Gemma
Gemma
- 1.使用
- 2.RAG
- 3.LoRA
- 3.1LoRA分类任务
- 3.2LoRA中文建模任务
1.使用
首先是去HF下载模型,但一直下载不了,所以去了HF镜像网站,下载gemma需要HF的Token,按照步骤就可以下载。代码主要是Kaggle论坛里面的分享内容。
huggingface-cli download --token hf_XXX --resume-download google/gemma-7b --local-dir gemma-7b-mirror
这里我有时是2b有时是7b,换着用。
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("D:/Gemma/gemma-2b-int-mirror2")
Gemma = AutoModelForCausalLM.from_pretrained("D:/Gemma/gemma-2b-int-mirror2")
def answer_the_question(question):input_ids = tokenizer(question, return_tensors="pt")generated_text = Gemma.generate(**input_ids,max_length=256)answer = tokenizer.decode(generated_text[0], skip_special_tokens=True)return answer
question = "给我写一首优美的诗歌?"
answer = answer_the_question(question)
print(answer)
2.RAG
参考
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
##2.1 根据question检索sentence chunk
import os
def get_all_pdfs(directory):pdf_files = []for root, dirs, files in os.walk(directory):for file in files:if file.endswith(".pdf"):pdf_files.append(os.path.join(root, file))return pdf_filesclass RAG:def __init__(self, num_retrieved_docs=5, pdf_folder_path='D:/Gemma/PDF'):pdf_files = get_all_pdfs(pdf_folder_path)print("Documents used", pdf_files)loaders = [PyPDFLoader(pdf_file) for pdf_file in pdf_files]all_documents = []for loader in loaders:raw_documents = loader.load()text_splitter = CharacterTextSplitter(separator="\n\n",chunk_size=10,chunk_overlap=1,# length_function=len,)documents = text_splitter.split_documents(raw_documents)all_documents.extend(documents)embeddings = HuggingFaceEmbeddings(model_name="D:/Projects/model/m3e-base") self.db = FAISS.from_documents(all_documents, embeddings)self.retriever = self.db.as_retriever(search_kwargs={"k": num_retrieved_docs})def search(self, query):docs = self.retriever.get_relevant_documents(query)return docs
retriever = RAG()
##2.2根据sentence chunk和question去回答
class Assistant:def __init__(self):self.tokenizer = AutoTokenizer.from_pretrained("D:/Gemma/gemma-2b-int-mirror2")self.Gemma = AutoModelForCausalLM.from_pretrained("D:/Gemma/gemma-2b-int-mirror2")def create_prompt(self, query, retrieved_info):prompt = f"""你是人工智能助手,需要根据Relevant information里面的相关内容回答用户的Instruction,其中相关信息如下:Instruction: {query}Relevant information: {retrieved_info}Output:"""print(prompt)return promptdef reply(self, query, retrieved_info):prompt = self.create_prompt(query, retrieved_info)input_ids = self.tokenizer(query, return_tensors="pt").input_ids# Generate text with a focus on factual responsesgenerated_text = self.Gemma.generate(input_ids,do_sample=True,max_length=500,temperature=0.7, # Adjust temperature according to the task, for code generation it can be 0.9)# Decode and return the answeranswer = self.tokenizer.decode(generated_text[0], skip_special_tokens=True)return answer
chatbot = Assistant()
## 2.3开始使用RAG
def generate_reply(query):related_docs = retriever.search(query)#print('related docs', related_docs)reply = chatbot.reply(query, related_docs)return reply
