推荐系统1--Deepfm学习笔记
目录
1 keras实现Deepfm
demo
2 deepctr模版
3 其他实现方式
ctr_Kera
模型
数据集
预处理
执行步骤
4何为focal loss
参考
1 keras实现Deepfm
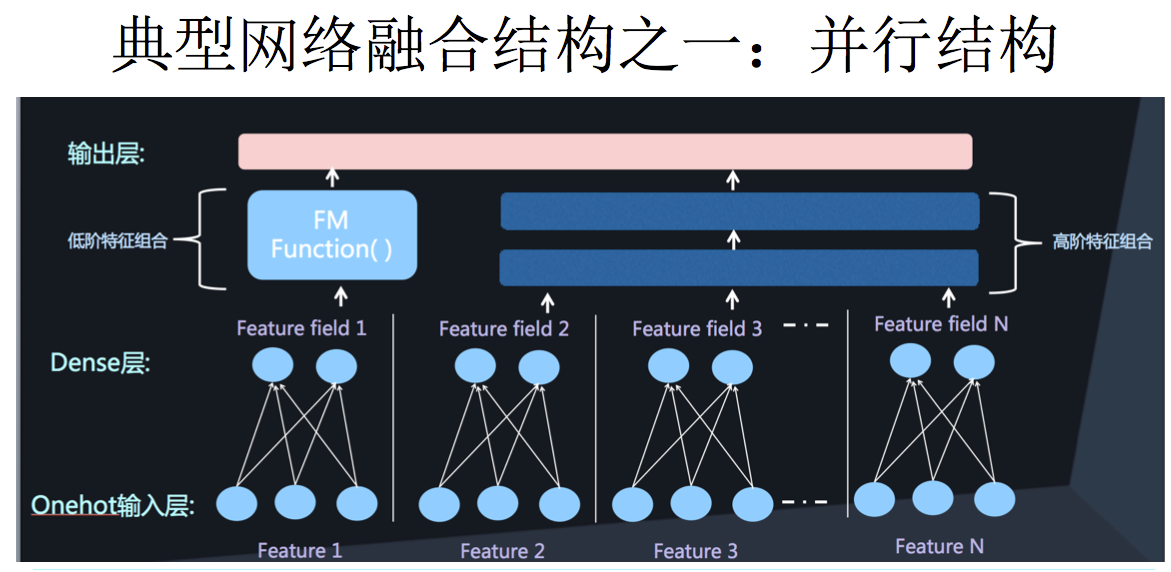
假设我们有两种 field 的特征,连续型和离散型,连续型 field 一般不做处理沿用原值,离散型一般会做One-hot编码。离散型又能进一步分为单值型和多值型,单值型在Onehot后的稀疏向量中,只有一个特征为1,其余都是0,而多值型在Onehot后,有多于1个特征为1,其余是0。
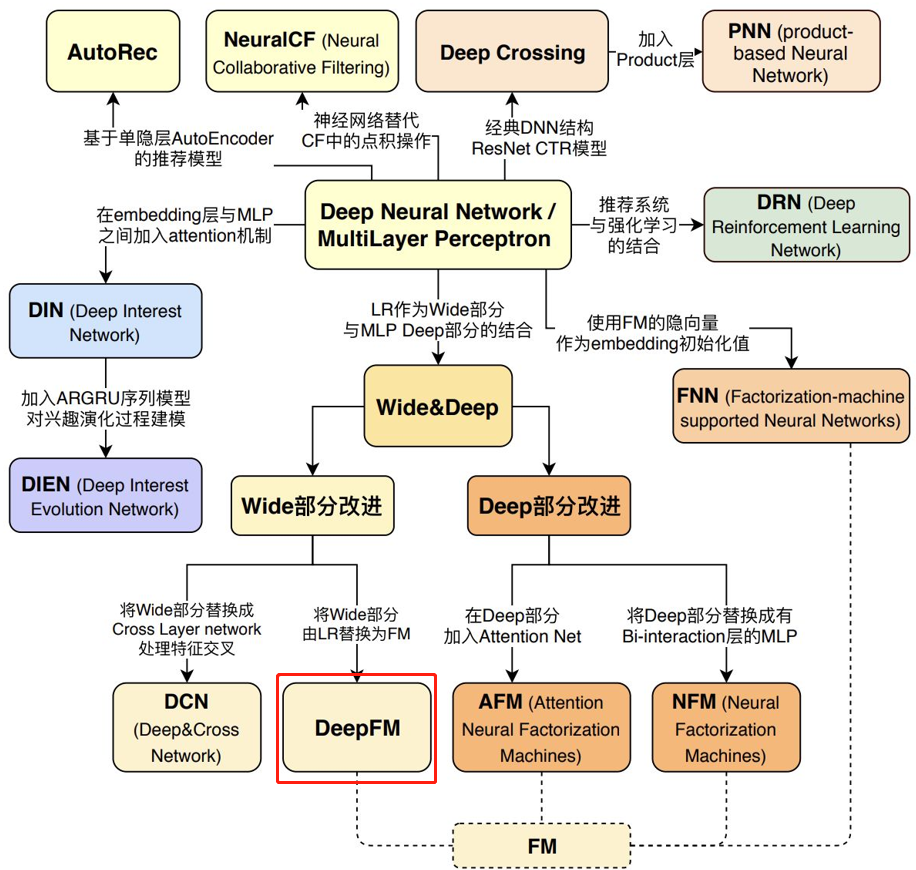
DeepFM模型本质
-
将Wide & Deep 部分的wide部分由 人工特征工程+LR 转换为FM模型,避开了人工特征工程;
-
FM模型与deep part共享feature embedding。
为什么要用FM代替线性部分(wide)呢?
因为线性模型有个致命的缺点:无法提取高阶的组合特征。 FM通过隐向量latent vector做内积来表示组合特征,从理论上解决了低阶和高阶组合特征提取的问题。但是实际应用中受限于计算复杂度,一般也就只考虑到2阶交叉特征。
DeepFM包含两部分:神经网络部分与因子分解机部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的输入。
不需要预训练 FM 得到隐向量;
不需要人工特征工程;
能同时学习低阶和高阶的组合特征;
FM 模块和 Deep 模块共享 Feature Embedding 部分,可以更快的训练,以及更精确的训练学习。
https://blog.csdn.net/m0_51933492/article/details/126888136


