【InternLM 实战营笔记】大模型评测
随着人工智能技术的快速发展, 大规模预训练自然语言模型成为了研究热点和关注焦点。OpenAI于2018年提出了第一代GPT模型,开辟了自然语言模型生成式预训练的路线。沿着这条路线,随后又陆续发布了GPT-2和GPT-3模型。与此同时,谷歌也探索了不同的大规模预训练模型方案,例如如T5, Flan等。OpenAI在2022年11月发布ChatGPT,展示了强大的问答能力,逻辑推理能力和内容创作能力,将模型提升到了实用水平,改变人们对大模型能力的认知。在2023年4月,OpenAI发布了新升级的GPT-4模型,通过引入多模态能力,进一步拓展了大语言模型的能力边界,朝着通用人工智能更进一步。ChatGPT和GPT-4推出之后,微软凭借强大的产品化能力迅速将其集成进搜索引擎和Office办公套件中,形成了New Bing和 Office Copilot等产品。谷歌也迅速上线了基于自家大语言模型PaLM和PaLM-2的Bard,与OpenAI和微软展开正面竞争。国内的多家企业和研究机构也在开展大模型的技术研发,百度,阿里,华为,商汤,讯飞等都发布了各自的国产语言大模型,清华,复旦等高校也相继发布了GLM, MOSS等模型。
为了准确和公正地评估大模型的能力,国内外机构在大模型评测上开展了大量的尝试和探索。斯坦福大学提出了较为系统的评测框架HELM,从准确性,安全性,鲁棒性和公平性等维度开展模型评测。纽约大学联合谷歌和Meta提出了SuperGLUE评测集,从推理能力,常识理解,问答能力等方面入手,构建了包括8个子任务的大语言模型评测数据集。加州大学伯克利分校提出了MMLU测试集,构建了涵盖高中和大学的多项考试,来评估模型的知识能力和推理能力。谷歌也提出了包含数理科学,编程代码,阅读理解,逻辑推理等子任务的评测集Big-Bench,涵盖200多个子任务,对模型能力进行系统化的评估。在中文评测方面,国内的学术机构也提出了如CLUE,CUGE等评测数据集,从文本分类,阅读理解,逻辑推理等方面评测语言模型的中文能力。
随着大模型的蓬勃发展,如何全面系统地评估大模型的各项能力成为了亟待解决的问题。由于大语言模型和多模态模型的能力强大,应用场景广泛,目前学术界和工业界的评测方案往往只关注模型的部分能力维度,缺少系统化的能力维度框架与评测方案。OpenCompass提供设计一套全面、高效、可拓展的大模型评测方案,对模型能力、性能、安全性等进行全方位的评估。OpenCompass提供分布式自动化的评测系统,支持对(语言/多模态)大模型开展全面系统的能力评估。
OpenCompass介绍
评测对象
本算法库的主要评测对象为语言大模型与多模态大模型。我们以语言大模型为例介绍评测的具体模型类型。
-
基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
-
对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
工具架构
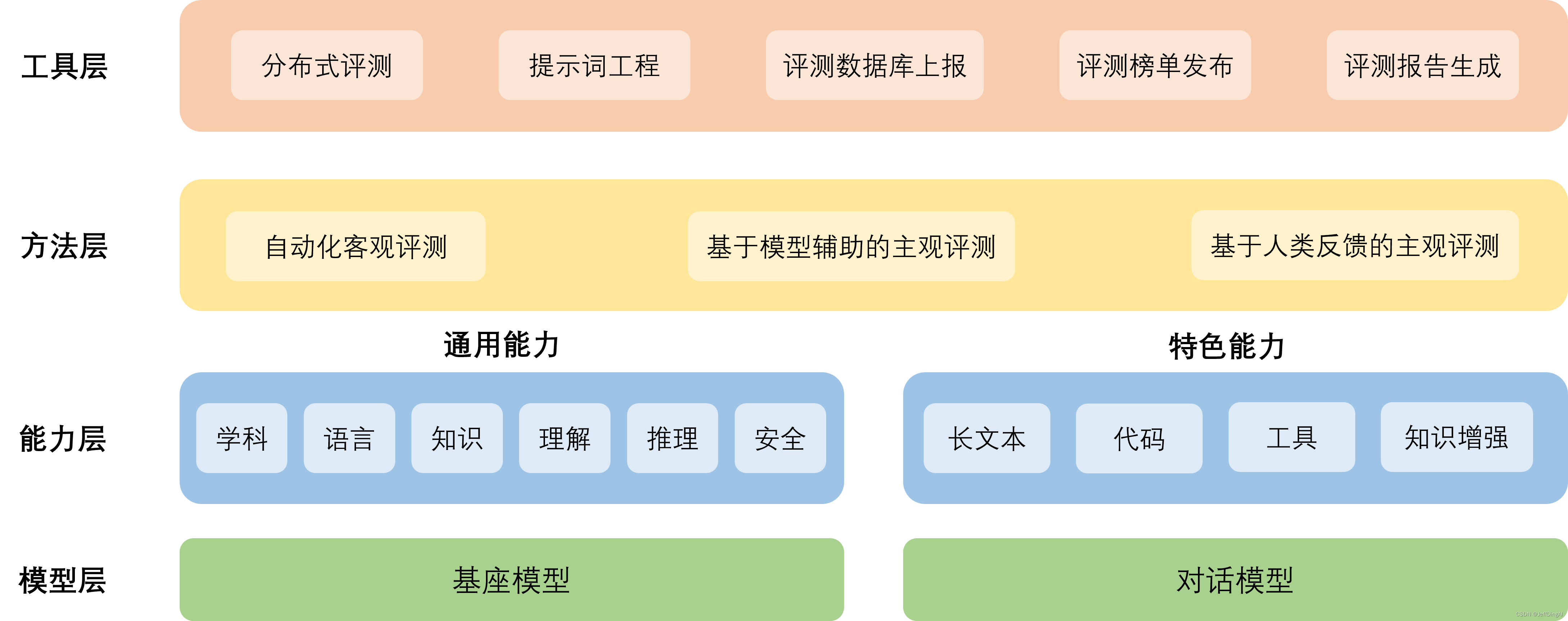
- 模型层:大模型评测所涉及的主要模型种类,OpenCompass以基座模型和对话模型作为重点评测对象。
- 能力层:OpenCompass从本方案从通用能力和特色能力两个方面来进行评测维度设计。在模型通用能力方面,从语言、知识、理解、推理、安全等多个能力维度进行评测。在特色能力方面,从长文本、代码、工具、知识增强等维度进行评测。
- 方法层:OpenCompass采用客观评测与主观评测两种评测方式。客观评测能便捷地评估模型在具有确定答案(如选择,填空,封闭式问答等)的任务上的能力,主观评测能评估用户对模型回复的真实满意度,OpenCompass采用基于模型辅助的主观评测和基于人类反馈的主观评测两种方式。
- 工具层:OpenCompass提供丰富的功能支持自动化地开展大语言模型的高效评测。包括分布式评测技术,提示词工程,对接评测数据库,评测榜单发布,评测报告生成等诸多功能。
能力维度
评测方法
OpenCompass采取客观评测与主观评测相结合的方法。针对具有确定性答案的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价。针对体现模型能力的开放式或半开放式的问题、模型安全问题等,采用主客观相结合的评测方式。
客观评测
针对具有标准答案的客观问题,我们可以我们可以通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。同时,由于大语言模型输出自由度较高,在评测阶段,我们需要对其输入和输出作一定的规范和设计,尽可能减少噪声输出在评测阶段的影响,才能对模型的能力有更加完整和客观的评价。
为了更好地激发出模型在题目测试领域的能力,并引导模型按照一定的模板输出答案,OpenCompass采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。
在客观评测的具体实践中,我们通常采用下列两种方式进行模型输出结果的评测:
- 判别式评测:该评测方式基于将问题与候选答案组合在一起,计算模型在所有组合上的困惑度(perplexity),并选择困惑度最小的答案作为模型的最终输出。例如,若模型在 问题? 答案1 上的困惑度为 0.1,在 问题? 答案2 上的困惑度为 0.2,最终我们会选择 答案1 作为模型的输出。
