Flink Catalog 解读与同步 Hudi 表元数据的最佳实践
 | 博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 |
文章目录
- 1. Flink Catalog 的整体设计和各类具体实现
- 2. Flink 读写 Hudi 表并同步至 Hive Metastore 的方法
- 3. 最佳解决方案
- 4. 示例代码
在当前的大数据格局中,Spark / Hive / Flink 是最为主流的 ETL 或 Streaming 引擎,元数据方面,Hive Metastore 可以视为事实上的 Data Catalog 标准,而在数据湖存储格式上,又有 Hudi、Iceberg 这类新晋的框架,在这种复杂的格局下,用户希望能它们之间能相互打通,以便能根据应用场景灵活地选择技术栈,同时又不会出现技术上的“隔离”,一个非常典型的例子是:当我们选择了 Hudi 作为数据湖的统一存储格式后,我们希望不管是 Flink 还是 Spark (也包括 Hive)都能顺利读写 Hudi 表,这也暗含着“元数据最好统一存储在 Hive Metastore 中”这样的诉求,这非常普遍且典型的一种用户诉求,而我们这篇文章其实就是针对这个诉求给出解决方案。
1. Flink Catalog 的整体设计和各类具体实现
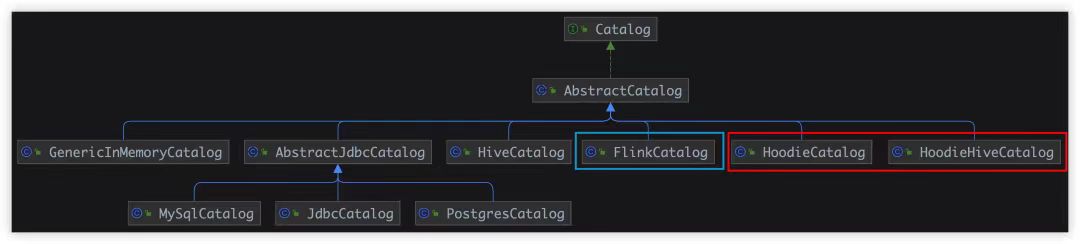
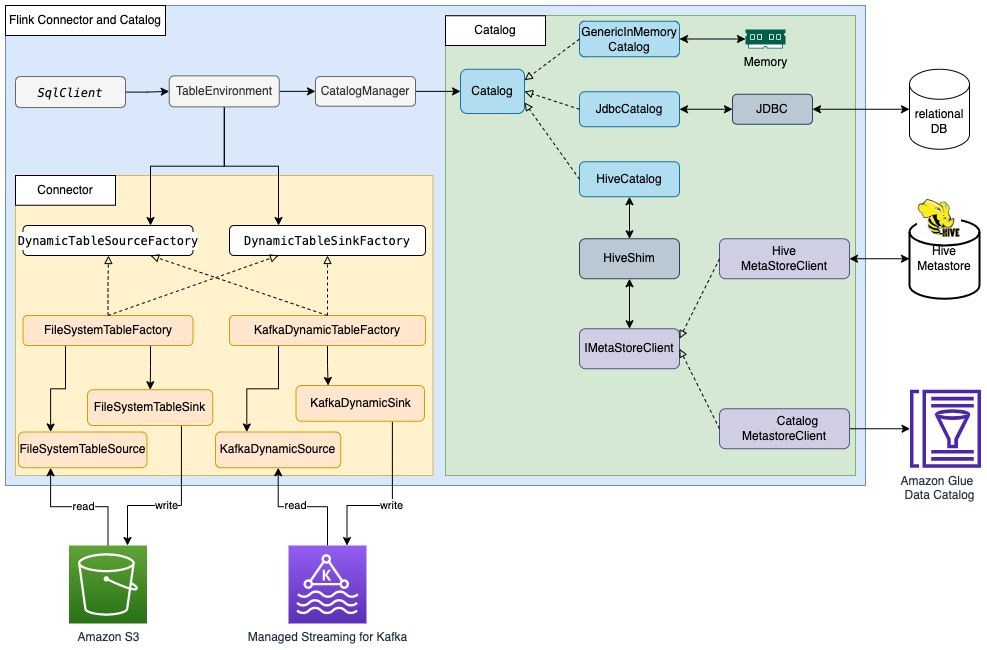
首先,我们要清楚地明白一点:Flink 是有自己的、完全独立的 Catalog 定义(接口)的,就像 Hive 设计并使用了自己的 Hive MetaStore 一样。Flink 在自已统一的 Catalog 定义(接口)下,提供了多种不同的实现,其实本质的差别主要是存储介质上的差异:
- 🗹 默认 Catalog(GenericInMemoryCatalog)
- 基于内存,Session 结束时,metadata 也会随之丢失,下次再使用需要重新建库、建表;
- 🗹 将元数据持久化到数据库中 (JdbcCatalog)
- 这就有点像 Hive Metastore 的实现方式了,但是要注意,只是性质上类似,metadata 的 schema 肯定是不一样的
- 🗹 将元数据持久化到 Hive Metastore 中(HiveCatalog)
- 这种方式要注意理解,它是把 Hive Metastore 当成了底层存储,通过调用 Hive Metastore 的 API 来读写 Flink 的 metadata;
- 同时,使用这种方式还能读写 Hive 中已有的 Hive 表,某种角度上看,有点类似在 Flink Catalog 和 Hive Metastore 之间做了“适配”;
- 鉴于 Hive Metestore 在大数据生态中的核心位置,将 Flink 的元数据统一到 Hive 的 Metastore 上也是一种必然地选择,不过,Flink Catalog 数据结构毕竟与 Hive 的 Catalog 结构有所不同,所以将大量 Flink 的 metadata 写入 Hive 会导致所谓的 “Hive 元数据污染” 问题(参考:《Flink 实时计算平台在知乎的演进》)
- 🗹 用户自定义 Catalog
- 既然 Flink 的 Catalog 基于接口设计的,那么用户自然可以开发自己的 Catalog 实现;
- 对于那些拥有内置元数据服务的数据湖框架,例如 Hudi 和 Iceberg,这是绝佳的元数据切入方式,通过这种形式,它们会开发自己的 Flink Catalog 实现,目的就在于为了和 Flink Catalog 机制无缝打通,让 Flink 能很好的读写这些格式内置的元数据,实际上,它们也确实这样做了
