【GPT-2】论文解读:Language Models are Unsupervised Multitask Learners
文章目录
- 介绍
- zero-shot learning 零样本学习
- 方法
- 数据
- Input Representation
- 结果
论文:Language Models are Unsupervised Multitask Learners
作者:Alec Radford, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, I. Sutskever
时间:2019
介绍
GPT-2 是一个有15亿参数的模型,GPT-2的想法是转向一个通用的系统,不需要进行数据集的标注就可以执行许多的任务;
因为数据集的创建是很难的,我们很难继续将数据集的创建和目标的设计扩大到可能需要用现有的技术推动我们前进的程度。这促使我们去探索执行多任务学习的额外设置。
当前性能最好的语言模型系统是通过预训练模型和微调完成的,预训练主要是自注意力模块去识别字符串的语意,而微调主要是通过语意去得出不同的结果;这样一来,我们在执行不同的任务时,只需要替换掉微调的那部分结构就可以;
而GPT-2证实了语言模型能够在不进行任何参数和结构修改的情况下,拥有执行下游任务的能力,这种能力获取的主要方式是强化语言模型的 zero-shot
zero-shot learning 零样本学习

零样本学习也叫ZSL,通俗来讲就是说在训练集中并没有出现的y能够在测试集中识别出来;当然,如果不做任何处理我们是无法识别的,我们需要没有出现的y的信息来帮助我们识别y;通过上面的图我们可以知道,horse和donkey可以得出horselike,tiger和hyena可以得出stripe,penguin和panda 可以得出 black and white,这里我们可以通过zebra的描述信息可以得出horselike,stripe,black and white 的动物是斑马来训练模型,这样我们可以在测试集的时候识别出斑马;
这里有两篇比较详细的介绍:
零次学习(Zero-Shot Learning)入门 (zhihu.com)
零次学习(Zero-Shot Learning) - 知乎 (zhihu.com)
方法
首先介绍一下语言模型:
p ( x ) = p ( s 1 , s 2 , … , s n ) = ∏ i = 1 n p ( s n ∣ s 1 , … , s n − 1 ) p(x)=p(s_1,s_2,\dots,s_n)=\prod_{i=1}^{n}p(s_n|s_1,\dots,s_{n-1}) p(x)=p(s1,s2,…,sn)=i=1∏np(sn∣s1,…,sn−1)
