Elasticsearch:使用 ELSER v2 进行语义搜索

在我之前的文章 “Elasticsearch:使用 ELSER 进行语义搜索”,我们展示了如何使用 ELESR v1 来进行语义搜索。在使用 ELSER 之前,我们必须注意的是:
重要:虽然 ELSER V2 已正式发布,但 ELSER V1 仍处于 [预览] 状态。此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束,并将保留在技术预览版中。
也就是说 ELSER v1 不建议在生产环境中使用。在生产的环境中,我们建议使用 ELSER v2。由于两个版本中的使用方法稍有不同。在今天的文章中,我们以 ELSER v2 为例来进行展示。
简介
Elastic Learned Sparse EncodeR(或 ELSER)是由 Elastic 训练的 NLP 模型,使你能够使用稀疏向量表示来执行语义搜索。 语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义来检索结果。
本教程中的说明向你展示如何使用 ELSER 对数据执行语义搜索。
注意:在使用 ELSER 进行语义搜索期间,仅考虑每个字段提取的前 512 个标记。 请参阅此页面了解更多信息。
要求
要使用 ELSER 执行语义搜索,你必须在集群中部署 NLP 模型。 请参阅 ELSER 文档以了解如何下载和部署模型。
注意:如果关闭部署自动扩展,则 Elasticsearch Service 中用于部署和使用 ELSER 模型的最小专用 ML 节点大小为 4 GB。 建议打开自动扩展功能,因为它允许你的部署根据需求动态调整资源。 通过使用更多分配或每次分配更多线程可以实现更好的性能,这需要更大的 ML 节点。 自动扩展可在需要时提供更大的节点。 如果关闭自动扩展,你必须自己提供适当大小的节点。
创建索引映射
首先,必须创建目标索引的映射 - 包含模型根据你的文本创建的 token 的索引。 目标索引必须具有 sparse_vector 或 rank_features 字段类型的字段才能对 ELSER 输出进行索引。
注意:ELSER 输出必须摄取到具有 sparse_vector 或 rank_features 字段类型的字段中。 否则,Elasticsearch 会将 token 权重对解释为文档中的大量字段。 如果你收到类似于 “Limit of total fields [1000] has been exceeded while adding new fields” 的错误,则 ELSER 输出字段未正确映射,并且其字段类型不同于 sparse_vector 或 rank_features。
PUT my-index
{"mappings": {"properties": {"content_embedding": { "type": "sparse_vector" },"content": { "type": "text" }}}
}- content_embedding 包含生成的 token 的字段的名称。 必须在下一步的推理管道配置中引用它。
- sparse_vector 定义字段是 sparse_vector 字段。
- 用于创建稀疏向量表示的字段的名称。 在此示例中,字段的名称是 content。 必须在下一步的推理管道配置中引用它。
- text 定义字段类型为文本。
使用推理处理器创建摄取管道
创建带有 inference processor 的 ingest pipeline,以使用 ELSER 来推理管道中摄取的数据。
PUT _ingest/pipeline/elser-v2-test
{"processors": [{"inference": {"model_id": ".elser_model_2","input_output": [ {"input_field": "content","output_field": "content_embedding"}]}}]
}- input_output:配置对象,定义推理过程的输入字段和包含推理结果的输出字段。
加载数据
在此步骤中,你将加载稍后在推理摄取管道中使用的数据,以从中提取 token。
使用 msmarco-passagetest2019-top1000 数据集,该数据集是 MS MARCO Passage Ranking 数据集的子集。 它由 200 个查询组成,每个查询都附有相关文本段落的列表。 所有独特的段落及其 ID 均已从该数据集中提取并编译到 tsv 文件中。
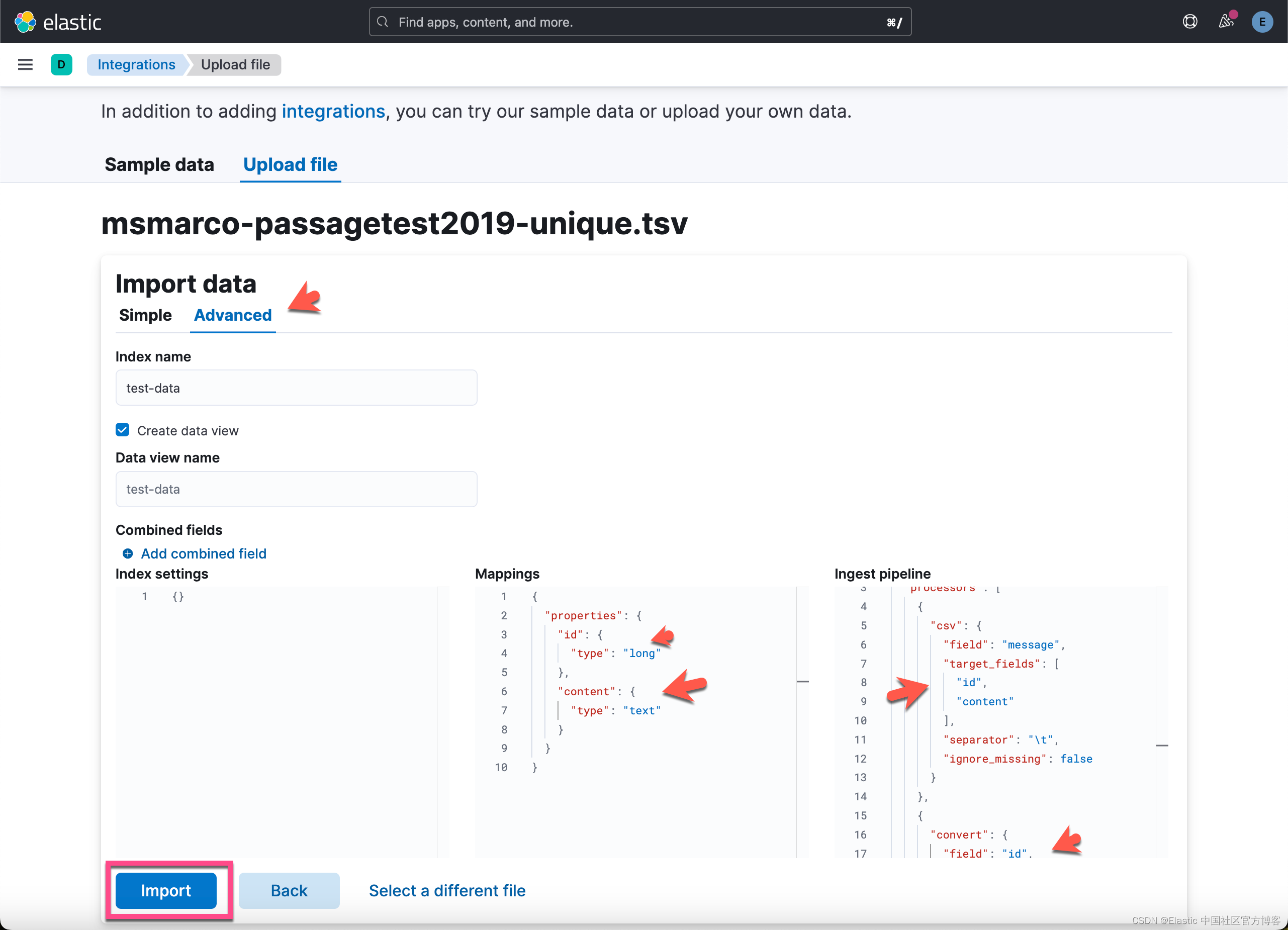
下载文件并使用机器学习 UI 中的数据可视化工具将其上传到集群。 将名称 id 分配给第一列,将内容分配给第二列。 索引名称是 test-data。 上传完成后,你可以看到名为 test-data 的索引,其中包含 182469 个文档。
关于如何加载这个数据,请详细阅读文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索”。


