重初始化方法
我个人的习惯是在构建模型的时候直接对需要手写的权重进行初始化。权重用Xavier初始化,偏置直接初始化为全0向量,代码示例:
from torch.nn.init import xavier_normal_class MPBFNDecoder(nn.Module):def __init__(self):super(MPBFNDecoder,self).__init__()...self.Wf12=nn.Parameter(xavier_normal_(torch.empty(charge_num,ds)))self.Wf13=nn.Parameter(xavier_normal_(torch.empty(penalty_num,ds)))self.Wf23=nn.Parameter(xavier_normal_(torch.empty(penalty_num,ds)))self.b12=nn.Parameter(torch.zeros(charge_num,))self.b13=nn.Parameter(torch.zeros(penalty_num,))self.b23=nn.Parameter(torch.zeros(penalty_num,))
完整代码见https://github.com/PolarisRisingWar/LJP_Collection/blob/master/models/MPBFN/train_and_test.py
PyTorch内置的模型都已经自动写好了初始化函数,不需要手动设置。
以下有些代码示例是指定Linear中的权重进行初始化的。如果你们需要改成对特定参数进行初始化的话也好改,反正你们懂这个意思就行。
1. 随机初始化
Uniform 高斯分布初始化
-
公式:权重 w ∼ N ( 0 , stdev 2 ) w \sim \mathcal{N}(0, \text{stdev}^2) w∼N(0,stdev2)
- 其中, N ( 0 , stdev 2 ) \mathcal{N}(0, \text{stdev}^2) N(0,stdev2) 表示均值为0,标准差为 stdev \text{stdev} stdev 的高斯(正态)分布。
-
概述:最简单的方法是从某个分布(通常是均匀分布或正态分布)中随机选取权重值。
-
代码实例:
import torch
import torch.nn as nn# 均匀分布初始化
def uniform_init(model):if isinstance(model, nn.Linear):nn.init.uniform_(model.weight, -1, 1)if model.bias is not None:nn.init.constant_(model.bias, 0)# 正态分布初始化
def normal_init(model):if isinstance(model, nn.Linear):nn.init.normal_(model.weight, mean=0, std=1)if model.bias is not None:nn.init.constant_(model.bias, 0)
2. Xavier/Glorot 初始化
公式:权重 w ∼ U ( − 6 n in + n out , 6 n in + n out ) w \sim \mathcal{U}(-\sqrt{\frac{6}{n_{\text{in}} + n_{\text{out}}}}, \sqrt{\frac{6}{n_{\text{in}} + n_{\text{out}}}}) w∼U(−nin+nout6,nin+nout6)
- 其中, U ( a , b ) \mathcal{U}(a, b) U(a,b) 表示均匀分布, n in n_{\text{in}} nin 是层输入的单元数, n out n_{\text{out}} nout 是层输出的单元数。
对梯度消失问题有优势。
- 论文:(2010 PMLR) Understanding the difficulty of training deep feedforward neural networks
- 原理:考虑到输入和输出的方差,目的是保持所有层的梯度大小大致相同。
- 代码实例:
def xavier_init(model):if isinstance(model, nn.Linear):nn.init.xavier_uniform_(model.weight)if model.bias is not None:nn.init.constant_(model.bias, 0)
3. He/Kaiming 初始化
- 公式:权重 w ∼ N ( 0 , 2 n in ) w \sim \mathcal{N}(0, \frac{2}{n_{\text{in}}}) w∼N(0,nin2)
- 其中, n in n_{\text{in}} nin 是层输入的单元数,假设权重初始化为均值为0,方差为 2 n in \frac{2}{n_{\text{in}}} nin2 的正态分布。
Kaiming Normal(也称为He Normal)初始化是由何凯明等人在2015年提出的一种权重初始化方法,旨在解决ReLU激活函数在深度神经网络中使用时的梯度消失或爆炸问题。这种方法考虑到了ReLU激活函数特性,特别是其非零区域的分布特点,从而提出通过调整初始化权重的方差来保持信号在前向传播和反向传播过程中的稳定。
- 论文:(2015 ICCV) Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
- 原理:Kaiming Normal 初始化的核心思想是根据网络层的输入单元数量(即fan_in)来调整权重的方差,确保各层激活值的方差保持一致,以此来避免在深层网络中出现梯度消失或爆炸的问题。具体来说,该方法建议将权重初始化为均值为0,方差为 2 / fan_in 2/\text{fan\_in} 2/fan_in的正态分布,其中 fan_in \text{fan\_in} fan_in是权重矩阵中输入单元的数量。
- 代码实例:
def he_init(model):if isinstance(model, nn.Linear):nn.init.kaiming_uniform_(model.weight, mode='fan_in', nonlinearity='relu')if model.bias is not None:nn.init.constant_(model.bias, 0)
4. SVD 初始化
- 公式:无特定公式。SVD 初始化涉及对权重矩阵进行奇异值分解(SVD),然后根据需要重新组合以初始化网络权重。
SVD(奇异值分解)初始化是一种高级权重初始化技术,它通过对权重矩阵应用奇异值分解来初始化神经网络。这种方法特别适用于需要保持输入数据特征或处理特定矩阵结构(如正交性或特定范数)的场合。
对RNN有比较好的效果。参考论文:(2014 ICLR) Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
SVD 初始化的基本思想是将权重矩阵 W W W 分解为三个矩阵的乘积: W = U Σ V T W = U\Sigma V^T W=UΣVT,其中 U U U 和 V V V 是正交矩阵, Σ \Sigma Σ 是对角矩阵,包含 W W W 的奇异值。初始化过程中,可以通过调整 Σ \Sigma Σ 中的奇异值来控制权重矩阵的性质,如其范数或分布特性,从而影响模型的训练动态和最终性能。
代码实例
在PyTorch中实现SVD初始化可能涉及到使用torch.svd对权重矩阵进行奇异值分解,然后根据分解结果来重构权重矩阵。以下是一个简化的示例:
import torch
import torch.nn as nndef svd_init(model):if isinstance(model, nn.Linear):U, S, V = torch.svd(torch.randn(model.weight.shape))# 可以根据需要调整S中的奇异值model.weight.data = torch.mm(U, torch.mm(torch.diag(S), V.t()))if model.bias is not None:nn.init.constant_(model.bias, 0)
SVD初始化提供了一种灵活的方法来控制神经网络权重的特性,尤其是在需要维护输入特征结构或优化训练稳定性的高级应用中。通过精确控制权重矩阵的奇异值,研究者和工程师可以优化网络的初始化状态,从而提高模型训练的效率和效果。然而,由于其实现相对复杂,通常仅在特定需求下采用此方法。
结论
权重初始化在神经网络训练中起着决定性的作用。选择合适的初始化方法可以显著提高训
练效率和模型性能。在实践中,应根据模型的具体结构和使用的激活函数来选择最适合的初始化方法。以上提到的方法仅是众多初始化技术中的几种,研究者和开发者可以根据需要选择或创新更适合自己模型需求的初始化策略。
本文撰写过程中使用到的其他参考资料
- 数据竞赛中如何优化深度学习模型
相关文章:

神经网络权重初始化
诸神缄默不语-个人CSDN博文目录 (如果只想看代码,请直接跳到“方法”一节,开头我介绍我的常用方法,后面介绍具体的各种方案) 神经网络通过多层神经元相互连接构成,而这些连接的强度就是通过权重ÿ…...

代码随想录训练营第三十九天|62.不同路径63. 不同路径 II
62.不同路径 1确定dp数组(dp table)以及下标的含义 从(0,0)出发到(i,j)有 dp[i][j]种路径 2确定递推公式 dp[i][j]dp[i-1][j]dp[i][j-1] 3dp数组如何初始化 for(int i0;i<m…...
学习大数据所需的java基础(5)
文章目录 集合框架Collection接口迭代器迭代器基本使用迭代器底层原理并发修改异常 数据结构栈队列数组链表 List接口底层源码分析 LinkList集合LinkedList底层成员解释说明LinkedList中get方法的源码分析LinkedList中add方法的源码分析 增强for增强for的介绍以及基本使用发2.使…...
Python 光速入门课程
首先说一下,为啥小编在即PHP和Golang之后,为啥又要整Python,那是因为小编最近又拿起了 " 阿里天池 " 的东西,所以小编又不得不捡起来大概五年前学习的Python,本篇文章主要讲的是最基础版本,所以比…...