其中 x x x是句子, s 1 , s 2 , … , s n s_1,s_2,\dots,s_n s1,s2,…,sn 组成句子可能出现的词;
在经过预训练之后,我们在执行特定的任务时,我们需要对特定的输入有特定的输出,这时模型就变成了 p ( o u t p u t ∣ i n p u t ) p(output|input) p(output∣input) ;为了让模型更一般化,能执行不同的任务,我们需要对模型继续进行处理,变成了 p ( o u t p u t ∣ i n p u t , t a s k ) p(output|input, task) p(output∣input,task) ;
这样一来,我们需要对数据框架的形式进行一定的修改,如翻译任务我们可以写为
translate to french, english text , french text
阅读理解任务可以写为
answer the question, document, question, answer
语言模型在原则上来说是可以利用上面的框架进行无监督学习训练的;在训练过程中,由于最终的评价方式是一致的,所以监督学习和无监督学习的目标函数是一样的;唯一不同的是监督学习是在子集上进行评估损失,而无监督学习是在全局上评估损失,综合来说对全局不产生影响,因此无监督学习损失的全局最小值和有监督学习损失的全局最小值是一致的;
论文进行初步实验证实,足够多参数的模型能够在这种无监督训练方式中学习,但是学习要比有监督学习收敛要慢得多;
作者认为,对于有足够能力的语言模型来说,模型能够以某种方式识别出语言序列中的任务并且能够很好的执行它,如果语言模型能够做到这一点,那么就是在高效的执行无监督多任务学习;
数据
由于是多任务模型,需要构建尽可能大的和多样化的数据集,这里作者采用的是网络爬虫的方式进行解决;为了避免文档质量不高,这里只采集了经过人类策划/过滤后的网页,手动过滤是困难的,所以作者只采集了Reddit社交平台上信息;最后生成的数据集包含了4500万个链接的文本子集;文本是通过Dragnet 和 newspaper进行提取的,经过重复数据删除和一些启发式的清理,该链接包含近800万文档,共计40GB文本,并且删除了所有的维基百科文档,因为它是其他数据集的通用数据源,并且可能会由于过度-而使分析复杂化;
Input Representation
这里采用的是BPE编码方式,具体在[BPE]论文实现:Neural Machine Translation of Rare Words with Subword Units-CSDN博客可以详细了解;
结果
