RPC通信原理解析
一、什么是RPC框架?
RPC,全称为Remote Procedure Call,即远程过程调用,是一种计算机通信协议。
比如现在有两台机器:A机器和B机器,并且分别部署了应用A和应用B。假设此时位于A机器上的A应用想要调用位于B机器上的B应用提供的函数或是方法,由于A应用和B应用不在一个内存空间里面,所以不能直接调用,此时就需要通过网络来表达调用的方式和传输调用的数据。也即所谓的远程调用。
二、RPC框架的实现原理?
主要有以下几个步骤:
1、建立通信
首先要解决通讯的问题:即A机器想要调用B机器,首先得建立起通信连接。主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有相关的数据都在这个连接里面进行传输交换。
通常这个连接可以是按需连接(需要调用的时候就先建立连接,调用结束后就立马断掉),也可以是长连接(客户端和服务器建立起连接之后保持长期持有,不管此时有无数据包的发送,可以配合心跳检测机制定期检测建立的连接是否存活有效),多个远程过程调用共享同一个连接。
2、服务寻址
解决寻址的问题:即A机器上的应用A要调用B机器上的应用B,那么此时对于A来说如何告知底层的RPC框架所要调用的服务具体在哪里呢?
通常情况下我们需要提供B机器(主机名或IP地址)以及特定的端口,然后指定调用的方法或者函数的名称以及入参出参等信息,这样才能完成服务的一个调用。比如基于Web服务协议栈的RPC,就需要提供一个endpoint URI,或者是从UDDI服务上进行查找。如果是RMI调用的话,还需要一个RMI Registry来注册服务的地址。
3、网络传输
3.1、序列化
当A机器上的应用发起一个RPC调用时,调用方法和其入参等信息需要通过底层的网络协议如TCP传输到B机器,由于网络协议是基于二进制的,所有我们传输的参数数据都需要先进行序列化(Serialize)或者编组(marshal)成二进制的形式才能在网络中进行传输。然后通过寻址操作和网络传输将序列化或者编组之后的二进制数据发送给B机器。
3.2、反序列化
当B机器接收到A机器的应用发来的请求之后,又需要对接收到的参数等信息进行反序列化操作(序列化的逆操作),即将二进制信息恢复为内存中的表达方式,然后再找到对应的方法(寻址的一部分)进行本地调用(一般是通过生成代理Proxy去调用, 通常会有JDK动态代理、CGLIB动态代理、Javassist生成字节码技术等),之后得到调用的返回值。
4、服务调用
B机器进行本地调用(通过代理Proxy)之后得到了返回值,此时还需要再把返回值发送回A机器,同样也需要经过序列化操作,然后再经过网络传输将二进制数据发送回A机器,而当A机器接收到这些返回值之后,则再次进行反序列化操作,恢复为内存中的表达方式,最后再交给A机器上的应用进行相关处理(一般是业务逻辑处理操作)。
通常,经过以上四个步骤之后,一次完整的RPC调用算是完成了,另外可能因为网络抖动等原因需要重试等。
三、为什么需要RPC?
主要就是因为在几个进程内(应用分布在不同的机器上),无法共用内存空间,或者在一台机器内通过本地调用无法完成相关的需求,比如不同的系统之间的通讯,甚至不同组织之间的通讯。此外由于机器的横向扩展,需要在多台机器组成的集群上部署应用等等。
四、RPC支持哪些协议?
最早的CORBA、Java RMI, WebService方式的RPC风格, Hessian, Thrift甚至Rest API。
五、RPC的实现基础?
1、需要有非常高效的网络通信,比如一般选择Netty作为网络通信框架
2、需要有比较高效的序列化框架,比如谷歌的Protobuf序列化框架
3、可靠的寻址方式(主要是提供服务的发现),比如可以使用Zookeeper来注册服务等等
4、如果是带会话(状态)的RPC调用,还需要有会话和状态保持的功能
六、RPC调用过程?
6.1 一个基本的RPC架构里面应该至少包含以下4个组件:
1、客户端(Client):服务调用方(服务消费者)
2、客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
3、服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
4、服务端(Server):服务的真正提供者
6.2 具体的调用过程如下:
1、服务消费者(client客户端)通过本地调用的方式调用服务
2、客户端存根(client stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体
3、客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端
4、服务端存根(server stub)收到消息后进行解码(反序列化操作)
5、服务端存根(server stub)根据解码结果调用本地的服务进行相关处理
6、本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub)
7、服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方
8、客户端存根(client stub)接收到消息,并进行解码(反序列化)
9、服务消费方得到最终结果
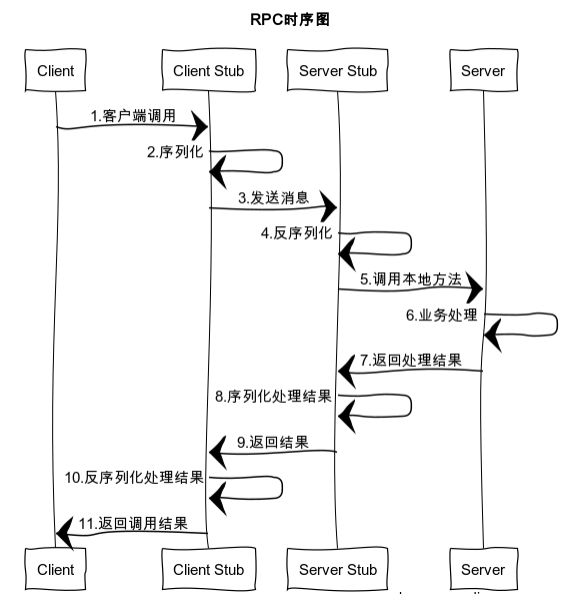
而RPC框架的实现目标则是将上面的第2-10步完好地封装起来,也就是把调用、编码/解码的过程给封装起来,让用户感觉上像调用本地服务一样的调用远程服务。
七、RPC框架需要解决的问题?
1、如何确定客户端和服务端之间的通信协议?
2、如何更高效地进行网络通信?
3、服务端提供的服务如何暴露给客户端?
4、客户端如何发现这些暴露的服务?
5、如何更高效地对请求对象和响应结果进行序列化和反序列化操作?
八、使用了哪些技术?
8.1、动态代理
生成Client Stub(客户端存根)和Server Stub(服务端存根)的时候需要用到java动态代理技术,可以使用jdk提供的原生的动态代理机制,也可以使用开源的:Cglib代理,Javassist字节码生成技术。
8.2、序列化
在网络中,所有的数据都将会被转化为字节进行传送,所以为了能够使参数对象在网络中进行传输,需要对这些参数进行序列化和反序列化操作。
序列化:把对象转换为字节序列的过程称为对象的序列化,也就是编码的过程。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程。
目前比较高效的开源序列化框架:如Kryo、fastjson和Protobuf等。
8.3、NIO通信
出于并发性能的考虑,传统的阻塞式 IO 显然不太合适,因此我们需要异步的 IO,即 NIO。
Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的 NIO.2 支持。可以选择Netty或者mina来解决NIO数据传输的问题。
8.4、服务注册中心
可选:Redis、Zookeeper、Consul 、Etcd。
一般使用ZooKeeper提供服务注册与发现功能,解决单点故障以及分布式部署的问题(注册中心)。
九. 模拟RPC的客户端、服务端、通信协议三者如何工作的
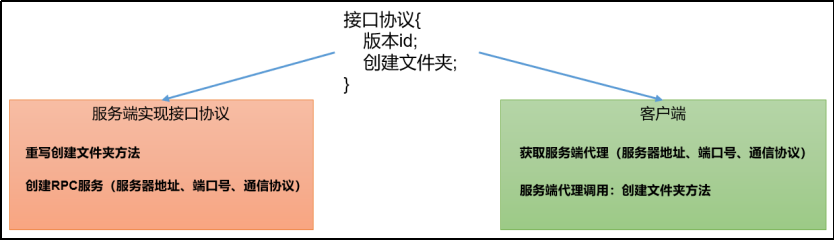
9.1 代码编写:
(1)在HDFSClient项目基础上创建包名com.hadoop.rpc
(2)创建RPC协议
