黑马头条-day10
文章目录
- app端文章搜索
- 1、文章搜索
- 1.1 ElasticSearch环境搭建
- 1.2 索引库创建
- ①需求分析
- ②ES导入数据场景分析
- ③创建索引和映射
- 1.3 索引数据同步
- ①app文章历史数据导入ES
- ②文章实时数据导入ES
- 1.4 文章搜索多条件复合查询
- ①关键词搜索
- ②搜索接口定义
- 2、搜索历史记录
- 2.1 需求说明
- 2.2 数据存储说明
- 2.1 异步保存搜索历史
- ①实现思路
- 2.2 查看搜索历史列表
- ①接口定义
- 2.3 删除搜索历史
- 3、联想词查询
- 需求分析
- 3.1 联想词的来源
- 3.2 联想词功能实现
- 接口定义
- 正则表达式说明
app端文章搜索
1、文章搜索
1.1 ElasticSearch环境搭建
1、启动ElasticSearch
docker start elasticsearch
2、启动Kibana
docker start kibana
3、kibana测试分词效果
1.2 索引库创建
①需求分析

- 用户输入关键词 比如
java只要文章titile、content包含此关键词就可以搜索出来,搜索黑马程序员能把黑马、程序员相关都搜索出来 - 搜索的文章结果里
词条要高亮显示 - 用户点击搜索结果任意一条可查看文章详情
②ES导入数据场景分析
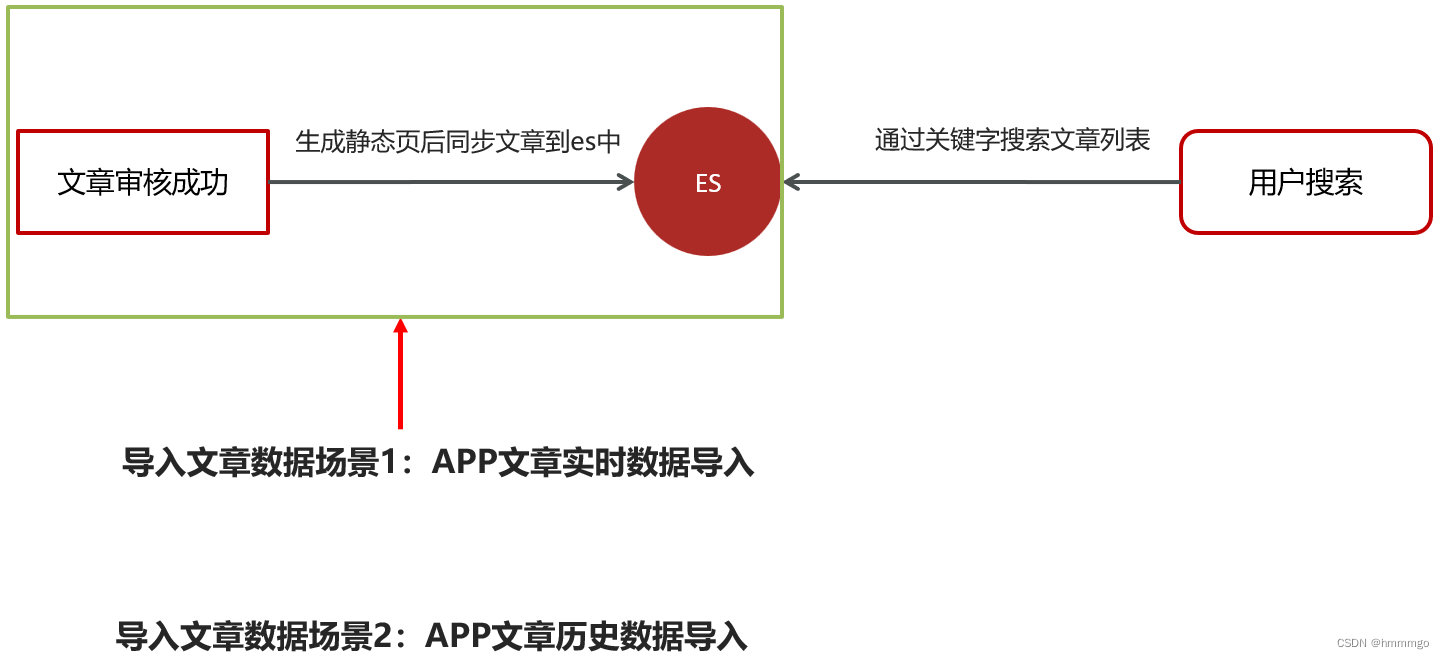
③创建索引和映射
搜索结果页面展示什么内容?
- 标题
- 布局
- 封面图片
- 发布时间
- 作者名称
- 文章id
- 作者id
- 静态url
哪些字段需要索引和分词?
- 标题
- 内容
使用Kibana添加映射
索引库名称:app_info_article
PUT /app_info_article
{"mappings":{"properties":{"id":{"type":"long"},"publishTime":{"type":"date"},"layout":{"type":"integer"},"images":{"type":"keyword","index": false},"staticUrl":{"type":"keyword","index": false},"authorId": {"type": "long"},"authorName": {"type": "keyword"},"title":{"type":"text","analyzer":"ik_max_word"},"content":{"type":"text","analyzer":"ik_max_word"}}}
}
1.3 索引数据同步
①app文章历史数据导入ES
1、创建es索引和映射
前面创建过了
2、文章微服务集成es功能
导入es服务的依赖
3、编写单元测试将历史状态正常的文章数据同步到es中
数据量特别少一次导入
数据量特别多分批导入,一次一两千条
mapper接口和sql语句
/**
* 查询es需要的全部文章数据* @return*/
List<SearchArticleVo> loadSearchArticleList();
<select id="loadSearchArticleList" resultType="com.heima.model.search.vos.SearchArticleVo">select aa.*, aacc.content from ap_article aaleft join ap_article_config aac on aa.id=aac.article_idLEFT JOIN ap_article_content aacc on aa.id = aacc.article_id
where aac.is_down=0 and aac.is_delete=0</select>
测试类代码
@Autowired
private RestHighLevelClient client;
/*** 将历史文章数据导入ES中*/
@Test
