【Python】 剪辑法欠采样 CNN压缩近邻法欠采样
借鉴:关于K近邻(KNN),看这一篇就够了!算法原理,kd树,球树,KNN解决样本不平衡,剪辑法,压缩近邻法 - 知乎
但是不要看他里面的代码,因为作者把代码里的一些符号故意颠倒了 ,比如“==”改成“!=”,还有乱加“~”,看明白逻辑才能给他改过来
一、剪辑法
当训练集数据中存在一部分不同类别数据的重叠时(在一部分程度上说明这部分数据的类别比较模糊),这部分数据会对模型造成一定的过拟合,那么一个简单的想法就是将这部分数据直接剔除掉即可,也就是剪辑法。
剪辑法将训练集 D 随机分成两个部分,一部分作为新的训练集 Dtrain,一部分作为测试集 Dtest,然后基于 Dtrain,使用 KNN 的方法对 Dtest 进行分类,并将其中分类错误的样本从整体训练集 D 中剔除掉,得到 Dnew。
由于对训练集 D 的划分是随机划分,难以保证数据重叠部分的样本在第一次剪辑时就被剔除,因此在得到 Dnew 后,可以对 Dnew 继续进行上述操作数次,这样可以得到一个比较清爽的类别分界。
效果如下图:

附上可直接运行的代码:
from sklearn import datasets
import matplotlib.pyplot as pyplot
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier as KNN
import numpy as np
from collections import Counter
from numpy import where# make_classification用于手动构造数据
# 1000个样本,分成4类
X, y = datasets.make_classification(n_samples=1000, n_features=2,n_informative=2, n_redundant=0, n_repeated=0,n_classes=4, n_clusters_per_class=1)# # # 画出二维散点图
# for label, _ in counter.items():
# row_ix = where(y == label)[0]
# pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
# pyplot.legend()
# pyplot.show()# 剪辑10次
for i in range(10):x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.5)k = 5KNN_clf = KNN(n_neighbors=k)KNN_clf.fit(x_train, y_train) # 用训练集训练KNNy_predict = KNN_clf.predict(x_test) # 用测试集测试cond = y_predict == y_testx_test = x_test[cond] # 把预测错误的从整体数据集中剔除掉y_test = y_test[cond] # 把预测错误的从整体数据集中剔除掉X = np.vstack([x_train, x_test]) # 为下一次循环做准备(剔除掉本轮预测错误的y = np.hstack([y_train, y_test]) # 为下一次循环做准备(剔除掉本轮预测错误的# summarize the new class distribution
counter = Counter(y)
print(counter)# 画出二维散点图
for label, _ in counter.items():row_ix = where(y == label)[0]pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()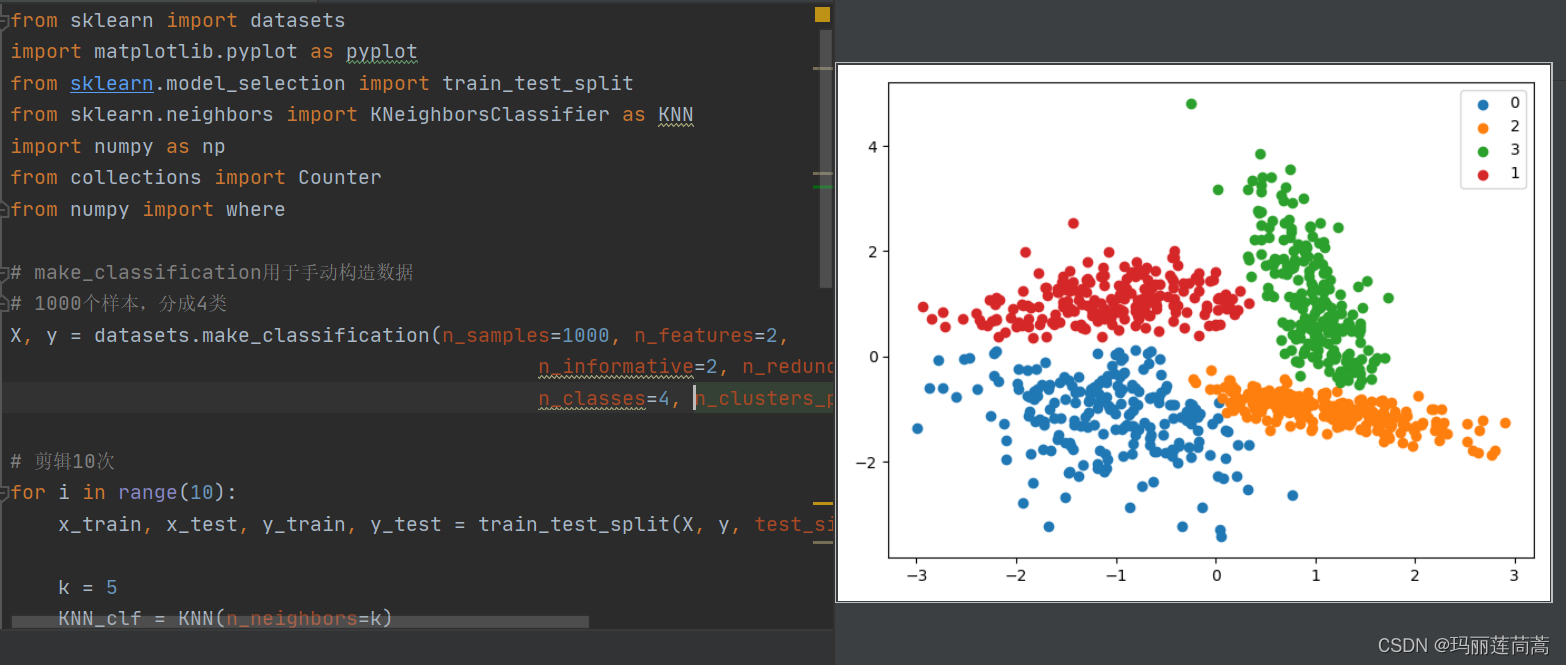
以上使用了k=20的参数进行剪辑的结果,循环了10次,一般而言,k越大,被抛弃的样本会越多,因为被分类的错误的概率更大。
二、CNN压缩近邻法欠采样
压缩近邻法的想法是认为同一类型的样本大量集中在类簇的中心,而这些集中在中心的样本对分类没有起到太大的作用,因此可以舍弃掉这些样本。
其做法是将训练集随机分为两个部分,第一个部分为 store,占所有样本的 10% 左右,第二个部分为 grabbag,占所有样本的 90% 左右,然后将 store 作为训练集训练 KNN 模型,grabbag 作为测试集,将分类错误的样本从 grabbag 中移动到 store 里,然后继续用增加了样本的 store 和减少了样本的 grabbag 再次训练和测试 KNN 模型,直到 grabbag 中所有样本被分类正确,或者 grabbag 中样本数为0。
