XGB-11:随机森林
XGBoost通常用于训练梯度提升决策树和其他梯度提升模型。随机森林使用与梯度提升决策树相同的模型表示和推断,但使用不同的训练算法。可以使用XGBoost来训练独立的随机森林,或者将随机森林作为梯度提升的基模型。这里我们专注于训练独立的随机森林。
XGB从早期开始就有用于训练随机森林的API,而Scikit-Learn在0.82版本之后才有封装。
使用XGBoost API训练独立的随机森林
要启用随机森林训练,必须设置以下参数:
-
booster应设置为gbtree,因为正在训练森林。由于这是默认值,通常不需要显式设置此参数。 -
subsample必须设置为小于 1 的值,以启用对训练样本(行)的随机选择。 -
colsample_by参数之一必须设置为小于 1 的值,以启用对列的随机选择。通常,colsample_bynode 应设置为小于 1 的值,以在每次树分裂时随机抽样列。 -
num_parallel_tree应设置为正在训练的森林的大小。 -
num_boost_round应设置为 1,以防止 XGBoost 提升多个随机森林。请注意,这是train()的关键字参数,不是参数字典的一部分。 -
在训练随机森林回归时,应将
eta(别名:learning_rate)设置为 1。 -
random_state可以用于设置随机数生成器的种子。
其他参数应以类似于梯度提升时设置的方式进行设置。例如,对于回归任务,objective 通常将设置为 reg:squarederror,而对于分类任务,将设置为 binary:logistic,lambda 应根据所需的正则化权重进行设置,等等。
如果 num_parallel_tree 和 num_boost_round 都大于 1,则训练将使用随机森林和梯度提升策略的组合。它将执行 num_boost_round 轮,在每一轮中提升 num_parallel_tree 棵树的随机森林。如果未启用提前停止,最终模型将由 num_parallel_tree * num_boost_round 棵树组成。
以下是在 GPU 上使用 xgboost 训练随机森林的示例参数字典:
params = {"colsample_bynode": 0.8,"learning_rate": 1,"max_depth": 5,"num_parallel_tree": 100,"objective": "binary:logistic","subsample": 0.8,"tree_method": "hist","device": "cuda",
}
然后可以按如下方式训练随机森林模型:
bst = train(params, dmatrix, num_boost_round=1)
import xgboost as xgb
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errordiabetes = load_diabetes()
X = diabetes.data
y = diabetes.target# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create a DMatrix for XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)# Set parameters for random forest training
params = {"booster": "gbtree","subsample": 0.8,"colsample_bynode": 0.8,"num_parallel_tree": 100,"num_boost_round": 1,"eta": 1,"random_state": 42,"objective": "reg:squarederror",
}# Train the random forest model
model = xgb.train(params, dtrain)# Make predictions on the test set
y_pred = model.predict(dtest)# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
基于 Scikit-Learn-Like API 实现随机森林
XGBRFClassifier 和 XGBRFRegressor 是类似于 Scikit-Learn 的类,提供了随机森林的功能。 它们基本上是 XGBClassifier 和 XGBRegressor 的版本,用于训练随机森林而不是梯度提升, 并相应地调整了一些参数的默认值和含义。具体来说:
n_estimators指定要训练的森林的大小;它被转换为num_parallel_tree,而不是boosting轮数的数量learning_rate默认设置为 1colsample_bynode和subsample默认设置为 0.8booster始终为gbtree
例如,可以使用以下代码训练一个随机森林回归器:
from sklearn.model_selection import KFold# Your code ...kf = KFold(n_splits=2)
for train_index, test_index in kf.split(X, y):xgb_model = xgb.XGBRFRegressor(random_state=42).fit(X[train_index], y[train_index])
注意,与使用 train() 相比,这些类的参数选择较少。特别是,使用此 API 无法将随机森林与梯度提升结合起来。
import xgboost as xgb
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from xgboost import XGBRFRegressor
from sklearn.model_selection import KFolddiabetes = load_diabetes()
X = diabetes.data
y = diabetes.targetkf = KFold(n_splits=2)
for train_index, test_index in kf.split(X, y):xgb_model = xgb.XGBRFRegressor(random_state=42).fit(X[train_index], y[train_index])# Make predictions on the test set
y_pred = xgb_model.predict(X_test)# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
注意事项
- XGBoost 使用二阶逼近来近似目标函数。这可能导致与使用目标函数的精确值的随机森林实现不同的结果
- 在子采样训练样本时,XGBoost 不执行替换操作。每个训练案例在子采样集中可能出现 0 次或 1 次
参考
- https://xgboost.readthedocs.io/en/latest/tutorials/rf.html
相关文章:

XGB-11:随机森林
XGBoost通常用于训练梯度提升决策树和其他梯度提升模型。随机森林使用与梯度提升决策树相同的模型表示和推断,但使用不同的训练算法。可以使用XGBoost来训练独立的随机森林,或者将随机森林作为梯度提升的基模型。这里我们专注于训练独立的随机森林。 XG…...

超平面介绍
超平面公式 (1) 超平面是指n维线性空间中维度为n-1的子空间。它可以把线性空间分割成不相交的两部分。比如二维空间中,一条直线是一维的,它把平面分成了两部分;三维空间中,一个平面是二维的,它把空间分成了两部分。(2…...
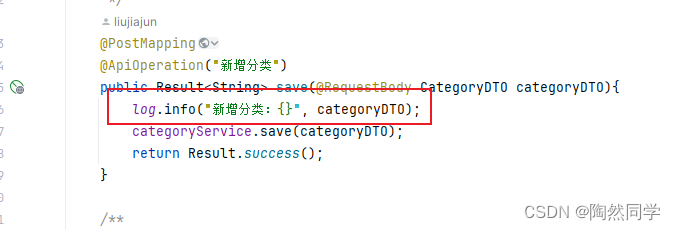
【苍穹外卖】一些开发总结
1、DTO、VO的区别 DTO:如果前端返回的实体类和对应的实体类比较较大差别 使用DTO来封装数据 后面在使用 BeanUtils.copyProperties() 将熟悉复制到对应的实体类中 VO:主要用于展示数据,例如在控制器层和视图层之间。它通常包含一些与显示相关的属性,如标题、描述等。 2…...

Python 3 中,`asynchat`异步通信
在 Python 3 中,asynchat 是基于 asyncore 的一个高层抽象模块,用于处理异步通信协议。它提供了一种简单的方式来创建自定义的异步通信协议,并处理通信中的错误和异常。 asynchat 模块主要作用是将网络数据流分割成消息或者数据包࿰…...
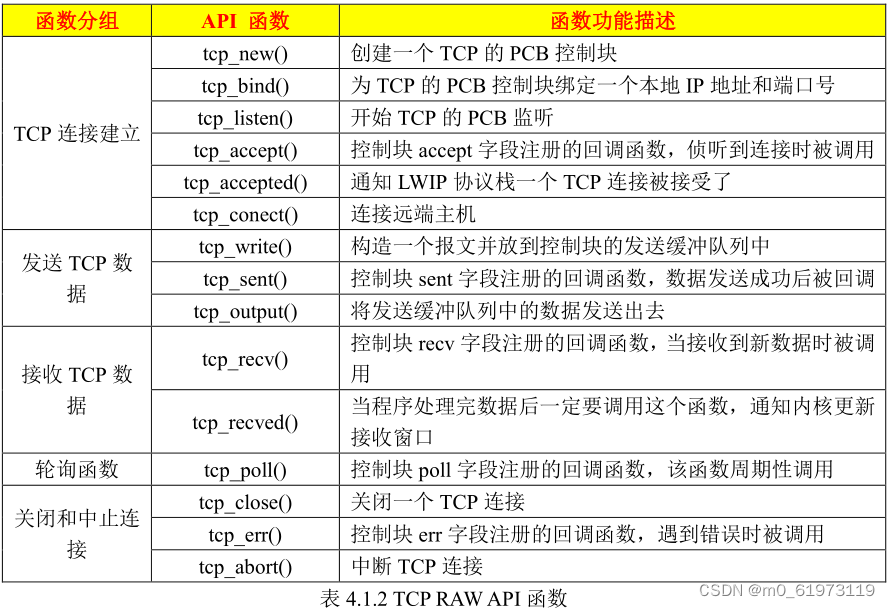
RAW 编程接口 TCP 简介
一、LWIP 中 中 RAW API 编程接口中与 TCP 相关的函数 二、LWIP TCP RAW API 函数 三、LwIP_Periodic_Handle函数 LwIP_Periodic_Handle 函数是一个必须被无限循环调用的 LwIP支持函数,一般在 main函数的无限循环中调用,主要功能是为 LwIP各个模块提供…...