public void testImportES() throws IOException {// 1. 查询所有状态正常的文章列表List<SearchArticleVo> searchArticleVoList = apArticleMapper.loadSearchArticleList();// 2. 构建BulkRequest批量请求对象BulkRequest bulkRequest = new BulkRequest();// 3. 遍历文章列表逐一添加IndexRequestfor (SearchArticleVo searchArticleVo : searchArticleVoList) {IndexRequest indexRequest = new IndexRequest("app_info_article");indexRequest.source(JSON.toJSONString(searchArticleVo), XContentType.JSON).id(String.valueOf(searchArticleVo.getId()));bulkRequest.add(indexRequest);}// 4. 执行restHighLevelClient的bulk批量插入文档请求BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);// 5. 获取响应结果数据并输出int status = bulk.status().getStatus();System.out.println("导入完成,响应状态码"+status);System.out.println("==============================================================================================");BulkItemResponse[] items = bulk.getItems();for (BulkItemResponse item : items) {String result = item.getResponse().getResult().getLowercase();System.out.println(result);}
}
②文章实时数据导入ES
跨服务调用的异步,要使用mq
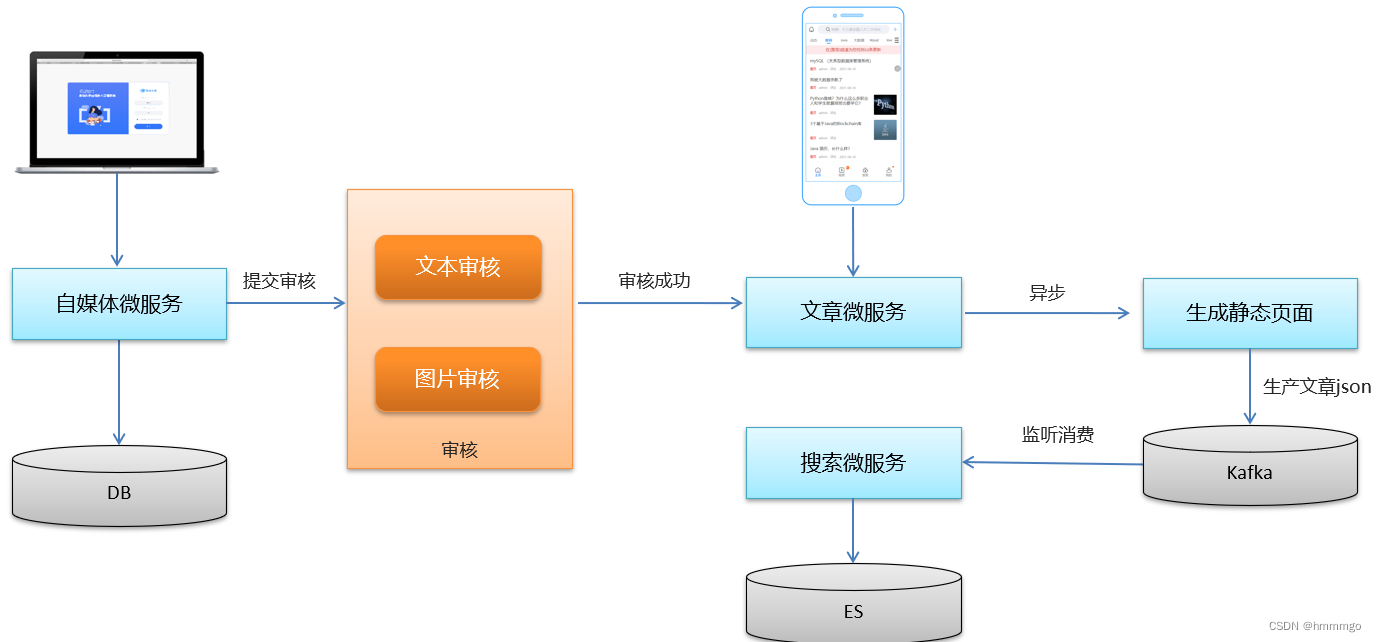
生产者
kafka:bootstrap-servers: 192.168.200.130:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer
// 5. 封装es所需的数据转为JSON,生产到Kafka中
SearchArticleVo searchArticleVo = new SearchArticleVo();
BeanUtils.copyProperties(apArticle,searchArticleVo);
searchArticleVo.setStaticUrl(url);
searchArticleVo.setContent(contentStr);
String articleJson = JSON.toJSONString(searchArticleVo);
kafkaTemplate.send(ArticleConstants.ARTICLE_ES_SYNC_TOPIC,articleJson);
消费者
spring:kafka:bootstrap-servers: 192.168.200.130:9092consumer:group-id: ${spring.application.name}key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
@Component
@Slf4j
public class ApArticleImportESListener {@Autowiredprivate RestHighLevelClient client;@KafkaListener(topics = ArticleConstants.ARTICLE_ES_SYNC_TOPIC)public void msg (ConsumerRecord<String,String> consumerRecord) {if (consumerRecord != null) {String articleJSON = consumerRecord.value();SearchArticleVo searchArticleVo = JSON.parseObject(articleJSON, SearchArticleVo.class);IndexRequest indexRequest = new IndexRequest("app_info_article");indexRequest.source(articleJSON, XContentType.JSON).id(searchArticleVo.getId().toString());try {IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);String result = indexResponse.getResult().getLowercase();String desc = result.equals("created") ? "导入成功" : "导入失败";log.info("[异步导入APP文章到ES],导入结果:{}", desc);} catch (IOException e) {throw new RuntimeException(e);}}}
