预测脱碳企业的信用评级-论文代码复现
文献来源
【Forecasting credit ratings of decarbonized firms: Comparative assessmentof machine learning models】
文章有代码复现有两个基本工作,1.是提取每个算法的重要性;2.计算每个算法的评价指标
算法有 CRT 分类决策树 ANN 人工神经网络 RFE 随机森林 SVM支持向量机
评价指标有F1 Score ;Specificity ;Accuracy
1.准备数据
分类标签【信誉等级CR1-CR7】和特征向量【变量】
[特征-变量]Probability of Default违约概率
Coverages覆盖范围
Capital Structure资本结构
Liquidity流动性
Profitability盈利能力
Operating Efficiency运营效率
Scale, Scope, and Diversity规模、范围和多样性
Competitive Advantage竞争优势
Fiscal Strength and Credit Conditions财政实力和信用状况
Systemic Governance and Effectiveness系统治理和有效性
Economic Strength经济实力
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, accuracy_score, confusion_matrix
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier# Regenerating the dataset with binary classification
num_companies = 500
features = {'Probability_of_Default': np.random.uniform(0, 1, num_companies),'Coverages': np.random.uniform(0, 1, num_companies),'Capital_Structure': np.random.uniform(0, 1, num_companies),'Liquidity': np.random.uniform(0, 1, num_companies),'Profitability': np.random.uniform(0, 1, num_companies),'Operating_Efficiency': np.random.uniform(0, 1, num_companies),'Scale_Scope_and_Diversity': np.random.uniform(0, 1, num_companies),'Competitive_Advantage': np.random.uniform(0, 1, num_companies),'Fiscal_Strength_and_Credit_Conditions': np.random.uniform(0, 1, num_companies),'Systemic_Governance_and_Effectiveness': np.random.uniform(0, 1, num_companies),'Economic_Strength': np.random.uniform(0, 1, num_companies),
}
features['Rating'] = np.random.choice([1, 2], num_companies)# Create a DataFrame
df = pd.DataFrame(features)# Preview the data
df.head()
df.to_excel(r'C:\Users\12810\Desktop\组会\组会记录\2024-0103寒假集训材料\看论文任务\要讲的\模拟数据.xlsx')
df.head()
| Probability_of_Default | Coverages | Capital_Structure | Liquidity | Profitability | Operating_Efficiency | Scale_Scope_and_Diversity | Competitive_Advantage | Fiscal_Strength_and_Credit_Conditions | Systemic_Governance_and_Effectiveness | Economic_Strength | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.298531 | 0.328423 | 0.665525 | 0.985169 | 0.107456 | 0.933863 | 0.714293 | 0.681608 | 0.508398 | 0.472675 | 0.508559 | 2 |
| 1 | 0.841430 | 0.736388 | 0.999020 | 0.689946 | 0.348265 | 0.929935 | 0.066077 | 0.609516 | 0.797929 | 0.048373 | 0.424858 | 2 |
| 2 | 0.462897 | 0.105783 | 0.716292 | 0.912855 | 0.564482 | 0.850507 | 0.774066 | 0.880007 | 0.737817 | 0.729397 | 0.283405 | 2 |
| 3 | 0.062724 | 0.073537 | 0.611761 | 0.213703 | 0.483220 | 0.668749 | 0.052895 | 0.924532 | 0.134043 | 0.126261 | 0.910167 | 1 |
| 4 | 0.242200 | 0.089723 | 0.874793 | 0.659927 | 0.159241 | 0.348462 | 0.828590 | 0.273572 | 0.117796 | 0.154820 | 0.324018 | 2 |
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import train_test_split# Define features and labels
X = df.drop('Rating', axis=1)
y = df['Rating']# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Initialize the classifiers
classifiers = {'CRT': DecisionTreeClassifier(random_state=42),'ANN': MLPClassifier(random_state=42, max_iter=1000),'RFE': RandomForestClassifier(random_state=42),'SVM': SVC(random_state=42)
}# Dictionary to store models' performance metrics
performance_metrics = {}# Training and evaluating classifiers
for name, clf in classifiers.items():clf.fit(X_train, y_train) # Train the modely_pred = clf.predict(X_test) # Predict on test set# Calculate performance metricsperformance_metrics[name] = classification_report(y_test, y_pred, output_dict=True)performance_metrics[name]['accuracy'] = accuracy_score(y_test, y_pred)# Since ANN and SVM don't provide a direct method for feature importance, we will skip that part as per user's instructions.performance_metrics# ... (previous code to generate data and split sets)# Initialize classifiers
