springboot基础(82):分布式定时任务解决方案shedlock
文章目录
- 前言
- 简介
- shedlock + db
- SchedulerLock注解说明
- shedlock + redis
- 遇到的问题
- 1.配置shedlock不生效
- 2.报错net/javacrumbs/shedlock/core/LockProvider
- shedlock升级高版本
- 同名定时任务
前言
多节点或者多服务器拥有相同的定时任务,这种情况下,不同节点的相同定时任务会被重复执行。如何解决分布式定时任务重复执行问题?此刻我们可以引入分布式定时任务解决shedlock来解决这种定时任务重复执行的问题。
代码已分享至Gitee: https://gitee.com/lengcz/shedlock01
简介
Shedlock是一个基于Java的分布式锁库,用于解决分布式环境下的并发问题。它可以确保同一时间只有一个线程能够获取到锁,从而避免了多线程竞争导致的数据不一致或错误的问题。
Shedlock的原理是在数据库中创建一个特殊的表,用于记录锁的状态和持有者信息。当一个线程想要获取锁时,它会在表中插入一条记录,如果插入成功,则表示该线程成功获取到了锁;否则,表示有其他线程已经获取到了锁,当前线程需要等待。
Shedlock提供了简单易用的API,可以方便地在代码中使用锁。它支持不同的锁提供者,包括数据库(如MySQL、PostgreSQL)、ZooKeeper等。此外,Shedlock还提供了一些高级特性,如自动解锁、锁超时、定时任务等,以满足不同的场景需求。
总的来说,Shedlock是一个可靠、高效的分布式锁库,可以帮助开发者在分布式环境中处理并发问题,保证数据的一致性和正确性。它的设计简单,易于集成和使用,是Java开发者的理想选择之一。
shedlock + db
- 创建表
CREATE TABLE `shedlock` (`name` varchar(64) COLLATE utf8mb4_bin NOT NULL,`lock_until` timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3),`locked_at` timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),`locked_by` varchar(255) COLLATE utf8mb4_bin NOT NULL,PRIMARY KEY (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
- 引入依赖
<!--此依赖是shedlock核心依赖包,编译时依赖spring,大版本需要一致--><dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-spring</artifactId><version>2.2.0</version></dependency><!--shedlock+jdbc 方案需要引入此依赖--><dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-provider-jdbc-template</artifactId><version>2.2.0</version></dependency><!--quartz定时任务--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId></dependency><!--mysql连接驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!--jdbcTemplate需要的依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency>
- 配置数据源(如果没有配置的话)
spring:datasource:url: jdbc:mysql://xxx.xxx.xxx.xxx:3306/db1?characterEncoding=UTF-8&useSSL=false #//username: root #//password: 123456 #//driver-class-name: com.mysql.cj.jdbc.Driver- 配置LockProvider
import net.javacrumbs.shedlock.core.LockProvider;
import net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider;