下图从本质上(类的继承关系)揭示了 Flink Catalog 的设计框架和各个实现之间的关系:
同样的,下图从更大的一个上下文中展示了 Flink 表种 Catalog 具体实现的工作场景:
2. Flink 读写 Hudi 表并同步至 Hive Metastore 的方法
存放 Hudi 的元数据有多种途径,本着不再发明轮子的态度,这两篇文章《Flink SQL操作Hudi并同步Hive使用总结》和 《Flink SQL通过Hudi HMS Catalog读写Hudi并同步Hive表》已经总结的非常全面和细致了,总结一下一共有以下几种途径:
① 在 Flink 的默认 Catalog 中创建 Hudi 表,不同步表格元数据到 Hive Metastore (不配置 hudi 表的 hive_sync.* 属性)
这一方案 Spark 和 Hive 都读取不到这张 Hudi 表,且 Flink 自己在 Session 关闭后也需要重新建表,所以,这一方案并没有实用价值。
② 在 Flink 的 Hive Catalog 中创建 Hudi 表,不同步表格元数据到 Hive Metastore (不配置 hudi 表的 hive_sync.* 属性)
这一方案是在 Flink SQL 中连通 Hive Metastore(即使用 HiveCatalog),直接在 Hive Metastore 中创建 Hudi 表,这样,原则上,Spark / Hive 都能发现这张 Hudi 表,并对其进行读写。但实际上,使用在这种模式下,Spark / Hive 是不能正常读写 Hudi 表的,因为该方法创建的 Hudi 表写入了大量的 Flink 特有的 metadata,同时又缺少了 Hive / Spark 必要的 Hudi 表的属性,所以 Spark / Hive 不能读写这种方式创建的 Hudi 表。简单地说,在这种方式下,Flink 只是将 Hive Metastore 当做一种底层的元数据存储服务,所以写入的元数据都是 Flink Catalog 风格的,并不会考虑任何与 Hive / Spark 元数据兼容的问题,所以 Spark / Hive 读不出这种方式创建的 Hudi 表就不难理解了。
③ 在 Flink 的默认 Catalog 中创建 Hudi 表,并同步表格元数据到 Hive Metastore (配置 hudi 表的 hive_sync.* 属性)
这一方案在 Flink 中创建的 Hudi 表的元数据能自动同步到 Hive Metastore,这样,Spark / Hive 就可以读写这张表了,但是,唯一不足的地方是:对于 Flink 这一端,具体说就是 Flink SQL Client,当 Session 关闭再重新打开后,Flink 的 Catalog 里原来的 Hudi 表就消失了,虽然可以通过注册 Hive Catalog 读到上次创建的 Hudi 表,但是,先后两次操作,SQL 会不一样,所以还是有一些瑕疵。说到底,这种方式是在混用 Flink Catalog 和 Hive Metastore。
④ 在 Flink 的 Hive Catalog 中创建 Hudi 表,并同步表格元数据到 Hive Metastore (配置 hudi 表的 hive_sync.* 属性)