- 生成式评测:该评测方式主要用于生成类任务,如语言翻译、程序生成、逻辑分析题等。具体实践时,使用问题作为模型的原始输入,并留白答案区域待模型进行后续补全。我们通常还需要对其输出进行后处理,以保证输出满足数据集的要求。
主观评测
语言表达生动精彩,变化丰富,大量的场景和能力无法凭借客观指标进行评测。针对如模型安全和模型语言能力的评测,以人的主观感受为主的评测更能体现模型的真实能力,并更符合大模型的实际使用场景。
OpenCompass采取的主观评测方案是指借助受试者的主观判断对具有对话能力的大语言模型进行能力评测。在具体实践中,我们提前基于模型的能力维度构建主观测试问题集合,并将不同模型对于同一问题的不同回复展现给受试者,收集受试者基于主观感受的评分。由于主观测试成本高昂,本方案同时也采用使用性能优异的大语言模拟人类进行主观打分。在实际评测中,本文将采用真实人类专家的主观评测与基于模型打分的主观评测相结合的方式开展模型能力评估。
在具体开展主观评测时,OpenComapss采用单模型回复满意度统计和多模型满意度比较两种方式开展具体的评测工作。
实践
安装
conda create --name opencompass --clone=/root/share/conda_envs/internlm-base
source activate opencompass
git clone https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
数据准备
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
查看支持的数据集和模型
# 列出所有跟 internlm 及 ceval 相关的配置
python tools/list_configs.py internlm ceval
启动评测
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
命令解析
--datasets ceval_gen \
--hf-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace 模型路径
--tokenizer-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 2048 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
评测结果
dataset version metric mode opencompass.models.huggingface.HuggingFace_model_repos_internlm-chat-7b
---------------------------------------------- --------- ------------- ------ -------------------------------------------------------------------------
ceval-computer_network db9ce2 accuracy gen 31.58
ceval-operating_system 1c2571 accuracy gen 36.84
ceval-computer_architecture a74dad accuracy gen 28.57
ceval-college_programming 4ca32a accuracy gen 32.43
ceval-college_physics 963fa8 accuracy gen 26.32
ceval-college_chemistry e78857 accuracy gen 16.67
ceval-advanced_mathematics ce03e2 accuracy gen 21.05
ceval-probability_and_statistics 65e812 accuracy gen 38.89
ceval-discrete_mathematics e894ae accuracy gen 18.75
ceval-electrical_engineer ae42b9 accuracy gen 35.14
ceval-metrology_engineer ee34ea accuracy gen 50
ceval-high_school_mathematics 1dc5bf accuracy gen 22.22
ceval-high_school_physics adf25f accuracy gen 31.58
ceval-high_school_chemistry 2ed27f accuracy gen 15.79
ceval-high_school_biology 8e2b9a accuracy gen 36.84
ceval-middle_school_mathematics bee8d5 accuracy gen 26.32
ceval-middle_school_biology 86817c accuracy gen 61.9
