多数pythoneer只知有列表list却不知道python也有array数组

数组和列表
Python中数组和列表是不同的,我敢断言大多数的pythoneer只知道有列表list,却不知道python也有array数组。列表是一个包含不同数据类型的元素集合,而数组是一个只能含相同数据类型的元素集合。
Python的array库是一个提供数组操作的模块,它提供了一种用于存储和处理多个相同类型元素的容器。与Python的列表list相比,数组array在存储和操作大量数值型数据时更为高效,因为它在内存中以连续的方式存储数据,占用的内存空间更小。
数组创建
array(typecode [, initializer]) -> array
返回一个新数组,该数组的项受类型代码的限制,并通过可选的初始值设定项值进行初始化,该值必须是列表、字符串或可在适当类型的元素上迭代。
数组表示基本值,其行为与列表非常相似,只是其中存储的对象类型受到约束。类型是在对象创建时使用类型代码指定的,该代码是单个字符。
类型代码 typecode
| 类型 | C类型 | 最小字节 |
| 'b' | signed integer | 1 |
| 'B' | unsigned integer | 1 |
| 'u' | Unicode character | 2 |
| 'h' | signed integer | 2 |
| 'H' | unsigned integer | 2 |
| 'i' | signed integer | 2 |
| 'I' | unsigned integer | 2 |
| 'l' | signed integer | 4 |
| 'L' | unsigned integer | 4 |
| 'q' | signed integer | 8 |
| 'Q' | unsigned integer | 8 |
| 'f' | floating point | 4 |
| 'd' | floating point | 8 |
创建数组
import array
arr = array.array('i', [1, 2, 3, 4, 5]) # 创建一个整数类型的数组
arr = array.array('u', 'abcde') # 创建一个字符类型的数组
类型属性
import array
arr = array.array('i', [1, 2, 3, 4, 5])
print(arr.typecode) # 打印数组类型 i
数组切片
与列表用法相同:
>>> arr = array.array('i', [1, 2, 3, 4, 5])
>>> arr[0]
1
>>> arr[2]
3
>>> arr[-1]
5
>>> arr[:3]
array('i', [1, 2, 3])
>>> arr[3:]
array('i', [4, 5])
>>> arr[:-1]
array('i', [1, 2, 3, 4])
>>> arr[::-1]
array('i', [5, 4, 3, 2, 1])
>>> arr[1::2]
array('i', [2, 4])
>>> arr[0::2]
array('i', [1, 3, 5])
类型转换
整数数组可以转换到浮点数数组,反之不行。
>>> arr1 = array.array('i', [1, 2, 3, 4, 5])
>>> arr1
array('i', [1, 2, 3, 4, 5])
>>> arr2 = array.array('f', arr1)
>>> arr2
array('f', [1.0, 2.0, 3.0, 4.0, 5.0])
>>> arr3 = array.array('i', arr2)
Traceback (most recent call last):
File "<pyshell#77>", line 1, in <module>
arr3 = array.array('i', arr2)
TypeError: 'float' object cannot be interpreted as an integer
数组与列表占用内存的比较
import sys, array
arr = array.array('i', [_ for _ in range(1024)])
lst = [_ for _ in range(1024)]
print(sys.getsizeof(arr)) # 输出:4176 array对象本身的大小
print(sys.getsizeof(lst)) # 输出:8856 列表list对象本身的大小
# 注意:这些值可能因操作系统或Python解释器的实现和版本而略有不同。
数组方法
append()--将一个新项追加到数组的末尾
buffer_info()--返回给出当前内存信息的信息
byteswap()--字节交换数组的所有项
count()--返回对象的出现次数
extend()--通过从可迭代项中附加多个元素来扩展数组
fromfile()--从文件对象读取项
fromlist()--从列表中追加项
frombytes()--从字符串中追加项
fromunicode()--从unicode字符串中追加项
index()--返回对象第一次出现的索引
insert()--在数组中提供的位置插入一个新项
pop()--移除并返回项(默认为最后一个)
remove()--删除对象的第一个出现项
reverse()--反转数组中项目的顺序
tofile()--将所有项写入文件对象
tolist()--返回转换为普通列表的数组
tobytes()--返回转换为字符串的数组
在举例讲解前先来复习一个列表list的方法,用法相同的(绿色标注)可以省略不学:
append(self, object, /)
Append object to the end of the list.clear(self, /)
Remove all items from list.copy(self, /)
Return a shallow copy of the list.count(self, value, /)