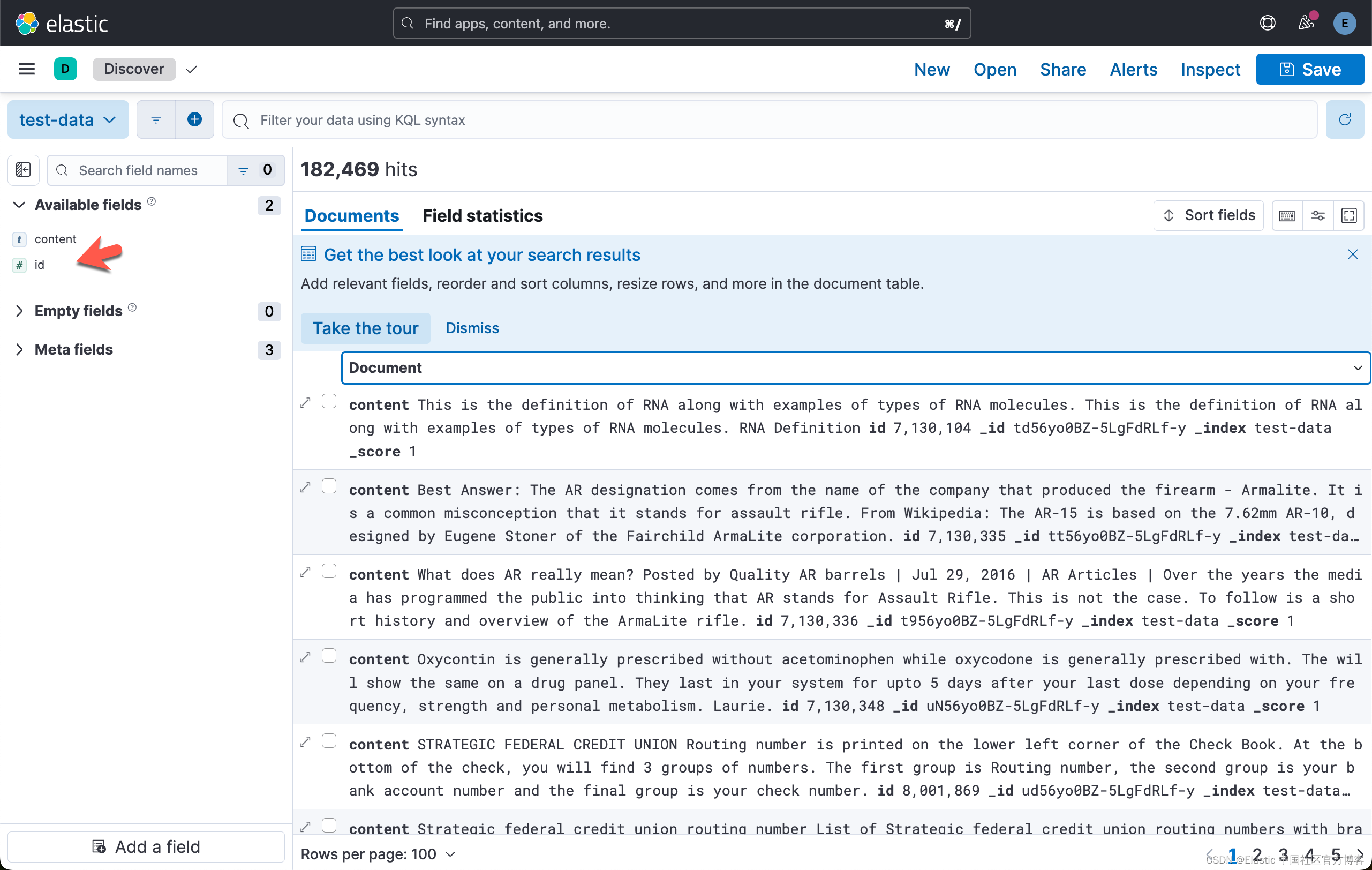
我们可以在 Discover 中进行查看:
通过推理摄取管道摄取数据
通过使用 ELSER 作为推理模型的推理管道重新索引数据,从文本创建标记。
POST _reindex?wait_for_completion=false
{"source": {"index": "test-data","size": 50 },"dest": {"index": "my-index","pipeline": "elser-v2-test"}
}- Reindex 的默认批量大小为 1000。将大小减小到较小的数字可以使重新索引过程的更新更快,使你能够密切跟踪进度并尽早发现错误。