reply = generate_reply("存在的不足及后续的优化工作")
for s in reply.split('\n'):print(s)
3.LoRA
3.1LoRA分类任务
参考
使用nlp-getting-started数据集训练模型做二分类任务。首先拿到源model
from datasets import load_dataset
from transformers import AutoTokenizer,AutoModelForSequenceClassification, DataCollatorWithPadding, Trainer, TrainingArguments,pipeline
from peft import prepare_model_for_int8_training,LoraConfig, TaskType, get_peft_model
import numpy as np
NUM_CLASSES = 2#模型输出分类的类别数
BATCH_SIZE,EPOCHS,R,LORA_ALPHA,LORA_DROPOUT = 8,5,64,32,0.1#LoRA训练的参数
MODEL_PATH="D:/Gemma/gemma-2b-int-mirror2"#模型地址
# 1.源model,设置输出二分类
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_PATH,num_labels=NUM_CLASSES)
print(model)
处理csv数据,将输入文字经过tokenizer编码处理
#2.处理dataset,输入过长进行truncation(tokenizer处理后)
dataset = load_dataset('csv', data_files='D:/Gemma/nlp-getting-started/train.csv')
dataset['test'] = dataset['train']
dataset = dataset.remove_columns(['id', 'keyword', 'location'])
dataset = dataset.rename_column("target", "label")#csv最后只保留了text列和label列
tokenized_dataset = {}#train和test
for split in dataset.keys():tokenized_dataset[split] = dataset[split].map(lambda x: tokenizer(x["text"], truncation=True), batched=True)
print(tokenized_dataset["train"])
print(tokenized_dataset["train"][1])
在源model基础上配置LoRA的参数,形成lora_model
#3.LoRA模型参数设置
model = prepare_model_for_int8_training(model)
lora_config = LoraConfig(r=R,lora_alpha=LORA_ALPHA,lora_dropout=LORA_DROPOUT,task_type=TaskType.SEQ_CLS,#SEQ_CLS:序列分类任务;TOKEN_CLS命名实体识别;SEQ2SEQ机器翻译;LM语言建模任务target_modules='all-linear'#all-linear所有线性层;embeddings嵌入层;convs卷积层
)
lora_model = get_peft_model(model, lora_config)
print(lora_model)
print(lora_model.print_trainable_parameters())#LoRA模型要训练的参数
配置lora_model的训练参数
#4.LoRA训练参数设置(损失计算等)
def compute_metrics(eval_pred):predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return {"accuracy": (predictions == labels).mean()}trainer = Trainer(model=lora_model,args=TrainingArguments(output_dir="./LoAR_data/",learning_rate=2e-5,per_device_train_batch_size=BATCH_SIZE,per_device_eval_batch_size=BATCH_SIZE,evaluation_strategy="epoch",save_strategy="epoch",num_train_epochs=EPOCHS,weight_decay=0.01,load_best_model_at_end=True,logging_steps=10,report_to="none"),train_dataset=tokenized_dataset["train"],eval_dataset=tokenized_dataset["test"],tokenizer=tokenizer,data_collator=DataCollatorWithPadding(tokenizer=tokenizer),compute_metrics=compute_metrics,
)
开始训练并保存使用模型
#5.训练并评估
print("Evaluating the Model Before Training!")
trainer.evaluate()
print("Training the Model")
trainer.train()
print("Evaluating the trained model")
trainer.evaluate()
#6.保存并使用
lora_model.save_pretrained('fine-tuned-model')
clf = pipeline("text-classification", lora_model, tokenizer=MODEL_PATH)#LoRA训练后的模型
3.2LoRA中文建模任务
参考
首先拿到源model和config