import net.javacrumbs.shedlock.spring.annotation.EnableSchedulerLock;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.scheduling.annotation.EnableScheduling;import javax.sql.DataSource;import static net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider.Configuration.builder;@Configuration
@EnableScheduling //开启定时任务
@EnableSchedulerLock(defaultLockAtMostFor = "PT30S") //默认锁的最大占有30秒,建议在启动类上添加,这里是为了方便
public class SchedulerConfiguration {@AutowiredDataSource dataSource;@Beanpublic LockProvider lockProvider() {// //可以自定义数据源,可以作为一种考虑,一般不使用这个
// org.apache.tomcat.jdbc.pool.DataSource dataSource1 = new org.apache.tomcat.jdbc.pool.DataSource();
// dataSource1.setUrl("jdbc:mysql://127.0.0.1:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false");
// dataSource1.setUsername("root");
// dataSource1.setPassword("123456");LockProvider lockProvider = new JdbcTemplateLockProvider(builder()//指定表名.withTableName("shedlock")//指定数据源,一般使用dataSource而非手动定义的数据源.withJdbcTemplate(new JdbcTemplate(dataSource))//指定表字段名称,字段数量固定,只能改名称,且只有较高版本的shedlock-provider-jdbc-template依赖才提供该配置项
// .withColumnNames(new JdbcTemplateLockProvider.ColumnNames("name","lock_until","locked_at","locked_by"))//使用数据库时间,只有较高版本的shedlock-provider-jdbc-template依赖才提供该配置项
// .usingDbTime()//作用未知,只有较高版本的shedlock-provider-jdbc-template依赖才提供该配置项
// .withLockedByValue("myvalue")//作用未知,只有较高版本的shedlock-provider-jdbc-template依赖才提供该配置项
// .withIsolationLevel(1).build());return lockProvider;}
}
- 使用
import lombok.extern.slf4j.Slf4j;
import net.javacrumbs.shedlock.core.SchedulerLock;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;@Slf4j
@Component
@EnableScheduling //开启定时任务
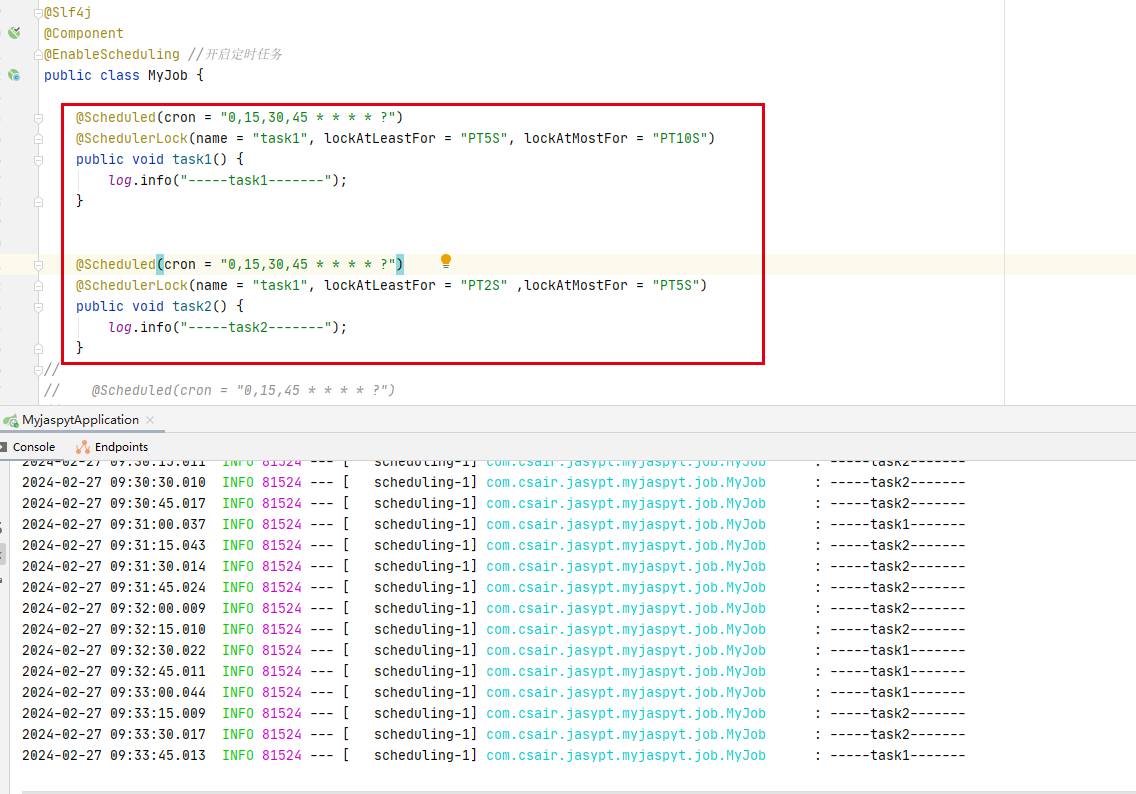
public class MyJob {@Scheduled(cron = "0,15,30,45 * * * * ?")@SchedulerLock(name = "task1", lockAtLeastForString = "PT5S", lockAtMostForString = "PT10S")public void task1() {log.info("-----task1-------");}
}
定时任务执行后,查看数据库
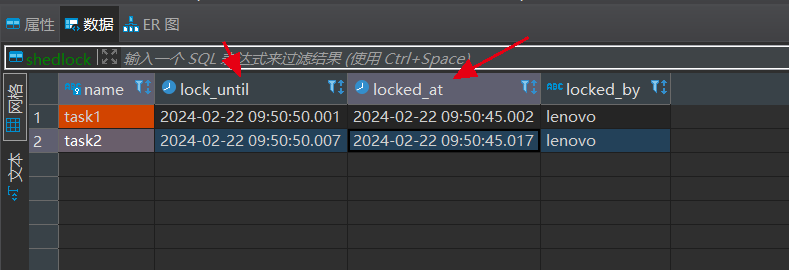
- name : 定时任务名称,多节点执行定时任务,谁获得锁资源谁执行