Return number of occurrences of value.extend(self, iterable, /)
Extend list by appending elements from the iterable.index(self, value, start=0, stop=9223372036854775807, /)
Return first index of value.
Raises ValueError if the value is not present.insert(self, index, object, /)
Insert object before index.pop(self, index=-1, /)
Remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.remove(self, value, /)
Remove first occurrence of value.
Raises ValueError if the value is not present.reverse(self, /)
Reverse *IN PLACE*.sort(self, /, *, key=None, reverse=False)
Sort the list in ascending order and return None.
用法讲解
buffer_info()
返回当前数组缓冲区的内存信息。
import array
arr = array.array('i', [1, 2, 3])
buffer_info = arr.buffer_info()
print(buffer_info) # 输出包含内存地址、大小等信息的元组
byteswap()
字节交换数组的所有项,通常用于处理二进制数据的不同字节顺序。
import array
arr = array.array('i', [0x12345678]) # 假设这是一个32位整数
arr.byteswap()
print(arr) # 输出:[305419896] (0x78563412)
fromfile()
从文件对象中读取项,通常用于从二进制文件中读取数据。
import array
with open('data.bin', 'rb') as f:
arr = array.array('i')
arr.fromfile(f, 3) # 从文件中读取3个整数
print(arr) # 输出:假设文件中有3个整数,则输出这些整数构成的数组
fromlist()
从列表中追加项,创建一个新的数组。
import array
list_data = [1, 2, 3, 4, 5]
arr = array.array('i', list_data)
print(arr) # 输出:array('i', [1, 2, 3, 4, 5])
frombytes()
从字节字符串中追加项,创建一个新的数组。
import array
byte_data = b'\x01\x02\x03\x04'
arr = array.array('B', byte_data) # 'B' 表示无符号字符
print(arr) # 输出:array('B', [1, 2, 3, 4])
tofile()
将所有项写入文件对象,通常用于将数组数据写入二进制文件。
import array
arr = array.array('i', [1, 2, 3])
with open('output.bin', 'wb') as f:
arr.tofile(f)
# 现在'output.bin'文件包含数组的数据
tolist()
返回转换为普通列表的数组。
import array
arr = array.array('i', [1, 2, 3])
list_data = arr.tolist()
print(list_data) # 输出:[1, 2, 3]
tobytes()
返回转换为字节字符串的数组。
import array
arr = array.array('i', [1, 2, 3])
byte_data = arr.tobytes()
print(byte_data) # 输出:b'\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00'
用法举例
实例1
import array # 创建一个浮点数类型的array实例
float_array = array.array('f', [1.0, 2.0, 3.0, 4.0, 5.0]) # 打印原始数组
print("Original Array:", float_array) # 计算每个元素的平方
squared_array = array.array('f')
for num in float_array: squared_array.append(num ** 2) # 打印平方数组
print("Squared Array:", squared_array) # 计算每个元素的立方
cubed_array = array.array('f')
for num in float_array: cubed_array.append(num ** 3) # 打印立方数组
print("Cubed Array:", cubed_array) # 计算平方和立方数组的和
sum_squared = sum(squared_array)
sum_cubed = sum(cubed_array) # 打印和
print("Sum of Squared:", sum_squared)
print("Sum of Cubed:", sum_cubed)输出结果:
Original Array: array('f', [1.0, 2.0, 3.0, 4.0, 5.0])
Squared Array: array('f', [1.0, 4.0, 9.0, 16.0, 25.0])
Cubed Array: array('f', [1.0, 8.0, 27.0, 64.0, 125.0])
