week04day04(爬虫)
一. 嵌套构造URL
下载所有英雄的皮肤图片:因为每个英雄图片的网址不同,但是有共同点,通过构建这个网址,再经过循环建立 所有链接
import requests
import os# 1. 获取所有英雄的ID
def get_all_hero_id():url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'res = requests.get(url).json()return [x['heroId'] for x in res['hero']]# list1 = get_all_hero_id()
# print(list1)
# https://game.gtimg.cn/images/lol/act/img/js/hero/{897}.js# 2.定义函数获取指定英雄的皮肤信息
def get_one_hero_skins(hero_id:str):url = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{hero_id}.js'result = requests.get(url).json()# 创建英雄的文件夹hero_name = result['hero']['name']folder_path = f'所有英雄的皮肤/{hero_name}'if not os.path.exists(folder_path):os.mkdir(folder_path)# 下载这个英雄的皮肤的链接for skin in result['skins']:skin_name = skin['name'].replace('/','')skin_img = skin['mainImg']if not skin_img:skin_img = skin['chromaImg']# 下载皮肤图片res = requests.get(skin_img)if res.status_code == 200:file_path = f'{folder_path}/{skin_name}.jpg'with open(file_path,'wb') as f:f.write(res.content)print('下载成功!')if __name__ == '__main__':ids = get_all_hero_id()for x in ids:get_one_hero_skins(x)二、selenium
-
使用和浏览器相匹配的webdriver
-
chrome://version/ 查看版本
1.selenium的基本使用
from selenium.webdriver import Chrome# 1.创建浏览器对象
driver = Chrome()# 2.打开页面
driver.get('https://movie.douban.com/top250')# 3. 获取网页源代码
print(driver.page_source)# 4. 关闭浏览器窗口
driver.close()# 5.释放资源
driver.quit()2. selenium进阶 自动在京东网站的搜索框中查找笔记本电脑
from selenium.webdriver import Chrome
from time import sleep
from selenium.webdriver.common.by import By# 1. 创建对象
b = Chrome()# 2.打开网页
b.get('https://www.jd.com/')