package com.hadoop.rpc;public interface RPCProtocol {long versionID = 666;void mkdirs(String Path);void delete(String Path);
}
(3)创建RPC服务端
package com.hadoop.rpc;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.Server;
import java.io.IOException;
import java.io.*;
public class NNServer implements RPCProtocol{@Overridepublic void mkdirs(String Path){//System.out.println("服务端,创建路径" + Path);File f = new File(Path);final boolean mkdirs = f.mkdirs();if (mkdirs){System.out.println("服务端,创建路径" + Path);}}public void delete(String Path){//System.out.println("服务端,创建路径" + Path);File f = new File(Path);final boolean delete = f.delete();if (delete){System.out.println("服务端,删除" + Path);}}public static void main(String[] args) throws IOException {Server server = new RPC.Builder(new Configuration()).setBindAddress("localhost").setPort(8888).setProtocol(RPCProtocol.class).setInstance(new NNServer()).build();System.out.println("服务器开始工作");server.start();}
}(4)创建RPC客户端
package com.hadoop.rpc;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;import java.io.IOException;
import java.net.InetSocketAddress;public class HDFSClient {public static void main(String[] args) throws IOException {RPCProtocol client = RPC.getProxy(RPCProtocol.class,RPCProtocol.versionID,new InetSocketAddress("localhost",8888),new Configuration());System.out.println("我是客户端");System.out.println("开始创建文件夹");client.mkdirs("./input");int j = 0;while (j < 10){j++;client.mkdirs("./hadoop/hadoop100/hadoop"+j);}System.out.println("开始删除前五个文件夹");int i = 0;while (i < 5){i++;client.delete("./hadoop/hadoop100/hadoop"+i);}}
}pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.apache.hadoop</groupId><artifactId>hadoop</artifactId><version>1.0-SNAPSHOT</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><hadoop.version>2.7.5</hadoop.version><hive.version>1.1.0</hive.version><hbase.version>1.2.0</hbase.version><scala.version>2.11.8</scala.version><spark.version>2.4.4</spark.version></properties><dependencies><!--scala--><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><!-- spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><!-- spark-graphx --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-graphx_2.11</artifactId><version>${spark.version}</version></dependency><!-- hadoop --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><!-- log4j --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><!-- junit --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version></dependency><!-- kafka-clients --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>0.11.0.2</version></dependency></dependencies></project>
3)测试
(1)启动服务端
观察控制台打印:服务器开始工作
在控制台Terminal窗口输入,jps,查看到NNServer服务
(2)启动客户端
观察客户端控制台打印:我是客户端
观察服务端控制台打印:服务端,创建路径/input
4)总结
RPC的客户端调用通信协议方法,方法的执行在服务端;
通信协议就是接口规范。
参考https://my.oschina.net/huangyong/blog/361751实现了RPC框架
github代码:https://github.com/hu1991die/netty-rpc
原文参考:
1、https://www.zhihu.com/question/25536695
2、http://www.importnew.com/22003.html
3、http://blog.jobbole.com/92290/
4、https://mp.weixin.qq.com/s?__biz=MzAxMjY5NDU2Ng==&mid=2651856984&idx=1&sn=3896636d2d2907b5b7157bec14c58088&chksm=80496511b73eec072a10c2465e229683789432b31232016ce064036988d8a75a1d0de5dccc48&scene=27
相关文章:
RPC通信原理解析
一、什么是RPC框架? RPC,全称为Remote Procedure Call,即远程过程调用,是一种计算机通信协议。 比如现在有两台机器:A机器和B机器,并且分别部署了应用A和应用B。假设此时位于A机器上的A应用想要调用位于B机…...

