数据结构与算法之堆排序
目录
- 堆排序概述
- 代码实现
- 时间复杂度
堆排序概述
堆排序(Heap Sort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
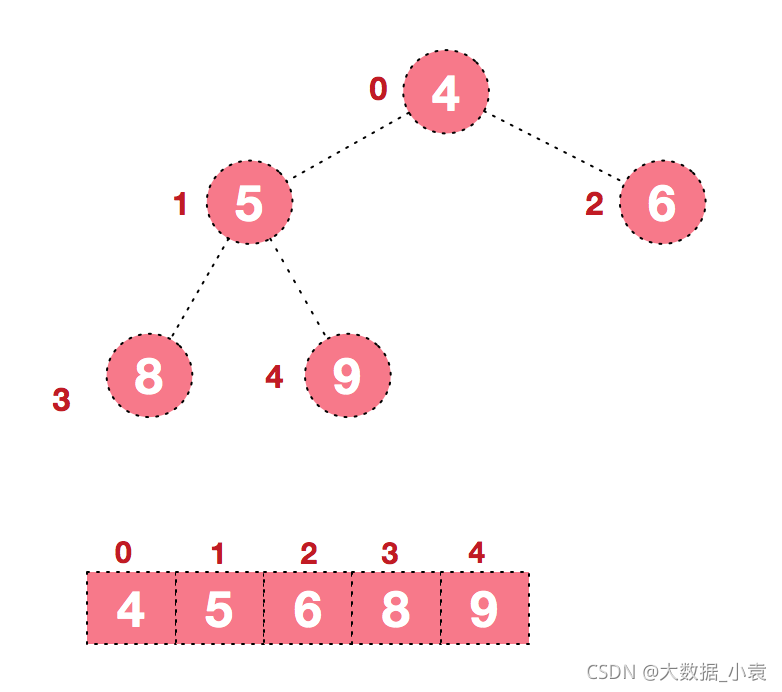
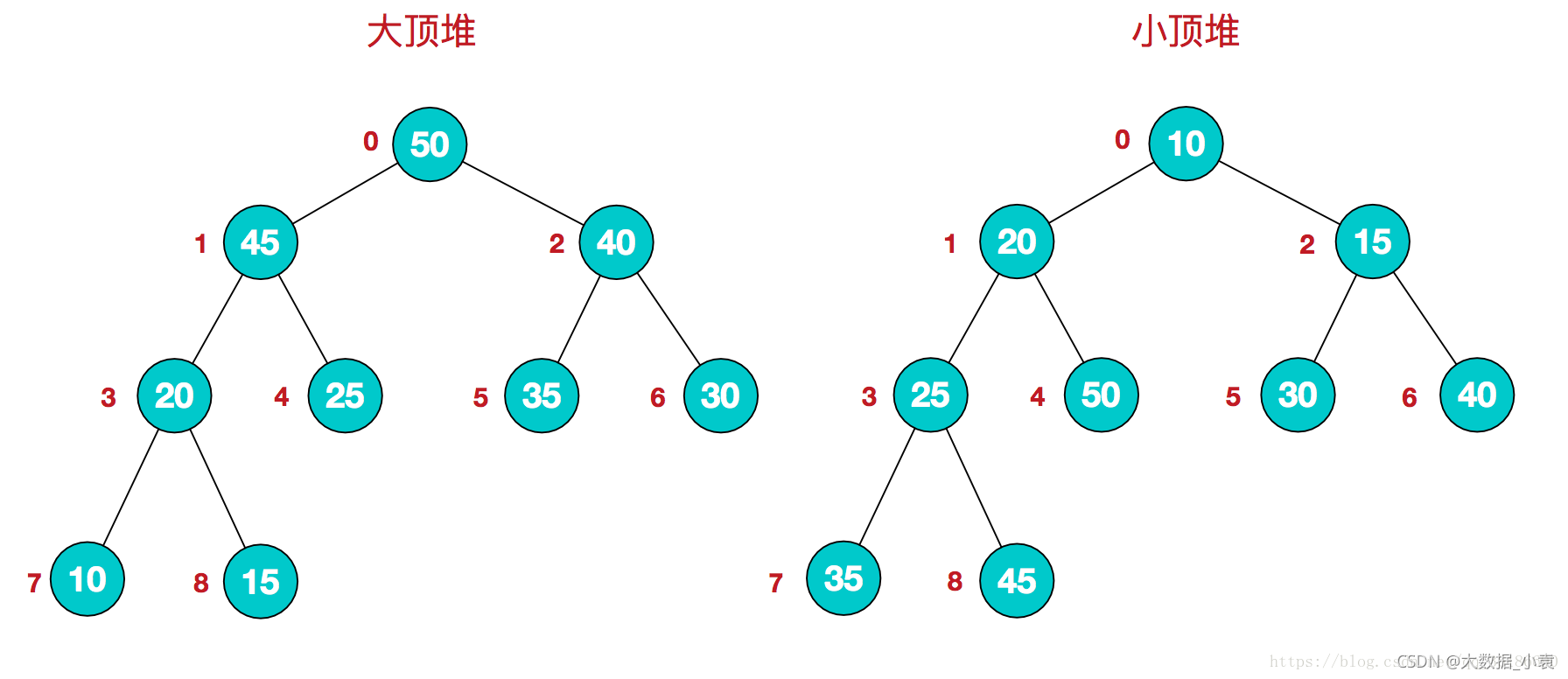 同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子
同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子
 该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是:
该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是:
-
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
-
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
步骤一 构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)
1)假设给定无序序列结构如下
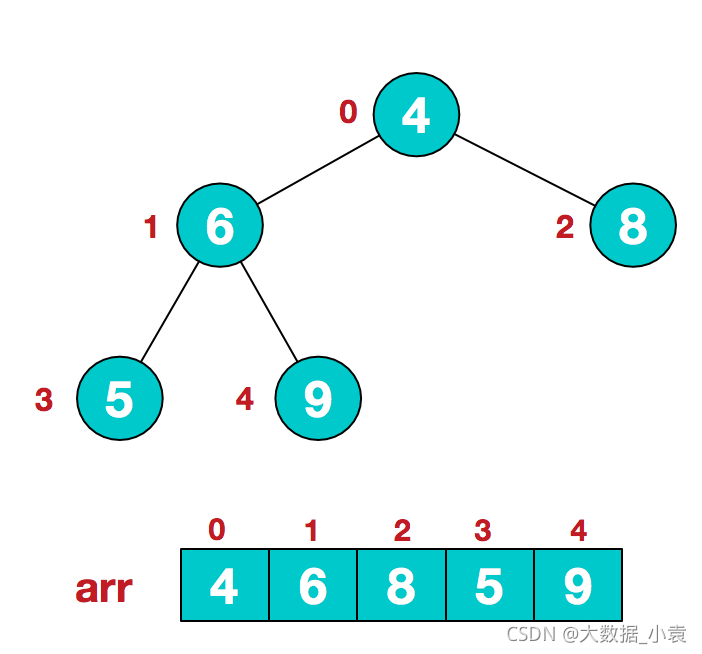
2)此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整
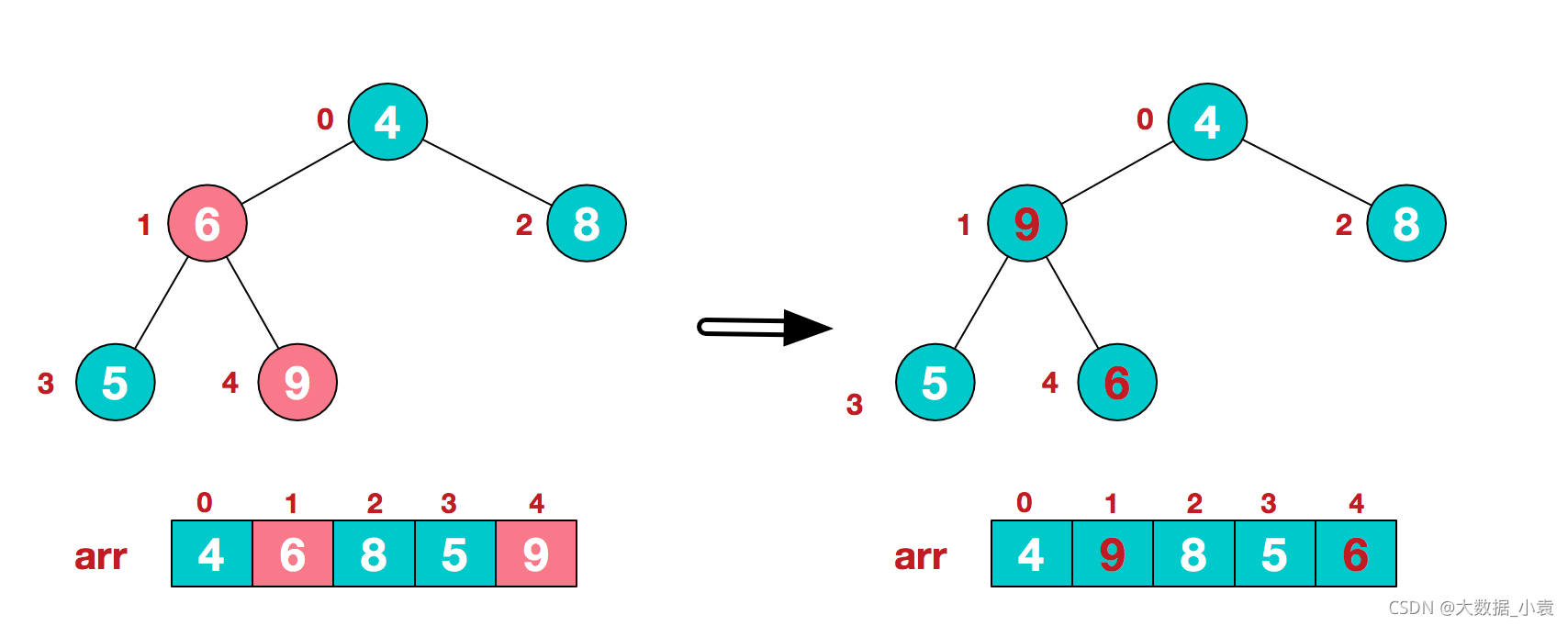
3)找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换