}1.4 文章搜索多条件复合查询
①关键词搜索
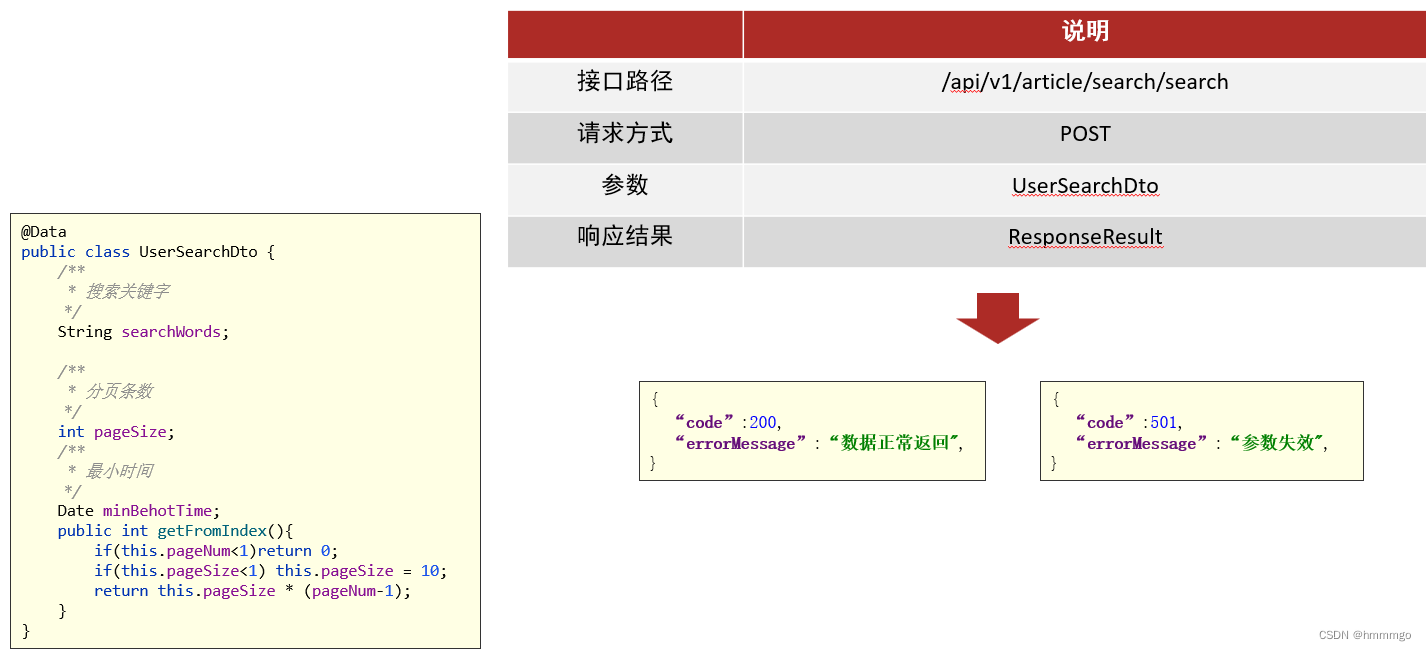
②搜索接口定义
2、搜索历史记录
2.1 需求说明
- 异步保存搜索记录
- 默认查询10条搜索记录,按照搜索关键词的时间倒序
- 可以删除搜索记录
2.2 数据存储说明
用户的搜索记录,需要给每一个用户都保存一份,数据量大,要求加载速度快,通常这样的数据存储到mongodb更合适,不建议直接存储到关系型数据库中
2.1 异步保存搜索历史
①实现思路
保存的数据量太大,不想同步影响效率,采用异步保存
@Service
@Slf4j
public class ApUserSearchServiceImpl implements ApUserSearchService {@Autowiredprivate MongoTemplate mongoTemplate;@Async("taskExecutor")@Overridepublic void insert(String keyword, Integer userId) {// 1. 查询搜索记录Query query = Query.query(Criteria.where("keyword").is(keyword).and("userId").is(userId));ApUserSearch apUserSearch = mongoTemplate.findOne(query, ApUserSearch.class);// 2. 如果搜索记录不存在,则保存搜索记录if (apUserSearch == null) {apUserSearch = new ApUserSearch();SnowflakeIdWorker isWorker = new SnowflakeIdWorker(10, 10);apUserSearch.setId(isWorker.nextId());// 使用雪花算法的值当做主键IDapUserSearch.setUserId(userId);apUserSearch.setKeyword(keyword);apUserSearch.setIsDeleted(0); // 未删除apUserSearch.setCreatedTime(new Date());apUserSearch.setUpdatedTime(new Date());mongoTemplate.save(apUserSearch);return;}// 3. 如果搜索记录存在且未删除,则更新updatedTimeif (apUserSearch.getIsDeleted() == 0) {apUserSearch.setUpdatedTime(new Date());mongoTemplate.save(apUserSearch);return;}// 4. 如果搜索记录存在且已删除,则更新为未删除及更新updateTimeapUserSearch.setIsDeleted(0);apUserSearch.setUpdatedTime(new Date());mongoTemplate.save(apUserSearch);}
}2.2 查看搜索历史列表
①接口定义
按照当前用户,按照时间倒序查询
@Overridepublic ResponseResult findUserSearch() {// 根据条件查询搜索记录列表(条件:userId和isDeleted 结果:updateTime倒序)Query query = Query.query(Criteria.where("userId").is(ThreadLocalUtil.getUserId()).and("isDeleted").is(0)).with(Sort.by(Sort.Direction.DESC,"updateTime"));query.limit(10);List<ApUserSearch> apUserSearchList = mongoTemplate.find(query, ApUserSearch.class);return ResponseResult.okResult(apUserSearchList);}
2.3 删除搜索历史
根据搜索历史id删除