decision_tree = DecisionTreeClassifier(random_state=42)
random_forest = RandomForestClassifier(random_state=42)
ann = MLPClassifier(random_state=42, max_iter=1000)
svm = SVC(random_state=42)# Train and predict using each classifier
for clf in [decision_tree, random_forest, ann, svm]:clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print(f"{clf.__class__.__name__} metrics:")print(classification_report(y_test, y_pred))print(f"Accuracy: {accuracy_score(y_test, y_pred)}\n")# Feature importance for Decision Tree and Random Forest
print(f"Decision Tree Feature Importance: {decision_tree.feature_importances_}")
print(f"Random Forest Feature Importance: {random_forest.feature_importances_}")D:\install_file\Anaconda3\lib\site-packages\sklearn\neural_network\_multilayer_perceptron.py:691: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (1000) reached and the optimization hasn't converged yet.warnings.warn(DecisionTreeClassifier metrics:precision recall f1-score support1 0.36 0.38 0.37 452 0.47 0.45 0.46 55accuracy 0.42 100macro avg 0.42 0.42 0.42 100
weighted avg 0.42 0.42 0.42 100Accuracy: 0.42RandomForestClassifier metrics:precision recall f1-score support1 0.39 0.40 0.40 452 0.50 0.49 0.50 55accuracy 0.45 100macro avg 0.45 0.45 0.45 100
weighted avg 0.45 0.45 0.45 100Accuracy: 0.45MLPClassifier metrics:precision recall f1-score support1 0.40 0.44 0.42 452 0.50 0.45 0.48 55accuracy 0.45 100macro avg 0.45 0.45 0.45 100
weighted avg 0.46 0.45 0.45 100Accuracy: 0.45SVC metrics:precision recall f1-score support1 0.45 0.42 0.44 452 0.55 0.58 0.57 55accuracy 0.51 100macro avg 0.50 0.50 0.50 100
weighted avg 0.51 0.51 0.51 100Accuracy: 0.51Decision Tree Feature Importance: [0.1373407 0.1034318 0.09762338 0.047583 0.13000749 0.047780610.04700612 0.09306039 0.13848067 0.05285945 0.1048264 ]
Random Forest Feature Importance: [0.09758143 0.09809294 0.09033973 0.08525976 0.09331244 0.082810670.094648 0.10032612 0.08863182 0.08533643 0.08366067]D:\install_file\Anaconda3\lib\site-packages\sklearn\neural_network\_multilayer_perceptron.py:691: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (1000) reached and the optimization hasn't converged yet.warnings.warn(
from sklearn.inspection import permutation_importance# For ANN
ann.fit(X_train, y_train)
perm_importance_ann = permutation_importance(ann, X_test, y_test, n_repeats=30, random_state=42)# For SVM
svm.fit(X_train, y_train)
perm_importance_svm = permutation_importance(svm, X_test, y_test, n_repeats=30, random_state=42)# Store the permutation importances in a dictionary or DataFrame
feature_importances_ann = perm_importance_ann.importances_mean
feature_importances_svm = perm_importance_svm.importances_mean# You can then display these importances or further analyze them
print("Feature importances from ANN:", feature_importances_ann)
print("Feature importances from SVM:", feature_importances_svm)
D:\install_file\Anaconda3\lib\site-packages\sklearn\neural_network\_multilayer_perceptron.py:691: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (1000) reached and the optimization hasn't converged yet.warnings.warn(Feature importances from ANN: [-0.04366667 -0.04866667 -0.06166667 -0.01633333 -0.06166667 -0.069-0.059 -0.07333333 -0.02866667 -0.041 -0.04266667]
Feature importances from SVM: [-0.002 -0.00633333 0.019 0.035 0.00666667 0.00233333-0.00233333 -0.01466667 -0.02 0.00833333 0.02 ]
相关文章:

预测脱碳企业的信用评级-论文代码复现
文献来源 【Forecasting credit ratings of decarbonized firms: Comparative assessmentof machine learning models】 文章有代码复现有两个基本工作,1.是提取每个算法的重要性;2.计算每个算法的评价指标 算法有 CRT 分类决策树 ANN 人工神经网络 R…...

目标检测——KITTI目标跟踪数据集
KITTI目标跟踪数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创建的一个大规模自动驾驶场景下的计算机视觉算法评测数据集。这个数据集主要用于评估立体图像、光流、视觉测距、3D物体检测和3D跟踪等计算机视觉技术在车载环境下的性能这个数据集包含了在市区、乡村和…...

25-k8s集群中-RBAC用户角色资源权限
一、RBAC概述 1,k8s集群的交互逻辑(简单了解) 我们通过k8s各组件架构,知道各个组件之间是使用https进行数据加密及交互的,那么同理,我们作为“使用”k8s的各种资源的使用者,也是通过https进行数…...
Android 面试问题 2024 版(其二)
Android 面试问题 2024 版(其二) 六、多线程和并发七、性能优化八、测试九、安全十、Material设计和 **UX/UI** 六、多线程和并发 Android 中的进程和线程有什么区别? 答:进程是在自己的内存空间中运行的应用程序的单独实例&…...

SpringMVC的异常处理
异常分类 : 预期异常(检查型异常)和运行时异常 1、使用@ExceptionHandle注解处理异常 @ExceptionHandle(value={***.class} 异常类型) public modelandview handelException(){} 仅限当前类使用 2、全局处理方式 @ControllerAdvice + @ExceptionHandle 新建类 @Cont…...

【计算机网络】1 因特网概述
一.网络、互联网和因特网 1.网络(network),由若干结点(node)和连接这些结点的链路(link)组成。 2.多个网络还可以通过路由器互联起来,这样就构成了一个覆盖范围更大的网络…...

【Ubuntu】Anaconda的安装和使用
目录 1 安装 2 使用 1 安装 (1)下载安装包 官网地址:Unleash AI Innovation and Value | Anaconda 点击Free Download 按键。 然后 点击下图中的Download开始下载安装包。 (2)安装 在安装包路径下打开终端&#…...