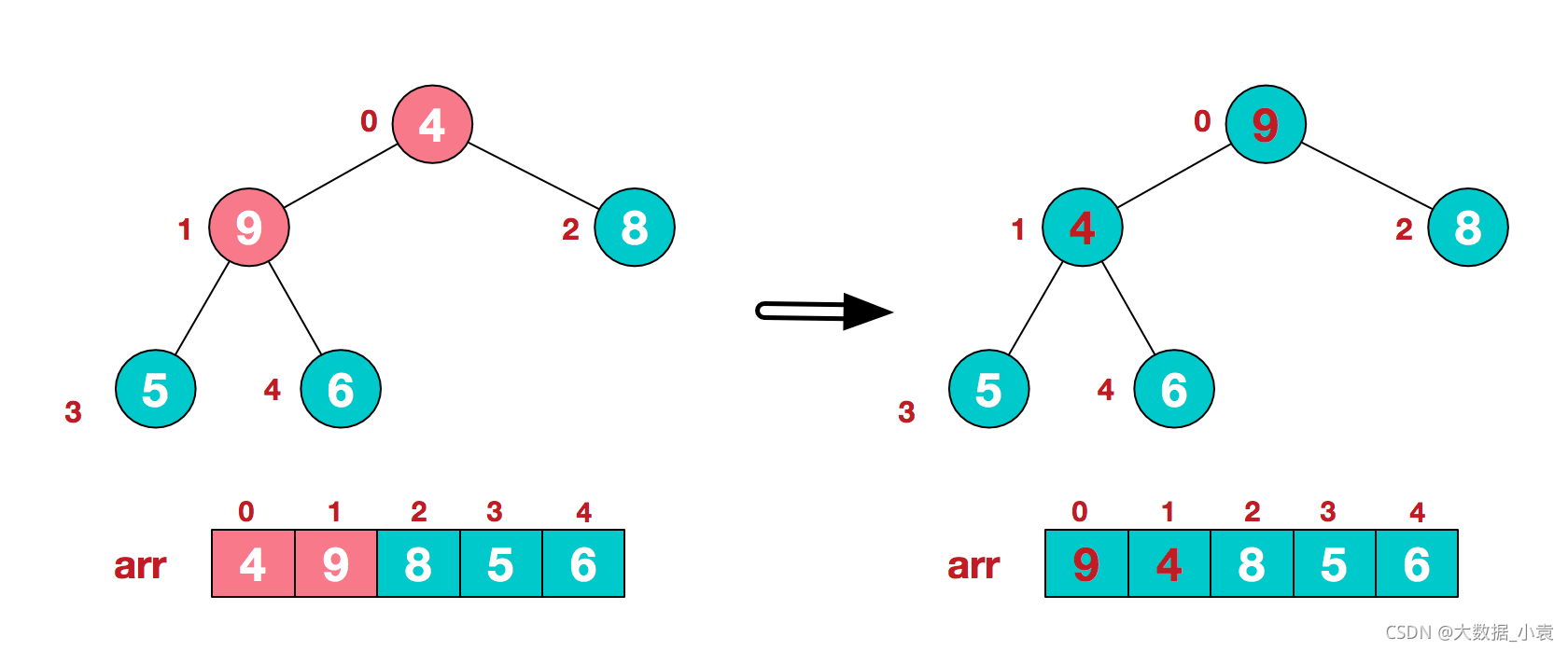 4)这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
4)这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
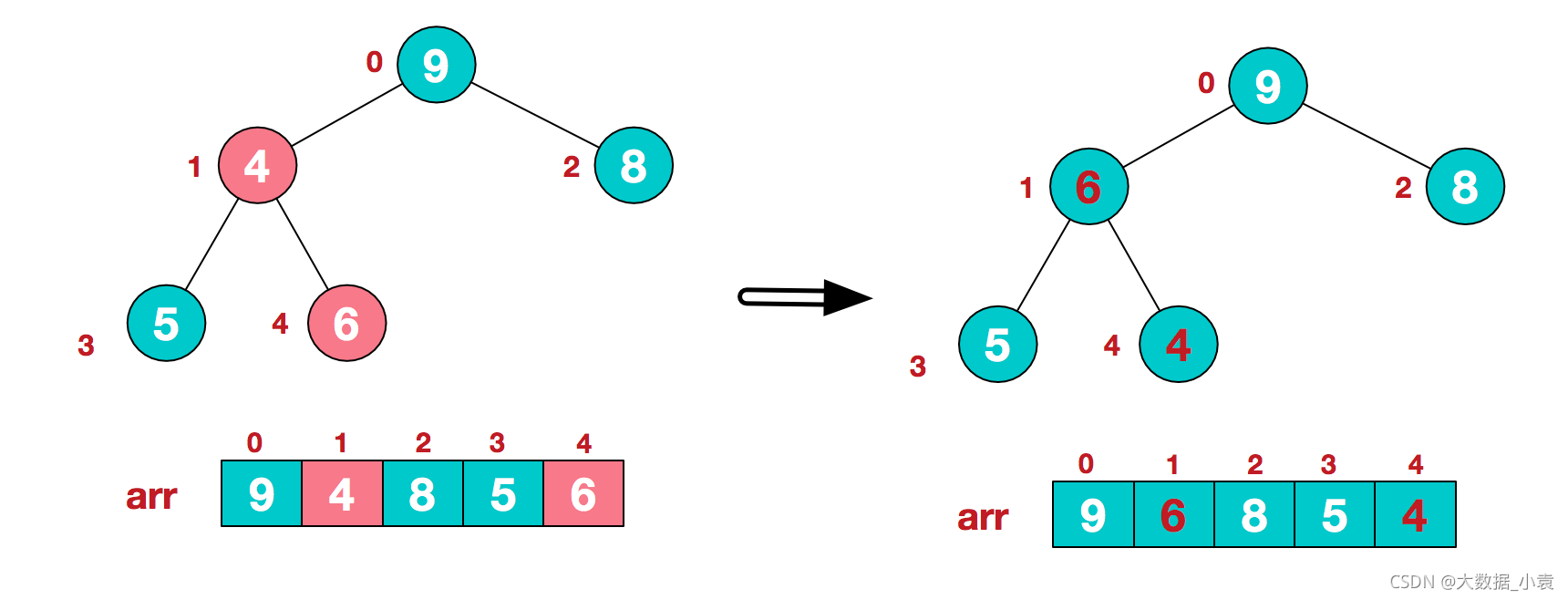 此时,我们就将一个无需序列构造成了一个大顶堆
此时,我们就将一个无需序列构造成了一个大顶堆
步骤二 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换
1)将堆顶元素9和末尾元素4进行交换,9就不用继续排序了
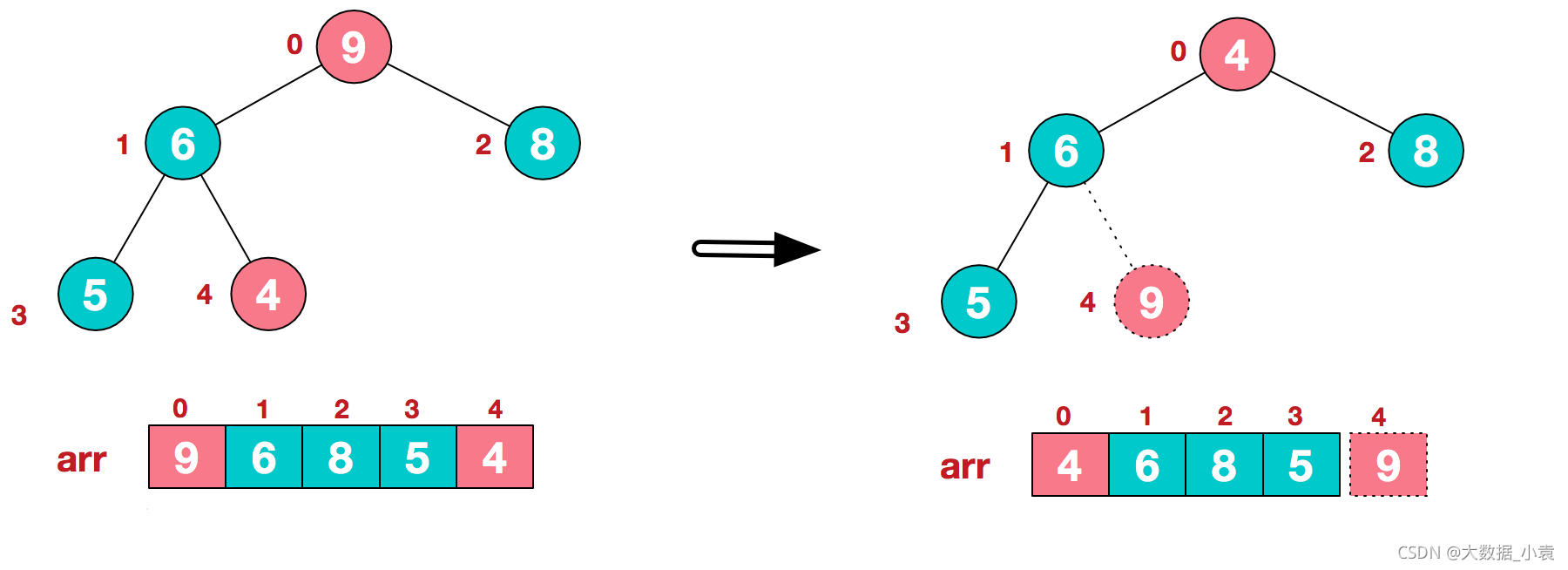
2)重新调整结构,使其继续构建大顶堆(9除外)