@Overridepublic ResponseResult delUserSearch(HistorySearchDto dto) {ApUserSearch apUserSearch = mongoTemplate.findById(dto.getId(), ApUserSearch.class);if (apUserSearch == null) {return ResponseResult.errorResult(AppHttpCodeEnum.DATA_NOT_EXIST,"搜索记录不存在");}// 更新记录为已删除apUserSearch.setIsDeleted(1);apUserSearch.setUpdatedTime(new Date());mongoTemplate.save(apUserSearch);return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}
3、联想词查询
需求分析
根据用户输入的关键字展示联想词
3.1 联想词的来源
通常是网上搜索频率比较高的一些词,通常在企业中有两部分来源:
第一:自己维护搜索词
通过分析用户搜索频率较高的词,按照排名作为搜索词
第二:第三方获取
关键词规划师(百度)、5118、爱站网
3.2 联想词功能实现
接口定义
正则表达式说明

@Service
@Slf4j
public class ApAssociateWordsServiceImpl implements ApAssociateWordsService {@Autowiredprivate MongoTemplate mongoTemplate;@Overridepublic ResponseResult search(UserSearchDto dto) {// 替换一切特殊字符dto.setSearchWords(dto.getSearchWords().replaceAll("[^\u4e00-\u9fa5a-zA-z0-9]", ""));List<ApAssociateWords> apAssociateWordsList = mongoTemplate.find(Query.query(Criteria.where("associateWords").regex(".*?\\" + dto.getSearchWords() + ".*")).limit(dto.getPageSize()), ApAssociateWords.class);return ResponseResult.okResult(apAssociateWordsList);}
}
相关文章:
黑马头条-day10
文章目录 app端文章搜索1、文章搜索1.1 ElasticSearch环境搭建1.2 索引库创建①需求分析②ES导入数据场景分析③创建索引和映射 1.3 索引数据同步①app文章历史数据导入ES②文章实时数据导入ES 1.4 文章搜索多条件复合查询①关键词搜索②搜索接口定义 2、搜索历史记录2.1 需求说…...