# 强制等待5s
sleep(5)# 输入框输入内容
# a.找到输入框
# 通过id 找到输入框
input_tag = b.find_element(By.ID, 'key')# b. 输入东西
# send_keys 是自动输入
input_tag.send_keys('笔记本电脑\n') # \n是回车的意思
input('是否结束')# 3.结束
b.close()
b.quit()3. selenium再进阶 在百度中进行搜索, 增加功能:获取所有打开的页面,并且切换到最新打开的页面
from selenium.webdriver import Chrome
from time import sleep
from selenium.webdriver.common.by import By# 1. 创建对象
b = Chrome()# 2.打开网页
b.get('https://www.baidu.com/')
sleep(5)# 输入框输入内容
# a.找到输入框
# 这里的value去网页看检查, 看输入框的id 是什么,这里百度的id 是kw
input_tag = b.find_element(By.ID, 'kw')# b. 输入东西
input_tag.send_keys('上海天气') # \n是回车的意思
# 百度一下那个按钮
btn = b.find_element(By.ID,'su')# 按下按钮
btn.click()
# 获取当前所有打开的窗口
all_window = b.window_handles
# 切换到最新打开的浏览器窗口,[-1]是最右边新的窗口
b.switch_to.window(all_window[-1])# 3.结束
b.close()
b.quit()**4.selenium超进阶 获取lol 所有装备名字 加入等待。 显示等待、隐式等待以及睡眠等待, 且使用selenium获取元素
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait# 1.浏览器的选项对象
options = webdriver.ChromeOptions()# 浏览器实例化
chrome = webdriver.Chrome()# 打开页面
chrome.get('https://lol.qq.com/data/info-item.shtml#Navi')# 1.隐式等待
# 设置全局元素等待超时时间20秒
#设置一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步,超出设置的时长20秒还没有定位到元素,则抛出异常。
# 缺点:程序会一直等待整个页面加载完成,直到超时,但有时候我需要的那个元素早就加载完成了,只是页面上有个别其他元素加载特别慢,我仍要等待页面全部加载完成才能执行下一步。
# 注意:对driver起作用,所以只要设置一次即可,没有必要到处设置
chrome.implicitly_wait(20)# 2.显式等待
# 最长等待时间
wait_obj = WebDriverWait(driver=chrome,timeout=10)
# 显示等待是明确提出要等什么, 在这里是等待#jSearchHeroDiv>li>a该标签的内容加载完毕
wait_obj.until(expected_conditions.element_to_be_clickable(chrome.find_element(By.CSS_SELECTOR,'#jSearchHeroDiv>li>a')))# 3.强制等待 from time import sleep