在压缩结束之后,store 中存储的是初始化时随机选择的 10% 左右的样本,以及在之后每一次循环中被分类错误的样本,这些被分类错误的样本集中在类簇的边缘,认为是对分类作用较大的样本。
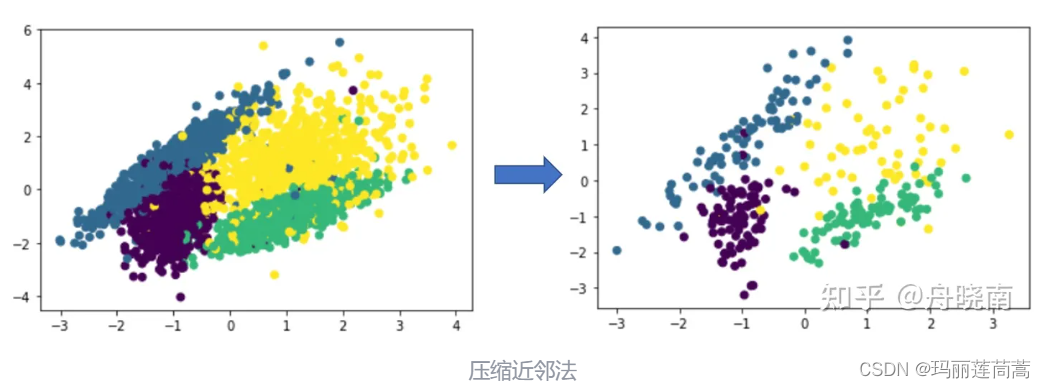
CNN欠采样已经有相应的Python实现库了,相应的方法是CondensedNearestNeighbour(),下面是可直接运行的代码。
# Undersample and plot imbalanced dataset with the Condensed Nearest Neighbor Rule
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.under_sampling import CondensedNearestNeighbour
from matplotlib import pyplot
from numpy import where# make_classification方法用于生成分类任务的人造数据集
# X是数据,几维都可以,n_features=4表示4维
# y用0/1表示类别,weights调整0和1的占比
X, y = make_classification(n_samples=500, n_classes=2, n_features=3, n_redundant=0,# n_clusters_per_class表示每个类别多少簇 # flip_y噪声,增加分类难度n_clusters_per_class=2, weights=[0.5], flip_y=0, random_state=1)# summarize class distribution
counter = Counter(y) # {0: 990, 1: 10} counter是一个字典,value存储类别,key存储类别个数
print(counter)# ==================CNN有直接可以调用的包 n_neighbors设置k值,k值越小越省时间,就设置为1吧
undersample = CondensedNearestNeighbour(n_neighbors=1)
# transform the dataset
X, y = undersample.fit_resample(X, y)# summarize the new class distribution
counter = Counter(y)
print(counter)# scatter plot of examples by class label
for label, _ in counter.items():row_ix = where(y == label)[0]pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()但是我觉得这个CondensedNearestNeighbour()方法的可操作性太低,所以没用这个方法,而是根据CNN的原理(CNN底层是训练KNN)去写的
from sklearn import datasets
import matplotlib.pyplot as pyplot
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier as KNN
import numpy as np
from collections import Counter
from numpy import where# make_classification用于手动构造数据
# 1000个样本,分成4类
X, y = datasets.make_classification(n_samples=1000, n_features=2,n_informative=2, n_redundant=0, n_repeated=0,n_classes=4, n_clusters_per_class=1, random_state=1)
counter = Counter(y)