C++的stack容器->基本概念、常见接口
#include<iostream> using namespace std; #include <stack> //栈stack容器常用接口 void test01() { //创建栈容器 栈容器必须符合先进后出 stack<int> s; //向栈中添加元素,叫做 压栈 入栈 s.push(10); s.push(20); s…...

VUE中引入外部jquery.min.js文件
jquery官网:https://jquery.com/ cdn链接:https://code.jquery.com/jquery-3.7.1.js <template><div class"">测试jq<div id"jq">这是一个盒子</div></div> </template><script> import…...

MongoDB聚合运算符:$avg
$avg运算符返回给定数值的平均值 $avg可用于以下阶段: $addFields阶段(从MongoDB 3.4开始可用)$bucket阶段$bucketAuto阶段$group阶段包含$expr表达式的$match阶段$project阶段$replaceRoot阶段(从MongoDB 3.4开始可用)$replaceWith阶段(从MongoDB 4.2开始可用)$s…...
Web 前端 UI 框架Bootstrap简介与基本使用
Bootstrap 是一个流行的前端 UI 框架,用于快速开发响应式和移动设备优先的网页。它由 Twitter 的设计师和工程师开发,现在由一群志愿者维护。Bootstrap 提供了一套丰富的 HTML、CSS 和 JavaScript 组件,可以帮助开发者轻松地构建和定制网页和…...

【Python笔记-设计模式】惰性评价模式
一、说明 将某些对象的创建或计算延迟到真正需要它们的时候,以减少不必要的资源消耗和提高性能。 惰性评价在Python中实现也成为生成器,一般通过yield关键字实现。 (一) 解决问题 在处理大量数据时,使用惰性加载可以避免一次性加载所有数…...

每日学习总结20240221
每日总结 20240221 花自飘零水自流。一种相思,两处闲愁。 —— 李清照「一剪梅红藕香残玉簟秋」 1. stat 在Linux中,stat 是一个用于显示文件或文件系统状态的命令行工具。它提供了关于文件的详细信息,包括文件类型、权限、大小、所有者、修…...
学生成绩管理系统(C语言课设 )
这个学生成绩管理系统使用C语言编写,具有多项功能以方便管理学生信息和成绩。首先从文件中读取数据到系统中,并提供了多种功能(增删改查等)选项以满足不同的需求。 学生成绩管理系统功能: 显示学生信息增加学生信息删除学生信息…...
)
ChatGPT提示词(最新)
它能干什么? 包括但不限于: 类别描述学术论文它可以写各种类型的学术论文,包括科技论文、文学论文、社科论文等。它可以帮助你进行研究、分析、组织思路并编写出符合学术标准的论文。创意写作它可以写小说、故事、剧本、诗歌等创意性的文学作品&#…...

