【算法与数据结构】复杂度深度解析(超详解)

文章目录
- 📝算法效率
- 🌠 算法的复杂度
- 🌠 时间复杂度的概念
- 🌉大O的渐进表示法。
- 🌠常见复杂度
- 🌠常见时间复杂度计算举例
- 🌉常数阶O(1)
- 🌉对数阶 O(logN)
- 🌉线性阶 O(N)
- 🌉平方阶O(N^2)
- 🌉指数阶O(2^N)
- 🌠常见复杂度
- 🌉空间复杂度
- 🌉空间复杂度为 O(1)
- 🌉空间复杂度为 O(N)
- 🚩总结
📝算法效率
如何衡量一个算法的好坏
如何衡量一个算法的好坏呢?比如对于以下斐波那契数列:
long long Fib(int N)
{if(N < 3)return 1;return Fib(N-1) + Fib(N-2);
}
斐波那契数列的递归实现方式非常简洁,但简洁一定好吗?那该如何衡量其好与坏呢?
算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
**时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。**在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
衡量一个算法好坏主要从以下几个方面来看:
- 时间复杂度
时间复杂度反映了算法随问题规模增长所需要的计算时间增长情况。时间复杂度越低,算法效率越高。
对于上述斐波那契递归算法,其时间复杂度是O(2^N),随问题规模的增长,需要计算时间呈指数级增长,效率很低。
- 空间复杂度
空间复杂度反映了算法需要使用的辅助空间大小,与问题规模的关系。空间复杂度越低,算法效率越高。
递归算法需要在调用栈中保存大量中间结果,空间复杂度很高。
所以对于斐波那契数列来说,简洁的递归实现时间和空间复杂度都很高,不如使用迭代方式。
总的来说,在评价算法好坏时,时间和空间复杂度应该放在首位,然后是代码质量和其他方面。而不是单纯看代码是否简洁。
🌠 算法的复杂度
算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
**时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。**在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
🌠 时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
// 请计算一下Func1中++count语句总共执行了多少次?
void Func1(int N)
{int count = 0;for (int i = 0; i < N; ++i){for (int j = 0; j < N; ++j){++count;}}for (int k = 0; k < 2 * N; ++k){++count;}int M = 10;while (M--){++count;}printf("%d\n", count);
}
Func1 执行的基本操作次数 :
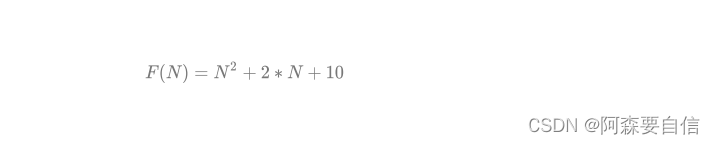
N = 10 F(N) = 130
N = 100 F(N) = 10210
N = 1000 F(N) = 1002010
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里我们使用大O的渐进表示法。
🌉大O的渐进表示法。
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
使用大O的渐进表示法以后,Func1的时间复杂度为:O(N^2)
N = 10 F(N) = 100
N = 100 F(N) = 10000
N = 1000 F(N) = 1000000
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
🌠常见复杂度
常数阶O(1)
对数阶O(logN)
线性阶 O(N)
线性对数阶O(nlogN)O(N*logN)
平方阶O(N^2)
K次方阶O(N^k)
指数阶O(2^N)
K次N方阶O(k^N)
N的阶乘O(N!)
🌠常见时间复杂度计算举例
🌉常数阶O(1)
// 计算Func4的时间复杂度?
void Func4(int N)
{int count = 0;for (int k = 0; k < 100; ++ k){++count;}printf("%d\n", count);
}
Func4中有一个for循环,但是for循环的迭代次数是固定的100次,不依赖输入参数N。在for循环内部,只有一个++count操作,这是一个常数时间的操作。打印count也是常数时间的操作。
所以Func4中的所有操作的时间都不依赖输入参数N,它的时间复杂度是常数级别O(1)。
又如int a = 4;int b= 10;那a+b的复杂度是多少?它的时间复杂度是O(1),无论a为2000万,b为10亿,a+b还是O(1),因为a,b都是int 类型,都是32位,固定好的常数操作,&,/…都是O(1)
🌉对数阶 O(logN)
// 计算BinarySearch的时间复杂度?
int BinarySearch(int* a, int n, int x)