这一方案和方案 2 很接近,通过主动同步 Hudi 元数据到 Hive Metastore 解决了 Hive / Spark 无法读写 Hudi 表的问题。不过,这一方案将势必在 Hive Metastore 中创建出至少两张以上的表(对于 MOR 表是 3 张),一张是 Flink 原生的 Hudi 表,另一张是通过 Hive Sync 同步出来的表,虽然两张表的数据是一份,但是元数据上确实是两张不同的表,且使用 Flink 时,只能读写 Flink 注册的表,使用 Hive / Spark 时,只能使用 Hive Sync 出来的表,虽然可以 work,但显然还是一种很别扭的方案
⑤ 使用 Hudi HMS Catalog ( HoodieHiveCatalog )
上述四种方案都有一定的局限性,为此,Flink / Hudi 社区专门针对 Hudi 的 metadata 开发了一个单独的 Flink Catalog 实现:HoodieHiveCatalog,这一方案从最底层上解决了元数据适配和共享的问题。接下来我们会详细介绍这种实现。
3. 最佳解决方案
在“Flink 读写 Hudi 表并同步至 Hive Metastore” 这件事情上,作为需求,最好的解决方案应该:在 Flink 中创建的 Hudi 表能自动被 Hive / Spark 发现和读写,鉴于 Hive Metastore 在大数据生态中的地位,元数据应该存储于 Hive Metastore 中,但不需要显式配置 Hive Sync,也不应存储两份以上的元数据,Flink / Hive / Spark 有统一的元数据视图,均可共同读写同一张 Hudi 表,而这就是 HoodieHiveCatalog 所要完成的任务。
从设计模式的角度看,本质上,HoodieHiveCatalog 是一个 “适配器”,它将 Flink Catalog 的元数据格式和 Hudi 的元数据格式以及 Hive Metastore 的格式做了完备的适配,这才得以实现三者的无缝集成!使得 Hudi 表元数据在 Flink / Hive / Spark 上做到的真正意义上的统一。下图非常细致地描绘了 HoodieHiveCatalog 的工作方式(Glue Data Catalog 部分不影响解读,可忽略):
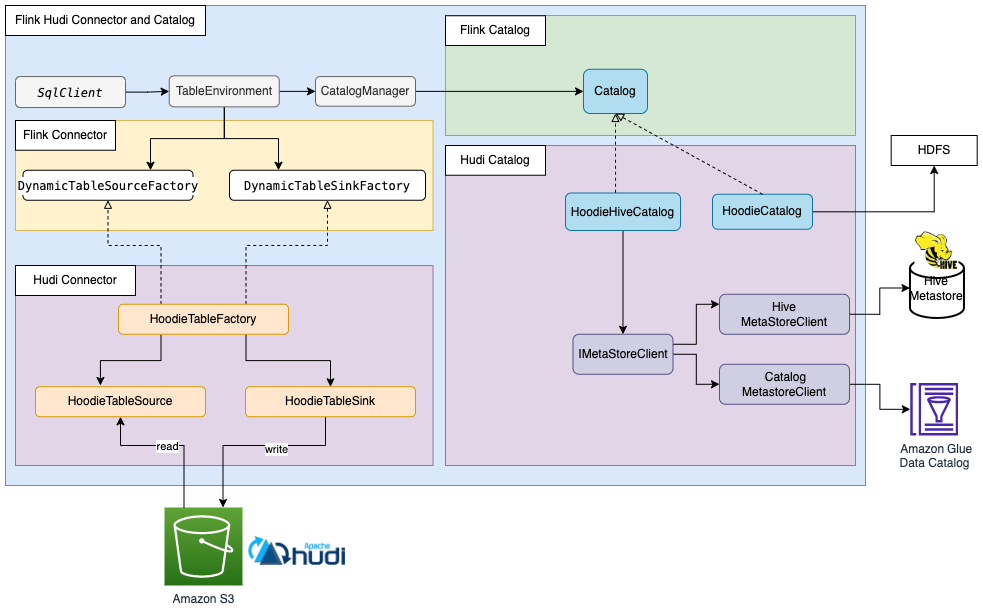
方案 5 自始至终只使用 Hive Metastore 一种存储介质,并面向 Hudi Metadata 的存储在 Flink Catalog 和 Hive Catalog 进行了适配,只存储一份元数据,而其他方案都是同时使用两套 Catalog,并通过 Hive Sync 尽量弥合两套 Catalog 之间的差异,总会遇到这样那样的不一致问题。
4. 示例代码
关于使用 Hudi HMS Catalog ( HoodieHiveCatalog ) 统一 Hudi 表在 Flink / Spark / Hive 上的元数据示例,我们已经在《CDC 整合方案:MySQL > Flink CDC + Schema Registry + Avro > Kafka > Hudi》 一文中给出了细致的演示和程序代码,请移步此文了解详情。
相关文章:
Flink Catalog 解读与同步 Hudi 表元数据的最佳实践
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…...
git 使用总结
文章目录 git merge 和 git rebasegit mergegit rebase总结 git merge 和 git rebase git merge git merge 最终效果说明: 假设有一个仓库情况如下,现需要进行 merge: merge 操作流程: merge 的回退操作: git reba…...