【蓝桥杯集训·周赛】AcWing 第93场周赛
文章目录第一题 AcWing 4867. 整除数一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解第二题 AcWing 4868. 数字替换一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解第三题 AcWing 4869. 异或值一、题目1、原题…...
蓝桥杯-刷题统计
蓝桥杯-刷题统计1、问题描述2、解题思路3、代码实现3.1 方案一:累加方法(超时)3.2 方案二1、问题描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a 道题目, 周六和周日每天做 b 道题目。请你帮小明计算, 按照计划他将在 第几天实现做题数…...

Linux入门教程||Linux Shell 变量|| Shell 传递参数
Shell 变量 定义变量时,变量名不加美元符号($,PHP语言中变量需要),如: your_name"w3cschool.cn"注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一…...
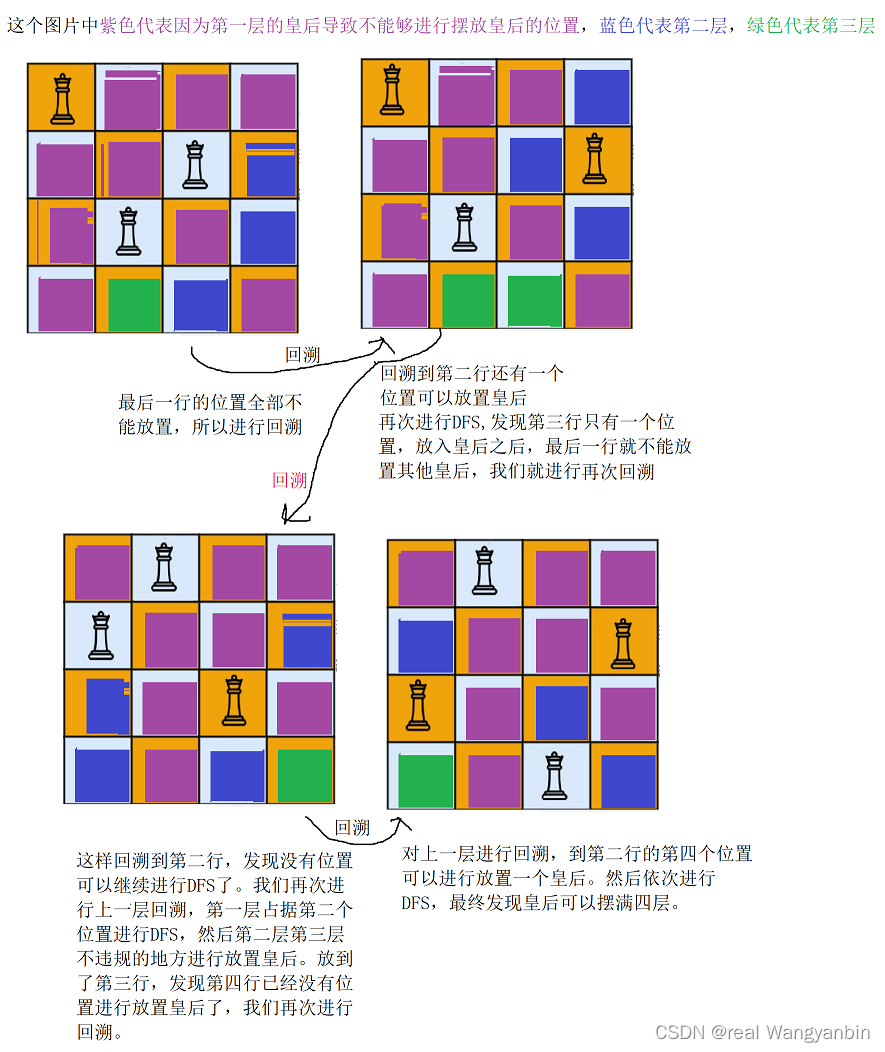
[算法和数据结构]--回溯算法之DFS初识
回溯算法——DFSDFS介绍(Depth First Search)DFS经典题目1. 员工的重要性2. 图像渲染3.被围绕的区域4.岛屿数量5. 电话号码的字母组合6.数字组合7. 活字印刷8. N皇后DFS介绍(Depth First Search) 回溯法(back tracking)(探索与回溯法&#x…...
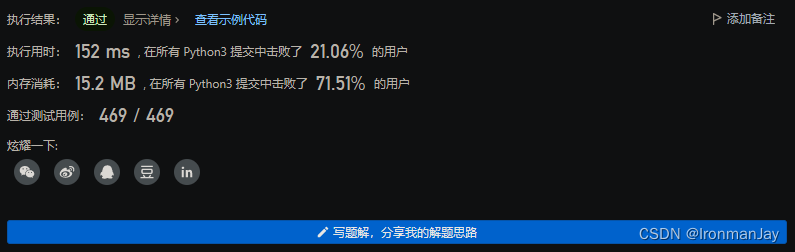
【LeetCode每日一题】——680.验证回文串 II
文章目录一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【解题思路】七【题目提示】八【时间频度】九【代码实现】十【提交结果】一【题目类别】 贪心算法 二【题目难度】 简单 三【题目编号】 680.验证回文串 II 四【题目描述】 给你一个字…...