{assert(a);int begin = 0;int end = n - 1;// [begin, end]:begin和end是左闭右闭区间,因此有=号while (begin <= end){int mid = begin + ((end - begin) >> 1);if (a[mid] < x)begin = mid + 1;else if (a[mid] > x)end = mid - 1;elsereturn mid;}return -1;
}
BinarySearch的时间复杂度是O(logN)
原因:
BinarySearch采用二分查找算法,每次都将搜索区间缩小一半, while循环里面计算mid点和比较a[mid]与x的操作都是常数时间复杂度的, 最坏情况下,需要log2N次循环才能找到元素或判断不存在。所以BinarySearch的时间复杂度取决于while循环迭代的次数,而循环次数是与输入规模N成对数级别的关系,即O(logN)。基本操作执行最好1次,最坏O(logN)次,时间复杂度为 O(logN) ps:logN在算法分析中表示是底数为2,对数为N。有些地方会写成lgN。
🌉线性阶 O(N)
// 计算Func2的时间复杂度?
void Func2(int N)
{int count = 0;for (int k = 0; k < 2 * N; ++k){++count;}int M = 10;while (M--){++count;}printf("%d\n", count);
}
Func2里面有一个外层for循环,循环次数是2N,for循环内部的++count是常数时间操作,基本操作执行了2N+10次,通过推导大O阶方法知道,时间复杂度为 O(N)。
🌉平方阶O(N^2)
// 计算BubbleSort的时间复杂度?
void BubbleSort1(int* a, int n)
{assert(a);for (size_t end = n; end > 0; --end){int exchange = 0;for (size_t i = 1; i < end; ++i){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);exchange = 1;}}if (exchange == 0)break;}
}
BubbleSort2的时间复杂度是O(n^2)
原因:
BubbleSort采用冒泡排序算法,它有两个循环,外层循环从n遍历到1,循环n次,内层循环每次比较相邻元素,从1遍历到end-1,循环从n-1到1次,所以内层循环的总时间复杂度是Σ(n-1)+(n-2)+...+1 = n(n-1)/2 = O(n^ 2) ,外层循环n次,内层循环每个都为O(n), 所以整体时间复杂度是外层循环次数乘内层循环时间复杂度,即O(n)×O(n)=O(n^ 2 ), 其他操作如交换等都是常数时间,对总时间影响不大,基本操作执行最好N次,最坏执行了(N*(N+1)/2次,通过推导大O阶方法+时间复杂度一般看最坏,时间复杂度为 O(N^2)
不要用代码结构来判断时间复杂度,比如只有一个while循环的冒泡排序,
计算BubbleSort2的时间复杂度?
void bubbleSort2(int[] arr)
{if (arr == null || arr.length < 2) {return;}int n = arr.length;int end = n - 1, i = 0;while (end > 0) {if (arr[i] > arr[i + 1]) {swap(arr, i, i + 1);}if (i < end - 1) {i++;} else {end--;i = 0;}}}void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}
冒泡排序每一轮循环都可以使得最后一个元素"沉底",即升序排列, 数组长度为n的排序,需要进行n-1轮比较才能完成排序,每一轮循环需要进行n-1次元素比较,最坏情况下每次比较都需要交换元素,所以总共需要进行(n-1)+(n-2)+...+1 = n(n-1)/2次元素比较,每次元素比较和交换的时间复杂度都是O(1),所以冒泡排序的时间复杂度是O(n^2)。
总之,判断算法时间复杂度应该基于操作次数的估算,而不仅仅看代码结构,如循环、递归等。
又比如:N/1+N/2+N/3 ...+N/N,这个流程的时间复杂度是O(N*logN),著名的调和级数
for (int i = 1; i <= N; i++)
{for (int j = i; j <= N; j += i) {// 这两个嵌套for循环的流程,时间复杂度为O(N * logN)// 1/1 + 1/2 + 1/3 + 1/4 + 1/5 + ... + 1/n,也叫"调和级数",收敛于O(logN)// 所以如果一个流程的表达式 : n/1 + n/2 + n/3 + ... + n/n// 那么这个流程时间复杂度O(N * logN)}
}
对于这个代码,时间复杂度分析需要更仔细:外层循环i从1到N,循环次数是O(N),内层循环j的起始点是i,终止点是N,但是j的步长是i,也就是j每次增加i,那么内层循环每次迭代的次数大致是N/i,所以总体循环迭代次数可以表示为:∑(N/i) = N*(H(N) - 1) ,其中H(N)是哈密顿数,也就是1到N的和,约为O(logN),所以这个算法的时间复杂度是:O(N*(logN)) = O(NlogN)