# 画出二维散点图
for label, _ in counter.items():row_ix = where(y == label)[0]pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()# 10%作为训练集,90%作为测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.9)while True:k = 1KNN_clf = KNN(n_neighbors=k)KNN_clf.fit(x_train, y_train)y_predict = KNN_clf.predict(x_test)cond = y_predict == y_test # cond记录分类的对与错,分类错是False,正确是True# 都分类正确,退出if cond.all():print('所有测试集都分类正确,CNN正常结束')breakx_train = np.vstack([x_train, x_test[~cond]]) # 把分类错误(cond的值是False)的移动到训练集里y_train = np.hstack([y_train, y_test[~cond]])x_test = x_test[cond] # 把分类对的继续作为下一轮的测试集y_test = y_test[cond]if len(x_test) == 0:print("所有样本都能做到分类错误,也就是结果集=原始数据集,一般不会出现这种情况")break# summarize the new class distribution
counter = Counter(y_train)
print(counter)# 画出二维散点图
for label, _ in counter.items():row_ix = where(y_train == label)[0]pyplot.scatter(x_train[row_ix, 0], x_train[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()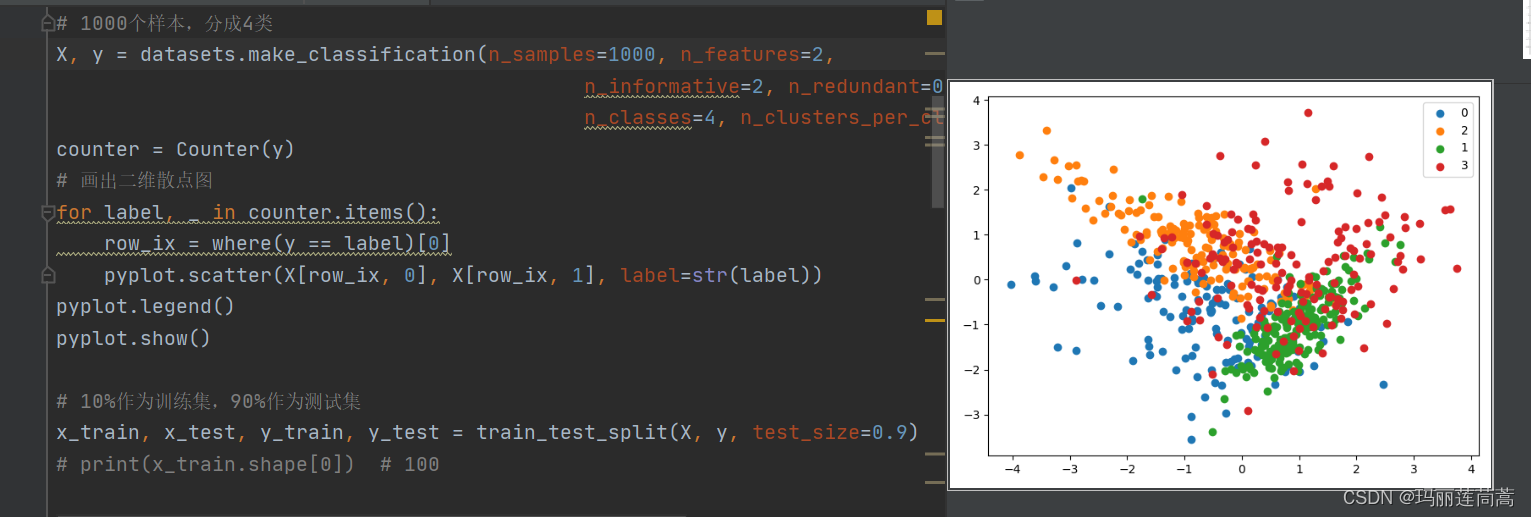
2.1 改进版——指定压缩后样本大小的CNN
在如下代码中,用sampleNum指定全体样本数量,用endNum指定压缩后样本数量
from sklearn import datasets
import matplotlib.pyplot as pyplot
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier as KNN
import numpy as np
from collections import Counter
from numpy import wheresampleNum = 1000
endNum = 500
k = 1 # KNN算法的K值
# make_classification用于手动构造数据
# 1000个样本,分成4类
X, y = datasets.make_classification(n_samples=sampleNum, n_features=2,n_informative=2, n_redundant=0, n_repeated=0,n_classes=4, n_clusters_per_class=1, random_state=1)
# counter = Counter(y)
# # 画出二维散点图
# for label, _ in counter.items():
# row_ix = where(y == label)[0]
# pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
# pyplot.legend()
# pyplot.show()# 10%作为训练集,90%作为测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.9)
# print(x_train.shape[0]) # 100nowNum = x_train.shape[0] # 用来控制 训练集/筛选后的样本数 满足resultNum就停下, 初始有x_train这么多个while True:KNN_clf = KNN(n_neighbors=k)KNN_clf.fit(x_train, y_train)y_predict = KNN_clf.predict(x_test)cond = y_predict == y_test # cond记录分类的对与错,分类错是False,正确是True# 都分类正确,退出if cond.all():print('所有测试集都分类正确,CNN自动结束,但是结果集没凑够呢!')break# 