【C语言进阶:指针的进阶】你真分得清sizeof和strlen?
本章重点内容: 字符指针指针数组数组指针数组传参和指针传参函数指针函数指针数组指向函数指针数组的指针回调函数指针和数组面试题的解析这篇博客 FLASH 将带大家一起来练习一些容易让人凌乱的题目,通过这些题目来进一步加深和巩固对数组,指…...
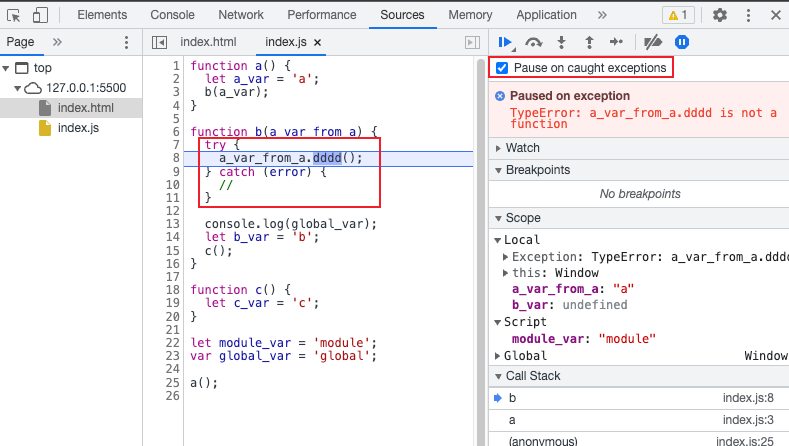
【前端必看】极大提高开发效率的网页 JS 调试技巧
大家好,我是前端西瓜哥。本文讲解如何使用浏览器提供的工具进行 JS 代码的断点调试。 debugger 在代码中需要打断点的地方,加上 debugger,表示一个断点。浏览器代码执行到该位置时,会停下来,进入调试模式。 示例代码…...