当然举个例子就更清晰了:
for (int i = 1; i <= N; i++)
{for (int j = i; j <= N; j += i) 1 2 3 4 5 6 7 8 9 10 11 12.......N
第一轮: 1 2 3 4 5 6 7 8 9 10 11 12.......i=1,j每次加1,都遍历为N
第二轮: 2 4 6 8 10 12.......i=2,j每次加2,以2的倍数来遍历为N/2
第三轮: 3 6 9 12.......i=3,j每次加3,以3的倍数来遍历为N/3
第四轮: 4 8 12.......i=4,j每次加4,以4的倍数来遍历为N/4....i=N,j每次加N,以N的倍数来遍历为N/NN/1+N/2+N/3+N/4+....N/N
1+1/2+1/3+1/4+1/5+......1/N-->O(logN)
N/1+N/2+N/3+N/4+....N/N-->N*(1+1/2+1/3+1/4+1/5+......1/N)->O(N*logN)
我们可以看出:对于循环嵌套,我们需要考虑所有细节,不能简单下定论,给出一个更准确的时间复杂度分析。
🌉指数阶O(2^N)
// 计算斐波那契递归Fib的时间复杂度?
long long Fib(size_t N)
{if(N < 3)return 1;return Fib(N-1) + Fib(N-2);
}
斐波那契递归Fib函数的时间复杂度是O(2^N)
原因:
斐波那契数列的递归定义是:Fib(N) = Fib(N-1) + Fib(N-2),每次调用Fib函数,它会递归调用自己两次。
可以用递归树来表示斐波那契递归调用的关系:
Fib(N) / \Fib(N-1) Fib(N-2)/ \ / \
...
可以看出每次递归会产生两条子节点,形成一个二叉树结构。
二叉树的高度就是输入N,每一层节点数都是2的N次方,根据主定理,当问题可以递归分解成固定数目的子问题时,时间复杂度就是子问题数的对数,即O(c^ N )。这里每次都分解成2个子问题,所以时间复杂度是O(2^ N)。 Fib递归函数的时间复杂度是指数级的O(2^N),属于最坏情况下的递归。
🌠常见复杂度
🌉空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
🌉空间复杂度为 O(1)
// 计算BubbleSort的空间复杂度?
void BubbleSort(int* a, int n)
{assert(a);for (size_t end = n; end > 0; --end){int exchange = 0;for (size_t i = 1; i < end; ++i){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);exchange = 1;}}if (exchange == 0)break;}
}
BubbleSort的空间复杂度是O(1)
原因:
BubbleSort是一种原地排序算法,它不需要额外的空间来排序,算法中只使用了几个大小为常数的变量,如end、exchange等,交换元素也是直接在原数组上操作,不需要额外空间,整个排序过程中只使用了固定数量的变量空间,不会随着输入规模n的增加而增加,常数空间对空间复杂度的影响可以忽略不计。所以,BubbleSort的空间复杂度取决于它使用的变量空间,而变量空间不随n的增加而增加,是固定的O(1)级别。
🌉空间复杂度为 O(N)
// 计算Fibonacci的空间复杂度?
// 返回斐波那契数列的前n项
long long* Fibonacci(size_t n)
{if (n == 0)return NULL;long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long));fibArray[0] = 0;fibArray[1] = 1;for (int i = 2; i <= n; ++i){fibArray[i] = fibArray[i - 1] + fibArray[i - 2];}return fibArray;
}
斐波那契数列递归算法Fibonacci的空间复杂度是O(n)
原因:
算法使用了一个长整型数组fibArray来存储计算出来的前n项斐波那契数列,这个数组需要的空间大小是n+1,随着输入n的增加而线性增长,除此之外,递归过程中没有其他额外空间开销, 所以空间消耗完全取决于fibArray数组的大小,即O(n),常数因子可以忽略,所以算法的空间复杂度为O(n)。
// 计算阶乘递归Fac的空间复杂度?
long long Fac(size_t N)
{if(N == 0)return 1;return Fac(N-1)*N;
}
阶乘递归算法Fac的空间复杂度是O(N)
原因:
Fac函数是递归定义的,每递归一次就会在函数调用栈中push一个栈帧,递归深度等于输入N,随着N增加而增加,每个栈帧中保存的信息(如参数N值等)大小为常量,所以总的栈空间大小就是递归深度N乘以每个栈帧大小,即O(N),Fac函数内部没有其他额外空间开销。阶乘递归算法Fac之所以空间复杂度为O(N),是因为它使用递归调用栈的深度正比于输入N,而栈深度决定了总空间需求。
🚩总结
感谢你的收看,如果文章有错误,可以指出,我不胜感激,让我们一起学习交流,如果文章可以给你一个小小帮助,可以给博主点一个小小的赞😘

