pyspark分布式部署随机森林算法
前言
分布式算法的文章我早就想写了,但是一直比较忙,没有写,最近一个项目又用到了,就记录一下运用Spark部署机器学习分类算法-随机森林的记录过程,写了一个demo。
基于pyspark的随机森林算法预测客户
本次实验采用的数据集链接:https://pan.baidu.com/s/13blFf0VC3VcqRTMkniIPTA
提取码:DJNB
数据集说明
某运营商提供了不同用户3个月的使用信息,共34个特征,1个标签列,其中存在一定的重复值、缺失值与异常值。各个特征的说明如下:
MONTH_ID 月份
USER_ID 用户id
INNET_MONT 在网时长
IS_AGREE 是否合约有效客户
AGREE_EXP_DATE 合约计划到期时间
CREDIT_LEVEL 信用等级
VIP_LVL vip等级
ACCT_FEE 本月费用(元)
CALL_DURA 通话时长(秒)
NO_ROAM_LOCAL_CALL_DURA 本地通话时长(秒)
NO_ROAM_GN_LONG_CALL_DURA 国内长途通话时长(秒)
GN_ROAM_CALL_DURA 国内漫游通话时长(秒)
CDR_NUM 通话次数(次)
NO_ROAM_CDR_NUM 非漫游通话次数(次)
NO_ROAM_LOCAL_CDR_NUM 本地通话次数(次)
NO_ROAM_GN_LONG_CDR_NUM 国内长途通话次数(次)
GN_ROAM_CDR_NUM 国内漫游通话次数(次)
P2P_SMS_CNT_UP 短信发送数(条)
TOTAL_FLUX 上网流量(MB)
LOCAL_FLUX 本地非漫游上网流量(MB)
GN_ROAM_FLUX 国内漫游上网流量(MB)
CALL_DAYS 有通话天数
CALLING_DAYS 有主叫天数
CALLED_DAYS 有被叫天数
CALL_RING 语音呼叫圈
CALLING_RING 主叫呼叫圈
CALLED_RING 被叫呼叫圈
CUST_SEX 性别
CERT_AGE 年龄
CONSTELLATION_DESC 星座
MANU_NAME 手机品牌名称
MODEL_NAME 手机型号名称
OS_DESC 操作系统描述
TERM_TYPE 硬件系统类型(0=无法区分,4=4g,3=dg,2=2g)
IS_LOST 用户在3月中是否流失标记(1=是,0=否),1月和2月值为空(标签)
数据字段打印
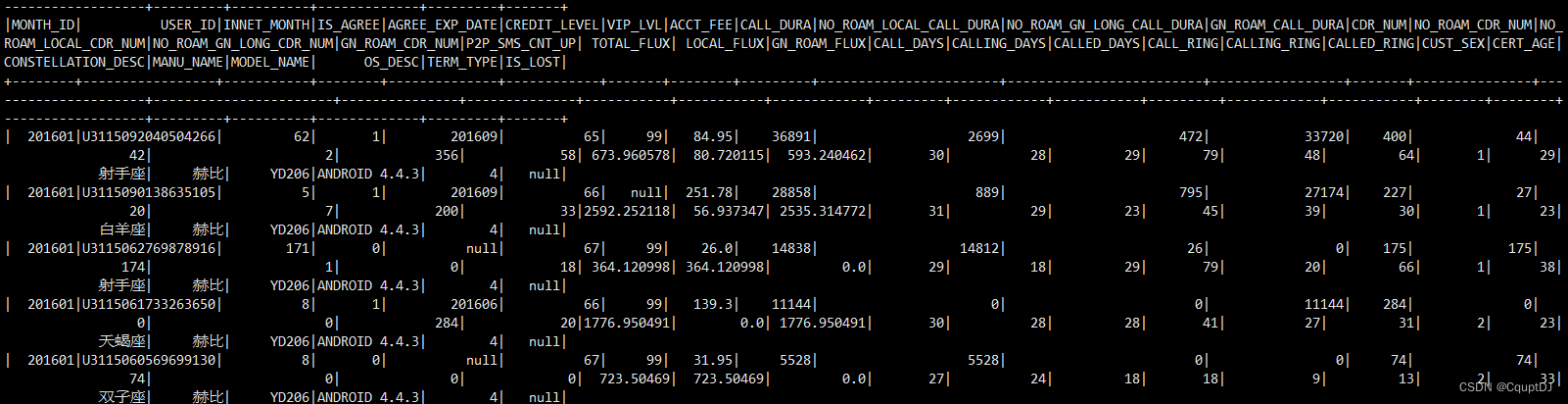
将数据集放到hadoop的HDFS中,通过Saprk读取HDFS文件里面的CSV格式的数据集,通过hadoop命令上传本地数据集到HDFS:
hadoop fs -put ./USER_INFO_M.csv /data/test/USER_INFO_M.csv
查看HDFS中的数据集CSV文件:
hadoop fs -ls /data/test