- locked_at: 上锁开始时间,就是任务的执行开始时间
- lock_until: 释放锁的时间
- locked_by: 谁操作的,通常会计算机名称
SchedulerLock注解说明
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface SchedulerLock {/*** 任务的名称,同名任务互斥,只会执行一个*/String name() default "";/*** 锁的最多占用多久,单位毫秒*/long lockAtMostFor() default -1L;/*** 锁的最多占用多久,字符格式,PT2S 表示2秒,PT2M表示2分钟*/String lockAtMostForString() default "";/*** 锁的最少占用时间,单位毫秒*/long lockAtLeastFor() default -1L;/*** 锁的最少占用时间,字符格式,PT2S 表示2秒,PT2M表示2分钟*/String lockAtLeastForString() default "";
}
shedlock + redis
引入依赖,注意建议版本相同,避免可能带来的版本兼容问题。
- 引入依赖
<dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-spring</artifactId><version>2.2.0</version></dependency><dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-provider-redis-spring</artifactId><version>2.2.0</version></dependency>
- 配置LockProvider
@Beanpublic LockProvider lockProvider(RedisTemplate redisTemplate) {return new RedisLockProvider(redisTemplate.getConnectionFactory());}
遇到的问题
1.配置shedlock不生效
- 在非springboot中,请确保配置的bean是否被扫描到,确保LockProvider是否被加载到容器中。
- 是否定时任务开启了线程池等
2.报错net/javacrumbs/shedlock/core/LockProvider
请检查shedlock-spring 依赖的spring版本与项目的spring版本是否一致(大版本号是否一致)。
报错net/javacrumbs/shedlock/core/LockProvider
注意 shedlock改版本后,注意检查代码,会存在轻微不同。
shedlock升级高版本
升级到4.46.0后,SchedulerLock会提示废弃
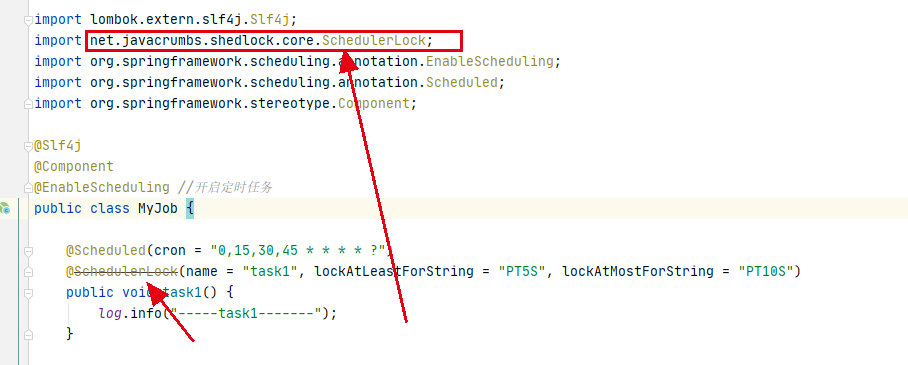
此时需要更换导入新的SchedulerLock注解
import net.javacrumbs.shedlock.spring.annotation.SchedulerLock;
该注解的内容,只有3个参数,lockAtMostFor 锁的最长占有时间,lockAtLeastFor 锁的最小占有时间,单位毫秒
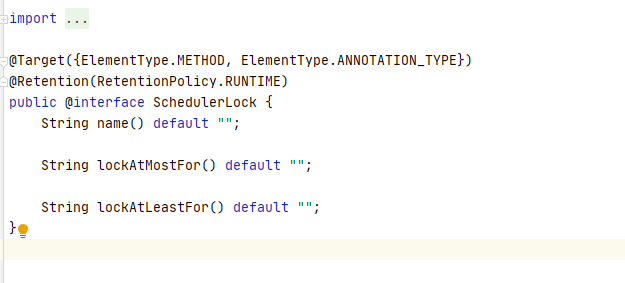
代码
@Scheduled(cron = "0,15,30,45 * * * * ?")@SchedulerLock(name = "task1", lockAtLeastFor = "PT5S", lockAtMostFor = "PT10S")public void task1() {log.info("-----task1-------");}
同名定时任务
同名定时任务只会执行一个,多个节点(节点这里指的是服务,一个服务视为一个节点)相同名称的任务只会有一个获取到锁资源并执行,而同一个节点的同名任务只会有一个被执行,且任务的执行是随机的,没有规律,不能预测下一次谁有执行资格,对于多节点而言,也同样遵循此规则。
相关文章:
springboot基础(82):分布式定时任务解决方案shedlock
文章目录 前言简介shedlock dbSchedulerLock注解说明 shedlock redis遇到的问题1.配置shedlock不生效2.报错net/javacrumbs/shedlock/core/LockProvider shedlock升级高版本同名定时任务 前言 多节点或者多服务器拥有相同的定时任务,这种情况下,不同节…...