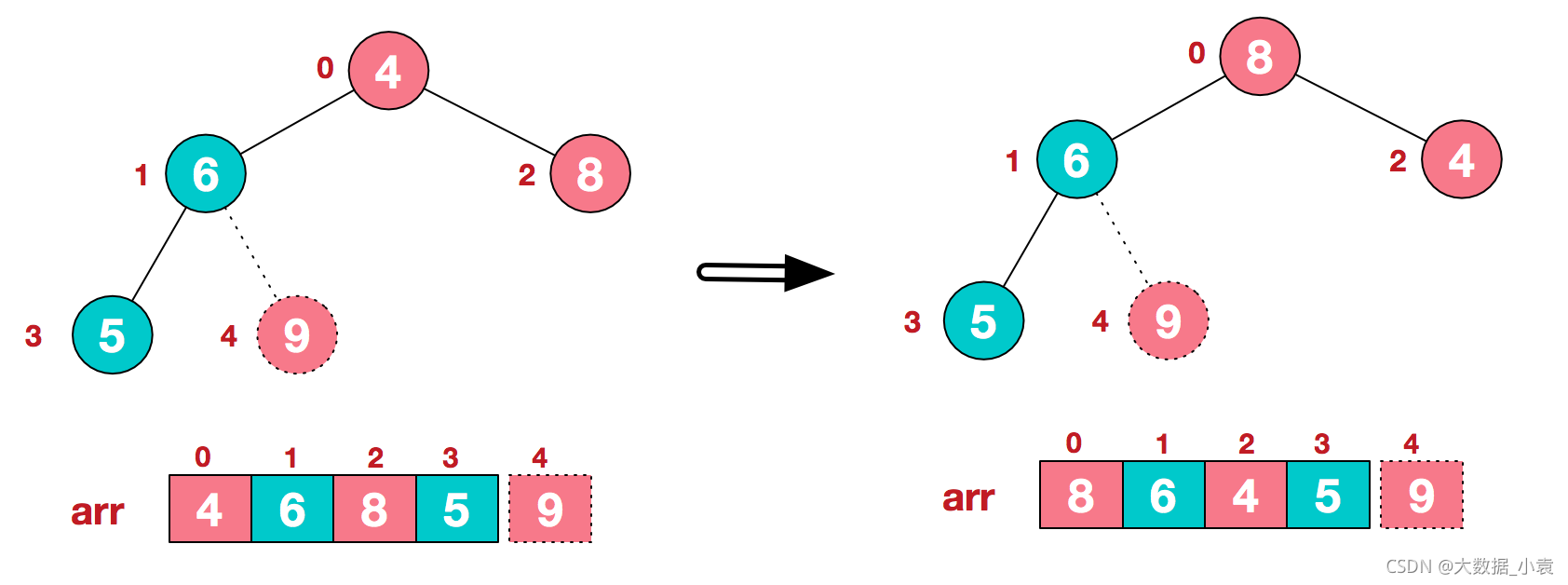
3)再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
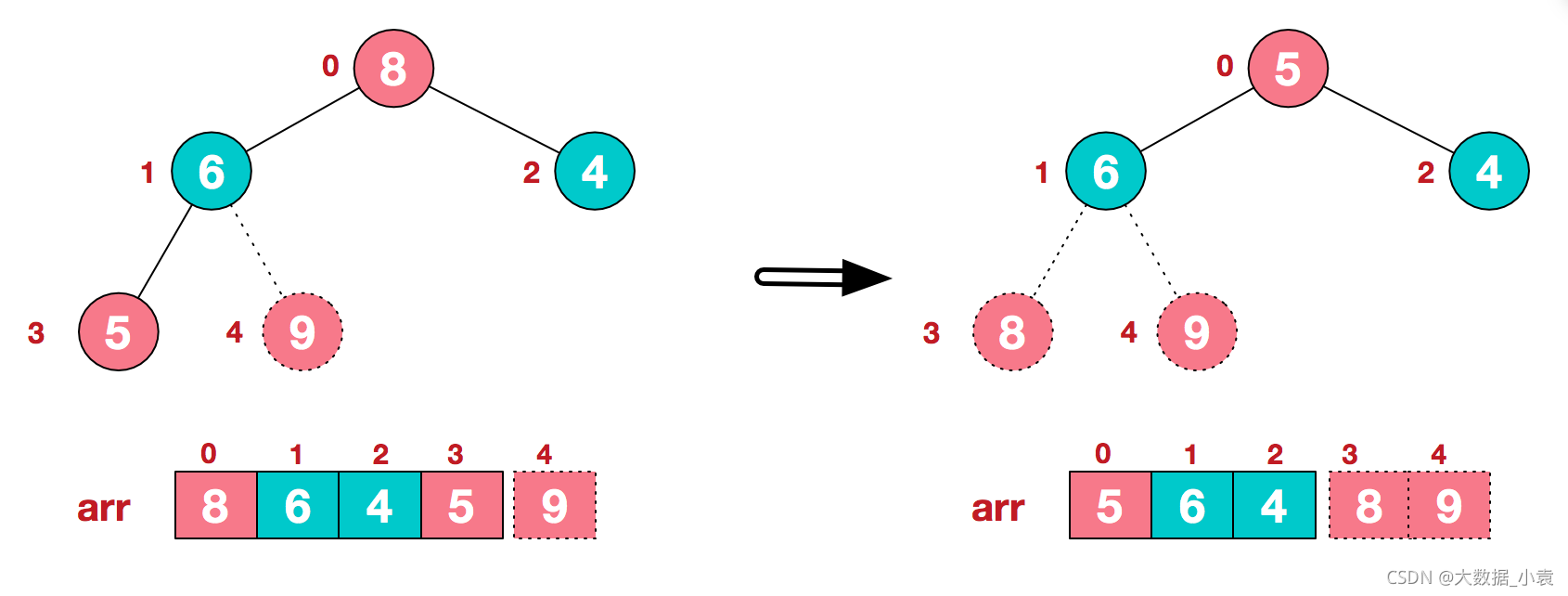
步骤三 后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
排序思路:
-
将无需序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
-
将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
-
重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序
动图展示:

代码实现
import java.util.Arrays;public class HeapSort {public static void main(String[] args) {int[] arr = {4, 6, 8, 5, 9};heapSort(arr);
// [4, 6, 8, 5, 9]
// [4, 9, 8, 5, 6]
// [4, 9, 8, 5, 6]
// [9, 6, 8, 5, 4]
// [9, 6, 8, 5, 4]
// [9, 6, 8, 5, 4]
// [8, 6, 4, 5, 9]
// [8, 6, 4, 5, 9]
// [6, 5, 4, 8, 9]
// [6, 5, 4, 8, 9]
// [5, 4, 6, 8, 9]
// [5, 4, 6, 8, 9]
// [4, 5, 6, 8, 9]}//堆排序public static void heapSort(int[] arr) {//开始位置是最后一个非叶子节点(最后一个节点的父节点)int start = (arr.length - 1) / 2;//循环调整为大顶堆for (int i = start; i >= 0; i--) {maxHeap(arr, arr.length, i);}//先把数组中第0个和堆中最后一个交换位置for (int i = arr.length - 1; i > 0; i--) {int temp = arr[0];arr[0] = arr[i];arr[i] = temp;//再把前面的处理为大顶堆maxHeap(arr, i, 0);}}//数组转大顶堆,size:调整多少(从最后一个向前减),index:调整哪一个(最后一个非叶子节点)public static void maxHeap(int[] arr, int size, int index) {//左子节点int leftNode = 2 * index + 1;//右子节点int rightNode = 2 * index + 2;//先设当前为最大节点int max = index;//和两个子节点分别对比,找出最大的节点if (leftNode < size && arr[leftNode] > arr[max]) {max = leftNode;}if (rightNode < size && arr[rightNode] > arr[max]) {max = rightNode;}//交换位置if (max != index) {int temp = arr[index];arr[index] = arr[max];arr[max] = temp;//交换位置后,可能会破坏之前排好的堆,所以之间排好的堆需要重新调整maxHeap(arr, size, max);}//打印每次排序后的结果System.out.println(Arrays.toString(arr));}
}
时间复杂度
- 最优时间复杂度:
o(nlogn) - 最坏时间复杂度:
o(nlogn) - 稳定性:不稳定
它的运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上。
在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端结点开始构建,将它与其孩子进行比较和若有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间(完全二叉树的某个结点到根结点的距离为log2i+1),并且需要取n-1次堆顶记录,因此,重建堆的时间复杂度为O(nlogn)。
所以总体来说,堆排序的时间复杂度为O(nlogn)。由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)。这在性能上显然要远远好过于冒泡、简单选择、直接插入的O(n2)的时间复杂度了。
空间复杂度上,它只有一个用来交换的暂存单元,也非常的不错。不过由于记录的比较与交换是跳跃式进行,因此堆排序是一种不稳定的排序方法。
相关文章:
数据结构与算法之堆排序
目录堆排序概述代码实现时间复杂度堆排序概述 堆排序(Heap Sort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点…...

