深入探索pdfplumber:从PDF中提取信息到实际项目应用【第94篇—pdfplumbe】
深入探索pdfplumber:从PDF中提取信息到实际项目应用
在数据处理和信息提取的过程中,PDF文档是一种常见的格式。然而,要从PDF中提取信息并进行进一步的分析,我们需要使用适当的工具。本文将介绍如何使用Python库中的pdfplumber库来读取PDF文档,并通过实际代码示例演示如何将提取的信息写入Excel文件。

1. pdfplumber简介
pdfplumber是一个用于处理PDF文件的Python库,它基于PDFMiner、pyPDF2和其他库构建而成。它提供了简单而强大的接口,使得从PDF文档中提取文本、表格和其他元素变得更加容易。
2. 安装pdfplumber
首先,确保你已经安装了Python。然后使用以下命令安装pdfplumber:
pip install pdfplumber
3. 使用pdfplumber读取PDF文档
让我们通过以下步骤演示如何使用pdfplumber读取PDF文档。
import pdfplumber# 读取PDF文档
with pdfplumber.open('example.pdf') as pdf:# 获取文档的总页数total_pages = len(pdf.pages)# 遍历每一页for page_number in range(total_pages):# 获取当前页page = pdf.pages[page_number]# 提取文本内容text = page.extract_text()# 打印文本内容print(f"Page {page_number + 1}:\n{text}")
以上代码演示了如何打开PDF文档,获取总页数,并遍历每一页提取文本内容。接下来,我们将演示如何提取表格数据,并将其写入Excel文件。
4. 将提取的表格数据写入Excel
import pdfplumber
import pandas as pd# 读取PDF文档
with pdfplumber.open('example.pdf') as pdf:# 获取文档的总页数total_pages = len(pdf.pages)# 创建一个空的DataFrame来存储表格数据df = pd.DataFrame()# 遍历每一页for page_number in range(total_pages):# 获取当前页page = pdf.pages[page_number]# 提取表格数据table = page.extract_table()# 将表格数据转换为DataFramedf_page = pd.DataFrame(table)# 将当前页的数据添加到整体DataFrame中df = df.append(df_page, ignore_index=True)# 将DataFrame写入Excel文件df.to_excel('output.xlsx', index=False)
以上代码演示了如何使用pdfplumber提取PDF文档中的表格数据,并将其存储到一个Pandas DataFrame中。最后,将DataFrame写入Excel文件。这样,你就可以轻松地将PDF中的表格数据转移到Excel进行进一步分析。
6. 代码解析
让我们深入了解上述代码的关键部分:
-
导入pdfplumber和pandas库:
import pdfplumber import pandas as pd在代码的开头,我们导入了pdfplumber和pandas库。pdfplumber用于处理PDF文件,而pandas用于处理表格数据。
-
打开PDF文档并遍历每一页:
with pdfplumber.open('example.pdf') as pdf:total_pages = len(pdf.pages)df = pd.DataFrame()for page_number in range(total_pages):page = pdf.pages[page_number]# ...使用
pdfplumber.open打开PDF文档,并通过pdf.pages获取文档中的所有页。然后,我们创建一个空的DataFramedf用于存储表格数据,并使用for循环遍历每一页。 -
提取表格数据和将其转换为DataFrame:
table = page.extract_table() df_page = pd.DataFrame(table)使用
page.extract_table()方法从当前页提取表格数据,并将其转换为Pandas DataFrame。 -
将当前页的数据添加到整体DataFrame中:
df = df.append(df_page, ignore_index=True)使用
df.append方法将当前页的数据添加到整体DataFrame中。ignore_index=True确保每页的数据都具有唯一的索引。 -
将DataFrame写入Excel文件:
df.to_excel('output.xlsx', index=False)使用