【春招面经】视源股份前端一面
前言 本次主要记录一下视源股份CVTE前端一面 (3.3下午4点15) 文章目录前言本次主要记录一下视源股份CVTE前端一面 (3.3下午4点15)问题总结介绍一下项目的来源以及做这个项目的初衷一直监听滚动,有没有对性能产生影响&a…...
插件化开发入门
一、背景顾名思义,插件化开发就是将某个功能代码封装为一个插件模块,通过插件中心的配置来下载、激活、禁用、或者卸载,主程序无需再次重启即可获取新的功能,从而实现快速集成。当然,实现这样的效果,必须遵…...

tftp、nfs 服务器环境搭建
目录 一、认识 tftp、nfs 1、什么是 tftp? 2、什么是 nfs? 3、tftp 和 nfs 的区别 二、tftp的安装 1、安装 tftp 服务端 2、配置 tftp 3、启动 tftp 服务 三、nfs 的安装 1、安装 nfs 服务端 2、配置 nfs 3、启动 nfs 服务 一、认识 tftp、…...
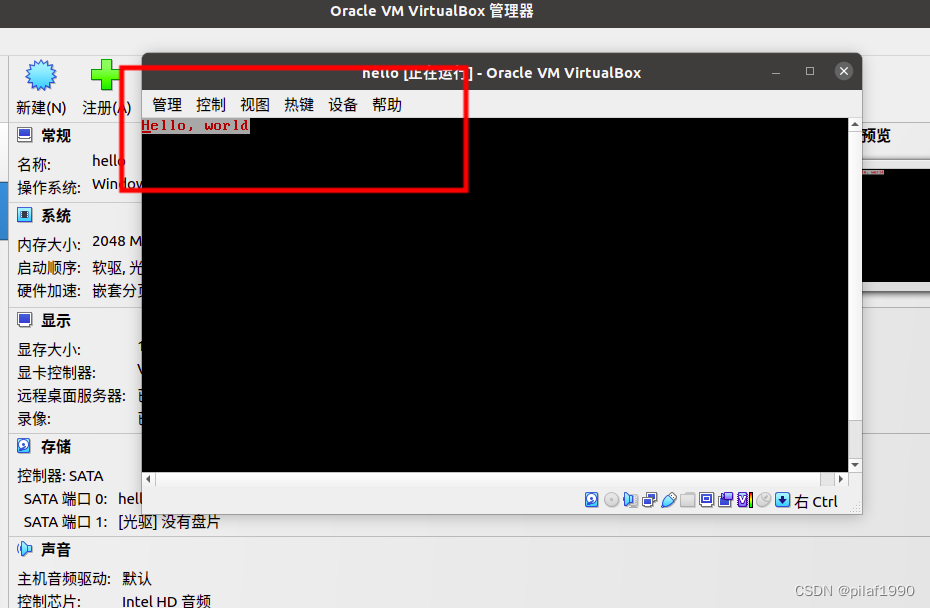
汇编系列03-不借助操作系统输出Hello World
每天进步一点点,加油! 上一节,我们通过汇编指令,借助操作系统的系统调用实现了向标准输出打印Hello world。这一节我们打算绕过操作系统,直接在显示屏幕上打印Hello world。 计算机的启动过程 当我们给计算机加电启…...