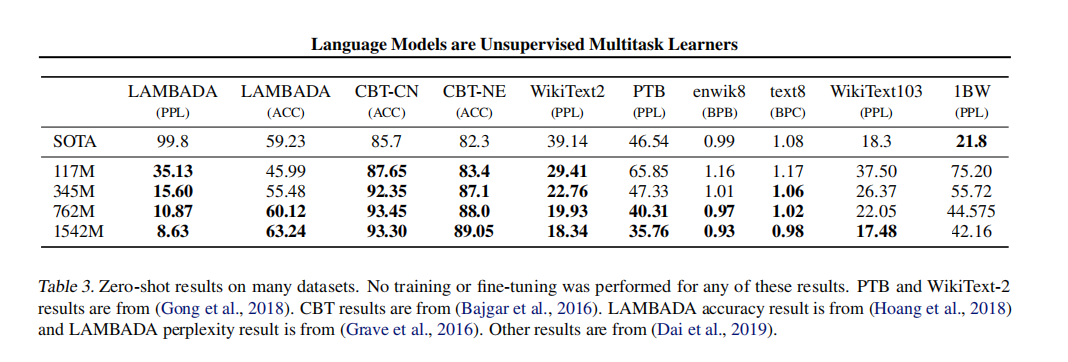
这里有ACC,PPL,BPC,BPB 四个指标:
详细可以看这篇文章:困惑度(perplexity)的基本概念及多种模型下的计算(N-gram, 主题模型, 神经网络) - 知乎 (zhihu.com)
ACC 指的是准确度: A C C = T P + T N T P + T N + F P + F N ACC=\frac{TP+TN}{TP+TN+FP+FN} ACC=TP+TN+FP+FNTP+TN
介绍后面的指标之前需要先介绍一下Cross entropy也就是交叉熵: H ( P , Q , s ) = − ∑ i = 1 n P ( x i ) l n Q ( x i ) H(P,Q,s)=-\sum_{i=1}^n P(x_i)lnQ(x_i) H(P,Q,s)=−i=1∑nP(xi)lnQ(xi)
这里P指的是真实概率,Q指的是预测概率, x i x_i xi指的是每一个unit,而s由n个unit的 x i x_i xi组成,这里表示s这一句话的交叉熵;
PPL 指的是困惑度,也就是一句话出现的概率,句子出现的概率越大,困惑度越小: P P L = P ( x 1 , x 2 , … , x n ) − 1 N PPL=P(x_1,x_2,\dots,x_n)^{-\frac{1}{N}} PPL=P(x1,x2,…,xn)−N1
BPC,BPW和BPB 分别指的是bits-per-character, bits-per-word,bits-per-byte: B P C / B P W / B P B = 1 T ∑ t = 1 T H ( P , Q , s t ) BPC/BPW/BPB=\frac{1}{T}\sum_{t=1}^{T}H(P,Q,s_t) BPC/BPW/BPB=T1t=1∑TH(P,Q,st)
其不同就是在计算H的时候计算的分别是character,word,byte;主要在于分词;
由于PPL中P的特殊性,只有一个1,其余都是0,有公式如下:
B P C = − 1 T ∑ t = 1 T ∑ i = 1 n P ( c t i ) l n Q ( c t i ) = − 1 T ∑ t = 1 T l n Q ( s t ) = − 1 T l n P ( d o c u m e n t ) = l n P P L \begin{align} BPC & = -\frac{1}{T}\sum_{t=1}^T\sum_{i=1}^{n}P(c_{ti})lnQ(c_{ti}) \\ & = -\frac{1}{T}\sum_{t=1}^TlnQ(s_t) \\ & = -\frac{1}{T}lnP(document) \\ & = lnPPL \end{align} BPC=−T1t=1∑Ti=1∑nP(cti)lnQ(cti)=−T1t=1∑TlnQ(st)=−T1lnP(document)=lnPPL