# 强制等待10秒再执行下一步。缺点:是不管资源是不是完成,都必须等待
sleep(10)# 使用selenium获取页面元素
items_tags_p = chrome.find_elements(By.CSS_SELECTOR,'#jSearchItemDiv>li>p')
for p in items_tags_p:print(p.text)chrome.close()
chrome.quit()4.爬取中国知网 数据挖掘第一篇论文的摘要
from selenium.webdriver import Chrome
from time import sleep
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
# 1.实例化 打开网页
b = Chrome()
b.get('https://www.cnki.net/')
sleep(5)# 2. 获取输入框
search_tag =b.find_element(By.ID,'txt_SearchText') # 按id找
search_tag.send_keys('数据挖掘\n') #自动往输入框中输入数据挖掘 并按回车sleep(10)# 3.获取所有结果的链接标签
all_results =b.find_elements(By.CSS_SELECTOR,'.result-table-list .name>a') # CSS# 点击第一个
all_results[0].click()
sleep(10)# 获取当前所有打开的窗口
all_window = b.window_handles
# 切换到最新打开的浏览器窗口,[-1]是最右边新的窗口
b.switch_to.window(all_window[-1])#使用bs4解析内容
soup = BeautifulSoup(b.page_source,'lxml')
result = soup.select_one('#ChDivSummary').text
print(result)input('end?')
b.close()
b.quit()相关文章:
)
week04day04(爬虫)
一. 嵌套构造URL 下载所有英雄的皮肤图片:因为每个英雄图片的网址不同,但是有共同点,通过构建这个网址,再经过循环建立 所有链接 import requests import os# 1. 获取所有英雄的ID def get_all_hero_id():url https://game.gti…...
【数据结构初阶 6】二叉树:堆的基本操作 + 堆排序的实现
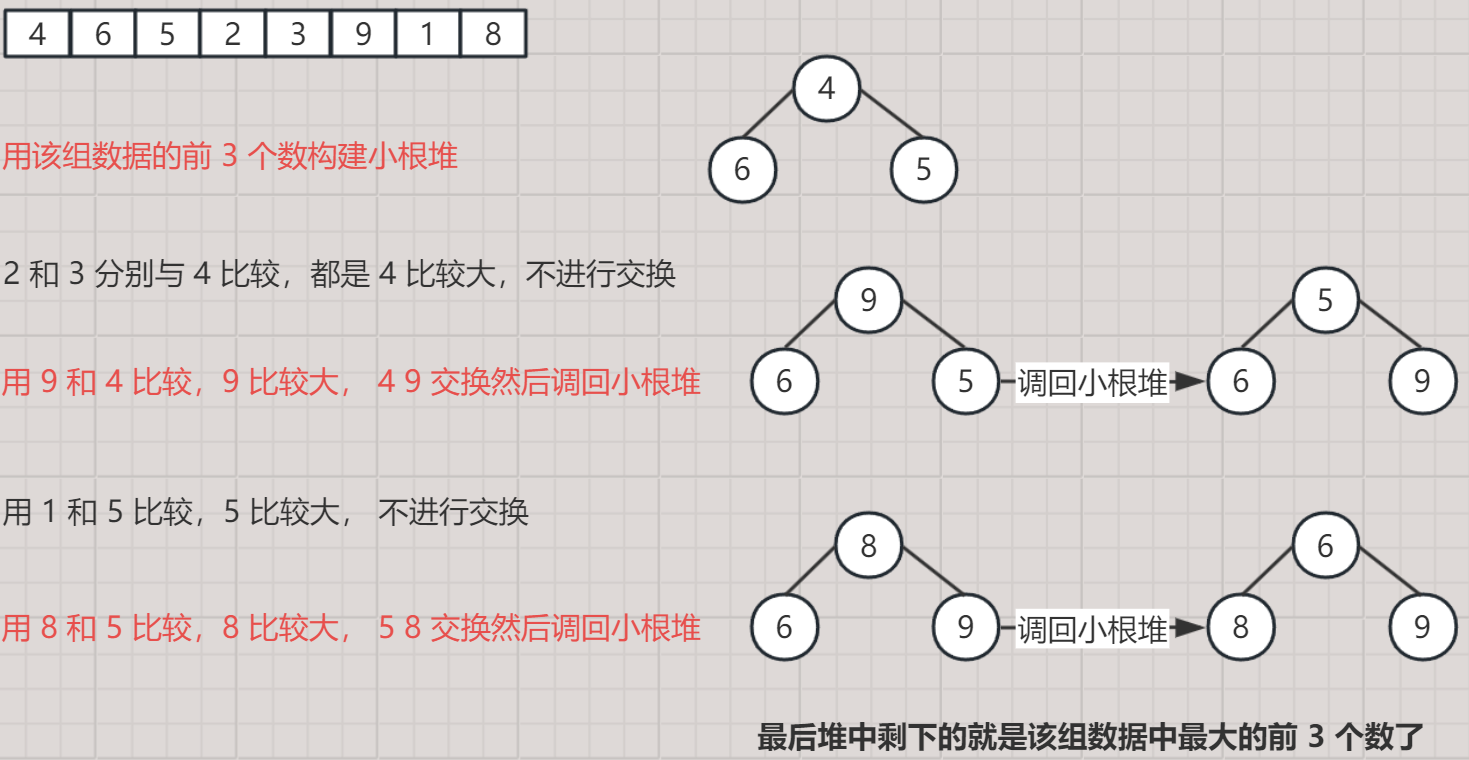
文章目录 🌈 Ⅰ 二叉树的顺序结构🌈 Ⅱ 堆的概念与性质🌈 Ⅲ 堆的基本操作01. 堆的定义02. 初始化堆03. 堆的销毁04. 堆的插入05. 向上调整堆06. 堆的创建07. 获取堆顶数据08. 堆的删除09. 向下调整堆10. 判断堆空 🌈 Ⅳ 堆的基本…...
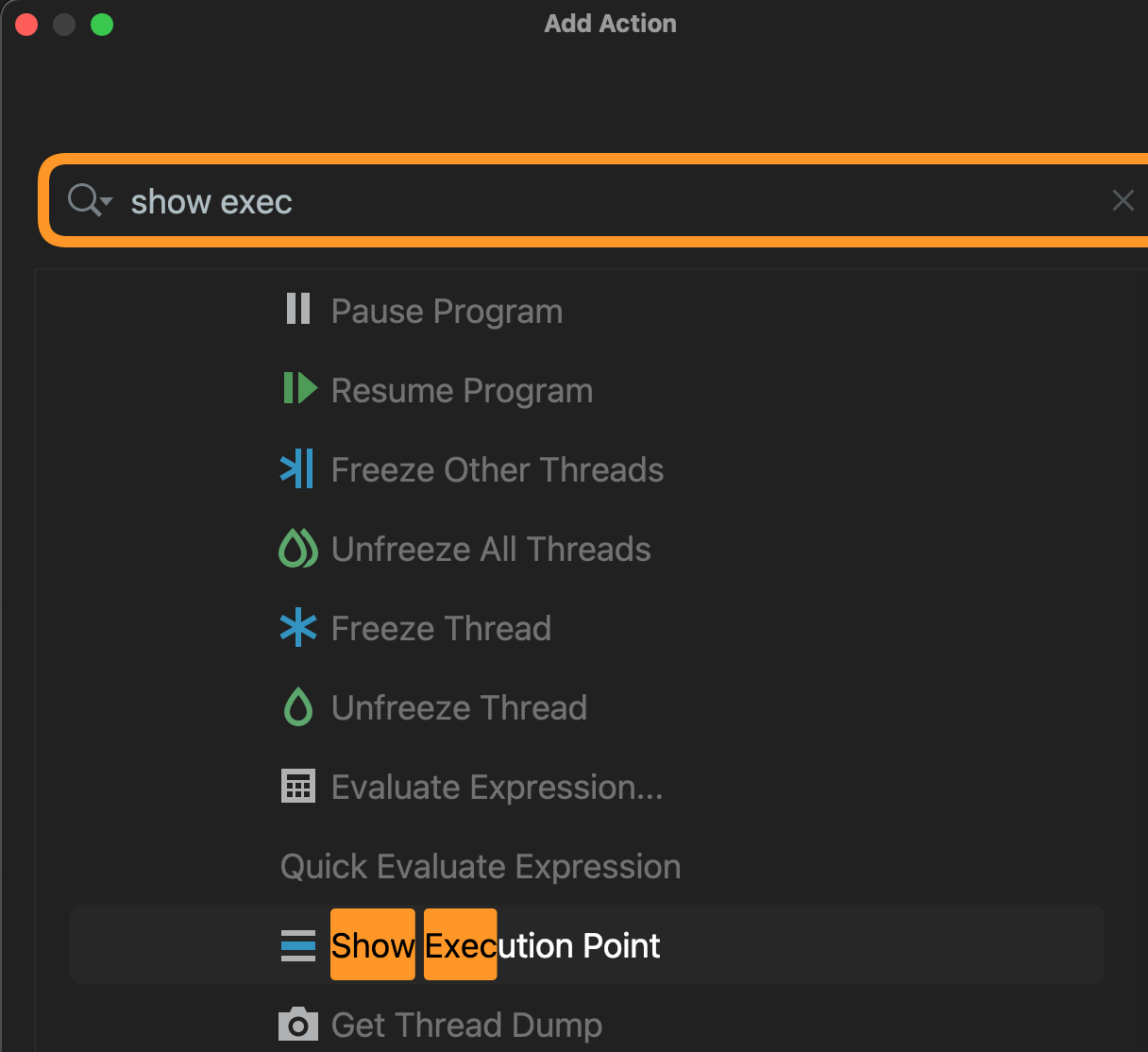
IDEA Debug框的 show execution point按钮没了
在这里右键: Add Action: 搜索添加: 本文由博客一文多发平台 OpenWrite 发布!...
))
突破编程_C++_面试(类(1))
面试题 1 :解释一下 C 中的类是什么,它有哪些基本特性? C 中的类(class)是面向对象程序设计的基本构成单位,它是一种自定义的数据类型,用于封装数据以及操作这些数据的方法。类是创建对象的模板…...

