【深度学习笔记】3_2线性回归的从零实现
注:本文为《动手学深度学习》开源内容,仅为个人学习记录,无抄袭搬运意图
3.2 线性回归的从零开始实现
在了解了线性回归的背景知识之后,现在我们可以动手实现它了。尽管强大的深度学习框架可以减少大量重复性工作,但若过于依赖它提供的便利,会导致我们很难深入理解深度学习是如何工作的。因此,本节将介绍如何只利用Tensor和autograd来实现一个线性回归的训练。
首先,导入本节中实验所需的包或模块,其中的matplotlib包可用于作图,且设置成嵌入显示。
%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
3.2.1 生成数据集
我们构造一个简单的人工训练数据集,它可以使我们能够直观比较学到的参数和真实的模型参数的区别。设训练数据集样本数为1000,输入个数(特征数)为2。给定随机生成的批量样本特征 X ∈ R 1000 × 2 \boldsymbol{X} \in \mathbb{R}^{1000 \times 2} X∈R1000×2,我们使用线性回归模型真实权重 w = [ 2 , − 3.4 ] ⊤ \boldsymbol{w} = [2, -3.4]^\top w=[2,−3.4]⊤ 和偏差 b = 4.2 b = 4.2 b=4.2,以及一个随机噪声项 ϵ \epsilon ϵ 来生成标签
y = X w + b + ϵ \boldsymbol{y} = \boldsymbol{X}\boldsymbol{w} + b + \epsilon y=Xw+b+ϵ
其中噪声项 ϵ \epsilon ϵ 服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰。下面,让我们生成数据集。
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),dtype=torch.float32)
注意,features的每一行是一个长度为2的向量,而labels的每一行是一个长度为1的向量(标量)。
print(features[0], labels[0])
输出:
tensor([0.8557, 0.4793]) tensor(4.2887)
通过生成第二个特征features[:, 1]和标签 labels 的散点图,可以更直观地观察两者间的线性关系。
def use_svg_display():# 用矢量图显示display.set_matplotlib_formats('svg')def set_figsize(figsize=(3.5, 2.5)):use_svg_display()# 设置图的尺寸plt.rcParams['figure.figsize'] = figsize# # 在../d2lzh_pytorch里面添加上面两个函数后就可以这样导入
# import sys
# sys.path.append("..")
# from d2lzh_pytorch import * set_figsize()
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
这里导入可能会报错,可综合参考解决No module named ‘torchtext’ 有大坑以及李沐动手学深度学习pytorch :问题:找不到d2l包,No module named ‘d2l’,还要注意python版本的关系,建议使用创建虚拟环境直接下载对应版本的包
我们将上面的plt作图函数以及use_svg_display函数和set_figsize函数定义在d2lzh_pytorch包里。以后在作图时,我们将直接调用d2lzh_pytorch.plt。由于plt在d2lzh_pytorch包中是一个全局变量,我们在作图前只需要调用d2lzh_pytorch.set_figsize()即可打印矢量图并设置图的尺寸。
原书中提到的
d2lzh里面使用了mxnet,改成pytorch实现后本项目统一将原书的d2lzh改为d2lzh_pytorch。
3.2.2 读取数据
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它每次返回batch_size(批量大小)个随机样本的特征和标签。
# 本函数已保存在d2lzh包中方便以后使用
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))random.shuffle(indices) # 样本的读取顺序是随机的for i in range(0, num_examples, batch_size):j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batchyield features.index_select(0, j), labels.index_select(0, j)
让我们读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输入个数;标签形状为批量大小。
batch_size = 10for X, y in data_iter(batch_size, features, labels):print(X, y)break
输出:
tensor([[-1.4239, -1.3788],[ 0.0275, 1.3550],[ 0.7616, -1.1384],[ 0.2967, -0.1162],[ 0.0822, 2.0826],[-0.6343, -0.7222],[ 0.4282, 0.0235],[ 1.4056, 0.3506],[-0.6496, -0.5202],[-0.3969, -0.9951]]) tensor([ 6.0394, -0.3365, 9.5882, 5.1810, -2.7355, 5.3873, 4.9827, 5.7962,4.6727, 6.7921])