# FM的一阶特征运算
#将预处理完的类别特征列合并
cat_columns = [movie_ind_col, user_ind_col, user_genre_ind_col, item_genre_ind_col]#数值型特征不用经过独热编码和特征稠密化,转换成可以输入神经网络的dense类型直接输入网络
【推荐系统】DeepFM模型_deepfm多分类求auc_—Xi—的博客-CSDN博客
Model: "model" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== movieAvgRating (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ movieGenre1 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ movieGenre2 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ movieGenre3 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ movieId (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ movieRatingCount (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ movieRatingStddev (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ releaseYear (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userAvgRating (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userGenre1 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userGenre2 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userGenre3 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userGenre4 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userGenre5 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userId (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userRatedMovie1 (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userRatingCount (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ userRatingStddev (InputLayer) [(None,)] 0 __________________________________________________________________________________________________ dense_features_16 (DenseFeature (None, 10) 190 movieAvgRating[0][0] movieGenre1[0][0] movieGenre2[0][0] movieGenre3[0][0] movieId[0][0] movieRatingCount[0][0] movieRatingStddev[0][0] releaseYear[0][0] userAvgRating[0][0] userGenre1[0][0] userGenre2[0][0] userGenre3[0][0] userGenre4[0][0] userGenre5[0][0] userId[0][0] userRatedMovie1[0][0] userRatingCount[0][0] userRatingStddev[0][0] __________________________________________________________________________________________________ dense_features_17 (DenseFeature (None, 10) 10010 movieAvgRating[0][0] movieGenre1[0][0] movieGenre2[0][0] movieGenre3[0][0] movieId[0][0] movieRatingCount[0][0] movieRatingStddev[0][0] releaseYear[0][0] userAvgRating[0][0] userGenre1[0][0] userGenre2[0][0] userGenre3[0][0] userGenre4[0][0] userGenre5[0][0] userId[0][0] userRatedMovie1[0][0] userRatingCount[0][0] userRatingStddev[0][0] __________________________________________________________________________________________________ dense_features_18 (DenseFeature (None, 10) 190 movieAvgRating[0][0] movieGenre1[0][0] movieGenre2[0][0] movieGenre3[0][0] movieId[0][0] movieRatingCount[0][0] movieRatingStddev[0][0] releaseYear[0][0] userAvgRating[0][0] userGenre1[0][0] userGenre2[0][0] userGenre3[0][0] userGenre4[0][0] userGenre5[0][0] userId[0][0] userRatedMovie1[0][0] userRatingCount[0][0] userRatingStddev[0][0] __________________________________________________________________________________________________ dense_features_19 (DenseFeature (None, 10) 300010 movieAvgRating[0][0] movieGenre1[0][0] movieGenre2[0][0] movieGenre3[0][0] movieId[0][0] movieRatingCount[0][0] movieRatingStddev[0][0] releaseYear[0][0] userAvgRating[0][0] userGenre1[0][0] userGenre2[0][0] userGenre3[0][0] userGenre4[0][0] userGenre5[0][0] userId[0][0] userRatedMovie1[0][0] userRatingCount[0][0] userRatingStddev[0][0] __________________________________________________________________________________________________ dense_features_20 (DenseFeature (None, 7) 0 movieAvgRating[0][0] movieGenre1[0][0] movieGenre2[0][0] movieGenre3[0][0] movieId[0][0] movieRatingCount[0][0] movieRatingStddev[0][0] releaseYear[0][0] userAvgRating[0][0] userGenre1[0][0] userGenre2[0][0] userGenre3[0][0] userGenre4[0][0] userGenre5[0][0] userId[0][0] userRatedMovie1[0][0] userRatingCount[0][0] userRatingStddev[0][0] __________________________________________________________________________________________________ dense_18 (Dense) (None, 64) 704 dense_features_16[0][0] __________________________________________________________________________________________________ dense_19 (Dense) (None, 64) 704 dense_features_17[0][0] __________________________________________________________________________________________________ dense_20 (Dense) (None, 64) 704 dense_features_18[0][0] __________________________________________________________________________________________________ dense_21 (Dense) (None, 64) 704 dense_features_19[0][0] __________________________________________________________________________________________________ dense_22 (Dense) (None, 64) 512 dense_features_20[0][0] __________________________________________________________________________________________________ reshape_10 (Reshape) (None, 10, 64) 0 dense_18[0][0] __________________________________________________________________________________________________ reshape_11 (Reshape) (None, 10, 64) 0 dense_19[0][0] __________________________________________________________________________________________________ reshape_12 (Reshape) (None, 10, 64) 0 dense_20[0][0] __________________________________________________________________________________________________ reshape_13 (Reshape) (None, 10, 64) 0 dense_21[0][0] __________________________________________________________________________________________________ reshape_14 (Reshape) (None, 10, 64) 0 dense_22[0][0] __________________________________________________________________________________________________ concatenate_2 (Concatenate) (None, 50, 64) 0 reshape_10[0][0] reshape_11[0][0] reshape_12[0][0] reshape_13[0][0] reshape_14[0][0] __________________________________________________________________________________________________ dense_features_14 (DenseFeature (None, 31040) 0 movieAvgRating[0][0] movieGenre1[0][0] movieGenre2[0][0] movieGenre3[0][0] movieId[0][0] movieRatingCount[0][0] movieRatingStddev[0][0] releaseYear[0][0] userAvgRating[0][0] userGenre1[0][0] userGenre2[0][0] userGenre3[0][0] userGenre4[0][0] userGenre5[0][0] userId[0][0] userRatedMovie1[0][0] userRatingCount[0][0] userRatingStddev[0][0] __________________________________________________________________________________________________ dense_features_15 (DenseFeature (None, 7) 0 movieAvgRating[0][0] movieGenre1[0][0] movieGenre2[0][0] movieGenre3[0][0] movieId[0][0] movieRatingCount[0][0] movieRatingStddev[0][0] releaseYear[0][0] userAvgRating[0][0] userGenre1[0][0] userGenre2[0][0] userGenre3[0][0] userGenre4[0][0] userGenre5[0][0] userId[0][0] userRatedMovie1[0][0] userRatingCount[0][0] userRatingStddev[0][0] __________________________________________________________________________________________________ reduce_layer (ReduceLayer) (None, 64) 0 concatenate_2[0][0] __________________________________________________________________________________________________ multiply_1 (Multiply) (None, 50, 64) 0 concatenate_2[0][0] concatenate_2[0][0] __________________________________________________________________________________________________ flatten_2 (Flatten) (None, 3200) 0 concatenate_2[0][0] __________________________________________________________________________________________________ dense_16 (Dense) (None, 1) 31041 dense_features_14[0][0] __________________________________________________________________________________________________ dense_17 (Dense) (None, 1) 8 dense_features_15[0][0] __________________________________________________________________________________________________ multiply (Multiply) (None, 64) 0 reduce_layer[0][0] reduce_layer[0][0] __________________________________________________________________________________________________ reduce_layer_1 (ReduceLayer) (None, 64) 0 multiply_1[0][0] __________________________________________________________________________________________________ dense_23 (Dense) (None, 32) 102432 flatten_2[0][0] __________________________________________________________________________________________________ add_2 (Add) (None, 1) 0 dense_16[0][0] dense_17[0][0] __________________________________________________________________________________________________ subtract (Subtract) (None, 64) 0 multiply[0][0] reduce_layer_1[0][0] __________________________________________________________________________________________________ dense_24 (Dense) (None, 16) 528 dense_23[0][0] __________________________________________________________________________________________________ concatenate_3 (Concatenate) (None, 81) 0 add_2[0][0] subtract[0][0] dense_24[0][0] __________________________________________________________________________________________________ dense_25 (Dense) (None, 1) 82 concatenate_3[0][0] ================================================================================================== Total params: 447,819 Trainable params: 447,819 Non-trainable params: 0 __________________________________________________________________________________________________ None
TensorFlow的plot_model功能_plot_model函数_buptwhq的博客-CSDN博客
from keras.utils.vis_utils import plot_model
...
plot_model(model, to_file="model.png", show_shapes=True, show_layer_names=False, rankdir='TB')
8. keras - 绘制网络结构_keras 设计网络_Micheal超的博客-CSDN博客
问题一:什么是特征交互,为什么要进行特征交互?
二阶特征交互:通过对主流应用市场的研究,我们发现人们经常在用餐时间下载送餐的应用程序,这就表明应用类别和时间戳之间的(阶数-2)交互作用是CTR预测的一个信号。
三阶或者高阶特征交互:我们还发现男性青少年喜欢射击游戏和RPG游戏,这意味着应用类别、用户性别和年龄的(阶数-3)交互是CTR的另一个信号。
根据谷歌的W&D模型的应用, 作者发现同时考虑低阶和高阶的交互特征,比单独考虑其中之一有更多的改进
问题二:为啥人工特征工程有挑战性?
一些特征工程比较容易理解,就比如上面提到的那两个, 这时候往往我们都能很容易的设计或者组合那样的特征。 然而,其他大部分特征交互都隐藏在数据中,难以先验识别(比如经典的关联规则 "尿布和啤酒 "就是从数据中挖掘出来的,而不是由专家发现的),只能由机器学习自动捕捉,即使是对于容易理解的交互,专家们似乎也不可能详尽地对它们进行建模,特别是当特征的数量很大的时候.。
demo
【CTR模型】TensorFlow2.0 的 xDeepFM 实现与实战(附代码+数据)_tensorflow ctr 模型_VariableX的博客-CSDN博客
python相减substract_浅谈keras中的Merge层(实现层的相加、相减、相乘实例)_林祈墨的博客-CSDN博客
# coding:utf-8
from keras.layers import *
from keras.models import Model
from MyMeanPooling import MyMeanPool
from MySumLayer import MySumLayer
from MyFlatten import MyFlatten
from keras.utils import plot_model# numeric fields
in_score = Input(shape=[1], name="score") # None*1
in_sales = Input(shape=[1], name="sales") # None*1
# single value categorical fields
in_gender = Input(shape=[1], name="gender") # None*1
in_age = Input(shape=[1], name="age") # None*1
# multiple value categorical fields
in_interest = Input(shape=[3], name="interest") # None*3, 最长长度3
in_topic = Input(shape=[4], name="topic") # None*4, 最长长度4'''First Order Embeddings'''
numeric = Concatenate()([in_score, in_sales]) # None*2
dense_numeric = Dense(1)(numeric) # None*1
emb_gender_1d = Reshape([1])(Embedding(3, 1)(in_gender)) # None*1, 性别取值3种
emb_age_1d = Reshape([1])(Embedding(10, 1)(in_age)) # None*1, 年龄取值10种
emb_interest_1d = Embedding(11, 1, mask_zero=True)(in_interest) # None*3*1
emb_interest_1d = MyMeanPool(axis=1)(emb_interest_1d) # None*1
emb_topic_1d = Embedding(22, 1, mask_zero=True)(in_topic) # None*4*1
emb_topic_1d = MyMeanPool(axis=1)(emb_topic_1d) # None*1'''compute'''
y_first_order = Add()([dense_numeric,emb_gender_1d, emb_age_1d,emb_interest_1d,emb_topic_1d]) # None*1latent = 8
'''Second Order Embeddings'''
emb_score_Kd = RepeatVector(1)(Dense(latent)(in_score)) # None * 1 * K
emb_sales_Kd = RepeatVector(1)(Dense(latent)(in_sales)) # None * 1 * K
emb_gender_Kd = Embedding(3, latent)(in_gender) # None * 1 * K
emb_age_Kd = Embedding(10, latent)(in_age) # None * 1 * K
emb_interest_Kd = Embedding(11, latent, mask_zero=True)(in_interest) # None * 3 * K
emb_interest_Kd = RepeatVector(1)(MyMeanPool(axis=1)(emb_interest_Kd)) # None * 1 * K
emb_topic_Kd = Embedding(22, latent, mask_zero=True)(in_topic) # None * 4 * K
emb_topic_Kd = RepeatVector(1)(MyMeanPool(axis=1)(emb_topic_Kd)) # None * 1 * Kemb = Concatenate(axis=1)([emb_score_Kd,emb_sales_Kd,emb_gender_Kd,emb_age_Kd,emb_interest_Kd,emb_topic_Kd]) # None * 6 * K'''compute'''
summed_features_emb = MySumLayer(axis=1)(emb) # None * K
summed_features_emb_square = Multiply()([summed_features_emb,summed_features_emb]) # None * Ksquared_features_emb = Multiply()([emb, emb]) # None * 9 * K
squared_sum_features_emb = MySumLayer(axis=1)(squared_features_emb) # Non * Ksub = Subtract()([summed_features_emb_square, squared_sum_features_emb]) # None * K
sub = Lambda(lambda x:x*0.5)(sub) # None * Ky_second_order = MySumLayer(axis=1)(sub) # None * 1'''deep parts'''
y_deep = MyFlatten()(emb) # None*(6*K)
y_deep = Dropout(0.5)(Dense(128, activation='relu')(y_deep))
y_deep = Dropout(0.5)(Dense(64, activation='relu')(y_deep))
y_deep = Dropout(0.5)(Dense(32, activation='relu')(y_deep))
y_deep = Dropout(0.5)(Dense(1, activation='relu')(y_deep))'''deepFM'''
y = Concatenate(axis=1)([y_first_order, y_second_order,y_deep])
y = Dense(1, activation='sigmoid')(y)model = Model(inputs=[in_score, in_sales,in_gender, in_age,in_interest, in_topic],outputs=[y])plot_model(model, 'model.png', show_shapes=True)in_interest本身one-hot
2 deepctr模版
DeepCTR & DeepMatch简单实用指南_tf.Print(**)的博客-CSDN博客