Sum of Squared: 55.0
Sum of Cubed: 225.0
实例2
import array # 原始字符串
original_string = "Hello, World!" # 将字符串转换为字符数组
# 注意:'u' 类型用于存储 Unicode 字符,但在 Python 3 中,'u' 类型已被废弃
# 我们应该使用 'U' 类型来存储 Unicode 字符(码点),但这通常用于宽字符集
# 在此示例中,我们将使用字节数组 'b' 并通过编码字符串来处理它 # 编码原始字符串为字节
encoded_string = original_string.encode('utf-8') # 创建一个字节类型的array实例
byte_array = array.array('b', encoded_string) # 打印字节数组
print("Byte Array:", byte_array) # 查找特定字节(例如查找 'o' 字符的字节表示)
# 注意:这里我们查找的是 'o' 字符的 UTF-8 编码的第一个字节
# 在 ASCII 中,'o' 的编码是 0x6F,但在 UTF-8 编码的字符串中,我们需要找到正确的字节序列
# 对于简单的 ASCII 字符,UTF-8 编码与 ASCII 编码相同
target_byte = ord('o') # 获取 'o' 字符的 ASCII 码点值
target_indices = [i for i, b in enumerate(byte_array) if b == target_byte]
print("Indices of 'o':", target_indices) # 替换所有 'o' 字符的字节表示为另一个字符(例如 'x')
# 注意:直接替换可能破坏 UTF-8 编码的多字节字符序列
# 因此,这个例子仅适用于单字节字符(ASCII 范围内)的字符串
replacement_byte = ord('x') # 获取 'x' 字符的 ASCII 码点值
for i in target_indices: byte_array[i] = replacement_byte # 将修改后的字节数组转换回字符串
# 注意:如果替换了多字节字符的一部分,解码可能会失败
try: modified_string = byte_array.tobytes().decode('utf-8') print("Modified String:", modified_string)
except UnicodeDecodeError: print("Decoding failed due to invalid UTF-8 sequence.") # 注意:在处理包含非ASCII字符的字符串时,应该格外小心,
# 因为UTF-8编码可能会使用多个字节来表示一个字符。
# 在这种情况下,直接替换单个字节可能会破坏字符的编码。
输出结果:
Byte Array: array('b', [72, 101, 108, 108, 111, 44, 32, 87, 111, 114, 108, 100, 33])
Indices of 'o': [4, 8]
Modified String: Hellx, Wxrld!
实例3
import array # 创建一个整数类型的array实例
int_array = array.array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) # 打印原始数组
print("Original Integer Array:", int_array) # 将数组写入文件
with open('int_array.bin', 'wb') as f: int_array.tofile(f) # 打开文件以读取二进制数据
with open('int_array.bin', 'rb') as f: # 读取整个文件到数组中 # 由于我们知道文件中的数据类型和大小,我们可以使用这些信息来创建数组 # 假设文件中的整数是32位的(即 'i' 表示整数),并且我们不知道有多少个整数 # 我们可以先读取文件的大小,然后除以整数的字节大小来得到整数的数量 file_size = f.seek(0, 2) # 移动到文件末尾以获取文件大小 num_ints = file_size // 4 # 假设整数是32位的(4字节) f.seek(0) # 将文件指针重置回文件开头 # 创建一个空的array实例,用于存储读取的数据 read_array = array.array('i') # 从文件中读取整数数据到数组中 read_array.fromfile(f, num_ints) # 打印从文件中读取的数组
print("Array Read from File:", read_array)# 验证两个数组是否相同
assert int_array == read_array
print("The arrays are the same.")输出结果:
Original Integer Array: array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Array Read from File: array('i', [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
The arrays are the same.
完。
相关文章:
多数pythoneer只知有列表list却不知道python也有array数组
数组和列表 Python中数组和列表是不同的,我敢断言大多数的pythoneer只知道有列表list,却不知道python也有array数组。列表是一个包含不同数据类型的元素集合,而数组是一个只能含相同数据类型的元素集合。 Python的array库是一个提供数组操作…...
)
【Rust】——控制流(if-else,循环)
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...