算法——模拟
1. 什么是模拟算法? 官方一点来说 模拟算法(Simulation Algorithm)是一种通过模拟现实或抽象系统的运行过程来研究、分析或解决问题的方法。它通常涉及创建一个模型,模拟系统中的各种事件和过程,以便观察系统的行为&a…...
如何进行高性能架构的设计
一、前端优化 减少请求次数页面静态化边缘计算 增加缓存控制:请求头 减少图像请求次数:多张图片变成 一张。 减少脚本的请求次数:css和js压缩,将多个文件压缩成一个文件。 二、页面静态化 三、边缘计算 后端优化 从三个方面进…...
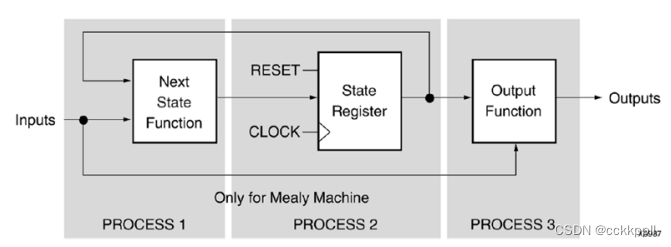
vivado FSM Components
Vivado合成功能 •同步有限状态机(FSM)组件的特定推理能力。 •内置FSM编码策略,以适应您的优化目标。 •FSM提取默认启用。 •使用-fsm_extraction off可禁用fsm提取。 FSM描述 Vivado综合支持Moore和Mealy中的有限状态机(…...
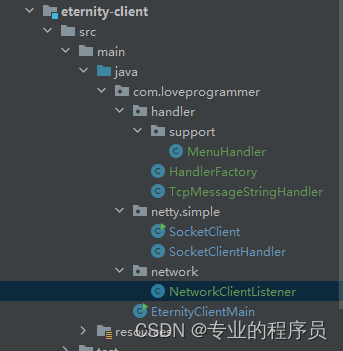
从零开始手写mmo游戏从框架到爆炸(十五)— 命令行客户端改造
导航:从零开始手写mmo游戏从框架到爆炸(零)—— 导航-CSDN博客 到现在,我们切实需要一个客户端来完整的进行英雄选择,选择地图,打怪等等功能。所以我们需要把之前极为简陋的客户端改造一下。 首先…...
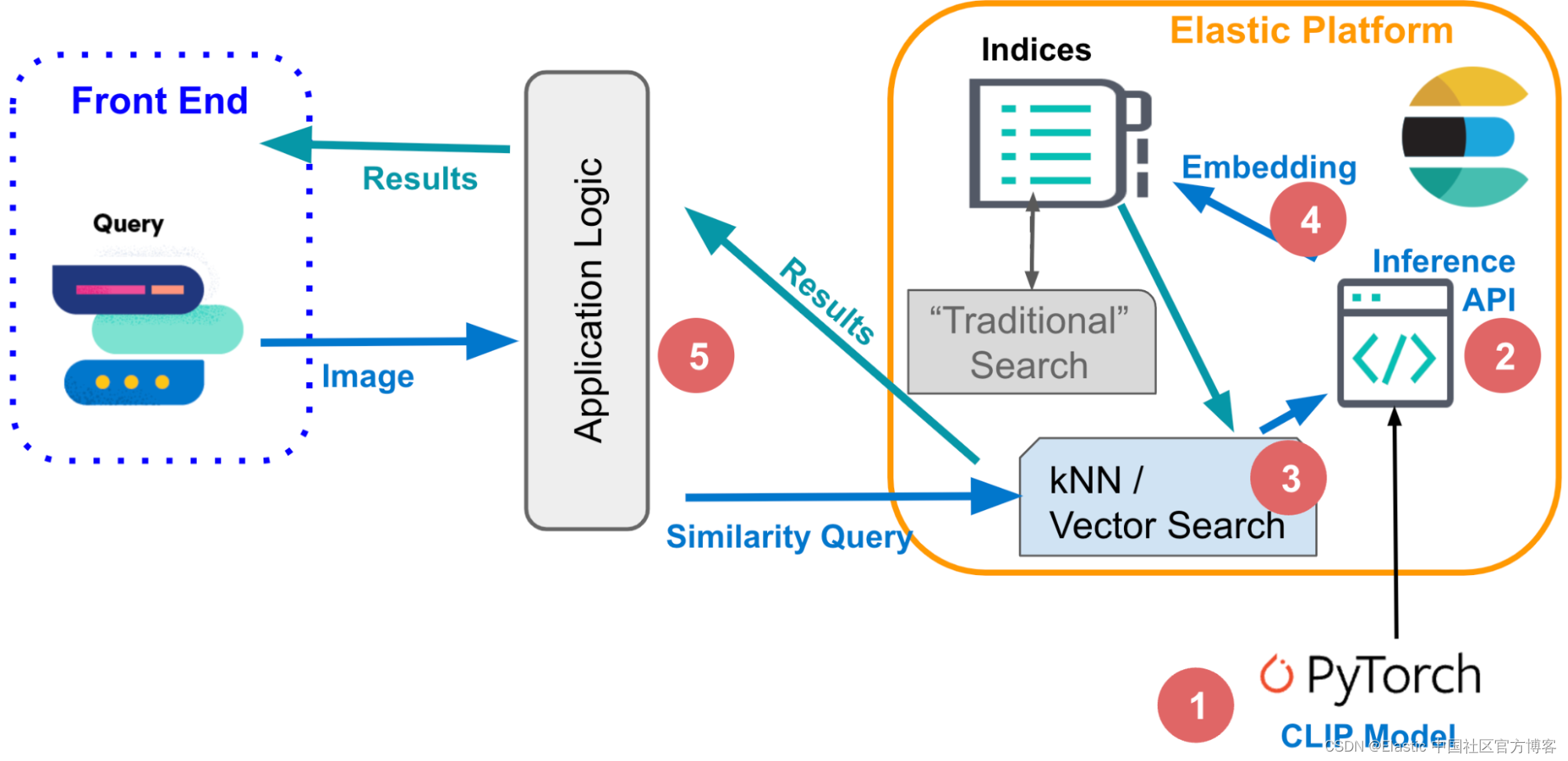
Elasticsearch:什么是 kNN?
kNN - K-nearest neighbor 定义 kNN(即 k 最近邻算法)是一种机器学习算法,它使用邻近度将一个数据点与其训练并记忆的一组数据进行比较以进行预测。 这种基于实例的学习为 kNN 提供了 “惰性学习(lazy learning)” 名…...