文档:
Welcome to DeepCTR’s documentation! — DeepCTR 0.9.3 documentation
模型保存:
FAQ — DeepCTR 0.9.3 documentation
deepctr.models.deepfm module — DeepCTR 0.9.3 documentation
model = DeepFM()
model.save_weights('DeepFM_w.h5')
model.load_weights('DeepFM_w.h5')sparse_features = ['C' + str(i) for i in range(1, 27)]
#稀疏,离散特征
dense_features = ['I' + str(i) for i in range(1, 14)]
#连续,全连接def get_feature_names(feature_columns):features = build_input_features(feature_columns)return list(features.keys())def build_input_features(feature_columns, prefix=''):input_features = OrderedDict()# 字典for fc in feature_columns:if isinstance(fc, SparseFeat):input_features[fc.name] = Input(shape=(1,), name=prefix + fc.name, dtype=fc.dtype)elif isinstance(fc, DenseFeat):input_features[fc.name] = Input(shape=(fc.dimension,), name=prefix + fc.name, dtype=fc.dtype)elif isinstance(fc, VarLenSparseFeat):input_features[fc.name] = Input(shape=(fc.maxlen,), name=prefix + fc.name,dtype=fc.dtype)if fc.weight_name is not None:input_features[fc.weight_name] = Input(shape=(fc.maxlen, 1), name=prefix + fc.weight_name,dtype="float32")if fc.length_name is not None:input_features[fc.length_name] = Input((1,), name=prefix + fc.length_name, dtype='int32')else:raise TypeError("Invalid feature column type,got", type(fc))return input_features
class DenseFeat(namedtuple('DenseFeat', ['name', 'dimension', 'dtype', 'transform_fn'])):""" Dense featureArgs:name: feature name.dimension: dimension of the feature, default = 1.dtype: dtype of the feature, default="float32".transform_fn: If not `None` , a function that can be used to transformvalues of the feature. the function takes the input Tensor as itsargument, and returns the output Tensor.(e.g. lambda x: (x - 3.0) / 4.2)."""__slots__ = ()def __new__(cls, name, dimension=1, dtype="float32", transform_fn=None):return super(DenseFeat, cls).__new__(cls, name, dimension, dtype, transform_fn)def __hash__(self):return self.name.__hash__()# def __eq__(self, other):# if self.name == other.name:# return True# return False# def __repr__(self):# return 'DenseFeat:'+self.name
class SparseFeat(namedtuple('SparseFeat',['name', 'vocabulary_size', 'embedding_dim', 'use_hash', 'vocabulary_path', 'dtype', 'embeddings_initializer','embedding_name','group_name', 'trainable'])):__slots__ = ()def __new__(cls, name, vocabulary_size, embedding_dim=4, use_hash=False, vocabulary_path=None, dtype="int32", embeddings_initializer=None,embedding_name=None,group_name=DEFAULT_GROUP_NAME, trainable=True):if embedding_dim == "auto":embedding_dim = 6 * int(pow(vocabulary_size, 0.25))if embeddings_initializer is None:embeddings_initializer = RandomNormal(mean=0.0, stddev=0.0001, seed=2020)if embedding_name is None:embedding_name = namereturn super(SparseFeat, cls).__new__(cls, name, vocabulary_size, embedding_dim, use_hash, vocabulary_path, dtype,embeddings_initializer,embedding_name, group_name, trainable)使用例子
python:sklearn标签编码(LabelEncoder)_sklearn labelencoder_jenny_paofu的博客-CSDN博客
from sklearn import preprocessingdata=['电脑','手机','手机','手表']enc=preprocessing.LabelEncoder()
enc=enc.fit(['电脑','手机','手表'])#训练LabelEncoder,将电脑,手表,手机编码为0,1,2
data=enc.transform(data)#使用训练好的LabelEncoder对原数据进行编码,也叫归一化print(data)#[2 0 0 1]
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScalerfrom deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_namesif __name__ == "__main__":data = pd.read_csv('./criteo_sample.txt')sparse_features = ['C' + str(i) for i in range(1, 27)]dense_features = ['I' + str(i) for i in range(1, 14)]data[sparse_features] = data[sparse_features].fillna('-1', )data[dense_features] = data[dense_features].fillna(0, )target = ['label']# 1.Label Encoding for sparse features,and do simple Transformation for dense featuresfor feat in sparse_features:lbe = LabelEncoder()data[feat] = lbe.fit_transform(data[feat])mms = MinMaxScaler(feature_range=(0, 1))data[dense_features] = mms.fit_transform(data[dense_features])# 2.count #unique features for each sparse field,and record dense feature field namefixlen_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4 )for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)for feat in dense_features]dnn_feature_columns = fixlen_feature_columnslinear_feature_columns = fixlen_feature_columnsfeature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)# 3.generate input data for modeltrain, test = train_test_split(data, test_size=0.2, random_state=2018)train_model_input = {name:train[name] for name in feature_names}test_model_input = {name:test[name] for name in feature_names}# 4.Define Model,train,predict and evaluatemodel = DeepFM(linear_feature_columns, dnn_feature_columns, task='binary')model.compile("adam", "binary_crossentropy",metrics=['binary_crossentropy'], )history = model.fit(train_model_input, train[target].values,batch_size=256, epochs=10, verbose=2, validation_split=0.2, )pred_ans = model.predict(test_model_input, batch_size=256)print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))fm
输入:
model = Model(inputs=inputs_list, outputs=output)return model输入样式
def input_from_feature_columns(features, feature_columns, l2_reg, seed, prefix='', seq_mask_zero=True,support_dense=True, support_group=False):sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []embedding_matrix_dict = create_embedding_matrix(feature_columns, l2_reg, seed, prefix=prefix,seq_mask_zero=seq_mask_zero)group_sparse_embedding_dict = embedding_lookup(embedding_matrix_dict, features, sparse_feature_columns)dense_value_list = get_dense_input(features, feature_columns)if not support_dense and len(dense_value_list) > 0:raise ValueError("DenseFeat is not supported in dnn_feature_columns")sequence_embed_dict = varlen_embedding_lookup(embedding_matrix_dict, features, varlen_sparse_feature_columns)group_varlen_sparse_embedding_dict = get_varlen_pooling_list(sequence_embed_dict, features,varlen_sparse_feature_columns)group_embedding_dict = mergeDict(group_sparse_embedding_dict, group_varlen_sparse_embedding_dict)if not support_group:group_embedding_dict = list(chain.from_iterable(group_embedding_dict.values()))return group_embedding_dict, dense_value_listdef build_input_features(feature_columns, prefix=''):input_features = OrderedDict()for fc in feature_columns:if isinstance(fc, SparseFeat):input_features[fc.name] = Input(shape=(1,), name=prefix + fc.name, dtype=fc.dtype)elif isinstance(fc, DenseFeat):input_features[fc.name] = Input(shape=(fc.dimension,), name=prefix + fc.name, dtype=fc.dtype)elif isinstance(fc, VarLenSparseFeat):input_features[fc.name] = Input(shape=(fc.maxlen,), name=prefix + fc.name,dtype=fc.dtype)if fc.weight_name is not None:input_features[fc.weight_name] = Input(shape=(fc.maxlen, 1), name=prefix + fc.weight_name,dtype="float32")if fc.length_name is not None:input_features[fc.length_name] = Input((1,), name=prefix + fc.length_name, dtype='int32')else:raise TypeError("Invalid feature column type,got", type(fc))return embedding
深度学习框架Keras中的embedding简单理解 - 简书
def create_embedding_dict(sparse_feature_columns, varlen_sparse_feature_columns, seed, l2_reg,prefix='sparse_', seq_mask_zero=True):sparse_embedding = {}for feat in sparse_feature_columns:emb = Embedding(feat.vocabulary_size, feat.embedding_dim,embeddings_initializer=feat.embeddings_initializer,embeddings_regularizer=l2(l2_reg),name=prefix + '_emb_' + feat.embedding_name)emb.trainable = feat.trainablesparse_embedding[feat.embedding_name] = embif varlen_sparse_feature_columns and len(varlen_sparse_feature_columns) > 0:for feat in varlen_sparse_feature_columns:# if feat.name not in sparse_embedding:emb = Embedding(feat.vocabulary_size, feat.embedding_dim,embeddings_initializer=feat.embeddings_initializer,embeddings_regularizer=l2(l2_reg),name=prefix + '_seq_emb_' + feat.name,mask_zero=seq_mask_zero)emb.trainable = feat.trainablesparse_embedding[feat.embedding_name] = embreturn # -*- coding:utf-8 -*-
"""
Author:Weichen Shen, weichenswc@163.com
Reference:[1] Guo H, Tang R, Ye Y, et al. Deepfm: a factorization-machine based neural network for ctr prediction[J]. arXiv preprint arXiv:1703.04247, 2017.(https://arxiv.org/abs/1703.04247)
"""from itertools import chainfrom tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Densefrom ..feature_column import build_input_features, get_linear_logit, DEFAULT_GROUP_NAME, input_from_feature_columns
from ..layers.core import PredictionLayer, DNN
from ..layers.interaction import FM
from ..layers.utils import concat_func, add_func, combined_dnn_inputdef DeepFM(linear_feature_columns, dnn_feature_columns, fm_group=(DEFAULT_GROUP_NAME,), dnn_hidden_units=(256, 128, 64),l2_reg_linear=0.00001, l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False, task='binary'):"""Instantiates the DeepFM Network architecture.:param linear_feature_columns: An iterable containing all the features used by the linear part of the model.:param dnn_feature_columns: An iterable containing all the features used by the deep part of the model.:param fm_group: list, group_name of features that will be used to do feature interactions.:param dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of DNN:param l2_reg_linear: float. L2 regularizer strength applied to linear part:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector:param l2_reg_dnn: float. L2 regularizer strength applied to DNN:param seed: integer ,to use as random seed.:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.:param dnn_activation: Activation function to use in DNN:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN:param task: str, ``"binary"`` for binary logloss or ``"regression"`` for regression loss:return: A Keras model instance."""features = build_input_features(linear_feature_columns + dnn_feature_columns)inputs_list = list(features.values())linear_logit = get_linear_logit(features, linear_feature_columns, seed=seed, prefix='linear',l2_reg=l2_reg_linear)group_embedding_dict, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed, support_group=True)fm_logit = add_func([FM()(concat_func(v, axis=1))for k, v in group_embedding_dict.items() if k in fm_group])dnn_input = combined_dnn_input(list(chain.from_iterable(group_embedding_dict.values())), dense_value_list)dnn_output = DNN(dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)dnn_logit = Dense(1, use_bias=False)(dnn_output)final_logit = add_func([linear_logit, fm_logit, dnn_logit])output = PredictionLayer(task)(final_logit)model = Model(inputs=inputs_list, outputs=output)return model
3 其他实现方式
GitHub - as472780551/ctr_Keras: LR, Wide&Deep, DCN, NFM, DeepFM, NFFM
ctr_Keras
很简单的ctr模型实现,欢迎指出bug&提出宝贵意见!
模型
LR
FNN:http://www0.cs.ucl.ac.uk/staff/w.zhang/rtb-papers/deep-ctr.pdf
Wide&Deep:https://arxiv.org/abs/1606.07792
IPNN:https://arxiv.org/abs/1611.00144
DCN:https://arxiv.org/abs/1708.05123
NFM:https://www.comp.nus.edu.sg/~xiangnan/papers/sigir17-nfm.pdf
DeepFM:https://arxiv.org/abs/1703.04247
NFFM:腾讯赛冠军模型
数据集
kaggle-criteo-2014 dataset
Kaggle Display Advertising Challenge Dataset - Criteo Engineering
数据集按9:1划分,请自行划分
| train | test |
|---|---|
| 41256556 | 4584063 |
预处理
连续型特征(13):缺失值补0,离散分桶
离散型特征(26):过滤频率低于10的特征值
执行步骤
运行preprocess.py生成train.csv和test.csv文件
python preprocess.py
运行相应的ctr模型代码文件,如
python lr.py代码:
Embedding理解及keras中Embedding参数详解,代码案例说明_小时不识月123的博客-CSDN博客
from keras.layers.embeddings import Embedding
keras.layers.Embedding(input_dim, #词汇表大小,就是你的文本里你感兴趣词的数量
output_dim, #词向量的维度
embeddings_initializer='uniform',# Embedding矩阵的初始化方法
embeddings_regularizer=None,# Embedding matrix 的正则化方法
activity_regularizer=None,
embeddings_constraint=None, # Embedding matrix 的约束函数
mask_zero=False, #是否把 0 看作"padding" 值,取值为True时,接下来的所有层都必须支持 masking,词汇表的索引要从1开始(因为文档填充用的是0,如果词汇表索引从0开始会产生混淆,input_dim
=vocabulary + 1)
input_length=None)# 输入序列的长度,就是文档经过padding后的向量的长度。'''函数输入:尺寸为(batch_size, input_length)的2D张量,
batch_size就是你的mini batch里的样本量,
input_length就是你的文档转化成索引向量(每个词用词索引表示的向量)后的维数。函数输出:尺寸为(batch_size, input_length,output_dim)的3D张量,
上面说了,output_dim就是词向量的维度,就是词转化为向量,这个向量的维度,
比如word2vec把“哈哈”转化为向量[1.01,2.9,3],那么output_dim就是3.
'''
embedding
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
@author:
@contact:
@time:
@context:
"""
from keras.layers.embeddings import Embedding
from keras.models import Sequential
import numpy as np#我们随机生成第一层输入,即每个样本存储于单独的list,此list里的每个特征或者说元素用正整数索引表示,同时所有样本构成list
input_array = np.random.randint(1000, size=(32, 10))
'''
[[250 219 228 56 572 110 467 214 173 342][678 13 994 406 678 995 966 398 732 715]...[426 519 254 180 235 707 887 962 834 269][775 380 706 784 842 369 514 265 797 976][666 832 821 953 369 836 656 808 562 263]]
'''model = Sequential()
model.add(Embedding(1000, 64, input_length=10))#词汇表里词999,词向量的维度64,输入序列的长度10
# keras.layers.Embedding(input_dim, output_dim, input_length)#词汇表大小,词向量的维度,输入序列的长度print(model.input_shape)
print(model.output_shape)
'''
(None, 10) #其中 None的取值是batch_size
(None, 10, 64)input_shape:函数输入,尺寸为(batch_size, 10)的2D张量(矩阵的意思)
output_shape:函数输出,尺寸为(batch_size, 10,64)的3D张量
'''model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64)
print(output_array)
print(len(output_array))
print(len(output_array[1]))
print(len(output_array[1][1]))
'''
[
[[] [] [] ... [] [] []]
[[] [] [] ... [] [] []]
...
[[] [] [] ... [] [] []]
]32:最外层维数32,32个样本
10:第二层维数10,每个样本用10个词表示
64:最内层维数64,每个词用64维向量表示
'''
for cat in cat_columns:input = Input(shape=(1,))cat_field_input.append(input)nums = pd.concat((train[cat], test[cat])).max() + 1embed = Embedding(nums, 1, input_length=1, trainable=True)(input)def base_model(cat_columns, train, test):cat_num = len(cat_columns)field_cnt = cat_numcat_field_input = []field_embedding = []lr_embedding = []for cat in cat_columns:input = Input(shape=(1,))cat_field_input.append(input)nums = pd.concat((train[cat], test[cat])).max() + 1embed = Embedding(nums, 1, input_length=1, trainable=True)(input)reshape = Reshape((1,))(embed)lr_embedding.append(reshape)# fm embeddingsfield = []embed = Embedding(nums, 10, input_length=1, trainable=True)(input)reshape = Reshape((10,))(embed)field_embedding.append(reshape)# fm embeddings#######fm layer##########fm_square = Lambda(lambda x: K.square(x))(add(field_embedding))square_fm = add([Lambda(lambda x:K.square(x))(embed)for embed in field_embedding])inner_product = subtract([fm_square, square_fm])inner_product = Lambda(lambda x: K.sum(x / 2, axis=-1, keepdims=True))(inner_product)#######dnn layer##########embed_layer = concatenate(field_embedding, axis=-1)embed_layer = Dense(64)(embed_layer)embed_layer = BatchNormalization()(embed_layer)embed_layer = Activation('relu')(embed_layer)embed_layer = Dense(64)(embed_layer)embed_layer = BatchNormalization()(embed_layer)embed_layer = Activation('relu')(embed_layer)embed_layer = Dense(1)(embed_layer)########linear layer##########lr_layer = add(lr_embedding + [embed_layer, inner_product])preds = Activation('sigmoid')(lr_layer)opt = Adam(0.001)model = Model(inputs=cat_field_input, outputs=preds)model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['acc'])print(model.summary())return model4何为focal loss
focal loss 是随网络RetinaNet一起提出的一个令人惊艳的损失函数 paper 下载,主要针对的是解决正负样本比例严重偏斜所产生的模型难以训练的问题。
在keras中使用此函数作为损失函数,只需在编译模型时指定损失函数为focal loss:
model.compile(loss=[binary_focal_loss(alpha=.25, gamma=2)], metrics=["accuracy"], optimizer=optimizer)
参考
- 深度学习推荐系统作业:deepFM介绍和代码实现_deepfm代码_J_co的博客-CSDN博客
- CTR算法总结_Roger-Liu的博客-CSDN博客
- DeepCTR模型优缺点对比_deepctr训练加速_ChristineC_的博客-CSDN博客
- deepFm的keras实现_deepfm keras_xxaxtt的博客-CSDN博客
- 如何用keras实现deepFM_DemonHunter211的博客-CSDN博客
- 最通俗的deepFM理解及keras实现_keras实现deepfm_Mr_不想起床的博客-CSDN博客
- 用Keras实现一个DeepFM_deepfm 基于libsvm实现_蕉叉熵的博客-CSDN博客
- DeepCTR:易用可扩展的深度学习点击率预测算法包 - 知乎
- python:sklearn标签编码(LabelEncoder)_sklearn labelencoder_jenny_paofu的博客-CSDN博客
- 【推荐系统】DeepFM模型_deepfm多分类求auc_—Xi—的博客-CSDN博客
- GitHub - shenweichen/DeepCTR: Easy-to-use,Modular and Extendible package of deep-learning based CTR models .
- 理解:推荐算法之DeepFM_Aliert的博客-CSDN博客
相关文章:
推荐系统1--Deepfm学习笔记
目录 1 keras实现Deepfm demo 2 deepctr模版 3 其他实现方式 ctr_Kera 模型 数据集 预处理 执行步骤 4何为focal loss 参考 1 keras实现Deepfm 假设我们有两种 field 的特征,连续型和离散型,连续型 field 一般不做处理沿用原值,离散型一…...
javaDoc生成方式
javaDoc生成方式 命令行生成 在cmd控制台窗口上找到需要生成文件的路径,然后执行命令。 # javadoc -encoding UTF-8 -charset UTF-8 文件名 javadoc -encoding UTF-8 -charset UTF-8 Doc.java这样就生成完成了。 测试Doc.java文件 package com.jiang.base;/***…...