Vue3 中的模板语法
目录前言一、什么是模板语法?二、内容渲染指令1. v-text2. {{ }} 插值表达式3. v-html三、双向绑定指令1. v-model2. v-model的修饰符四、属性绑定指令1. 动态绑定多个属性值2. 绑定class和style属性五、条件渲染指令1. v-if、v-else-if、v-else2. v-show3. v-if和v…...

Redis十大类型——Hash常见操作
Redis十大类型——Hash常见操作命令操作简列存放及获取获取健值对长度元素查找列出健值对对数字进行操作赋值hsetnx很明显咯它也是以健值对方式存在的,只不过value也就是值,在这里也变成了一组简直对。 🍊个🌰: 想必多…...

Python采集本地二手房,一键知晓上万房源信息
前言 大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 所以今天教大家用Python来采集本地房源数据,帮助大家筛选好房。 话不多说,让我们开始愉快的旅程吧~ 更多精彩内容、资源皆可点击文章下方名片获取此处跳转 本文涉及知识点 采集基本流程 requests 发送…...

Ubuntu 18.04 出现GLIBC_2.28 not found的解决方法(亲测有效)
关于/lib/x86_64-linux-gnu/libc.so.6: version GLIBC_2.28’ not found出现报错,建议不要使用源码包去编译并升级。在下文有分享一个使用官方的Debian软件包去升级使用的方法。仅供参考! 环境 # uname -a Linux Ubuntu 5.4.0-144-generic #161~18.04.…...

Java文档搜索引擎总结
Java文档搜索引擎总结项目介绍项目使用的技术栈前端页面展示后端逻辑部分索引部分搜索模块部分Web模块部分项目介绍 Java文档搜索引擎项目是一个SSM项目,该项目的前端界面部分是由搜索页面和展示页面组成,后端部分索引模块(ScanAnalysis、in…...
Linux内核学习笔记——页表的那些事。
目录页表什么时候创建内核页表变化什么时候更新到用户页表源码分析常见问题解答问题一:页表到底是保存在内核空间中还是用户空间中?问题2:页表访问,软件是不是会频繁陷入内核?问题3:内存申请,软…...

C++,Qt分别读写xml文件
XML语法 第一行是XML文档声明,<>内的代表是元素,基本语法如以下所示。C常见的是使用tiny库读写,Qt使用自带的库读写; <?xml version"1.0" encoding"utf-8" standalone"yes" ?> <根元素>…...
WebStorm安装教程【2023年最新版图解】一文教会你安装
文章目录引言一、下载WebStorm三、WebStorm激活配置及创建项目Active Code安装完成尝试新建一个项目引言 今天发现了一个专注前端开发的软件,相比VSCode的话,这个好像也不错,为了后续做个API接口项目做准备。 对于入门JavaScript 开发的者&am…...

用户态和内核态,系统调用
特权指令:具有特殊权限的指令,比如清内存,重置时钟,分配系统资源,修改用户的访问权限 由于这类指令的权限最大,所以使用不当会导致整个系统崩溃 系统调用:是操作系统提供给应用程序的接口(供应…...

Java 包装类
Java 中有些类只能操作对象,因此 Java 的基本数据类型都有一个对应的包装类。 byte:Byteshort:Shortint:Integerlong:Longfloat:Floatdouble:Doublechar:Characterbooleanÿ…...

Raspberry Pi GPIO入门指南
如果您想使用 Raspberry Pi 进行数字输入/输出操作,那么您需要使用 GPIO(通用输入/输出)引脚。在这篇文章中,我们将为您提供 Raspberry Pi GPIO 的基础知识,包括如何访问和操作 GPIO 引脚。 0.认识GPIO 树莓派上的那…...

汇编语言程序设计(三)之汇编程序
系列文章 汇编语言程序设计(一) 汇编语言程序设计(二)之寄存器 汇编程序 经过上述课程的学习,我们可以编写一个完整的程序了。这章开始我们将开始编写完整的汇编语言程序,用编译和连接程序将它们连接成可…...

用二极管和电容过滤电源波动,实现简单的稳压 - 小水泵升压改装方案
简而言之,就是类似采样保持电路,当电源电压因为电机启动而骤降时,用二极管避免电容电压跟着降低,从而让电容上连接的低功耗芯片有一个比较稳定的供电电压。没什么特别的用处,省个LDO 吧,电压跌幅太大的时候…...