Oracle EBS FA折旧回滚的分录追溯
FA模块向子分类账和总账追溯分为两部分:事务表和折旧,但是FA相关表做其实关联计划外折旧的分录会被遗漏的原因: 如果已经当月折旧,运行完成折旧后,又进行了计划外折旧,因为计划折旧时又要区分【是否进行当月…...
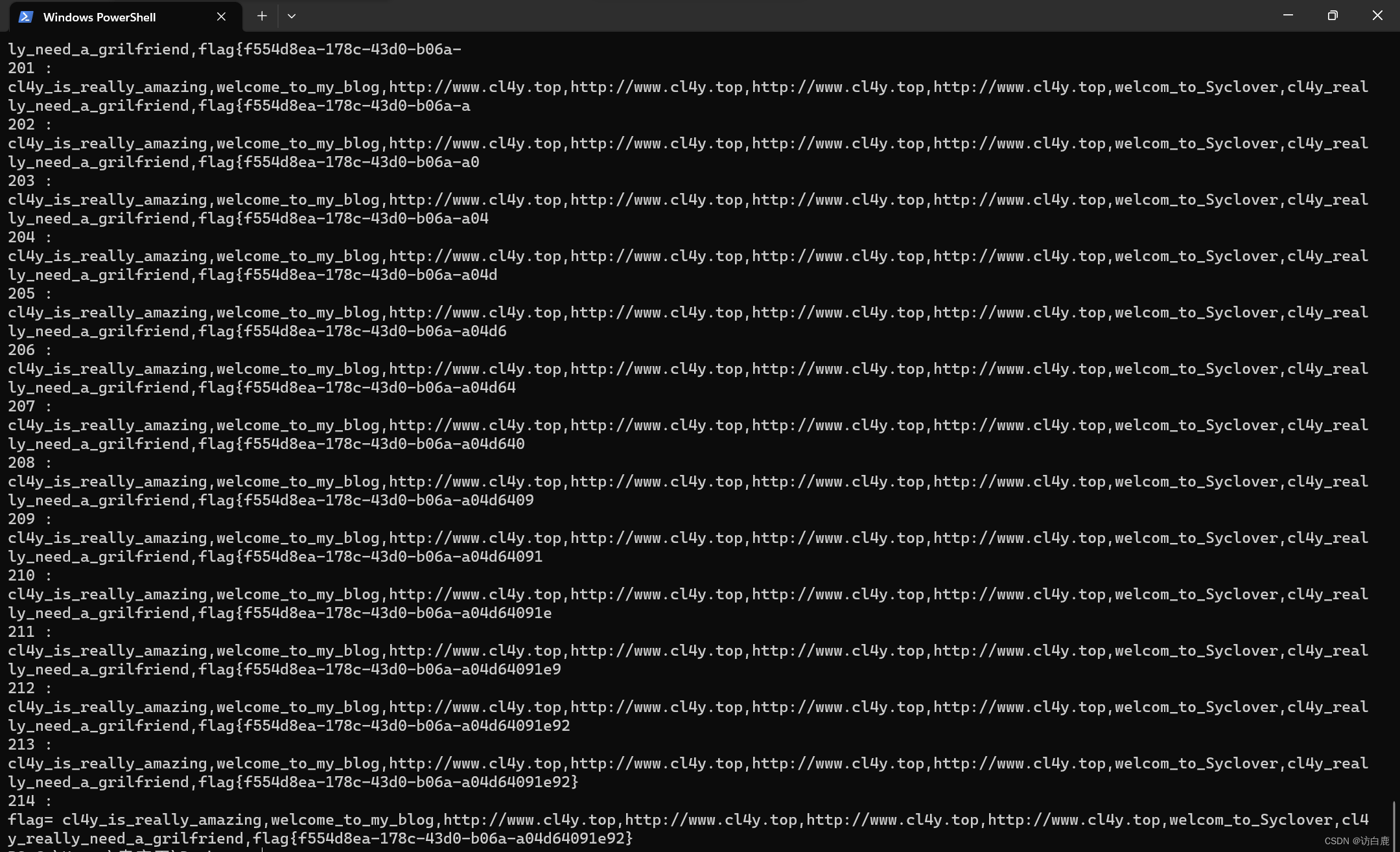
sql注入 [极客大挑战 2019]FinalSQL1
打开题目 点击1到5号的结果 1号 2号 3号 4号 5号 这里直接令传入的id6 传入id1^1^1 逻辑符号|会被检测到,而&感觉成了注释符,&之后的内容都被替换掉了。 传入id1|1 直接盲注比较慢,还需要利用二分法来编写脚本 这里利用到大佬的脚…...