【Elasticsearch专栏 01】深入探索:Elasticsearch的正向索引和倒排索引是什么
文章目录 什么是Elasticsearch的正向索引和倒排索引?1.倒排索引(Inverted Index)2.正向索引(Forward Index)3.小结 什么是Elasticsearch的正向索引和倒排索引? 首先,要明确的是,Ela…...

Linux、Ubuntu、CenterOS、RedHat、Debian、AIpine关系和区别?
目录 1. 区别和联系 2. 安装命令 3. 其他发行版本 4. 拓展知识 Linux 内核和操作系统发行版的关系-CSDN博客 5.参考 1. 区别和联系 Ubuntu, Debian, RedHat, CentOS都是不同的Linux发行版。 Ubuntu 是基于Debian的一个开源GNU/Linux操作系统。它的目标是为一般用户提供…...
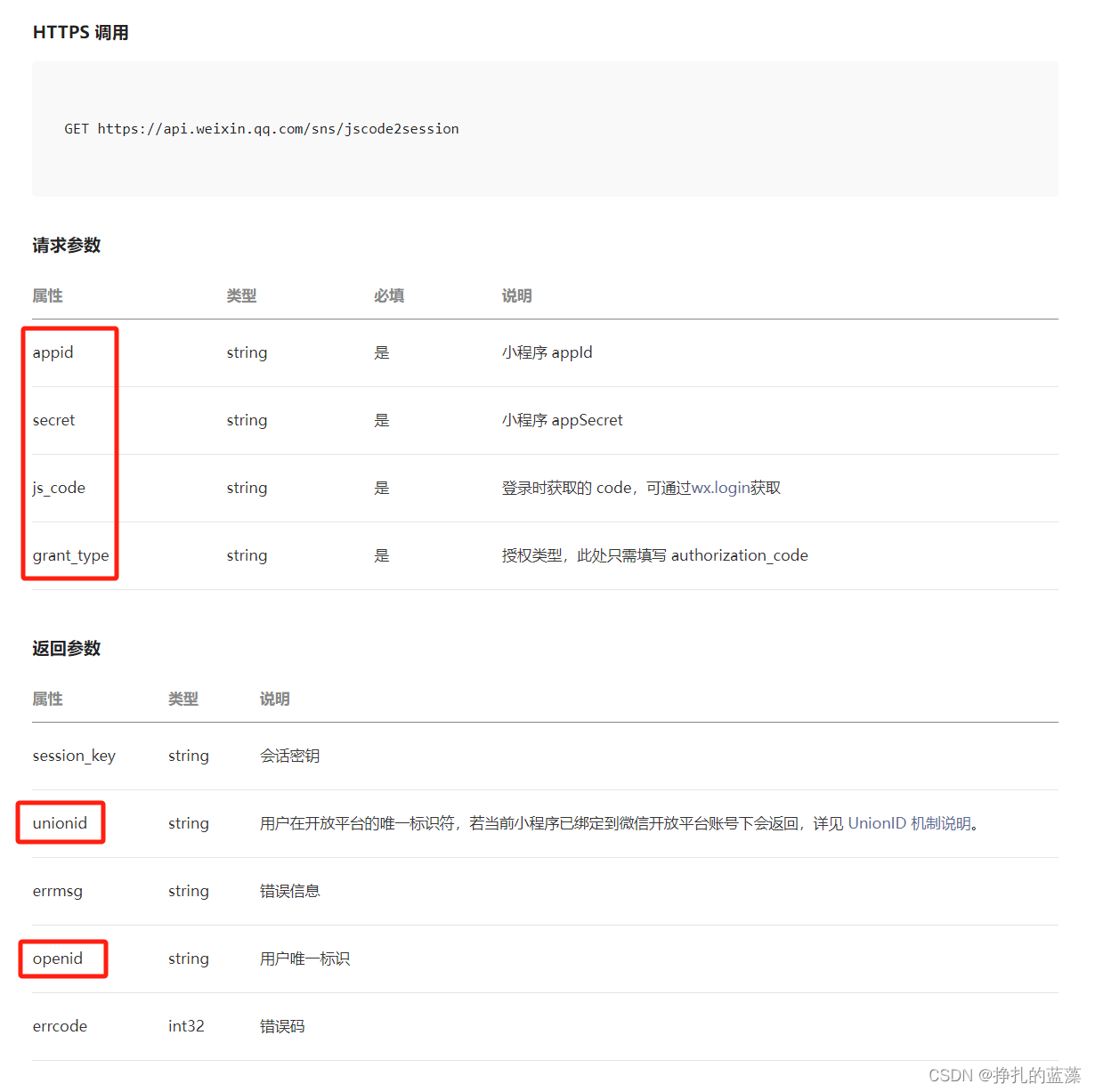
微信小程序开发:通过wx.login()获取用户唯一标识openid和unionid
下面代码展示了 openid 的获取过程。 想获取 unionid 需要满足条件:小程序已绑定到微信开放平台账号下,不然只会返回 openid。 【相关文档】 微信小程序开发:appid 和 secret 的获取方法 wx.login({success (res) {if (res.code) {// 发起网…...