OpenAI推出首个AI视频模型Sora:重塑视频创作与体验
链接:华为OD机考原题附代码 Sora - 探索AI视频模型的无限可能 随着人工智能技术的飞速发展,AI视频模型已成为科技领域的新热点。而在这个浪潮中,OpenAI推出的首个AI视频模型Sora,以其卓越的性能和前瞻性的技术,引领着…...
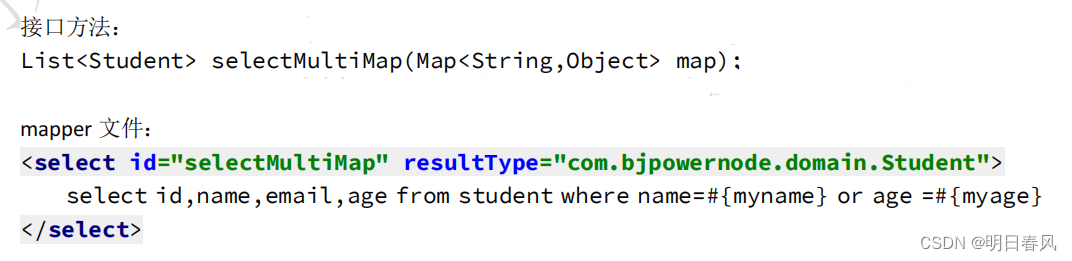
mybatis总结传参三
十、(不推荐)多个参数-按位置传参 参数位置从 0 开始, 引用参数语法 #{ arg 位置 } , 第一个参数是 #{arg0}, 第二个是 #{arg1} 注意: mybatis-3.3 版本和之前的版本使用 #{0},#{1} 方式, 从 myba…...
JSONVUE
1.JSON学习 1.概念: JSON是把JS对象变成字符串. 2.作用: 多用于网络中数据传输. JavaScript对象 let person{name:"张三",age:18}//将JS对象转换为 JSON数据let person2JSON{"name":"张三","age":18}; 3.JS对象与JSON字符串转换…...
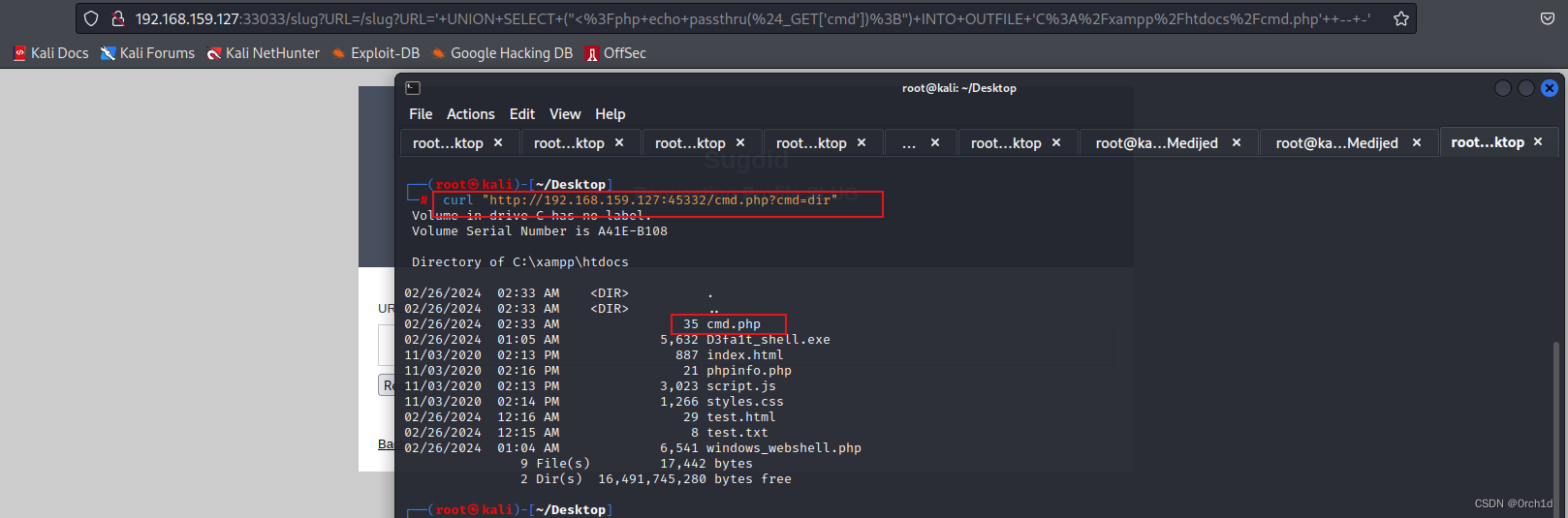
OSCP靶机--Medjed
OSCP靶机–Medjed 考点:(1.ftp文件上传 2.sql注入写shell 3.第三软件提权) 1.nmap ┌──(root㉿kali)-[~/Desktop] └─# nmap 192.168.200.127 -sV -sC -p- --min-rate 5000 Starting Nmap 7.92 ( https://nmap.org ) at 2024-02-25 19:42 EST Nmap scan repo…...
【Unity】Unity与安卓交互
问题描述 Unity和安卓手机进行交互,是我们开发游戏中最常见的场景。本教程将从一个简单的例子来演示一下。 本教程需要用到Android Studio2021.1.1 1.Android Studio新建一个工程 2.选择Empty Activity 然后点击Next 3.点击Finish完成创建 4.选择File-New-New Mo…...