我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=34m59s418000k
相关文章:
【算法与数据结构】复杂度深度解析(超详解)
文章目录 📝算法效率🌠 算法的复杂度🌠 时间复杂度的概念🌉大O的渐进表示法。 🌠常见复杂度🌠常见时间复杂度计算举例🌉常数阶O(1)🌉对数阶 O(logN)🌉线性阶 O(N)&#x…...
Upload-Labs-Linux1【CTF】
拿到这道题目一看,发现是upload靶场;这不简简单单吗;结果中间还是遇到了一些小问题 小坑总结:该关只识别标准php语法:<?php phpinfo()?>格式;即<?php ?> 不识别<? phpinfo()?> &…...

搜维尔科技:OptiTrack 提供了性能最佳的动作捕捉平台
OptiTrack 动画 我们的 Prime 系列相机和 Motive 软件相结合,产生了世界上最大的捕获量、最精确的 3D 数据和有史以来最高的相机数量。OptiTrack 提供了性能最佳的动作捕捉平台,具有易于使用的制作工作流程以及运行世界上最大舞台所需的深度。 无与伦比…...
java设计模式之职责链模式
基本介绍 职责链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式对请求的发送者和接收者进行解耦。职责链模式 又叫责任链模式,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求。那…...

连不上网的解决办法集--持续更新
连不上网的解决办法集–持续更新 1、有网卡,但网卡驱动失效 背景:有网络驱动但是依旧连不上网,只有inteV6有值,inte 没有值(正常应该有个ipv4的信息) 判断原因:可能是之前格式化磁盘驱动的时…...

Unity之PUN2插件实现多人联机射击游戏
目录 📖一、准备工作 📺二、UI界面处理 📱2.1 登录UI并连接PUN2服务器 📱2.2 游戏大厅界面UI 📱2.3 创建房间UI 📱2.4 进入房间UI 📱2.5 玩家准备状态 📱2.6 加载战斗场景…...
)
72_Pandas.DataFrame保存并读取带pickle的系列(to_pickle、read_pickle)
72_Pandas.DataFrame保存并读取带pickle的系列(to_pickle、read_pickle) 要将 pandas.DataFrame、pandas.Series 对象保存为 pickle 文件,请使用 to_pickle() 方法,并使用 pd.read_pickle() 函数读取保存的 pickle 文件。 在此对…...