设计模式之模板方法
模式定义 定义一个操作中的算法的骨架 (稳定),而将一些步骤延迟(变化)到子类中。Template Method使得子类可以不改变(复用)一个算法的结构即可重定义(override 重写)该算法的某些特定步骤。 …...
Tubi 故事|中国团队本地管理队伍的形成
当一支团队在公司核心业务中发挥着越来越重要的作用,他们将会获得更多资源以支持团队的发展并在核心业务中持续贡献。相应地,公司也需要投入更多的精力去管理这支规模日渐壮大的团队,尤其当这支远程团队与公司总部在地理和文化上有明显差异时…...
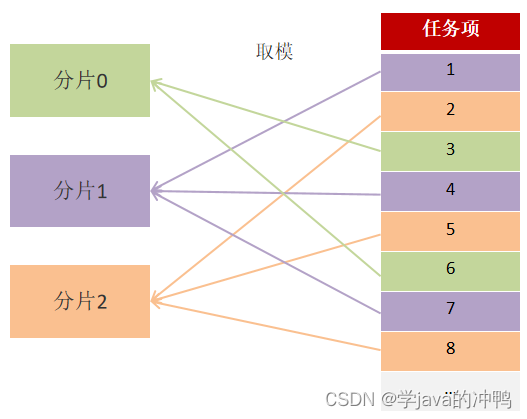
微服务篇之任务调度
一、xxl-job的作用 1. 解决集群任务的重复执行问题。 2. cron表达式定义灵活。 3. 定时任务失败了,重试和统计。 4. 任务量大,分片执行。 二、xxl-job路由策略 1. FIRST(第一个):固定选择第一个机器。 2. LAST&#x…...
提取游戏音频文件.bnk
提取游戏音频文件.bnk 什么是.bnk准备Wwise-Unpacker工具使用Wwise-Unpacker工具总结 什么是.bnk .bnk其实是一种对音频的加密方式,一个.bnk文件中通常包含了多个语音文件,一般可以使用Wwise-Unpacker来解码.bnk格式文件 准备Wwise-Unpacker工具 Wwis…...