如果结果集数量不够要求的endNum,继续下一轮if nowNum+y_test[~cond].shape[0] < endNum:nowNum = nowNum+y_test[~cond].shape[0]print("目前结果集数量:", nowNum)x_train = np.vstack([x_train, x_test[~cond]]) # 把分类错误(cond的值是False)的移动到训练集里y_train = np.hstack([y_train, y_test[~cond]])x_test = x_test[cond] # 把分类对的继续作为下一轮的测试集y_test = y_test[cond]# 如果结果集数量超过endNum,我们只要测试集里分类错误的前endNum-nowNum个else:# 记录前endNum-nowNum个的位置(截取位置condCut = 0 # 记录截取位置for i in range(cond.shape[0]):if not cond[i]:nowNum = nowNum + 1if nowNum == endNum:condCut = i # 在cond[condCut]处刚好是我们要的第endNum个结果集样本break# 把cond[condCut]后面的都设置成Truecond[condCut+1:] = Truex_train = np.vstack([x_train, x_test[~cond]]) # 把分类错误(cond的值是False)的移动到训练集里y_train = np.hstack([y_train, y_test[~cond]])print("结果集的数量为", x_train.shape[0], "满足endNum=", endNum)breakif len(x_test) == 0:print("所有样本都能做到分类错误,也就是结果集=原始数据集,一般不会出现这种情况")break# summarize the new class distribution
counter = Counter(y_train)
print(counter)# 画出二维散点图
for label, _ in counter.items():row_ix = where(y_train == label)[0]pyplot.scatter(x_train[row_ix, 0], x_train[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()相关文章:
【Python】 剪辑法欠采样 CNN压缩近邻法欠采样
借鉴:关于K近邻(KNN),看这一篇就够了!算法原理,kd树,球树,KNN解决样本不平衡,剪辑法,压缩近邻法 - 知乎 但是不要看他里面的代码,因为作者把代码…...
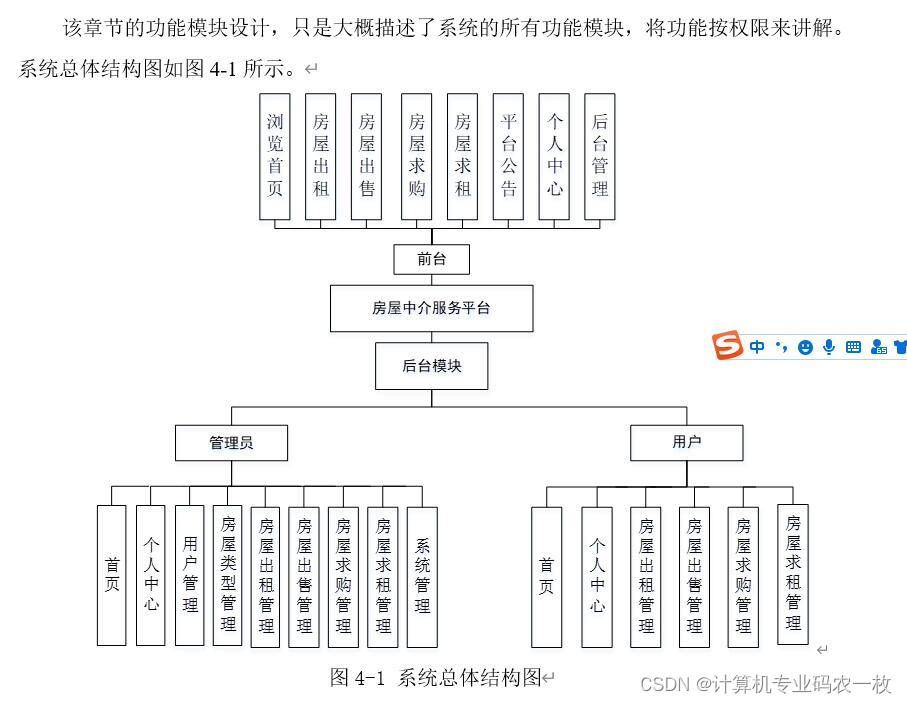
springmvc+ssm+springboot房屋中介服务平台的设计与实现 i174z
本论文拟采用计算机技术设计并开发的房屋中介服务平台,主要是为用户提供服务。使得用户可以在系统上查看房屋出租、房屋出售、房屋求购、房屋求租,管理员对信息进行统一管理,与此同时可以筛选出符合的信息,给笔者提供更符合实际的…...

挑战30天学完Python:Day19 文件处理
📘 Day 19 🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点…...
Spring Boot application.properties和application.yml文件的配置
在Spring Boot中,application.properties 和 application.yml 文件用于配置应用程序的各个方面,如服务器端口、数据库连接、日志级别等。这两个文件是Spring Boot的配置文件,位于 src/main/resources 目录下。 application.properties 示例 …...

Unity单元测试
Unity单元测试是一个专门用于嵌入式单元测试的库, 现在简单讲下移植以及代码结构. 源码地址: GitHub - ThrowTheSwitch/Unity: Simple Unit Testing for C 1.我们只需要移植三个文件即可: unity.c, unity.h, unity_internals.h 2.然后添加需要测试的函数. 3.在main.c中添加…...

Spring Bean 的生命周期了解么?