3.2.3 初始化模型参数
我们将权重初始化成均值为0、标准差为0.01的正态随机数,偏差则初始化成0。
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
之后的模型训练中,需要对这些参数求梯度来迭代参数的值,因此我们要让它们的requires_grad=True。
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
3.2.4 定义模型
下面是线性回归的矢量计算表达式的实现。我们使用mm函数做矩阵乘法。
def linreg(X, w, b): # 本函数已保存在d2lzh_pytorch包中方便以后使用return torch.mm(X, w) + b
3.2.5 定义损失函数
我们使用上一节描述的平方损失来定义线性回归的损失函数。在实现中,我们需要把真实值y变形成预测值y_hat的形状。以下函数返回的结果也将和y_hat的形状相同。
def squared_loss(y_hat, y): # 本函数已保存在d2lzh_pytorch包中方便以后使用# 注意这里返回的是向量, 另外, pytorch里的MSELoss并没有除以 2return (y_hat - y.view(y_hat.size())) ** 2 / 2
3.2.6 定义优化算法
以下的sgd函数实现了上一节中介绍的小批量随机梯度下降算法。它通过不断迭代模型参数来优化损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和。我们将它除以批量大小来得到平均值。
def sgd(params, lr, batch_size): # 本函数已保存在d2lzh_pytorch包中方便以后使用for param in params:param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
3.2.7 训练模型
在训练中,我们将多次迭代模型参数。在每次迭代中,我们根据当前读取的小批量数据样本(特征X和标签y),通过调用反向函数backward计算小批量随机梯度,并调用优化算法sgd迭代模型参数。由于我们之前设批量大小batch_size为10,每个小批量的损失l的形状为(10, 1)。回忆一下自动求梯度一节。由于变量l并不是一个标量,所以我们可以调用.sum()将其求和得到一个标量,再运行l.backward()得到该变量有关模型参数的梯度。注意在每次更新完参数后不要忘了将参数的梯度清零。
在一个迭代周期(epoch)中,我们将完整遍历一遍data_iter函数,并对训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数num_epochs和学习率lr都是超参数(关于超参数前面没理解的话可以看这篇【什么是超参数】传送门辅助理解),分别设3和0.03。在实践中,大多超参数都需要通过反复试错来不断调节。虽然迭代周期数设得越大模型可能越有效,但是训练时间可能过长。而有关学习率对模型的影响,我们会在后面“优化算法”一章中详细介绍。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_lossfor epoch in range(num_epochs): # 训练模型一共需要num_epochs个迭代周期# 在每一个迭代周期中,会使用训练数据集中所有样本一次(假设样本数能够被批量大小整除)。X# 和y分别是小批量样本的特征和标签for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y).sum() # l是有关小批量X和y的损失l.backward() # 小批量的损失对模型参数求梯度sgd([w, b], lr, batch_size) # 使用小批量随机梯度下降迭代模型参数# 不要忘了梯度清零w.grad.data.zero_()b.grad.data.zero_()train_l = loss(net(features, w, b), labels)print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
输出:
epoch 1, loss 0.028127
epoch 2, loss 0.000095
epoch 3, loss 0.000050
训练完成后,我们可以比较学到的参数和用来生成训练集的真实参数。它们应该很接近。
print(true_w, '\n', w)
print(true_b, '\n', b)
输出:
[2, -3.4] tensor([[ 1.9998],[-3.3998]], requires_grad=True)
4.2 tensor([4.2001], requires_grad=True)
小结
- 可以看出,仅使用
Tensor和autograd模块就可以很容易地实现一个模型。接下来,本书会在此基础上描述更多深度学习模型,并介绍怎样使用更简洁的代码(见下一节)来实现它们。
注:本节除了代码之外与原书基本相同,原书传送门
相关文章:
【深度学习笔记】3_2线性回归的从零实现
注:本文为《动手学深度学习》开源内容,仅为个人学习记录,无抄袭搬运意图 3.2 线性回归的从零开始实现 在了解了线性回归的背景知识之后,现在我们可以动手实现它了。尽管强大的深度学习框架可以减少大量重复性工作,但若…...

