Apache celeborn 安装及使用教程
1.下载安装包
https://celeborn.apache.org/download/
测0.4.0时出现https://github.com/apache/incubator-celeborn/issues/835

2.解压
tar -xzvf apache-celeborn-0.3.2-incubating-bin.tgz
3.修改配置文件
cp celeborn-env.sh.template celeborn-env.shcp log4j2.xml.template log4j2.xmlcp celeborn-defaults.conf.template cp celeborn-defaults.conf3.1修改celeborn-env.sh
CELEBORN_MASTER_MEMORY=2g
CELEBORN_WORKER_MEMORY=2g
CELEBORN_WORKER_OFFHEAP_MEMORY=4g3.2 修改celeborn-defaults.conf
# used by client and worker to connect to master
celeborn.master.endpoints 10.67.78.xx:9097# used by master to bootstrap
celeborn.master.host 10.67.78.xx
celeborn.master.port 9097celeborn.metrics.enabled true
celeborn.worker.flusher.buffer.size 256k# If Celeborn workers have local disks and HDFS. Following configs should be added.
# If Celeborn workers have local disks, use following config.
# Disk type is HDD by defaut.
#celeborn.worker.storage.dirs /mnt/disk1:disktype=SSD,/mnt/disk2:disktype=SSD# If Celeborn workers don't have local disks. You can use HDFS.
# Do not set `celeborn.worker.storage.dirs` and use following configs.
celeborn.storage.activeTypes HDFS
celeborn.worker.sortPartition.threads 64
celeborn.worker.commitFiles.timeout 240s
celeborn.worker.commitFiles.threads 128
celeborn.master.slot.assign.policy roundrobin
celeborn.rpc.askTimeout 240s
celeborn.worker.flusher.hdfs.buffer.size 4m
celeborn.storage.hdfs.dir hdfs://10.67.78.xx:8020/celeborn
celeborn.worker.replicate.fastFail.duration 240s# If your hosts have disk raid or use lvm, set celeborn.worker.monitor.disk.enabled to false
celeborn.worker.monitor.disk.enabled false4.复制到其他节点
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx1:/root/
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx2:/root/因为在配置文件中已经配置了master 所以启动matster和worker即可。
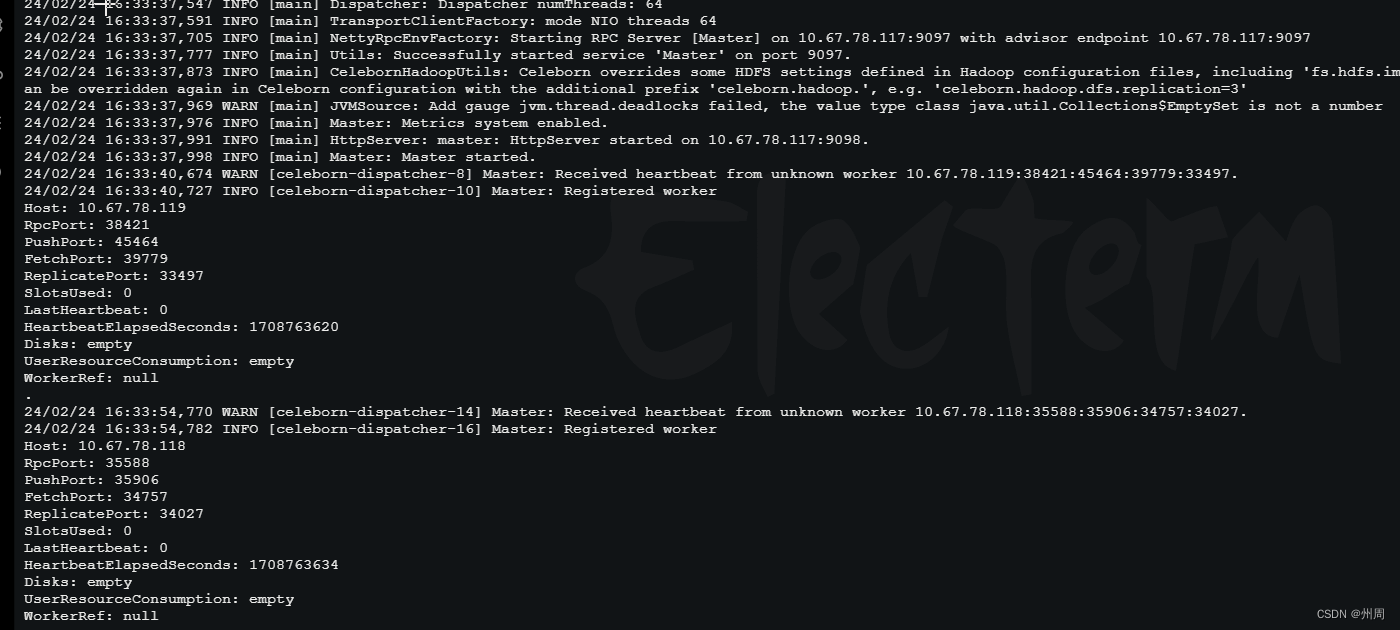
5.启动master和worker
cd $CELEBORN_HOME
./sbin/start-master.sh./sbin/start-worker.sh celeborn://<Master IP>:<Master Port>之后在master的日志中看woker是否注册上
6.在 spark客户端使用
复制 $CELEBORN_HOME/spark/*.jar 到 $SPARK_HOME/jars/
修改spark-defaults.conf
# Shuffle manager class name changed in 0.3.0:
# before 0.3.0: org.apache.spark.shuffle.celeborn.RssShuffleManager
# since 0.3.0: org.apache.spark.shuffle.celeborn.SparkShuffleManager
spark.shuffle.manager org.apache.spark.shuffle.celeborn.SparkShuffleManager
