2023 龙蜥操作系统大会演讲实录:《兼容龙蜥的云原生大模型数据计算系统——πDataCS》

本文主要分三部分内容:第一部分介绍拓数派公司,第二部分介绍 πDataCS 产品,最后介绍 πDataCS 与龙蜥在生态上的合作。
杭州拓数派科技发展有限公司(简称“拓数派”,英文名称“OpenPie”)是国内基础数据计算领域的高科技创新企业。作为国内云上数据库和数据计算领域的引领者,以“Data Computing for New Discoveries”「数据计算,只为新发现」为使命,致力于在数字原生时代,运用突破性计算理论、独创的云原生数据库旗舰产品以及之上的算法和数学模型,建立下一代云原生数据平台的前沿标准,驱动企业实现从“软件公司”到“数据公司”再到“数学公司”的持续进阶,加速数字化转型升级。
拓数派自成立以来专注于数据计算领域,旗下大模型数据计算系统(PieDataComputingSystem, 缩写:πDataCS),以云原生技术重构数据存储和计算,一份存储,多引擎数据计算,让 AI 模型更大更快,全面升级大数据系统至大模型时代。πDataCS 旨在助力企业优化计算瓶颈、充分利用和发挥数据规模优势,构建核心技术壁垒,更好地赋能业务发展,使得自主可控的大模型数据计算系统保持全球领先,让大模型技术全面赋能各行各业。 目前大模型数据计算系统,面向国内市场提供公有云版、社区版、企业版及一体机多个版本,满足企业不同业务场景需求,并已为金融、制造、医疗及教育等行业用户构建了 AI 数据底座。

拓数派拥有强悍的研发核心团队和有成功上市经验的管理团队。其核心团队成员主要来自 Pivotal、IBM、腾讯、字节跳动、快手、Oracle 等世界 500 强以及国内头部互联网公司。拓数派创始人兼 CEO 冯雷(Ray Von)是数据云和人工智能领域的连续创业者和技术引领者。冯雷于 2010 年从美国硅谷归国,曾在 500 强公司 EMC 旗下创建 Greenplum 中国研发部门工作。2013 年随着全球 Pivotal 组建,冯雷先生在中国 Greenplum 大数据和 VMWare 的 PaaS 云的基础上组建了 Pivotal 中国研发中心,推动了 Greenplum 大数据库、CloudFoundry PaaS 云等知名开源产品的领域领先地位。

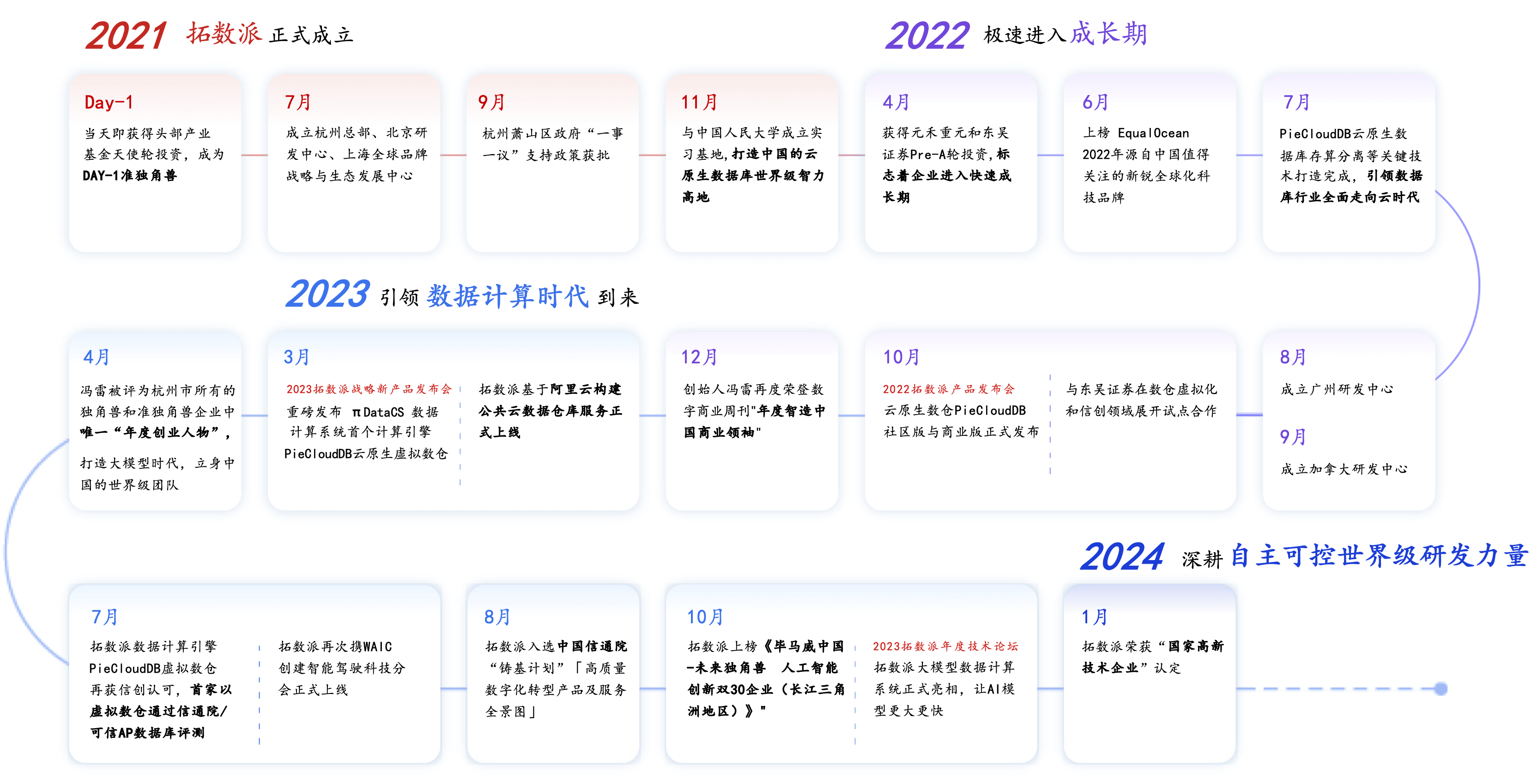
拓数派 2021 年创立,迅速进入快速发展阶段,引领数据计算时代的到来。成立当天即获得头部产业基金天使轮投资,成为 DAY-1 准独角兽。2022 年拓数派发布了云原生虚拟数仓 PieCloudDB 社区版与商业版。2023 年拓数派大模型数据计算系统 πDataCS 正式亮相,让 AI 模型更大更快。
下面介绍 πDataCS。数据分析的目的最终是为了发现解释世界规则的模型。有了数据和计算,最终用来描述世界规律,构建一个模型系统。构建模型系统的关键是要有足够多的数据,数据是核心竞争力。有了数据后要构造出解释世界的模型。拓数派团队既具备大数据分析的丰富经验,也具备云计算方面的实战经验。
一提到模型可能首先想到有几千亿参数的大模型数据系统,其实日常生活中的模型无处不在。例如自由落体模型,由物理实验推导而来。最早的物理规律并不是理论推导而成,而是由数据分析得出,例如开普勒行星运动三定律,就是通过分析天文学家几十年的观测数据总结得出。以自由落体模型为例,可以考虑物体的自由落体运动以时间和变量为参数。构造这样简单的一套模拟系统,通过观测收集到数据,再经过计算发现 p0、p1 参数都是 0,只有 p3 是5 。经过分析后得出,只有当 p0、p1 值为该值时才符合客观规律,这就是简单的模型训练过程。进行数据分析时,不仅要构造像大模型这种复杂系统,生活中也有很多像自由落体这种模型等待我们发现。
下面是 πDataCS 产品的架构图。