QYFB-02 无线风力报警仪 风速风向超限声光报警
产品概述 无线风力报警仪是由测控报警仪、无线风速风向传感器和太阳能供电盒组成,可观测大气中的瞬时风速,具有风速报警设定和报警输出控制功能;风力报警仪采用无线信号传输、显示屏输出,风速显示采用高亮LED数码管显示ÿ…...
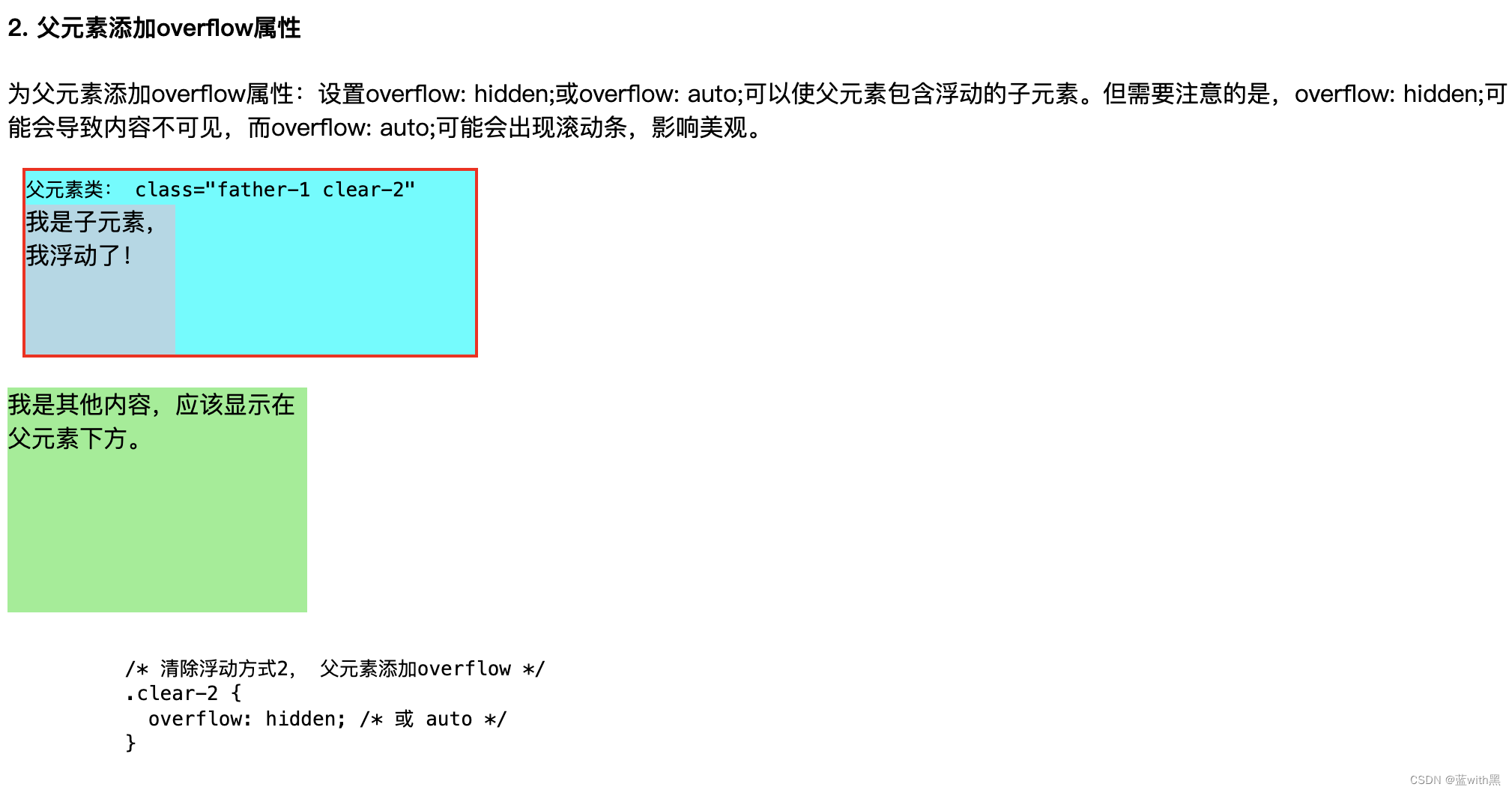
css知识:盒模型盒子塌陷BFC
1. css盒模型 标准盒子模型,content-box 设置宽度即content的宽度 width content 总宽度content(width设定值) padding border IE/怪异盒子模型,border-box width content border padding 总宽度 width设定值 2. 如何…...