# must use kryo serializer because java serializer do not support relocation
spark.serializer org.apache.spark.serializer.KryoSerializer# celeborn master
spark.celeborn.master.endpoints clb-1:9097,clb-2:9097,clb-3:9097
# This is not necessary if your Spark external shuffle service is Spark 3.1 or newer
spark.shuffle.service.enabled false# options: hash, sort
# Hash shuffle writer use (partition count) * (celeborn.push.buffer.max.size) * (spark.executor.cores) memory.
# Sort shuffle writer uses less memory than hash shuffle writer, if your shuffle partition count is large, try to use sort hash writer.
spark.celeborn.client.spark.shuffle.writer hash# We recommend setting spark.celeborn.client.push.replicate.enabled to true to enable server-side data replication
# If you have only one worker, this setting must be false
# If your Celeborn is using HDFS, it's recommended to set this setting to false
spark.celeborn.client.push.replicate.enabled true# Support for Spark AQE only tested under Spark 3
# we recommend setting localShuffleReader to false to get better performance of Celeborn
spark.sql.adaptive.localShuffleReader.enabled false# If Celeborn is using HDFS
spark.celeborn.storage.hdfs.dir hdfs://<namenode>/celeborn# we recommend enabling aqe support to gain better performance
spark.sql.adaptive.enabled true
spark.sql.adaptive.skewJoin.enabled true# Support Spark Dynamic Resource Allocation
# Required Spark version >= 3.5.0 注意spark版本是否满足
spark.shuffle.sort.io.plugin.class org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO
# Required Spark version >= 3.4.0, highly recommended to disable 注意spark版本是否满足
spark.dynamicAllocation.shuffleTracking.enabled false
7.启动spark-shell
./bin/spark-shell spark.sparkContext.parallelize(1 to 1000, 1000).flatMap(_ => (1 to 100).iterator.map(num => num)).repartition(10).count相关文章:
Apache celeborn 安装及使用教程
1.下载安装包 https://celeborn.apache.org/download/ 测0.4.0时出现https://github.com/apache/incubator-celeborn/issues/835 2.解压 tar -xzvf apache-celeborn-0.3.2-incubating-bin.tgz 3.修改配置文件 cp celeborn-env.sh.template celeborn-env.shcp log4j2.xml.…...