df.to_excel方法将整体DataFrame写入Excel文件,index=False表示不将DataFrame的索引写入Excel文件中。
8. 进阶应用与注意事项
8.1 进阶应用
-
处理复杂表格结构: 对于包含合并单元格、嵌套表格等复杂结构的PDF表格,pdfplumber提供了一些高级的方法和属性,如
cells、merge_strategy等,使我们能够更灵活地处理这些情况。 -
提取非文本元素: pdfplumber不仅可以提取文本数据,还可以获取图片、矩形、线条等元素。这为处理包含图像或其他非文本内容的PDF提供了可能性。
8.2 注意事项
-
PDF文档质量: pdfplumber的性能受到PDF文档质量的影响。在处理低质量或扫描的文档时,提取数据可能会变得更加复杂,需要更多的处理和清理。
-
编码和字体: 在处理PDF文档时,特别是处理非英语文本时,可能会遇到编码和字体的问题。确保系统中安装了适当的字体,并根据需要设置文本编码。
-
文档结构变化: pdfplumber依赖于PDF的结构,如果文档的结构发生变化,可能需要调整代码以适应新的结构。
10. 拓展阅读与学习资源
为了帮助读者更深入地学习和应用pdfplumber以及相关技术,以下是一些拓展阅读和学习资源:
- PDFMiner官方文档: pdfplumber基于PDFMiner,因此熟悉PDFMiner库的使用也是有益的。PDFMiner的官方文档提供了对PDF文档的更底层访问,适合需要更高度自定义的场景。
- Python编程学习: 如果你是Python新手,建议深入学习Python编程语言的基础知识。你可以通过在线教程、课程或经典教材来提高你的Python编程技能。
11. 探索其他PDF处理工具
pdfplumber是众多用于处理PDF的Python库之一。根据不同需求,你可能还会对其他库感兴趣,如PyMuPDF、PyPDF2等。了解多个库的优缺点,选择适合你项目需求的工具。
12. 参与社区与反馈
如果在使用pdfplumber的过程中遇到问题或有建议,可以通过GitHub等社区渠道提出。积极参与社区讨论,与其他开发者分享经验,共同促进工具的不断改进。
希望通过这些建议和资源,你能够更加深入地学习和应用PDF文档处理技术,提升你的数据分析和信息提取能力。祝你在技术学习的道路上取得更多成就!
13. 实践项目:从PDF中提取特定信息
为了更好地巩固对pdfplumber的理解,让我们尝试一个实践项目:从一份包含多个人员信息的PDF文件中提取姓名、邮箱地址和电话号码,并将其存储到一个结构化的数据格式中。
import pdfplumber
import redef extract_information_from_pdf(pdf_path):with pdfplumber.open(pdf_path) as pdf:total_pages = len(pdf.pages)# 创建一个空的列表用于存储信息extracted_data = []for page_number in range(total_pages):page = pdf.pages[page_number]# 提取文本内容text = page.extract_text()# 使用正则表达式提取姓名、邮箱地址和电话号码name_match = re.search(r'姓名: (.+)', text)email_match = re.search(r'邮箱: (.+)', text)phone_match = re.search(r'电话: (.+)', text)if name_match and email_match and phone_match:name = name_match.group(1)email = email_match.group(1)phone = phone_match.group(1)# 将提取的信息添加到列表中extracted_data.append({'姓名': name, '邮箱': email, '电话': phone})return extracted_data# 指定PDF文件路径
pdf_file_path = 'person_info.pdf'# 提取信息并打印
result = extract_information_from_pdf(pdf_file_path)
for entry in result:print(entry)
在这个示例中,我们使用正则表达式从每一页的文本中提取姓名、邮箱地址和电话号码。请注意,实际的PDF文档结构可能因具体情况而异,你可能需要根据文档的实际结构进行适当的调整。
14. 进一步学习
-
深入学习正则表达式: 正则表达式在文本提取中非常有用。深入学习正则表达式的语法和应用可以帮助你更高效地处理各种文本模式。
-
数据清洗与预处理: 在实际项目中,你可能需要进行更复杂的数据清洗和预处理。学习Pandas和其他数据处理工具,掌握数据清洗技巧将对你的工作大有裨益。
-
Web Scraping: 如果你的信息源不仅限于PDF文档,还包括Web页面,学习Web Scraping技术将进一步拓展你的信息获取能力。
15. 反馈与交流