Redis哨兵模式和Redis Cluster模式
文章目录 🔊博主介绍🥤本文内容Redis Cluster 模式支持自动故障转移功能吗?Redis Cluster 模式支持自动故障转移功能和哨兵有什么区别?Redis Cluster 模式和哨兵模式(Sentinel)在自动故障转移方面有一些关键…...
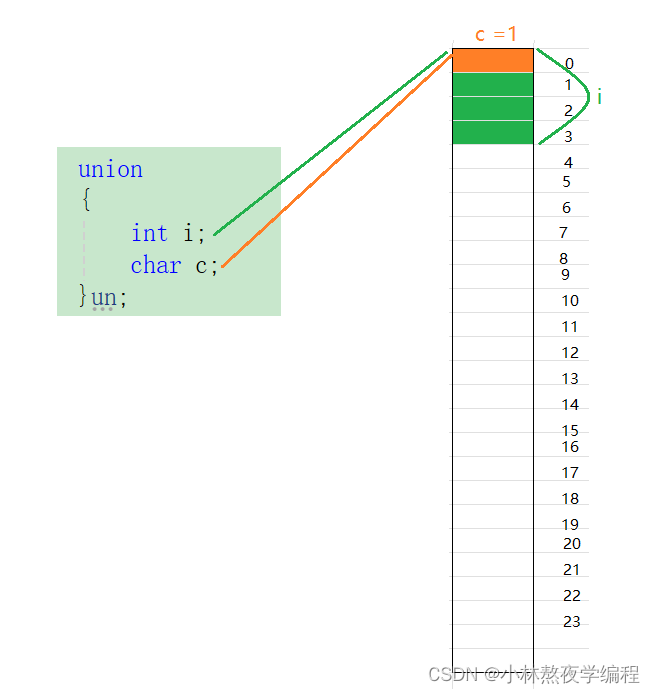
C语言第三十二弹---自定义类型:联合和枚举
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 目录 1、联合体 1.1、联合体类型的声明 1.2、联合体的特点 1.3、相同成员的结构体和联合体对比 1.4、联合体大小的计算 1.5、联合的⼀个练习 2、枚举类型 …...

milvus upsert流程源码分析
milvus版本:v2.3.2 整体架构: Upsert 的数据流向: 1.客户端sdk发出Upsert API请求。 import numpy as np from pymilvus import (connections,Collection, )num_entities, dim 4, 3print("start connecting to Milvus") connections.connect("default",…...
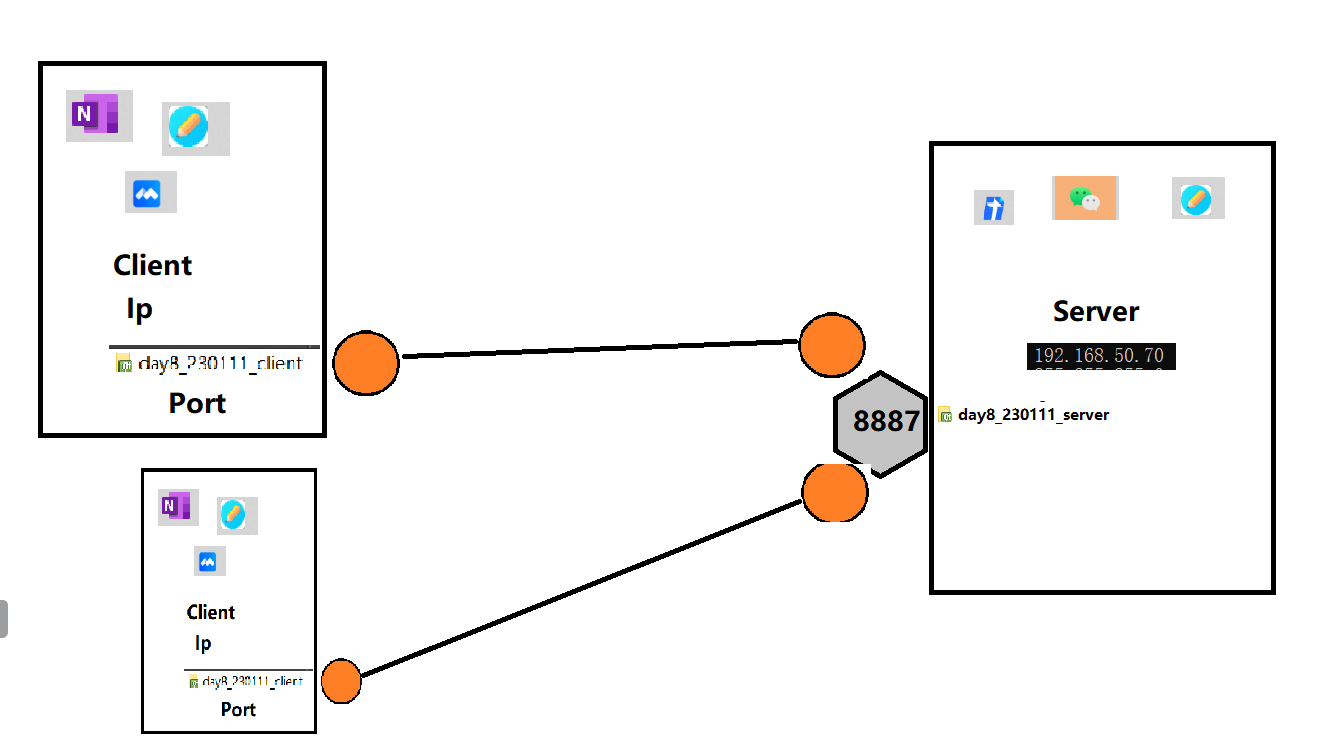
QT网络通信
九、网络 基础概念 1.1 TCP/UDP TCP/UDP UDP TCP 协议相同点:都存在于传输层,全双工通信 TCP:全双工通信、面向连接、可靠 TCP(即传输控制协议):是一种面向连接的传输层协议,它能提供高可靠性通…...
案例分析|山西某光伏发电站轨道巡检机器人解决方案
随着光伏发电技术的不断发展,光伏变电站配电室作为能量转换和输送的关键节点,承担着重要的电力分配和保护功能。然而,传统的人工巡检方式存在诸多问题,如巡检周期长、效率低、安全风险高等,已经无法满足光伏变电站配电…...
Apache POl
介绍 Apache POl是一个处理Miscrosoft Ofice各种文件格式的开源项目。简单来说就是,我们可以使用 POI 在 Java 程序中对Miscrosoft Office各种文件进行读写操作,一般情况下,POI都是用于操作 Excel 文件。 Apache POl 的应用场景 1.银行网银系统导出交易…...