持续集成,持续交付和持续部署的概念,以及GitLab CI / CD的介绍
引言:上一期我们部署好了gitlab极狐网页版,今天我们介绍一下GitLabCI / CD 目录 一、为什么要 CI / CD 方法 1、持续集成 2、持续交付 3、持续部署 二、GitLab CI / CD简介 三、GitLab CI / CD 的工作原理 4、基本CI / CD工作流程 5、首次设置 …...
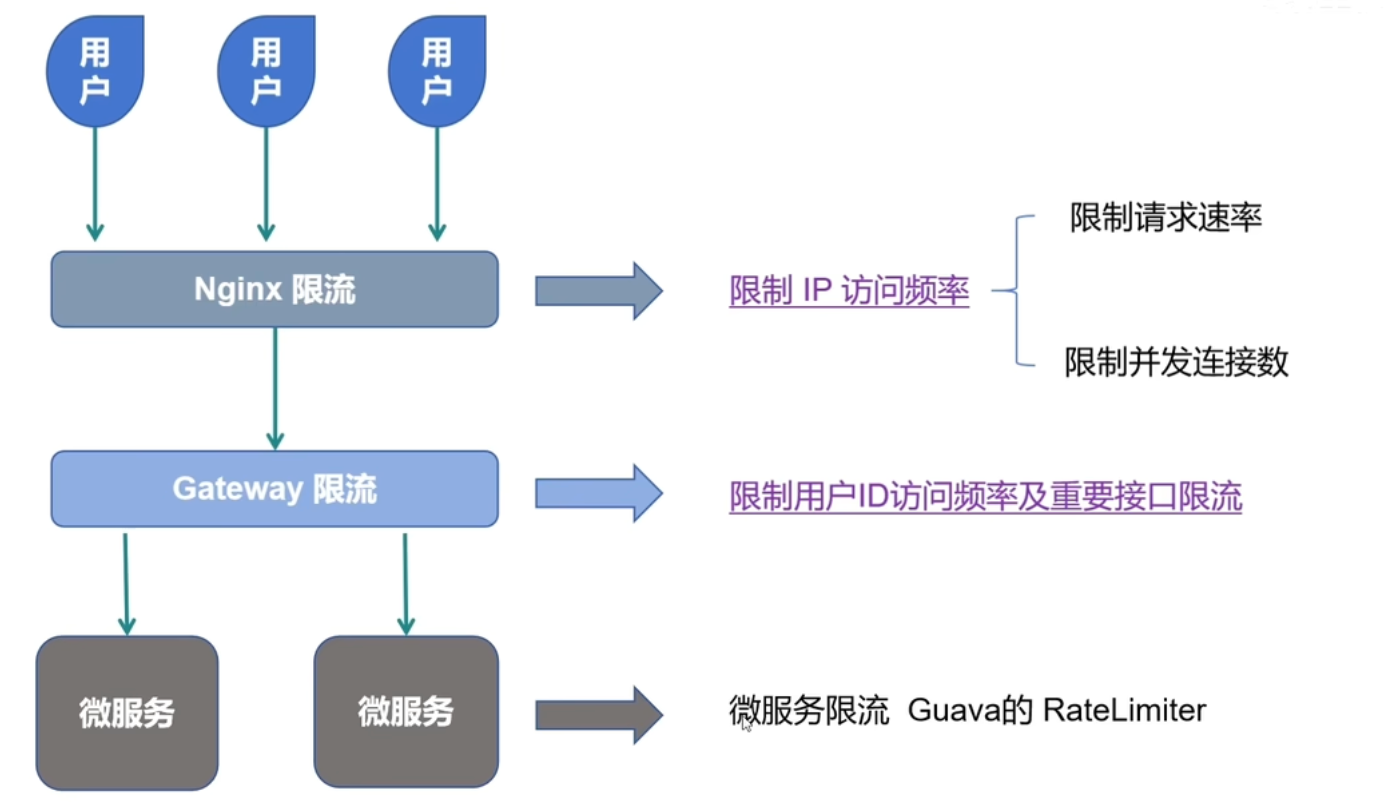
[Java 项目亮点] 三层限流设计
思路来源:bilibili 河北王校长 文章目录 面试官可能会问你能详细介绍一下Nginx的http_limit_req_module模块吗?你能解释一下如何在Nginx中配置http_limit_req_module模块吗?你知道如何调整Nginx的http_limit_req_module模块以适应不同的业务需…...
GPT-SoVITS 快速声音克隆使用案例:webui、api接口
参考: https://github.com/RVC-Boss/GPT-SoVITS 环境: Python 3.10 PyTorch 2.1.2, CUDA 12.0 安装包: 1、使用: 1)下载项目 git clone https://github.com/RVC-Boss/GPT-SoVITS.git2)下载预训练模型 https://huggingface.co/lj1995/GPT-SoVITS 下载模型文件放到GPT…...
系统功能规范)
高速自动驾驶智慧匝道(HIC)系统功能规范
智慧匝道功能规范 Highway Intelligent Change Functional Specification 文件状态: 【√】草稿 【】正式发布 【】正在修改 文件起草分工 撰写: 审核: 编制: 签名: 日期: 审核: 签名&am…...
SQL Server——建表时为字段添加注释
在 MySQL 中,新建数据库表为字段添加注释可以使用 comment 属性来实现。SQL Server 没有 comment 属性,但是可以通过执行 sys.sp_addextendedproperty 这个存储过程添加扩展属性来实现相同的功能。 这个存储过程的参数定义如下: exec sys.s…...