数据保护:如何有效应对.BecSec-P-XXXXXXXX勒索病毒的威胁
导言: 随着网络安全威胁的不断增加,勒索软件成为了网络犯罪分子的一种常见手段之一。.BecSec-P-XXXXXXXX勒索病毒(简称.BecSec勒索病毒)作为其中之一,对用户的数据安全构成了严重威胁。本文91数据恢复将介绍.BecSec勒…...
-继承的优缺点)
流畅的Python(十二)-继承的优缺点
一、核心要义 1. 子类化内置类型的缺点 2.多重继承和方法解析顺序 二、代码示例 1. 子类化内置类型的缺点 #!/usr/bin/env python # -*- coding: utf-8 -*- # Time : 2024/2/24 7:29 # Author : Maple # File : 01-子类化内置类型的问题.py # Software: PyCharm fr…...
机器学习基础(三)监督学习的进阶探索
导语:上一节我们深入地探讨监督学习和非监督学习的知识,重点关注它们的理论基础、常用算法及实际应用场景,详情可见: 机器学习基础(二)监督与非监督学习-CSDN博客文章浏览阅读769次,点赞15次&a…...

avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目
avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目 avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目avidemux下载avidemux源代码参考资料 avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目 avidemux下载 avidemux …...
RisingWave最佳实践-利用Dynamic filters 和 Temporal filters 实现监控告警
心得的体会 刚过了年刚开工,闲暇之余调研了分布式SQL流处理数据库–RisingWave,本人是Flink(包括FlinkSQL和Flink DataStream API)的资深用户,但接触到RisingWave令我眼前一亮,并且拿我们生产上的监控告警…...

【Qt学习】QRadioButton 的介绍与使用(性别选择、模拟点餐)
文章目录 介绍实例使用实例1(性别选择 - 单选 隐藏)实例2(模拟点餐,多组单选) 相关资源文件 介绍 这里简单对QRadioButton类 进行介绍: QRadioButton 继承自 QAbstractButton ,用于创建单选按…...

基于java springboot的图书管理系统设计和实现
基于java springboot的图书管理系统设计和实现 博主介绍:5年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获取源码联…...
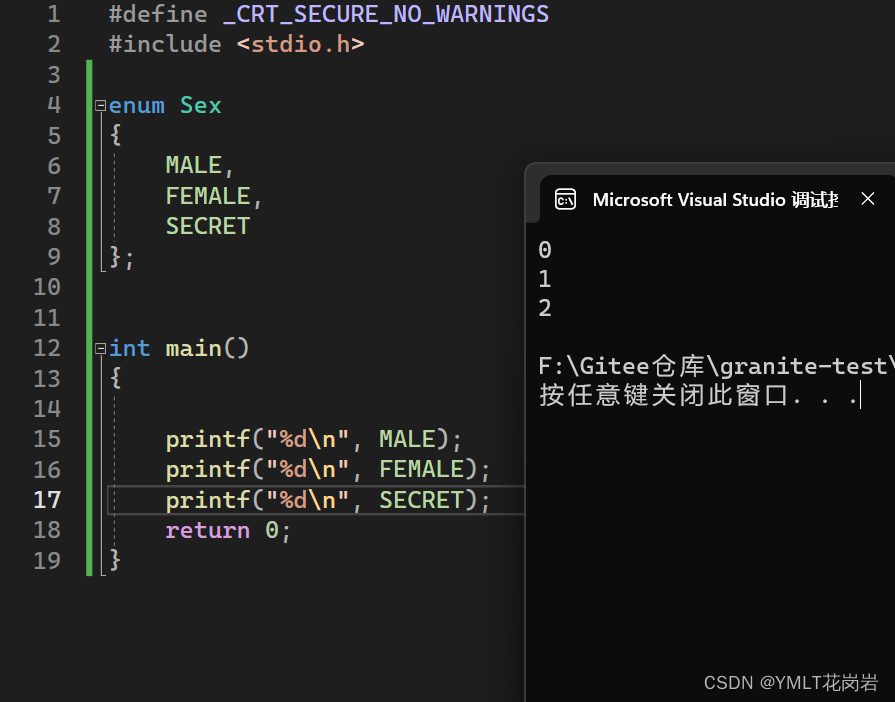
自定义类型:联合和枚举
目录 1. 联合体 1.1 联合体类型的声明及特点 1.2 相同成员的结构体和联合体对比 1.3 联合体大小的计算 1.4 联合体的应用举例 2. 枚举类型 2.1 枚举类型的声明 2.2 枚举类型的优点 1. 联合体 1.1 联合体类型的声明及特点 像结构体一样,联合体也是由一个或…...