Spark中搭建分布式随机森林模型
从上面的数据集可以看到,数据是一个二分类数据,IS_LOST就是需要预测的标签,所以只需要构建一个随机森林二分类模型就可以了。Spark中提供了用于机器学习算法的库MLlib,这个库里面包含了许多机器学习算法,监督学习和无监督学习算法都有,例如线性回归、随机森林、GBDT、K-means等等(没有sklearn中提供的算法多),但是和sklearn中的随机森林模型构建有区别的是spark中程序底层是基于RDD弹性分布式计算单元,所以基于RDD的DataFrame数据结构和python中的DataFrame结构不一样,写法就不一样,python程序写的随机森林算法是不能直接在Spark中运行的,我们需要按照Spark中的写法来实现随机森林模型的构建,直接看代码:
from pyspark.sql import SparkSession
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml import Pipeline
from pyspark.sql.functions import col
import timestart_time = time.time()
# 创建SparkSession
spark = SparkSession.builder.appName("RandomForestExample").getOrCreate()# 读取数据集,数据集放在HDFS上
data = spark.read.csv("/data/test/USER_INFO_M.csv", header=True, inferSchema=True, encoding='gbk')
print('=====================================================')
data.show()
# 去除包含缺失值的行
data = data.na.drop(subset=["IS_LOST"])
# 选择特征列和标签列
data = data.select([col for col in data.columns if col not in ['MONTH_ID', 'USER_ID','CONSTELLATION_DESC','MANU_NAME','MODEL_NAME','OS_DESC']])
label_col = "IS_LOST"
feature_cols=['CONSTELLATION_DESC','MANU_NAME','MODEL_NAME','OS_DESC']data = data.fillna(-1)# 创建特征向量列
assembler = VectorAssembler(inputCols=[col for col in data.columns if col not in ["IS_LOST"]], outputCol="features")
data = assembler.transform(data)# 选择特征向量列和标签列
data = data.select("features", label_col)# 将数据集分为训练集和测试集
(trainingData, testData) = data.randomSplit([0.8, 0.2])# 创建随机森林分类器
rf = RandomForestClassifier(labelCol=label_col, featuresCol="features")# 训练模型
model = rf.fit(trainingData)# 在测试集上进行预测
predictions = model.transform(testData)# 评估模型
evaluator = MulticlassClassificationEvaluator(labelCol=label_col, predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)# 打印准确率
print("测试集准确率为: {:.2f}".format(accuracy))
end_time = time.time()
print("代码运行时间: {:.2f}".format(end_time - start_time))
# 关闭SparkSession
spark.stop()
上面是通过python代码构建的Spark中的随机森林模型,Spark支持scala、java、R和python语言,python最简洁,所以直接用pyspark进行程序实现。将上面的代码放到自己的路径下,然后通过spark-submit命令提交.py文件运行即可:
./spark-submit --master yarn --deploy-mode client --num-executors 4 /data/rf/spark_m.py
提交:

拓展:Spark中还支持提交Python环境,而不需要每个spark分布式集群节点都安装适配的python环境,spark-submit命令可以支持将python解释器连同整个配置好了的环境都提交到集群上面然后下发给其他节点,命令如下:
./spark-submit \--master yarn \--deploy-mode client\--num-executors 4\--queue default \--verbose \--conf spark.pyspark.driver.python=/anaconda/bin/python \--conf spark.pyspark.python=/anaconda/bin/python \/test.py
其中spark.pyspark.python和spark.pyspark.driver.python两个参数就是配置提交机器的python环境的路径,还可以通过将python环境打包放到HDFS路径下,Spark直接读取HDFS中的python环境包。
模型运行结果
将数据集按照2-8分为测试集和训练集,在测试集上的预测准确率为97%,运行时间80s。

同时登录集群查看提交的Spark任务运行情况,访问http://localhost:8088/cluster查看如下:
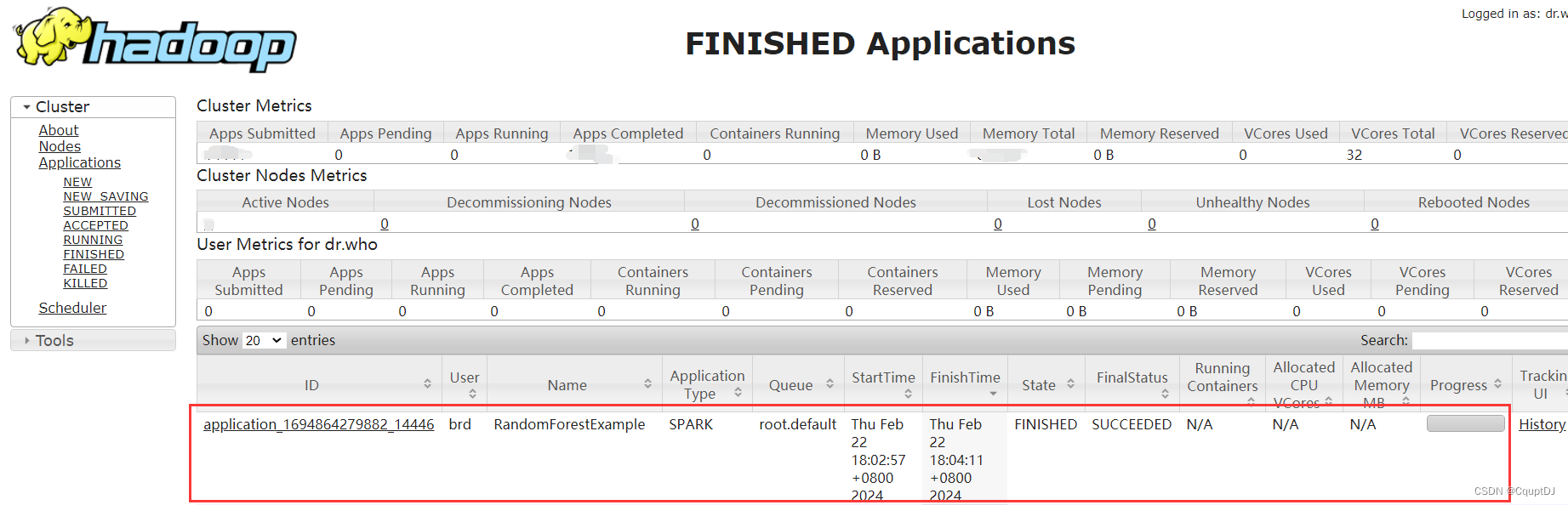
可以看到,RandomForestExample任务就是我们创建的任务,运行完成了,成功!
写在最后
在大规模数据的情况下如果需要用机器学习算法,Spark是一个很好的选择,可以大大提升任务的运行速度,工业环境中效率往往是最需要的,Spark可以解决我们的分布式算法部署需求。
本人才疏学浅,如果有不对的地方请指证!
相关文章:
pyspark分布式部署随机森林算法
前言 分布式算法的文章我早就想写了,但是一直比较忙,没有写,最近一个项目又用到了,就记录一下运用Spark部署机器学习分类算法-随机森林的记录过程,写了一个demo。 基于pyspark的随机森林算法预测客户 本次实验采用的…...
【Python笔记-设计模式】中介者模式
一、说明 中介者模式是一种行为设计模式,减少对象之间混乱无序的依赖关系。该模式会限制对象之间的直接交互,迫使它们通过一个中介者对象进行合作。 (一) 解决问题 降低系统中对象之间的直接通信,将复杂的交互转化为通过中介者进行的间接交…...
)
大语言模型构建的主要四个阶段(各阶段使用的算法、数据、难点以及实践经验)
大语言模型构建通常包含以下四个主要阶段:预训练、有监督微调、奖励建模和强化学习,简要介绍各阶段使用的算法、数据、难点以及实践经验。 预训练 需要利用包含数千亿甚至数万亿 单词的训练数据,并借助由数千块高性能 GPU 和高速网络组成的…...
[云原生] 二进制安装K8S(中)部署网络插件和DNS
书接上文,我们继续部署剩余的插件 一、K8s的CNI网络插件模式 2.1 k8s的三种网络模式 K8S 中 Pod 网络通信: (1)Pod 内容器与容器之间的通信 在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享…...