该调用返回一个任务 ID 以监控进度:

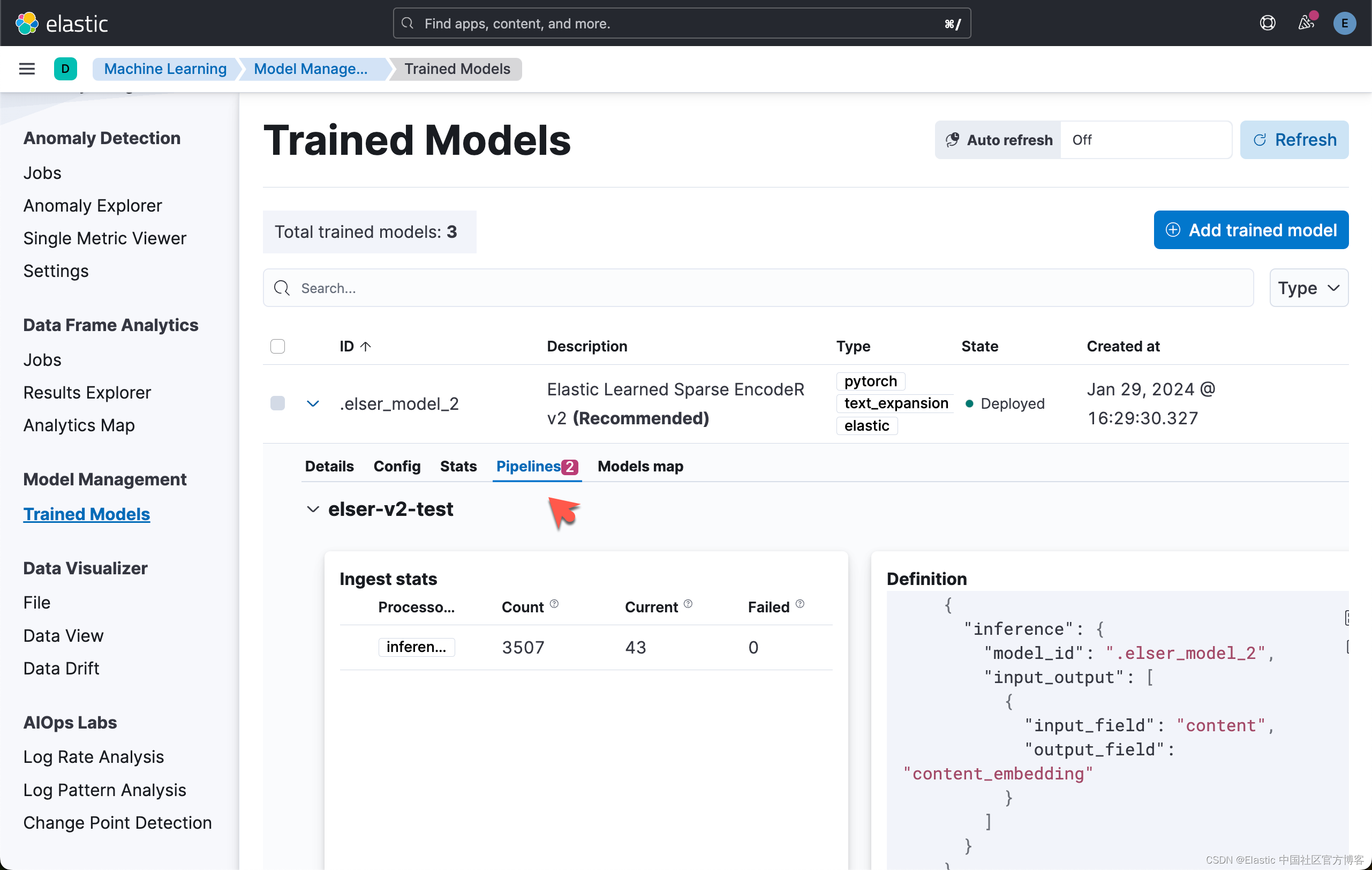
我们等到 completed 的状态变为 true:
你还可以打开训练模型 UI,选择 ELSER 下的 Pipelines 选项卡来跟踪进度。
使用 text_expansion 查询进行语义搜索
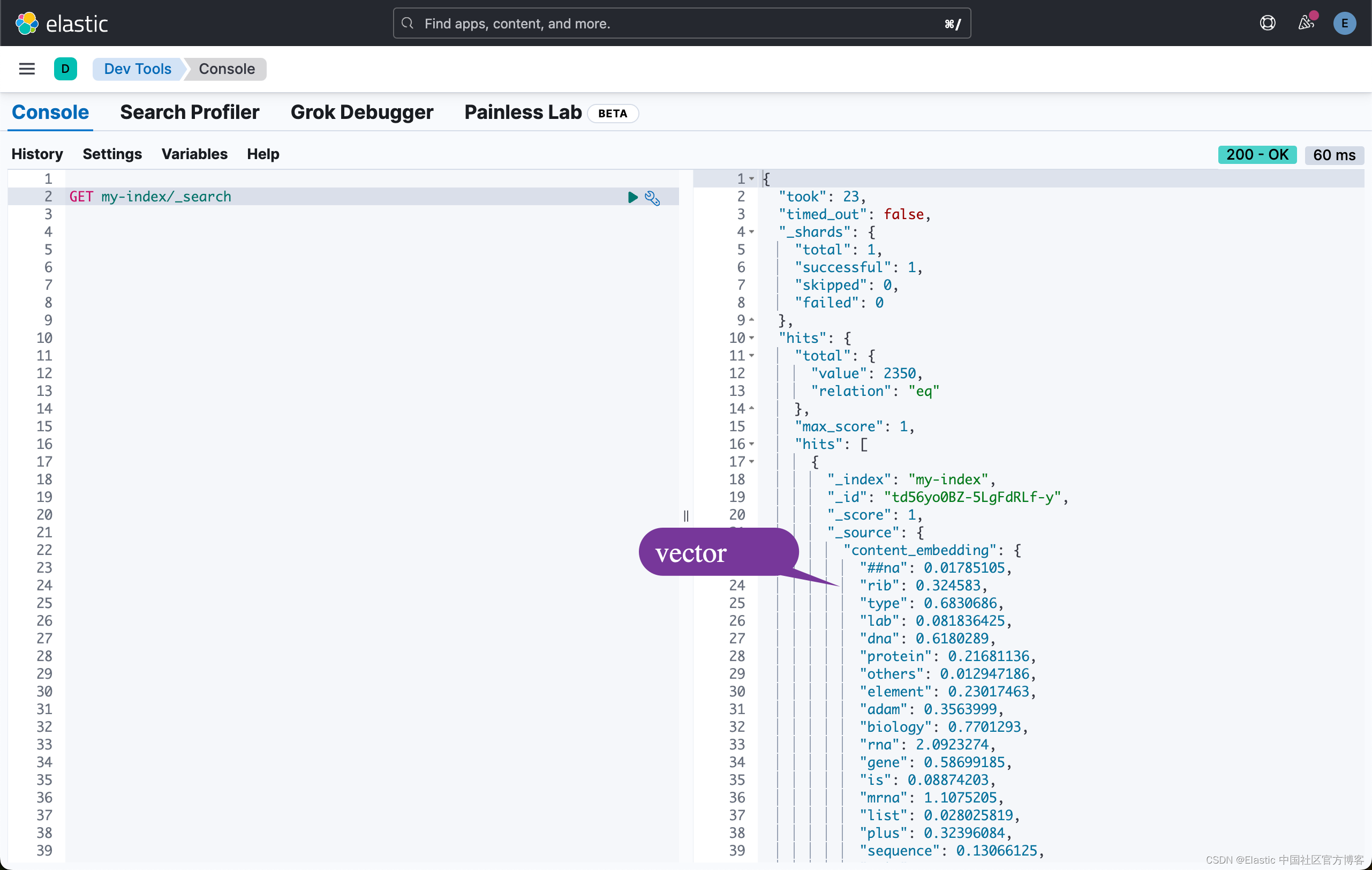
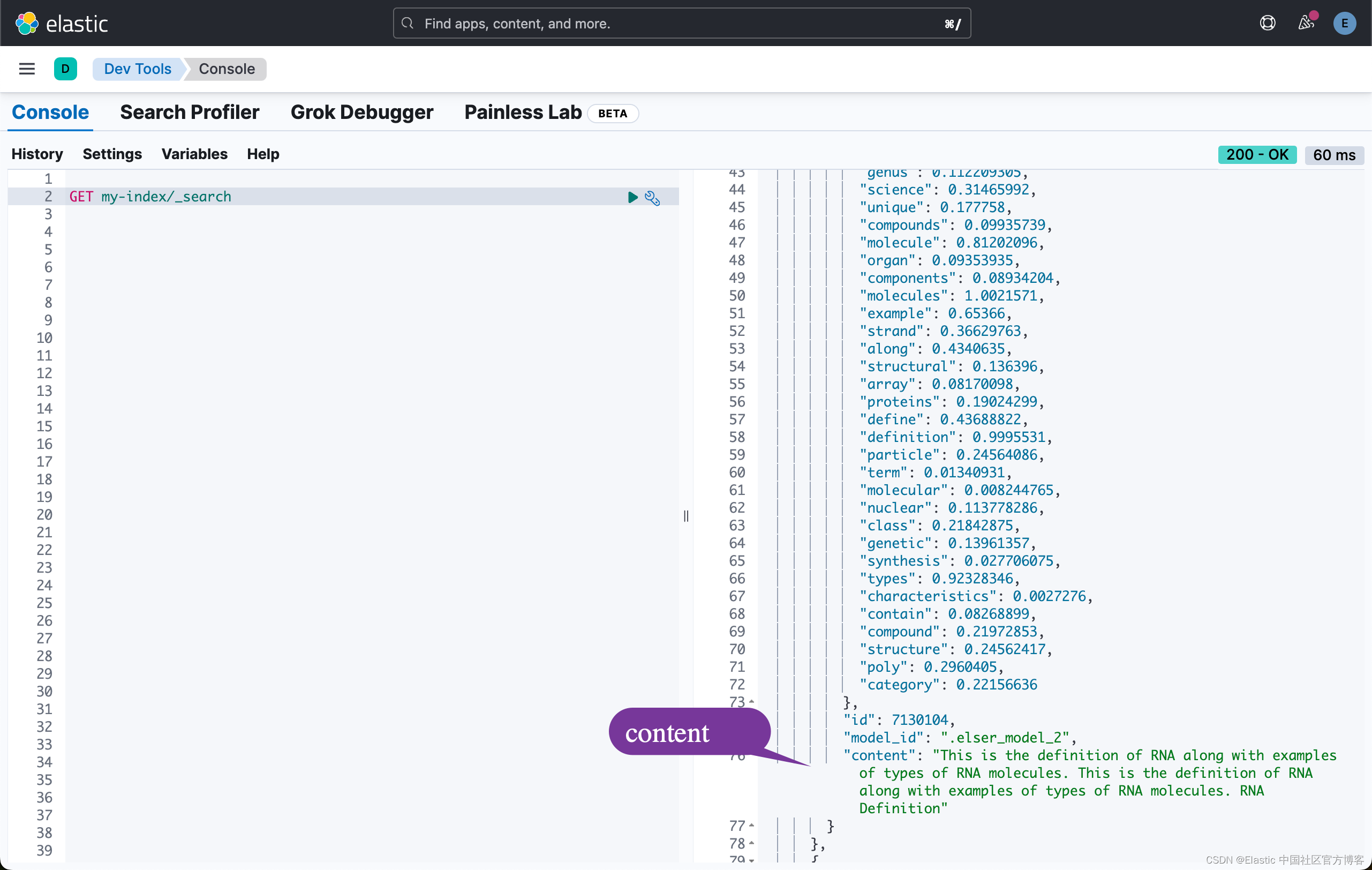
要执行语义搜索,请使用 text_expansion 查询,并提供查询文本和 ELSER 模型 ID。 下面的示例使用查询文本 “How to avoid muscle soreness after running?”,content_embedding 字段包含生成的 ELSER 输出:
GET my-index/_search
{"_source": false,"fields": ["content"], "query":{"text_expansion":{"content_embedding":{"model_id":".elser_model_2","model_text":"How to avoid muscle soreness after running?"}}}
}结果是 my-index 索引中按相关性排序的与你的查询文本含义最接近的前 10 个文档。 结果还包含为每个相关搜索结果提取的 token 及其权重。 标记是捕获相关性的学习关联,它们不是同义词。 要了解有关 token 是什么的更多信息,请参阅此页面。 可以从源中排除 token,请参阅下面的章节以了解更多信息。
{"took": 1531,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 10000,"relation": "gte"},"max_score": 25.669455,"hits": [{"_index": "my-index","_id": "fd96yo0BZ-5LgFdRMD7b","_score": 25.669455,"fields": {"content": ["There are a few foods and food groups that will help to fight inflammation and delayed onset muscle soreness (both things that are inevitable after a long, hard workout) when you incorporate them into your postworkout eats, whether immediately after your run or at a meal later in the day. Advertisement. Advertisement."]