Nginx的反向代理:实现灵活的请求转发和内容缓存
一、引言:代理服务器的简介 本节介绍代理服务器的基本配置。学习如何通过不同协议将 NGINX 请求传递给代理的服务器,修改发送到代理服务器的客户端请求标头,以及配置来自代理服务器的响应缓冲。 代理通常用于在多个服务器之间分配负载&…...
免费享受企业级安全:雷池社区版WAF,高效专业的Web安全的方案
网站安全成为了每个企业及个人不可忽视的重要议题。 随着网络攻击手段日益狡猾和复杂,选择一个强大的安全防护平台变得尤为关键。 推荐的雷池社区版——一个为网站提供全面安全防护解决方案的平台,它不仅具备高效的安全防护能力,还让网站安…...
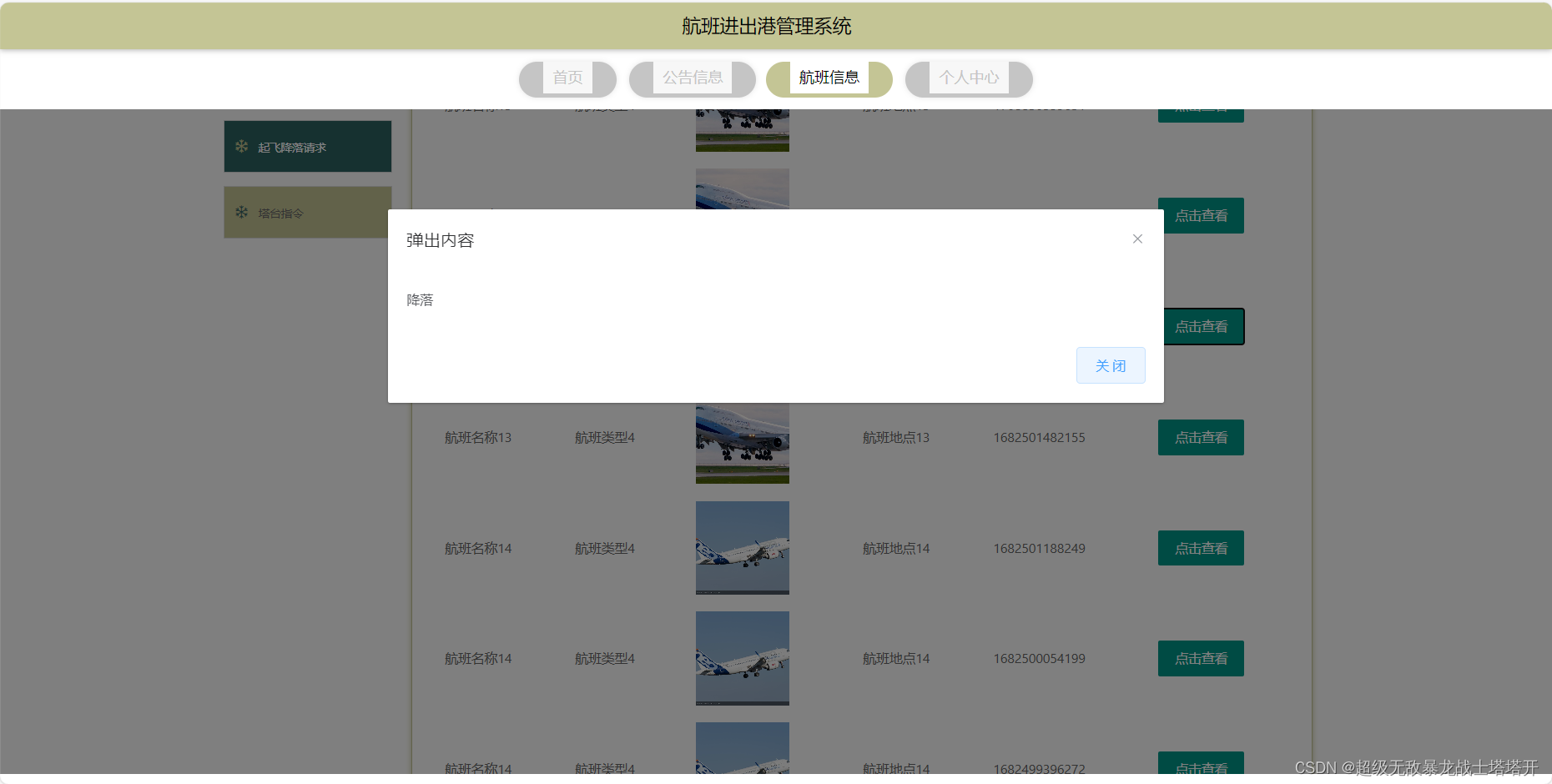
基于SpringBoot的航班进出港管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式 🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 &…...
Odoo系统安装部署并结合内网穿透实现固定域名访问本地ERP系统
文章目录 前言1. 下载安装Odoo:2. 实现公网访问Odoo本地系统:3. 固定域名访问Odoo本地系统 前言 Odoo是全球流行的开源企业管理套件,是一个一站式全功能ERP及电商平台。 开源性质:Odoo是一个开源的ERP软件,这意味着企…...