云端技术驾驭DAY13——Pod污点、容忍策略、Pod优先级与抢占、容器安全
往期回顾: 云端技术驾驭DAY01——云计算底层技术奥秘、云服务器磁盘技术、虚拟化管理、公有云概述 云端技术驾驭DAY02——华为云管理、云主机管理、跳板机配置、制作私有镜像模板 云端技术驾驭DAY03——云主机网站部署、web集群部署、Elasticsearch安装 云端技术驾驭…...
掌握Docker:让你的应用轻松部署和管理
文章目录 一、引言(为什么要学习docker?)1.1 环境不一致1.2 隔离性1.3 弹性伸缩1.4 学习成本 二、Docker介绍2.1 Docker的由来2.2 什么是Docker2.3 为什么要用Docker2.3.1 虚拟机2.3.2 Linux容器 2.4 Docker与传统虚拟机的区别2.5 Docker的思…...

5G-A,未来已来
目前,全国首个5G-A规模组网示范完成。这项由北京联通携手华为共同打造的示范项目,实现了北京市中心金融街、历史建筑长话大楼、大型综合性体育场北京工人体育场三个重点场景的连片覆盖。 实际路测结果显示,5G-A用户下行峰值速率达到10Gbps&am…...

智慧公厕让社区生活更美好
随着科技的迅猛发展,城市管理、城市服务均使用科技化的手段进行升级改造,社区生活更美好赋予全新的智慧效能,其中智慧公厕也成为了城市环卫设施的新宠。智慧公厕以物联网、互联网、大数据、云计算、5G通信、自动化控制等技术为核心࿰…...

Apache软件基金会的孵化标准和毕业标准
Apache软件基金会的孵化标准和毕业标准是一个项目成功的重要衡量指标。这些标准关注项目的多个方面,包括开放性、合作性、共建性、透明性、技术可行性、社区建设以及用户基础等。在孵化阶段,Apache软件基金会主要关注项目的开放性和合作性。首先…...
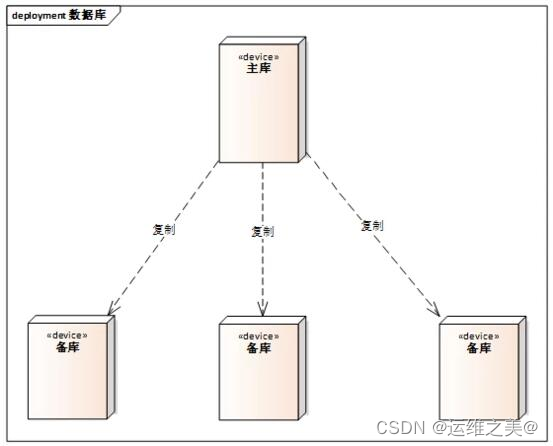
什么是高可用架构
一、什么是高可用 在运维中,经常听到高可用,那么什么是高可用架构呢?通俗点讲,高可用就是在服务故障,节点宕机的情况下,业务能够保证不中断,服务正常运行。 举个例子,支付宝&#…...