如果在实践项目中遇到了问题或有任何疑问,欢迎在相关社区、论坛或平台上提出。与其他开发者分享你的经验,获取反馈,这对于你的学习和成长都是非常有益的。祝你在实际项目中取得成功!
16. 最佳实践:代码优化和异常处理
在实际项目中,为了保证代码的可维护性和稳定性,我们通常需要考虑一些最佳实践,包括代码优化和异常处理。
16.1 代码优化
- 使用函数和模块: 将代码组织为函数和模块,以提高可读性和可维护性。将上述提取信息的代码封装成一个函数,便于复用和管理。
import pdfplumber
import redef extract_information_from_text(text):name_match = re.search(r'姓名: (.+)', text)email_match = re.search(r'邮箱: (.+)', text)phone_match = re.search(r'电话: (.+)', text)if name_match and email_match and phone_match:name = name_match.group(1)email = email_match.group(1)phone = phone_match.group(1)return {'姓名': name, '邮箱': email, '电话': phone}else:return Nonedef extract_information_from_pdf(pdf_path):with pdfplumber.open(pdf_path) as pdf:total_pages = len(pdf.pages)extracted_data = []for page_number in range(total_pages):page = pdf.pages[page_number]text = page.extract_text()result = extract_information_from_text(text)if result:extracted_data.append(result)return extracted_data
16.2 异常处理
- 处理异常情况: 在现实项目中,PDF文档的结构可能因来源和版本而异,因此我们需要在代码中添加适当的异常处理来处理不同情况。
def extract_information_from_pdf(pdf_path):with pdfplumber.open(pdf_path) as pdf:total_pages = len(pdf.pages)extracted_data = []for page_number in range(total_pages):try:page = pdf.pages[page_number]text = page.extract_text()result = extract_information_from_text(text)if result:extracted_data.append(result)except Exception as e:print(f"Error processing page {page_number + 1}: {str(e)}")return extracted_data
通过添加异常处理,我们能够捕获并打印错误信息,同时继续处理其他页面,确保程序的鲁棒性。
17. 持续学习和实践
在编程和数据处理的领域中,持续学习和实践是非常关键的。不断挑战新的项目,学习新的技术和工具,参与开发者社区的讨论和贡献,将有助于提升你的技能水平。
-
参与开源项目: 在GitHub等平台上,有许多与PDF处理相关的开源项目,可以参与其中,学习他人的代码风格和最佳实践。
-
阅读相关文档和博客: 随着技术的不断更新,阅读相关文档和博客是了解最新技术动态和最佳实践的好方法。
-
参与在线学习平台: 利用在线学习平台(如Coursera、edX、Udacity等),参加相关的课程和培训,提升自己的专业水平。
通过不断的学习和实践,你将能够更加熟练地处理各种数据处理任务,从而在实际项目中表现出色。祝你在编程和数据处理的旅程中取得更多成功!
相关文章:
深入探索pdfplumber:从PDF中提取信息到实际项目应用【第94篇—pdfplumbe】
深入探索pdfplumber:从PDF中提取信息到实际项目应用 在数据处理和信息提取的过程中,PDF文档是一种常见的格式。然而,要从PDF中提取信息并进行进一步的分析,我们需要使用适当的工具。本文将介绍如何使用Python库中的pdfplumber库来…...
实现linux platform tree框架下ICM20608驱动开发(SPI)
目录 概述 1 硬件接口 2 添加ICM20608的设备树信息 2.1 使用i.MX Pins Tool v6配置SPI引脚 2.2 配置设备树 2.3 编译.dts 2.4 在板卡中更新设备树 3 编写驱动程序 3.1 创建设备匹配表 3.2 重要函数介绍 3.2.1 初始化函数 3.2.2 写寄存器函数 3.2.3 读寄存器函数 …...