Spring Bean 的生命周期基本流程 一个Spring的Bean从出生到销毁的全过程就是他的整个生命周期, 整个生命周期可以大致分为3个大的阶段 : 创建 使用 销毁 还可以分为5个小步骤 : 实例化(Bean的创建) , 初始化赋值, 注册Destruction回调 , Bean的正常使用 以及 Bean的销毁 …...

.ryabina勒索病毒数据怎么处理|数据解密恢复
导言: 随着网络安全威胁的不断增加,勒索软件已成为严重的威胁之一,.ryabina勒索病毒是其中之一。本文将介绍.ryabina勒索病毒的特点、数据恢复方法和预防措施,以帮助用户更好地应对这一威胁。当面对被勒索病毒攻击导致的数据文件…...
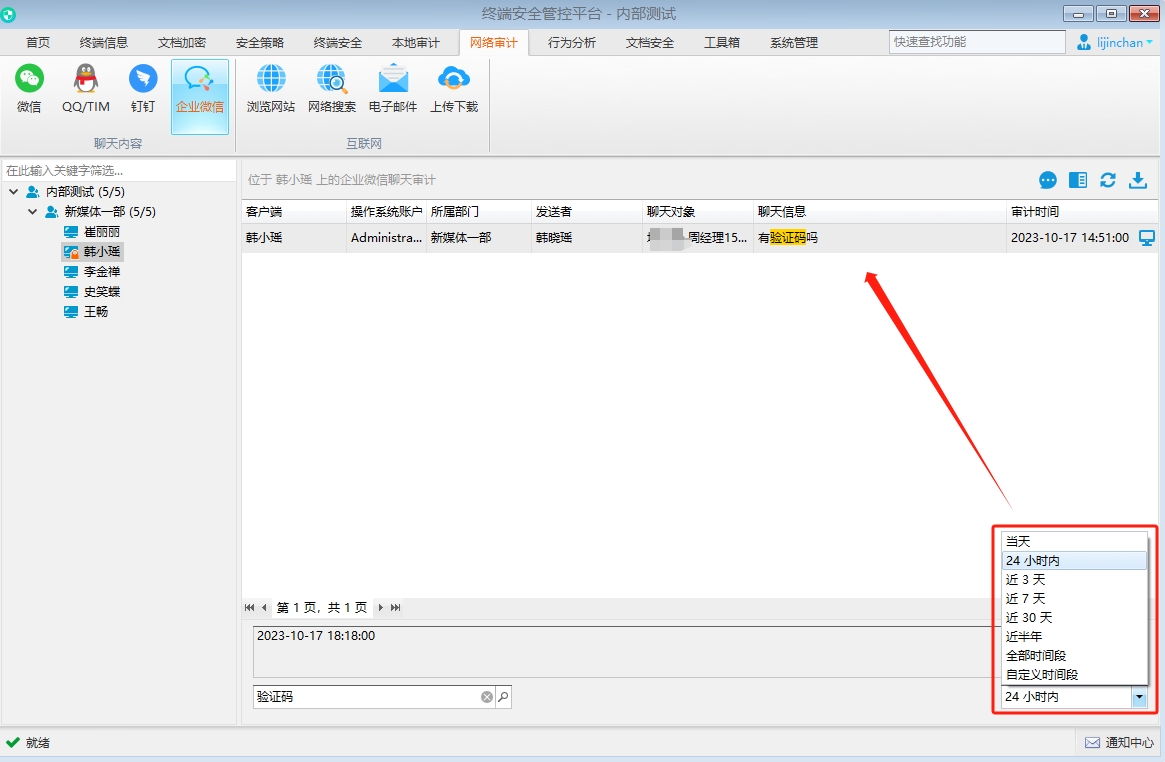
上网行为监控软件能够看到聊天内容吗
随着信息技术的不断发展,上网行为监控软件在企业网络安全管理中扮演着越来越重要的角色。 这类软件主要用于监控员工的上网行为,以确保工作效率和网络安全。 而在这其中,域智盾软件作为一款知名的上网行为监控软件,其功能和使用…...

Java知识点一
hello,大家好!我们今天开启Java语言的学习之路,与C语言的学习内容有些许异同,今天我们来简单了解一下Java的基础知识。 一、数据类型 分两种:基本数据类型 引用数据类型 (1)整型 八种基本数…...
Django学习笔记-forms使用
1.创建forms.py文件,导入包 from django import forms from django.forms import fields from django.forms import widgets2. 创建EmployeeForm,继承forms.Form 3.创建testform.html文件 4.urls.py添加路由 5.views中导入forms 创建testform,编写代码 1).如果请求方式为GET,…...
)
BM100 设计LRU缓存结构(java实现)
一、题目 设计LRU(最近最少使用)缓存结构,该结构在构造时确定大小,假设大小为 capacity ,操作次数是 n ,并有如下功能: Solution(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存get(key):如果关键字 key …...
论文阅读——ONE-PEACE
ONE-PEACE: EXPLORING ONE GENERAL REPRESENTATION MODEL TOWARD UNLIMITED MODALITIES 适应不同模态并且支持多模态交互。 预训练任务不仅能提取单模态信息,还能模态间对齐。 预训练任务通用且直接,使得他们可以应用到不同模态。 各个模态独立编码&am…...