React 模态框的设计(三)拖动组件的完善
我在上次的Draggable组件的设计中给了一个简化的方法,今天我来完善一下这个组件,可用于任何可移动组件的包裹。完善后的效果如下所示: 这个优化中,增加了一个注目的效果,还增加了触发可拖动区域的指定功能,…...
wondows10用Electron打包threejs的项目记录
背景 电脑是用的mac,安装了parallels desktop ,想用electron 想同时打包出 苹果版本和windows版本。因为是在虚拟机里安装,它常被我重装,所以记录一下打包的整个过程。另外就是node生态太活跃,几个依赖没记录具体版本࿰…...

git的master、develop、feature分支分别是做什么用的?有什么区别和联系?
在Git版本控制系统中,master、develop和feature分支都是常用的分支类型,它们有不同的用途和特点。 master分支:master分支是Git默认的主分支,它包含了项目的稳定版本。通常,master分支用于发布正式版本,即经…...

前端基础面试题
摘要:最近,看了下慕课2周刷完n道面试题,记录下... 1.请说明Ajax、Fetch、Axios三者的区别 三者都用于网络请求,但维度不同: Ajax(Asynchronous Javascript ang XML),是一种在不重新…...
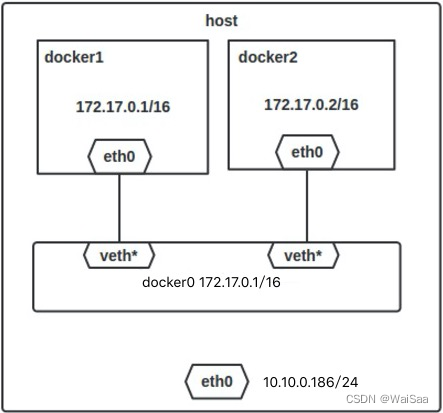
docker自定义网络实现容器之间的通信
Background docker原理 docker是一个Client-Server结构的系统,Docker的守护进程运行在主机上。通过Socket从客户端访问。docker核心三大组件:image–镜像、container-容器、 repository-仓库。docker使用的cpu、内存以及系统内核等资源都是直接使用宿主…...

NLP_构建GPT模型并完成文本生成任务
文章目录 搭建GPT模型(解码器)构建文本生成任务的数据集训练过程中的自回归文本生成中的自回归(贪婪搜索)完整代码小结 搭建GPT模型(解码器) GPT 只使用了 Transformer的解码器部分,其关键组件…...

使用puppeteer完成监听浏览器下载文件并保存到自己本地或服务器上完成上传功能
需求场景 获取网站点击的下载pdf,并把pdf重命名再上传到COS云上面 技术使用 “puppeteer”: “^19.7.2”, “egg”: “^3.15.0”, // 服务期用egg搭的 文件服务使用COS腾讯云 核心思路 获取浏览器下载事件,并把文件保存到本地 const session awai…...

软件压力测试:测试方法与步骤详解
随着软件应用的不断发展,用户对系统性能的要求也逐渐提高。在不同的负载条件下,系统必须能够保持稳定、高效的运行。软件压力测试是一种验证系统在各种负载情况下性能表现的关键手段。本文将详细探讨软件压力测试的方法和步骤。 1. 明确测试目标 在进行压…...