Armv9 registers
A64指令集包括访问system registers编码空间的指令。这些指令有: Access to System registers, including the debug registers, that provide system control, and system status information.Access to Special-purpose registers such as SPSR_ELx, ELR_ELx, an…...
套接字实现TCP
套接字 套接字的意义就是客户端与服务器进行双向通信的端点,如果有不理解点上面套接字三字更近距离了解套接字。 网络套接字与客户连接的特定网络有关的服务端口号,这个端口号允许linux进入特定的端口号的连接转到正确的服务器进程。 套接字通信的建立过…...
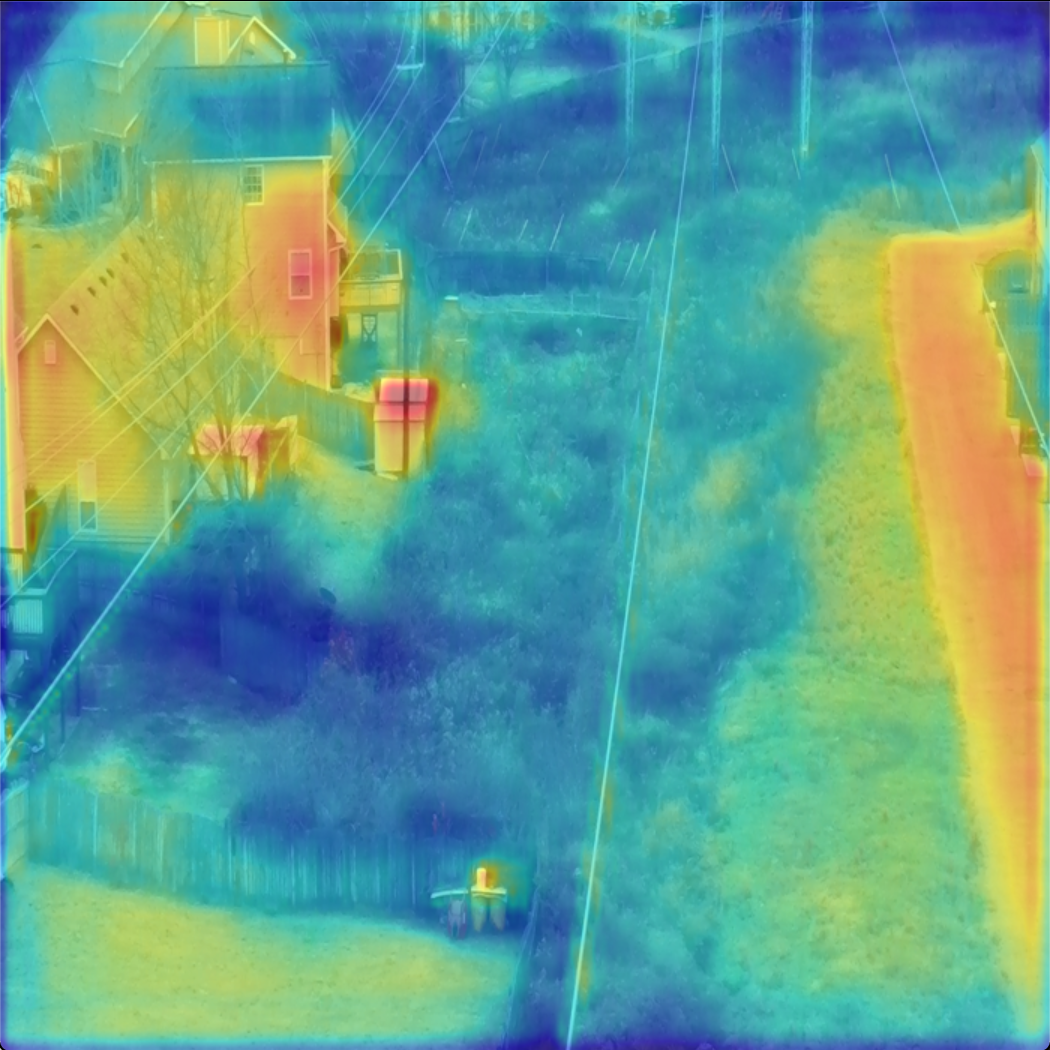
MMSeg绘制模型指定层的Heatmap热力图
文章首发及后续更新:https://mwhls.top/4475.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 摘要:绘制模型指定层的热力图 可视化环境安装 …...
关于Paul C.R. - Inductance_ Loop and partial-Wiley (2009)一书的概括
环感抗和部分感抗是两种不同的电路元件,它们通常用于描述不同类型的导体结构中的电流承载能力。 环感抗通常用于描述绕制在磁性芯上的线圈。当电流通过线圈时,它会在磁性芯中产生一个磁场,这个磁场又会对线圈产生一个磁通量。这个磁通量的大…...