围剿尚未终止 库迪深陷瑞幸9.9阳谋
文|智能相对论 作者|霖霖 总能被“累了困了”的打工人优先pick的咖啡,刚复工就顺利站上话题C位。 #瑞幸9.9元一杯活动缩水#的话题才爬上新浪微博热搜,“库迪咖啡河北分公司运营总监带头坑害河北联营商”的实名举报帖就出现在了小红书,一时…...
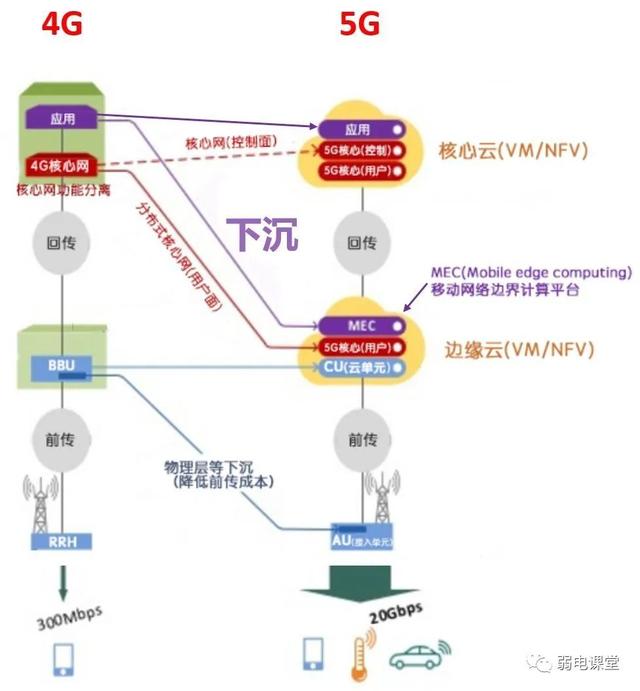
5G网络(接入网+承载网+核心网)
5G网络(接入网承载网核心网) 一、5G网络全网架构图 这张图分为左右两部分,右边为无线侧网络架构,左边为固定侧网络架构。 无线侧:手机或者集团客户通过基站接入到无线接入网,在接入网侧可以通过RTN或者IP…...
学习Markdown
https://shadows.brumm.af 欢迎使用Markdown编辑器 你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。 新的改变 我们对Markdown编辑器进行了一些…...
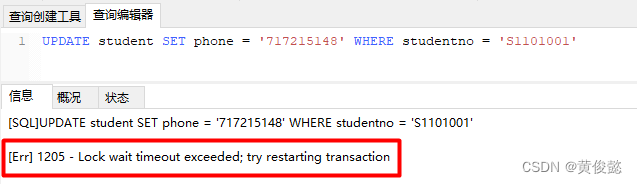
MySQL知识点总结(五)——锁
MySQL知识点总结(五)——锁 锁分类表锁 & 行锁如何添加表锁?如何添加行锁? 读锁 & 写锁行锁 & 间隙锁(gap lock)& 临键锁(next-key lock) 加锁机制分析可重复读隔离…...
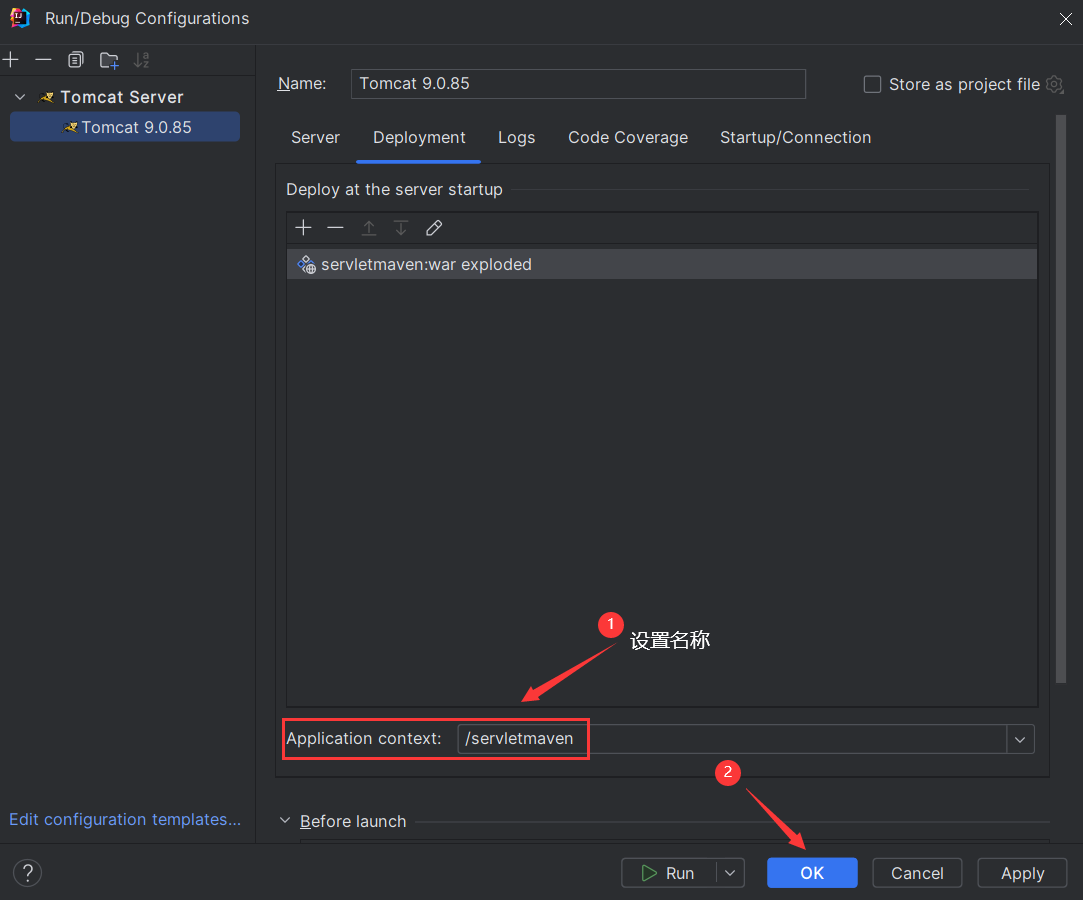
IDEA 2023.2 配置 JavaWeb 工程
目录 1 不使用 Maven 创建 JavaWeb 工程 1.1 新建一个工程 1.2 配置 Tomcat 1.3 配置模块 Web 2 使用 Maven 配置 JavaWeb 工程 2.1 新建一个 Maven 工程 2.2 配置 Tomcat 💥提示:IDEA 只有专业版才能配置 JavaWeb 工程,若是社区版&am…...