vue项目使用vue2-org-tree
实现方式 安装依赖 npm i vue2-org-tree使用的vue页面引入 <template><div class"container"><div class"oTree" ><vue2-org-tree name"test":data"data":horizontal"horizontal":collapsable"…...

Vue30 自定义指令 函数式 对象式
实例 <!DOCTYPE html> <html><head><meta charset"UTF-8" /><title>自定义指令</title><script type"text/javascript" src"../js/vue.js"></script></head><body><!-- 需求1&…...
JAVA高并发——单例模式和不变模式
文章目录 1、探讨单例模式2、不变模式 由于并行程序设计比串行程序设计复杂得多,因此我强烈建议大家了解一些常见的设计方法。就好像练习武术,一招一式都是要经过学习的。如果自己胡乱打,效果不见得好。前人会总结一些武术套路,对…...
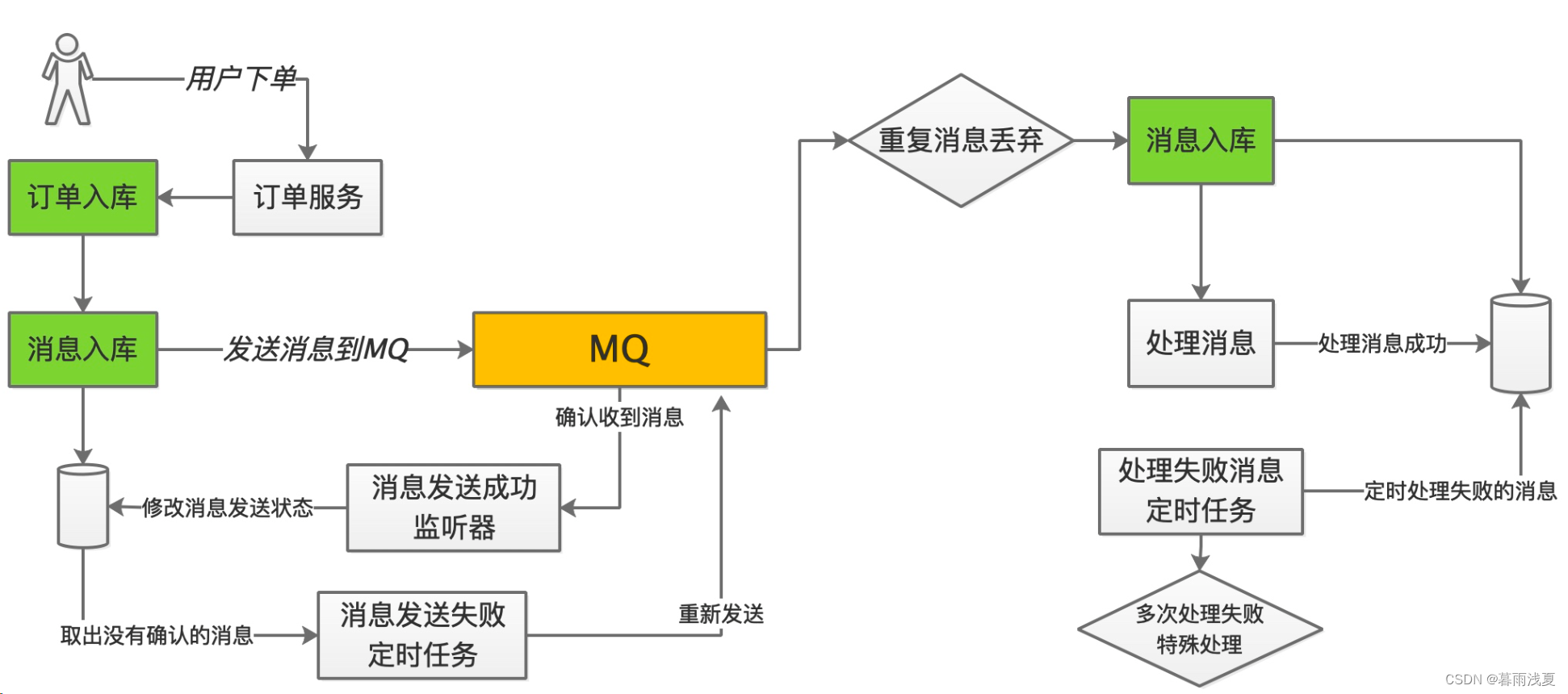
RabbitMQ(一):消息队列MQ
目录 1 消息队列MQ1.1 MQ简介1、什么是MQ2、MQ的优势流量削峰应用解耦异常处理数据分发分布式事务 3、消息中间件的弊端4、常用的MQ 1.2 MQ中几个基本概念1.3 MQ的通信模式1.4 消息的发布策略1.5 常用消息中间件协议1、AMQP协议2、MQTT协议3、OpenMessage协议4、kafaka协议 1 消…...
HarmonyOS—使用预览器查看应用/服务效果
DevEco Studio为开发者提供了UI界面预览功能,可以查看应用/服务的UI界面效果,方便开发者随时调整界面UI布局。预览器支持布局代码的实时预览,只需要将开发的源代码进行保存,就可以通过预览器实时查看应用/服务运行效果,…...