}},{"_index": "my-index","_id": "nt96yo0BZ-5LgFdRLQCy","_score": 23.388044,"fields": {"content": ["What so many out there do not realize is the importance of what you do after you work out. You may have done the majority of the work, but how you treat your body in the minutes and hours after you exercise has a direct effect on muscle soreness, muscle strength and growth, and staying hydrated. Cool Down. After your last exercise, your workout is not over. The first thing you need to do is cool down. Even if running was all that you did, you still should do light cardio for a few minutes. This brings your heart rate down at a slow and steady pace, which helps you avoid feeling sick after a workout."]}},{"_index": "my-index","_id": "ot96yo0BZ-5LgFdRLzD0","_score": 22.550915,"fields": {"content": ["If you’ve been exercising more, you may be suffering from the aches and pains of having overdone it at the gym. I’ve been there. Making sure your workout is challenging without overdoing it is one way to prevent muscle soreness. But research also points to some foods and beverages that can help ward off and minimize exercise-related muscle soreness, which we’ve reported on in EatingWell Magazine. Related: Foods to Eat to Improve Your Workout Post-Workout Breakfast Recipes What to Drink Before, During and After You Exercise. Blueberries."]}}...将语义搜索与其他查询相结合
你可以将 text_expansion 与复合查询中的其他查询结合起来。 例如,在布尔查询或全文查询中使用过滤子句,该查询可能会或可能不会使用与 text_expansion 查询相同的查询文本。 这使你能够合并两个查询的搜索结果。