【Golang】Gorm乐观锁optimisticlock的使用
在数据库操作中,为了保证数据的一致性和完整性,常常需要采取一些措施来防止并发操作导致的数据冲突。悲观锁和乐观锁是两种常见的并发控制机制。 悲观锁(Pessimistic Lock) 悲观锁的基本假设是,数据在并发访问时很可能…...

Apache Doris 发展历程、技术特性及云原生时代的未来规划
本文节选自《基础软件之路:企业级实践及开源之路》一书,该书集结了中国几乎所有主流基础软件企业的实践案例,由 28 位知名专家共同编写,系统剖析了基础软件发展趋势、四大基础软件(数据库、操作系统、编程语言与中间件…...
2024-02-26(Spark,kafka)
1.Spark SQL是Spark的一个模块,用于处理海量结构化数据 限定:结构化数据处理 RDD的数据开发中,结构化,非结构化,半结构化数据都能处理。 2.为什么要学习SparkSQL SparkSQL是非常成熟的海量结构化数据处理框架。 学…...

RubyMine 2023:让Ruby编程变得更简单 mac/win版
JetBrains RubyMine 2023是一款专为Ruby开发者打造的强大集成开发环境(IDE)。这款工具集成了许多先进的功能,旨在提高Ruby编程的效率和生产力。 RubyMine 2023软件获取 RubyMine 2023的智能代码编辑器提供了丰富的代码补全和提示功能&#…...
低功耗设计——门控时钟
1. 前言 芯片功耗组成中,有高达40%甚至更多是由时钟树消耗掉的。这个结果的原因也很直观,因为这些时钟树在系统中具有最高的切换频率,而且有很多时钟buffer,而且为了最小化时钟延时,它们通常具有很高的驱动强度。此外&…...

《凤凰架构》-本地事务章节 读书笔记
1、写锁又名排它锁,写锁禁止其他事务施加读锁和写锁,而不禁止其他事务读取数据(如果遇到了个不加任何锁的另一个事务2,写锁是无法阻止事务2读取数据的),这就是读未提交隔离级别中的脏读问题产生的根因。 2…...

ruby对比python,30分钟教程
会python还需要搞会ruby吗? web方面:ruby有rails,python有flask,django,rails远超django Ruby,一种简单快捷的面向对象(面向对象程序设计)脚本语言,在20世纪90年代由日本人松本行弘…...

C语言——oj刷题——判断闰年
当我们谈到判断闰年时,我们通常会遵循以下规则:闰年是指能被4整除但不能被100整除的年份,或者能被400整除的年份。在C语言中,我们可以通过编写一个简单的程序来实现这一功能。下面是一个示例代码,用于判断一个给定年份…...
Git笔记——3
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 一、合并模式和分支策略 二、bug分支 三、强制删除分支 四、创建远程仓库 五、克隆远程仓库_HTTPS和_SSH 克隆远程仓库_HTTPS 克隆远程仓库_SSH 六、向远程仓库…...

C++面试 -操作系统-安全能力:死锁的危害、出现原因、解决方法
目录 死锁的危害 死锁出现的原因 死锁的解决方法 死锁是计算机科学中一个非常重要的概念,特别是在多线程、并发编程以及数据库管理系统等领域中。下面是关于死锁的危害、出现原因和解决方法的基础概述: 死锁的危害 资源浪费:死锁导致系统…...