即有: P P L = e B P C PPL=e^{BPC} PPL=eBPC
从上图中可以看出GPT-2都表现出了不错的性能;
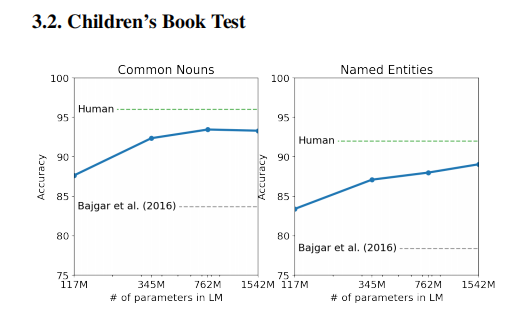
同时在儿童读物测试中 随着参数量的增加,性能都出现了一定的增强;
还有一些结果证实了无标注训练模型的能力,这里就不展示了,这篇文章证明了当一个大型语言模型在一个足够大和多样化的数据集上进行训练时,它能够在许多领域和数据集上表现良好。
相关文章:
【GPT-2】论文解读:Language Models are Unsupervised Multitask Learners
文章目录 介绍zero-shot learning 零样本学习 方法数据Input Representation 结果 论文:Language Models are Unsupervised Multitask Learners 作者:Alec Radford, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, I. Sutskever 时间:2019 介…...
基于机器学习、遥感和Penman-Monteith方程的农田蒸散发混合模型研究_刘燕_2022
基于机器学习、遥感和Penman-Monteith方程的农田蒸散发混合模型研究_刘燕_2022 摘要关键词 1 绪论2 数据与方法2.1 数据2.2 机器学习算法2.3 Penman-Monteith方程2.4 Medlyn公式2.5 模型性能评估 3 基于机器学习算法的混合模型估算农田蒸散量的评价与比较4 利用人工神经网络算法…...
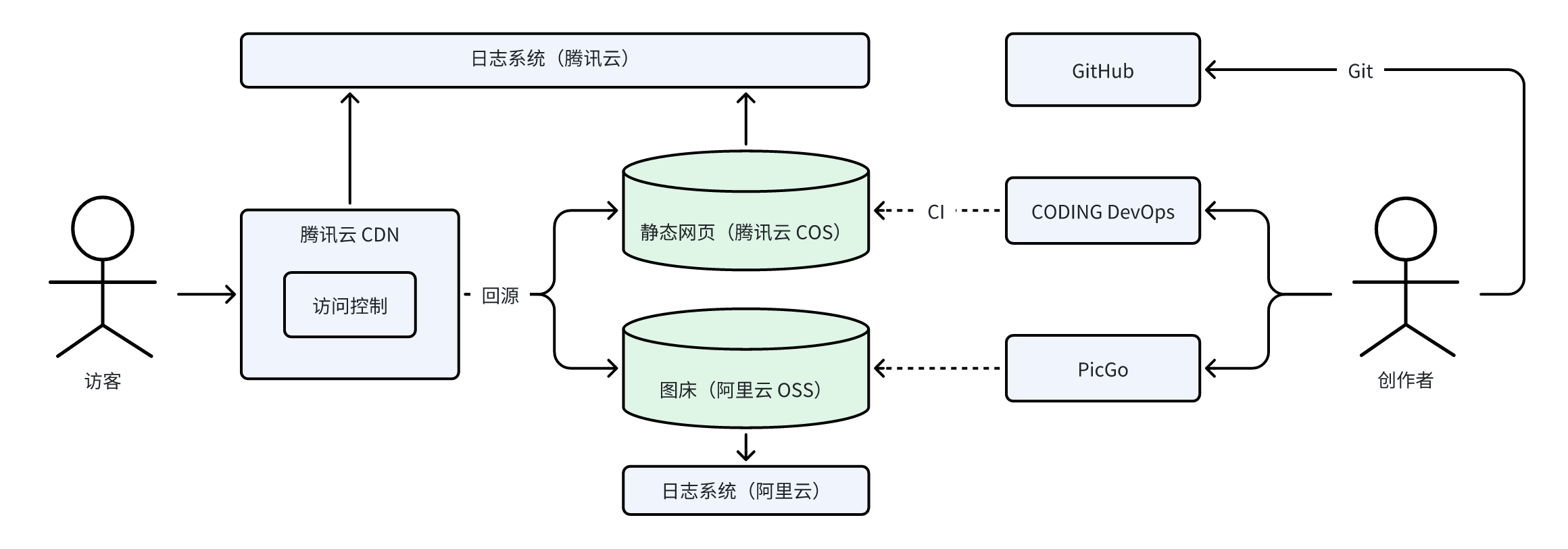
博客 cn 站搭建 v3 v3.1
1. 架构设计 v3.1 版本 2. v2.x 存在的痛点 在v2.x版本中,围绕 服务器 遇到了两个主要的问题: 服务器成本高:博客以静态页面为主,理论上可以实现无服务器部署,但是为了防止恶意攻击,不得不使用服务器进…...
2024全国水科技大会暨流域水环境治理与水生态修复论坛(六)
论坛召集人 冯慧娟 中国环境科学研究院流域中心研究员 刘 春 河北科技大学环境与工程学院院长、教授 一、会议背景 为深入贯彻“山水林田湖是一个生命共同体”的重要指示精神,大力实施生态优先绿色发展战略,积极践行人、水、自然和谐共生理念&…...