解决vite打包出现 “default“ is not exported by “node_modules/...问题
项目场景: vue3tsvite项目打包 问题描述 // codemirror 编辑器的相关资源 import Codemirror from codemirror;error during build: RollupError: "default" is not exported by "node_modules/vue/dist/vue.runtime.esm-bundler.js", impor…...

c语言strtok的使用
strtok函数的作用为以指定字符分割字符串,含有两个参数,第一个函数为待分割的字符串或者空指针NULL,第二个参数为分割字符集。 对一个字符串首次使用strtok时第一个参数应该是待分割字符串,strtok以指定字符完成第一次分割后&…...
hash,以及数据结构——map容器
1.hash是什么? 定义:hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出, 该输出就是散列值。这种转换是一种压缩映射&…...

AIoT网关 人工智能物联网网关
AIoT(人工智能物联网)作为新一代技术的代表,正以前所未有的速度改变着我们的生活方式。在这个智能时代,AIoT网关的重要性日益凸显。它不仅是连接智能设备和应用的关键,同时也是实现智能化家居、智慧城市和工业自动化的必备技术。 一…...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的鸟类识别系统(Python+PySide6界面+训练代码)
摘要:本文详细阐述了一个利用深度学习进行鸟类识别的系统,该系统集成了最新的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等先前版本进行了性能比较。该系统能够在图像、视频、实时视频流和批量文件中精确地识别和分类鸟类。文中不仅深入讲解了YO…...

核密度分析
一.算法介绍 核密度估计(Kernel Density Estimation)是一种用于估计数据分布的非参数统计方法。它可以用于多种目的和应用,包括: 数据可视化:核密度估计可以用来绘制平滑的密度曲线或热力图,从而直观地表…...