【Vuforia+Unity】AR04-地面、桌面平面识别功能(Ground Plane Target)
不论你是否曾有过相关经验,只要跟随本文的步骤,你就可以成功地创建你自己的AR应用。 官方教程Ground Plane in Unity | Vuforia Library 这个功能很棒,但是要求也很不友好,只能支持部分移动设备,具体清单如下: 01.Vuforia的地面识别功能仅支持的设备清单: Recommended…...

【Git】解决‘每次初始化一个新仓库时,都需要执行git config --global --add safe.directory命令‘
问题 这个命令是用来将一个安全目录添加到全局的 Git 配置中。但每次克隆一个仓库或者新建一个仓库,并且对该仓库进行操作时,都需要执行该命令,十分麻烦! 这是因为,Git 近期进行了版本升级,添加了新的目录…...
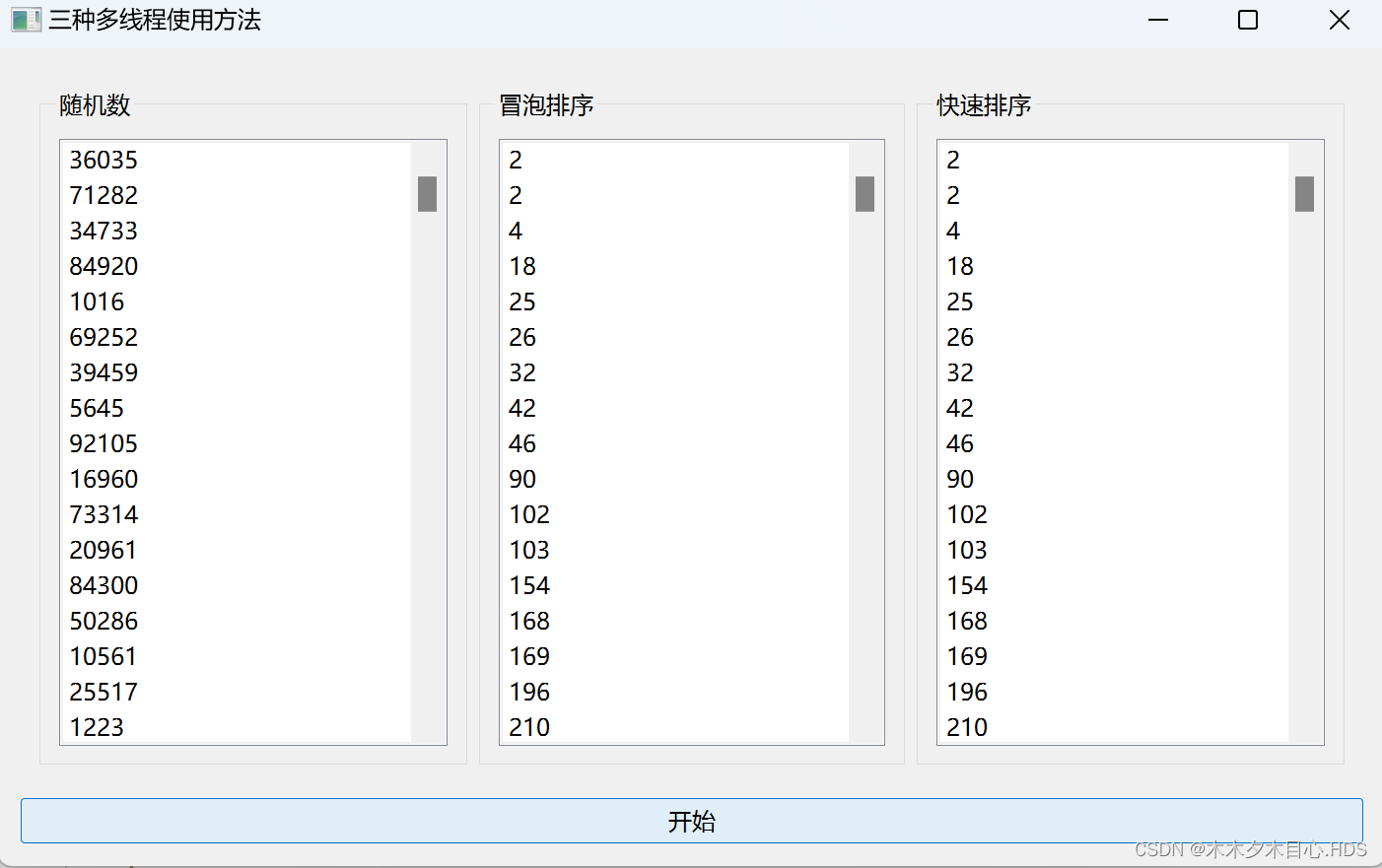