TPU编程竞赛系列|算能赛道冠军SO-FAST团队获第十届CCF BDCI总决赛特等奖!
近日,第十届中国计算机学会(CCF)大数据与计算智能大赛总决赛暨颁奖典礼在苏州顺利落幕,算能赛道的冠军队伍SO-FAST从2万余支队伍中脱颖而出,获得了所有赛道综合评比特等奖! 本届CCF大赛吸引了来自全国的2万…...
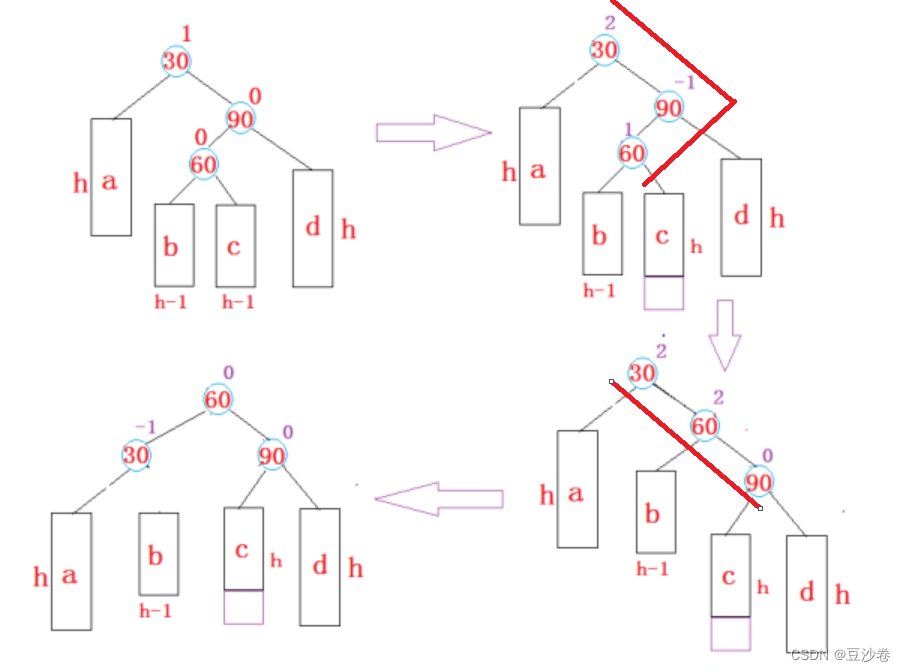
【C++】AVL树,平衡二叉树详细解析
文章目录前言1.AVL树的概念2.AVL树节点的定义3.AVL树的插入4.AVL树的旋转左单旋右单旋左右双旋右左双旋AVL树的验证AVL树的删除AVL树的性能前言 前面对map/multimap/set/multiset进行了简单的介绍,在其文档介绍中发现,这几个容器有个共同点是࿱…...
C/C++开发,无可避免的多线程(篇四).线程与函数的奇妙碰撞
一、函数、函数指针及函数对象 1.1 函数 函数(function)是把一个语句序列(函数体, function body)关联到一个名字和零或更多个函数形参(function parameter)的列表的 C 实体,可以通过返回或者抛…...