先进语言模型带来的变革与潜力
用户可以通过询问或交互方式与GPT-4这样的先进语言模型互动,开启通往知识宝库的大门,即时访问人类历史积累的知识、经验与智慧。像GPT-4这样的先进语言模型,能够将人类历史上积累的海量知识和经验整合并加以利用。通过深度学习和大规模数据训…...
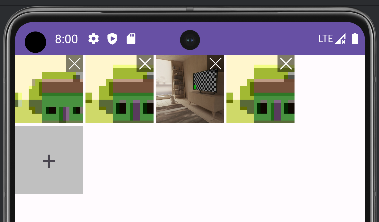
重铸安卓荣光——上传图片组件
痛点: 公司打算做安卓软件,最近在研究安卓,打算先绘制样式 研究发现安卓并不像前端有那么多组件库,甚至有些基础的组件都需要自己实现,记录一下自己实现的组件 成品展示 一个上传图片的组件 可以选择拍照或者从相册中…...
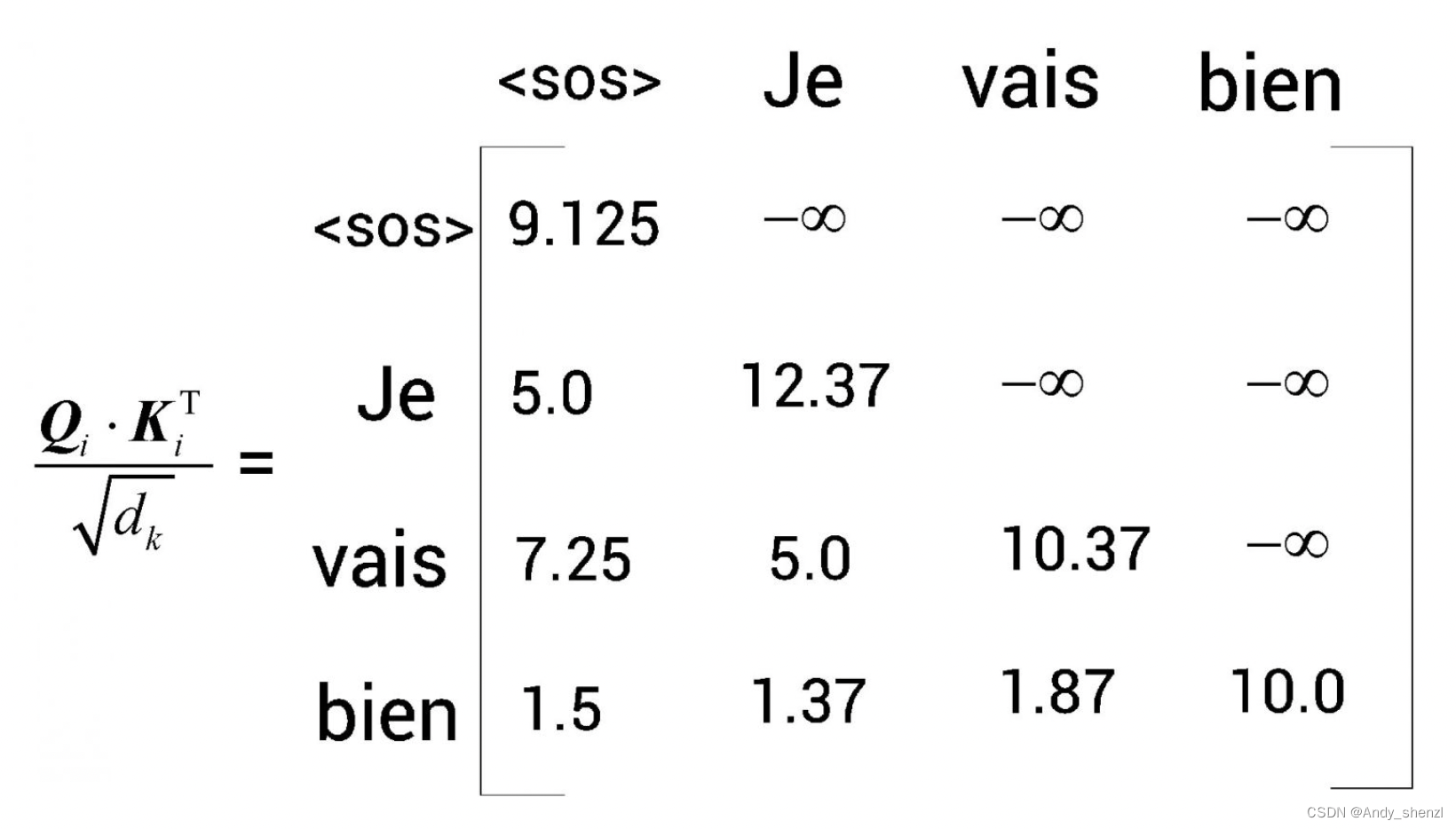
Bert基础(四)--解码器(上)
1 理解解码器 假设我们想把英语句子I am good(原句)翻译成法语句子Je vais bien(目标句)。首先,将原句I am good送入编码器,使编码器学习原句,并计算特征值。在前文中,我们学习了编…...

Visual Studio快捷键记录
日常使用Visual Studio进行开发,记录一下常用的快捷键: 复制:CtrlC剪切:CtrlX粘贴:CtrlV删除:CtrlL撤销:CtrlZ反撤销:CtrlY查找:CtrlF/CtrlI替换:CtrlH框式选…...

分享84个Html个人模板,总有一款适合您
分享84个Html个人模板,总有一款适合您 84个Html个人模板下载链接:https://pan.baidu.com/s/1GXUZlKPzmHvxtO0sm3gHLg?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集…...

vue使用.sync和update实现父组件与子组件数据绑定的案例
在 Vue 中,.sync 是一个用于实现双向数据绑定的特殊修饰符。它允许父组件通过一种简洁的方式向子组件传递一个 prop,并在子组件中修改这个 prop 的值,然后将修改后的值反馈回父组件,实现双向数据绑定。 使用 .sync 修饰符的基本语…...

C语言系列15——C语言的安全性与防御性编程
目录 写在开头1 缓冲区溢出:如何防范与处理1.1 缓冲区溢出的原因1.2 预防与处理策略 2. 安全的字符串处理函数与使用技巧2.1 strncpy函数2.2 snprintf函数2.3 strlcpy函数2.4 使用技巧 3 防御性编程的基本原则与实际方法3.1 基本原则3.2 实际方法 写在最后 写在开头…...

objectMapper、ObjectNode、JsonNode调用接口时进行参数组装
objectMapper、ObjectNode、JsonNode用于调用接口时进行参数组装 public String sendText( List< String > listUser, String content ) throws JsonProcessingException{if ( listUser.size() < 0 ){return "用户ID为空!";}if ( content.lengt…...