text_expansion 查询的搜索命中得分往往高于其他 Elasticsearch 查询。 可以通过使用 boost 参数增加或减少每个查询的相关性分数来对这些分数进行正则化。 当存在不太相关的结果时,text_expansion 查询的召回率可能很高。 使用 min_score 参数来修剪那些不太相关的文档。
GET my-index/_search
{"query": {"bool": { "should": [{"text_expansion": {"content_embedding": {"model_text": "How to avoid muscle soreness after running?","model_id": ".elser_model_2","boost": 1 }}},{"query_string": {"query": "toxins","boost": 4 }}]}},"min_score": 10
}- text_expansion 和 query_string 查询都位于 bool 查询的 should 子句中。
- text_expansion 查询的 boost 值为 1,这是默认值。 这意味着该查询结果的相关性得分不会提高。
- query_string 查询的提升值为 4。 该查询结果的相关性得分增加,导致它们在搜索结果中排名更高。
- 仅显示分数等于或高于 10 的结果。
优化性能
通过从文档源中排除 ELSER token 来节省磁盘空间
必须对 ELSER 生成的 token 进行索引,以便在 text_expansion 查询中使用。 但是,没有必要在文档源中保留这些术语。 你可以通过使用 source exclude 映射从文档源中删除 ELSER 术语来节省磁盘空间。
警告:重新索引使用文档源来填充目标索引。 一旦 ELSER 术语从源中排除,就无法通过重新索引来恢复它们。 从源中排除 token 是一种节省空间的优化,只有在你确定将来不需要重新索引时才应应用该优化! 仔细考虑这种权衡并确保从源中排除 ELSER 术语符合你的特定要求和用例,这一点很重要。 仔细查看禁用 _source 字段和从 _source 中包含/排除字段部分,以详细了解从 _source 中排除 token 可能产生的后果。
可以通过以下 API 调用创建从 _source 字段中排除 content_embedding 的映射:
PUT my-index
{"mappings": {"_source": {"excludes": ["content_embedding"]},"properties": {"content_embedding": {"type": "sparse_vector"},"content": {"type": "text"}}}
}注意:根据你的数据,使用 track_total_hits: false 时文本扩展查询可能会更快。
更多阅读:Elasticsearch:使用 ELSER v2 文本扩展进行语义搜索
相关文章:
Elasticsearch:使用 ELSER v2 进行语义搜索
在我之前的文章 “Elasticsearch:使用 ELSER 进行语义搜索”,我们展示了如何使用 ELESR v1 来进行语义搜索。在使用 ELSER 之前,我们必须注意的是: 重要:虽然 ELSER V2 已正式发布,但 ELSER V1 仍处于 [预览…...