大项目中,某个cpp文件读取所在包路径的方法
在一个比较大的C项目中,我们有很多包,每个包都有一个自己的src、include、CMakeLists.txt和其它文件,比如以下文件结构: project- pkg1- datas- data.json- src- xxx1.cpp- include- xxx1.h - CMakeLists.txt- pkg2- src- xxx2.…...
:用于异构SoC的片上网络模型——Garnet2.0)
gem5学习(25):用于异构SoC的片上网络模型——Garnet2.0
目录 一、Invocation 二、Configuration 三、Topology 四、Routing 五、Flow Control 六、Router Microarchitecture 七、Buffer Management 八、Lifecycle of a Network Traversal 九、Running Garnet2.0 with Synthetic Traffic 官网教程:gem5: Garnet 2…...
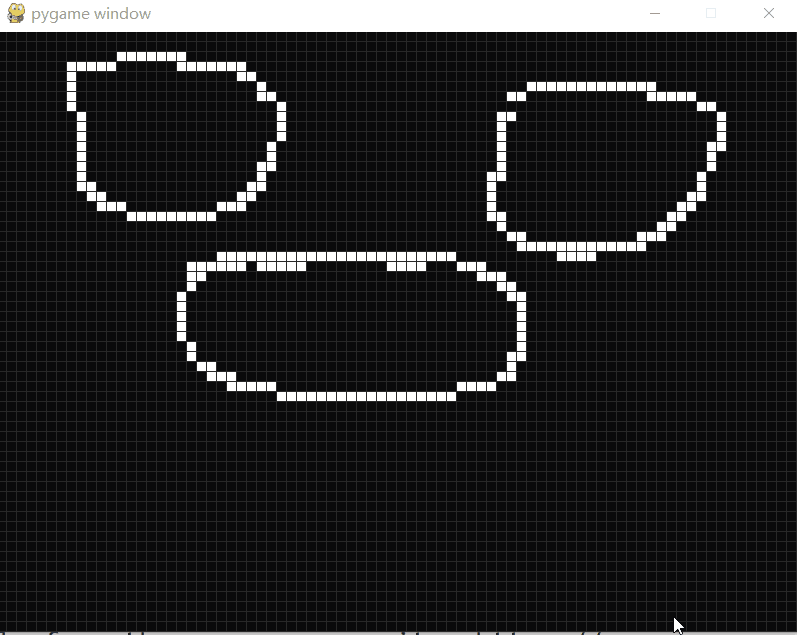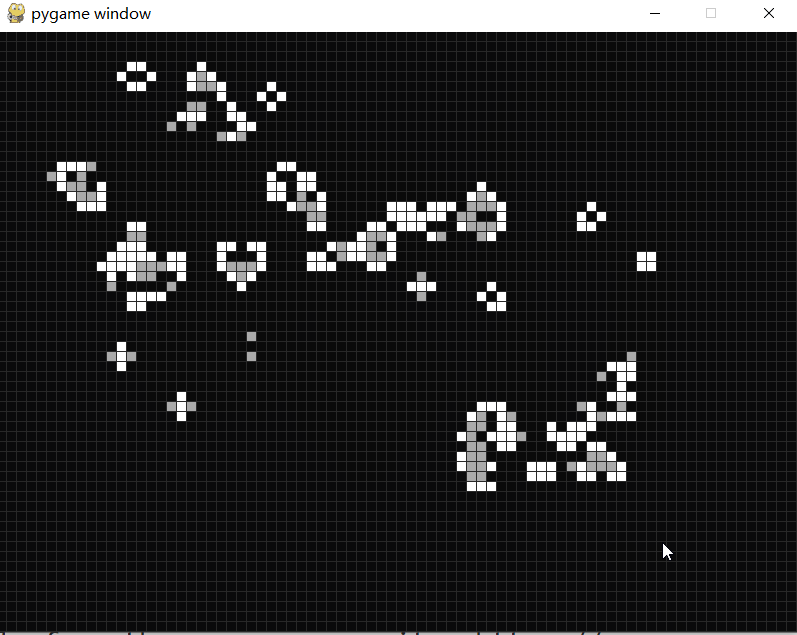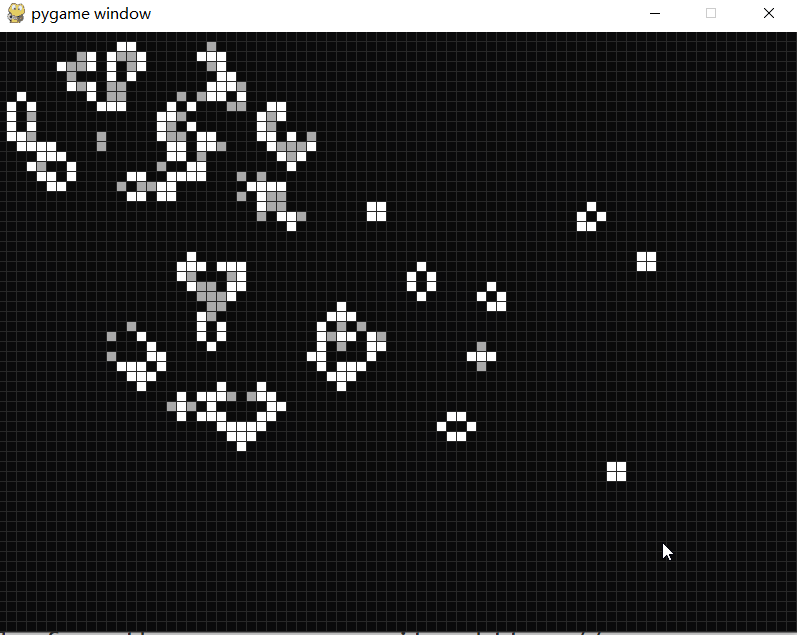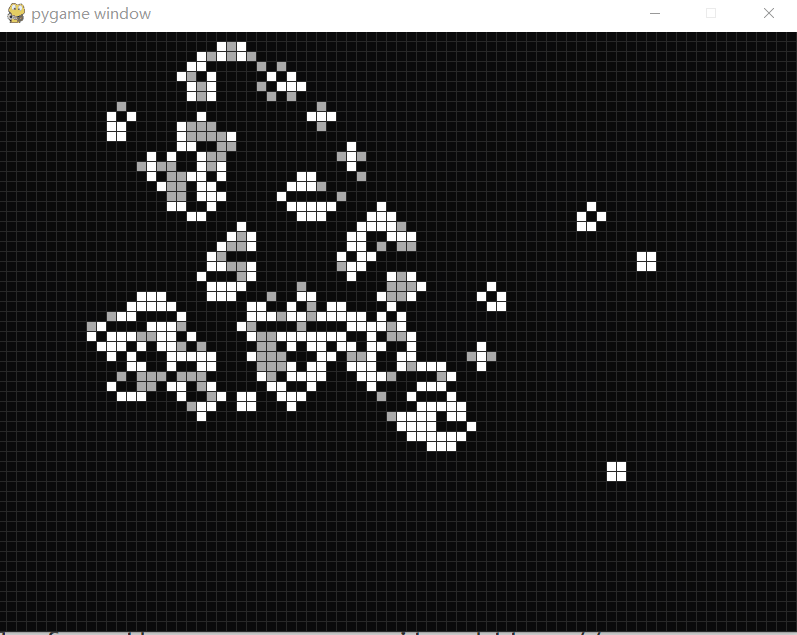
康威生命游戏
康威生命游戏 康威生命游戏(Conway’s Game of Life)是康威发明的细胞自动机。 生命游戏有几个简单的规则: 细胞有两种状态,存活或死亡,每个细胞以自身为中心与周围的八格细胞互动。 对于存活的细胞: 当周围的细胞过少(<2)或…...