每日一学—由面试题“Redis 是否为单线程”引发的思考
文章目录 📋 前言🌰 举个例子🎯 什么是 Redis(知识点补充)🎯 Redis 中的多线程🎯 I/O 多线程🎯 Redis 中的多进程📝 结论🎯书籍推荐🔥参与方式 &a…...
chatGPT PLUS 绑卡提示信用卡被拒的解决办法
chatGPT PLUS 绑卡提示信用卡被拒的解决办法 一、 ChatGPT Plus介绍 作为人工智能领域的一项重要革新,ChatGPT Plus的上线引起了众多用户的关注,其背后的OpenAI表现出傲娇的态度,被誉为下一个GTP 4.0。总的来说,ChatGPT Plus的火…...

opencv鼠标操作与响应
//鼠标事件 Point sp(-1, -1); Point ep(-1, -1); Mat temp; static void on_draw(int event, int x, int y, int flags, void *userdata) {Mat image *((Mat*)userdata);if (event EVENT_LBUTTONDOWN) {sp.x x;sp.y y;std::cout << "start point:"<<…...
vue里echarts的使用:画饼图和面积折线图
vue里echarts的使用,我们要先安装echarts,然后在main.js里引入: //命令安装echarts npm i echarts//main.js里引入挂载到原型上 import echarts from echarts Vue.prototype.$echarts = echarts最终我们实现的效果如下: 头部标题这里我们封装了一个全局公共组件common-he…...
插件unplugin-auto-import的使用)
个人建站前端篇(六)插件unplugin-auto-import的使用
vue3日常项目中定义变量需要引入ref,reactive等等比较麻烦,可以通过unplugin-auto-import给我们自动引入 * unplugin-auto-import 解决了vue3-hook、vue-router、useVue等多个插件的自动导入,也支持自定义插件的自动导入,是一个功能强大的typ…...
【Python】 剪辑法欠采样 CNN压缩近邻法欠采样
借鉴:关于K近邻(KNN),看这一篇就够了!算法原理,kd树,球树,KNN解决样本不平衡,剪辑法,压缩近邻法 - 知乎 但是不要看他里面的代码,因为作者把代码…...
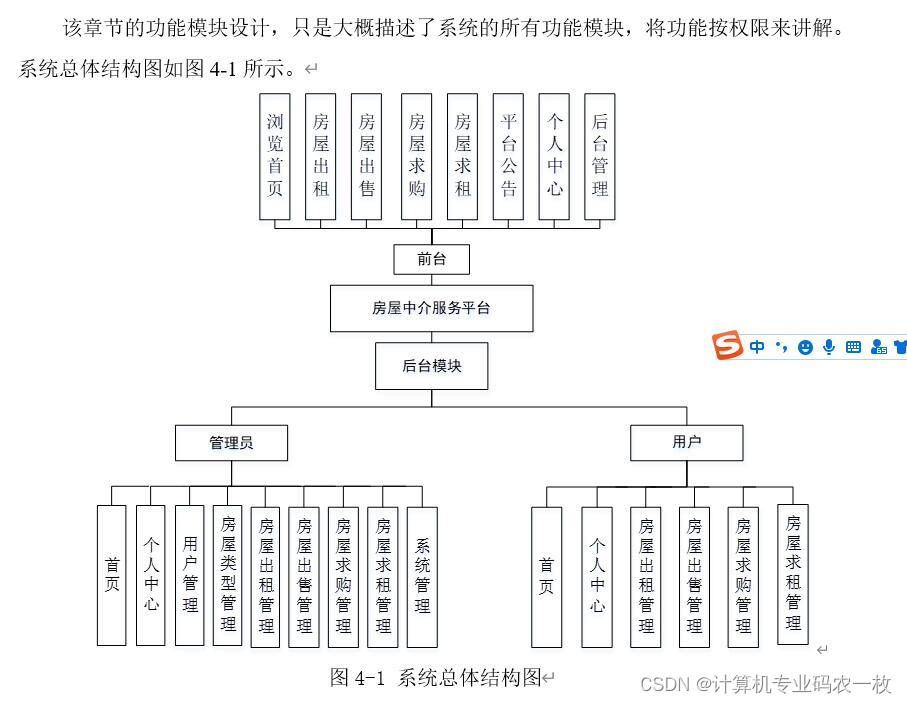
springmvc+ssm+springboot房屋中介服务平台的设计与实现 i174z
本论文拟采用计算机技术设计并开发的房屋中介服务平台,主要是为用户提供服务。使得用户可以在系统上查看房屋出租、房屋出售、房屋求购、房屋求租,管理员对信息进行统一管理,与此同时可以筛选出符合的信息,给笔者提供更符合实际的…...