Oerlikon欧瑞康LPCVD system操作使用说明
Oerlikon欧瑞康LPCVD system操作使用说明...

pyspark统计指标计算
下面介绍如何使用pyspark处理计算超大数据的统计指标,主要为:最大值、最小值、均值、方差、标准差、中位数、众数、非重复值等。 # 加载稽核数据 rd_sql f"select * from database.table" spark_data spark.sql(rd_sql)# 计算众数 由于spar…...

2.22号qt
1.使用信号和槽实现多个界面跳转 1.1准备两个界面 1.2第一个界面准备signal 1.3第二个界面准备slot 1.4将第一个界面的信号和槽进行连接 2.qss登录界面升级优化 2.1概念 Qss是Qt程序界面中用来设置控件的背景图片、大小、字体颜色、字体类型、按钮状态变化等属性ÿ…...

CVBS转BT656/BT601,能成熟、应用广泛的低功耗视频解码器
GM7150是一款低功耗、9位NTSC/PAL视频解码器,由成都振芯科技股份有限公司生产。该芯片采用CMOS工艺,通过IC总线与PC或DSP相连构成应用系统。它内部包含1个模拟处理通道,能实现CVBS、S-Video视频信号源选择、A/D转换、自动钳位、自动增益控制(…...

高效AI专著生成:20万字专著一键搞定,AI写专著工具实测推荐!
学术专著写作挑战与AI工具助力 对于初次尝试编写学术专著的研究者来说,写作过程就像是在“摸索着走过一条未知的小路”,处处都有挑战等待着他们。在选题上常常感到迷惘,难以在“有意义”与“可操作性”之间找到合适的平衡:有的研…...

别再被格式卡论文了!Paperxie 格式排版功能,一键搞定从本科到博士的规范难题
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 论文季里,有多少人的崩溃,不是因为写不出内容,而是死在了格式上&#x…...

从零构建自定义操作系统镜像:Packer与Ansible自动化实践指南
1. 项目概述:从“能用”到“好用”的系统构建哲学“操作系统自定义和部署构建”,这听起来像是一个庞大而复杂的工程,似乎只属于大型企业或专业发行版维护者的领域。但事实上,任何一个对现有操作系统感到“别扭”的开发者、运维工程…...

Windows Cleaner:免费开源的系统优化神器,彻底告别C盘爆红烦恼
Windows Cleaner:免费开源的系统优化神器,彻底告别C盘爆红烦恼 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常被Windows系统C盘…...

pycharm接入AI大模型测试脚本费用说明
费用说明 阿里云通义千问提供: 新用户免费额度:注册即送一定额度的免费 tokens 按量付费:用多少付多少,无最低消费 价格透明:详见 官方定价 示例成本(以 qwen-plus 为例) 解析-个 100页 PDF≈ 50,000 tokens ≈0.4 生成 100 个问答对≈20,000 tokens ≈0.16 下一步 …...

FPGA静态侧信道攻击防御与传感器绕过技术解析
1. FPGA安全防御机制与静态侧信道攻击概述在现代数字安全领域,现场可编程门阵列(FPGA)因其可重构性和高性能特性,已成为加密加速、信号处理等关键应用的核心组件。然而,FPGA面临的物理安全威胁与日俱增,特别是针对硬件的侧信道攻击…...

复古CRT电视改造:用RF调制器连接树莓派与现代电脑
1. 项目概述:当太空时代美学遇见现代计算几年前,我在一个复古科技展上第一次见到JVC Videosphere,那个圆润的球面屏幕和未来感十足的造型瞬间击中了我。它诞生于上世纪70年代,是那个太空竞赛黄金时期工业设计的缩影。但和大多数老…...

换背景照片怎么制作?一篇全网最全的AI抠图工具对比指南
最近经常有朋友问我:"怎样才能快速换背景照片啊?"确实,随着自媒体时代的到来,无论是做电商展示产品、准备证件照,还是制作社交媒体内容,都离不开换背景这个需求。今天我就把这两年用过的所有抠图…...

Warcraft Helper完整指南:让经典魔兽争霸3在现代Windows系统焕发新生
Warcraft Helper完整指南:让经典魔兽争霸3在现代Windows系统焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在Wi…...