智慧农业之智能物流
智慧物流属于农业生产环节中的重要节点,上游为农业生产环节,下游为销售与商贸环节,因此,通过联通生产与销售环节,通过合理调配物流过程,可以实现对于农产品的快速运输与销售,减少中间环节中的无效损耗,从而实现增收节支,实实在在地解决了农产品利润偏低的问题。 生产…...

Redis主从、哨兵、Redis Cluster集群架构
Redis主从、哨兵、Redis Cluster集群架构 Redis主从架构 Redis主从架构搭建 主从搭建的问题 如果同步数据失败,查看log日志报错无法连接,检查是否端口未开放出现”Error reply to PING from master:...“日志,修改参数protected-mode no …...

Javascript 运算符、流程控制语句和数组
【三】运算符 【1】算数运算符 (1)分类 加减乘除:*/取余:%和python不一样的点:没有取整// (2)特殊的点 只要NaN参与运算得到的结果也是NaNnull转换成0,undefined转换成NaN 【2…...

电机驱动死区时间
电机驱动死区时间 电机驱动死区时间死区时间(Dead Time)自己话补充说明 电机驱动死区时间 电机驱动死区时间一般在几纳秒到几微秒之间,具体长度取决于所使用的电子器件。 一、什么是电机驱动死区时间? 电机驱动死区时间指的是在电…...

图像的压缩感知的MATLAB实现(第3种方案)
前面介绍了两种不同的压缩感知实现: 图像压缩感知的MATLAB实现(OMP) 压缩感知的图像仿真(MATLAB源代码) 上述两种方法还存在着“速度慢、精度低”等不足。 本篇介绍一种新的方法。 压缩感知(Compressed S…...
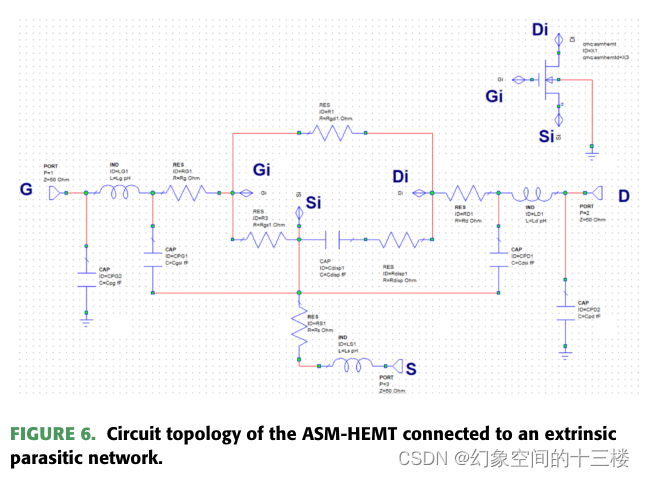
高温应用中GaN HEMT大信号建模的ASM-HEMT
来源:An ASM-HEMT for Large-Signal Modeling of GaN HEMTs in High-Temperature Applications(JEDS 23年) 摘要 本文报道了一种用于模拟高温环境下氮化镓高电子迁移率晶体管(GaN HEMT)的温度依赖性ASM-HEMT模型。我…...

文件上传---->生僻字解析漏洞
现在的现实生活中,存在文件上传的点,基本上都是白名单判断(很少黑名单了) 对于白名单,我们有截断,图片马,二次渲染,服务器解析漏洞这些,于是今天我就来补充一种在upload…...

Ubuntu中Python3找不到_sqlite3模块
今天跑一个代码,出现了一个找不到sqlite3模块的错误,错误如下: from _sqlite3 import * ModuleNotFoundError: No module named _sqlite3 网上查资料说,因为python3没有自带sqlite3相关方面的支持,要自己先安装然后再重新编译Py…...

HarmonyOS4.0系统性深入开发37 改善布局性能
改善布局性能 Flex为采用弹性布局的容器。容器内部的所有子元素,会自动参与弹性布局。子元素默认沿主轴排列,子元素在主轴方向的尺寸称为主轴尺寸。 在单行布局场景下,容器里子组件的主轴尺寸长度总和可能存在不等于容器主轴尺寸长度的情况…...

Internet协议
文章目录 Internet协议网络层协议IPV4协议IP地址:IPv4数据报格式IP数据报的封装和分片 Internet路由协议路由信息协议RIP开放最短路径优先协议OSPF外部网关协议BGP组播协议PIM和MOSPF ARP和RARPARP协议:RARP协议: Internet控制报文协议ICMPIP…...
深度学习基础(一)神经网络基本原理
之前的章节我们初步介绍了机器学习相关基础知识,目录如下: 机器学习基础(一)理解机器学习的本质-CSDN博客 机器学习基础(二)监督与非监督学习-CSDN博客 机器学习基础(四)非监督学…...