Qt的QThread、QRunnable和QThreadPool的使用
1.相关描述 随机生产1000个数字,然后进行冒泡排序与快速排序。随机生成类继承QThread类、冒泡排序使用moveToThread方法添加到一个线程中、快速排序类继承QRunnable类,添加到线程池中进行排序。 2.相关界面 3.相关代码 widget.cpp #include "widget…...
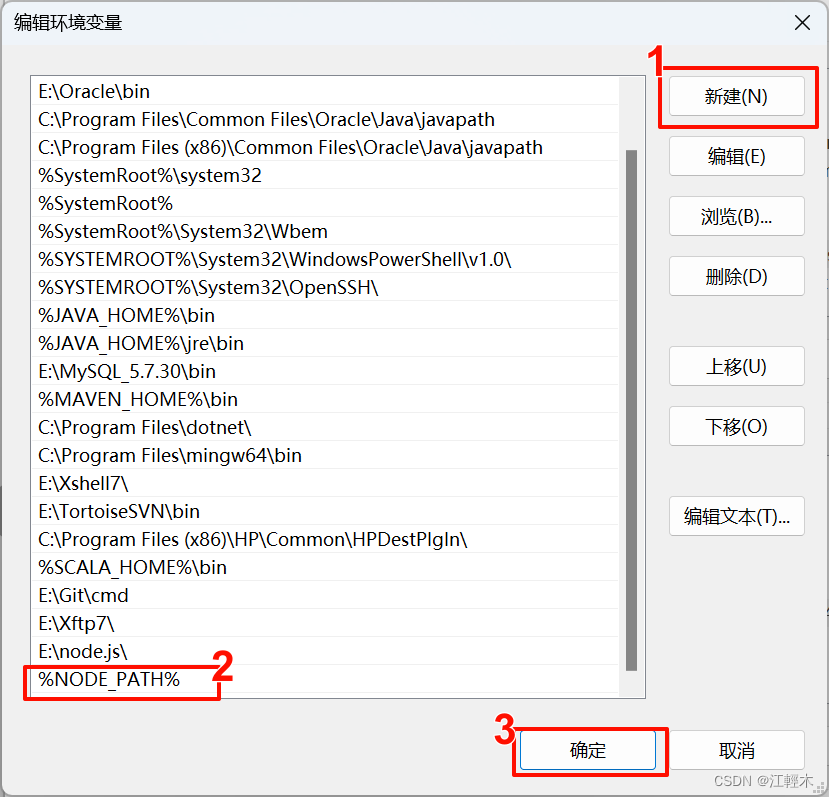
windows安装部署node.js并搭建Vue项目
一、官网下载安装包 官网地址:https://nodejs.org/zh-cn/download/ 二、安装程序 1、安装过程 如果有C/C编程的需求,勾选一下下图所示的部分,没有的话除了选择一下node.js安装路径,直接一路next 2、测试安装是否成功 【winR】…...