Apache Maven简介
Maven 简介 Apache Maven 是一个用于项目构建、依赖管理和项目信息管理的强大工具。它基于项目对象模型(Project Object Model,POM)进行构建,通过描述项目的结构和依赖关系来管理项目的构建过程。 以下是 Apache Maven 的一些关键原理和工作流程: 项目对象模型(POM)…...
#12解决request中getReader()和getInputStream()只能调用一次的问题
目录 1、背景 2、解决方案 2.1、自定义HttpServletRequestWrapper 2.2、JsonRequestHeaderParamsHelper 2.3、HttpServletRequestReplacedFilter 2.4、使用 1、背景 当前系统Content-Type为application/json,参数接收方式采用RequestBody和RequestParam&#…...

直接插入排序+希尔排序+冒泡排序+快速排序+选择排序+堆排序+归并排序+基于统计的排序
插入排序:直接插入排序、希尔排序 交换排序:冒泡排序、快速排序 选择排序:简单选择排序、堆排序 其他:归并排序、基于统计的排序 一、直接插入排序 #include<stdio.h> #include<stdlib.h> /* 直接插入排序&#…...
)
Java高级 / 架构师 场景方案 面试题(二)
1.双十一亿级用户日活统计如何用 Redis快速计算 在双十一这种亿级用户日活统计的场景中,使用Redis进行快速计算的关键在于利用Redis的数据结构和原子操作来高效地统计和计算数据。以下是一个基于Redis的日活统计方案: 选择合适的数据结构: …...
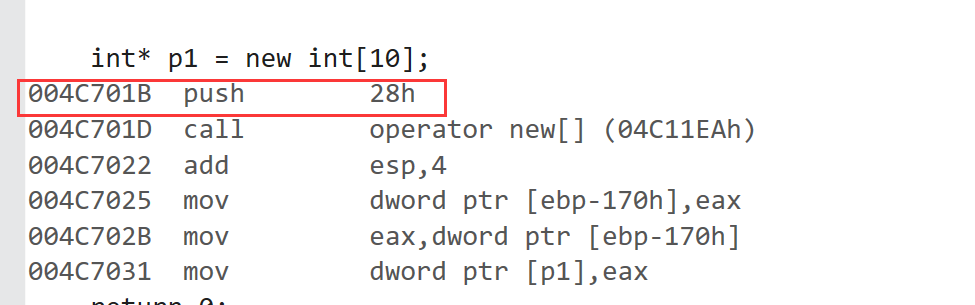
C/C++内存管理学习【new】
文章目录 一、C/C内存分布二、C语言中动态内存管理方式:malloc/calloc/realloc/free三、C内存管理方式3.1 new/delete操作内置类型3.2 new和delete操作自定义类型四、operator new与operator delete函数五、new和delete的实现原理5.1 内置类型 六、定位new表达式(pl…...

选择适合你的编程语言
引言 在当今瞬息万变的技术领域中,选择一门合适的编程语言对于个人职业发展和技术成长至关重要。每种语言都拥有独特的设计哲学、应用场景和市场需求,因此,在决定投入时间和精力去学习哪种编程语言时,我们需要综合分析多个因素&a…...

【力扣每日一题】力扣106从中序和后序遍历序列构造二叉树
题目来源 力扣106从中序和后序遍历序列构造二叉树 题目概述 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 思路分析 后序遍历序列的最末尾数…...

logback日志回滚原理
日志输出主要依赖RollingFileAppender、TimeBasedRollingPolicy、SizeAndTimeBasedFNATP。 RollingFileAppender 主要用于生成日志文件,格式化内容再输出到日志文件TimeBasedRollingPolicy 设置回滚策略,如果发现日志输出的时间超过单位时间,…...