台湾香港澳门媒体宣发稿报道有哪些平台资源,跨境出海推广新闻营销公司告诉你
【本篇由言同数字科技有限公司原创】随着全球化的快速发展和互联网的普及,品牌越来越重视海外市场的开拓。作为亚洲地区的重要经济中心,香港、台湾和澳门不仅具有独特的地理位置和文化背景,还拥有丰富的媒体资源。在本文中,我们将…...

Python分支和循环结构及其应用(文末送书)
一、分支结构 应用场景 我们写的Python代码都是一条一条语句顺序执行,这种代码结构通常称之为顺序结构。然而仅有顺序结构并不能解决所有的问题。 if语句的使用 在Python中,要构造分支结构可以使用if、elif和else关键字。所谓关键字就是有特殊含义的…...

机器学习——线性代数中矩阵和向量的基本介绍
矩阵和向量的基本概念 矩阵的基本概念(这里不多说,应该都知道) 而向量就是一个特殊的矩阵,即向量只有一列,是个n*1的矩阵 注:一般矩阵用大写字母表示,向量用小写字母表示 矩阵的加减运算 两个…...
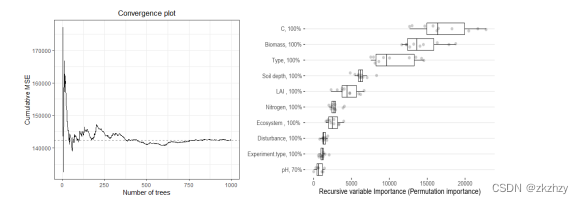
基于R语言的Meta分析【全流程、不确定性分析】方法与Meta机器学习技术应用
Meta分析是针对某一科研问题,根据明确的搜索策略、选择筛选文献标准、采用严格的评价方法,对来源不同的研究成果进行收集、合并及定量统计分析的方法,最早出现于“循证医学”,现已广泛应用于农林生态,资源环境等方面。…...
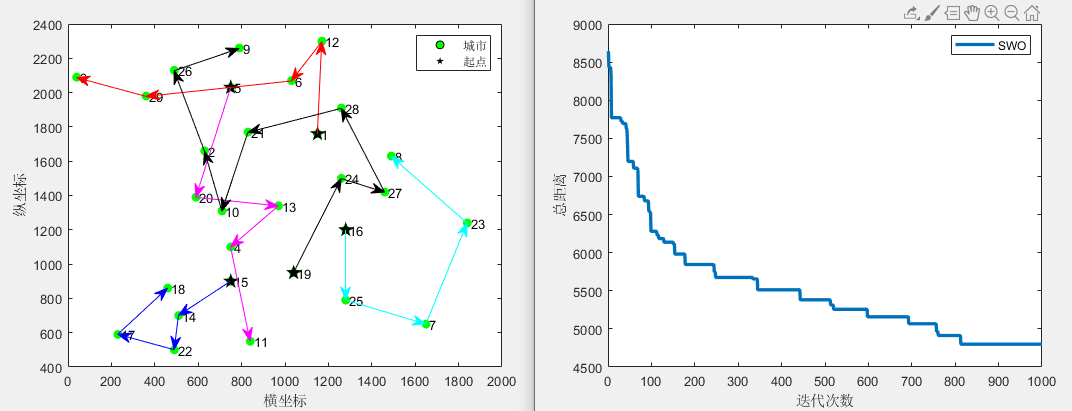
蜘蛛蜂优化算法SWO求解不闭合MD-MTSP,可以修改旅行商个数及起点(提供MATLAB代码)
1、蜘蛛蜂优化算法SWO 蜘蛛蜂优化算法(Spider wasp optimizer,SWO)由Mohamed Abdel-Basset等人于2023年提出,该算法模型雌性蜘蛛蜂的狩猎、筑巢和交配行为,具有搜索速度快,求解精度高的优势。VRPTW&#x…...

Java架构师之路六、高并发与性能优化:高并发编程、性能调优、线程池、NIO、Netty、高性能数据库等。
目录 高并发编程: 性能调优: 线程池: NIO: Netty: 高性能数据库: 上篇:Java架构师之路五、微服务:微服务架构、服务注册与发现、服务治理、服务监控、容器化等。-CSDN博客 下篇…...