【数据结构与算法】数据结构有哪些?算法有哪些?
1. 算法与数据结构总览图 2.常用的数据结构 2.1.数组(Array) 数组是一种聚合数据类型,它是将具有相同类型的若干变量有序地组织在一起的集合。数组可以说是最基本的数据结构,在各种编程语言中都有对应。一个数组可以分解为多个数…...
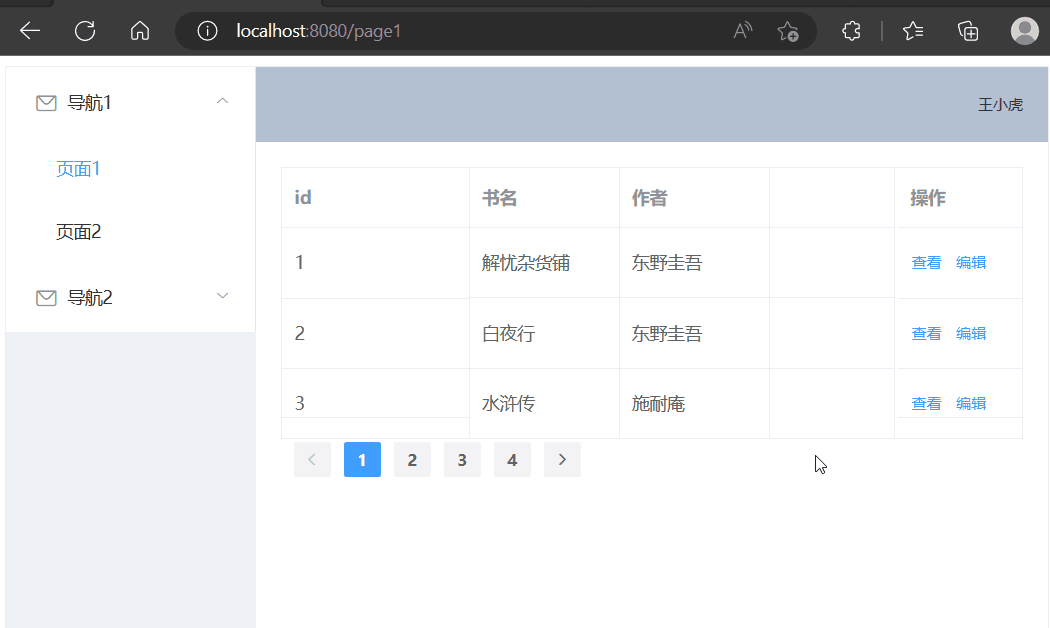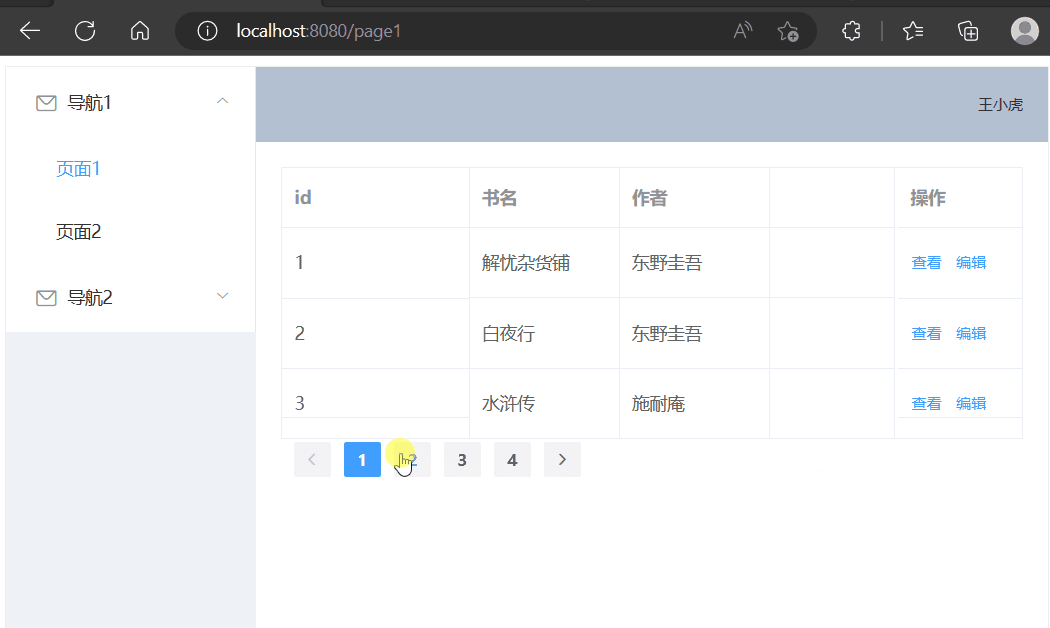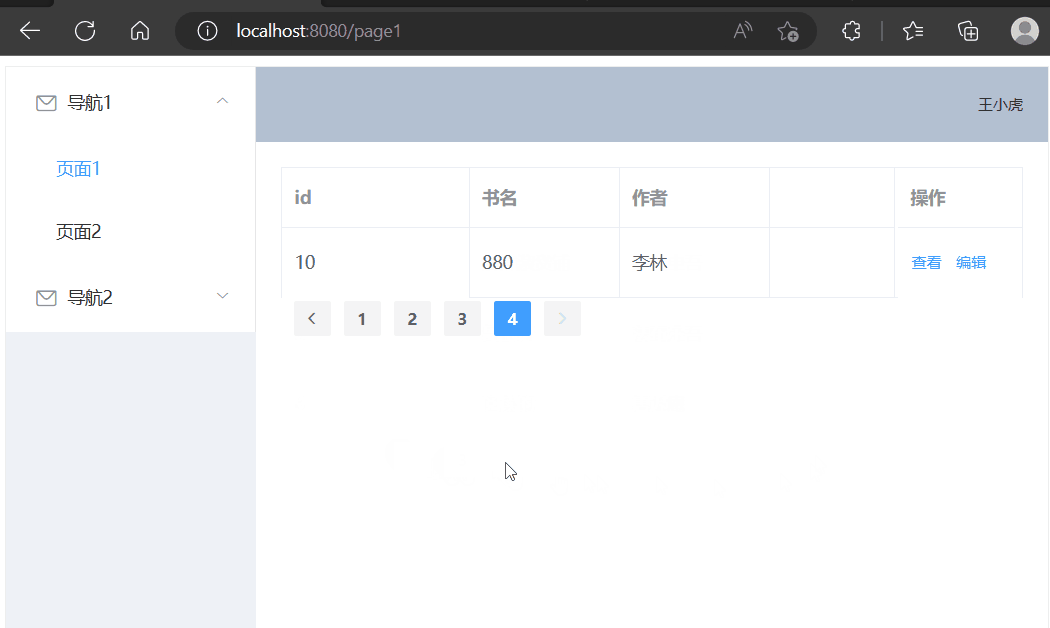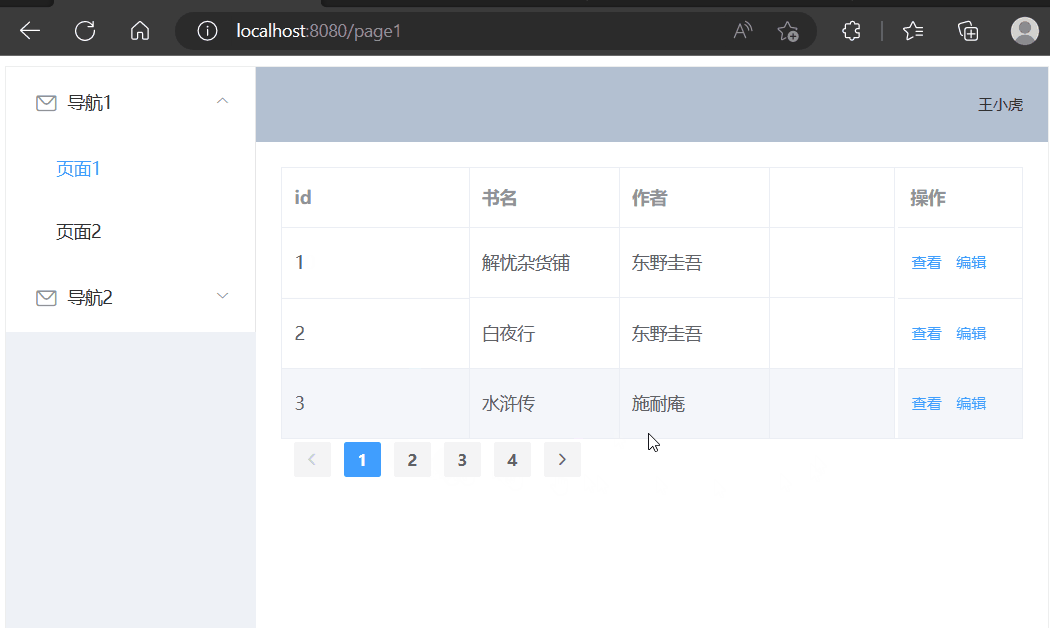
使用Element-UI展示数据(动态查询)
学习内容来源:视频P4 本篇文章进度接着之前的文章进行续写 精简前后端分离项目搭建 Vue基础容器使用 目录选择组件修改表格组件修改分页组件增加后端接口前端请求数据接口页面初始化请求数据点击页码请求数据选择组件 在官方文档中选择现成的组件,放在页…...