πDataCS 打造了全新的云原生架构,支持一份数据,多引擎计算。πDataCS 支持多种云平台,包括公有云和私有云。πDataCS 以云原生技术重构数据存储和计算,先将数据计算系统中的计算和数据分离,增强系统的弹性。接着,考虑到未来数据治理和交易,拓数派把元数据和用户数据再次分离,实现了全新的 eMPP 架构。元数据被映射到块存储,由元数据管理系统「木牍」进行管理;用户数据被映射到对象存储,由「简墨」存储系统来管理;计算被映射到容器或者虚拟机,由计算系统来管理。元数据可以在系统中描述数据的结构,找到数据位置。将元数据单独处理后简化了数据交换。例如进行黄金交易时不一定一手交钱一手交货,可以将存储黄金的保险柜钥匙交出,此处的保险柜钥匙就相当于元数据管理系统,避免了数据遗漏等风险。此外 πDataCS 还利用 FPGA 硬件加速技术来提高对数据文件的访问。
目前,πDataCS支持三种计算引擎:
- PieCloudDB: 作为拓数派首款云原生数仓计算引擎,支持 SQL 语言模型,兼容 HTAP
- PieCloudVector: 为支持和大模型配合的向量计算而建立的云原生向量计算引擎
- PieCloudML: 为支持 Python 和 R 等机器学习语言而建立的云原生机器学习引擎
πDataCS 的第一个优势是全面升级 Hadoop 大数据和 Greenplum 数仓至云原生数据平台。打造 πDataCS 是为了全面升级用户的数据平台。曾经谈到大数据时一定会提到 Hadoop,随着时间发展,人们发现 Hadoop 的很多问题,但很多用户的大数据系统还是基于 Hadoop 实现。自从 Hadoop 之后出现很多大数据技术,但只能解决一部分数据问题。例如 MPP 数据库,主要为了处理关系型数据,还有 MySQL 数据库只能处理某一个类型的数据。只有 Hadoop 平台可以使用它的若干个模块来处理所有的数据,包括结构化的、非结构化的、文本、图像等等。同 Hadoop 一样,πDataCS 和也可以通过一个平台多种计算引擎来为客户处理所有数据,包括结构化的、非结构化的、文本、图像等。

πDataCS 的第二优势是可以全面支持大语言基础模型和私域数据结合做垂直应用。拓数派第二款计算引擎 PieCloudVector,是一款可以用于存储、查询和分析向量数据(比如特征向量)的向量数据库。
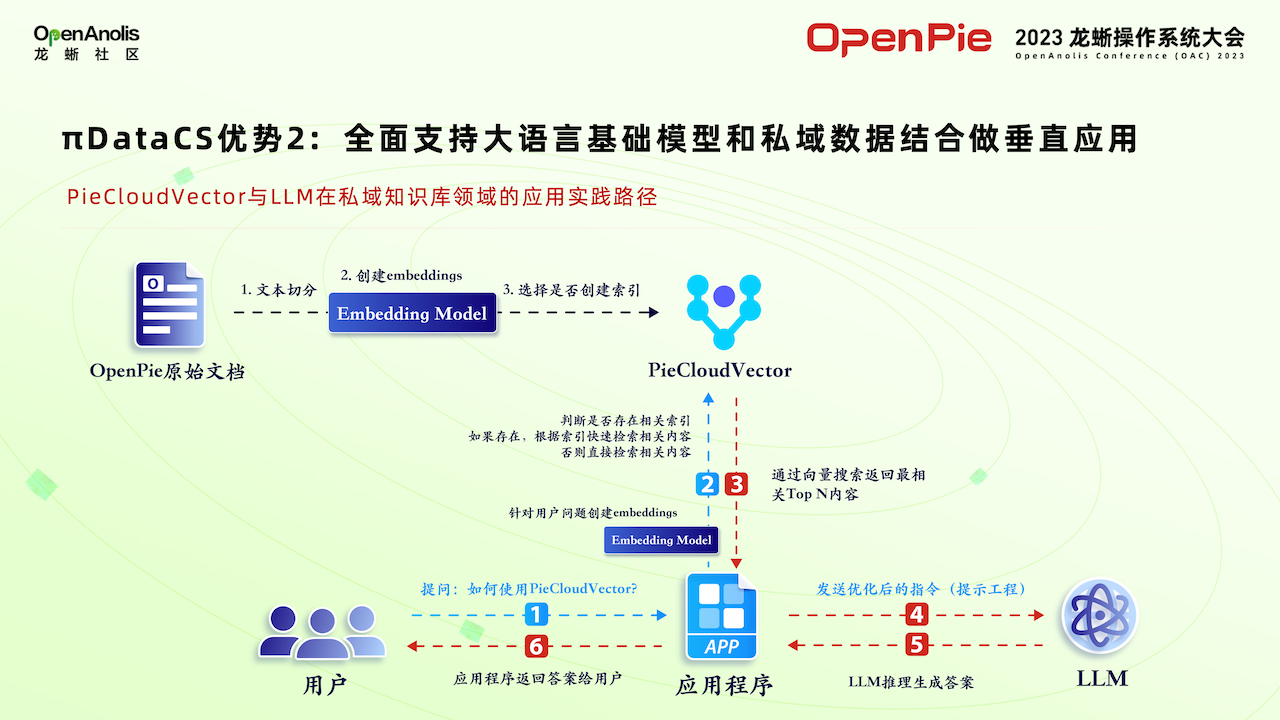
某知名金融客户积累了很多金融方面的数据,包括各种各业的行业和所投资的各个公司的一些财务数据等,这些是他的核心竞争力。他希望打造一个他私有的大模型系统,使用问答的方式来使用他收集的这些金融方面数据,但是考虑到数据的隐私和安全等,不可能使用公开的大模型。上图是以 PieCloudVector 为核心,帮助客户找到了这样一套私有的金融方面的大模型系统。首先这些文档使用模型进行提取,将特征存入向量计算 Vector 数据中,再通过架构和他的应用程序进行交互,然后可以使用问答的方式来使用金融数据,也可以使用像大语言模型系统。
πDataCS 的第三个优势是云原生 eMPP 计算引擎全面颠覆 MPP 技术,打造大模型数据计算新范式。这一优势是通过第一款计算引擎 PieCloudDB Database 来实现的。
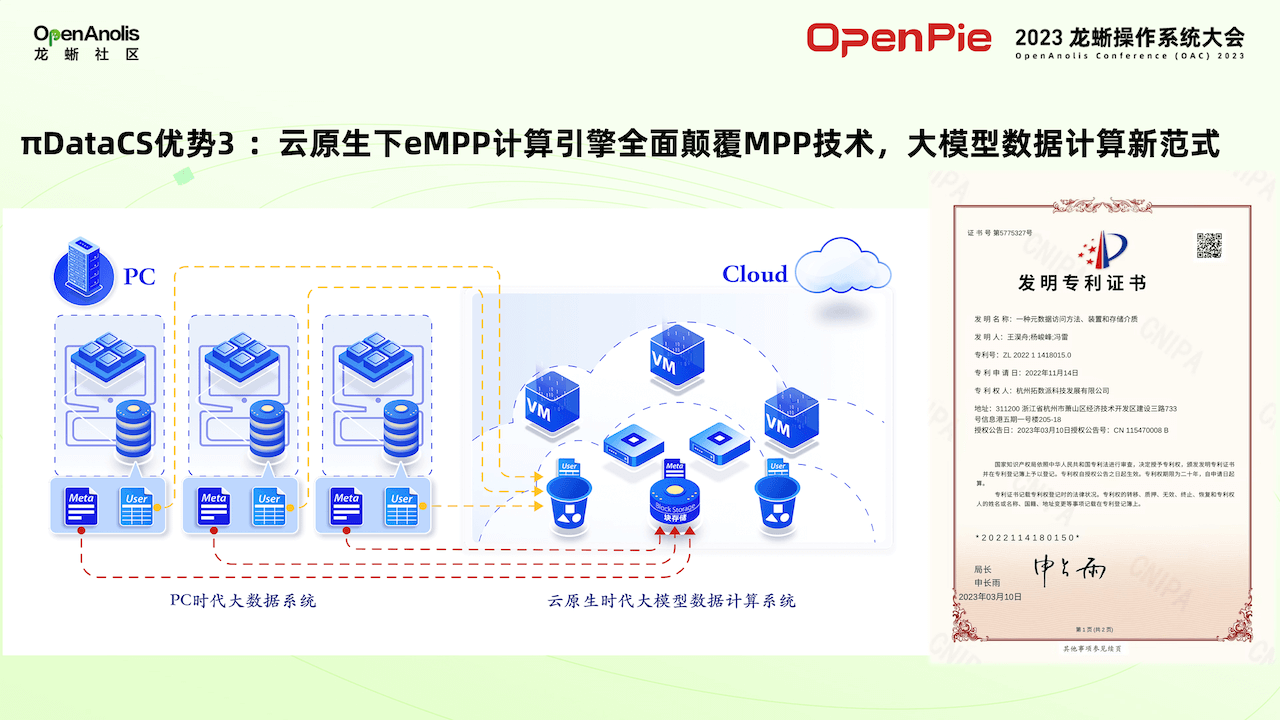
虚拟机技术可以把一台物理服务器切换成若干台小的服务器,把它一台物理服务器的资源切换虚拟机,给不同的用户来用。同样我们希望把数仓资源切算成若干的虚拟数仓,然后交给各个部门来使用,提高硬件的使用效率。以上解释了为什么拓数派团队要对 PieCloudDB 打造基于云原生的 eMPP 架构。
PieCloudDB 是基于 eMPP 架构的数仓系统,实现了把元数据收集到元数据服务木牍当中,把用户数据存储到了简墨系统中,然后实现了存储分离的虚拟数仓,实现了元数据、用户数据和虚拟数仓数据计算之间独立的扩缩容。使用基于 PC 架构的传统数仓系统,数据和计算紧紧绑定在一起。可以对它进行横向的扩展,但是同时必须要扩展存储,也需要扩展计算,计算和存储不能进行独立的扩展。这种架构下需要缩容时操作很困难。通过 PieCloudDB 虚拟数仓,将一个个数仓打造成不包含任何数据而且无状态的计算平台。可以根据需要对数仓的计算能力进行扩缩容。