在前端开发中需要考虑的常见web安全问题和攻击原理以及防范措施
文章目录 一、XSS攻击1、反射型XSS攻击原理2、DOM型XSS攻击原理3、存储型XSS攻击原理 防范措施 二、CSRF攻击攻击原理:防范措施: 三、点击劫持攻击原理:防范措施: 四、项目中如何预防安全问题 随着互联网的发展,Web应用…...

年关将至送大礼 社区适时献爱心
在这个快节奏的时代,社区作为人们生活的重要组成部分,其凝聚力和互助精神显得尤为重要。2024年2月7日,实践队员李若钰有幸参与了社区礼盒分装的活动,这不仅仅是一次简单的劳动,更是一次心灵的洗礼和感悟。 礼盒分装&am…...

singularity容器的技术基础
Singularity容器技术是专为科学计算、数据密集型工作和高性能计算(HPC)环境设计的。与其他容器技术如Docker相比,Singularity提供了一些独特的特性和设计考虑,使其在科学和研究社区中受到欢迎。以下是Singularity容器技术的一些关…...
)
jax可微分编程的笔记(2)
jax可微分编程的笔记(2) 第2章 自动微分 自动微分和符号求导有诸多的相似之处:它们同样依赖于计算图 的构建,同样依赖于求导的递归实现。从某种意义上来说,它们 甚至有完全相同的数据结构。不过,二者的区…...
在Linux服务器上部署一个单机项目
目录 一、jdk安装 二、tomcat安装 三、MySQL安装 四、部署项目 一、jdk安装 1. 上传jdk安装包 jdk-8u151-linux-x64.tar.gz 进入opt目录,将安装包拖进去 2. 解压安装包 这里需要解压到usr/local目录下,在这里我新建一个文件夹保存解压后的文件 [r…...
HTTP概要
文章目录 什么是HTTP?URL的结构请求报文结构请求方法GETHEADPOSTPUTDELETETRACEOPTIONSCONNECTPATCH解释 请求头字段 响应报文结构响应状态响应头字段 HTTP会话3次握手无状态协议 什么是HTTP? HTTP,即Hypertext Transfer Protocol(超文本传输协议) 它是一个”请…...
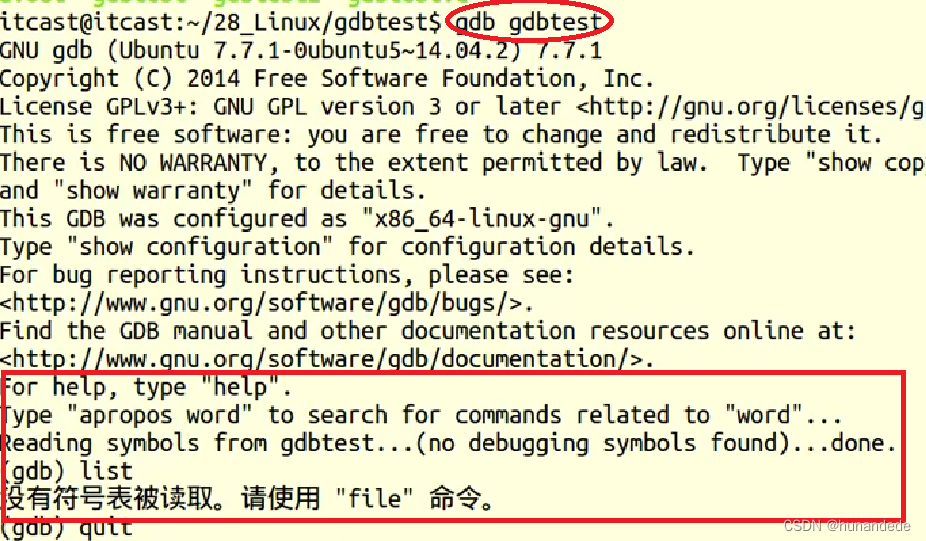
128 Linux 系统编程6 ,C++程序在linux 上的调试,GDB调试
今天来整理 GDB 调试。 在windows 上我们使用vs2017开发,可以手动的加断点,debug。 那么在linux上怎么加断点,debug呢?这就是今天要整理的GDB调试工具了。 那么有些同学可能会想到:我们在windows上开发,…...
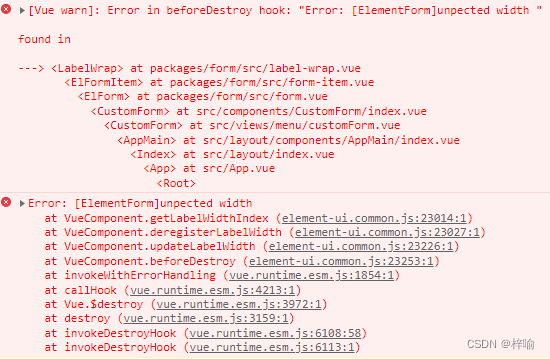
vue2的ElementUI的form表单报错“Error: [ElementForm]unpected width”修复
1. 问题 ElementUI的form表单,当动态切换显示表单时报错 Error: [ElementForm]unpected width。 翻译过来就是form表单的label宽度width出了问题。 2. 分析 参数说明类型可选值默认值label-width表单域标签的宽度,例如 ‘50px’。作为 Form 直接子元…...

Linux 网络命令指南
目录 配置IP地址和子网掩码 网络接口的详细信息 测试与目标主机的连通性 下载文件或内容 远程登录,进行远程管理和协作 CentOS / Red Hat(使用 firewalld) 关闭防火墙 开启防火墙 配置TCP端口(假设使用3306端口ÿ…...