基于支持向量机SVM的面部表情分类预测
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 SVM应用实例,基于SVM的面部表情分类预测 代码 结果分析 展望 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型,它的基本…...
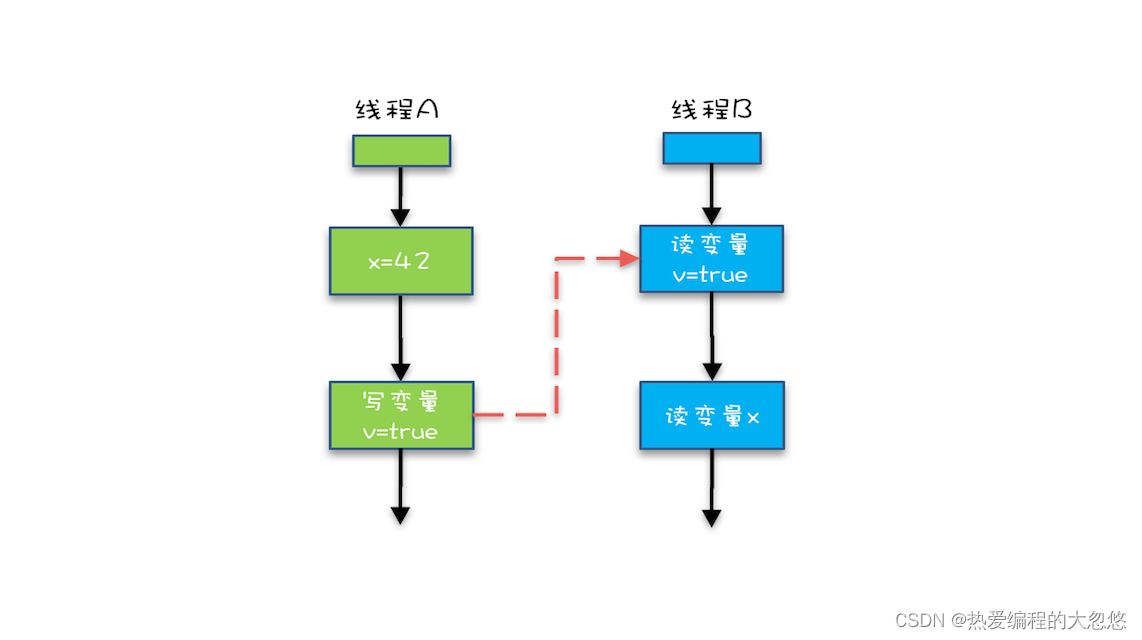
java内存模型的理解
java内存模型的理解并发问题产生的源头缓存导致的可见性问题线程切换导致的原子性问题编译优化带来的有序性问题小结Java内存模型: 解决可见性和有序性问题Java内存模型与JVM内存模型的区别volatile关键字Happens-Before规则小结思考题参考并发问题产生的源头 缓存导致的可见性…...
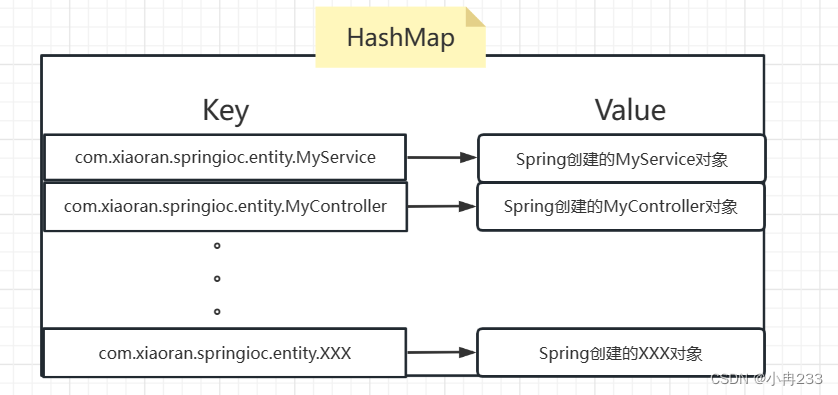
自己写一个简单的IOC
什么是SpringIOC? 答:IOC即控制反转,就是我们不在手动的去new一个对象,而是将创建对象的权力交给Spring去管理,我们想要一个User类型的对象,就只需要定义一个User类型的变量user1,然后让Spring去…...
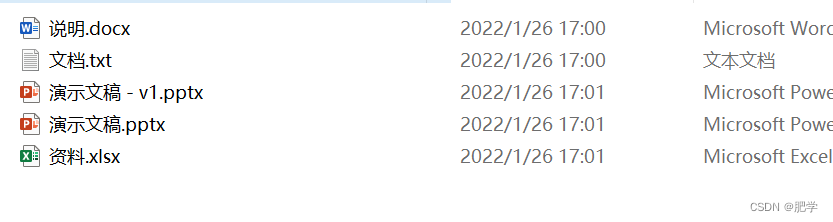
用Python批量重命名文件
案例 今天,我们来整理文件夹中的文件,给某个文件夹下的所有文件重新命名。要求是给所有文件按照修改时间,按顺序在文件名前面加上编号。比如将文件资料.xlsx重命名为1. 资料.xlsx import osdef Get_modify_time(file):return os.path.getmtime(file) #获取文件修改时间path…...
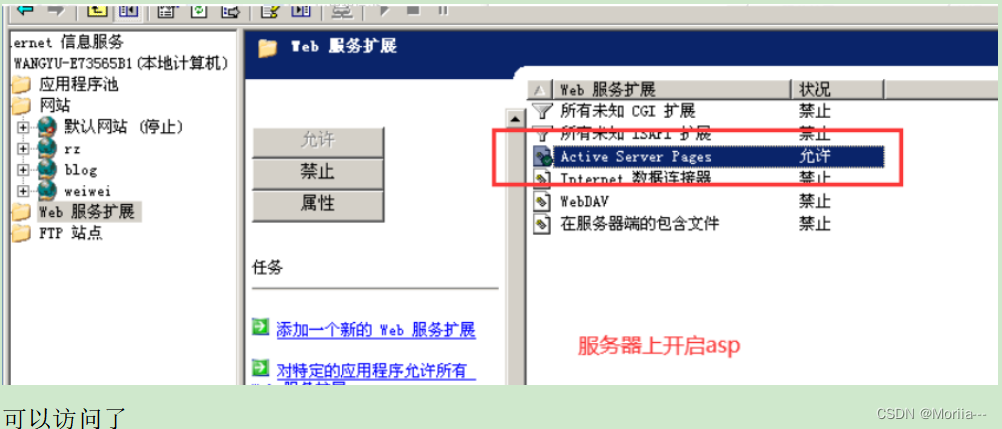
iis之web服务器搭建、部署(详细)~千锋
目录 Web服务器 部署web服务器 实验一 发布一个静态网站 实验二 一台服务器同时发布多个web站点 网站类型 Web服务器 也叫网页服务或HTTP服务器web服务器使用的协议是HTTPHTTP协议端口号:TCP 80、HTTPS协议端口号:TCP 443Web服务器发布软件&…...
javascript的ajax
学什么Ajax基础JSON跨域XHR对象Ajax进阶Ajax应用Ajax扩展Ajax基础初识 AjaxAjax的基本用法GET请求POST请求JSON初识JSONJSON的3种形式JSON的常用方法跨域初识跨域CORS跨域资源共享JSONPXHR 对象XHR的属性XHR的方法XHR的事件Ajax进阶FormData封装Ajax使用Promise改造封装好的Aja…...