MySQL-行转列,链接查询
1. 行转列 1.1 示例数据准备 create table test_9(id int,name varchar(22),course varchar(22),score decimal(18,2) ); insert into test_9 (id,name,course,score)values(1,小王,java,99); insert into test_9 (id,name,course,score)values(2,小张,java,89.2); inse…...
Linux之安装jdk,tomcat,mysql,部署项目
目录 一、操作流程 1.1安装jdk 1.2安装tomcat(加创建自启动脚本) 1.3 安装mysql 1.4部署项目 一、操作流程 首先把需要用的包放进opt文件下 1.1安装jdk 把jdk解压到/usr/local/java里 在刚刚放解压包的文件夹打开vim /etc/profile编辑器,…...

HTMLElement.click()的回调触发踩坑
先看看以下代码 const el document.getElementById("btn") el.addEventListener("click", () > {Promise.resolve().then(() > console.log("microtask 1"));console.log("1"); }); el.addEventListener("click", (…...

2026年OPPO迎来“大年”:影像、折叠屏、IoT等多领域突破,高端化版图持续扩张
2026年4月21日,OPPO在成都举办新品发布会,发布Find X9s Pro和Find X9 Ultra。这一年OPPO在多个领域取得重大进展,迎来发展“大年”。旗舰影像:定义下一代移动影像移动影像是OPPO长期投入的领域,2026年收获颇丰。Find X…...

英雄联盟客户端效率工具League Akari:从手动操作到智能辅助的全面升级
英雄联盟客户端效率工具League Akari:从手动操作到智能辅助的全面升级 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akar…...

AMD硬件调试终极指南:使用SMUDebugTool实现性能调优
AMD硬件调试终极指南:使用SMUDebugTool实现性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitc…...

打造你的专属Web端粒子艺术工坊:手势交互、音频响应与30种几何形态切换
打造你的专属Web端粒子艺术工坊:手势交互、音频响应与30种几何形态切换 在数字艺术与创意编程的交汇处,一个全新的可能性正在被打开——通过现代Web技术,任何人都能在浏览器中构建属于自己的沉浸式粒子艺术空间。这不再仅仅是专业开发者的专利…...

python游戏开发和设计学习总结
在本次 Python 课程中,我们主要学习了弹球游戏和飞机大战两款小游戏的开发与设计,借助 pygame 库完成代码编写、功能设计与调试,从基础小游戏入手,逐步了解 2D 游戏的开发流程,收获了很多编程与游戏设计的知识。 一、…...

LOL云顶之弈自动化脚本:3步搭建你的智能刷经验助手
LOL云顶之弈自动化脚本:3步搭建你的智能刷经验助手 【免费下载链接】LOL-Yun-Ding-Zhi-Yi 英雄联盟 云顶之弈 全自动挂机刷经验程序 外挂 脚本 ,下载慢可以到https://gitee.com/stringify/LOL-Yun-Ding-Zhi-Yi 项目地址: https://gitcode.com/gh_mirrors/lo/LOL-Y…...

告别单线程等待:用xtdata的download_history_data2批量拉取A股全市场历史数据
告别单线程等待:用xtdata的download_history_data2批量拉取A股全市场历史数据 在量化研究的日常工作中,构建本地行情数据库往往是第一步,也是最耗时的一步。传统的数据获取方式通常需要逐只股票请求,不仅效率低下,还容…...

用Python操作PostgreSQL时,psycopg2报UndefinedColumn错误?检查你的占位符写法
Python操作PostgreSQL时psycopg2的UndefinedColumn错误解析与解决方案 PostgreSQL作为一款功能强大的开源关系型数据库,在Python生态中常通过psycopg2库进行交互。但在实际开发中,不少开发者会遇到psycopg2.errors.UndefinedColumn错误——明明数据库中存…...

【C# .NET 11 AI推理加速终极指南】:5大零拷贝内存优化+3层GPU绑定技巧,实测吞吐提升4.7倍
第一章:C# .NET 11 AI推理加速的核心演进与架构变革.NET 11 将 AI 推理能力深度融入运行时与 SDK 层,不再依赖外部 Python 运行时桥接,而是通过原生张量抽象(Tensor<T>)、统一硬件调度器(HardwareAcc…...

30 秒开启!Brex 开源 CrabTrap,以大语言模型保障 HTTP 代理安全
开源项目 Brex 开源安全部署代理 CrabTrap,30 秒即可开启大语言模型评判的 HTTP 代理安全保障。 安全部署代理 CrabTrap 是一款以大语言模型为评判标准的 HTTP 代理,用于保障生产环境中代理的安全。它会拦截 AI 代理发出的每一个请求,依据…...