【明道云】导入Excel数据时的默认顺序
【背景】 明道云导入Excel过程中由于数据问题往往会有一些需要补录的地方。这种情况下就需要已上传到线上的数据和本地Excel的记录顺序完全一致才方便对比。因此需要清除如何让两者的记录顺序一致。 【分析】 经过多次排序对比,考虑到分页的影响,发现…...

几种后端开发中常用的语言。
几种后端开发中常用的语言。 C/C 语言 C 语言最初是用于系统开发工作,特别是组成操作系统的程序。由于 C 语言所产生的代码运行速度与汇编语言编写的代码运行速度几乎一样,所以采用 C 语言作为系统开发语言。目前,C 语言是最广泛使用的系统…...

Sora——探索AI视频模型的无限可能
Sora - 探索AI视频模型的无限可能 Sora作为OpenAI发布的一款AI视频模型,其探索的无限可能性表现在多个方面。首先,从技术的角度来看,Sora将文本生成图像的技术扩展到了视频领域,实现了从文字描述到视频内容的自动生成。这种技术突…...
[NCTF2019]True XML cookbook --不会编程的崽
题目的提示很明显了,就是xxe攻击,直接抓包。 <?xml version "1.0"?> <!DOCTYPE ANY [ <!ENTITY xxe SYSTEM "file:///etc/passwd" > ]> <user><username> &xxe; </username><passwor…...

Qt 应用程序中指定使用桌面版本的 OpenGL或嵌入式系统OpenGL ES的 API 进行渲染
qputenv(“QT_OPENGL”, “desktop”) 是用于在 Qt 应用程序中指定使用桌面版本的 OpenGL API 进行渲染。 具体来说,qputenv 是 Qt 提供的一个环境变量设置函数,它允许开发者在程序运行时设置环境变量。在这个例子中,环境变量 QT_OPENGL 被设…...

大数据软件,待补充
数据采集: 实时采集: Debezuim Debezuim是构建在 Apach Kafka之上,并提供Kafka连接器来监视特定的数据库管理(采集多种数据库) Canal canal 是阿里开发,用于实时采集Mysql 当中变化的数据 maxwell,flinkX,flinkCDC 离线采集&#…...