Python实战:读取MATLAB文件数据(.mat文件)
Python实战:读取MATLAB文件数据(.mat文件) 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程 👈 希望得到您的订阅…...
spring boot3登录开发-3(账密登录逻辑实现)
⛰️个人主页: 蒾酒 🔥系列专栏:《spring boot实战》 🌊山高路远,行路漫漫,终有归途。 目录 前置条件 内容简介 用户登录逻辑实现 创建交互对象 1.创建用户登录DTO 2.创建用户登录VO 创建自定义登录业务异…...

Django后端开发——ORM
文章目录 参考资料ORM-基础字段及选项字段类型练习——添加模型类应用bookstore下的models.py数据库迁移——同步至mysqlmysql中查看效果字段选项Meta类定义示例:改表名应用bookstore下的models.py终端效果练习——改表名+字段选项修改应用bookstore下的models.py终端效果ORM基…...

AI模型训练的初步整理
明天会有人来给我们讲AI方面的课,我也一直想整理一下这方面的知识,今天也趁着这个机会做一下功课,算是预习。 首先,AI的模型训练可以分为: 增量学习(Incremental Learning) 增量学习允许模型在…...
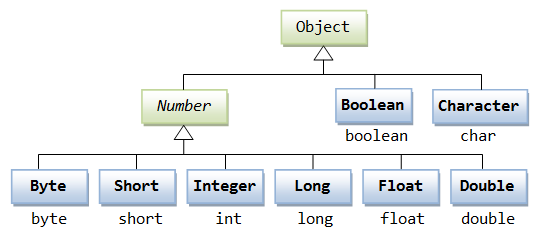
【Java从入门到精通】Java Number Math 类
Java Number & Math 类 一般地,当需要使用数字的时候,我们通常使用内置数据类型,如:byte、int、long、double 等。 实例 int a 5000; float b 13.65f; byte c 0x4a; 然而,在实际开发过程中,我们…...
SQL字符集
目标:了解字符集的概念,掌握MySQL数据库存储数据的字符集逻辑以及设置方式 字符集概念 MySQL字符集关系 解决乱码问题 字符集设置原理 1、字符集概念 目标:了解字符集概念,掌握字符集存储和读取的实现原理 概念 字符集:charset或者character set&am…...
openssl 生成nginx自签名的证书
1、命令介绍 openssl req命令主要的功能有,生成证书请求文件, 查看验证证书请求文件,还有就是生成自签名证书。 主要参数 主要命令选项: -new :说明生成证书请求文件 -x509 :说明生成自签名证书 -key :指定已…...

adb push 使用
adb push命令用于将文件从本地计算机推送到Android设备。要使用adb push命令,需要先连接Android设备并启动ADB调试模式。以下是使用adb push命令的基本步骤: 打开终端(命令提示符)。 使用cd命令导航到存储要推送文件的文件夹。 …...

【Docker】构建pytest-playwright镜像并验证
Dockerfile FROM ubuntu LABEL maintainer "langhuang521l63.com" ENV TZAsia/Shanghai #设置时区 #安装python3依赖与下载安装包 RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone \&& apt update \&&…...

算法沉淀——穷举、暴搜、深搜、回溯、剪枝综合练习四(leetcode真题剖析)
算法沉淀——穷举、暴搜、深搜、回溯、剪枝综合练习四 01.解数独02.单词搜索03.黄金矿工04.不同路径 III 01.解数独 题目链接:https://leetcode.cn/problems/sudoku-solver/ 编写一个程序,通过填充空格来解决数独问题。 数独的解法需 遵循如下规则&am…...

如何在java中使用 Excel 动态函数生成依赖列表
前言 在Excel 中,依赖列表或级联下拉列表表示两个或多个列表,其中一个列表的项根据另一个列表而变化。依赖列表通常用于Excel的业务报告,例如学术记分卡中的【班级-学生】列表、区域销售报告中的【区域-国家/地区】列表、人口仪表板中的【年…...

07 MyBatis之高级映射 + 懒加载(延迟加载)+缓存
1. 高级映射 例如有两张表, 分别为班级表和学生表 自然, 一个班级对应多个学生 像这种数据 , 应该如果如何映射到Java的实体类上呢? 这就是高级映射解决的问题 以班级和学生为例子 , 因为一个班级对应多个学生 , 因此学生表中必定有一个班级编号字段cid 但我们在学生的实体…...

MT8791迅鲲900T联发科5G安卓核心板规格参数_MTK平台方案定制
MT8791安卓核心板是一款搭载了旗舰级配置的中端手机芯片。该核心板采用了八核CPU架构设计,但是升级了旗舰级的Arm Cortex-A78核心,两个大核主频最高可达2.4GHz。配备了Arm Mali-G68 GPU,通过Mali-G88的先进技术,图形处理性能大幅提…...

java:Java中的数组详解
目录 Java数组的定义和特点: Java数组的初始化和赋值 Java数组的常用操作 1. 遍历数组 2. 获取数组长度 3. 访问数组元素 4. 数组的拷贝 多维数组 数组的排序和查找 冒泡排序: 快速排序 : 二分查找: 数组的应用: Java数…...

Modern C++ std::visit从实践到原理
前言 std::visit 是 C17 中引入的一个模板函数,它用于对给定的 variant、union 类型或任何其他兼容的类型执行一个访问者操作。这个函数为多种可能类型的值提供了一种统一的访问机制。使用 std::visit,你可以编写更通用和灵活的代码,而无需关…...