挑战30天学完Python:Day19 文件处理
📘 Day 19 🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点…...
Spring Boot application.properties和application.yml文件的配置
在Spring Boot中,application.properties 和 application.yml 文件用于配置应用程序的各个方面,如服务器端口、数据库连接、日志级别等。这两个文件是Spring Boot的配置文件,位于 src/main/resources 目录下。 application.properties 示例 …...

Unity单元测试
Unity单元测试是一个专门用于嵌入式单元测试的库, 现在简单讲下移植以及代码结构. 源码地址: GitHub - ThrowTheSwitch/Unity: Simple Unit Testing for C 1.我们只需要移植三个文件即可: unity.c, unity.h, unity_internals.h 2.然后添加需要测试的函数. 3.在main.c中添加…...

Spring Bean 的生命周期了解么?
Spring Bean 的生命周期基本流程 一个Spring的Bean从出生到销毁的全过程就是他的整个生命周期, 整个生命周期可以大致分为3个大的阶段 : 创建 使用 销毁 还可以分为5个小步骤 : 实例化(Bean的创建) , 初始化赋值, 注册Destruction回调 , Bean的正常使用 以及 Bean的销毁 …...

终极指南:在Windows上直接安装安卓APK文件的5个简单步骤
终极指南:在Windows上直接安装安卓APK文件的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但又厌…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...

如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案
如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

Windows Defender终极移除指南:高效卸载13项核心服务完整教程
Windows Defender终极移除指南:高效卸载13项核心服务完整教程 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirr…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

终极指南:3步实现PotPlayer实时字幕翻译,外语视频无障碍观看
终极指南:3步实现PotPlayer实时字幕翻译,外语视频无障碍观看 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 还…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

KIVI开源工具箱:模块化设计赋能开发者效率提升
1. 项目概述:一个面向开发者的开源工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫KIVI。第一眼看到这个名字,我以为是某种新的UI框架或者设计系统,毕竟“KIVI”听起来有点像是“Kiwi”的变体,容易联…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...

基于WebSocket的机械爪远程控制桥接系统设计与实战
1. 项目概述:一个连接物理世界与数字世界的“机械爪”远程控制桥最近在捣鼓一个挺有意思的开源项目,叫lucas-jo/openclaw-bridge-remote。光看名字,你可能觉得这又是一个关于机器人或者机械臂的遥控项目,但实际深入进去࿰…...