在实际的应用场景中,简墨系统可以构建在 S3 对象存储中或者 HDFS 和 NAS 中。
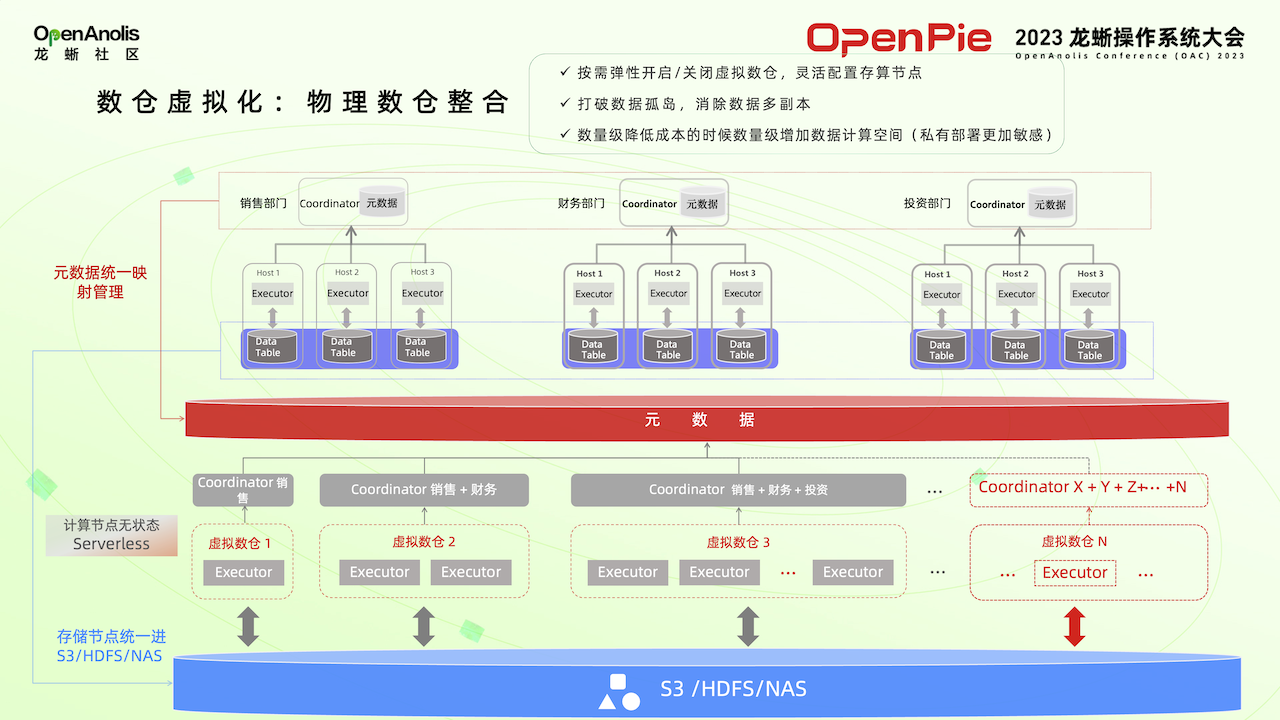
PieCloudDB 通过映射,让每一个业务部门自己拥有独立的一套数仓系统,使用起来与传统 MPP 数据库没有太大区别。但各个部门进行数据交换时,不需要再进行 ETL 操作,通过数据授权对元数据进行操作,将不同部门之间的数据映射给其他部门。在存储系统中,所有数据只存储了一份。类似前文交换保险柜钥匙来获得黄金,而不是真正进行黄金交换。通过虚拟数仓系统,可以降低硬件和管理成本。虚拟化可以提高硬件的使用率,提升数据资源的应用效率,再通过一些技术提高数据安全性。