深入探索pdfplumber:从PDF中提取信息到实际项目应用【第94篇—pdfplumbe】
深入探索pdfplumber:从PDF中提取信息到实际项目应用 在数据处理和信息提取的过程中,PDF文档是一种常见的格式。然而,要从PDF中提取信息并进行进一步的分析,我们需要使用适当的工具。本文将介绍如何使用Python库中的pdfplumber库来…...
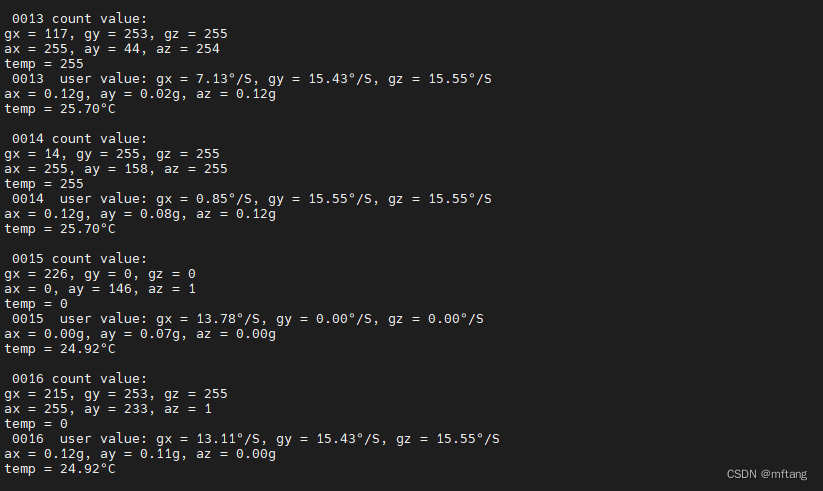
实现linux platform tree框架下ICM20608驱动开发(SPI)
目录 概述 1 硬件接口 2 添加ICM20608的设备树信息 2.1 使用i.MX Pins Tool v6配置SPI引脚 2.2 配置设备树 2.3 编译.dts 2.4 在板卡中更新设备树 3 编写驱动程序 3.1 创建设备匹配表 3.2 重要函数介绍 3.2.1 初始化函数 3.2.2 写寄存器函数 3.2.3 读寄存器函数 …...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案
Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...

数据中心碳足迹与可靠性优化框架解析
1. 数据中心碳足迹与可靠性优化的挑战 现代数据中心已成为数字经济的动力引擎,但伴随算力需求的爆炸式增长,其能源消耗与碳排放问题日益凸显。根据最新统计,全球数据中心年耗电量已达4600亿度,占全球总用电量的2%。随着大语言模型…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...

Arm Neoverse CMN-700多芯片架构与一致性哈希解析
1. Arm Neoverse CMN-700多芯片架构解析在现代高性能计算领域,多芯片系统架构已成为突破单芯片性能瓶颈的关键技术路径。Arm Neoverse CMN-700作为第二代一致性网状网络控制器,其设计哲学体现在三个维度:首先是通过模块化设计实现计算单元的可…...

基于Feather微控制器的智能灯光系统:颜色感应与BLE遥控实现
1. 项目概述与核心价值又到了折腾点节日氛围的时候了。往年都是买现成的彩灯串,总觉得少了点意思,今年决定自己动手,做个能“听懂”指令、甚至能“看见”颜色的智能灯光系统。这个项目的核心,就是用一块小小的微控制器,…...

FastAPI+AI应用脚手架:模块化架构与生产级实践指南
1. 项目概述:一个为AI应用量身定制的FastAPI脚手架如果你正在寻找一个能快速启动、结构清晰且功能强大的AI应用后端框架,那么fastapi-genai-boilerplate这个项目绝对值得你花时间研究。它不是一个简单的“Hello World”示例,而是一个面向生产…...

基于Go的轻量级自托管IM系统OpenWhisp部署与架构解析
1. 项目概述:一个开源的即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个轻量级的即时通讯模块。市面上成熟的方案不少,但要么是SaaS服务,数据不在自己手里,心里不踏实;要么是像Rocket.Chat、Matt…...

ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台
ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vario…...