vscode与vue环境配置
一、下载并安装VScode 安装VScode 官网下载 二、配置node.js环境 安装node.js 官网下载 会自动配置环境变量和安装npm包(npm的作用就是对Node.js依赖的包进行管理),此时可以执行 node -v 和 npm -v 分别查看node和npm的版本号: 配置系统变量 因为在执…...
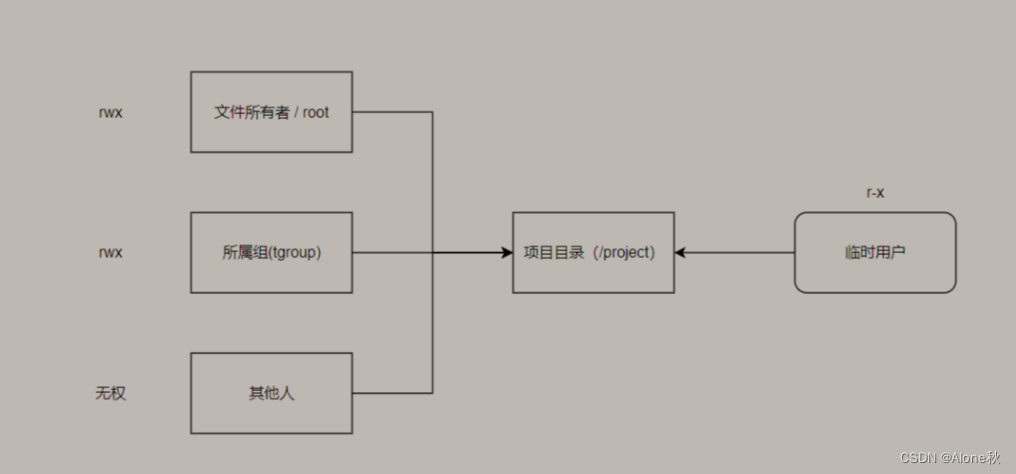
Linux的ACL权限以及特殊位和隐藏属性
前言: ACL是什么? ACL(Access Control List)是一种权限控制机制,用于在Linux系统中对文件和目录进行细粒度的访问控制。传统的Linux权限控制机制基于所有者、所属组和其他用户的三个权限类别(读、写、执行…...
使用openai-whisper实现语音转文字
使用openai-whisper实现语音转文字 1 安装依赖 1.1 Windows下安装ffmpeg FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。 # ffmpeg官网 https://ffm…...