vue3组件间的通信,通过props,emit,provide和inject把数据传递N个层级,expose和ref实现父组件调用子组件方法
文章目录 一、父组件数据传递N个层级的子组件vue3 provide 与 injectA组件名称 app.vueB组件名称 provideB.vueC组件名称 provideCSetup.vue 二、使用v-model指令实现父子组件的双向绑定父组件名称 app.vue子组件名称 v-modelSetup.vue 三、父组件props向子组件传值子组件 prop…...
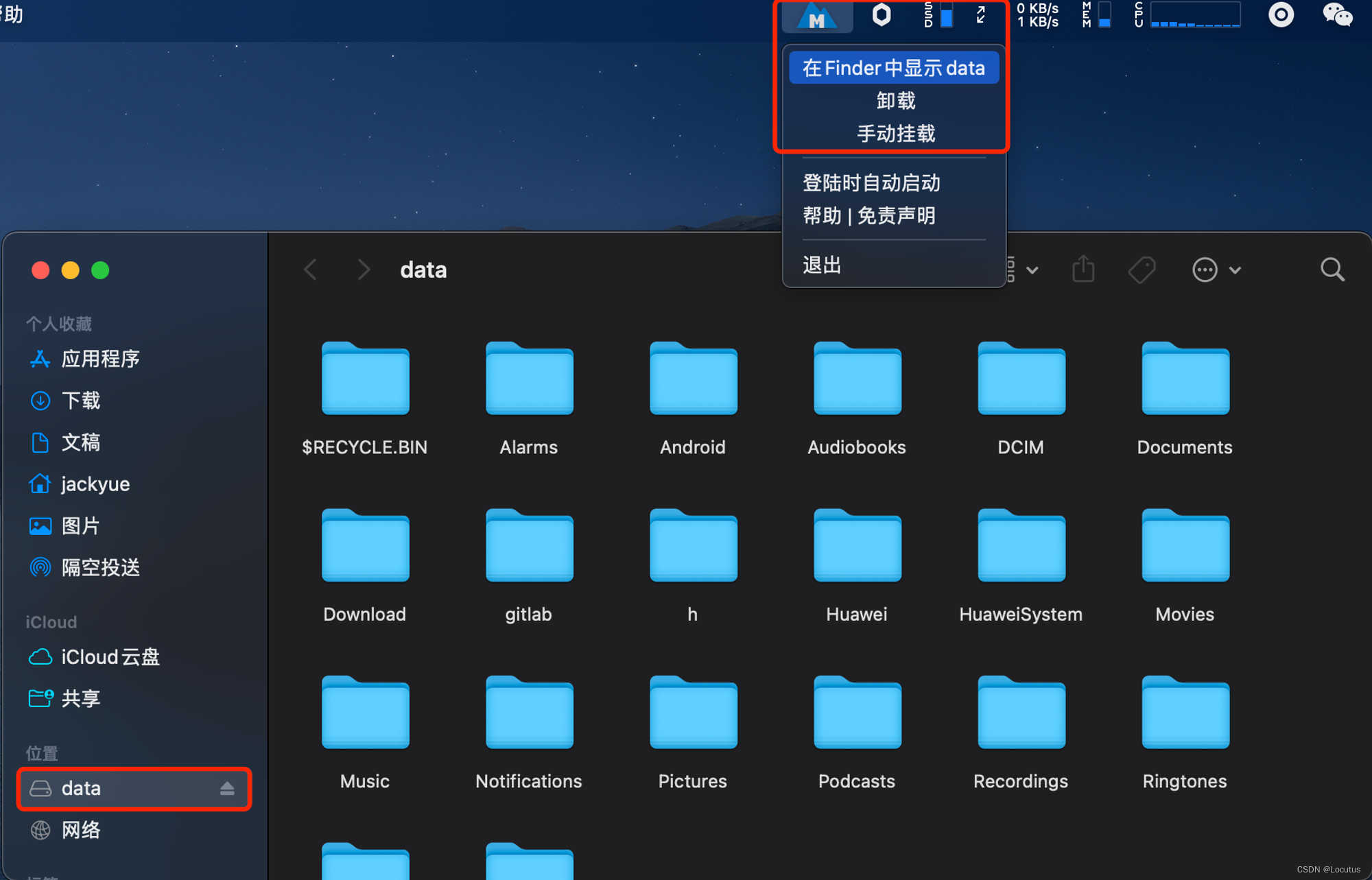
开源免费的NTFS for mac工具mounty
开源免费的NTFS for mac工具mounty 安装依赖 brew install gromgit/fuse/ntfs-3g-macbrew install --cask macfuse安装mounty 如果已经安装macFUSE和ntfs-3g-mac,可以直接点击下载的dmg安装包,安装升级。第一次启动mounty,你需要接受一系列…...