为了实现虚拟数仓系统,PieCloudDB 完成了四大技术突破。
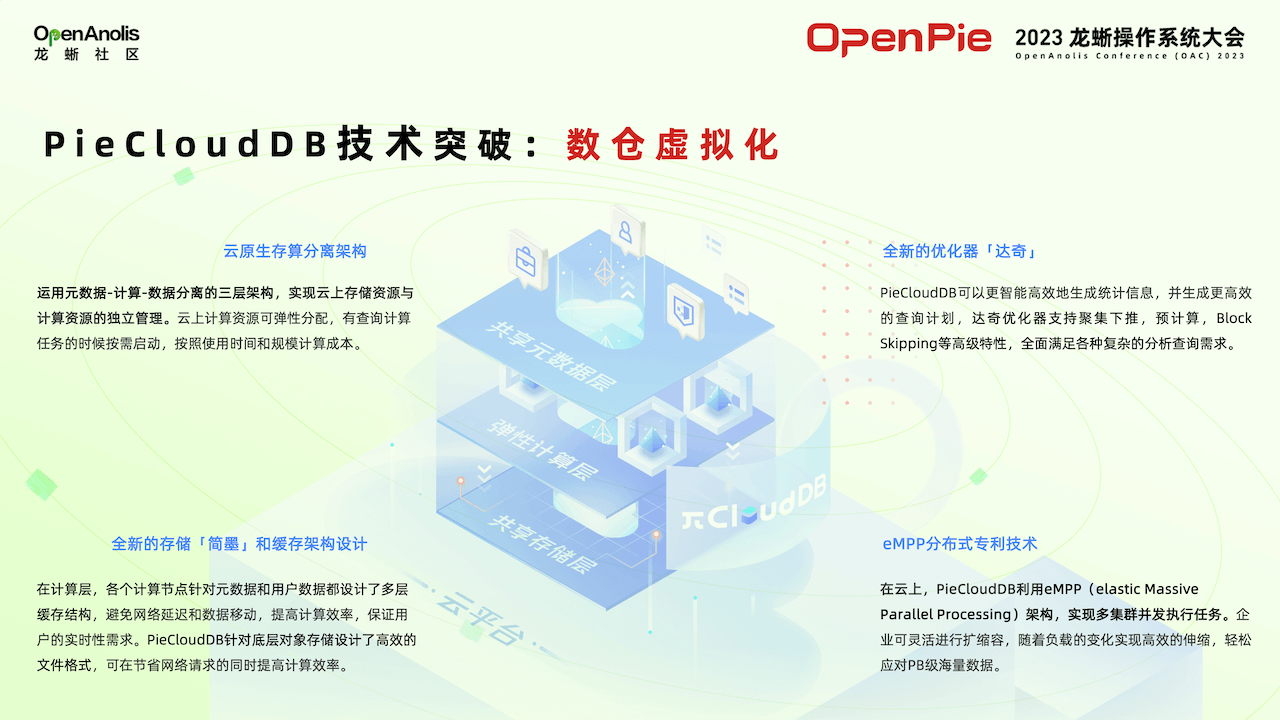
首先,PieCloudDB 实现了云原生存算分离架构:用户数据,元数据和计算三层分离,可进行独立扩缩容。第二根据云原生特点打造优化器达奇。云原生优化器负责根据部署 PieCloudDB 架构的特点来生成更优的执行计划,提高数据分析效率。第三是全新的数据存储引擎简墨,还有相关缓存架构设计,提高虚拟数仓访问数据输出的效率。第四是 eMPP 分布式技术,为传统 MPP 架构增加弹性,使虚拟数仓进行横向的扩容和缩容变得非常方便。
πDataCS 第二款计算引擎PieCloudVector,针对一些像金融、保险这方面用户,对数据的安全性要求比较高,需要打造一个自己私有的大模型系统。
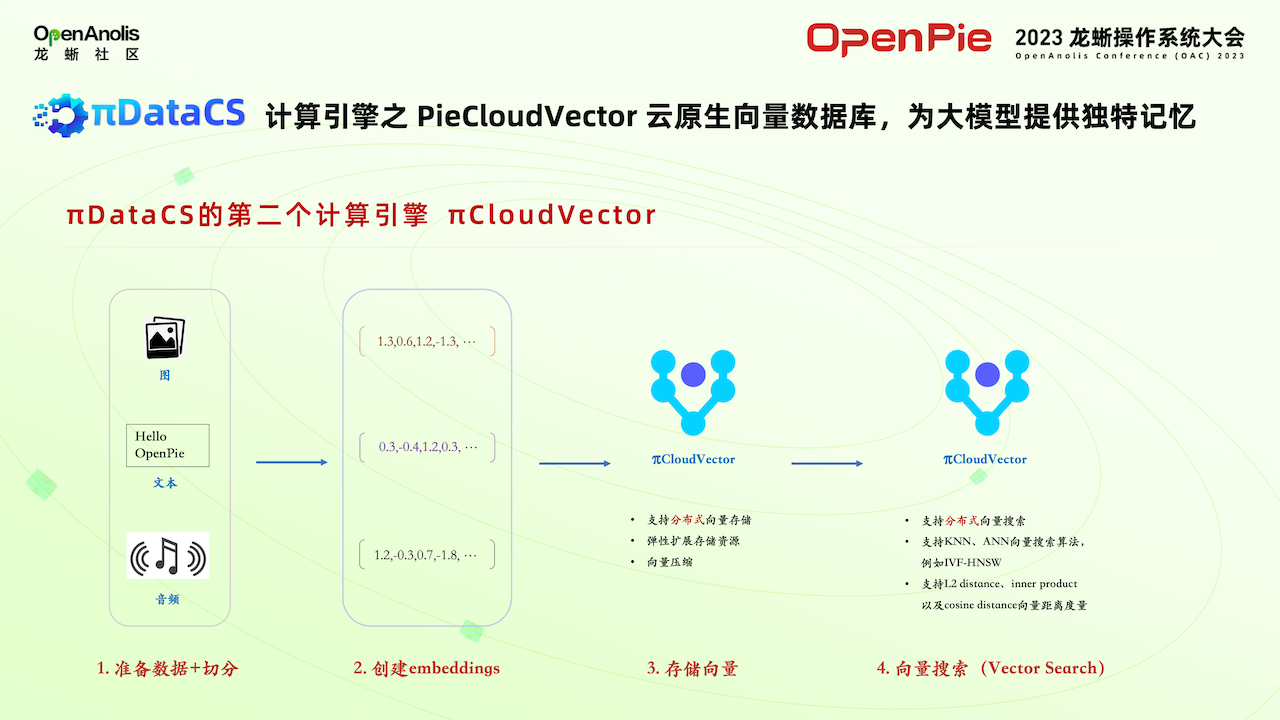
把用户收集的数据或者是公有的数据,通过特征提取,创建一系列 embeddings,存储到向量数组中,再通过其他一些开源框架和大模型进行一个交互。相当于 PieCloudVector 为客户自己构建自有大模型提供存储底座。相对于其他的向量数据库,包括一些专用的数据库,还有传统的关键数据库有这些向量的插件。
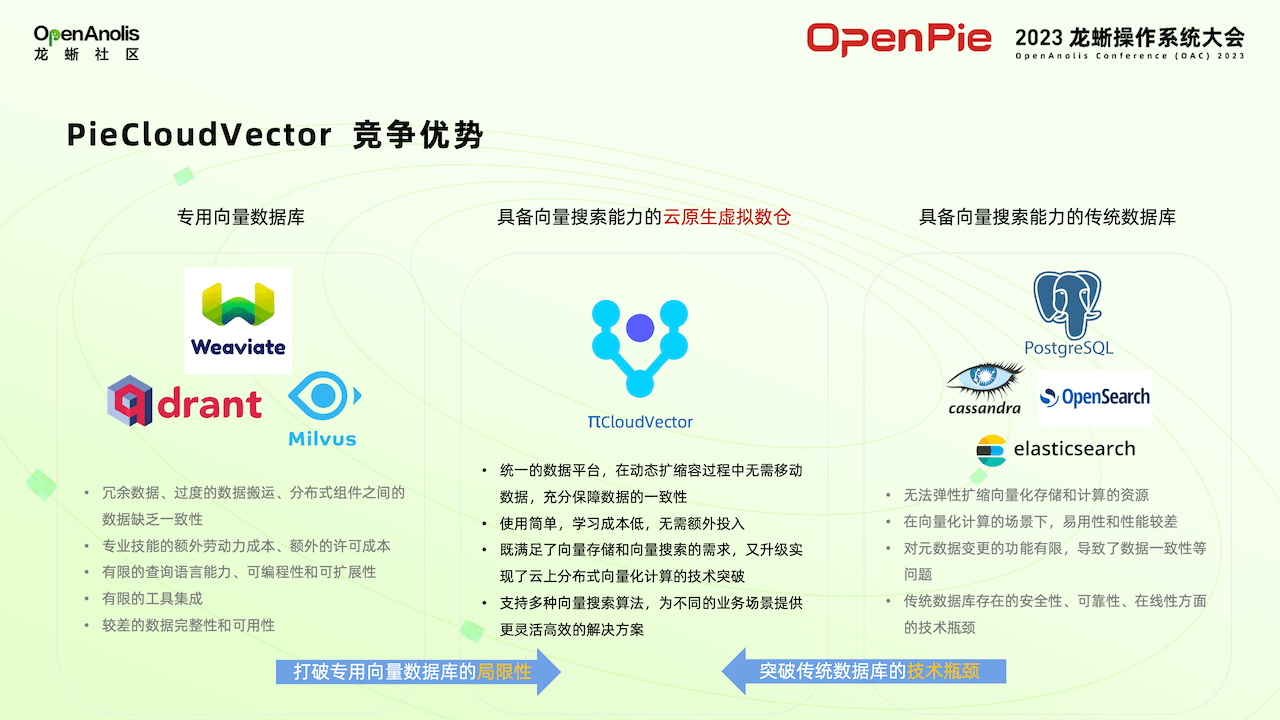
相比这两种方案,我们这套系统有哪些优势呢?第一,使用专用的向量数据库,其他一些相关数据,例如存储在数据库中的关键型数据等,需要进行若干数据移动。传统的数据库在高可用或者扩展方面有缺陷。所以 PieCloudVector 集中了两方面优势,比较方便进行水平的扩缩容,第二个同时具有这两方面的优点,既可以存储普通的关系型数据,也可以存储向量数据。
第三款计算引擎是正在开发的新一代(大模型)机器学习 PieCloudML,在现有这些架构的基础上,通过新一代 PieCloudML,增加机器学习、图像数据处理等大模型系统提供更深一步的支持。