from transformers import AutoConfig,AutoTokenizer,AutoModelForCausalLM, Trainer, TrainingArguments
from peft import LoraConfig, get_peft_model,prepare_model_for_kbit_training,PeftModel
import torch
import datasets
from tqdm import tqdm
import json
BATCH_SIZE,EPOCHS,R,LORA_ALPHA,LORA_DROPOUT = 8,5,64,32,0.1#LoRA训练的参数
MODEL_PATH="D:/Gemma/gemma-2b-int-mirror2"#模型地址
device = torch.device('cuda:0')
# 1.源model和model的config
config = AutoConfig.from_pretrained(MODEL_PATH, trust_remote_code=True)
config.is_causal = True #确保模型在生成文本时只能看到左侧的上下文
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH,device_map="auto", config=config,trust_remote_code=True)
根据模型和config处理json数据
#2.根据model的config处理dataset(tokenizer处理后),并保存加载
def preprocess(tokenizer: PreTrainedTokenizer, config, file_path, max_seq_length, prompt_key, target_key, skip_overlength=False): # 数据预处理 pad_token_id = tokenizer.pad_token_id # 获取填充标记的ID with open(file_path, "r", encoding="utf8") as f: for line in tqdm(f.readlines()): example = json.loads(line) prompt_ids = tokenizer.encode(example[prompt_key], max_length=max_seq_length, truncation=True) target_ids = tokenizer.encode(example[target_key], max_length=max_seq_length, truncation=True) # 检查prompt和target连接后是否超出最大长度,并在需要时跳过 total_length = len(prompt_ids) + len(target_ids) + (1 if config.eos_token_id is not None else 0) if skip_overlength and total_length > max_seq_length: continue # 连接prompt和target,并添加EOS标记(如果提供) input_ids = prompt_ids + target_ids if config.eos_token_id is not None: input_ids.append(config.eos_token_id) # 截断序列到最大长度 input_ids = input_ids[:max_seq_length] # 填充序列到最大长度 input_ids.extend([pad_token_id] * (max_seq_length - len(input_ids))) assert len(input_ids) == max_seq_length, "序列长度必须等于max_seq_length" yield { "input_ids": input_ids, "seq_len": len(prompt_ids) # 注意:这里提供的seq_len是原始prompt的长度,不包括填充 }
dataset = datasets.Dataset.from_generator(lambda: preprocess(tokenizer, config, "D:/Gemma/try/hc3_chatgpt_zh_specific_qa.json", max_seq_length=2000, prompt_key="q",target_key="a",))dataset.save_to_disk("h3c-chinese") # 保存处理后的数据集
train_set = datasets.load_from_disk("h3c-chinese")#加载处理后的数据集
配置Lora参数
#3.LoRA模型参数设置
model = prepare_model_for_kbit_training(model)
lora_config = LoraConfig(r=R,lora_alpha=LORA_ALPHA,lora_dropout=LORA_DROPOUT,task_type="CAUSAL_LM",target_modules='all-linear'
)
lora_model = get_peft_model(model, lora_config)
print(lora_model)
print(lora_model.print_trainable_parameters())#LoRA模型要训练的参数
配置lora的训练参数,包括损失计算compute_metrics,并对输入的input_ids构造输入样本列表批次处理。
trainer = Trainer(model=lora_model,args=TrainingArguments(output_dir="./LoAR_data2/",learning_rate=2e-5,per_device_train_batch_size=BATCH_SIZE,save_strategy="epoch",num_train_epochs=EPOCHS,weight_decay=0.01,logging_steps=10,report_to="none"),train_dataset=train_set,tokenizer=tokenizer,data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
# compute_metrics=compute_metrics
)
trainer.train()
相关文章:

Gemma
Gemma 1.使用2.RAG3.LoRA3.1LoRA分类任务3.2LoRA中文建模任务 1.使用 首先是去HF下载模型,但一直下载不了,所以去了HF镜像网站,下载gemma需要HF的Token,按照步骤就可以下载。代码主要是Kaggle论坛里面的分享内容。 huggingface-…...

淘宝关键词搜索API、搜索商品接口、商品价格监控
淘宝搜索引擎的工作原理: 淘宝搜索引擎的工作原理是基于搜索引擎的核心技术——爬虫和索引,通过对海量数据的抓取、分析和存储,提供给用户最准确的搜索结果。 具体来说,淘宝搜索引擎的工作流程如下: 企业级api数据…...
vue实现水印功能
目录 一、应用场景 二、实现原理 三、详细开发 1.水印的实现方式 2.防止用户通过控制台修改样式去除水印效果(可跳过,有弊端) 3.水印的使用 (1)单页面/全局使用 (2)全局使用个别页面去掉…...

记录一下我的Ruby On Rails的systemd服务脚本
自己也是一个 ROR 框架的学习者,同时也是 Ruby 的新手。对于如何让 ROR 应用随系统自动启动并不是很了解。在尝试了各种方法之后,我最终找到了一条可行的途径。虽然不确定是否完全正确,但服务已经成功启动了。因此,我决定在这里保…...
【计算机网络】传输层——TCP和UDP详解
文章目录 一. TCP和UDP简介二. UDP 协议详解1. UDP报文格式2. UDP的使用场景 三. TCP 协议详解1. TCP报文格式2. TCP协议的重要机制确认应答(保证可靠传输的最核心机制)超时重传连接管理(三次握手、四次挥手)!…...
stm32和嵌入式linux可以同步学习吗?
在开始前我有一些资料,是我根据网友给的问题精心整理了一份「stm3的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!如果需要使用STM32,建…...

maven--->maven中的<properties>属性有什么作用?
🙌🙌🙌🙌🙌🙌 在Maven中,元素用于定义项目中可重用的属性值。这些属性值可以在项目的POM文件中被引用,以便在整个项目中统一管理和使用。通过使用元素,可以避免在POM文件…...

android 网络请求总结
1 先看下基础部分: android okhttp网络访问是基于 tcp/ip 的 最上层是应用层的封装,有http,https(加密),ftp 下面是socket套接字的封装,就是将ip和端口的封装 在下面就是tcp/udp 在下面 ip协议…...

用 Python 自动化处理无聊的事情
“编程最棒的部分就是看到机器做一些有用的事情而获得的胜利。用 Python 将无聊的事情自动化将所有编程视为这些小小的胜利;它让无聊变得有趣。” Hilary Mason,数据科学家兼 Fast Forward Labs 创始人 “我很享受打破东西然后把它们重新组合起来的乐趣…...
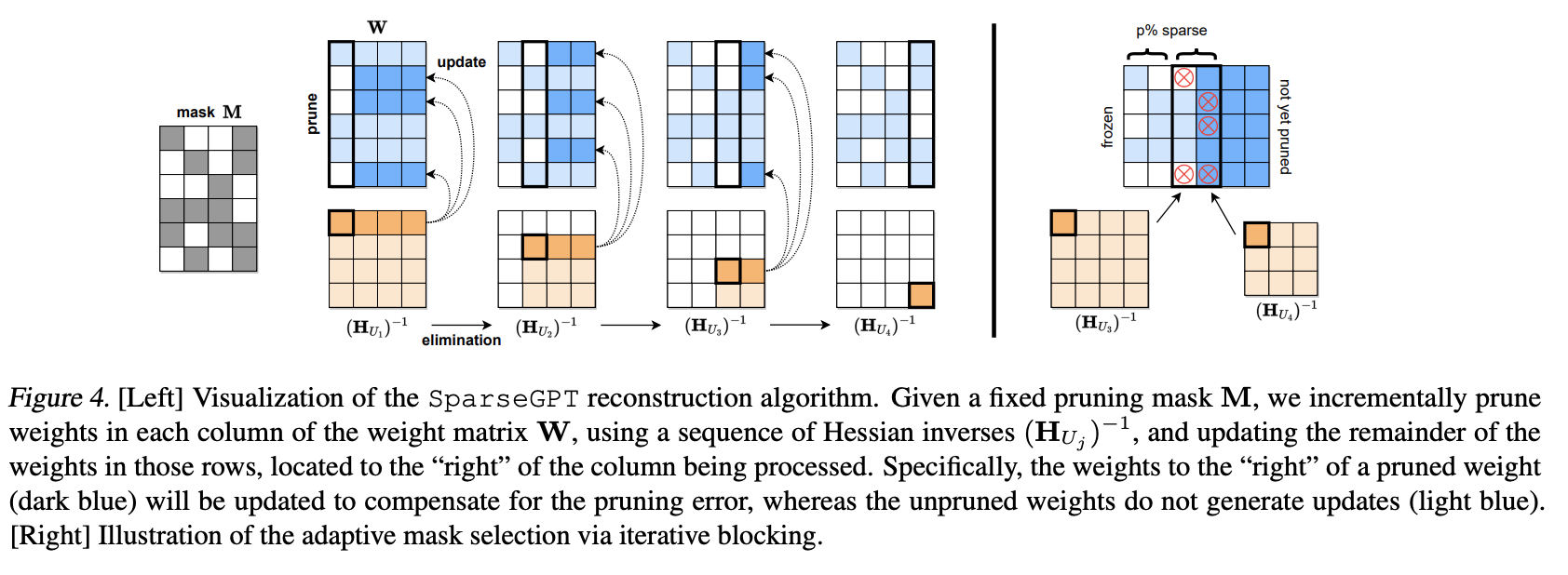
稀疏计算、彩票假说、MoE、SparseGPT
稀疏计算可能是未来10年内最有潜力的深度学习方向之一,稀疏计算模拟了对人脑的观察,人脑在处理信息的时候只有少数神经元在活动,多数神经元是不工作的。而稀疏计算的基本思想是:在计算过程中,将一些不重要的参数设置为…...
Git Windows安装教程
Git简介 Git是目前世界上最先进的分布式版本控制系统。它的工作原理 / 流程如下: [ Workspace:工作区 Index / Stage:暂存区 Repository:仓库区(或本地仓库) Remote:远程仓库 ] Git的下载 去 Git 官网下载对应系统的软件了,下…...