ceval-middle_school_physics 8accf6 accuracy gen 63.16
ceval-middle_school_chemistry 167a15 accuracy gen 60
ceval-veterinary_medicine b4e08d accuracy gen 47.83
ceval-college_economics f3f4e6 accuracy gen 41.82
ceval-business_administration c1614e accuracy gen 33.33
ceval-marxism cf874c accuracy gen 68.42
ceval-mao_zedong_thought 51c7a4 accuracy gen 70.83
ceval-education_science 591fee accuracy gen 58.62
ceval-teacher_qualification 4e4ced accuracy gen 70.45
ceval-high_school_politics 5c0de2 accuracy gen 26.32
ceval-high_school_geography 865461 accuracy gen 47.37
ceval-middle_school_politics 5be3e7 accuracy gen 52.38
ceval-middle_school_geography 8a63be accuracy gen 58.33
ceval-modern_chinese_history fc01af accuracy gen 73.91
ceval-ideological_and_moral_cultivation a2aa4a accuracy gen 63.16
ceval-logic f5b022 accuracy gen 31.82
ceval-law a110a1 accuracy gen 25
ceval-chinese_language_and_literature 0f8b68 accuracy gen 30.43
ceval-art_studies 2a1300 accuracy gen 60.61
ceval-professional_tour_guide 4e673e accuracy gen 62.07
ceval-legal_professional ce8787 accuracy gen 39.13
ceval-high_school_chinese 315705 accuracy gen 63.16
ceval-high_school_history 7eb30a accuracy gen 70
ceval-middle_school_history 48ab4a accuracy gen 59.09
ceval-civil_servant 87d061 accuracy gen 53.19
ceval-sports_science 70f27b accuracy gen 52.63
ceval-plant_protection 8941f9 accuracy gen 59.09
ceval-basic_medicine c409d6 accuracy gen 47.37
ceval-clinical_medicine 49e82d accuracy gen 40.91
ceval-urban_and_rural_planner 95b885 accuracy gen 45.65
ceval-accountant 002837 accuracy gen 26.53
ceval-fire_engineer bc23f5 accuracy gen 22.58
ceval-environmental_impact_assessment_engineer c64e2d accuracy gen 64.52
ceval-tax_accountant 3a5e3c accuracy gen 34.69
ceval-physician 6e277d accuracy gen 40.82
ceval-stem - naive_average gen 35.09
ceval-social-science - naive_average gen 52.79
ceval-humanities - naive_average gen 52.58
ceval-other - naive_average gen 44.36
ceval-hard - naive_average gen 23.91
ceval - naive_average gen 44.16
02/28 20:08:44 - OpenCompass - INFO - write summary to /root/opencompass/outputs/default/20240228_194822/summary/summary_20240228_194822.txt
相关文章:
【InternLM 实战营笔记】大模型评测
随着人工智能技术的快速发展, 大规模预训练自然语言模型成为了研究热点和关注焦点。OpenAI于2018年提出了第一代GPT模型,开辟了自然语言模型生成式预训练的路线。沿着这条路线,随后又陆续发布了GPT-2和GPT-3模型。与此同时,谷歌也…...