幻兽帕鲁(Palworld 1.4.1)私有服务器搭建(docker版)
文章目录 说明客户端安装服务器部署1Panel安装和配置docker服务初始化设置设置开机自启动设置镜像加速 游戏服务端部署游戏服务端参数可视化配置 Palworld连接服务器问题总结 说明 服务器硬件要求:Linux系统/Window系统(x86架构,armbian架构…...

好书推荐丨细说Python编程:从入门到科学计算
文章目录 写在前面Python简介推荐图书内容简介编辑推荐作者简介 推荐理由粉丝福利写在最后 写在前面 本期博主给大家推荐一本Python基础入门的全新正版书籍,对Python、机器学习、人工智能感兴趣的小伙伴们快来看看吧~ Python简介 Python 是一种广泛使用的高级、解…...

从原理到实践:详解Livox激光雷达与相机外参标定的ROS实现
1. 为什么需要激光雷达与相机标定? 在自动驾驶和机器人领域,激光雷达和相机是最常用的两种传感器。激光雷达能提供精确的三维距离信息,而相机则能捕捉丰富的纹理和颜色信息。但要让这两种传感器真正发挥11>2的效果,就必须解决…...

ModuleNotFoundError: No module named ‘ui_form‘
问题描述:在QT CREATER创建一个新的python QT项目后,若无法直接编译而是报错如下:解决办法: 在该项目的目录下输入cmd,打开命令行窗口——然后输入pyside6-uic form.ui -o ui_form.py 运行即可正常编译 (若…...

从零到一:在Windows Server上快速部署OpenLDAP服务与客户端连接实战
1. 为什么选择OpenLDAP? 如果你正在管理一个中小型企业的IT基础设施,用户账号管理可能会让你头疼。每次有新员工入职,都要在每台电脑上创建账号;员工离职时又要逐个删除权限。这种重复劳动不仅效率低下,还容易出错。Op…...

DroidCam OBS插件终极指南:零成本将手机变身高清直播摄像头
DroidCam OBS插件终极指南:零成本将手机变身高清直播摄像头 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin 还在为专业直播设备价格昂贵而烦恼?想用手机摄像头获得…...

1.7.3 掌握Scala函数 - 神奇占位符
本次Scala函数实战主要聚焦于“神奇占位符”下划线(_)的灵活运用,通过三个递进的案例深入理解其简化代码的核心作用。 演示过滤列表:利用 filter 方法,对比了常规匿名函数与使用占位符的写法,直观展示了如何…...

CORP开源协作框架:从人治到规则驱动的自动化协作协议
1. 项目概述:一个面向未来的开源协作框架最近在折腾一个开源项目,叫CORP,全称是“Collaborative Open-source Resource Platform”。这名字听起来挺唬人,但说白了,它想解决的就是开源世界里一个老生常谈但又一直没被彻…...

ARM GICv4.1 GICD_TYPER2寄存器详解与虚拟化应用
1. GICD_TYPER2寄存器概述 GICD_TYPER2是ARM GICv4.1架构中引入的关键寄存器,属于中断控制器类型寄存器家族。作为GIC Distributor的一部分,它专门用于增强虚拟化场景下的中断管理能力。这个32位寄存器位于内存映射地址Dist_base 0x000C处,仅…...

2026出海技术观察:云API接口迭代的能力边界与业务增量空间
摘要:2026年AI出海告别粗放扩张,底层技术适配能力成为竞争核心。云API接口迭代持续优化跨境对接、算力调度与合规适配体系,补齐传统出海技术短板,为企业全球化精细化运营提供坚实支撑。一、2026 AI出海新格局:底层接口…...

modbus 512 断线重连 db browser for sqlite
断线重连 private async Task HeartbeatLoopAsync(CancellationToken token) {// 监工一直循环干活,直到工长喊停工(token.IsCancellationRequested)while (!token.IsCancellationRequested){try{// 每隔一段时间检查一次(最少20…...

OpenClacky:AI Agent技能加密与商业分发平台实战指南
1. 项目概述:从开源共享到知识变现的桥梁在AI Agent(智能体)生态蓬勃发展的今天,我们看到了一个有趣的现象:无数开发者贡献了海量的“技能”(Skills),让像OpenClaw这样的平台功能日益…...