通过platform总线驱动框架编写LED灯的驱动,编写应用程序测试
mydev.c #include <linux/init.h> #include <linux/module.h> #include <linux/of_gpio.h> #include <linux/gpio.h> #include <linux/platform_device.h> #include <linux/mod_devicetable.h>// 创建功能码 #define LED_ON _IO(l, 1) #d…...

费舍尔FISHER金属探测器探测仪维修F70
美国FISHER LABS费舍尔地下金属探测器,金属探测仪等维修(考古探金银铜探宝等仪器)。 费舍尔F70视听目标ID金属探测器,Fisher 金属探测器公司成立于1931年,在实验条件很艰苦的情况下,研发出了地下金属探测器…...
Airtest-Selenium实操小课③:下载可爱猫猫图片
1. 前言 那么这周我们看看如何实现使用Airtest-Selenium实现自动搜索下载可爱的猫猫图片吧~ 2. 需求分析和准备 整体的需求大致可以分为以下步骤: 打开chrome浏览器 打开百度网页 搜索“可爱猫猫图片” 定位图片元素 创建存储图片的文件夹 下载可爱猫猫图片…...
Druid无法登录监控页面
问题表现:在配置和依赖都正确的情况下,无法通过配置的用户名密码登录Druid的监控页面 检查配置发现 配置的用户名和密码和请求中参数是一致的🤔 Debug发现 ResourceServlet 是Druid的登录实现, 且调试发现usernameParam是null&am…...

【Linux系统化学习】深入理解匿名管道(pipe)和命名管道(fifo)
目录 进程间通信 进程间通信目的 进程间通信的方式 管道 System V IPC(本地通信) POSIX IPC(网络通信) 管道 什么是管道 匿名管道 匿名管道的创建 匿名管道的使用 匿名管道的四种情况 匿名管道的五种特性 命名管道 …...

信息学奥赛一本通1209:分数求和
1209:分数求和 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 19111 通过数: 10647 【题目描述】 输入n个分数并对他们求和,并用最简形式表示。所谓最简形式是指:分子分母的最大公约数为11;若最终结果的分母为11&am…...

LabVIEW储氢材料循环寿命测试系统
LabVIEW储氢材料循环寿命测试系统 随着氢能技术的发展,固态储氢技术因其高密度和安全性成为研究热点。储氢材料的循环寿命是衡量其工程应用的关键。然而,传统的循环寿命测试设备存在成本高、测试效率低、数据处理复杂等问题。设计了一种基于LabVIEW软件…...

Unity3D 框架如何搭建基于纯Lua的U框架与开发模式详解
前言 Unity3D 是一款非常流行的游戏开发引擎,它支持C#、JavaScript和Boo等多种脚本语言。而Lua语言作为一种轻量级的脚本语言,也在游戏开发中得到了广泛应用。本文将介绍如何在Unity3D框架中搭建基于纯Lua的U框架,并详细讲解其开发模式。 对…...

Linux常见指令(2)
目录 1、tar指令 ! 2、bc指令 3、uname 4、重要热键 5、关机 1、tar指令 ! 功能:压缩/解压缩文件或目录,类似zip 我们先来看一下我们的文件即目录,接下来我们输入指令: tar -czf test.tgz test 压缩 -c …...