高防服务器托管应注意什么
选择高防服务器托管主要考虑的因素:1.服务商的服务器大小。2.服务器的防御值大小。3.服务器机房的位置以及机房的资质。 具体内容如下: 1.服务器大小是按照U来定的,U是一种表示服务器外部尺寸的单位(计量单位:高度或厚…...
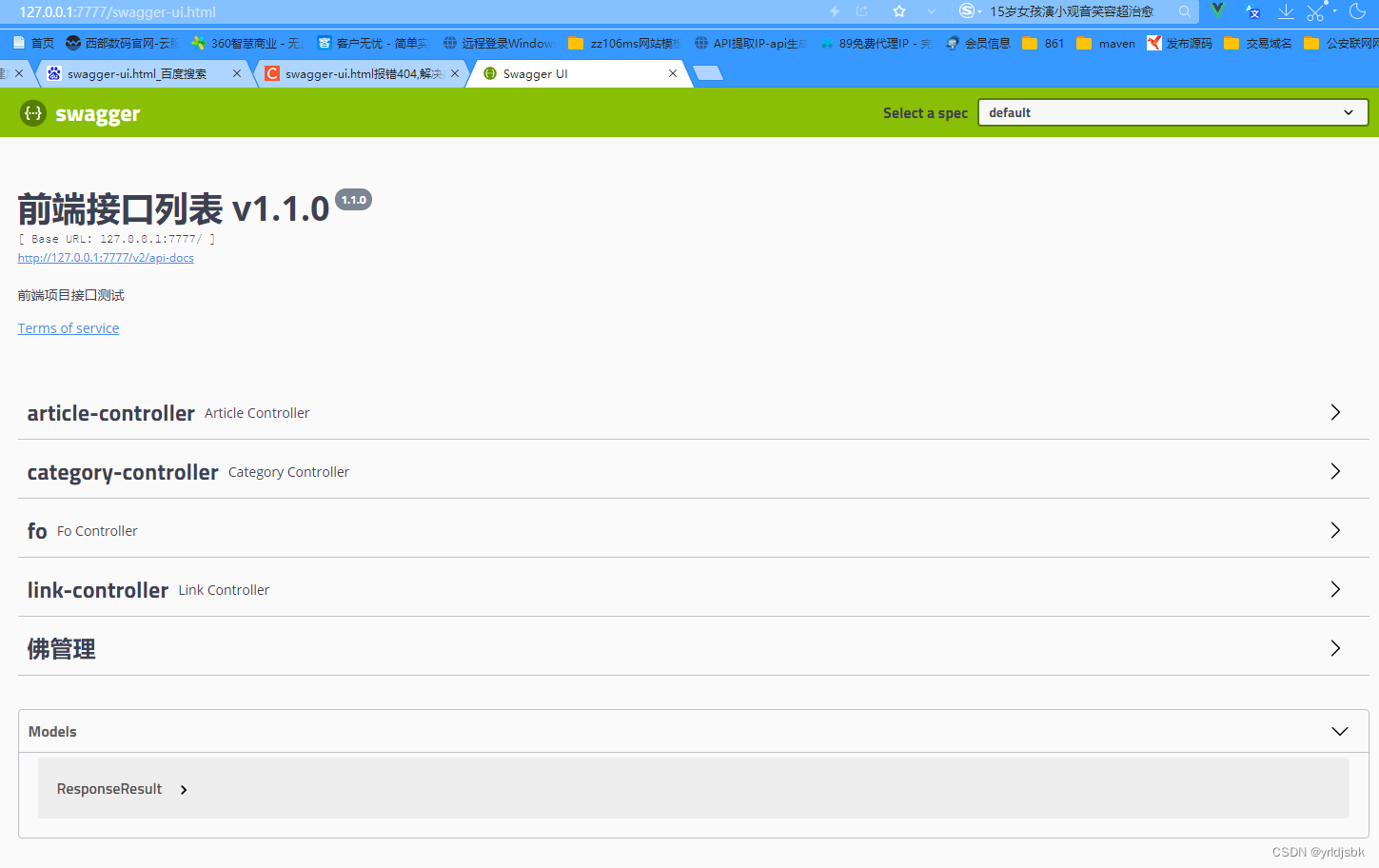
swagger-ui.html报错404,解决办法
swagger-ui.html报错404,解决办法!现在后端开发项目中,为了节省时间,使用swagger插件,可以方便的快捷生成接口文档。但是如果你在请求前端页面路径比如:http://127.0.0.1:7777/swagger-ui.html。找不到。那是因为你的配…...