SpringBoot入门 - 开发中还有哪些常用注解
本文主要介绍一些SpringBoot中常用的注解。Spring Boot 常用注解SpringBootApplicationTarget(ElementType.TYPE) Retention(RetentionPolicy.RUNTIME) Documented Inherited Configuration EnableAutoConfiguration ComponentScan public interface SpringBootApplication {/*…...
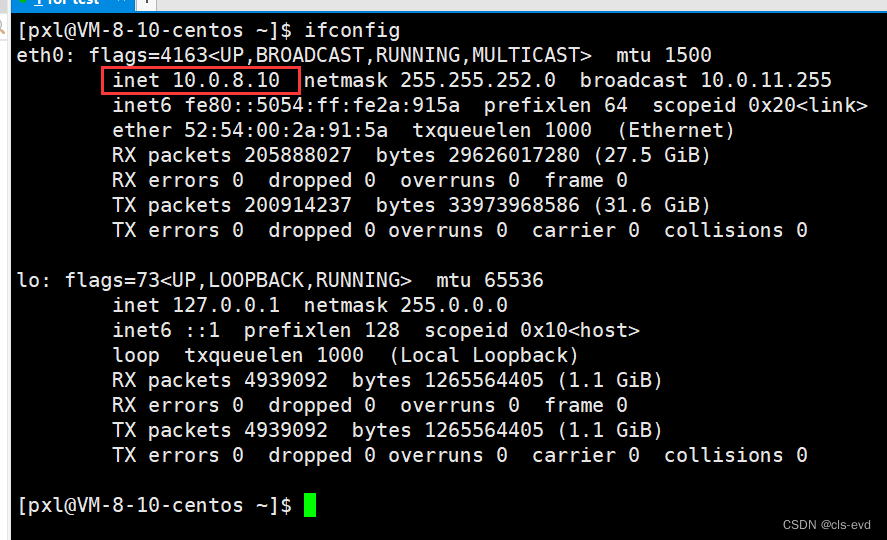
网络基础(三)
目录 网络层与数据链路层 编辑 网络层 IP协议 IP的构成 TCP和IP各自解决什么问题? 基本概念 协议头格式 协议头分析 如何分离与封装? 如何分用(向上交付)? 16位首部校验和 32位源IP和目的IP 4位版本 8位服务类型(Type Of…...