2024年2月22日 - mis
rootyy3568-alip:/sys# ls /sys/class/gpio/gpio* -F /sys/class/gpio/gpio114 /sys/class/gpio/gpiochip511 /sys/class/gpio/gpiochip0 /sys/class/gpio/gpiochip64 /sys/class/gpio/gpiochip128 /sys/class/gpio/gpiochip96 /sys/class/gpio/gpiochip32符号表示该文…...
【字符串处理】)
拼接 URL(C 语言)【字符串处理】
题目来自于博主算法大师的专栏:最新华为OD机试C卷AB卷OJ(CJavaJSPy) https://blog.csdn.net/banxia_frontend/category_12225173.html 题目 给定一个 url 前缀和 url 后缀 通过,分割 需要将其连接为一个完整的 url 如果前缀结尾和后缀开头都…...
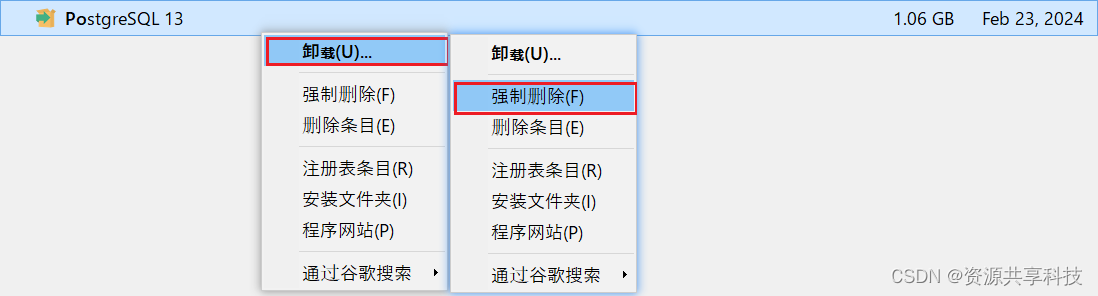
故障排除:Failed to load SQL Modules into database Cluster
PostgreSQL 安装和故障排除 重新安装前的准备工作 在重新安装 PostgreSQL 之前,确保完成以下步骤: 重新卸载 PostgreSQL 并重启电脑。 删除以下目录: C:\Program Files\PostgreSQL\13C:\Users\admin\AppData\Roaming\pgadmin 重启安装过…...
)
【超详细】HIVE 日期函数(当前日期、时间戳转换、前一天日期等)
文章目录 相关文献常量:当前日期、时间戳前一天日期、后一天日期获取日期中的年、季度、月、周、日、小时、分、秒等时间戳转换时间戳 to 日期日期 to 时间戳 日期之间月、天数差 作者:小猪快跑 基础数学&计算数学,从事优化领域5年&#…...
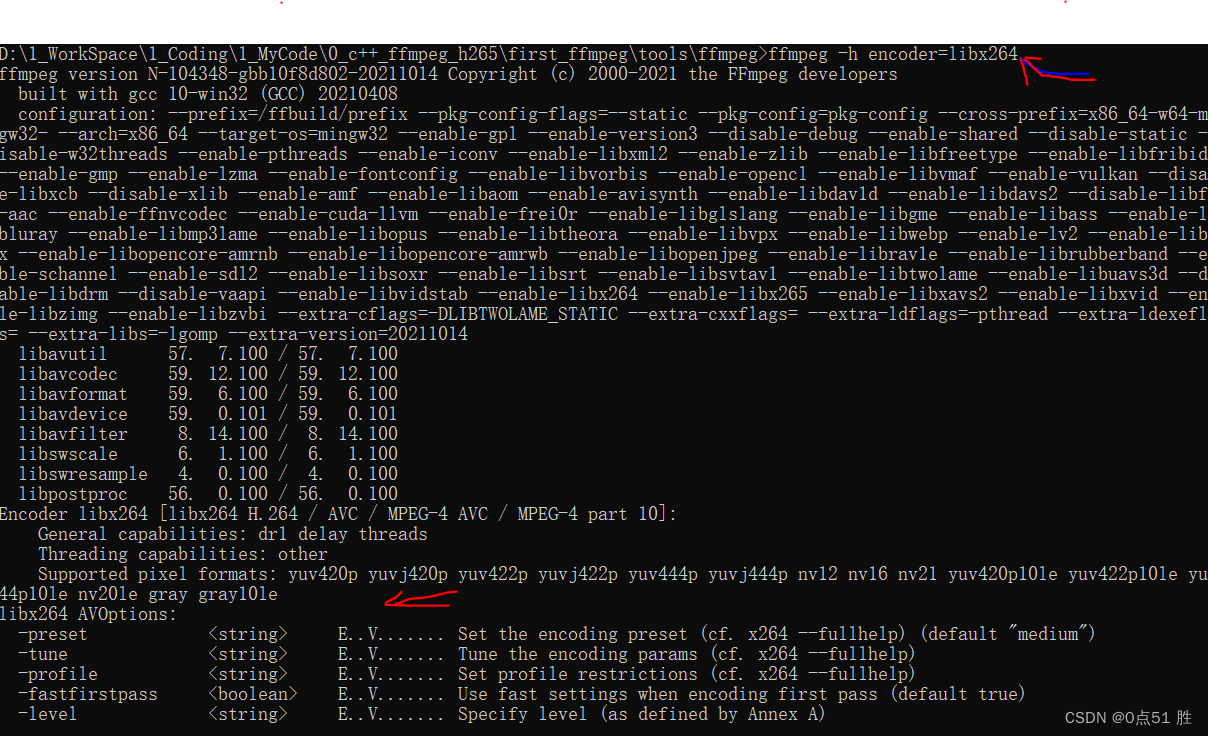
[ffmpeg] x264 配置参数解析
背景 创建 x264 编码器后,其有一组默认的编码器配置参数,也可以根据需要修改参数,来满足编码要求。 具体参数 可修改的参数,比较多,这边只列举一些常用的。 获取可以配置的参数 方式1 查看 ffmpeg源码 libx264.c…...
GO语言基础总结
多态: 定义一个父类的指针(接口),然后把指针指向子类的实例,再调用这个父类的指针,然后子类的方法被调用了,这就是多态现象。 Golang 高阶 goroutine 。。。。。 channel channel的定义 …...
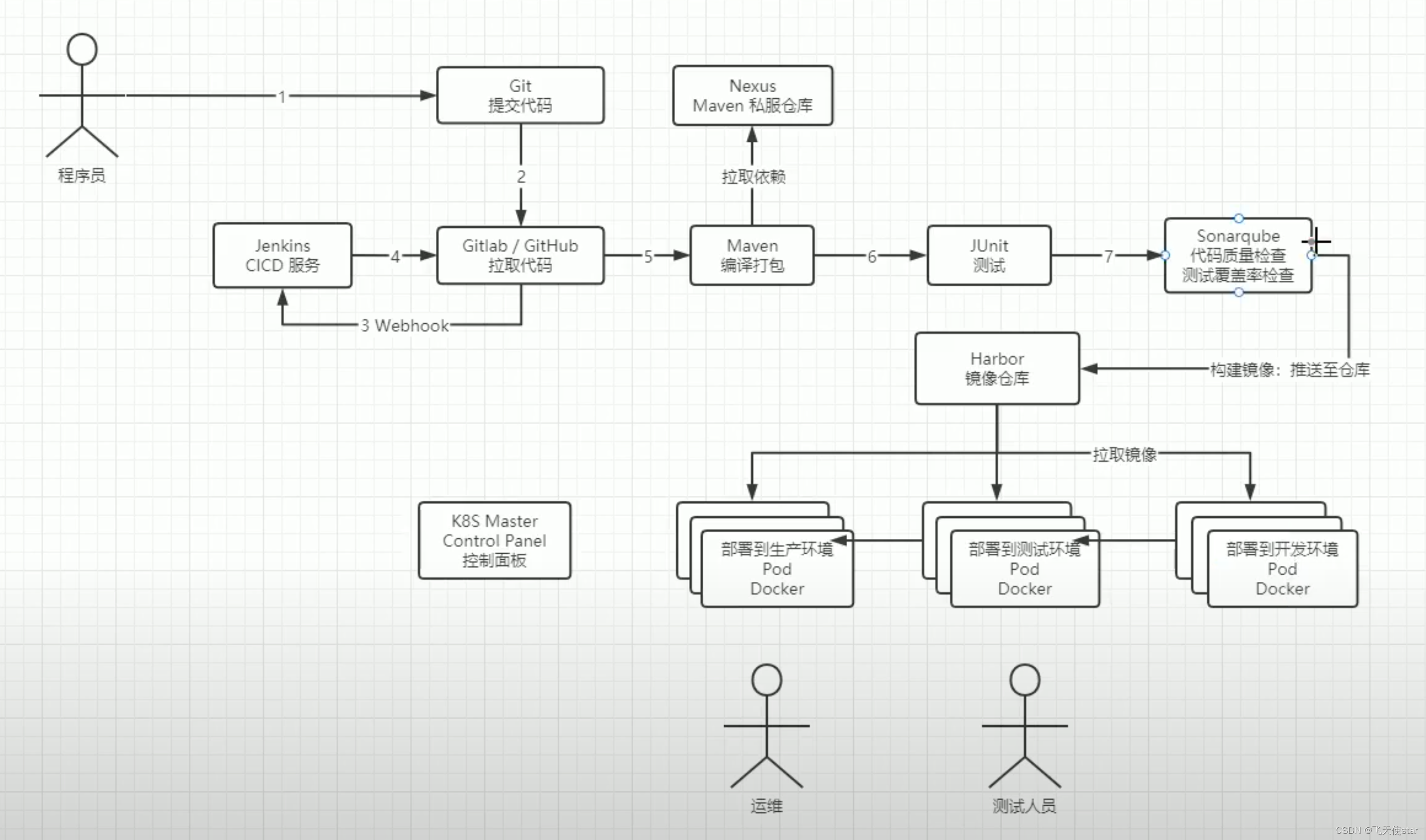
飞天使-linux操作的一些技巧与知识点7-devops
文章目录 简述devopsCICD 简述devops 让技术团队,运维,测试等团队实现一体式流程自动化 进阶版图 CICD 持续集成, 从编译,测试,发布的完成自动化流程 持续交付,包含持续集成,并且将项目部署…...