数据卷(Data Volumes) 自定义镜像(dockerfile)
目录 一. 数据卷(Data Volumes) 1.1 什么是数据卷 1.2 为什么需要数据卷 1.3 数据卷的作用 1.4 数据卷的使用 二. 自定义镜像(dockerfile) 2.1 什么是dockerfile 2.2 自定义centos 2.3 自定义tomcat 一. 数据卷(Data…...
数据库管理-第156期 Oracle Vector DB AI-07(20240227)
数据库管理156期 2024-02-27 数据库管理-第156期 Oracle Vector DB & AI-07(20240227)1 Vector相关DDL操作可以在现有的表上新增vector数据类型的字段:可以删除包含vector数据类型的列:可以使用CTAS的方式,从其他有…...
CASAtomic原子操作详解
什么是原子操作?如何实现原子操作? 我们在接触到事务的时候,了解到事务的一大特性是原子性,一个事务要么全部执行、要么全部不执行。 并发里的原子性和事务里的原子性有一样的内涵和概念。假定有2个操作A和B都包含多个步骤…...
真机测试——关于荣耀Magic UI系列HBuilder真机调试检测不到解决办法
出现这种状况怎么办 1、开启USB调试 2、重点来了——我们要选择USB配置,选择音频来源 3、连接OK...