C++模板为什么不能声明和定义分离
首先我们要直到C程序运行需要进行的四个阶段。 预处理->编译->汇编->链接 编译:对语法语义分析,分析无误生成汇编,头文件不参加编译,多个源文件是分开单独编译的。 链接:将多个obj文件链接合成一个&#x…...
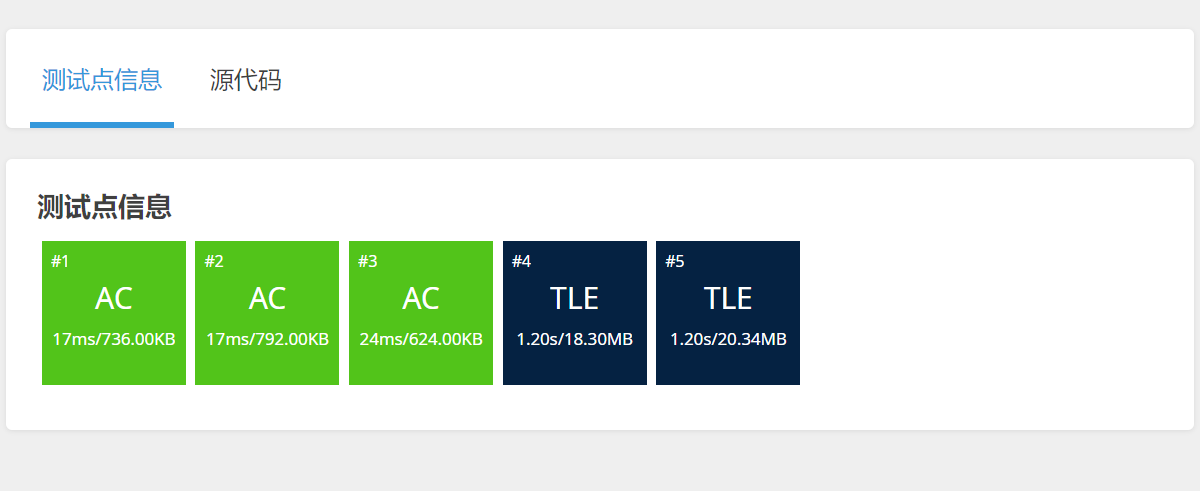
啊丢的刷题记录手册
1.洛谷题P1923 求第k小的数 题目描述 输入 n(1≤n<5000000 且 n 为奇数)个数字ai(1≤ai<109),输出这些数字的第 k 小的数。最小的数是第 0 小。 请尽量不要使用 nth_element 来写本题,因为本题…...