Sora-OpenAI 的 Text-to-Video 模型:制作逼真的 60s 视频片段
OpenAI 推出的人工智能功能曾经只存在于科幻小说中。 2022年,Openai 发布了 ChatGPT,展示了先进的语言模型如何实现自然对话。 随后,DALL-E 问世,它利用文字提示生成令人惊叹的合成图像。 现在,他们又推出了 Text-t…...
4 buuctf解题
[CISCN 2019 初赛]Love Math1 打开题目 题目源码 <?php error_reporting(0); //听说你很喜欢数学,不知道你是否爱它胜过爱flag if(!isset($_GET[c])){show_source(__FILE__); }else{//例子 c20-1$content $_GET[c];if (strlen($content) > 80) {die("…...
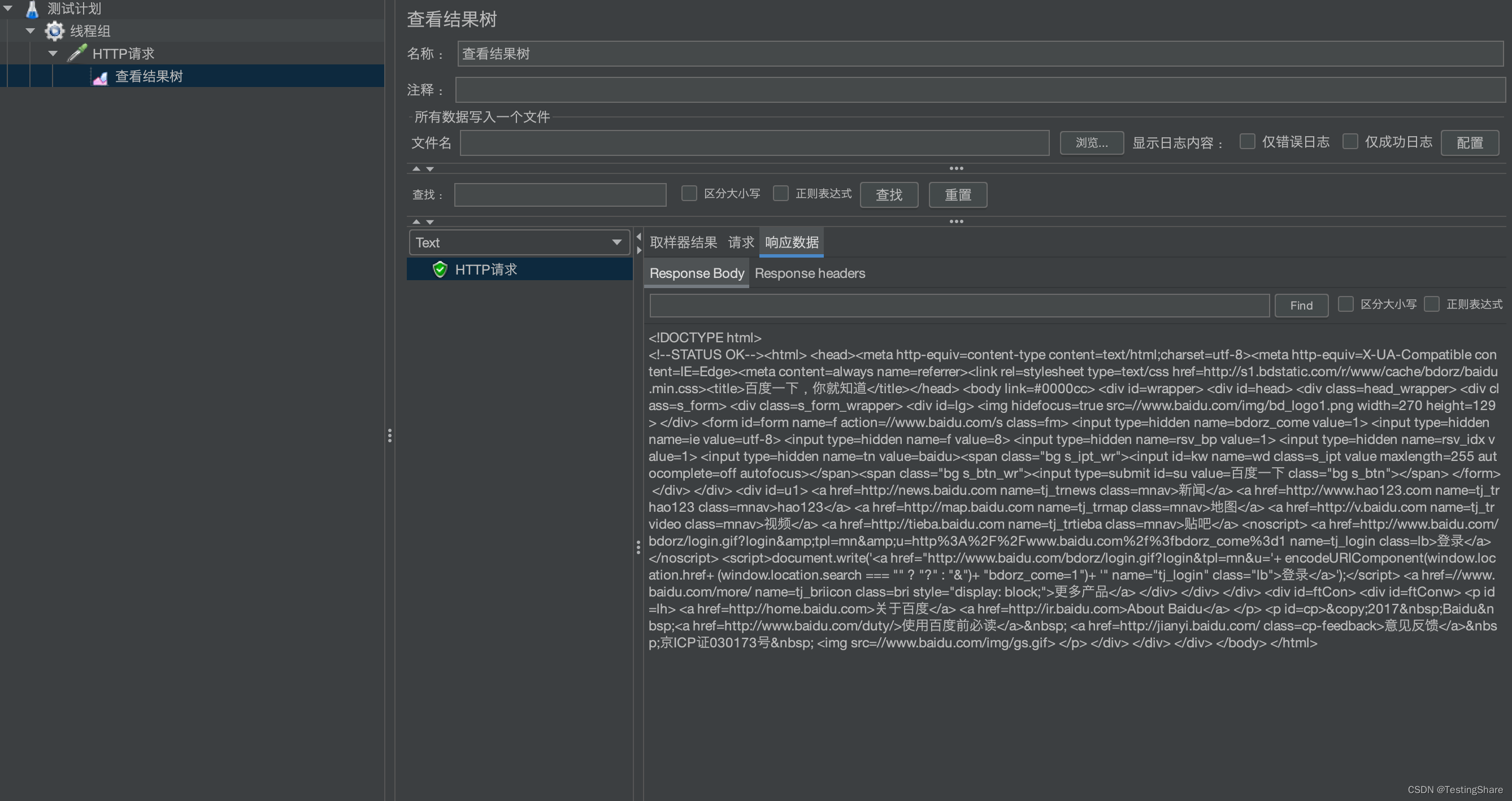
Jmeter基础(3) 发起一次请求
目录 Jmeter 一次请求添加线程组添加HTTP请求添加监听器 Jmeter 一次请求 用Jmeter进行一次请求的过程,需要几个步骤呢? 1、添加线程组2、添加HTTP请求3、添加监听器,查看结果树 现在就打开jmeter看下如何创建一个请求吧 添加线程组 用来…...
视频怎么变成gif动图?一招教你在线转换