代理IP安全问题:在国外使用代理IP是否安全
目录 前言 一、国外使用代理IP的安全风险 1. 数据泄露 2. 恶意软件 3. 网络攻击 4. 法律风险 二、保护国外使用代理IP的安全方法 1. 选择可信的代理服务器 2. 使用加密协议 3. 定期更新系统和软件 4. 注意网络安全意识 三、案例分析 总结 前言 在互联网时代&…...

SonarLint 疑难语法修正
/*** 投诉率统计(厂端)* 1.通过售后小区分组统计* 2.通过经销商分组统计* param kpiComplaintRateQueryVO 查询参数* return 投诉率统计数据*/ApiOperation(value "厂端投诉率统计维度查询")PostMapping("/vcdc/ratestatis")public List<KpiComplaintR…...

MurmurHash算法
MurmurHash:(multiply and rotate) and (multiply and rotate) Hash,乘法和旋转的hash 算法。 一、哈希函数 散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“…...
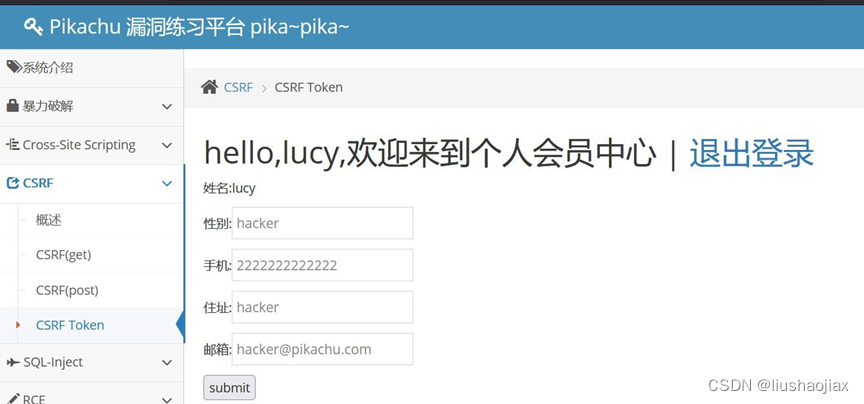
CSRF靶场实战
DVWA靶场链接:https://pan.baidu.com/s/1eUlPyB-gjiZwI0wsNW_Vkw?pwd0b52 提取码:0b52 DVWA Low 级别打开靶场,修改密码 复制上面的 url,写个简单的 html 文件 <html <body> <a hrefhttp://127.0.0.1/DVWA/vulne…...

小程序性能优化
背景 在开发小程序的过程中我们发现,小程序的经常会遇到性能问题,尤其是在微信开发者工具的时候更是格外的卡,经过排查发现,卡顿的页面有这么多的js代码需要加载,而且都是在进入这个页面的时候加载,这就会…...

C++拿几道题练练手吧
第 1 题 【 问答题 】 • 最短路径问题 平面上有n个点(n<100),每个点的坐标均在-10000~10000之间。其中的一些点之间有连线。 若有连线,则表示可从一个点到达另一个点,即两点间有通路,通路的距离为两点间的直线距离。现在的任务…...

【国产MCU】-CH32V307-I2C控制器
I2C控制器 文章目录 I2C控制器1、I2C模块介绍2、I2C驱动API介绍3、I2C使用实例3.1 主模式3.1.1 主设备发送模式和主设备接收模式3.1.2 DMA方式发送3.2 从模式内部集成电路总线(I2C)广泛用在微控制器和传感器及其他片外模块的通讯上,它本身支持多主多从模式,仅仅使用两根线(…...

k8s pod理论
一、Pod概述 1、Pod的定义 Pod是K8S中创建和管理的最小单位。 2、一个Pod至少包含多少容器 1个pause容器(基础容器/父容器/根容器)和 1个或者多个应用容器(业务容器) 通常一个Pod最好只包含一个应用容器,一个应用容…...

智慧应急:构建全方位、立体化的安全保障网络
一、引言 在信息化、智能化快速发展的今天,传统的应急管理模式已难以满足现代社会对安全保障的需求。智慧应急作为一种全新的安全管理模式,旨在通过集成物联网、大数据、云计算、人工智能等先进技术,实现对应急事件的快速响应、精准决策和高…...

国际黄金价格是什么?和黄金价格有何区别?
黄金是世界上最珍贵的贵金属之一,其价值被无数人所垂涎。而国际黄金价格作为市场上的参考指标,直接影响着黄金交易的买卖。那么国际黄金价格到底是什么,与黄金价格又有何区别呢?本文将为您详细解答。 国际黄金价格是指以美元计量的…...

React入门简介
React简介 react是Facebook用来创建用户界面的js库。React不是一个MVC框架,而是一个用于构建组件ui库,是一个前端界面开发工具,所以很多人认为React是MVC中的V(视图)。React的存在能够很好的解决‘构建随着时间数据不断…...