[C#]winform基于opencvsharp结合pairlie算法实现低光图像增强黑暗图片变亮变清晰
【低光图像增强介绍】 在图像处理领域,低光图像增强是一个具有挑战性的任务。由于光线不足,这些图像往往呈现出低对比度、高噪声和细节丢失等问题,严重影响了图像的视觉效果和后续分析的准确性。因此,开发有效的低光图像增强方法…...
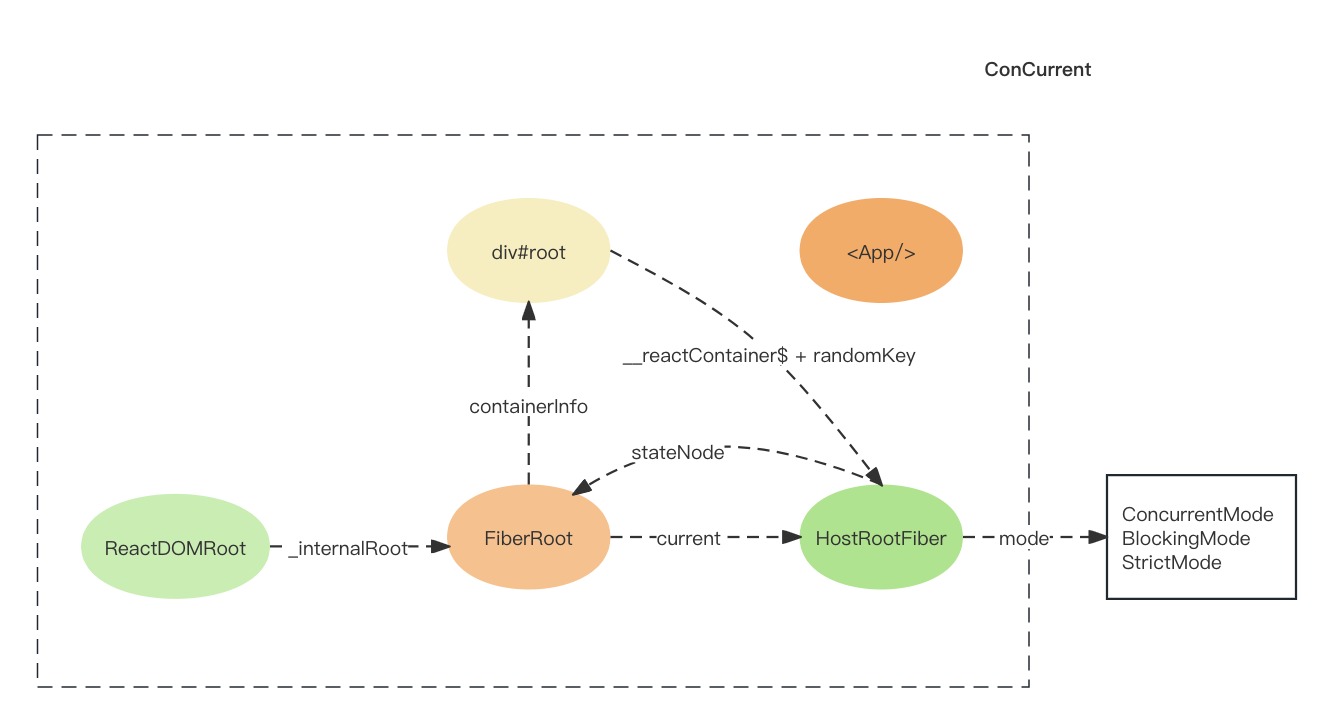
React18源码: reconcliler启动过程
Reconcliler启动过程 Reconcliler启动过程实际就是React的启动过程位于react-dom包,衔接reconciler运作流程中的输入步骤.在调用入口函数之前,reactElement(<App/>) 和 DOM对象 div#root 之间没有关联,用图片表示如下: 在启…...
【RN】为项目使用React Navigation中的navigator
简言 移动应用基本不会只由一个页面组成。管理多个页面的呈现、跳转的组件就是我们通常所说的导航器(navigator)。 React Navigation 提供了简单易用的跨平台导航方案,在 iOS 和 Android 上都可以进行翻页式、tab 选项卡式和抽屉式的导航布局…...

CS50x 2024 - Lecture 8 - HTML, CSS, JavaScript
00:00:00 - Introduction 关于互联网是怎么工作的,如何在他的基础上构建软件 HTML和CSS是描述性语言 javascript一种编程语言,在浏览器上下文中很有用,使得界面更具交互性,也用于服务器 00:01:01 - Bingo Board 00:01:51 - T…...
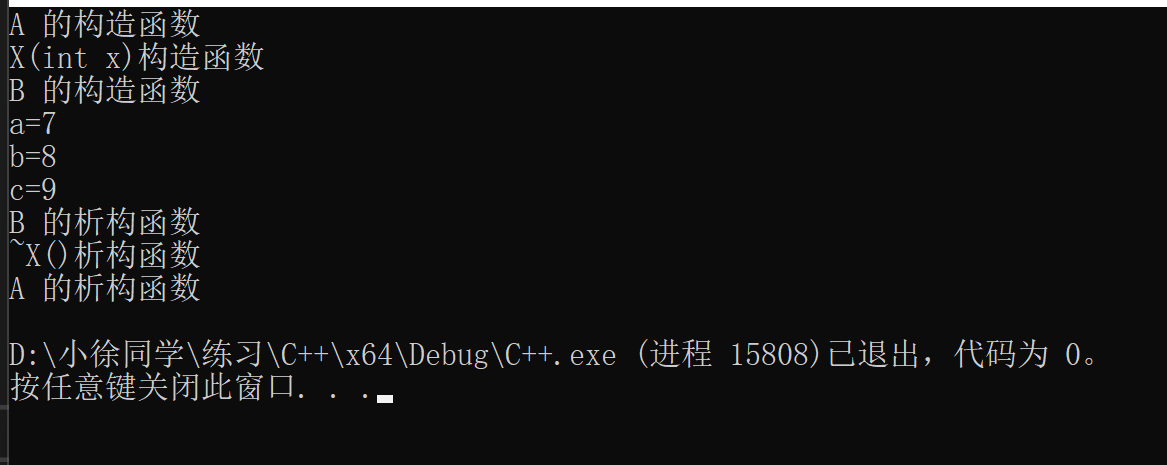
C++:派生类的生成过程(构造、析构)
目录 派生类的生成过程 派生类的构造函数与析构函数: 构造函数: 派生类组合类的构造和析构: 构造函数和析构函数调用顺序: 派生类的生成过程 三步骤: 吸收基类(父类)成员:实现代…...