【C++】封装
1.封装的意义 封装是C面向对象三大特性之一 实例化(通过一个类 创建一个对象的过程) 类中的属性和行为 我们统一称为 成员 属性 成员属性 成员变量 行为 成员函数 成员方法 封装的意义: 1.将属性和行为作为一个整体,表现生活中的事…...
Maxwell安装部署
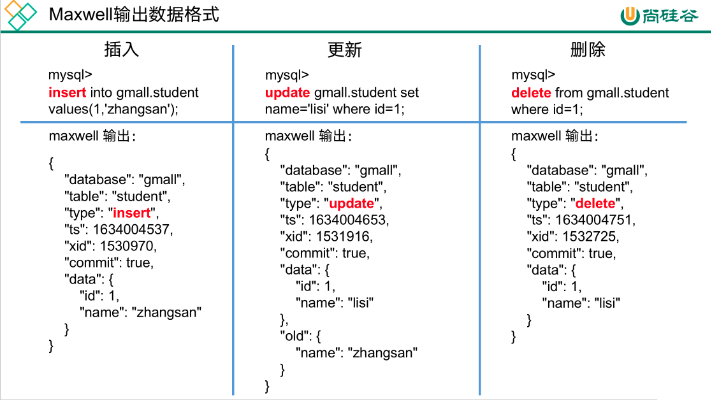
1 Maxwell输出格式 database:变更数据所属的数据库table:变更数据所属的表type:数据变更类型ts:数据变更发生的时间xid:事务idcommit:事务提交标志,可用于重新组装事务data:对于inse…...
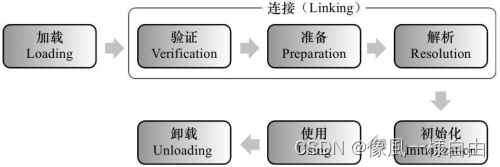
说一下JVM类加载机制?
Java中的所有类,都需要由类加载器装载到JVM中才能运行。类加载器本身也是一个类,而它的工作就是把class文件从硬盘读取到内存中。 在写程序的时候,我们几乎不需要关心类的加载,因为这些都是隐式装载的,除非我们有特殊…...
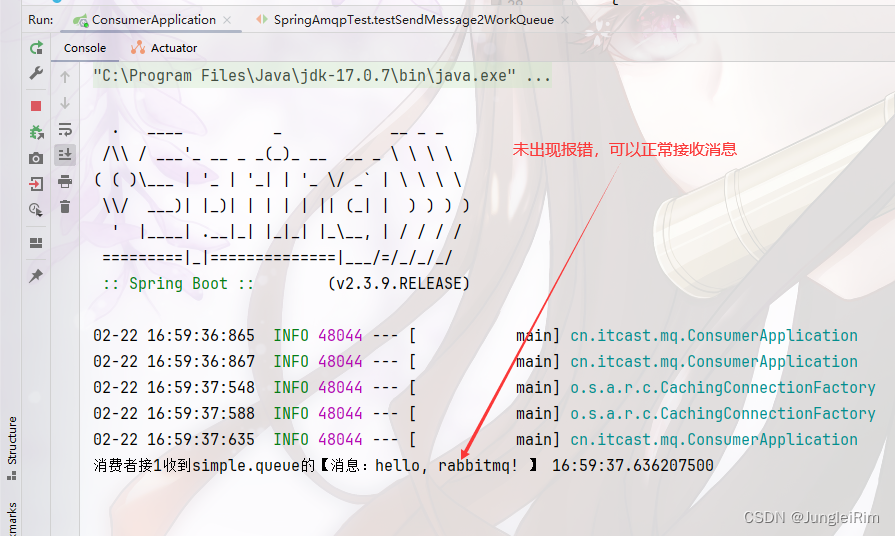
解决SpringAMQP工作队列模型程序报错:WARN 48068:Failed to declare queue: simple.queue
这里写目录标题 1.运行环境2.报错信息3.解决方案4.查看解决之后的效果 1.运行环境 使用docker运行了RabbitMQ的服务器: 在idea中导入springAMQP的jar包,分别编写了子模块生产者publisher,消费者consumer: 1.在publisher中运行测试…...

mysql在服务器中的主从复制Linux下
mysql在服务器中的主从复制Linux下 为什么要进行主从复制主从复制的原理主从复制执行流程操作步骤主库创建从库创建 测试 为什么要进行主从复制 在业务中通常会有情况,在sql执行时,将表锁住,导致不能进行查询,这样就会影响业务的…...
QT-Day2
思维导图 作业 使用手动连接,将登录框中的取消按钮使用qt4版本的连接到自定义的槽函数中,在自定义的槽函数中调用关闭函数 将登录按钮使用qt5版本的连接到自定义的槽函数中,在槽函数中判断ui界面上输入的账号是否为"admin"&#x…...