掌握网络未来:深入解析RSVP协议及其在确保服务质量中的关键作用
第一部分:RSVP简介 资源预留协议(RSVP)是一种网络协议,用于在网络中的各个节点之间预留资源,以支持数据流的服务质量(QoS)要求。RSVP特别适用于需要固定带宽和处理延迟的应用,如视频…...
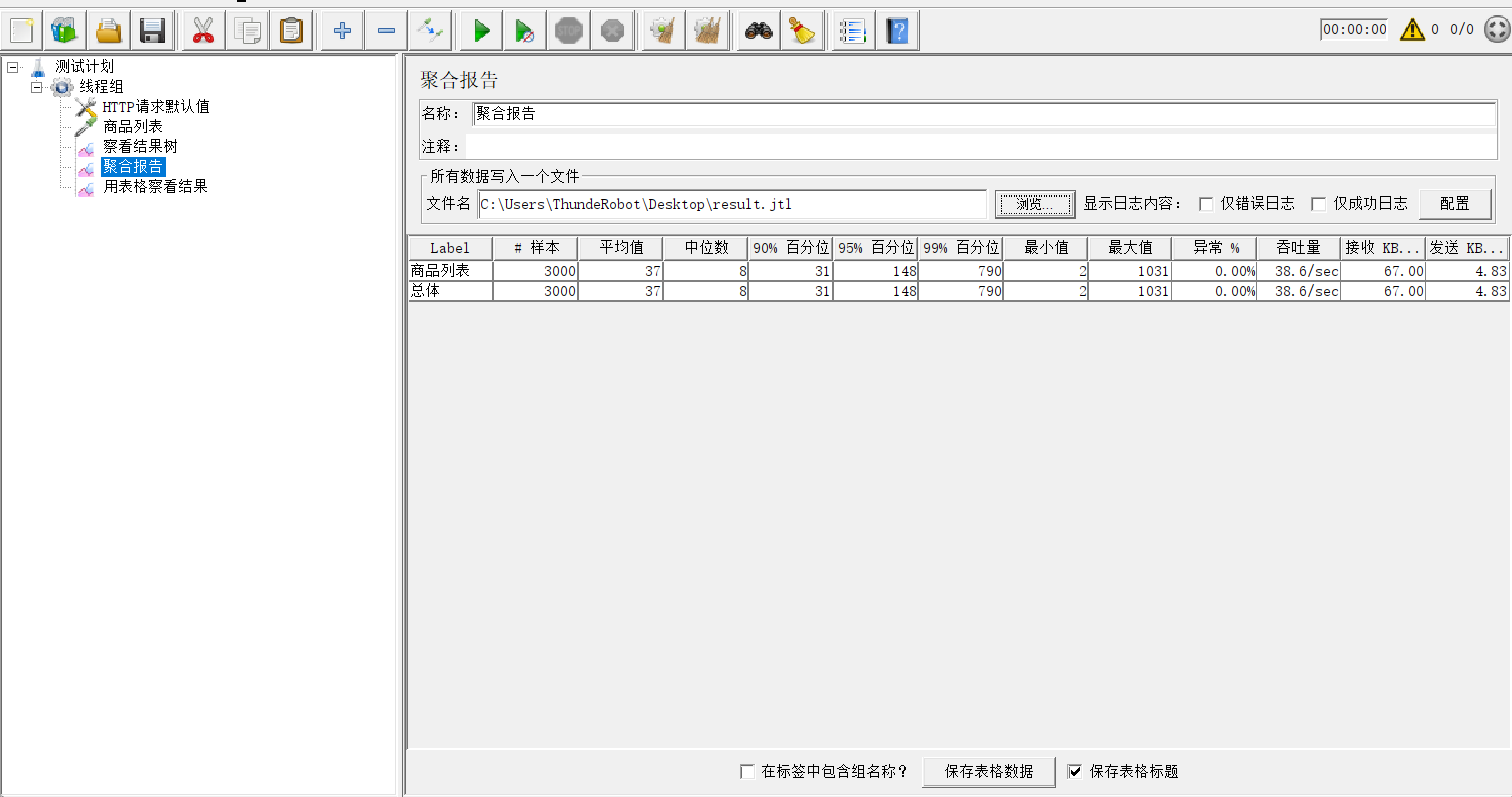
【Linux】一站式教会:Ubuntu(无UI界面)使用apache-jmeter进行压测
🏡浩泽学编程:个人主页 🔥 推荐专栏:《深入浅出SpringBoot》《java对AI的调用开发》 《RabbitMQ》《Spring》《SpringMVC》 🛸学无止境,不骄不躁,知行合一 文章目录 前言一、Java…...

Howler.js:音频处理的轻量级解决方案
文章目录 Howler.js:音频处理的轻量级解决方案引言一、Howler.js简介1.1 特性概览 二、Howler.js基本使用使用详解2.1 创建一个Howl对象2.2 控制音频播放2.3 监听音频事件 三、进阶功能3.1 音频Sprites3.2 3D音频定位 四、微前端场景下的Howler.js Howler.js&#x…...