大模型数据计算系统,面向国内市场提供云上云版、社区版、企业版、一体机四个版本,满足企业不同业务场景需求。πDataCS 有三种部署方式。第一种直接部署在云上,第二种部署在客户现有的云平台,第三种是一体机系统,用户接上网线,插上电源可以直接使用。
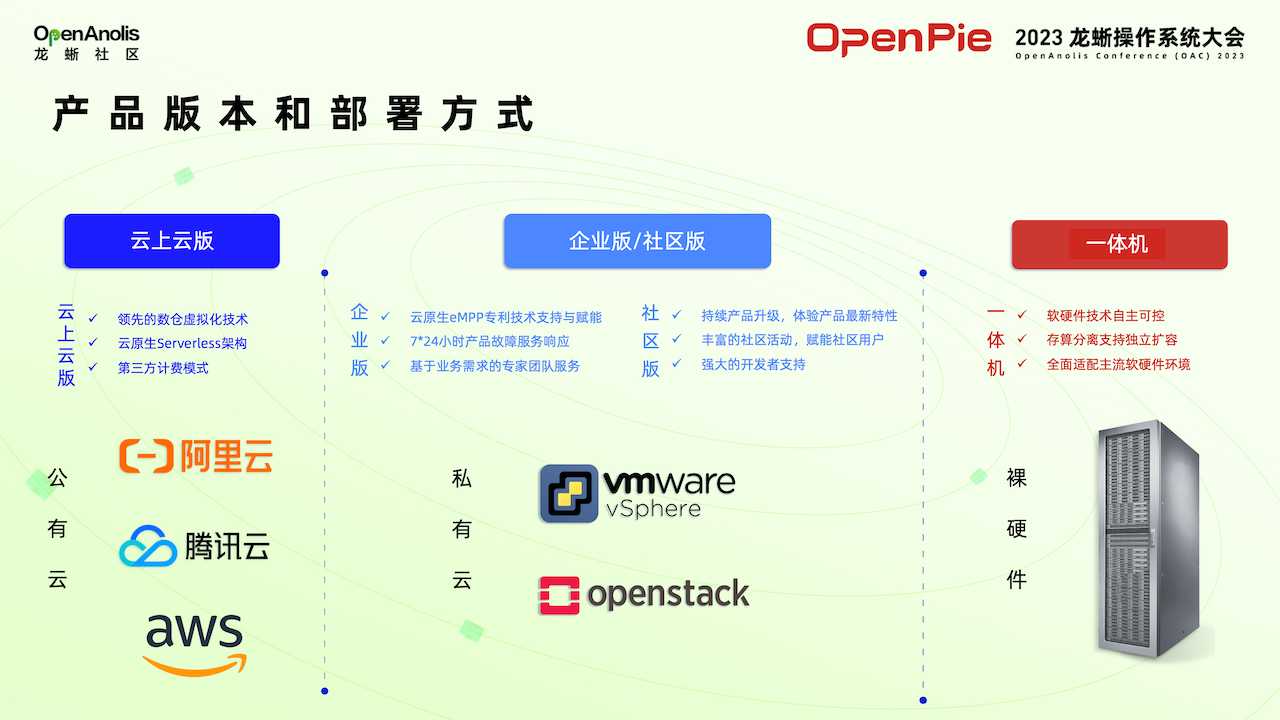
拓数派一直秉持着“开放互信、合作共赢”的理念,致力于构建蓬勃的数据生态。πDataCS 也非常注重软件生态打造,注重与社区方面的合作。πDataCS 需要适配各种各样的云环境,所以需要打造强大的软件生态系统。拓数派团队针对不同的部署方式与龙蜥平台进行了全方位的测试,测试结果显示,龙晰平台安全稳定、性能优异。因此,我们确信,龙蜥平台可以支持 πDataCS 良好运行。 除了龙蜥外,πDataCS 也完成了与其他主流软硬件平台的适配工作。拓数派将继续努力,打造完善的产品生态,为用户提供更安全稳定、高性能、易用的大模型数据计算平台。

相关文章:
2023 龙蜥操作系统大会演讲实录:《兼容龙蜥的云原生大模型数据计算系统——πDataCS》
本文主要分三部分内容:第一部分介绍拓数派公司,第二部分介绍 πDataCS 产品,最后介绍 πDataCS 与龙蜥在生态上的合作。 杭州拓数派科技发展有限公司(简称“拓数派”,英文名称“OpenPie”)是国内基础数据计…...

【Vue渗透】Vue站点渗透思路
原文地址 极核GetShell 前言 本文经验适用于前端用Webpack打包的Vue站点,阅读完本文,可以识别出Webpack打包的Vue站点,同时可以发现该Vue站点的路由。 成果而言:可能可以发现未授权访问。 识别Vue 识别出Webpack打包的Vue站…...

主数据管理是数字化转型成功的基石——江淮汽车案例分享
汽车行业数字化转型的背景 在新冠疫情导火索的影响下,经济全球化政治基础逐渐动摇。作为全球最大的汽车市场,我国的汽车市场逐渐由增量转为存量市场。 在数字化改革大背景下,随着工业4.0时代的到来,江淮汽车集团力争实现十四五数…...
----加密Encryption (CSFLE))
【Spring连载】使用Spring Data访问 MongoDB(十一)----加密Encryption (CSFLE)
[TOC](【Spring连载】使用Spring Data访问 MongoDB(十一)----加密Encryption (CSFLE)) 一级目录 二级目录 三级目录...
【postgresql】数据表id自增与python sqlachemy结合实例
需求: postgresql实现一个建表语句,表名:student,字段id,name,age, 要求:每次添加一个数据id会自动增加1 在PostgreSQL中,您可以使用SERIAL或BIGSERIAL数据类型来自动生成主键ID。以下是一个创建名为stude…...

什么是索引?在 MySQL 中有哪些类型的索引?它们各自的优势和劣势是什么?
什么是索引?在 MySQL 中有哪些类型的索引?它们各自的优势和劣势是什么? 索引是数据库中用于帮助快速查询数据的一种数据结构。在 MySQL 中,索引可以显著提高查询性能,因为它允许数据库系统不必扫描整个表来找到相关数据…...

Docker安装与基础知识
目录 -----------------Docker 概述--------------------------- 容器化越来越受欢迎,因为容器是: Docker与虚拟机的区别: Docker核心概念: ●镜像 ●容器 ●仓库 -----------------安装 Docker--------------------------…...
搭建Facebook直播网络对IP有要求吗?
在当今数字化时代,Facebook直播已经成为了一种极具吸引力的社交形式,为个人和企业提供了与观众直接互动的机会,成为推广产品、分享经验、建立品牌形象的重要途径。然而,对于许多人来说,搭建一个稳定、高质量的Facebook…...
Qt开发:MAC安装qt、qtcreate(配置桌面应用开发环境)
安装qt-creator brew install qt-creator安装qt brew install qt查看qt安装路径 brew info qtzhbbindembp ~ % brew info qt > qt: stable 6.6.1 (bottled), HEAD Cross-platform application and UI framework https://www.qt.io/ /opt/homebrew/Cellar/qt/6…...

python学习网站
Python系列干货之——Python与设计模式 - 知乎 Python之23种设计模式_23种设计模式 python-CSDN博客 用python实现设计模式 — python-golang-web-guide 0.1 文档 python设计模式_Python六大原则,23种设计模式 - 掘金 Python 常用设计模式 Python入门 类class提…...