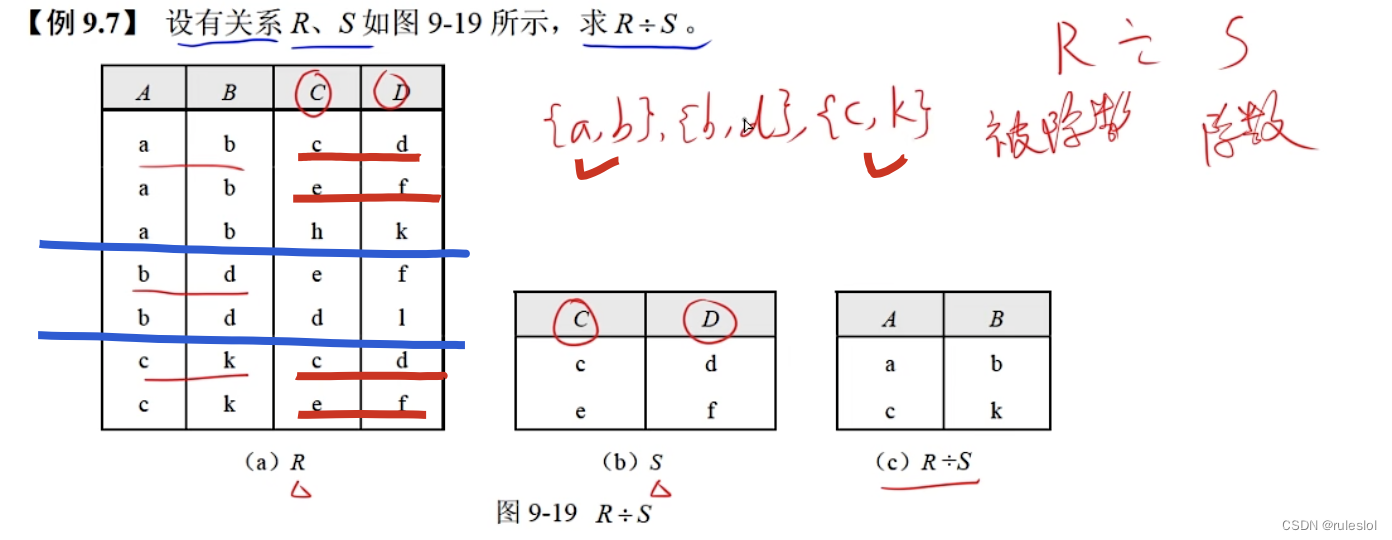
软考40-上午题-【数据库】-关系代数运算2-专门的集合运算
一、专门的集合运算 1、投影 示例: 可以用属性名进行投影,也可以用列的序号进行投影。 2、选择 例题 1、笛卡尔积 2、投影 3、选择 3、连接 第一步都要算:笛卡尔积。 3-1、θ连接 示例: 3-2、等值连接 示例: 3-3、自…...
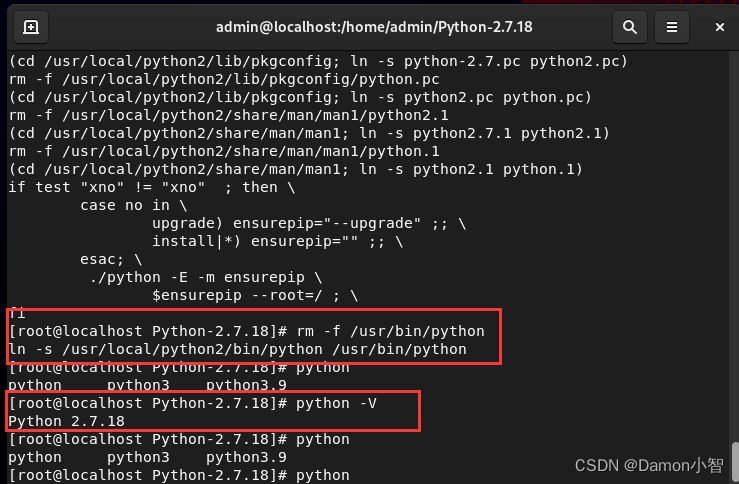
RHEL9安装Python2.7
RHEL9作为2022年5月新推出的版本,较RHEL8有了很多地方的改进,而且自带很多包,功能非常强大,稳定性和流畅度也较先前版本有了很大的提升。RHEL9自带python3.9,但是过高版本的python不可避免地会导致一些旧版本包地不兼容…...