【计算机】本科考研还是就业?
其实现在很多计算机专业的学生考研,也是无奈的选择 技术发展日新月异,而在本科阶段,大家学着落后的技术,出来找工作自然会碰壁。而且现在用人单位的门槛越来越高,学历默认研究生起步,面试一般都是三轮起步…...
ChatGPT调教指南 | 咒语指南 | Prompts提示词教程(三)
在人工智能成为我们日常互动中无处不在的一部分的时代,与大型语言模型(llm)有效沟通的能力是无价的。“良好提示的26条原则”为优化与这些复杂系统的交互提供了全面的指导。本指南证明了人类和人工智能之间的微妙关系,强调清晰、专一和结构化的沟通方法。…...
小程序一键链接WIFI
1.小程序一键链接WIFI connectWifi: function() {var that this;//检测手机型号wx.getSystemInfo({success: function(res) {var system ;if (res.platform android) system parseInt(res.system.substr(8));if (res.platform ios) system parseInt(res.system.substr(4…...

结构体位域保存传感器数据
1、原理图分析: 8个74HC4052共用两个选通引脚,8个输入引脚,一共可以检测64个数字红外传感器。74HC4052的功能表如下,nY0表示所有Y0引脚。 S1 S0 Channel on 0 0 nY0 0 1 nY1 1 0 nY2 1 1 nY3 enum sensor_id{HS01 0, HS02, HS03, HS0…...

66-ES6:var,let,const,函数的声明方式,函数参数,剩余函数,延展操作符
1.JavaScript语言的执行流程 编译阶段:构建执行函数;执行阶段:代码依次执行 2.代码块:{ } 3.变量声明方式var 有声明提升,允许重复声明,声明函数级作用域 访问:声明后访问都是正常的&…...
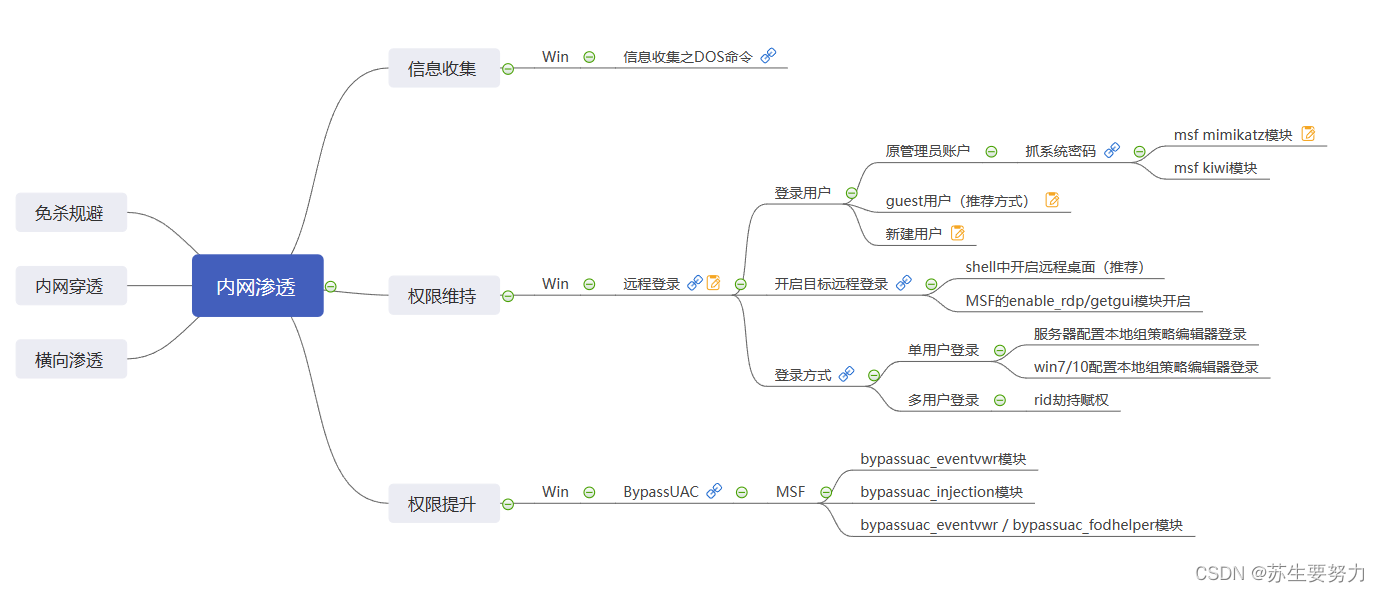
prime_series_level-1靶场详解
环境搭建 官网https://www.vulnhub.com/entry/prime-1,358/ 直接导入靶机 解题思路 arp-scan -l 确认靶机ip为192.168.236.136 也可以使用nmap扫网段 nmap -sn 192.168.236.0/24 使用nmap扫描靶机开放的端口 nmap -sS -T5 --min-rate 10000 192.168.236.136 -sC -p- …...