iOS高级理论:Runtime应用
一、遍历类的属性,快速归档 在 iOS 中,可以使用 Runtime 遍历类的属性来实现快速的归档(Archiving)操作。归档是将对象转换为数据流以便存储或传输的过程。下面是一个简单的示例,展示如何使用 Runtime 遍历类的属性进…...
,链接注入,框架注入等攻击)
php判断和过滤get或者post的html标签,防止跨站点脚本(XSS),链接注入,框架注入等攻击
大部分网站都包含搜索功能,根据用户搜索的词去执行服务端的业务逻辑。如果一些黑客在搜索参数包含链接(a)、嵌入其他网页(iframe)、前端代码(script)等html字符,再加上服务端php不加…...

PySide6实现课堂点名程序
目录 一:实现思路 二:实现代码 三:完整代码和界面 一:实现思路 为了创建一点名程序,并编写一个基本的 GUI 应用程序。新建一个窗口,展在窗口界面添加开始和停止按钮的QPushButton,和展示正在显示的人名QLabel,点击开始时随机显示人名列表中的一个名字并且展示在QLab…...

瑞_Redis_Redis命令
文章目录 1 Redis命令Redis数据结构Redis 的 key 的层级结构1.0 Redis通用命令1.0.1 KEYS1.0.2 DEL1.0.3 EXISTS1.0.4 EXPIRE1.0.5 TTL 1.1 String类型1.1.0 String类型的常见命令1.1.1 SET 和 GET1.1.2 MSET 和 MGET1.1.3 INCR和INCRBY和DECY1.1.4 SETNX1.1.5 SETEX 1.2 Hash类…...

js 算法题 在数组中找出和为目标值 target 的那 两个 整数,并返回它们的数组下标
题目:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以…...

基于springboot接口的编写
目录 1、模糊分页查询 2、批量删除 3、新增 4、编辑 此接口非彼接口。此接口是MVC的设计模式中的Controller层,一般我们会叫Controller层里的方法为接口。他们是负责接收前端或者其它服务的传来的请求,并对请求进行相应的处理,最终再将处…...
【HarmonyOS】鸿蒙开发之Video组件——第3.7章
Video组件内VideoOptions属性简介 src:设置视频地址。currentProgressRate:设置视频播放倍速,参数说明如下: number|string:只支持 0.75 , 1.0 , 1.25 , 1.75 , 2.0 。P…...