Go语言函数高级篇
Go语言函数高级篇1.高阶函数函数作为参数函数作为返回值2.匿名函数3.defer4.内置函数1.高阶函数 高阶函数分为函数作为参数和函数作为返回值两部分。 函数作为参数 函数可以作为参数: package mainimport "fmt"func add(x, y int) int {return x y }…...
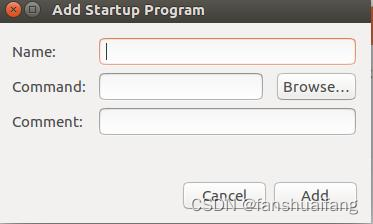
ubuntu16.04 python代码自启动和可执行文件自启动
1 python代码自启动 参考 https://blog.csdn.net/qq_38288618/article/details/104096606 准备好python文件 test.py import time c1 while 1:time.sleep(1)cc1print(c)运行 sudo chmod 777 test.py python3 test.py准备run.sh 文件 #!/bin/bash gnome-terminal -x bash -…...
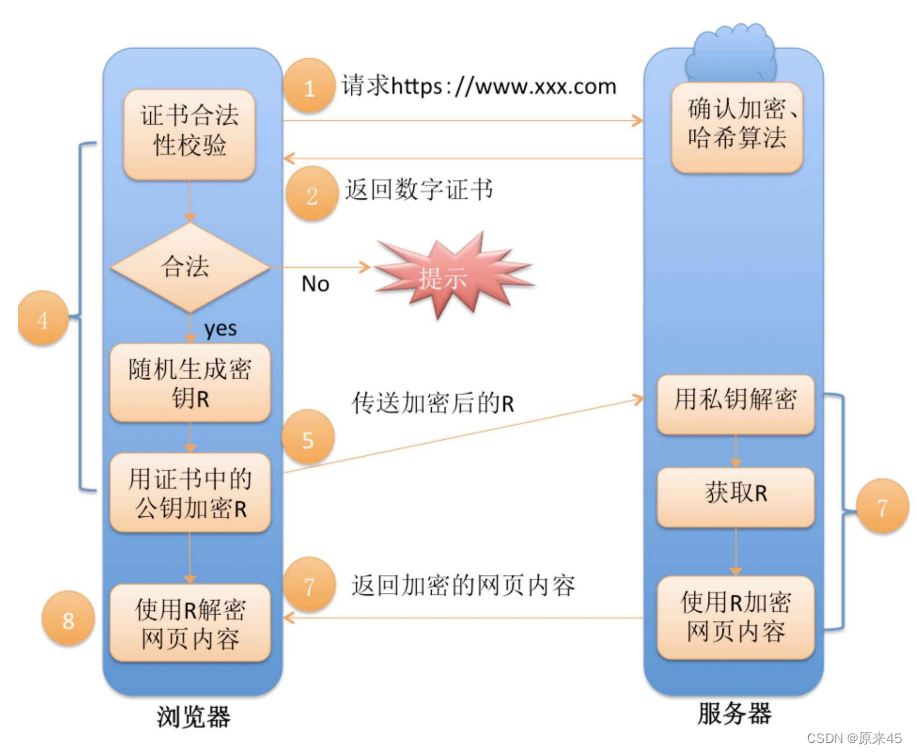
应用层协议 HTTP HTTPS
目录 应用层 再谈 "协议" 序列化和反序列化 关于 json库 request序列化 request反序列化 response序列化 response反序列化 PS:命令宏 HTTP协议 认识URL urlencode和urldecode HTTP协议格式 HTTP请求 HTTP响应 请求方法 编辑 HT…...