GPT-5.4 API 怎么低延迟调用?2026 年 5 种接入方案实测对比
上周 OpenAI 悄悄放出了 GPT-5.4,号称推理能力又上了一个台阶。我第一时间想接入到项目里试试,结果老问题又来了——官方 API 延迟高、Key 申请排队、计费规则又改了。折腾了两天,把市面上能找到的接入方案都试了一遍,今天把实测数…...

网盘直链解析工具终极指南:8大平台真实下载地址一键获取
网盘直链解析工具终极指南:8大平台真实下载地址一键获取 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

WeChatExporter:你的微信记忆守护者,一键解锁被封存的聊天时光
WeChatExporter:你的微信记忆守护者,一键解锁被封存的聊天时光 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 还记得那些深夜的长谈吗࿱…...
)
告别路由器!用美格SLM750在CentOS 7.6直连4G网络(附完整驱动编译脚本)
美格SLM750 4G模块在CentOS 7.6下的直连网络部署实战 在物联网和边缘计算场景中,传统路由器方案往往成为网络延迟和单点故障的瓶颈。本文将详细介绍如何通过美格SLM750 4G模块实现CentOS 7.6系统的直接蜂窝网络接入,这种端到端的连接方式特别适合需要低延…...
快速定位PCB上的开路和短路)
告别盲人摸象:手把手教你用TDR(时域反射技术)快速定位PCB上的开路和短路
告别盲人摸象:手把手教你用TDR(时域反射技术)快速定位PCB上的开路和短路 在电子工程领域,PCB故障排查常常像一场没有地图的寻宝游戏。当一块价值不菲的多层板出现信号传输异常时,传统方法往往需要工程师像"盲人摸…...
)
深入理解DSP28335的PWM模块:如何用EPWM实现三相电机控制(附代码分析)
DSP28335 EPWM模块实战:三相电机SPWM控制全解析 在工业驱动和电力电子领域,精确的PWM信号生成是电机控制的核心技术。TI的DSP28335凭借其增强型PWM(EPWM)模块,为三相逆变器控制提供了硬件级的解决方案。本文将带您深入…...

Phi-3.5-mini-instruct部署案例:开发者如何用单卡A10部署高性能轻量模型
Phi-3.5-mini-instruct部署案例:开发者如何用单卡A10部署高性能轻量模型 1. 模型简介 Phi-3.5-mini-instruct 是一个轻量级的高性能开放模型,属于Phi-3模型家族。这个模型基于精心筛选的高质量数据集构建,特别注重推理密集型任务的数据处理…...

Finatra Thrift服务构建:高并发RPC服务的终极解决方案
Finatra Thrift服务构建:高并发RPC服务的终极解决方案 【免费下载链接】finatra Fast, testable, Scala services built on TwitterServer and Finagle 项目地址: https://gitcode.com/gh_mirrors/fi/finatra Finatra是基于TwitterServer和Finagle构建的快速…...

高效视频修复指南:使用Untrunc专业恢复损坏的MP4/MOV文件
高效视频修复指南:使用Untrunc专业恢复损坏的MP4/MOV文件 【免费下载链接】untrunc Restore a truncated mp4/mov. Improved version of ponchio/untrunc 项目地址: https://gitcode.com/gh_mirrors/un/untrunc 当珍贵的视频文件因意外中断而损坏时ÿ…...
✅)
计算机毕业设计:Python农产品电商数据挖掘与推荐系统 Flask框架 矩阵分解 数据分析 可视化 协同过滤推荐算法 深度学习(建议收藏)✅
1、项目介绍 技术栈 采用 Python 语言开发,基于 Flask 框架搭建后端服务,通过 requests 爬虫采集农产品数据,运用矩阵分解算法(带偏置的协同过滤推荐算法)结合随机梯度下降优化模型,前端使用 Echarts 实现…...