强化学习_06_pytorch-PPO实践(Hopper-v4)
一、PPO优化 PPO的简介和实践可以看笔者之前的文章 强化学习_06_pytorch-PPO实践(Pendulum-v1) 针对之前的PPO做了主要以下优化: batch_normalize: 在mini_batch 函数中进行adv的normalize, 加速模型对adv的学习policyNet采用beta分布(0~1): 同时增加MaxMinScale …...
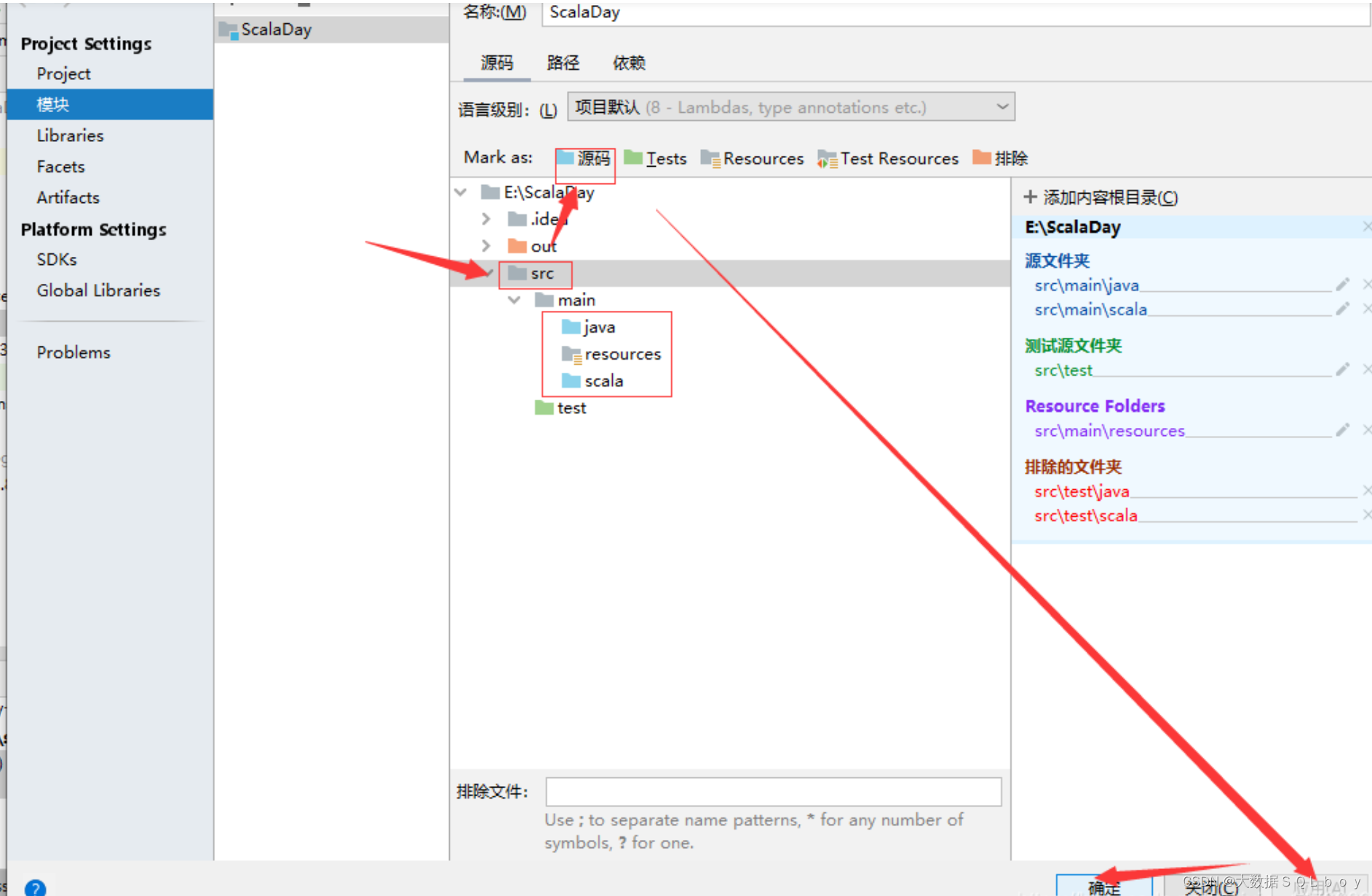
Scala Intellij编译错误:idea报错xxxx“is already defined as”
今天写scala代码时,Idea报了这样的错误,如下图所示: 一般情况下原因分两种: 第一是我们定义的类或对象重复多次出现,编译器无法确定使用哪个定义。 这通常是由于以下几个原因导致的: 重复定义:在同一个文件…...
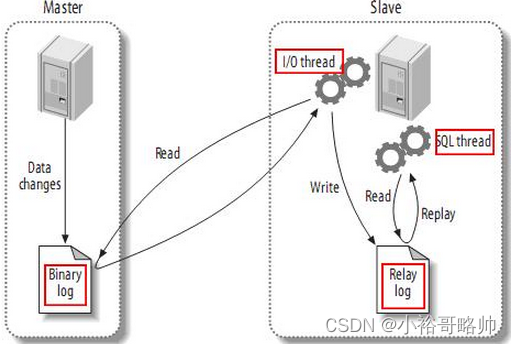
面试笔记系列五之MySql+Mybaits基础知识点整理及常见面试题
myibatis执行过程 1读取MyBatis的配置文件。 mybatis-config.xml为MyBatis的全局配置文件,用于配置数据库连接信息。 2加载映射文件。映射文件即SQL映射文件,该文件中配置了操作数据库的SQL语句,需要在MyBatis配置文件mybatis-config.xml中…...