流量分析——陇剑杯 2021【签到、jwt】
目录 签到1、攻击者正在进行的可能是什么协议的网络攻击 jwt1、该网站使用了______认证方式。前置知识:解: 2、黑客绕过验证使用的jwt中,id和username是3、黑客获取webshell之后,权限是什么4、黑客上传的恶意文件文件名是5、黑客在…...

Java并发基础:原子类之AtomicIntegerFieldUpdater全面解析
本文概要 AtomicIntegerFieldUpdater类提供了一种高效、简洁的方式来原子性地更新对象的volatile字段,无需使用重量级的锁机制,它通过基于反射的API实现了细粒度的并发控制,提升了多线程环境下的性能表现。 AtomicIntegerFieldUpdater核心概…...

普中51单片机学习(串口通信)
串口通信 原理 计算机通信是将计算机技术和通信技术的相结合,完成计算机与外部设备或计算机与计算机之间的信息交换 。可以分为两大类:并行通信与串行通信。并行通信通常是将数据字节的各位用多条数据线同时进行传送 。控制简单、传输速度快࿱…...

VisualCppRedist AIO:Windows系统运行库终极解决方案
VisualCppRedist AIO:Windows系统运行库终极解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在安装新软件或游戏时,突…...

5G网优路测数据分析方法:从数据采集到问题定位
路测(Drive Test)是5G网络优化最基础也是最关键的数据采集手段。本文从数据采集、分析方法、问题定位三个层面,系统讲解5G路测数据分析方法论。一、5G路测概述1.1 路测目的目的说明适用场景覆盖验证验证5G网络覆盖是否达标新站开通、优化后验…...

嵌入式通信系统抗干扰设计:从硬件防护到协议容错的实战指南
1. 项目概述:当通信遇上“嘈杂”的现实世界干了十几年嵌入式,从工业控制到智能家居,从车载网络到物联网终端,我踩过最多的坑,往往不是算法有多复杂,代码有多难写,而是通信链路在各种现实环境下的…...

避坑指南:STM32F407的ADC多通道采样,你的数据顺序真的对了吗?
STM32F407多通道ADC采样数据错位排查手册 在嵌入式开发中,ADC多通道采样是常见需求,但数据顺序错乱问题却让不少工程师深夜加班。上周有位同行发来求助:他的四通道温度监测系统运行两周后,突然出现通道数据交叉污染,导…...

Web架构师工具箱:从工程化实践到现代化Web开发全流程
1. 项目概述:一个Web架构师的工具箱最近在GitHub上看到一个挺有意思的项目,叫choppawave-beep/web-architect。光看这个名字,你可能会有点摸不着头脑,choppawave-beep像是个用户名,而web-architect则直白地指向“Web架…...
)
从集合运算到代码实战:一文搞懂Python中Jaccard相似度的5种计算姿势(附性能对比)
从集合运算到代码实战:一文搞懂Python中Jaccard相似度的5种计算姿势(附性能对比) 在数据科学和机器学习领域,集合相似度计算是一个基础但至关重要的任务。想象一下这样的场景:你需要比较数百万用户的兴趣标签ÿ…...

深入解析Umi-OCR:开源离线OCR工具的技术架构与实践应用
深入解析Umi-OCR:开源离线OCR工具的技术架构与实践应用 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语…...

轻量级代码生成模型nanocoder:边缘部署与高效微调实战
1. 项目概述:一个为边缘而生的高效代码生成模型最近在折腾一些边缘设备上的AI应用,比如在树莓派或者Jetson Nano上跑一些轻量级的代码补全工具,发现市面上那些动辄几十亿参数的大模型根本塞不进去,跑起来也慢得让人心焦。就在这个…...

TVA模型适配FPC材料疲劳差异
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

如何永久冻结IDM试用期:简单三步实现无限期免费使用
如何永久冻结IDM试用期:简单三步实现无限期免费使用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script IDM Activation Script是一款开源工具࿰…...