金蝶字段添加过滤条件
金蝶字段加过滤条件 F_PLDE_Date<GetValue(FDate) and F_PLDE_Date1>GetValue(FDate)...

SQLite 知识整理
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录 SQLite 类型数据…...
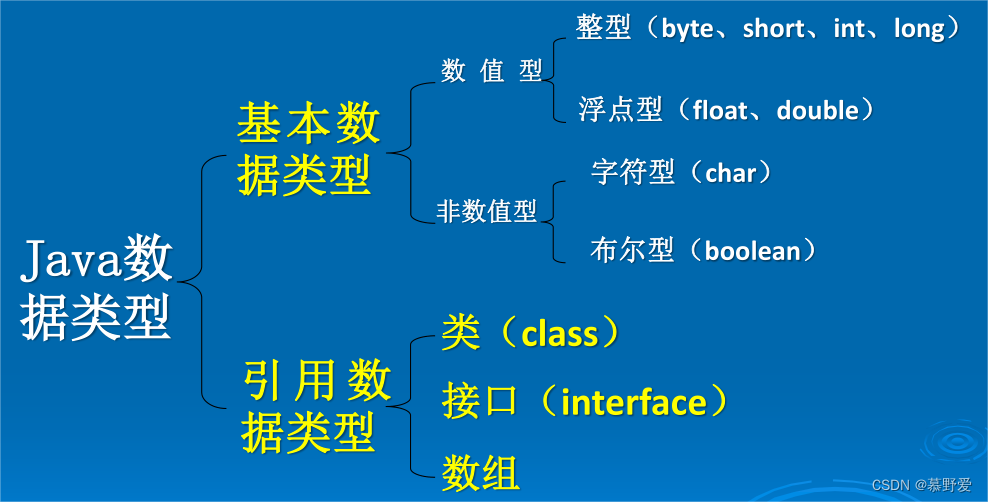
0基础JAVA期末复习最终版
啊啊啊啊啊啊啊啊啊啊,根据网上各位大佬的复习资料,看了很多大多讲的是基础但对内容的整体把握上缺乏系统了解。但是很不幸最终挂科了,那个出题套路属实把我整神了,所以我决定痛改前非,酣畅淋漓的写下这篇文章。。。。…...
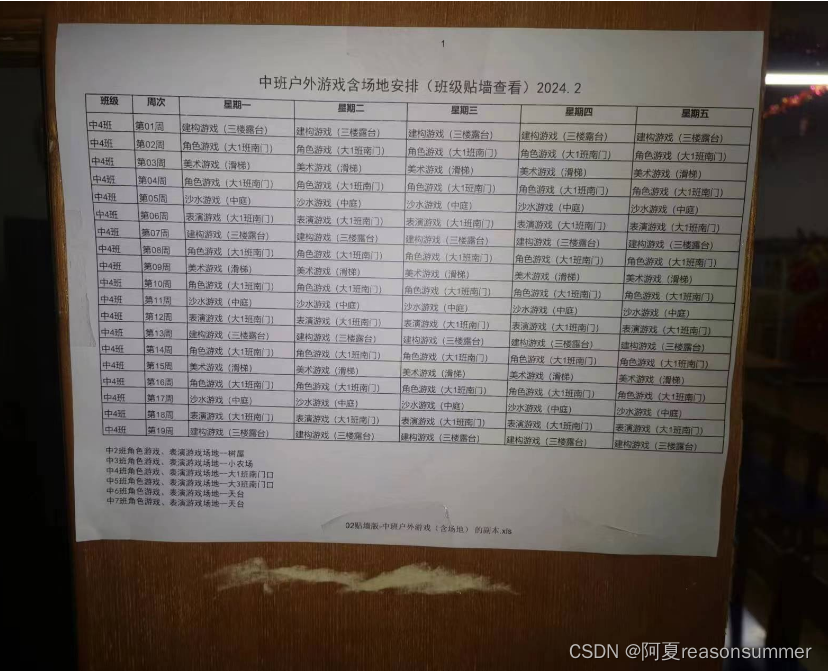
【办公类-16-07-04】合并版“2023下学期 中班户外游戏(有场地和无场地版,一周一次)”(python 排班表系列)
背景需求: 把 无场地版(贴周计划用) 和 有场地版(贴教室墙壁上用) 组合在一起,一个代码生成两套。 【办公类-16-07-02】“2023下学期 周计划-户外游戏 每班1周五天相同场地,6周一次循环”&…...