MP4是一种常见的视频文件格式,它可以包含音频和视频数据,并支持高质量的视频压缩。MP4视频可以呈现连续的动态效果,可以包含平滑的运动、音频等多媒体元素。而GIF动图是由一系列静态图像组成的,通过快速连续播放这些帧来创造出动态…...
Leetcode2583. 二叉树中的第 K 大层和
Every day a Leetcode 题目来源:2583. 二叉树中的第 K 大层和 解法1:层序遍历 排序 先使用层序遍历计算出树的每一层的节点值的和,保存在数组 levelSum 中。然后将数组进行排序,返回第 k 大的值。需要考虑数组长度小于 k 的边…...
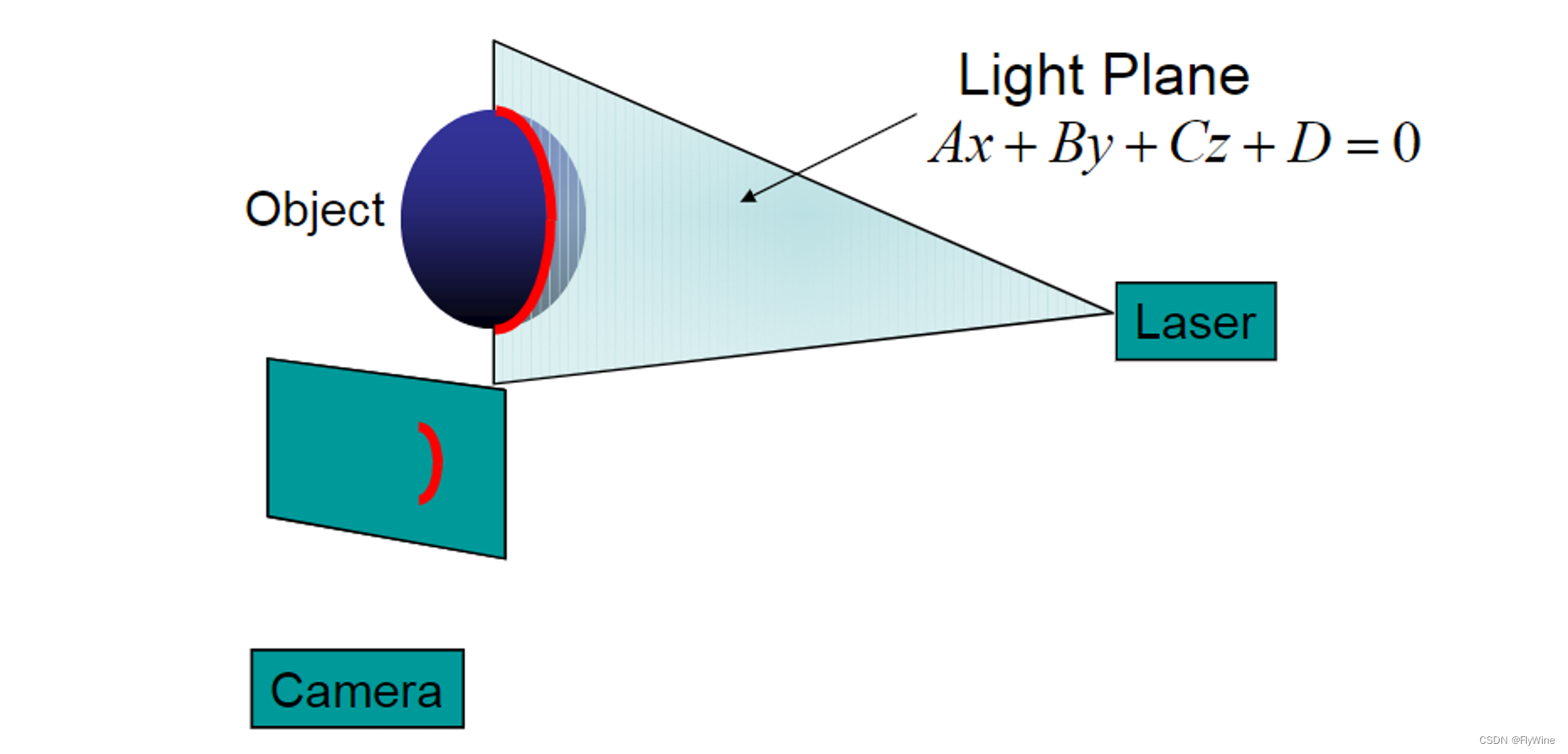
(六)激光线扫描-三维重建
本篇文章是《激光线扫描-三维重建》系列的最后一篇。 1. 基础理论 1.1 光平面 在之前光平面标定的文章中,已经提到过了,是指 激光发射器投射出一条线,形成的一个扇形区域平面就是光平面。 三维空间中平面的公式是: A X + B Y + C Z + D = 0 A X+B Y+C Z+D=0...
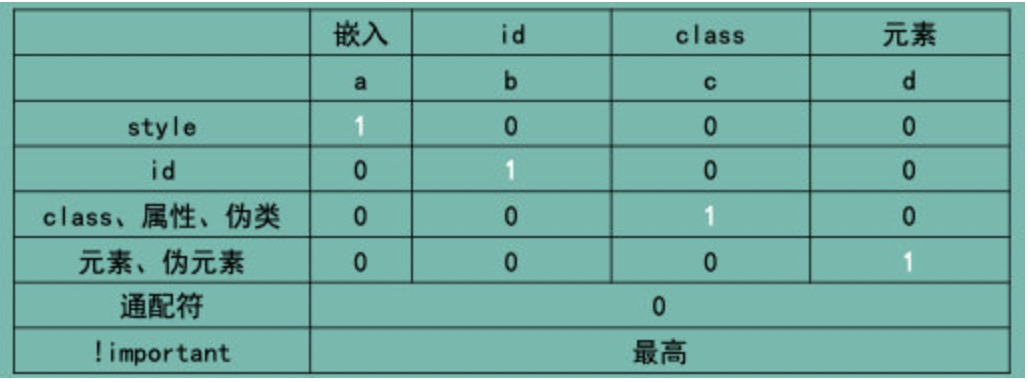
CSS 面试题汇总
CSS 面试题汇总 1. 介绍下 BFC 及其应 参考答案: 参考答案: 所谓 BFC,指的是一个独立的布局环境,BFC 内部的元素布局与外部互不影响。 触发 BFC 的方式有很多,常见的有: 设置浮动overflow 设置为 auto、scr…...

Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案
Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mountin…...

3分钟掌握跨平台模组下载神器:WorkshopDL全攻略
3分钟掌握跨平台模组下载神器:WorkshopDL全攻略 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台的游戏无法使用Steam创意工坊模组而烦恼吗…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...

MPLAB代码配置器实战:图形化配置PIC/AVR单片机外设,提升开发效率
1. 项目概述:为什么你需要关注MPLAB代码配置器如果你正在使用Microchip的PIC或AVR单片机,并且还在手动编写外设初始化代码、一遍遍翻阅数据手册核对寄存器位,那今天聊的这个工具,可能会让你有种“相见恨晚”的感觉。我说的就是MPL…...

微服务架构实战:从DDD设计到K8s部署的完整指南
1. 项目概述与核心价值最近几年,微服务架构的热度一直居高不下,从互联网大厂到初创团队,几乎人人都在谈微服务。但说实话,真正能把微服务玩转、落地,并且能稳定支撑业务发展的团队,其实并不多。很多项目要么…...

Step-by-Step知识蒸馏:让小模型学会大模型的推理过程
1. 项目概述:当“小个子”也能学会“大智慧”最近在模型压缩和知识蒸馏的圈子里,一个挺有意思的讨论点又热了起来:我们有没有可能让一个参数规模小得多的模型,通过一种更精细、更“手把手”的教学方式,达到甚至逼近那些…...

基于五年一线体验,青岛二胎家庭收纳系统的真相
一、行业痛点分析在收纳领域,二胎家庭面临着诸多核心技术挑战。数据表明,超过70%的二胎家庭在装修时未充分考虑未来的收纳需求,导致入住后空间拥挤、物品杂乱无章。青岛三木空间设计在五年的一线服务中发现,很多二胎家庭存在以下问…...

OpenAI GPT Image 2文字准确率95%,企业视觉硬核生产力4大核心升级与商业落地路径
GPT Image 2的4大核心升级能力1. 文字渲染准确率接近95%,多语言直出即用过去用AI生图,最头疼的就是文字。写个中文标题,十次有八次是乱码,英文稍微长一点也会出错。而GPT Image 2的文字渲染准确率做到了接近95%,支持中…...

影刀RPA跨境店群运营架构:基于Python的高并发环境隔离与自动化调度系统设计实战
关于我一个曾经死磕底层算法、痴迷于压榨软硬件性能的资深架构师,最后跑去给跨境工作室写店群底层自动化调度系统这件事。 很多以前在技术圈里混的同行,或者是看着我一路从后端重构做到 ImageTransPro 图像处理软件 5.0.3 这种复杂版本迭代的极客朋友们…...

ITK-SNAP医学图像分割:从临床需求到精准分析的完整指南
ITK-SNAP医学图像分割:从临床需求到精准分析的完整指南 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 面对复杂的医学影像数据,你是否曾为如何准确提取关键解剖结构而…...