用nginx正向代理https网站
目录 1. 缘起2. 部署nginx3. 测试3.1 http测试3.2 https测试4 给centos设置代理访问外网 1. 缘起 最近碰到了一个麻烦事情,就是公司的centos测试服务器放在内网环境,而且不能直接上外网,导致无法通过yum安装软件,非常捉急。 幸…...

面向对象设计模式
一、单例 一个类只能创建唯一一个对象 利用限制构造、static完成 二、工厂模式 优势:规范接口(纯虚函数);实现多态(虚函数表);继承 1、简单工厂 一个工厂创建所有产品。 返回基类指针可…...

人工智能_CPU微调ChatGLM大模型_使用P-Tuning v2进行大模型微调_007_微调_002---人工智能工作笔记0102
这里我们先试着训练一下,我们用官方提供的训练数据进行训练. 也没有说使用CPU可以进行微调,但是我们先执行一下试试: https://www.heywhale.com/mw/project/6436d82948f7da1fee2be59e 可以看到说INT4量化级别最低需要7GB显存可以启动微调,但是 并没有说CPU可以进行微调.我们…...

第一章 微信小程序概述与开发准备
第一章 微信小程序概述与开发准备 📚 系列教程:微信小程序投票系统完整开发 🔗 上一章:无 🔗 下一章:第二章 - 小程序目录结构与核心文件详解 1.1 什么是微信小程序 微信小程序(Mini Program&a…...

LLM函数调用工程化:从基础概念到智能体框架设计实战
1. 项目概述:从“函数调用”到智能体交互的范式演进最近在GitHub上看到一个名为“SKY-lv/function-calling”的项目,这个标题乍一看平平无奇,甚至有些过于直白。但作为一名长期混迹在AI应用开发一线的工程师,我立刻嗅到了一丝不寻…...

基于Git与Zenn的内容管理方案:打造高效技术写作工作流
1. 项目概述:一个内容创作者的知识管理中枢 最近在技术社区里,看到不少朋友在讨论如何高效地管理自己的技术笔记、博客草稿和项目文档。我自己也在这个问题上摸索了很久,直到我遇到了一个名为 seiryuu1215/zenn-content 的GitHub仓库。这不…...

OpenCore Legacy Patcher技术揭秘:4步实现老旧Mac硬件兼容性修复与系统升级
OpenCore Legacy Patcher技术揭秘:4步实现老旧Mac硬件兼容性修复与系统升级 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 在苹果生态系统中&…...

Spider2-V:多模态AI智能体框架,连接LLM与GUI自动化的工程实践
1. 项目概述:一个面向开发者的多模态智能体框架 最近在AI应用开发圈子里,一个名为“Spider2-V”的项目引起了我的注意。它不是一个简单的聊天机器人,也不是一个孤立的图像识别模型,而是一个旨在将大型语言模型(LLM&…...

QT开发避坑指南:用setWindowFlags搞定自定义标题栏,别再为窗口移动发愁了
QT自定义标题栏实战:从事件重写到优雅封装的完整解决方案 当开发者决定为QT应用打造一套独特的视觉风格时,第一个拦路虎往往是系统默认标题栏的去除与自定义实现。这看似简单的需求背后,隐藏着窗口管理、事件处理、用户体验等一系列技术挑战。…...

Pearcleaner深度清理工具:为你的Mac找回丢失的存储空间
Pearcleaner深度清理工具:为你的Mac找回丢失的存储空间 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经计算过,那些看似已…...

RK3588核心板赋能无人机智能飞控:异构计算与AI视觉实践
1. 项目概述:当高性能核心板遇上无人机最近在折腾一个挺有意思的项目,核心是把一块高性能的核心板——迅为的RK3588,塞进无人机里,让它成为飞控大脑。这听起来可能有点“大材小用”,毕竟RK3588这玩意儿算力不低&#x…...

实景复刻:动态目标实时映射与轨迹溯源平台
实景复刻:动态目标实时映射与轨迹溯源平台技术定位:实景动态复刻体系构建者 时空轨迹全链路溯源范式开创者执行摘要在数字孪生、视频孪生从静态可视化向动态可计算演进的关键阶段,物理世界与数字世界时空不同步、虚实不精准、动态不连续、轨…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...