React引入css的几种方式以及应用
1.直接引入css文件 import "./parent.css" 2.引入css模块,定义文件名[组件名.module.css];该方式可避免类名的重复,每个组件都有独立的作用域,避免了全局污染,保证了类名的唯一性 import styles from &qu…...

[算法沉淀记录] 排序算法 —— 冒泡排序
排序算法 —— 冒泡排序 基本概念 冒泡排序是一种简单的排序算法。它重复地遍历要排序的列表,一次比较两个元素,并交换它们的位置,如果它们不是按照升序排列的。这步遍历是重复进行的,直到没有再需要交换,也就是说该…...

camera-controls 调试与问题排查:常见错误与解决方案汇总
camera-controls 调试与问题排查:常见错误与解决方案汇总 【免费下载链接】camera-controls A camera control for three.js, similar to THREE.OrbitControls yet supports smooth transitions and more features. 项目地址: https://gitcode.com/gh_mirrors/ca/…...

数据转换与处理:Awesome Python Scripts中的7个强大转换器
数据转换与处理:Awesome Python Scripts中的7个强大转换器 【免费下载链接】Awesome-Python-Scripts A Curated list of Awesome Python Scripts that Automate Stuffs. 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome-Python-Scripts 在日常工作中&…...

别再为模糊的3D重建头疼了!手把手教你用3DSlicer处理不同层厚的DICOM数据
别再为模糊的3D重建头疼了!手把手教你用3DSlicer处理不同层厚的DICOM数据 医学影像三维重建是临床研究和教学中的重要工具,但许多初学者在使用3DSlicer时都会遇到一个令人沮丧的问题:为什么我的冠状位和矢状位图像总是模糊不清?这…...

如何用ViGEmBus解决Windows游戏手柄兼容性难题:完整指南
如何用ViGEmBus解决Windows游戏手柄兼容性难题:完整指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 还在为Windows游戏手柄兼容性发愁吗&…...

XXMI Launcher终极指南:一站式跨平台游戏模组管理平台
XXMI Launcher终极指南:一站式跨平台游戏模组管理平台 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 还在为管理不同游戏的模组而烦恼吗?每次都要打开不…...

如何在25分钟内完成700+飞书文档批量导出:告别手动操作的低效时代
如何在25分钟内完成700飞书文档批量导出:告别手动操作的低效时代 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 还在为飞书文档迁移而头疼吗?每天花费数小时手动复制粘贴…...

GME-Qwen2-VL-2B与数据结构优化:提升大规模图像特征检索效率
GME-Qwen2-VL-2B与数据结构优化:提升大规模图像特征检索效率 你有没有遇到过这种情况?手机里存了几千张照片,想找一张几年前拍的风景照,只记得大概的样子,却怎么也想不起名字,只能一张张手动翻找ÿ…...
)
Claude读论文系列(十)
精读笔记:CoDe-R CoDe-R: Refining Decompiler Output with LLMs via Rationale Guidance and Adaptive Inference arXiv: 2604.12913 | cs.SE / cs.AI / cs.CR 会议:IJCNN 2026(已收录) 机构:未标注(第一作…...
)
告别virt-manager!纯命令行搞定KVM虚拟机创建与管理(附常用命令清单)
告别virt-manager!纯命令行搞定KVM虚拟机创建与管理(附常用命令清单) 在当今追求极致效率的运维环境中,图形界面工具往往成为制约自动化流程的瓶颈。对于熟悉Linux命令行的工程师而言,virt-manager这类GUI工具不仅操作…...

DAMO-YOLO手机检测结果结构化解析:JSON输出格式与数据库存储设计
DAMO-YOLO手机检测结果结构化解析:JSON输出格式与数据库存储设计 1. 引言:从检测框到结构化数据 当你运行一个手机检测模型,看到屏幕上出现一个个红色的方框时,你可能在想:这些检测结果怎么用起来?怎么保…...