2024开年,手机厂商革了自己的命
文|刘俊宏 编|王一粟 2024开年,AI终端的号角已经由手机行业吹响。 OPPO春节期间就没闲着,首席产品官刘作虎在大年三十就迫不及待地宣布,OPPO正式进入AI手机时代。随后在开年后就紧急召开了AI战略发布会,…...

【安全】大模型安全综述
大模型相关非安全综述 LLM演化和分类法 A survey on evaluation of large language models,” arXiv preprint arXiv:2307.03109, 2023.“A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.“A survey on llm-gernerated text detection: Necess…...

2026生鲜零售收银软件推荐:四大主流方案深度对比
开一家生鲜店,最让人头疼的往往不是进货渠道或选址,而是每天高峰期那台“卡住”的收银机。想象一下,周末傍晚顾客排成长龙,称重员手忙脚乱地输入代码,屏幕转圈加载,后面的顾客开始不耐烦地催促,…...

对比直接使用厂商API与通过Taotoken聚合调用的费用观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API与通过Taotoken聚合调用的费用观感 1. 引言:成本感知的演变 在构建基于大模型的应用时࿰…...

NewJob浏览器插件终极指南:3步解决求职信息过时难题
NewJob浏览器插件终极指南:3步解决求职信息过时难题 【免费下载链接】NewJob 一眼看出该职位最后修改时间,绿色为2周之内,暗橙色为1.5个月之内,红色为1.5个月以上 项目地址: https://gitcode.com/GitHub_Trending/ne/NewJob …...

27考研er必备的那些学习工具!
对2027考研人来说,备考不是简单地“埋头刷题”,而是一场关于信息筛选、资源整合、时间管理和学习效率的长期战役。面对公共课、专业课、院校信息、经验帖、课程资源等海量内容,选对工具往往能让复习少走弯路。 以下这些平台和网站,…...

解锁游戏时间魔法:OpenSpeedy如何重塑你的单机游戏体验
解锁游戏时间魔法:OpenSpeedy如何重塑你的单机游戏体验 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾在游戏中经历过这样的时刻:冗长的剧情…...

STK Connectors接口函数全解析:如何用MATLAB脚本自动化你的航天仿真流程
STK Connectors接口函数全解析:如何用MATLAB脚本自动化你的航天仿真流程 航天仿真领域的工作者常常面临一个矛盾:STK提供了强大的轨道计算和场景可视化能力,但手动操作界面进行复杂任务时效率低下;MATLAB擅长处理复杂逻辑和批量计…...

CANopen设备配置不求人:手把手教你用Python-canopen库读写EDS/DCF文件
CANopen设备配置实战指南:用Python-canopen库深度操作EDS/DCF文件 在工业自动化领域,CANopen协议因其开放性和灵活性成为设备互联的重要标准。而对象字典(Object Dictionary)作为CANopen设备的核心配置数据库,直接决定了设备的通信行为和功能…...

别再只改IMEI了!深入理解高通基带QCN:从参数结构到软件检测的完整对抗思路
高通基带QCN参数体系解析与多维设备指纹对抗策略 在移动设备安全领域,设备标识参数的修改与检测始终是一场动态博弈。随着安卓系统安全机制的不断升级,简单的IMEI修改早已无法应对现代应用的多维指纹检测体系。理解高通基带QCN参数的组织结构及其在系统中…...

VS Code CircuitPython扩展实战:嵌入式开发环境搭建与高效调试指南
1. 项目概述:为什么选择 VS Code CircuitPython 扩展?如果你正在玩像 Adafruit Feather、Raspberry Pi Pico 或者 ESP32-S3 这类支持 CircuitPython 的开发板,你可能已经习惯了在CIRCUITPY这个神奇的U盘里直接编辑code.py文件。这种方式简单…...

NotebookLM相似文档推荐不准,深度解析向量维度坍缩、跨域语义漂移与上下文窗口截断三大根源问题
更多请点击: https://intelliparadigm.com 第一章:NotebookLM相似文档推荐不准的系统性现象观察 在实际使用 NotebookLM 过程中,用户频繁反馈其“相似文档推荐”功能存在显著偏差:高语义相关但低表面重合度的文档常被遗漏&#x…...