谷歌gemma2b windows本地cpu gpu部署,pytorch框架,模型文件百度网盘下载
简介 谷歌DeepMind发布了Gemma,这是一系列灵感来自用于Gemini相同研究和技术的开放模型。开放模型适用于各种用例,这是谷歌非常明智的举措。有2B(在2T tokens上训练)和7B(在6T tokens上训练)模型,包括基础和指令调整版本。在8192个token的上下文长度上进行训练。允许商业使…...
)
遥感图像处理实战:用eCognition多尺度分割搞定地物分类(附样本点与特征提取全流程)
遥感图像智能解译实战:eCognition多尺度分割与地物分类全流程解析 清晨的阳光透过窗帘缝隙洒在桌面上,我打开最新接收的卫星影像——这是一片混合了城市建筑、绿地和农田的复杂区域。作为遥感分析师,我们每天面对的都是这样充满信息量的图像&…...

从Halo部署到公网访问:手把手教你用Nginx反代搞定域名、HTTPS与安全配置
从Halo部署到公网访问:Nginx反代全流程实战指南 当你成功在本地服务器上部署了Halo博客系统,看着8080端口的测试页面时,是否思考过如何让它成为真正的互联网站点?本文将带你跨越从本地测试到公网可访问的最后一道鸿沟,…...

为什么MIT化学系要求博士生必学NotebookLM?——解密其在NMR谱图关联推理与副产物预测中的3个未公开API调用逻辑
更多请点击: https://intelliparadigm.com 第一章:NotebookLM化学研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为深度阅读、知识整合与推理设计。在化学研究场景中,它能高效解析 PDF 格式的文献(如 …...

5分钟快速上手:Proxmark3GUI图形界面终极指南
5分钟快速上手:Proxmark3GUI图形界面终极指南 【免费下载链接】Proxmark3GUI A cross-platform GUI for Proxmark3 client | 为PM3设计的跨平台图形界面 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmark3GUI 对于RFID技术初学者来说,Proxm…...
)
CVPR投稿后,我是如何用一篇高质量的Rebuttal说服审稿人的(附真实邮件模板)
CVPR投稿后,我是如何用一篇高质量的Rebuttal说服审稿人的(附真实邮件模板) 在计算机视觉领域的顶级会议CVPR投稿过程中,Rebuttal环节往往成为决定论文命运的关键转折点。许多研究者花费数月精心打磨论文,却在收到审稿意…...

吴哥窟水文测试:验证古代水库管理AI的智慧
一、从古代水利到现代AI测试的跨越吴哥窟,这座位于柬埔寨的古代都城遗址,以其宏伟的寺庙建筑群闻名于世。然而,鲜为人知的是,支撑这座城市繁荣数百年的,是一套复杂而精密的水管理系统。这套建于9至13世纪的水利工程&am…...

NotebookLM脑机接口安全红线清单,3类合规风险已致2家医疗AI公司终止临床试验
更多请点击: https://intelliparadigm.com 第一章:NotebookLM脑机接口研究 NotebookLM 是 Google 推出的基于用户自有文档进行深度理解与推理的 AI 助手,其核心能力在于语义锚定(semantic grounding)与多源文档交叉推…...

为Claude Code配置Taotoken作为备用API服务商防止中断
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken作为备用API服务商防止中断 当您依赖Claude Code作为编程助手时,可能会遇到服务暂时不可用或…...

ComfyUI ControlNet Aux:AI绘画精准控制的终极解决方案
ComfyUI ControlNet Aux:AI绘画精准控制的终极解决方案 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Aux是一个强大的AI…...

DDR的硬件拓扑与ODT匹配技术
前言 本文覆盖DDR信号时延偏差成因、DDR1~DDR5历代核心差异、全代ODT阻值/挂载总线/控制逻辑、多颗粒组网ODT启闭规则、主控有无片内ODT、末端反射影响、反射波回流泄放逻辑、DDR2地址控制线无ODT原因、DQ与CA拓扑严格区分、T型/Fly-by拓扑终端匹配方案、读写匹配不对称底层硬件…...