lamda 表达式例子全集
1、List 转 map 1.1、key(Model属性) value Model Map<String, Model> modeMap List.stream().collect(Collectors.toMap(Model1::属性get方法, v -> v, (p1, p2) -> p1)); 1.2、key(Model1属性) value Model2 Map<String, Model1> model2Map List.stream…...

计算机网络第八版——第一章课后题答案(超详细)
第一章 该答案为博主在网络上整理,排版不易,希望大家多多点赞支持。后续将会持续更新(可以给博主点个关注~ 【1-01】计算机网络可以向用户提供哪些服务? 解答:这道题没有现成的标准答案,因为可以从不同的…...
嵌入式和Python(二):python初识及其基本使用规则
目录 一,python基本特点 二,python使用说明 ● 两种编程方式 ① 交互式编程 ② 脚本式编程 ● python中文编码 ● python行和缩进 ● python引号 ● python空行 ● python等待用户输入 ① 没有转换变量类型 ② 转换变量类型 ● python变…...

C语言详解双向链表的基本操作
目录 双链表的定义与接口函数 定义双链表 接口函数 详解接口函数的实现 创建新节点(BuyLTNode) 初始化双链表(ListInit) 双向链表打印(ListPrint) 双链表查找(ListFind) 双链…...

星光护航 家校同行 多方联合点亮4·2世界孤独症日公益之光
2026年4月2日第19个世界孤独症关注日来临之际,联合国官宣年度主题Autism and Humanity — Every Life Has Value(孤独症与人类 — 每一个生命都弥足珍贵),中国同步确定“提质全生涯服务供给,聚焦孤独症家庭支持与成年服…...

RTKLIB数据流引擎str2str:从源码到实战的流式数据处理架构剖析
1. RTKLIB数据流引擎str2str架构解析 str2str是RTKLIB中负责数据流处理的核心模块,它的设计理念类似于工厂里的流水线传送带。想象一下GNSS数据就像流水线上的零件,str2str的工作就是把这些零件从不同来源的传送带(输入流)接过来&…...

EcomGPT-中英文-7B电商模型在Vue.js前端项目中的集成:打造实时智能客服聊天组件
EcomGPT-中英文-7B电商模型在Vue.js前端项目中的集成:打造实时智能客服聊天组件 最近在做一个电商后台的升级项目,客户提了个需求,希望能在用户端和管理后台都加上一个智能客服,能实时回答商品咨询、订单状态这些常见问题。一开始…...

终极指南:如何扩展Bloaty功能 - 自定义解析器和数据源开发完整教程
终极指南:如何扩展Bloaty功能 - 自定义解析器和数据源开发完整教程 【免费下载链接】bloaty Bloaty: a size profiler for binaries 项目地址: https://gitcode.com/gh_mirrors/bl/bloaty Bloaty二进制大小分析工具是一款强大的二进制文件大小分析工具&#…...

ai结对编程,让快马帮你自动生成openclaw多轮对话任务规划应用骨架
最近在开发一个基于OpenClaw的多轮对话任务规划应用时,发现这类项目往往需要处理大量重复性代码框架搭建工作。比如要同时兼顾意图识别、状态管理、API调用和结果生成等多个模块,光是初始化项目结构就得花上大半天。好在尝试了InsCode(快马)平台的AI辅助…...

C语言完美演绎6-21
/* 范例:6-21 */#include<stdio.h> #include<conio.h>int main(){int n;printf("这是nn乘法表,请输入一值>");scanf("%d",&n);int i1;for(;i<n;) /* i从1到n次循环*/{int j1;for(;j<n;) /…...

C# TCP服务端开发实战:从零构建高效网口调试工具
1. 为什么需要自建TCP调试工具? 做上位机开发的朋友应该都深有体会,网口通讯调试是绕不开的日常。市面上的调试助手要么功能简陋,要么收费昂贵,最头疼的是遇到特殊需求时根本找不到合适的工具。去年我在做一个工业设备监控项目时&…...

Qwen3.5-9B Visio图表描述生成:从文本到系统架构图的自动构思
Qwen3.5-9B Visio图表描述生成:从文本到系统架构图的自动构思 1. 引言:架构设计的效率革命 想象一下这样的场景:你正在会议室里和团队讨论一个新项目的系统架构。白板上画满了各种方框和连线,但总觉得不够系统化。回到工位后&am…...
)
别再怕环路!手把手教你用锐捷RG-IS2700G交换机配置ERPS环网(附完整命令)
锐捷RG-IS2700G交换机ERPS环网实战:从零搭建高可靠企业网络 第一次接手企业园区网核心交换机的运维工作时,看到拓扑图上那个醒目的环形结构,我的手指在键盘上方悬停了整整十分钟——毕竟谁都不想成为"那个让全公司断网的新人"。直到…...

开源广告拦截工具AdGuard浏览器扩展:全平台部署与效率优化指南
开源广告拦截工具AdGuard浏览器扩展:全平台部署与效率优化指南 【免费下载链接】AdguardBrowserExtension AdGuard browser extension 项目地址: https://gitcode.com/gh_mirrors/ad/AdguardBrowserExtension 【价值解析】AdGuard扩展如何重塑你的网络浏览体…...