编程笔记 Golang基础 033 反射的类型与种类
编程笔记 Golang基础 033 反射的类型与种类 一、反射的类型和种类二、切片与反射三、集合与反射四、结构体与反射五、指针与反射六、函数与反射小结 反射机制的作用范围涵盖了几乎所有的类型和值的操作层面,它极大地增强了Go语言在运行时对于自身类型系统的探索和操…...
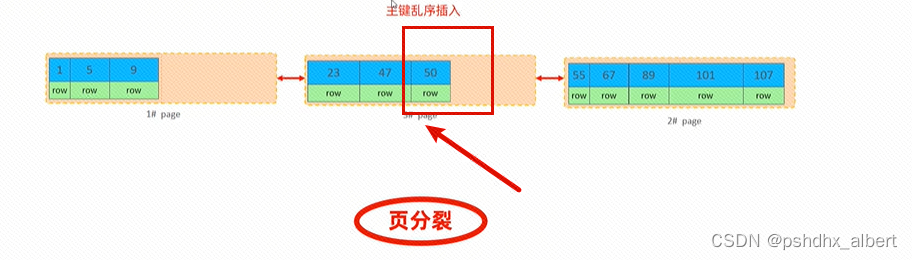
MySQL进阶篇2-索引的创建和使用以及SQL的性能优化
索引 mkdir mysql tar -xvf mysqlxxxxx.tar -c myql cd mysql rpm -ivh .....rpm yum install openssl-devel systemctl start mysqld gerp temporary password /var/log/mysqld.log mysql -u root -p mysql> show variables like validate_password.% set glob…...