【讨论】Web端测试和App端测试的不同,如何说得更有新意?
Web 端测试和 App 端测试是针对不同平台的上的应用进行测试,Web应用和App端的应用实现方式不同,测试时的侧重点也不一样。 Web端应用和App端应用的区别: 平台兼容性 安装方式 功能和性能 用户体验 更新和维护 测试侧重点有何不同 平台…...

运维SRE-18 自动化批量管理-ansible4
12.2handles handles触发器(条件),满足条件后再做什么事情应用场景:想表示:配置文件变化,再重启服务 配置handlers之前,每次运行剧本都会重启nfs,无论配置文件是否变化。 [rootm01 /server/ans/playbook]…...

编程笔记 Golang基础 008 基本语法规则
编程笔记 Golang基础 008 基本语法规则 Go语言的基本语法规则. Go语言的基本语法规则包括但不限于以下要点: 标识符: 标识符用于命名变量、常量、类型、函数、包等。标识符由字母(a-z,A-Z)、数字(0-9&#…...
)
HYCONTROL MICROFLEX-DB超声波液位计实操详解(参数+工况+故障排查)
在工业液位测量中,腐蚀性介质、罐内干扰、泡沫水汽、后期维护量大一直是现场普遍痛点,很多中小型储罐、水池、反应罐都会纠结性价比高、调试简单、稳定性强的超声波液位计。今天给大家详细拆解一款进口紧凑型液位变送器:英国HYCONTROL海康MIC…...

从Launch/Capture路径理解CRPR:一个例子讲清楚它在Setup/Hold检查中的关键作用
从Launch/Capture路径理解CRPR:一个例子讲清楚它在Setup/Hold检查中的关键作用 在芯片后端设计中,时序分析是确保电路功能正确的关键环节。当我们谈论时钟路径分析时,CRPR(Clock Reconvergence Pessimism Removal)是一…...

Arm Compiler 6.19嵌入式开发工具链解析
1. Arm Compiler for Embedded 6.19版本深度解析Arm Compiler for Embedded 6.19是Arm公司于2022年10月12日发布的嵌入式C/C编译工具链。作为一款专为裸机软件、固件和实时操作系统(RTOS)应用开发设计的工具链,它提供了对Arm架构最新特性的支持。需要注意的是&#…...

4 款主流论文降 AI 软件实测对比!谁能 5 分钟把 AI 率降到 10% 以下
4 款主流论文降 AI 软件实测对比!谁能 5 分钟把 AI 率降到 10% 以下 毕业季最焦虑的事——答辩前剩 3 天、AI 率还有 70%、想找一款 5 分钟就能搞定的工具。 市面上很多工具宣称"几分钟出结果"——但实测下来快的快、慢的慢、效果差距更大。这篇文章实测对…...

多智能体会被“单强模型”取代吗:从系统复杂度看真实趋势
标题:多智能体会被“单强模型”取代吗:从系统复杂度看真实技术演化趋势 关键词:多智能体系统、通用人工智能、大语言模型、系统复杂度、涌现性、任务分解、AI范式演化 摘要:2024年以来,GPT-4o、Claude 3 Opus等单一大模型的通用能力边界持续突破,不少开发者发现此前需要…...

京东滑块验证码JS逆向实战:从接口分析到轨迹加密
1. 京东滑块验证码逆向分析入门 第一次接触京东滑块验证码逆向时,我也被那一堆加密参数搞得头晕眼花。但经过多次实战后,我发现只要掌握几个关键点,就能轻松破解这个看似复杂的验证系统。滑块验证码的核心逻辑其实很简单:系统通过…...

长期项目使用 Taotoken 聚合 API 在模型选型与切换上的便利性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用 Taotoken 聚合 API 在模型选型与切换上的便利性体验 在一个持续数月的研发项目中,我们构建了一个需要集成…...

Scroll Reverser:为什么你的Mac需要这款滚动方向控制神器?
Scroll Reverser:为什么你的Mac需要这款滚动方向控制神器? 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 作为一名设计师,李华每天在MacBook…...

基板式PCB与嵌入式芯片:下一代电子系统集成的核心技术解析
1. 项目概述:从一块“板子”看透一个产业干了十几年硬件,从画第一块51单片机的板子,到如今参与定义复杂的系统级封装,我越来越觉得,PCB(印制电路板)和芯片的关系,早已不是简单的“承…...

减少重复劳作,气泡图软件助力质检效率升级
在制造业做过质量或工程的人,一定都有过这种体验:一张复杂图纸几百个尺寸,一个个手动画气泡、编号、抄 Excel,眼睛越看越花,手指越敲越累。更折磨的是,图纸一改,气泡编号几乎要全部重来…...