elisp简单实例: taglist
从vim 转到emacs 下,一直为缺少vim 中的tablist 插件而感到失落. 从网上得到的一个emacs中的taglist, 它的功能很简陋,而且没有任何说明, 把它做为elisp的简单实例,供初学者入门倒不错,我给它加了很多注释,帮助理解, 说实话,感觉这百行代码还是挺有深度的,慢慢体会,调试才会有收…...
-认知服务(3))
Azure AI基础到实战(C#2022)-认知服务(3)
目录 OpenFileDialog 类上一节代码的API剖析ComputerVisionClientExtensions.ReadAsync MethodReadHeaders ClassReadHeaders.OperationLocation Property探索ReadHeaders加上调试代码可用于 Azure 认知服务的身份验证标头使用单服务订阅密钥进行身份验证使用多服务订阅密钥进行…...
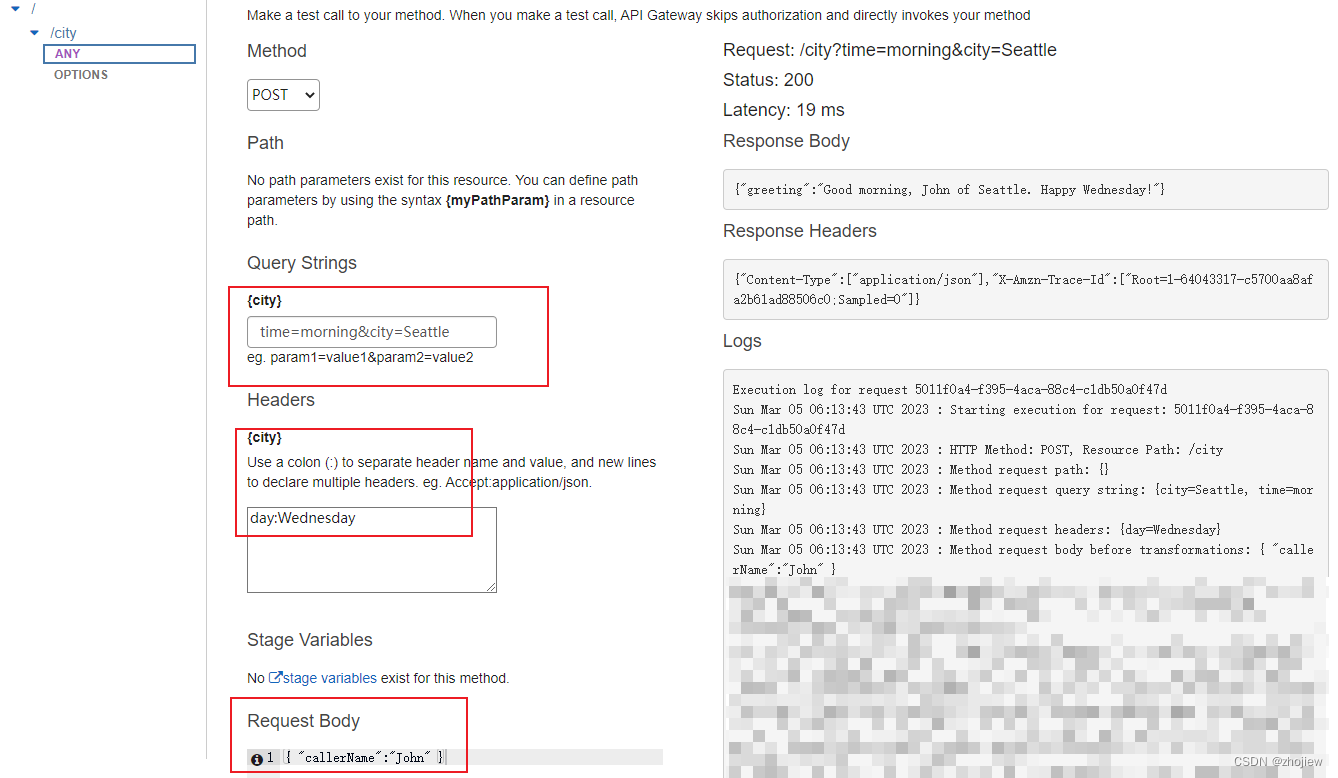
aws apigateway 使用restapi集成lambda
参考资料 代理集成,https://docs.aws.amazon.com/zh_cn/apigateway/latest/developerguide/api-gateway-create-api-as-simple-proxy-for-lambda.html非代理集成,https://docs.aws.amazon.com/zh_cn/apigateway/latest/developerguide/getting-started-…...
HTML基础
HTML 基础 文章目录HTML 基础列表标签无序列表有序列表自定义列表表格标签表格基本标签表格基本结构表格完整结构:合并行和合并列表单标签input 系列标签属性标签text 标签radio 标签 单选框file 标签 文件选择button 标签 按钮input系列标签总结button按钮标签sele…...