基于SVM的功率分类,基于支持向量机SVM的功率分类识别,Libsvm工具箱详解
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 完整代码和数据下载链接:基于SVM的功率分类,基于支持向量机SVM的功率分类识别资源-CSDN文库 https://download.csdn.net/download/abc991835105/88862836 SVM应用实例, 基于…...
【IO流】FileWrite字符输出流
FileWrite字符输出流 1. 概述2. 作用3. 方法4. 细节5. 代码示例6. 注意事项 1. 概述 java.io.FileWriter 类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。 FileWriter 是用于写入字符数据到文件的字符输出流。 2. 作用 写入字符数据:…...
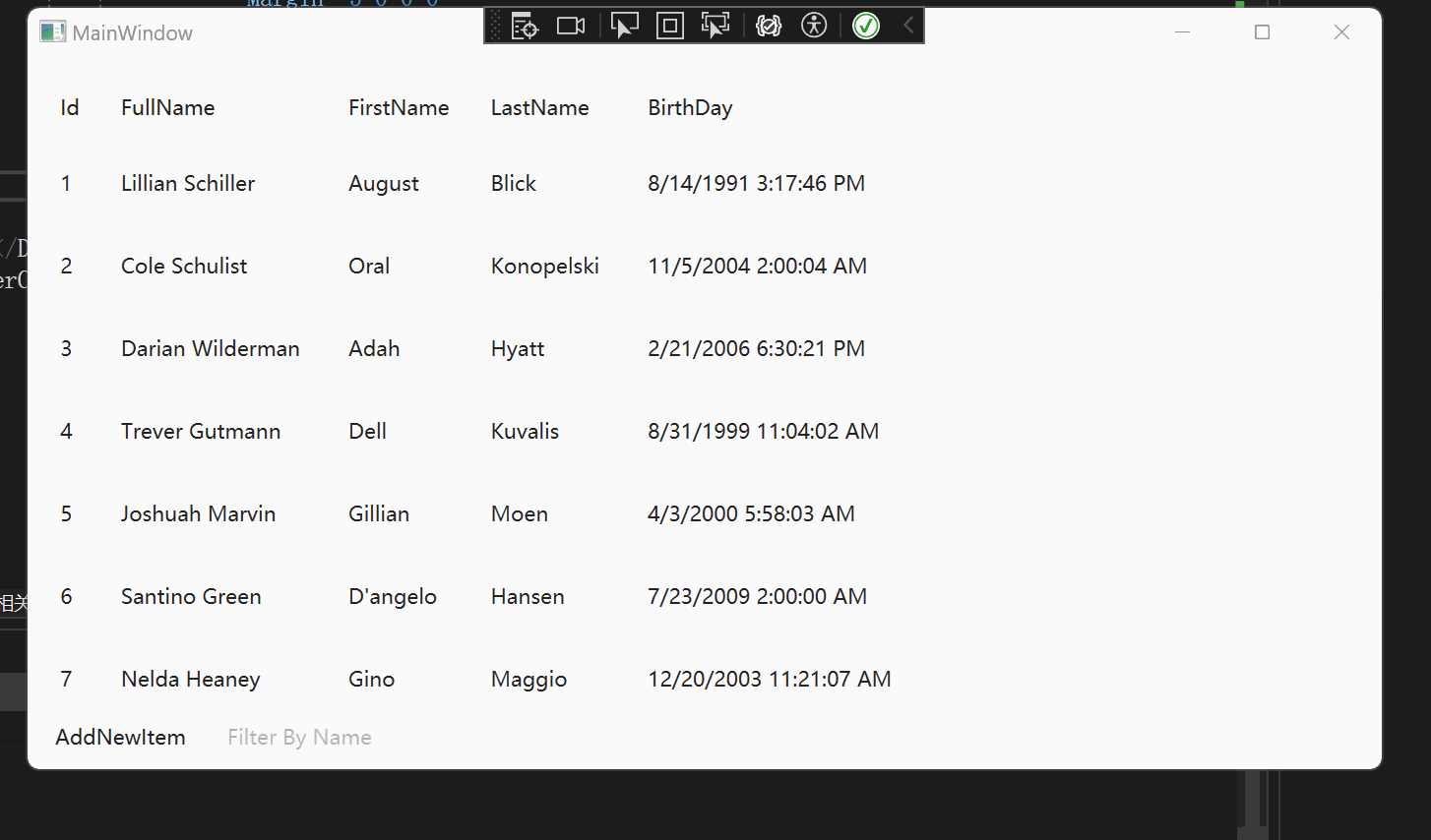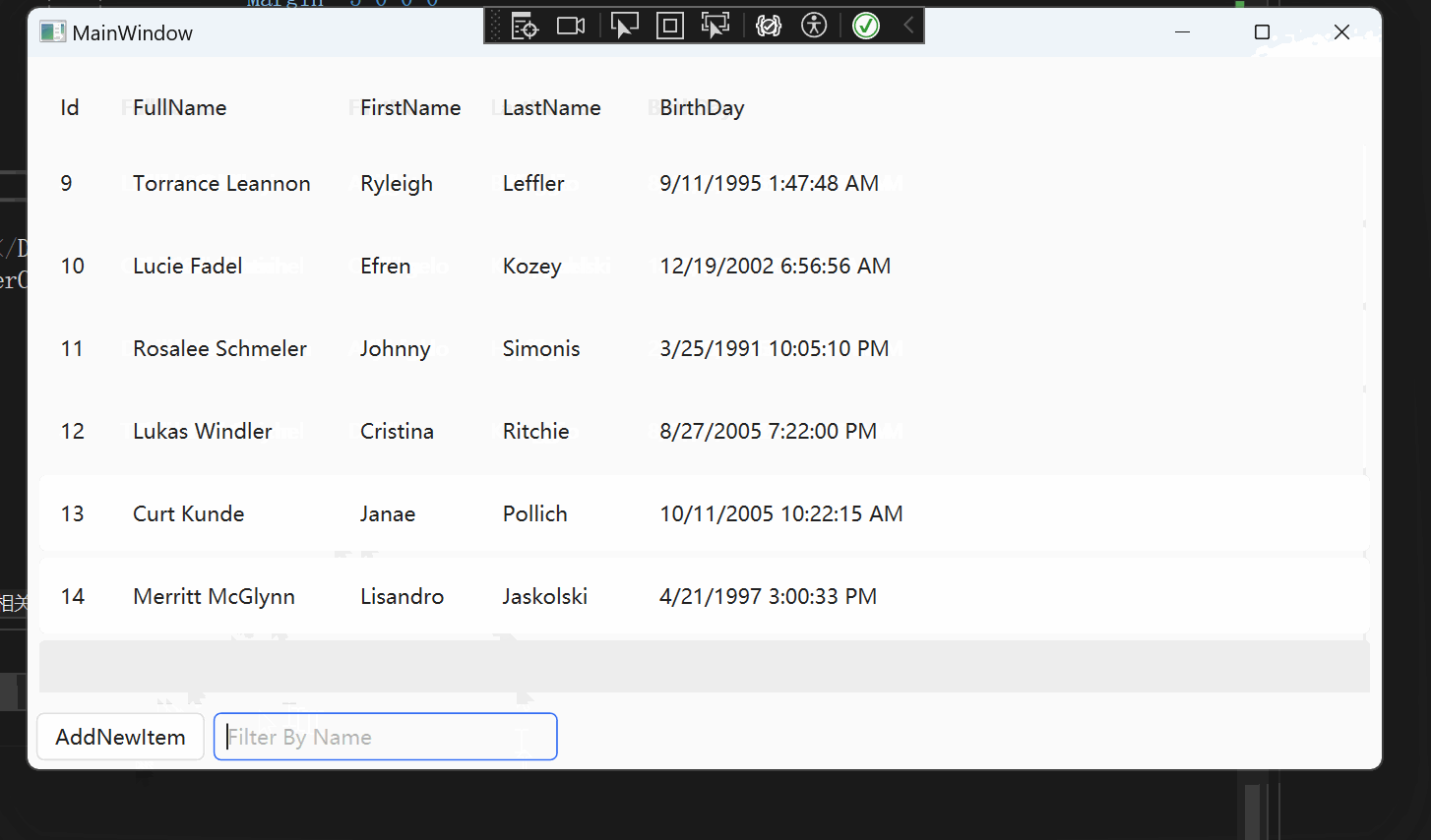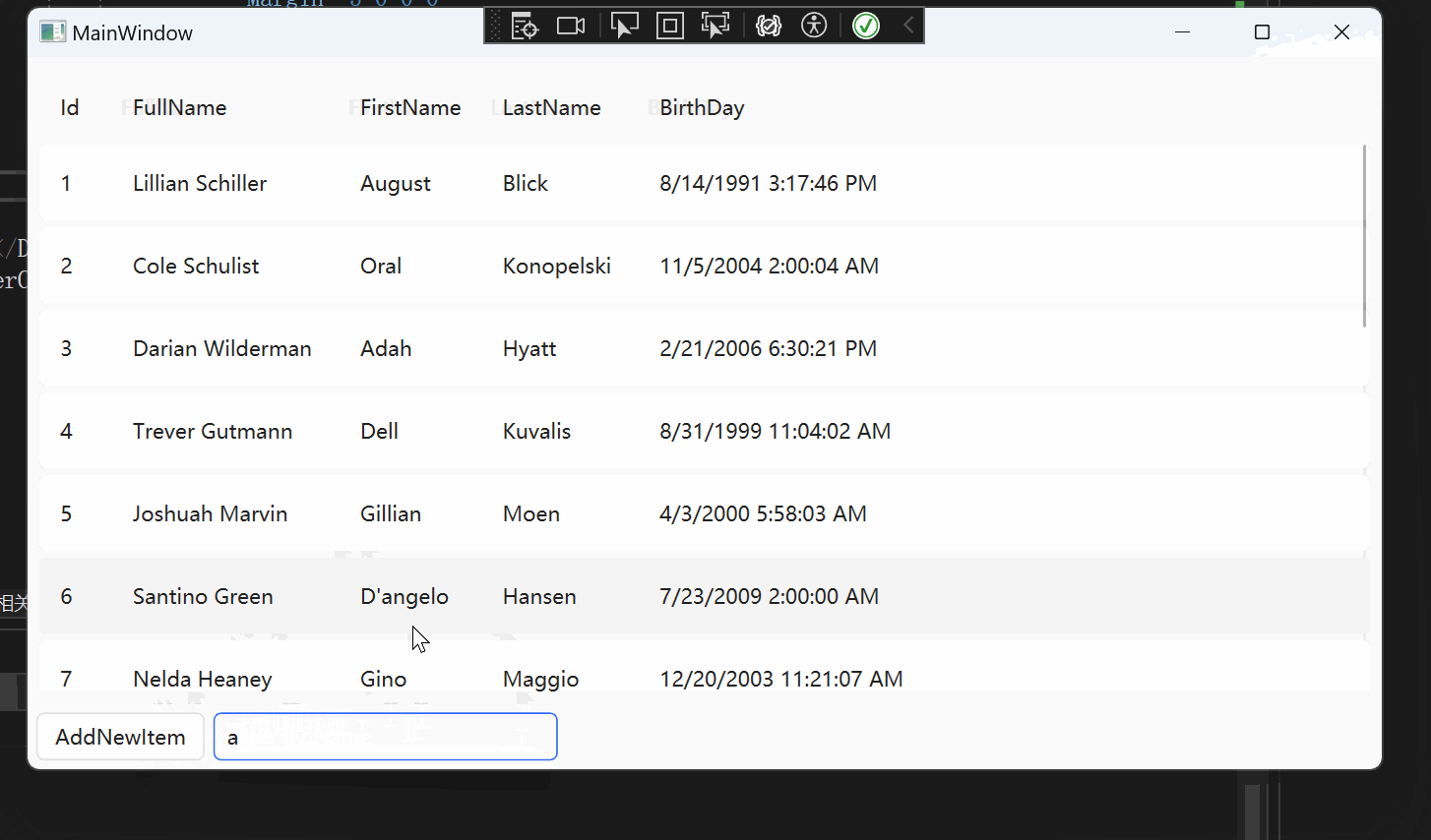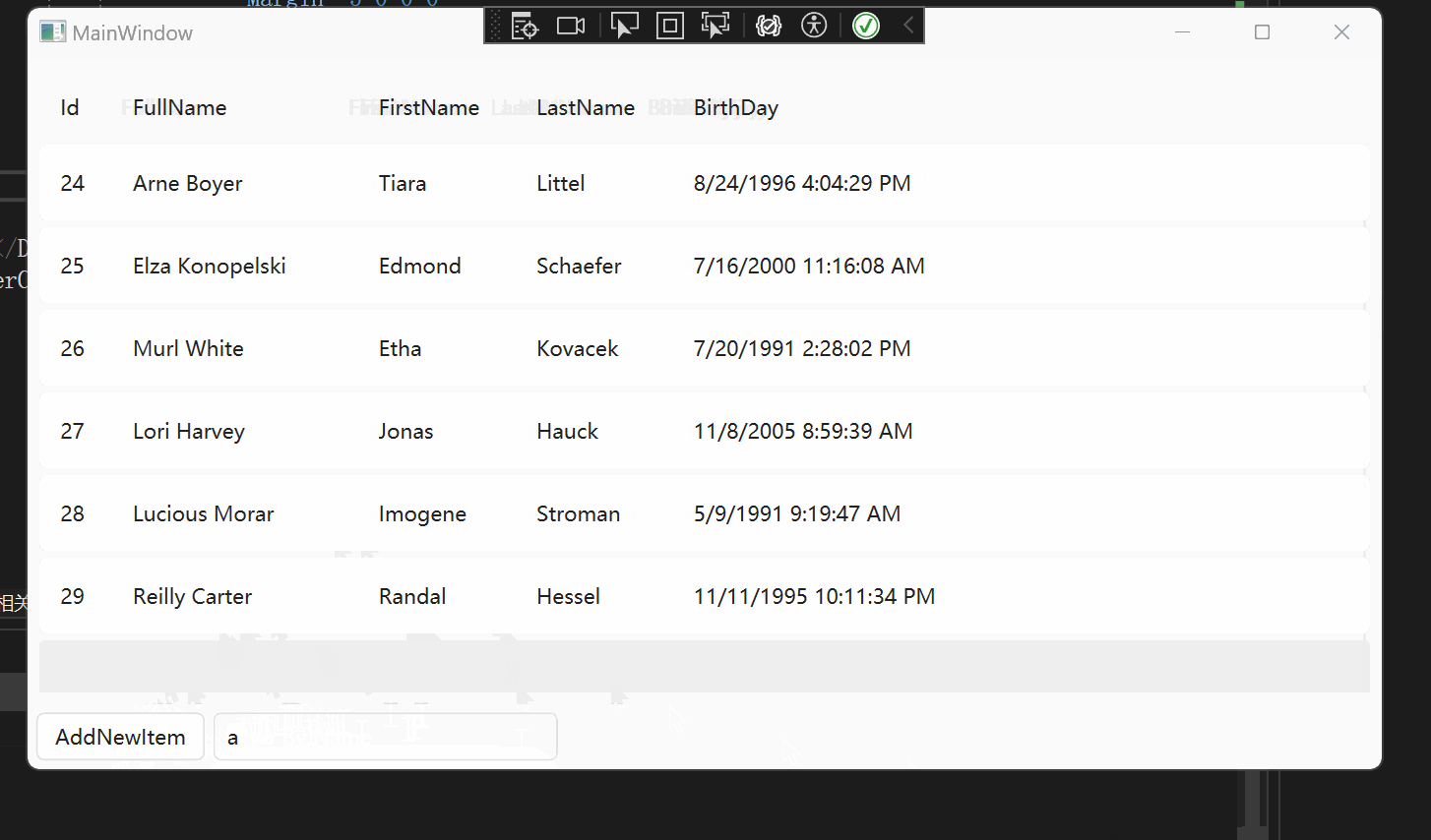
WPF 【十月的寒流】学习笔记(1):DataGrid过滤
文章目录 相关链接代码仓库前言环境DataGrid 数据筛选项目配置使用原理主要代码(详细代码可以看我的GitHub仓库)Models.PersonDataGirdViewDataGridViewModel 实现效果 DataGrid直接绑定CollectionViewxamlViewModel 总结 相关链接 十月的寒流 在 WPF 中…...