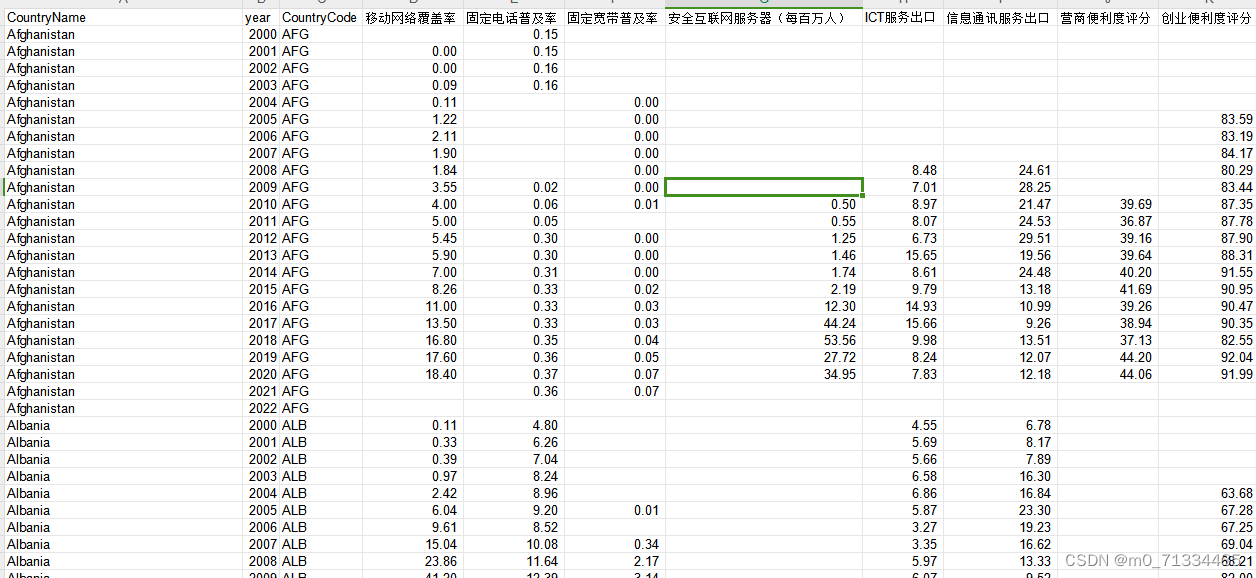
更新至2022年世界各国数字经济发展相关指标(23个指标)
更新至2022年世界各国数字经济发展相关指标(23个指标) 1、时间:具体指标时间见下文 2、来源:WDI、世界银行、WEF、UNCTAD、SJR、国际电联 3、指标:移动网络覆盖率(2000-2022)、固定电话普及率…...

5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager
5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是经常在右键文件时,面对几十个…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...

如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南
如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

Copaw_dev:AI编程助手增强框架,提升代码生成与自动化开发效率
1. 项目概述:Copaw_dev 是什么,以及它为何值得关注如果你是一名开发者,尤其是对自动化、代码生成或者AI辅助编程感兴趣,那么“Copaw_dev”这个项目标题很可能已经引起了你的注意。乍一看,这个由“G-Divine”维护的项目…...

基于意图与技能解耦的智能对话系统构建指南
1. 项目概述:一个意图与技能驱动的AI对话引擎最近在折腾AI应用开发,特别是对话型AI助手时,发现一个核心痛点:如何让AI不仅能理解用户说了什么(意图识别),还能精准地调用相应的功能(技…...

从零构建现代化工作流引擎:架构、实战与生产级部署指南
1. 项目概述:一个为专业开发者打造的现代化工作流引擎最近在GitHub上看到一个挺有意思的项目,叫rohitg00/pro-workflow。光看名字,你可能觉得这又是一个“工作流”工具,市面上这类工具已经多如牛毛了。但当我深入去研究它的源码、…...

开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300%
开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300% 【免费下载链接】freerouting Advanced PCB auto-router 项目地址: https://gitcode.com/gh_mirrors/fr/freerouting FreeRouting是一款功能强大的开源PCB自动布线工具,它能帮…...
)
Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包)
更多请点击: https://intelliparadigm.com 第一章:Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包) Tea印相(TeaYinXiang)在 v…...

基于React的记忆管理UI组件库:openclaw-memory-ui实战指南
1. 项目概述:一个为记忆管理而生的开源UI组件库最近在折腾一个需要处理大量结构化记忆数据的项目,比如知识库、笔记应用或者智能助手的历史对话管理。这类应用的核心痛点在于,数据本身是复杂的、多维的,但传统的列表或表格展示方式…...