golang 函数式编程库samber/mo使用: Future
golang 函数式编程库samber/mo使用: Future 如果您对samber/mo库不了解, 请先阅读第一篇 Option 本节讲述Future的使用,它可以帮助我们处理异步编程问题。 示例 我们先来看看下面代码的示例, 注释解释了每一步的操作。 packa…...
----Mongodb特有的查询方法)
【Spring连载】使用Spring Data访问 MongoDB(十四)----Mongodb特有的查询方法
【Spring连载】使用Spring Data访问 MongoDB(十四)----Mongodb特有的查询方法 一、定义通用查询方法二、MongoDB特有的查询方法2.1 地理空间查询Geo-spatial Queries2.2 基于JSON的查询方法和字段限制2.3 使用SpEL表达式的基于JSON的查询2.4 全文检索查询…...

消息中间件篇之RabbitMQ-消息重复消费
一、导致重复消费的情况 1. 网络抖动。 2. 消费者挂了。 消费者消费消息后,当确认消息还没有发送到MQ时,就发生网络抖动或者消费者宕机。那当消费者恢复后,由于MQ没有收到消息,而且消费者有重试机制,消费者就会再一次消…...

常见设计模式之单例模式
单例模式 单例模式是一种常用的软件设计模式,主要目的是确保一个类在整个应用程序生命周期中只有一个实例,并提供一个全局访问点以获取该实例。 单例模式分为几种不同的实现方式,包括懒汉模式和饿汉模式。每种方式都有其特点和适用场景。例如…...