chat GPT第一讲
计算机的语言奇迹:探秘ChatGPT的智能回答和写作能力 目前我们这个行业,最火的话题无疑是AI人工智能,类似ChatGPT这样的智能Ai,今天剩下的时间不多,每天一个主题,我给大家讲一下计算机回答问题和写作的能力,…...
JAVA工程师面试专题-Mysql篇
一、基础 1、mysql可以使用多少列创建索引? 16 2、mysql常用的存储引擎有哪些 存储引擎Storage engine:MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。常用的存储引擎有以下: Innodb引擎:In…...

SimulinkVeriStandLabVIEW协同开发——从模型编译到交互式仪表盘部署
1. 工具链协同开发的核心价值 在电力电子和工业控制领域,快速原型开发往往需要跨越建模、实时测试和人机交互三个关键环节。Simulink、VeriStand和LabVIEW组成的工具链,就像汽车制造的流水线——Simulink是设计图纸的工程师,VeriStand是组装车…...

All in Token,三个运营商建Token工厂,中国移动跟进Token经营 三大运营商争夺AI阵地
随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约…...

AI驱动命令行工具:用自然语言自动化开发任务
1. 项目概述:一个为开发者“下厨”的AI助手如果你是一名开发者,每天在终端里敲打命令,构建、部署、调试,那么你肯定对重复性的命令行操作感到厌倦。比如,每次启动一个新项目,都要手动创建目录结构、初始化G…...

线程化笔记工具:重塑深度思考与知识管理的技术实践
1. 项目概述:一个为线程化思考而生的笔记工具最近在折腾个人知识管理工具时,发现了一个挺有意思的开源项目:alishobeiri/thread-notebook。乍一看名字,可能会以为是又一个普通的Markdown笔记本应用。但深入使用后,我发…...

Rekall:基于时空查询的视频内容智能检索开源框架
1. 项目概述:Rekall,一个面向视频时空查询的开源利器 如果你曾经尝试过从一段长视频里,精准地找出“那个穿红色衣服的人从画面左侧走到右侧的片段”,或者想快速定位“所有出现这只特定宠物狗的镜头”,你就会知道这有多…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

Python自动化股票分析工具:从数据采集到可视化报告全流程实战
1. 项目概述:一个面向个人投资者的自动化股票分析工具如果你和我一样,是个对A股市场有点兴趣,但又没时间天天盯盘的上班族,那你肯定也经历过这种纠结:早上开盘前想看看心仪的几只股票有没有什么异动,结果一…...

多智能体强化学习环境PettingZoo:从核心概念到工程实践
1. 项目概述:从零理解PettingZoo如果你正在寻找一个能让你快速上手、高效构建多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)实验环境的工具,那么Farama Foundation旗下的PettingZoo项目,绝对是你绕不开…...

MedAgentBench:大模型临床决策能力评估基准详解与应用
1. 项目概述:当大模型成为医疗决策的“实习生” 最近在医疗AI的圈子里,一个名为“MedAgentBench”的开源项目引起了不小的讨论。这个由斯坦福机器学习组(Stanford ML Group)发布的项目,其核心目标非常明确:…...

RTKLIB 2.4.3项目在Visual Studio 2019中的工程化配置:告别零散文件,打造清晰结构
RTKLIB 2.4.3项目在Visual Studio 2019中的工程化配置:告别零散文件,打造清晰结构 对于卫星导航领域的开发者而言,RTKLIB无疑是一个绕不开的开源项目。这个由日本学者Tomoji Takasu开发的GNSS定位软件,以其强大的功能和开放的架构…...