掌握Pillow:Python图像处理的艺术
掌握Pillow:Python图像处理的艺术 引言Python与图像处理的概述Pillow库基础导入Pillow库基本概念图像的打开、保存和显示 图像操作基础图像的剪裁图像的旋转和缩放色彩转换和滤镜应用文字和图形的绘制 高级图像处理图像的合成与蒙版操作像素级操作与图像增强复杂图形…...

COMSOL声学建模实战:从散射场分析到声子晶体能带计算
1. 散射场分析:从声呐案例理解声波与物体的相互作用 第一次接触COMSOL声学模块时,最让我困惑的就是"散射场"这个概念。直到做了声呐的案例,才真正明白它的物理意义。想象一下,你站在湖边大喊,声音碰到对岸的…...

FanControl免费风扇控制软件:3分钟快速上手终极指南
FanControl免费风扇控制软件:3分钟快速上手终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/F…...
)
树莓派4B上Miniconda3保姆级安装教程(含清华源配置与常见SSL报错解决)
树莓派4B上Miniconda3保姆级安装教程(含清华源配置与常见SSL报错解决) 刚拿到树莓派4B的开发者们,往往迫不及待想搭建Python开发环境。但ARM架构的特殊性、网络问题、权限设置和SSL证书验证等坑,常常让新手寸步难行。本文将手把手…...
)
用C语言手把手教你写一个Linux虚拟键盘驱动(基于uinput模块)
用C语言手把手教你写一个Linux虚拟键盘驱动(基于uinput模块) 在嵌入式开发和系统编程领域,模拟用户输入是一个常见需求。想象一下这样的场景:你正在开发一台没有物理键盘的工业控制设备,或者需要为自动化测试创建可靠的…...

终极macOS视频预览解决方案:如何让Finder完美支持MKV、AVI、WebM等50+格式
终极macOS视频预览解决方案:如何让Finder完美支持MKV、AVI、WebM等50格式 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地…...

抖音下载器完整教程:免费无水印批量下载的终极解决方案
抖音下载器完整教程:免费无水印批量下载的终极解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

毕业设计实战:基于Java+SpringBoot与微信小程序的企业门户系统设计与开发
1. 项目背景与技术选型 最近几年,企业门户系统开发的技术栈发生了很大变化。记得5年前我做第一个企业站项目时,用的还是PHPMySQL组合,现在JavaSpringBoot已经成为企业级开发的主流选择。这次毕业设计选择这个技术组合,不仅符合当前…...
)
别再瞎调了!Cartographer 2D建图参数保姆级调试指南(附室内实测避坑清单)
Cartographer 2D建图参数调试实战手册:从入门到精通的避坑指南 当第一次打开Cartographer的配置文件时,大多数开发者都会有种面对瑞士军刀却不知从何下手的困惑。这个由Google开源的SLAM算法以其强大的建图能力著称,但海量的参数配置也让不少…...

时间序列模型选型指南:AR、MA、ARMA、ARIMA到底该用哪个?结合销售预测与服务器监控案例讲清楚
时间序列模型选型实战:从销售预测到服务器监控的决策逻辑 当业务团队甩来一份历史销售数据要求预测下季度业绩,或是运维部门急需根据服务器日志预测潜在故障时,许多技术决策者会陷入选择困难——AR、MA、ARMA、ARIMA这些字母组合究竟意味着什…...
)
告别OpenCV!用STM32+OV7725从零搭建一个HSL颜色追踪小车(附完整源码)
STM32OV7725颜色追踪小车:从硬件搭建到PID调参全指南 在创客圈和机器人竞赛中,自动追踪特定颜色物体的小车一直是热门项目。传统方案依赖OpenCV等计算机视觉库,但在资源受限的嵌入式场景下,如何仅用STM32微控制器和OV7725摄像头实…...