图神经网络 pytorch GCN torch_geometric KarateClub 数据集
图神经网络 安装Pyg 首先安装torch_geometric需要安装pytorch然后查看一下自己电脑Pytorch的版本 import torch print(torch.__version__) #1.12.0cu113然后进入官网文档网站 链接: https://pytorch-geometric.readthedocs.io/en/latest/install/installation.html 安装自己…...

【博学谷学习记录】超强总结,用心分享丨人工智能 自然语言处理 文本特征处理小结
目录文本特征处理作用常见的文本特征处理方法添加n-gram特征说明提取n-gram文本长度规范说明实现导包问题记录心得文本特征处理作用 文本特征处理包括为语料添加具有普适性的文本特征, 如:n-gram特征 以及对加入特征之后的文本语料进行必要的处理, 如: 长度规范. 这些特征处…...

2023年中职网络安全竞赛解析——隐藏信息探索
隐藏信息探索 需求环境可私信博主,求个三连! 1.访问服务器的FTP服务,下载图片QR,从图片中获取flag,并将flag提交; 2.访问服务器的FTP服务,下载文件document,从文件中获取flag,并将flag提交; 3.访问服务器的FTP服务,下载图片beach,从图片中获取flag,并将flag提交…...

终极指南:3分钟掌握Silk v3音频转换,彻底解决微信QQ语音播放难题
终极指南:3分钟掌握Silk v3音频转换,彻底解决微信QQ语音播放难题 【免费下载链接】silk-v3-decoder [Skype Silk Codec SDK]Decode silk v3 audio files (like wechat amr, aud files, qq slk files) and convert to other format (like mp3). Batch con…...
)
避坑指南:QML调用C++时那些让你debug到崩溃的隐藏问题(Qt5/6通用)
QML与C交互避坑实战:信号槽、内存管理与类型转换的终极解决方案 第一次在QML中调用C对象时,那种跨语言调用的兴奋感很快会被各种诡异问题冲淡——信号死活不触发、对象莫名其妙被销毁、类型转换时程序崩溃...这些问题往往让开发者陷入数小时的debug泥潭。…...

2026年木蜡油定做厂家大盘点,究竟哪家才是行业首选?
在当今注重环保和品质的时代,木蜡油作为一种天然环保的涂料,受到了越来越多消费者的青睐。无论是室内外木器家具、木艺制品,还是全屋定制、装饰装修等领域,木蜡油都有着广泛的应用。然而,市场上木蜡油定做厂家众多&…...

降AI后怎么做知网查重不超标:降AI和查重双通过的操作方法
降AI后怎么做知网查重不超标:降AI和查重双通过的操作方法 被问了太多次降AI后查重相关的问题,写一篇完整教程。 主要工具是嘎嘎降AI(www.aigcleaner.com),4.8元。第一次用的话有些细节知道和不知道差别挺大的。 操作…...

OpenClaw内存优化:千问3.5-35B-A3B-FP8在8GB设备的运行技巧
OpenClaw内存优化:千问3.5-35B-A3B-FP8在8GB设备的运行技巧 1. 为什么需要内存优化 当我第一次尝试在8GB内存的MacBook Pro上运行千问3.5-35B-A3B-FP8模型时,系统几乎立即崩溃了。这让我意识到,想要在资源有限的设备上运行大型语言模型&…...

3大突破让实时翻译不再阻碍跨语言体验
3大突破让实时翻译不再阻碍跨语言体验 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 在全球化浪潮下,语言障碍…...

双向互转|IEC104↔Modbus 工业网关,电力 / 工业现场一键通联
一、产品核心定位三格电子推出SG-IEC104-TCP与SG-TCP-IEC104两款工业级网关,专为电力、能源、智能制造场景打造,实现IEC104 与 Modbus 双向协议转换,兼容 DLT645 电表采集,支持 MQTT 上云,打通电力主站与现场设备的数据…...

卡证检测矫正模型惊艳案例:护照芯片区域反光消除+四角点亚像素定位
卡证检测矫正模型惊艳案例:护照芯片区域反光消除四角点亚像素定位 你有没有遇到过这样的烦恼?用手机拍身份证、护照或者驾照,准备上传办理业务时,系统总是提示“照片不清晰”、“证件边缘不完整”或者“请拍摄正面照”。尤其是护…...

CosyVoice2-0.5B实战案例:跨境电商独立站商品页嵌入式语音播放功能实现
CosyVoice2-0.5B实战案例:跨境电商独立站商品页嵌入式语音播放功能实现 1. 引言:当商品介绍会“说话” 想象一下,你正在浏览一个海外独立站的商品页面,琳琅满目的图片和文字描述让你有些眼花缭乱。这时,你看到一个“…...

Honey Select 2本地化增强补丁:技术实现与模块化架构深度解析
Honey Select 2本地化增强补丁:技术实现与模块化架构深度解析 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch作为Honey Select 2游戏社…...