当Vue项目启动后,通过IP地址方式在相同网络段的其他电脑上无法访问前端页面?
当Vue项目启动后,通过IP地址方式在相同网络段的其他电脑上无法访问前端页面,可能是由以下几个原因造成的: 服务监听地址:默认情况下,许多开发服务器(如Vue CLI的vue-cli-service serve)只监听lo…...

native sql -ABAP开发从入门到精通笔记
Native SQL SQL概要 OPEN SQL读取数据 Select Select <lines> <columns>... Select signle <cols>.... where. 列去重数据 Select distinct <cols>... where... 当取多条数据时,select结果会保存到内表中。 Select ... into...语句的结果不…...

C++完美转发【gpt】
提问:用极其通俗易懂的文字解释C的完美转发 ChatGPT 好的,让我用非常通俗易懂的方式解释一下 C 中的完美转发。 假设你有一个房子(函数),你想把家具(参数)从一个房间(函数&#x…...

C++之类和对象(2)
目录 1.类的6个默认成员函数 2. 构造函数 2.1 概念 2.2 特性 3.析构函数 3.1 概念 3.2 特性 4. 拷贝构造函数 4.1 概念 4.2 特征 5.赋值运算符重载 5.1 运算符重载 5.2 赋值运算符重载 2. 赋值运算符只能重载成类的成员函数不能重载成全局函数 3. 用户没有显式实现时&…...
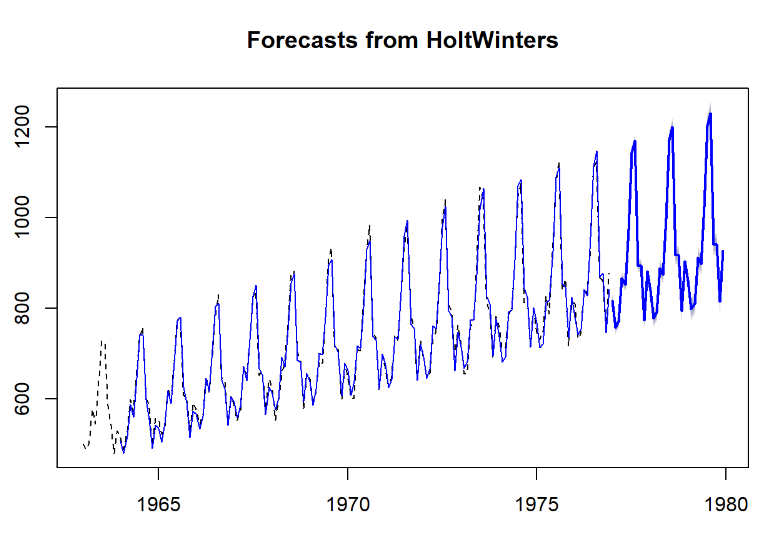
时间序列分析实战(四):Holt-Winters建模及预测
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972 个人介绍: 研一|统计学|干货分享 擅长Python、Matlab、R等主流编程软件 累计十余项国家级比赛奖项,参与研究经费10w、40w级横向 文…...
)
PLINK实战:用--indep-pairwise和R脚本搞定GWAS杂合率质控(附完整代码)
PLINK实战指南:GWAS杂合率质控全流程解析与代码实现 在基因组关联分析(GWAS)中,数据质量直接影响研究结果的可靠性。杂合率异常可能暗示样本污染或近亲繁殖等问题,而PLINK作为GWAS分析的瑞士军刀,配合R语言的数据处理能力…...
)
机械转行自学嵌入式,我用正点原子IMX6ULL复刻了一个智能仓储项目(附完整代码)
机械工程师的嵌入式转型之路:基于IMX6ULL的智能仓储实战 记得第一次拿起电烙铁时,我的手抖得像筛糠——这和我熟悉的游标卡尺、数控机床完全是两个世界。作为在汽车制造厂做了五年机械设计的工程师,我从未想过有一天会对着电路板调试UART通信…...

30款高效Adobe Illustrator脚本合集:一键实现设计自动化
30款高效Adobe Illustrator脚本合集:一键实现设计自动化 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中的重复性操作消耗大量时间而烦恼吗&a…...

VSCode玩转Arduino:手把手解决‘未定义Serial’和头文件找不到的坑
VSCode玩转Arduino:手把手解决‘未定义Serial’和头文件找不到的坑 当你从Arduino官方IDE转向VSCode时,可能会遇到一个令人抓狂的现象:代码明明能编译通过,但编辑器里却满是红色波浪线。这就像穿着正装参加重要会议,却…...

别再死磕毕业论文!Paperxie 智能写作:大四生的「论文通关秘籍」
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/期刊论文https://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 大四下学期的关键词,一半是毕业旅行、散伙饭,另一半却是改到崩溃的论文初稿、导师的红色…...
)
用ZYNQ FPGA和NVMe盘,我手搓了一个2GB/s的国产高速存储盒(附详细配置与踩坑记录)
从零构建2GB/s极速存储盒:ZYNQ FPGA与NVMe实战全解析 当一块M.2 NVMe固态硬盘在消费级主板上轻松突破3GB/s时,你可能不会想到——用国产FPGA搭建同等性能的存储系统,需要跨越多少技术鸿沟。去年冬天,我的NAS系统因频繁的4K视频编辑…...

从PyTorch到ONNX Runtime:跨平台模型部署实战指南
1. 为什么需要从PyTorch转向ONNX Runtime 当你费尽心思训练好一个PyTorch模型后,准备把它部署到生产环境时,往往会遇到几个头疼的问题。首先是环境依赖,PyTorch本身加上CUDA等组件动辄几个GB,在资源受限的边缘设备上根本装不下。其…...

CILQR:自动驾驶约束优化的突破性算法实现指南 [特殊字符]
CILQR:自动驾驶约束优化的突破性算法实现指南 🚗 【免费下载链接】Constrained_ILQR 项目地址: https://gitcode.com/gh_mirrors/co/Constrained_ILQR 在自动驾驶技术快速发展的今天,约束迭代线性二次调节器(Constrained …...

如何下载huggingface数据
使用 Hugging Face 新版 CLI 工具 hf 下载数据集(国内镜像加速版) 在进行机器学习和深度学习项目时,我们经常需要从 Hugging Face Hub 下载公开的数据集。然而,由于网络原因,国内用户直接访问 Hugging Face 官方源时往…...

Amazon速卖通双平台卖家必看:在线图片翻译工具帮你批量搞定多语言商品上架
【一、同时做Amazon和速卖通,商品图翻译的麻烦翻了一倍】 很多跨境电商卖家同时经营Amazon和速卖通两个平台。两个平台的买家群体不同、市场定位不同,但有一个共同点:商品图上的文字需要翻译成目标语言,否则海外买家看不懂。 问题…...