VL817-Q7 USB3.0 HUB芯片 适用于扩展坞 工控机 显示器
VL817-Q7 USB3.1 GEN1 HUB芯片 VL817-Q7 USB3.1 GEN1 HUB芯片 VIA Lab的VL817是一款现代USB 3.1 Gen 1集线器控制器,具有优化的成本结构和完全符合USB标准3.1 Gen 1规范,包括ecn和2017年1月的合规性测试更新。VL817提供双端口和双端口4端口配置&…...

3大核心策略解锁抖音纯净内容:douyin-downloader深度解析与实战
3大核心策略解锁抖音纯净内容:douyin-downloader深度解析与实战 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallb…...

Vector-CANoe实战:CAPL编程与NetWork Node节点深度配置指南
1. 初识NetWork Node:从Client到Server的角色转变 第一次接触CANoe时,大多数人都会把它当作一个简单的Client端工具,用来收发CAN报文、解析信号。但当我真正参与到一个整车网络测试项目时,才发现NetWork Node的强大之处。那次我们…...

MTools使用指南:整合图片处理、音视频编辑和AI智能工具
MTools使用指南:整合图片处理、音视频编辑和AI智能工具 1. MTools简介与核心功能 1.1 什么是MTools? MTools是一款现代化桌面工具集,将图片处理、音视频编辑、AI智能工具和开发辅助功能整合到一个界面精美的应用中。它就像数字工作台上一把…...

G-Helper实战指南:华硕笔记本轻量级性能控制完整解决方案
G-Helper实战指南:华硕笔记本轻量级性能控制完整解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix,…...

告别手动调参!用Antenna Magus 2022快速搞定2.4GHz蓝牙/WiFi天线初版设计
射频工程师的效率革命:Antenna Magus在2.4GHz天线设计中的实战应用 当智能家居设备的PCB尺寸比硬币还小,当可穿戴产品的厚度要求突破3mm极限,射频工程师们正在经历前所未有的设计挑战。传统天线设计流程中,工程师需要花费数周时间…...

Chapter 14: Link Initialization Training
Chapter 14: Link Initialization & Training 书籍: PCI Express Technology 3.0 (MindShare Press, 2012) 页码: Book Pages 487-520 | PDF Pages 547-580 学习日期: 2026-04-13本章概要 本章描述 PCIe 链路初始化和训练过程,包括 TS1/TS2 有序集、极性检测、L…...

从MPLS到SRv6:为什么运营商都在悄悄升级这个不起眼的技术?
从MPLS到SRv6:运营商网络升级背后的技术革命 当你在手机上流畅观看4K视频时,或许不会想到这背后有一场持续了二十年的网络协议演进。全球运营商正在将承载网核心技术从MPLS悄然升级为SRv6,这场变革将直接影响未来十年互联网的传输效率与业务创…...
介绍(指代码进入下一阶段(如合并到主分支、发布到生产环境)前,必须满足的一组自动化质量检查标准))
CI/CD质量门禁(Quality Gate)介绍(指代码进入下一阶段(如合并到主分支、发布到生产环境)前,必须满足的一组自动化质量检查标准)
文章目录什么是质量门禁(Quality Gate)?一文讲清 CI/CD 中的“最后一道防线”一、质量门禁是什么?二、为什么需要质量门禁?三、质量门禁通常检查什么?1. 构建与测试2. 代码质量(静态分析&#x…...
)
LaTeX表格总是不听话?用[h]参数让它乖乖待在原地(附完整代码示例)
LaTeX表格浮动问题终极指南:精准控制表格位置的7种实战技巧 第一次用LaTeX写论文时,我盯着那个莫名其妙跑到页面顶端的表格整整发呆了十分钟——明明代码里它乖乖待在文字下方,编译后却像长了腿一样自己跑到了前面。这种"表格不听话&quo…...

PySpark实战:从版本冲突到精准匹配Python的避坑指南
1. 当PySpark遇上Python版本冲突:一个真实运维案例 去年接手公司大数据平台时,我遇到了一个典型问题:开发团队提交的PySpark作业频繁报错,错误信息五花八门,从"ImportError: cannot import name xxx"到"…...