ThreadPoolExecutor参数 keepAliveTime allowCoreThreadTimeOut
/*** Timeout in nanoseconds for idle threads waiting for work.* Threads use this timeout when there are more than corePoolSize* present or if allowCoreThreadTimeOut. Otherwise they wait* forever for new work.*/ private volatile long keepAliveTime;等待工作的…...

NeuroKit2:Python神经生理信号处理的全流程解决方案
NeuroKit2:Python神经生理信号处理的全流程解决方案 【免费下载链接】NeuroKit NeuroKit2: The Python Toolbox for Neurophysiological Signal Processing 项目地址: https://gitcode.com/gh_mirrors/ne/NeuroKit 神经生理信号处理是连接生理数据与临床洞察…...

音频的爬虫
1.前提准备需要在终端中下载requests模块 --- 终端在软件的左下角,下方图案例下载的语法:pip install requests(1)下载成功会报出的结果,如下图所示:(2)下载失败会报出的结果&#…...

OpenClaw隐私方案:Kimi-VL-A3B-Thinking本地处理医疗影像数据分析
OpenClaw隐私方案:Kimi-VL-A3B-Thinking本地处理医疗影像数据分析 1. 为什么医疗数据必须留在本地? 去年参与一个医学研究项目时,团队需要分析3000多份CT影像。当我们尝试使用某云服务时,合规部门直接叫停——这些包含患者面部特…...

美团外卖省钱终极指南:如何用自动化脚本每月多省200元
美团外卖省钱终极指南:如何用自动化脚本每月多省200元 【免费下载链接】meituan-shenquan 美团 天天神券 地区活动 自动化脚本 项目地址: https://gitcode.com/gh_mirrors/me/meituan-shenquan 还在为美团天天神券抢不到而烦恼吗?还在因为忘记签到…...

新手入门实战:通过快马平台为博客系统扩展文章搜索功能
今天想和大家分享一个特别适合新手练手的实战项目——给个人博客系统扩展文章搜索功能。作为一个刚入门开发不久的小白,我最近在InsCode(快马)平台上完成了这个功能扩展,整个过程既学到了东西,又特别有成就感。 功能需求分析 首先需要明确我们…...

Mem Reduct多语言界面配置指南:从基础设置到高级应用
Mem Reduct多语言界面配置指南:从基础设置到高级应用 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 功能…...

17. 杠杆平衡条件探究
6. 杠杆平衡条件探究 功能介绍: 通过动态交互演示杠杆的平衡条件 (F1L1=F2L2F_1L_1 = F_2L_2F1...

GPU显存友好!Ostrakon-VL-8B Bfloat16加速部署详解
GPU显存友好!Ostrakon-VL-8B Bfloat16加速部署详解 1. 项目背景与核心价值 Ostrakon-VL-8B是一款专为零售与餐饮场景优化的多模态大模型,能够高效处理商品识别、货架分析等视觉任务。传统部署方案往往面临显存占用高、推理速度慢的问题,而本…...

【100%通过率】华为OD机试真题2026双机位C卷 C++ 实现【红黑图】
目录 题目 思路 Code 题目 众所周知红黑树时一种平衡树,它最突出的特性就是不能有两个相连的红色节点。那我们定义一个红黑图,也就是一张无向图中,每个节点可能是红黑两种颜色,但我们保证没有两个相邻的红色节点。 现在给一张未染色的无向图,只能染红黑两种颜色,问总共…...

超立方体可视化背后的数学原理:Processing实现详解
超立方体可视化背后的数学原理:Processing实现详解 想象一下,当你第一次看到超立方体的三维投影时,那种既熟悉又陌生的感觉——它像是我们熟知的立方体,却又在某种更高维度上展开。这种四维几何体在三维空间的投影,不仅…...