Sora:视频生成模型作为世界模拟器
我们探索了视频数据上生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和长宽比的视频和图像上联合训练文本条件扩散模型。我们利用了一个在视频和图像潜在码的时空块上操作的变压器架构。我们规模最大的模型 Sora 能够生成一分钟的高保真视频。我们的结…...
)
Jetson AGX Orin到手后,第一件事不是装CUDA,而是先搞定这个源(附nvidia-l4t-apt-source.list配置)
Jetson AGX Orin开发板开箱必做:正确配置软件源的深度指南 当你第一次拿到Jetson AGX Orin这款强大的边缘计算设备时,兴奋之余可能会迫不及待地想要安装CUDA、cuDNN等AI开发环境。但很多开发者都会在这里踩到一个"坑"——直接运行sudo apt ins…...

DotNext内存映射文件:高性能IO操作的终极解决方案
DotNext内存映射文件:高性能IO操作的终极解决方案 【免费下载链接】dotNext Next generation API for .NET 项目地址: https://gitcode.com/gh_mirrors/do/dotNext DotNext作为下一代.NET API,提供了强大的内存映射文件功能,为开发者带…...

基于OpenClaw构建智能家居环境感知系统:从传感器到自动化规则
1. 项目概述与核心价值如果你正在捣鼓一个智能家居系统,尤其是围绕着OpenClaw这类AI助手来构建,那你可能和我一样,经常遇到一个痛点:家里的设备虽然能联网、能控制,但它们大多“又聋又瞎”。空调能开能关,但…...
)
仅限档案学研究者获取:NotebookLM定制提示词库V2.3(含17个NARA/中国第一历史档案馆认证模板)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM档案学研究辅助 NotebookLM 是 Google 推出的基于 LLM 的研究型笔记工具,其核心能力在于对用户上传的私有文档(如 PDF、TXT、DOCX)进行语义理解与上下文关…...

如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持 对于使用 Hermes Agent 构建复杂应用的开发者而言,其强大的自…...

物联网技术如何重塑智能电网的底层架构
1. 物联网技术重塑智能电网的底层逻辑2003年美加大停电事故导致5000万人陷入黑暗,这场灾难直接催生了现代智能电网的诞生。如今,当我们谈论智能电网时,本质上是在讨论一个由物联网(IoT)技术重构的能源神经系统。这个系统通过海量智能终端实时…...

基于CircuitPython与BLE的智能振动腕带:从硬件选型到代码实现
1. 项目概述:打造你的智能触觉腕上伴侣如果你和我一样,经常被淹没在手机通知的海洋里,或者在专注工作时完全忘记了时间,那么这个项目可能就是为你量身定做的。今天,我们来动手制作一个基于CircuitPython和蓝牙低功耗&a…...

Perplexity开发者文档结构逆向工程:通过17个真实HTTP响应头+OpenAPI Schema反推隐藏端点与beta功能开关
更多请点击: https://intelliparadigm.com 第一章:Perplexity开发者文档查询 Perplexity 提供了一套面向 AI 应用开发者的 RESTful API 文档体系,其开发者中心(developer.perplexity.ai)支持结构化检索、版本过滤与实…...

【NotebookLM考古学研究辅助实战指南】:20年文博技术专家亲授3大冷启动技巧,让田野笔记秒变学术论文
更多请点击: https://intelliparadigm.com 第一章:NotebookLM考古学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,正悄然重塑考古学研究的信息处理范式。传统考古工作依赖大量手写笔记、田野报告、碳十四测年数…...
)
保姆级教程:用斐讯N1盒子刷Armbian 5.77,打造你的专属Debian服务器(附解决负载过高问题)
斐讯N1盒子改造指南:从电视盒子到高性能家庭服务器的蜕变 在智能家居和个性化网络需求日益增长的今天,拥有一台24小时运行的家庭服务器成为许多技术爱好者的刚需。而斐讯N1盒子凭借其出色的硬件配置和极低的功耗,成为了DIY玩家眼中的"宝…...